
2
How Not to Mess Up Your System Architecture
This chapter will start with an explanation of how you mess up your system landscape by not retaining a disciplined approach to implementation and governance. We will then go through how coupling can become so tight that you create systems too fragile to use. Finally, we will look at some anti-patterns related to how you can structure orgs within an organization that uses Salesforce into multiple geographies and business units.
In this chapter, we’re going to cover the following main topics:
- How the Stovepipe anti-pattern can leave us with systems that can only work in isolation and what you can do to avoid building stovepipes
- What a Big Ball of Mud is, why a system can deteriorate into a state that fits this description, and how you can prevent it from happening to your system
- How intense coupling makes systems fragile and potentially unusable, and how to draw clearer system boundaries that avoid this issue
- What unfettered org creation can do to your enterprise architecture and how to better manage your Salesforce environments
After completing this chapter, you will have a good grasp of some of the main maladies that can afflict a Salesforce system architecture. You will also learn about the key things to look out for in your architecture practice to avoid going down a path that will lead you to these anti-patterns or suggesting a solution prone to these kinds of issues when sitting for the CTA Review Board.
Muddling up the systems landscape
The easiest way to muddle up your systems landscape, as we shall see, is to go ahead with implementation in a local, unstructured, and badly governed way. While there are many attractions to small local projects, they very easily deteriorate into anti-patterns that have serious negative consequences for your overall enterprise architecture. We will start by looking at the classic Stovepipe anti-pattern, which is a common outgrowth of such projects, and then look at its organizational cousin, Stovepipe Enterprise.
Stovepipe
An example
John is the CRM manager at DreamCo, a provider of bespoke travel accessories. The company has decided to invest in a small implementation of Salesforce Sales Cloud, replacing an old Siebel system that’s been in operation for more than a decade. While initially fearful, John has come to be quite excited about the project, as it promises to fix a number of thorny issues that they’ve been unable to address with the old CRM.
DreamCo hires a small local Salesforce consultancy to do the implementation. Initially, it is a great success, the sales teams love the new tool, and many of the features requested by John are readily implemented. However, after a while, progress seems to slow and the price of changes goes up. DreamCo’s CIO makes the assessment that their business requirements are now too complex for the small local consultancy to manage and hire a leading Salesforce Summit partner to take over.
At the same time, DreamCo’s head of customer service decides to commission a third Salesforce partner to implement Salesforce Service Cloud for the company’s call center. John has been learning a lot about Salesforce during the initial period and is starting to get worried that there are no common conventions, standards, methodologies, or tools across the different partners or implementations. The sales department and the customer service department also seem to use very different data models to represent fundamentally the same things.
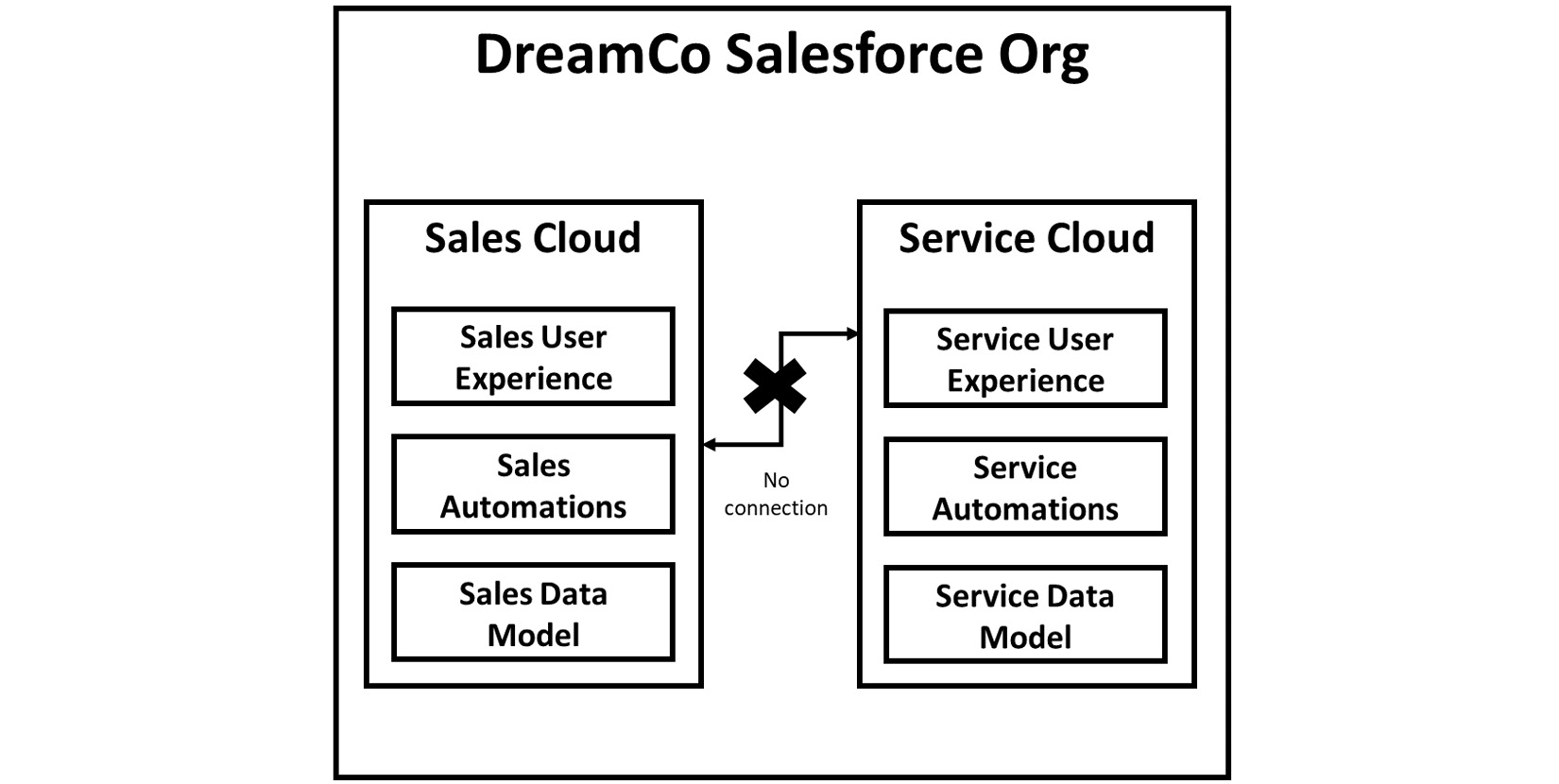
Figure 2.1 – DreamCo’s org after the initial implementations
John raises these points to the CIO and asks for a budget to hire an architect and to do some refactoring on the existing systems to bring them more in line. He is told that while his idea is good, it isn’t affordable right now, but he should put in a budget request for next year’s budget.
At this time, DreamCo purchases a smaller company that sells travel accessories via vending machines in airports. They reportedly have a very strong Salesforce implementation, much more advanced than DreamCo’s, including sales, service, and field service modules. John is given the task of finding a way to consolidate the two Salesforce orgs into one without requiring the two organizations to fundamentally change their processes.
John engages with the Summit partner to explore options for the consolidation. They come back with a proposal that meets the basic requirement, but at a cost that is much higher than expected. The partner explains that the excessive technical complexity in the DreamCo org makes it very difficult to integrate with the new org. Furthermore, they advise against going down the consolidation route and instead advise DreamCo to move everyone to the org from the company that has been recently acquired and change the processes to make this work without changing the technology.
After some internal discussion, DreamCo decides to go ahead with the consolidation anyway. Problems start appearing almost right away:
- First, it proves very difficult for the different vendors that need to be involved to collaborate effectively, leading to a situation where the lead partner is effectively required to reverse-engineer a number of features in order to understand them.
- Second, the implementation progress is very slow and John realistically can see no way for the project to complete on time.
- Third, the error rate is very high and there are many recurring errors on each test cycle. All of this is leading toward a project that will be significantly over budget, behind schedule, and below expectation on quality.
John starts digging into the detail, and from the various technical people involved in the project, he learns a number of disturbing facts. First, basic things such as naming conventions are completely different, not only between the DreamCo and the NewCo org but also within the DreamCo org; at least three completely different sets of conventions exist. In addition, features are implemented using completely different methodologies and toolsets, and sometimes the same feature is reimplemented in different ways in different parts of the system.
