
7
Keeping the Development Life Cycle from Going off Track
In this chapter, we will look at anti-patterns related to areas such as development process, governance, and DevOps. We will start by tackling a few significant process-level anti-patterns and then move on to one that deals with DevOps and packaging. Finally, we will tackle a common and very unfortunate anti-pattern related to testing. At the end of the chapter, we will summarize the key takeaways for real life and the CTA Review Board.
In this chapter, we’re going to cover the following main topics:
- How you can avoid big-picture mistakes in the delivery of your project such as how you structure releases and deal with key trade-offs
- How to avoid structuring your packages in a way that may be organizationally convenient but architecturally problematic
- How you can avoid falling into the trap of compromising on code and deployment quality when under pressure to deliver
After completing this chapter, you will have understood the ways in which common mistakes affect the development life cycle and related activities and mastered some tools to help you keep that from happening.
Misaligning the process
In this section, we will look at two anti-patterns that in different ways make the development life cycle go off the rails. First, we will look at how big bang releases can lead to disastrous outcomes in many cases. Second, we will look at project pieism—the disastrous belief that you can avoid making important trade-offs.
Big bang release
Example
RollerCo, a major manufacturer of roller skates and skateboards, is going through a major business transformation centered on creating a digitally enabled business that better meets the needs of today’s buyers. While not the end-all and be-all of the transformation, several system replacement projects are planned as part of the journey to provide more agility on the IT side.
Anandh is leading the project that aims to replace the legacy, home-grown CRM that RollerCo has been using for the past 15 years. The system will be replaced with a combination of Salesforce Sales and Service Cloud, but due to the high level of customization in the legacy system, it has proven impossible to keep the Salesforce design close to standard.
Another consequence of the high-level customization required is that the entire system will need to go live as a single unit. It won’t be possible to release smaller minimum viable product (MVP) increments prior to full go-live as that would make life too complex for the customer support staff.
Shortly after the project kick-off, Anandh is informed that the board of directors has OKed an Enterprise Resource Planning (ERP) upgrade to SAP S4/HANA. As the CRM and ERP are closely coupled for several processes, that means that not only will Anandh have to contend with an increased integration backlog, but the rollout plans for the two systems will also need to be coordinated so that both can go live at the same time.
It quickly turns out that the added complexity from the ERP upgrade means the original Salesforce implementation plans will have to slip. In particular, the integrations are proving to be more complex than anyone anticipated.
The CIO, after meeting a trusted vendor representative, announces that to address the issues regarding the CRM/ERP integration, RollerCo will invest in a new strategic middleware platform. This will replace the legacy middleware and go-live with the overall CRM/ERP timeline.
While Anandh and his team are busy redesigning all the integrations to fit with the new middleware platform, yet another discovery is made. The team responsible for RollerCo’s web shop determines that it will be next to impossible to get it to work with the new CRM/ERP setup.
It would require changing the fundamental architecture of the application’s data layer, and the developer who built that years ago is no longer with the company. No one else is able to figure out how to do it, so a new e-commerce application is also added to the overall program backlog. For convenience, the timeline is aligned with the overall CRM/ERP rollout:
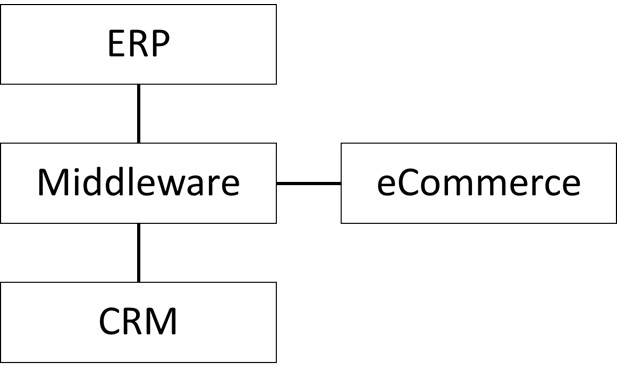
Figure 7.1 – RollerCo new platform
The program suffers never-ending delays. While some areas suffer more than others, none of the major platforms comes out of the implementation phase looking good. Three years go by, and finally, an initial release is nearing completion.
RollerCo has built an elaborate deployment pipeline and cutover plan to be able to handle the multi-system go-live, all slated to happen during a weekend in the company’s low season. The testing prior to go-live takes more than 3 months to complete and requires a number of scope reductions and hotfixes.
Even after that, no one in the project dares say unequivocally that the system will work as expected. The number of moving parts is simply too large.