There are also a number of custom fields and objects that exist in subtly different duplicated variants in different parts of the system. Finally, a number of third-party tools have been used to provide functionality. However, these tools and their functions were never properly documented and no one in the organization knows how to use them after the change of vendors. Adding this to the inherent complexity involved in finding a common language between the DreamCo and the NewCo orgs, most of the technical teams are starting to throw their hands up in despair.
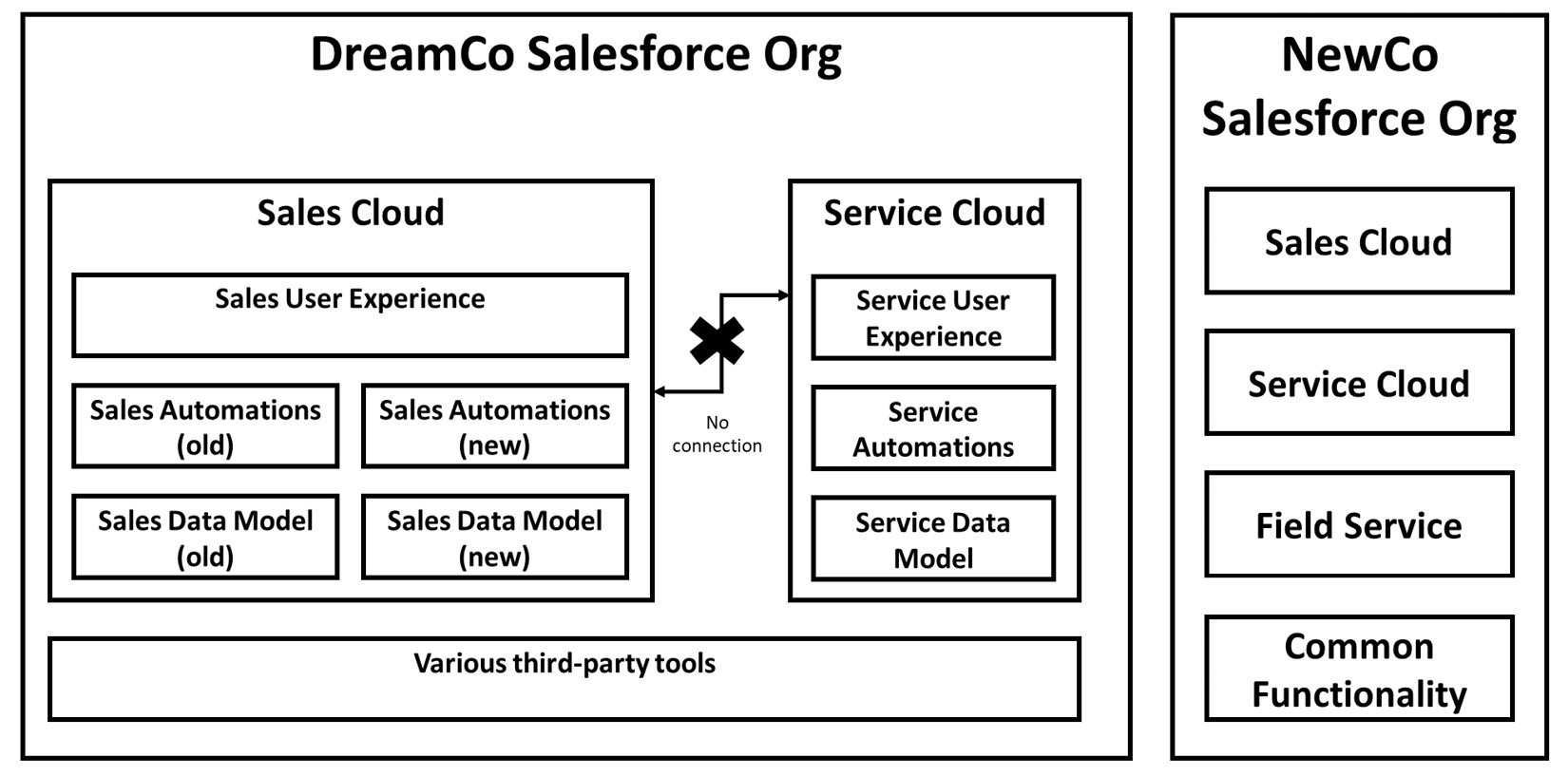
Figure 2.2 – The DreamCo consolidation scenario
John reports this back to senior management and the situation escalates into a major crisis. Eventually, after much wrangling, DreamCo gives up on consolidating the two orgs and decides to leave them in place separately instead for the time being, with data consolidated elsewhere for reporting.
The problem
How do you implement an IT system in an organization where departments are siloed, power is distributed into individual fiefdoms, technical teams work independently of each other, and there is no strong central authority on architecture or technical standards? The answer, in general, is the stovepipe anti-pattern. Given the prevalence of these organizational characteristics, stovepipe is one of the most common anti-patterns you are likely to encounter as an architect.
Let’s not disregard how hard it is to get around some of these issues. Changing organizational structures or cultures can require years of transformation, even with senior management support, and even then, many unfortunate practices may still linger.
So, when you are an ambitious manager with the need for a new IT system in the kind of organization described above, it is very tempting to simply go ahead within your own little kingdom and implement something, working with people that you personally trust, in a way that works for you, without much consideration for the rest of the business. Without strong corporate IT governance and enterprise architecture support, there is little most IT departments can do about this.
The stovepipe anti-pattern then does provide a real answer to a real problem, as we will discuss in the next section. However, it is an answer that reliably leads to unfortunate results.
The proposed solution
Fundamentally, a stovepipe proposes to solve the coordination problems inherent in many organizations by building a solution in splendid isolation, not taking into account any wider concerns or requirements, using whatever tooling and standards the implementing team prefers. That way, you can simply go ahead while short-circuiting corporate bureaucracy in the process.
This is an attractive solution in a number of ways:
- You do not have to engage in cross-silo collaboration or resolve thorny internal political issues
- Your technical teams often love it because they can use whatever tools they prefer to get the job done
- It tends to work very well in the short term, quickly delivering on requirements and generating local value, often at a very reasonable price point
- For organizations without strong central IT leadership, it can be the default way to operate, and it may simply become “the way things get done”
If we were living in a simpler world, where organizations could compartmentalize their operations between discreet groups that didn’t have to collaborate much to get things done, and consequently, systems didn’t have to support cross-cutting workflows or cross-system integrations, then a stovepipe would actually be a perfectly reasonable approach to software development.
However, in practice, most organizations do need most of their systems to work across a wide range of departments and use cases, which is when we start to get into trouble, as we’ll see in the next section.
The result
As previously pointed out, and as we saw in our example, a stovepipe often initially works well. For a point solution used by a single team, there isn’t any inherent downside to building in this local way. As we saw, the issues start to accumulate when we have multiple players on the same underlying platform, for example, the Sales and Service organizations we mentioned, when we try to extend the system to use cases it wasn’t designed for, and when we need it to play well with other external systems.
On Salesforce, it is normal to have many different modules in simultaneous operation in the same org that leverage a common data model, user interface, and technical configuration. Unfortunately, this makes it particularly easy to end up with stovepipe-type problems if you do not implement these modules consistently.
Over time, the indicators of a stovepipe anti-pattern tend to be the following:
- An increasing difficulty in understanding the code base, especially for new parties working with the system
- Inconsistent architectural design and implementation patterns in different areas of the system
- A diminishing user experience and user value due to the increasing inconsistency and inflexibility of the system
- Great difficulty whenever new requirements have to be implemented
- The system is hard to integrate with other systems in the landscape
- The system is hard to incorporate into global processes, for example, a consolidated DevOps pipeline
- Increasing error rates, both during development and in production
- A higher and higher cost of change due to all these factors
The fundamental reason a stovepipe tends to deteriorate in this way is due to a lack of common standards, practices, patterns, and tooling. Inconsistency increases the cognitive load on the technical team, making everything harder and more error-prone, as well as raising the learning curve across the board. The original team might have understood it, but over time, this understanding will be lost, and the result tends to be more inconsistent, rather than a concerted effort being made to refactor it into a more comprehensible state.