The go-live weekend starts promisingly, with successful completion of required data migration activities. However, as soon as real business users are brought into the systems, issues start cropping up.
By Sunday night, the number of issues has reached a volume that makes going forward seem excessively risky. While no individual issue has so far been a showstopper, the total disruption caused by small issues is significant. On a late-night call, the steering committee takes the decision to roll back and postpone go-live.
The fallout is significant. After all, the program has already had 3 years to complete its work. However, it quickly becomes clear that the issues cannot be fixed in a matter of weeks. There is still much to be done.
The teams come together to find a solution over the next 6 months. Through this period, they focus on reducing the scope and simplifying features to make the rollout process easier to manage.
Eventually, the combined platform with CRM, ERP, middleware, and e-commerce goes live. However, it does so with a large list of known issues and workarounds and a much-reduced scope from the one originally designed.
Problem
Big bang release is an anti-pattern that usually tries to solve the problem of how to handle complex dependencies in the release process. That can be dependencies between systems or inside them. It most frequently occurs where the digital transformation lacks strong leadership, and the leadership that there is highly risk-averse.
Dependencies are usually linked to certain business processes that have a legacy of being carried out in a certain way, which means that a large amount of functionality has to be deployed as a unit. Sometimes, as in our example, this can lead to massive dependencies even at the system level.
Disaggregating existing business processes and coming up with transition architectures (that accommodate the need to get work done while a partial solution is in place) can be quite difficult, as can MVP subsets of functionality that will deliver value on their own. Big bang release avoids those issues by simply pushing everything to one big event in the future.
Proposed solution
The big bang release anti-pattern proposes to just do one big release for all linked functionality at the end of a long delivery process. That can mean several years of work go-live at the same time without any intermediate feedback.
This solution can be highly attractive to both the delivery team and the customer for a variety of reasons:
- It reduces the entire system to a single deployment quantum that can be managed as a unit
- It simplifies the planning process as you don’t have to plan for multiple releases, partial data migrations, and co-existence scenarios
- That means the overall architecture is also simplified as there is no need to come up with transition architectures for the scope of the project
- You also avoid tough decisions about what to include when and which business needs you can accommodate, and at what times
- It’s easy to understand both for the delivery team and the customer
- You successfully push the problem down the line, making it something to deal with later. In some cases, there may even be other people doing it by then
You can, therefore, understand why—even at a time when small releases and DevOps thinking has become the leading paradigm—many projects still end up being deployed with a big bang. Unfortunately, it doesn’t tend to go well.
Results
The fundamental problem with big bang releases is that you—often inadvertently—take on a massive amount of risk. Technical risk doesn’t grow linearly with the number of components to deploy. Rather, it grows much faster due to the superlinear growth of interconnections and dependencies that come with a larger number of components.
Put simply, if you deploy one component, you only have the risk of that component failing to deal with. If you have just two interconnected components, you now have up to four failure modes to contend with:
- Component one failing independently
- Component two failing independently
- Component one failing and triggering a subsidiary failure in component two
- Component two failing and triggering a subsidiary failure in component one
All four may present unique symptoms and the root cause may not be obvious. Consider how many potential failure modes you’d have if you deployed 20 components together with a large number of interconnections between them.
Because the number of failure modes on a large deployment is so large, that necessarily means that testing becomes an enormous task, and often, you can test for weeks and still not be sure whether you have really tested all the important cases. Debugging errors is also much harder because tracing the potential knock-on effects between components is much harder than simply finding an error in a single component.
The same difficulties also apply to rolling out and rolling back any other cutover tasks that need to be done. Even training and change management becomes harder in a big-bang scenario.
Overall, the bigger the release, the more risk you have of it becoming a serious failure. Unless you are a gambler, you shouldn’t go down that route.
Better solutions
If big releases are the problem, it stands to reason that small releases are the solution. From a risk management perspective, the ideal amount of functionality to release at a time is a single feature or a single user story. That is the premise of continuous delivery (CD), as practiced by leading DevOps-focused organizations.
However, we must acknowledge that not all organizations have the scale or technological sophistication to adopt the pure DevOps setup that would allow CD of a single feature at a time. However, if you aspire to the ideal of small releases, you will at least start to mitigate the problems.
Smaller releases have the following attributes:
- Less risky
- Easier to test
- Easier to debug
- Easier to fix errors in once found
- Easier to roll out and roll back
- Deliver value quicker to business users
- Facilitate and increase system adoption
- Make change management easier to control
Overall, once you do the necessary technical and business process work to enable smaller releases, there are few—if any—downsides.