You can profitably compare a team building a stovepipe to a well-functioning agile team to understand what goes wrong. An agile team may also work in relative isolation with empowered Product Owners calling the shots. However, they will work with standards, practices, patterns, and tools that are accepted and well-understood in the organization, and they will work with stable interfaces for key integrations and common abstractions for crucial system components. That way, coordination happens implicitly via that common baseline and you do not end up with a stovepipe, but rather, a well-adjusted member of the system landscape.
Better solutions
The fact is that many organizations are quite siloed, and it therefore becomes hard to solve the business-level coordination problems that arise when building, implementing, or changing systems. As architects, dealing with these issues should be part of our bread-and-butter activities in order to avoid building stovepipe systems and ensure that our platforms, such as Salesforce, continue to deliver value over the long term.
While some of the more transformative things that can be done organizationally to break down silos and improve collaboration are often beyond our power, there are many things that we can reliably do to improve the situation:
- Define clear architectural patterns and practices that can be used between teams to create common abstractions
- Put in place conventions for how different things are to be implemented, both at the macro level, for example, when to use flows and when to use triggers, and micro level, such as a coding guideline
- Adopt standards for all technical areas, such as reporting and BI or data governance, in order to ensure consistency
- Have strong guidance for creating stable interfaces for cross-system integration, as well as integration patterns for different use cases
- Put in place a common methodology for implementation across Salesforce projects to ensure consistency
- Adopt consistent tooling for all elements of the development life cycle to enable cross-team and cross-system understanding
- Enforce these standards and practices vigorously
We are in a fortunate position as Salesforce architects in that much of this work can be taken from good practices already in existence, either established by Salesforce themselves or the wider Salesforce community. You can find many good resources on the Salesforce Architects website, and Salesforce has also recently introduced the Salesforce Operating, Governance, and Architecture (SOGAF) framework to help us understand the best practices for Salesforce governance:
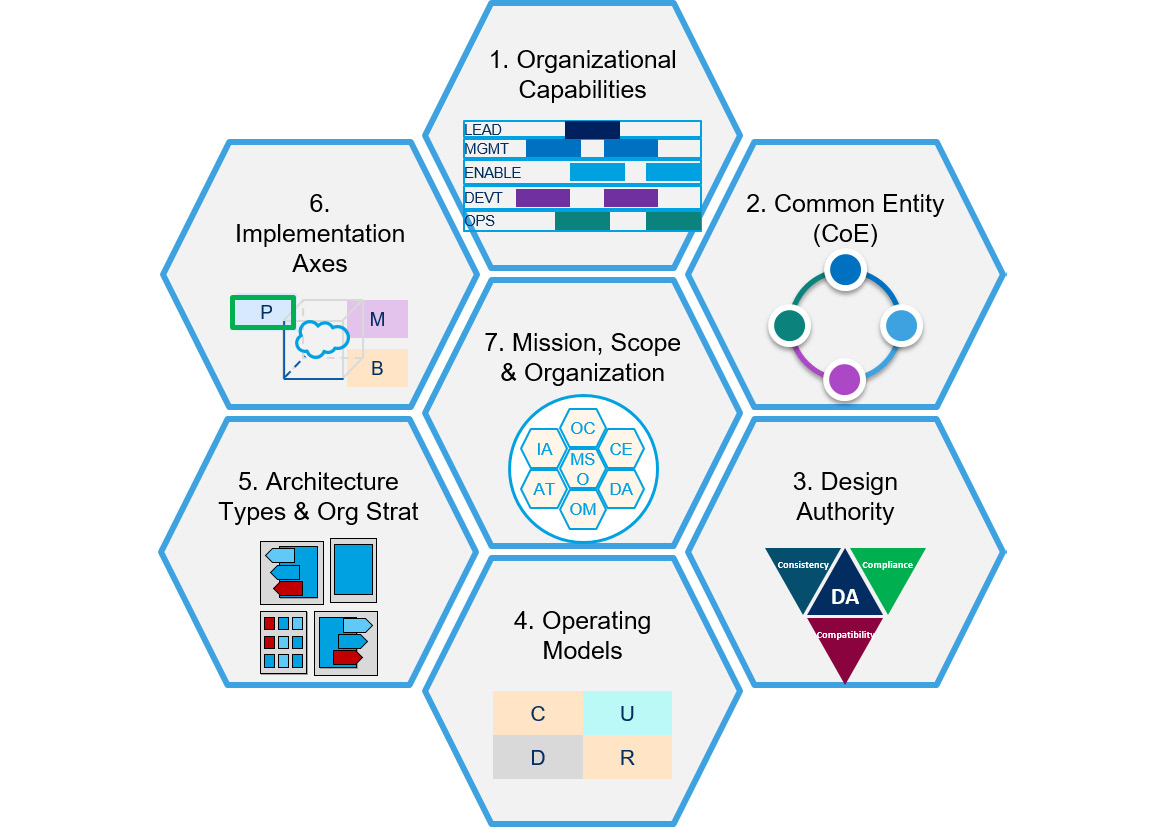
Figure 2.3 – SOGAF framework elements
However, we always have the responsibility to adopt, adapt, and implement it within our own organizations ourselves. This also includes adding the business-specific standards and practices that are unique to our situation and finding ways of communicating the standards and practices in a way that resonates across our organization.
It should be noted that sometimes standards should be broken. There are cases where you need different tools, methods, or patterns to get the job done, but you should have a standard to deviate from if you want to avoid ending up building stovepipes.
A note on Stovepipe Enterprise
The material we have discussed on this pattern so far has focused primarily on the system level. However, it will not have escaped a more perceptive reader that many of the issues that appear on the system level are related to organizational issues, particularly the tendency for some organizations to work in silos and be unproductively political.
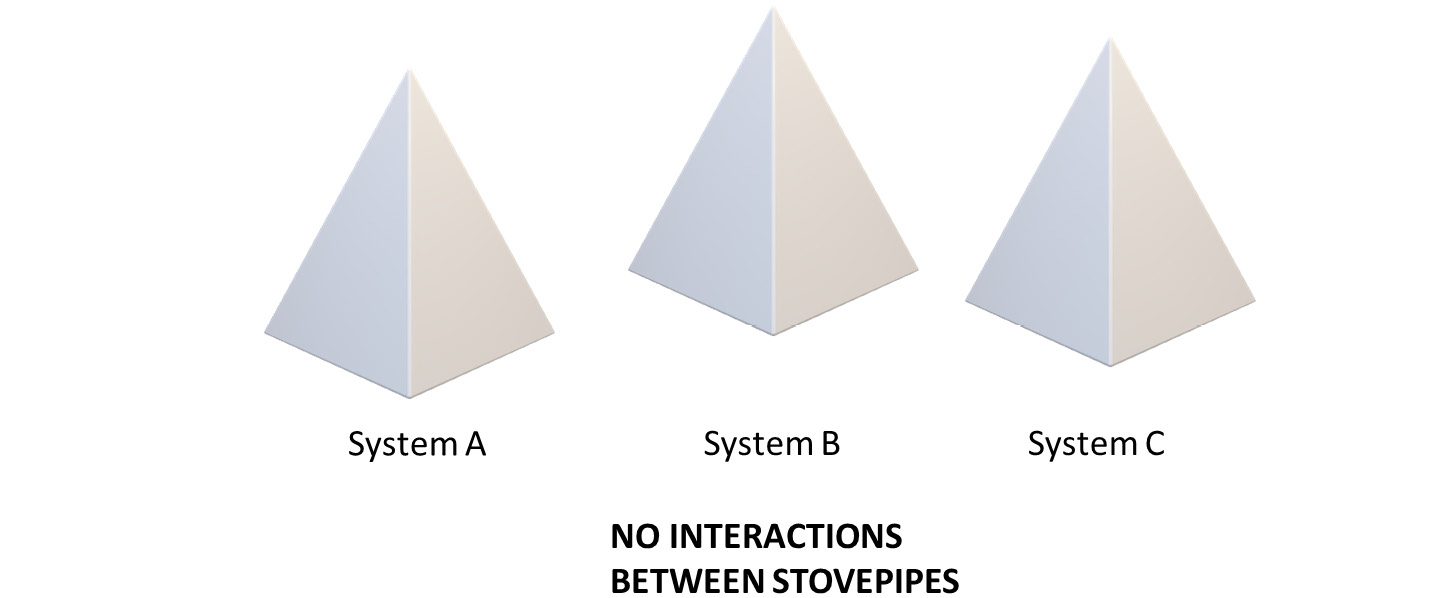
Figure 2.4 – A landscape of stovepipes making up a stovepipe enterprise
As a result, there’s an organizational-level version of the stovepipe anti-pattern called Stovepipe Enterprise, which focuses on this tendency of organizations to produce stovepipe systems due to their structural problems. While we can readily acknowledge this anti-pattern, as Salesforce architects, our remit does not usually extend to this level of problem, and we have therefore mostly focused on the system level in our discussion.
A Big Ball of Mud
An example
DreamCo has put adding more functionality to their Salesforce implementation on hold for a few months. During this time, John has been working on a plan to refactor key parts of the system to make it more maintainable. He’s been consulting a lot of technical people from the different teams that have been involved since day one and he finally thinks he has found a way forward.
However, shortly before John has a meeting to pitch his ideas to the CIO, things change rapidly on the ground. DreamCo has recently hired Ricky, an experienced architect from one of the big consultancies, to help figure out how to integrate the DreamCo and NewCo orgs. While he has generally been supportive of John’s effort to get refactoring started, it clearly hasn’t been at the top of his agenda.
Instead, he proposes to focus DreamCo’s efforts on the Salesforce side into an integration project to combine the two orgs. He proposes to do much of the technical work himself, using a third-party tool that he has previously used on other projects. The integration will be point-to-point, but it will reliably ferry the data needed back and forth between the two environments, and end the complex manual processes that the business has had to use to bridge the gap in the interim.
Given the pressure on the business, the CIO decides to go ahead with Ricky’s plan, and he implements the solution over a two-month period more or less single-handedly. John is told that his refactoring project will get the go-ahead after the integration is complete. However, once it’s done, the CIO gives the go-ahead to a new set of feature upgrades on the existing platform for both the Sales and Service teams. John is told that the business can’t wait for any new features and that instead, he will need to lead the development of a new logistics app that the business wants to build in a separate Salesforce org, with Ricky acting as the technical lead.
The new app is built quickly in the new environment but John remains concerned that it is being built with very little structure or discipline. The business seems to love what they’re seeing, so John relents and lets things go ahead, supporting where he can. While the app was meant to be an experimental prototype, the business decides they want to put it into production as is. The upgrade to the main org takes a long time to get done, but the day for the production deployment finally approaches.
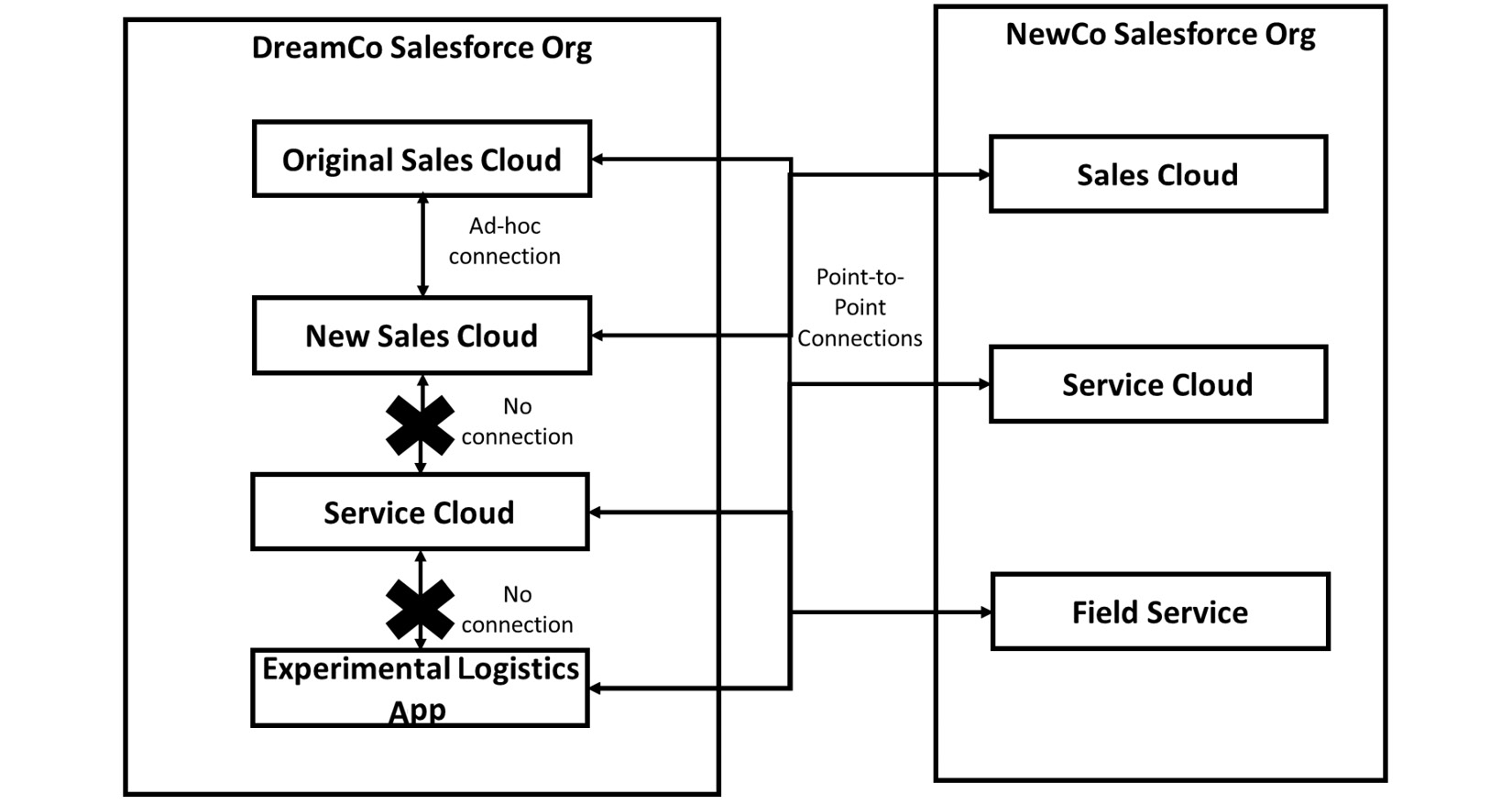
Figure 2.5 – The DreamCo Big Ball of Mud architecture
DreamCo will deploy the new upgrades as well as the new logistics app into the production org in a single deployment over a weekend. All hands are on deck and there is a positive buzz around the release, as many of these features, as well as the new app, are avidly anticipated. The last weeks are slightly marred by Ricky handing in his notice, as he has decided to take an offer from another consultancy. However, he promises to document and hand over everything before he leaves, so no one is overly concerned.
On the weekend it is going live, John is on call and avidly awaiting the results. The initial deployment runs into some issues and the full deployment doesn’t actually make it into production before Sunday afternoon. The test team starts their smoke test and it is obvious that there are major problems with the release. Major functional areas don’t seem to be working, the integration between the DreamCo and the NewCo org starts experiencing errors, and many test scripts that were working in the main org or the logistics org fail completely. Questions are raised about the quality of UAT testing but the fact is that the release has failed.
The team works frantically overnight to get the system back to a reasonable state before the business starts using it in the morning. Communications go out stating that the release had to be pulled back. DreamCo’s board calls the CIO for a consultation on what went wrong. However, no one can work it out, and for both the logistics app and the DreamCo to NewCo integration, it seems to be impossible to fix any issues now that Ricky has gone, despite knowledge transfer sessions having taken place.
After a week of finger-pointing back and forth, the CIO is fired and a replacement comes in. He commissions a detailed technical audit of the current system from a consultancy that he personally trusts. After consultation with John and many other DreamCo stakeholders, they conclude that the architecture and code quality on many components is so weak and the structure so incomprehensible that the only option is to rebuild significant parts of the system.
The problem
A Big Ball of Mud is what happens when all internal structure within a system collapses and what you are left with is a big ball of undifferentiated mud that is impossible to understand or change. In contrast to a stovepipe, which can work quite well within its own limited sphere, a Big Ball of Mud is effectively a throwaway system. You might be able to keep it running with enough firefighting, but you’ll never make it work well or significantly change it. It is a response to a system that has such great pressure to deliver functionality in several areas, that going along with any idea that seems to deliver the functionality in question seems to be a good idea.