Project pieism
Example
ConglomoCo is a large, diversified conglomerate that counts many business units (BUs)—some related to business lines, others to geography. Most BUs operate quite independently both operationally and with respect to IT infrastructure. In addition, BU heads have a lot of power relative to headquarters staff as they effectively are the masters of their own businesses.
When ConglomoCo’s CIO decides to push for a global rollout of Salesforce, he is therefore met by staunch resistance on the part of several division heads that have their own CRM strategies and don’t want HQ to get involved. However, as part of a new initiative, the CEO and CFO have requested a consolidated view of the global pipeline, which the CIO is leveraging for his Salesforce strategy.
Kim, a senior IT project manager with ConglomoCo’s HQ staff, is therefore given the responsibility to drive the global rollout of Salesforce Sales Cloud and CPQ. The CIO wants to use this as an opportunity to standardize the core sales process across BUs and simplify the reporting of sales data.
After corresponding with his architects, Kim, therefore, proposes a plan based on a single org with a standard process. There will be local variations within the BUs, but these are to be kept limited in scope.
As Kim starts presenting this plan to stakeholders, he finds that it is clearly not what they were expecting. The BUs have separate processes, UX expectations, local integrations, and reporting needs that they are expecting a new system to cater to.
At a senior leader’s workshop, many of these issues come to light, and a compromise is reached at the highest level. The new system must be able to cater to separate sales processes, automations, and local integrations and accommodate some level of customization of the UX for each BU:
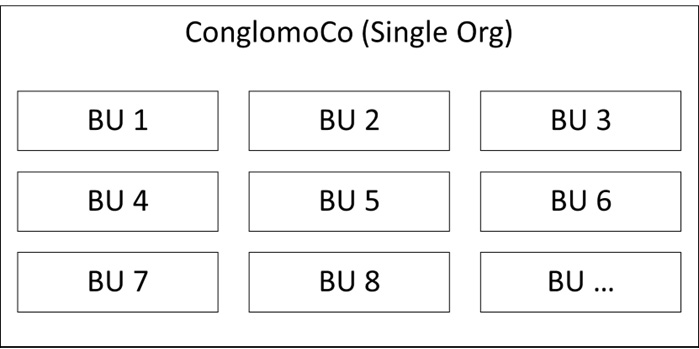
Figure 7.2 – ConglomoCo org
However, all of this must still reside within the same Salesforce org and leverage the same data model to make reporting across BUs simpler. It is understood that this will lead to a more customized implementation and have a cost implication, but the CIO would still like the implementation to be as close to standard as possible.
The implementation is long and slow. By necessity, it includes many separate streams related to the different BUs. Every stream seems to have its own complexities, and coordinating between streams is an ongoing and uphill battle. It is fair to say that as the implementation goes on, a level of attrition sets in, and everybody lowers their expectations for the future system, seeing it more as a necessary evil than a driver of positive change.
Kim negotiates with the business and manages to get two of the smaller areas to go live in a pilot fashion. They go live without much fanfare and with a lot of bugs. Worse than the bugs, however, is the low adoption. The salespeople in the BUs seem to do everything possible to avoid putting data in the system, and when they do, it is of low quality.
Given the unpromising early results, the rest of the rollout is put on hold. Instead, a management consultancy is brought in to investigate why adoption is so poor and what could be done better going forward.
Problem
Project pieism is an anti-pattern that has its root cause in an aspiration to avoid having to make difficult trade-offs when implementing a system. That may be because of political difficulties or weak project leadership, but it always involves a failure to acknowledge a key trade-off that needs a decision.
In a sense, most engineering problems in software architecture and in general are about balancing a set of trade-offs. However, those trade-offs are often uncomfortable and will involve not pleasing all stakeholders.
Therefore, it’s perfectly understandable that many projects proceed without making the necessary trade-offs in hope that a solution may be found later or simply by closing their eyes to the facts. In any case, it is an anti-pattern.
Proposed solution
Project pieism suggests as a solution to one or more important trade-offs in your solution that the trade-off is not real, that you don’t really have to compromise, and that you can in fact have your pie and eat it too. Sometimes this is done by ignoring the trade-off or sweeping it under the rug; sometimes it is acknowledged but special pleading is deployed to suggest that this case is somehow special and therefore the trade-off does not apply.
This position is attractive for obvious reasons. When there are key trade-offs to be made in an implementation project, you will probably have to disappoint one or more groups of stakeholders. If those groups are powerful within your organization, that may not be an easy or pleasant thing to do. You can even find yourself in situations where you are forced into project pieism because of corporate politics.