It happens usually either as a result of ignorance or desperation, as no one intentionally sets out to create a big mess. You do, however, frequently get Big Balls of Mud from systems that have been created due to one person or a couple of people working independently without supervision, clear documentation, or good decision-making processes, as with Ricky in our example.
You could say that a Big Ball of Mud shares the Nike approach to implementation, “Just Do It.” While this may be a good principle in athletics, it rarely works out well in enterprise IT.
The proposed solution
The solution proposed by a Big Ball of Mud, in general, is to put your trust in some team or person to just get something done with no regard for the consequences. It is often attractive in pressured situations because it gives you a seemingly good way out of your predicament without having to pay the costs of disciplined development or implementation.
Big Balls of Mud often evolve from systems such as Stovepipes, when all discipline and control are lost. A stovepipe, if it is true to its own internal structure, can work well on its own for a long period of time, but once you give up on this internal discipline, it quickly devolves into a Big Ball of Mud.
Big Balls of Mud are also often created from experimental or prototype systems that are elevated to production status, as with the logistics app in our earlier example. The results of a system reaching the Big Ball of Mud stage are usually catastrophic, as we’ll discuss in the following section.
The results
A Big Ball of Mud is an end state for a system. Once the system reaches a state of total internal disorganization, the only way to keep it running is to have the one or two people who still partially understand how it works continuously firefighting to keep it going. You will neither be able to make changes that are anything other than trivial nor will it be realistic to refactor the system into a reasonable state. It would be cheaper to rebuild the key modules, which is what tends to eventually happen with these kinds of systems.
As noted in the introduction, some people like to be heroes, and also like the job security that comes from being indispensable, so the period during which a Big Ball of Mud can remain operational is surprisingly long in some cases.
The fundamental solution to the Big Ball of Mud scenario is technical discipline in various forms, which we’ll discuss next.
Better solutions
In many ways, the better solution to the Big Ball of Mud anti-pattern is similar to those we listed for the stovepipe. If you have good technical standards and practices in place and they are followed in practice, then you will not end up with a Big Ball of Mud.
More fundamentally, though, the Big Ball of Mud scenario reveals a profound lack of technical discipline and respect for craftsmanship within the executing organization. If your technical culture does not value good practice, architecture, well-structured code, and abstractions, but instead values cowboys just getting something up and running, no matter how quick and dirty, then you will be prone to end up with Big Balls of Mud.
To be sure, there are situations where quick and dirty is good enough. If you’re writing code for an ephemeral marketing campaign, a research project, or a throwaway prototype, then you don’t have to care so much about whether the system you create can evolve. However, for most of us, most of the time, this is not the case.
Too much coupling
Designing systems with low coupling and high coherence is one of the foundational aims of software architects of any stripe. Coupling, however, can be difficult to avoid and in many cases, a level of coupling can be justified as a trade-off with other concerns. In this section, however, we will see how intense coupling can become an anti-pattern that seriously affects your system architecture.
Intense coupling
An example
BigCo has a mid-size Sales Cloud implementation that they use for managing their opportunity pipeline. However, all financial processes, quoting, and order management is done in their main SAP system, which has served as the source of truth for the business for a number of years.
The sales department loves their Salesforce system and would like to carry out the entire ordering and fulfilment process through Salesforce, leaving the SAP system to the purely financial processes. The finance and supply chain teams think this idea is not only misguided, but risks compromising the strong grip BigCo has had on its data for years.
After some internal political battles, the CFO and VP of Sales reach a compromise. The order and fulfilment process will stay in SAP, along with the financial processes, but quoting will move end-to-end to Salesforce using Salesforce CPQ. That way, the sales team will rarely need to go into SAP and can stay primarily in the Salesforce interface that they love, but the other teams still keep control of all master data. Anitha, a Salesforce architect, is tasked with making this compromise into reality.
She quickly discovers some major issues with this approach:
- First, all products and prices are kept directly in SAP and there is no appetite for moving this to Salesforce; therefore, it will need to be accessed from SAP as part of the quoting process and only stub data can be replicated to Salesforce.
- Second, a number of business logic checks happen for quotes during the business process to check that they fall within acceptable corporate parameters. Anitha looks into moving these checks to Salesforce as part of the implementation. While it is possible for many, some of these checks require access to data in SAP’s financial module and can’t be done on Salesforce. These will need to be accessed via an integration to SAP too.
- Third, a number of additional services need to be called as part of the quoting process to get current product availability and possible delivery dates for inclusion on the quote. These will have to be called via SAP, as they are already exposed via webservices on this platform, and BigCo does not have the integration resources to make a direct connection to Salesforce or to connect via other middleware.
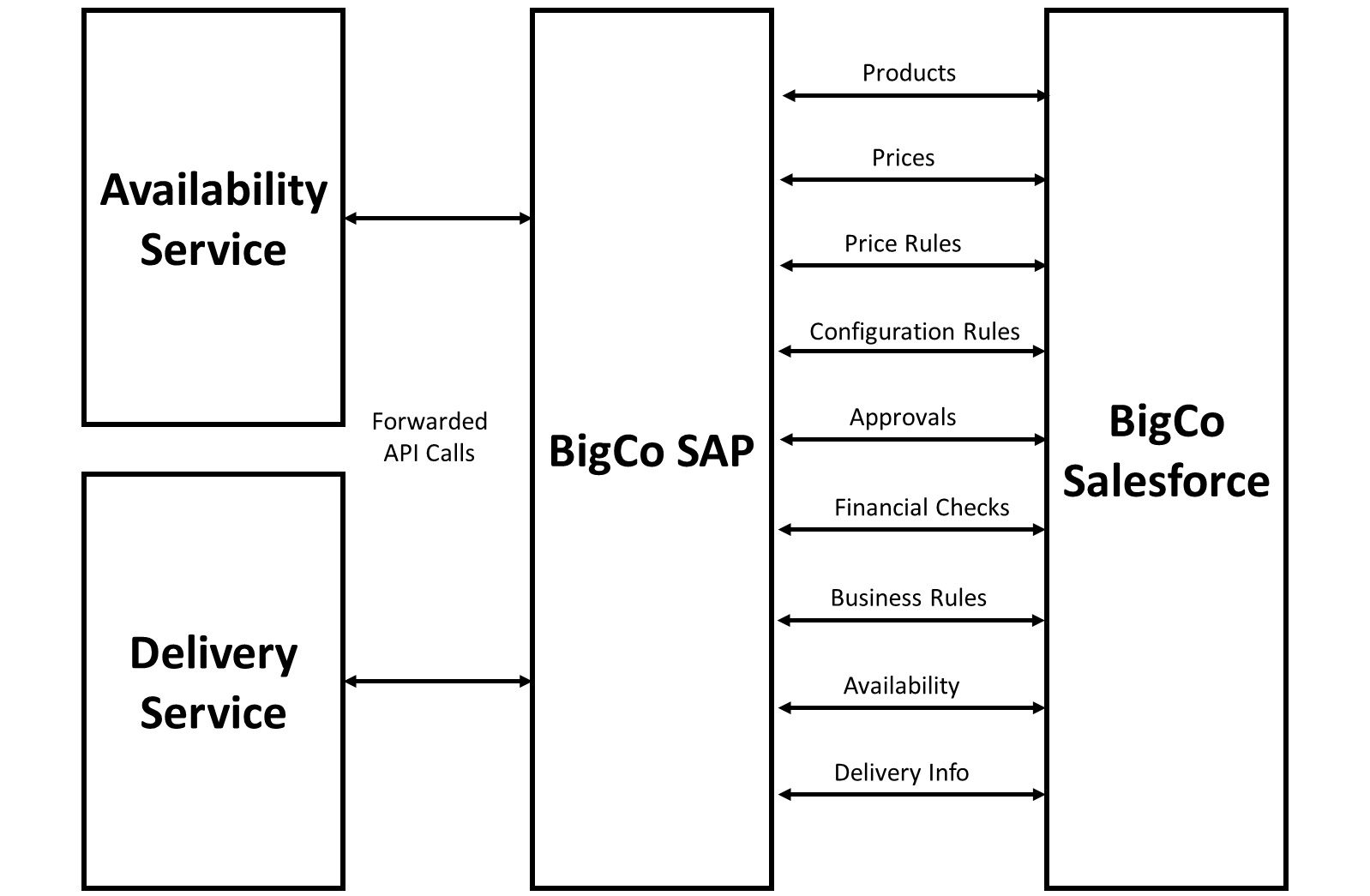
Figure 2.6 – The BigCo integration scenario
Anitha sounds the alarm and says that the degree to which Salesforce depends on SAP makes her doubt that the new system will perform to the high expectations of the sales team. She recommends looking into a different approach where there is a cleaner division between what is on SAP and what is on Salesforce. However, the Finance and Supply Chain teams rule out any process changes as part of the implementation and therefore she has to go ahead despite her doubts.
The initial workshops with users go well and the functional requirements of the sales team seem to be a good fit for what Salesforce has to offer. However, Anitha is still concerned that the final product will underperform due to the coupling to SAP.
During the UAT testing of the solution, some concerns are raised about the performance and responsiveness of the user interface, and there are also complaints that testing had to be interrupted several times due to maintenance or outages on SAP.
These concerns are not enough to hold back the go-live, however, as the team expects a boost in performance from moving to the production environment, and the basic functional aspects of the solution are acceptable.
Unfortunately, the problems are exacerbated and not alleviated by the move to production. Performance decreases significantly and sales users frequently have to wait for minutes to see a response from SAP. In addition, there are numerous periods during the day when SAP runs large scheduled jobs that stop sales users from doing anything.
The team works frantically to try to improve the situation. However, after a couple of weeks, the team has to throw in the towel and the sales team goes back to producing their quotes in SAP.
The problem
Intense coupling happens when the boundaries between systems or modules are blurred to such an extent that one depends entirely on the other for its operation. In general, as architects, we strive to reduce coupling while maintaining coherence. However, coupling – even tight coupling – can be a necessary trade-off with other requirements in some situations.
Intense coupling, however, is the most extreme version of this trade-off. At the system level, it happens when system boundaries are not respected, and you try to design a solution that incorporates and replicates significant parts of another system, using the other system as a synchronous backend.
The same pattern can repeat at the module level, where you have one module replicating all the functionality of another in a different context, calling intensely on functionality from the original module to do so.
Intense coupling is often done for good reason. There are usually real problems with the functionality of legacy systems or modules that are proving hard to address and that would seemingly be much simpler to solve in a different system or module context.
As we’ll see in the following section, the proposal that intense coupling makes to address such issues can be very compelling, which is what makes it a classic anti-pattern.
Proposed solutions
Intense coupling is a proposition that promises that you can have your cake and eat it too. By using APIs or SDKs, or using some other similar mechanism, you can get all the functionality and business logic that you are used to. Additionally, you can have it work within a new user experience that will address your changing requirements, and you won’t have to go through the pain of introducing a new system or making substantial changes to your legacy ones. As with all cake-related propositions of this kind, you should be quite skeptical about the truth of these surface claims.
Salesforce is particularly prone to this anti-pattern because it has a user interface that many users love and the business is used to things being fairly easy to implement on the platform. It is therefore common for a request to be made for parts of other systems to be incorporated into the Salesforce platform.
This can be done successfully if you are careful about the boundaries, are open to making the necessary process changes, and have a strong integration capability in place. However, it is also quite easy to end up in an intensely coupled scenario.
The results
Intense coupling tends to result in an end-to-end user experience that is characterized by fragility, instability, and low performance. This happens for the fairly obvious reason that an intensely coupled system is for all intents and purposes a single-user-facing system encompassing two underlying technical systems. It is a distributed system that has not been built with the awareness that it is a distributed system.
The more you need to rely on the other system, the more frequently you need to call out and access its functionality. This means you have an issue whenever either system has an issue in any of the areas that are part of the solution.
You also get the brittleness that comes from any changes to relevant functionality on either side of the system being likely to result in required changes to your intensely coupled system. This means that you will likely see more errors and issues over time than you’d expect.
In addition, the cumulative wait for the functionality going back and forth between the two sides of the intensely coupled system leads to reduced performance, sometimes to the extent that the system becomes unusable.
On the module level, the consequences tend to be more about reduced maintainability, lower flexibility, and higher cost of change, but performance issues will also occasionally creep in.
Better solutions
While the problems that lead to intense coupling are often legitimate, there are many things you as an architect can do to avoid the situation resulting in an anti-pattern. The following list provides a starting point:
- Keep a keen eye on system and module boundaries, and ensure that if they shift, the cut is made at a maintainable point.
- When designing a cross-boundary process, be very clear on system responsibilities and the integration architecture that will support those processes.
- Adapt processes so that they work seamlessly with the revised system boundaries. Don’t try to compensate with extra technical work if the processes don’t fit.
- Avoid redundant functionality in multiple systems. Be clear on where an engagement with a given set of functionalities is done.
- If what you are building is in fact a distributed system, be mindful of that fact and use low-coupling integration patterns, such as event-based integration, to achieve your goals. Resist calls for large amounts of synchronous integration.
Having now discussed a number of patterns that are applicable to Salesforce, as well as many other technologies, we will now move on to our first unique Salesforce anti-pattern, Ungoverned Org Proliferation.
Org complications
In the Salesforce world, you don’t have to manage your underlying infrastructure, which frees you from a good number of potential temptations that can lead to anti-patterns. However, the way that you structure environments with different orgs in the Salesforce world is subject to a number of anti-patterns in its own right.
Ungoverned Org Proliferation
An example
Miranda has been hired as BigCo’s new CRM Migration Manager. The company has had a business unit approach to IT and does not have any centralized CRM capabilities at this point. Instead, three units use Salesforce mainly for opportunity management, and there are at least 15 other systems in use from a variety of vendors, as well as in-house developed systems in play across departments and geographies.
Miranda has been tasked with consolidating this landscape, using Salesforce as the primary platform. There is a general aim to consolidate systems and standardize processes, but there are few central resources to drive this transformation.
Miranda plans a strategy to consolidate around the three existing Salesforce orgs. She has previously been through org consolidation projects in Salesforce and doesn’t think there is enough value to go through that pain in this case.
She will therefore create three variants of a core Salesforce implementation, dispersed across three geographies, and map the other CRM systems to whichever of these three is the best fit. She will implement reporting processes across these three orgs using the corporate data warehouse that already imports Salesforce data from two of the orgs.
However, as she starts to plan for migrations, she faces massive pushback from business users on her plans. While most teams are quite willing to move to Salesforce, users in France and China, two of BigCo’s largest markets, demand their own unique and segregated environments.
According to the country leads, this is a legal requirement and not up for discussion. Miranda escalates the question to the Legal department but is unable to get answer out of them quickly. She therefore has to accept the separate orgs for France and China.
BigCo’s largest market is the UK, and the country lead there, once he understands that having a separate environment is a possibility, demands that they are also given a unique Salesforce org that can be customized specifically to their requirements. The UK operation is highly efficient, but also unique, and there is no way it would work with the same processes as the rest of the business, the argument goes.
Once again, Miranda finds herself politically outgunned and has to assent to these demands. However, this leads to a new opening of the floodgates. Product development argue that their process is distinct enough to merit a separate environment, and similar requests from other departments and geographical units follow.
At the end of the day, Miranda will be looking at a dozen different Salesforce orgs, with many having quite distinctive processes implemented. This is still preferable to the fifteen totally different systems in play before Salesforce, but far from the original goals. At least, she finally has a way forward.