However, not even the most powerful executive in your organization can change the basic facts of software architecture. There are always trade-offs. Whenever you have a situation on a technical project where there doesn’t seem to be a trade-off in the decision you are making, you should be worried.
Results
The result of project pieism is the resurgence of the trade-off you’ve tried to ignore. Murphy’s law being what it is, that will probably happen at the most inconvenient point in your project life cycle and cause major damage to your project.
Of course, the specific damage will depend on the trade-off you have been ignoring. In our preceding example, we ignored trade-offs between the priority of global and local processes and between the level of standard functionality versus customization.
ConglomoCo attempted to have a standard system with a global process that also accommodate all relevant local variations. That led to a system that no one wanted to use because it met no one’s needs well enough.
Other trade-offs will have different consequences, but you can count on adverse consequences if you fail to make important decisions about the key trade-offs that drive your architecture.
Better solutions
The way to a less pieist future lies in openly acknowledging the trade-offs to be made and engaging constructively with stakeholders about the options. Often, there are ways of giving stakeholders more of what they all want, but it may come at an additional cost or a longer timeline.
One way to formalize this engagement is to set up good architectural governance early in a project and discuss the key architectural trade-offs in both architecture forums and business forums to ensure that all perspectives are taken into account. In our example, a competent architecture board might well have pointed out that there was no way of making a single org strategy work well in the ConglomoCo scenario.
As architects, we need to be honest with the business about what is and isn’t possible. We are the people who know the art of the possible on the technical side, and we shouldn’t pretend that our favorite technologies somehow transcend the need for making hard choices. Stand firm, be constructive, give options, and don’t ignore important trade-offs.
Unpacking the pipeline
This section will introduce a key DevOps anti-pattern related to how you should structure your packages for package-based development.
Using packages to create silos
Example
MillCo, a producer of CNC milling machines with subsidiaries across Europe and North America, is implementing Salesforce for its B2B sales. This includes Sales Cloud, CPQ, and B2B Commerce.
Abigail is the CRM tech lead from MillCo, a role she has recently taken up after leading a CRM implementation project in another B2B manufacturing company. Her principal job is to ensure that the technical delivery from the three different vendors that are implementing the different elements of the new system is consistent and of high quality.
At project kick-off, Abigail invites all three vendor teams along with internal stakeholders and emphasizes many times that while people are working for different companies, everyone should think of themselves as being on the same team. MillCo wants everyone on the same page and working together toward a common goal.
That turns out to have been all for naught. Once work commences for real, the three suppliers are quickly at each other’s throats. Abigail finds it impossible to get them to agree to any common approach and standard.
While she can mandate certain things, she has no team behind her, and there is only so much she can do if the vendors don’t cooperate. She escalates the issue but is told to find a solution that allows work to continue as planned.
The solution she decides to go with is to isolate each vendor in a separate package. That way, they can build in isolation, excepting cases where their work directly clashes with one another on key elements of the platform. Abigail takes it upon herself to monitor and mediate these disputes:

Figure 7.3 – Package structure
She ends up spending most of her time on the project mediating these kinds of inter-vendor conflicts. That also means she has very little time to investigate the general approaches used by the vendors in areas that aren’t subject to acrimony.
However, in the end, the system is built. As each vendor has been working in their own environment with only occasional deploys to a thinly tested integration environment, the first step to prepare for user acceptance testing (UAT) is to deploy all the packages to a common environment and test the basic processes. Each package has been thoroughly tested in its own environment, but no systematic testing has been done across packages.
Even before the test results start coming in, the situation starts to deteriorate. It turns out that there are incompatible system and package settings between the vendors—for instance, on the CPQ-managed package. This means the deployment stalls until a workaround can be found.
When the testers actually get started, things go from bad to worse. There are many subtle incompatibilities between the packages. For instance, there are different interpretations and uses of common fields, duplicate fields used by different packages for the same purpose, and custom objects that have a partially overlapping scope and the creation of redundant data. There is also a wide range of different automation patterns in use between the three vendors, despite this being an area where Abigail specified the standard upfront.
All in all, the differences are too large to reconcile quickly, and the project has to back off. Abigail’s boss negotiates an extension to the timeline in order to refactor the packages and bring them in line. While she is happy about the extension, Abigail does not relish the wrangling it will take to get the vendors to actually do this.