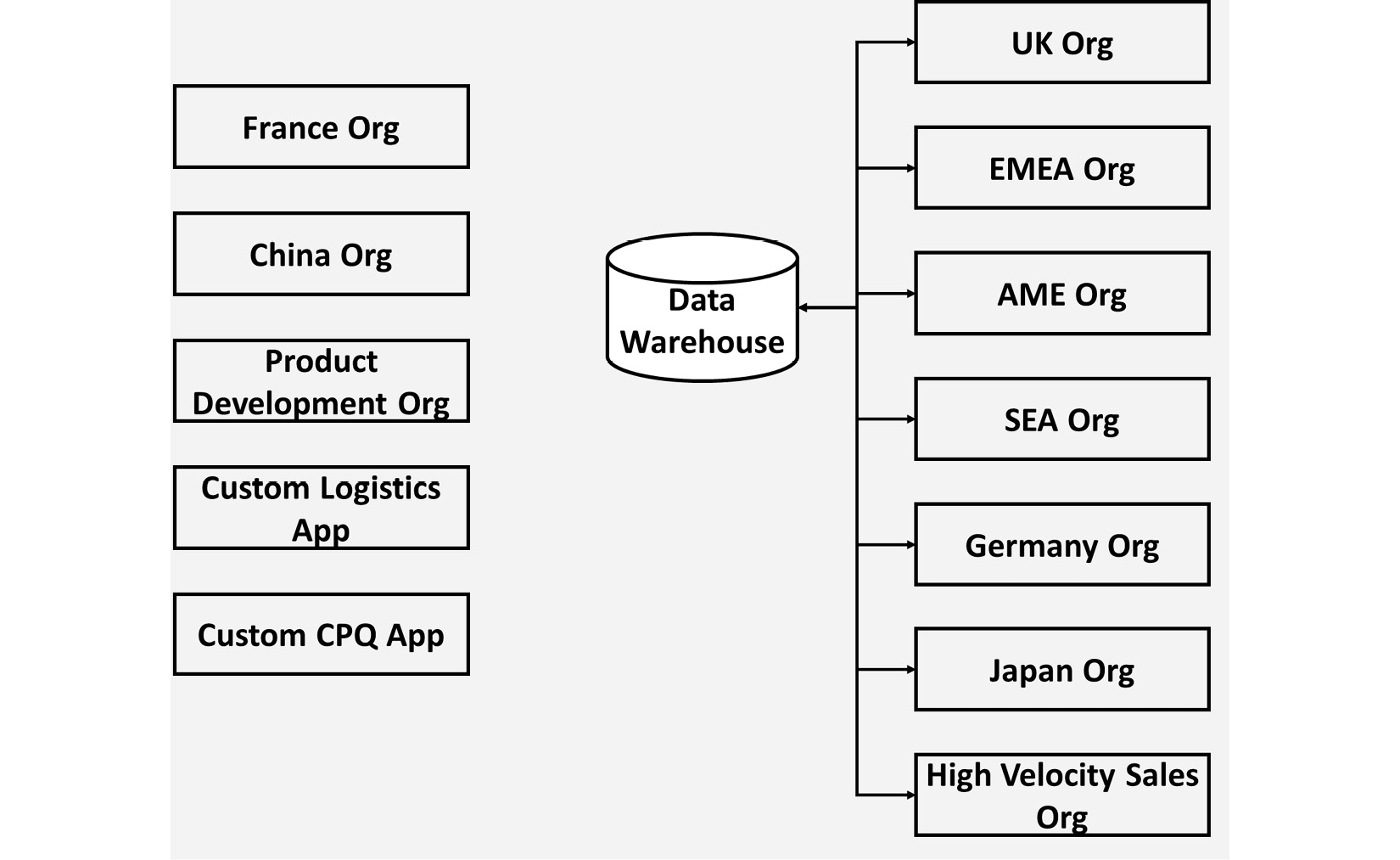
Figure 2.7 – The BigCo org overview
Now, a long-awaited report comes in from a leading management consultancy on how to optimize BigCo’s global sales process. This promises major global efficiency in sales and sales operations by moving to a globally standardized process for all field sales. It is implicitly assumed that this global process will be implemented on Salesforce.
Miranda asks around to see whether anyone is willing to change their position on the implementation plans in light of the new objectives. The answer is a resounding no. She decides that enough is enough and hands in her notice the following day.
The problem
Ungoverned Org Proliferation happens in organizations that like Salesforce, but don’t like standardizing processes, user interfaces, or other similar requirements, and don’t have any strong architectural governance around their Salesforce platform.
The problems that lead to Ungoverned Org Proliferation tend to be found within the following scenarios:
- Different business units or geographies have different processes and can’t agree to a compromise that can be implemented
- Different stakeholders have radically different views of how the user experience should be structured and can’t agree on a reasonable compromise
- Different stakeholders have radically different views on the data model to be implemented and can’t agree on a reasonable compromise
- There are certain critical features which are needed in some business units, but can’t be used in others, different integration backends, for example
- Different parts of the business are working with different Salesforce partners that are pushing them in different directions
- There are perceived or real security differences between different parts of the business that strongly impact the Salesforce implementation
- There are perceived or real legal compliance regime differences between different parts of the business that strongly impact the Salesforce implementation
Note
It’s worth noting that in the old days, Salesforce actively encouraged organizations to try out the software in a number of different places, the so-called “seed and grow” strategy, which worked very well for many years. In large organizations with a long history with Salesforce, you can sometimes still see this legacy living on within rather unstructured org landscapes.
The proposed solution
The proposed solution to the problems leading to Ungoverned Org Proliferation is to give everyone who wants it their own Salesforce org and let them get on with it. This is attractive because it reduces coordination issues, alignment problems, and allows easier resolution of thorny compliance issues. It also lets powerful stakeholders get things in their own way.
There are different variants and degrees of this anti-pattern, some which are relatively benign or even beneficial. In our previous example, some of the asks are probably entirely legitimate and should have been part of a systematically evaluated org strategy. Product development processes, for instance, are often configured in a separate org to the one used for Sales and Service, and sometimes there are real compliance headaches that necessitate multiple orgs.
Let’s be clear. There’s nothing wrong with a multi-org strategy; it can both be the right architectural choice and work well in practice. However, with Ungoverned Org Proliferation, we are talking about a multi-org operation without any strategy or architecture supporting it, and that tends to result in serious negative consequences, as we’ll discuss in the following section.
The results
The result of Ungoverned Org Proliferation is a sprawl of orgs that cannot be controlled from the organization’s center. How serious a problem that is will depend on the nature of the organizational culture and how much central control it requires.
In general, you will find some or all of these disadvantages present in an ungoverned org landscape:
- Difficulties in implementing processes that cut across business units or geographical divisions, as the Salesforce implementations vary by data model and components
- Difficulty aligning data for reporting, as the data model and the meaning of fields will be locally defined
- Complexity developing reports, even when data is brought together, due to the semantic gap between different uses of data
- Integrations often have to be replicated in several different places and can be hard to control
- Licensing can get expensive, as some users need multiple licenses
- Knowledge of the systems is heavily distributed and getting an overview of any particular aspect can be hard to find, as technical teams also mostly work in a local context
- Instituting any kind of global governance can be near impossible due to a combination of the aforementioned factors
- As org consolidation is hard, once you find yourself in this situation, it can be difficult to undo
This list is, to a large extent, simply a more extreme version of the downsides of a multi-org strategy, which makes sense, of course. As we will cover in the following section, the key takeaway to avoid this anti-pattern is to clearly define your org strategy up front, along with mitigations for the inevitable downsides.
Better solutions
It will come as no surprise at this point to anyone familiar with Salesforce architecture that the most important element for avoiding this anti-pattern is to have a clearly defined org strategy. This org strategy should clearly define when, if ever, it is permissible to spin up a new Salesforce org, as well as provide clear patterns to use for integration and data consolidation between orgs.
There are a number of good resources you can use to learn about org strategy. I recommend you start with the SOGAF framework that can be found on the Salesforce Architects site: https://architect.salesforce.com/govern/operating-models/sogaf-operating-models. This is a comprehensive view from the horse’s mouth, although it won’t cover all the details that may be required.
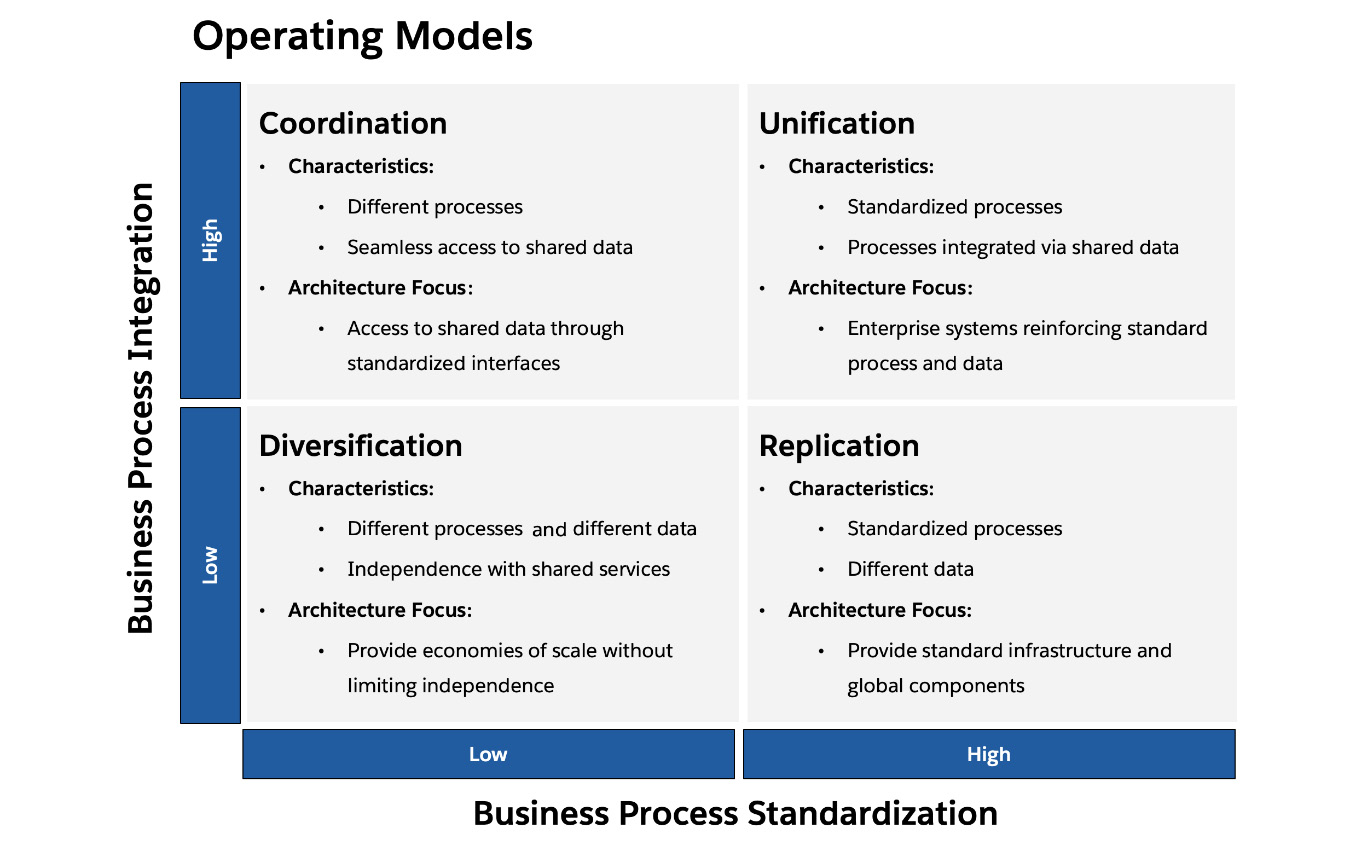
Figure 2.8 – SOGAF models
In addition, in what is becoming a refrain within this book, you should define a common framework for governance, ideally rooted in a Center of Excellence (CoE) that has a global oversight of all things Salesforce, and that is followed by all orgs. This framework should also include common standards and practices, and ideally, also a level of common tooling that must be used in every environment.
The opposite of this pattern
It is worth noting that this anti-pattern has an exact opposite, which I like to call a Procrustean Bed, in honor of the Greek mythological figure Procrustes.
This anti-pattern tries to fit all the requirements into a single org across geographies, business functions, and business units. While many organizations do well with a single global org, there are times when multiple orgs are needed to avoid creating a subpar user experience for key stakeholders, make genuinely diverse and business-critical processes work, or solve real legal issues.
That is to say, org strategy is a balancing act, and you can go too far in either direction, turning it into an anti-pattern. You should refer to the SOGAF models mentioned earlier to find the right way forward in your scenario.
Knowing the takeaways
In this section, we will abstract a bit from the specific patterns and instead, try to pull out the wider learning points that you can use in your day-to-day work as a Salesforce architect or when preparing for the CTA Review Board.
When architecting Salesforce solutions, you should be mindful of the following:
- Many organizations are internally siloed and political, and, in these kinds of organizations, the default mode of operation may be to develop Stovepipes or Big Balls of Mud.
- To avoid this, you as a Salesforce architect need to push strongly for countermeasures.
- This will include pushing for strong architecture governance and coordination on Salesforce projects, including establishing relevant governance forums to coordinate activities, and the right technical standards and practices to ensure everyone is building in a consistent way.
- You need to secure enough business support for these initiatives to make them enforceable when things get hectic; this will require careful cultivation and management of relevant stakeholders.
- Design your systems with common abstractions, for instance, by basing different modules on a common package of shared functionality. This will encourage technical consistency between projects.
- Having strong governance about the common elements shared between different Salesforce projects, such as the Hero objects that are used by nearly any Salesforce solution, is necessary.
- These must be used consistently and have clear ownership, or you will end with a mess in your data model and most likely also in your automations.
- Don’t have fuzzy boundaries between systems. Make it clear what processing needs to happen where and if the boundaries have to change, make sure it is accompanied by process change to avoid intense-coupling scenarios.
- Favor simpler integration patterns where possible. Favor asynchronous integration patterns over synchronous ones where possible. This helps limit coupling.
- Have a clearly defined org strategy that defines when, if ever, it is appropriate to create a new production org.
- Ensure that relevant stakeholders are consulted before any new org is created, for instance, you can make it subject to approval by a Design Authority or an Architecture Governance board.
- Ensure that common abstractions, standards, practices, and tools are also used in any new orgs.
In preparing for the CTA Review Board, you should be mindful of the following:
- Always include appropriate governance structures to ensure that you have a structured approach to implementation. These may include a Center of Excellence, an Architecture Governance Forum, and a Project Management Office (PMO).
- It is also worth mentioning the importance of common patterns, practices, and tools as a way to coordinate implementation activities between teams and ensure maintainability.
- There is often risk associated with stakeholder management if there are multiple different departments or business units involved. As we have seen, bad stakeholder management can be a major contributing factor in selecting an anti-pattern.
- Design a clear system landscape with easy-to-understand roles between the different systems. Avoid having lots of overlap between systems when it comes to core functionality.
- Consider carefully how the different elements in your solution both on and off platform should interact in a way that doesn’t introduce a stovepipe such as isolation for some elements. Your solution should present itself as a coherent whole.
- Avoid unnecessary coupling between systems, and avoid especially strong dependencies between systems, where it isn’t absolutely critical to the functional experience.
- Favor asynchronous integration patterns that reduce coupling if there isn’t a direct need for synchronous communication.
- You should always have an org strategy, you should state it up front, and you should be able to defend it from questioning.
- Be careful not to veer into having either too many orgs that will be extremely difficult to govern effectively or a single org in a scenario that has a strong impetus towards splitting, such as highly variable processes, or definite legal and compliance requirements.
- In any case, be prepared to say how you will mitigate the issues associated with your org strategy, as no scenario is ever clear-cut and there will be trade-offs to consider.
We have now covered the material for this chapter and are ready to proceed. First, however, we will summarize our learning.
Summary
In this chapter, we have seen how you can easily mess up your system architecture in a number of different ways by not carefully attending to architectural matters, good practice, and good governance. You should feel an increased sense of importance about your job as an architect after reading this. Getting things wrong is easy and it is often you who will have to raise the uncomfortable questions that are required to keep the business from veering off a sustainable path, despite the temptations to do so.
We saw that some patterns are common to Salesforce, and many other systems and platforms. These included the following:
- Stovepipes, both at the system and enterprise level
- Big Balls of Mud
- Intensive coupling
However, we also saw that the patterns related to org structure, namely Ungoverned Org Proliferation and its inverse Procrustean Bed, were unique to the Salesforce context. This is something we will come across many times in this book. Salesforce is in many ways a technology platform similar to other technology platforms, but it is also sufficiently unique enough that Salesforce architecture is not so similar to other, more general SaaS or PaaS architectures in some cases. Learning to distinguish when you are dealing with the unique patterns related to Salesforce and when you need to apply general good practice is a skill particular to the Salesforce architect.
We will now move on to one of the most important topics from the anti-pattern perspective, as errors in this domain can lead to major costs for your organization. Of course, we are referring to security, which will be covered in the next chapter.