Problem
Sometimes, you want to allow teams to work independently without having to depend on or coordinate with other teams. In a Salesforce context, that may be because the teams are working on different clouds, come from different vendors, or represent different departments or BUs within your organization.
This is very understandable as coordination problems can be hard to resolve. However, when that becomes the basis for dividing up your Salesforce platform into packages, it becomes a DevOps anti-pattern.
Proposed solution
The proposed solution of using packages to create silos is to give each team its own package to work in, reflecting what it is going to be working on. That avoids coordination issues but creates a host of other problems.
That means you structure the package setup for your project based on organizational needs rather than architecture. That can seem like a good idea at the outset and obviously works for the teams in the short term, but unfortunately means that hidden conflicts are likely and can remain hidden for a long time.
Results
The likely result of Using packages to create silos is that you will have hidden conflicts that only become apparent on the integration of the packages.
These conflicts include cases such as the following:
- Different use of data models—for instance, fields and objects
- Issues in security model where conflicting configurations are used
- Conflicting flows, validation rules, or other business logic
- Deviation from best practice, for instance multiple triggers on same object
- Different automation patterns used on the same object
- Conflicting assumptions about system settings
- Replicated functionality in different packages that is often only partially overlapping
This can lead to serious issues and can be a real mess to refactor, which is both costly and time-consuming.
Better solutions
In general, package design should be taken quite seriously. Package-based development is the direction of travel for most large-scale Salesforce projects, not least because it scales better than the alternatives.
To avoid falling into the using packages to create silos anti-pattern, follow these guidelines:
- Design your package structure with your architecture in mind. For instance, in a typical architecture that’s split by service lines, you could place common functionality in a “Common” package that all other packages depend on and then have separate packages for each service line containing relevant components. You might also have higher-level packages cutting across service lines for things such as common integrations and you could have separate packages split out for cross-cutting functionality, although that can be a bit tricky to manage. The point is that you should ensure that you manage dependencies cleanly and don’t have potentially conflicting overlaps.
- Be careful with dependencies; a layered approach can work well to only have dependencies go in one direction.
- Have teams work across packages when needed.
- Consider having certain teams own certain packages and others request work from them if they need anything.
- Coordinate via technical governance forums—for example, an architecture board.
In general, you don’t want to mistake package design for something else. Build your package structure so that it makes sense for your architecture and is workable for your developers.
Testing without testing
Testing is a critical activity within any large software project. In this section, we will see how trying to avoid writing the necessary unit tests can cause major issues in the mid-to-long term.
Dummy unit tests
Example
TruckCo is a start-up automotive company that focuses on building next-generation EV trucks. It sees itself as more of a technology company than a manufacturing company and therefore invests heavily in top-range solutions to keep its technological edge.
Generally, TruckCo tends toward heavy customization and intense agile projects with long hours and short timelines. The supply chain application TruckCo is currently building on Salesforce is no exception to this rule.
The application will integrate their B2B commerce portal with order management and their supply chain backend systems. It will enable just-in-time (JIT) ordering from spare parts vendors and in general significantly reduce the quote-to-cash (QTC) process for spare part orders.
In order to achieve these aims, TruckCo plans to integrate half a dozen key backend systems with Salesforce, build a custom user interface (UI) optimized for their special processes, and build a set of cross-platform, AI-enabled automations that drive efficiencies in the ordering process.
Because the application is expected to be code-heavy and development-focused, TruckCo repurposes a team of Java developers from its permanent staff to work on it, figuring that Apex is close enough for them to pick it up as they go along. Yana is the only traditional Salesforce person on the project, and her role is to guide the rest of the team in the ways of Salesforce.
Matt, the team lead, is a bit of a maverick, and the same is true of the rest of the team. While they use unit tests, they do not do so consistently, often preferring to have bugs reported by users and then fix them afterward. Inside TruckCo, there is an unstated but strong preference for releasing products on time, even if that means releasing something buggy and incomplete.
Coming from the Java world, the developers quickly start to get annoyed with the mandated 75% unit test coverage enforced by Salesforce and built into the deployment tooling for the platform. Yana accidentally mentions some ways to fool the Salesforce unit test calculation by creating dummy tests while having lunch with the rest of the team.
Although she mentioned it jokingly, much to her chagrin, she finds that a few days after, dummy unit tests are starting to appear in the code base. When she calls out Matt on this, he simply shrugs and says that they’re behind schedule, so they don’t have time to spend all their time coding tests.
Yana, however, is not deterred, and at the next project board, she raises the issue formally. She refers to the guidance provided by Salesforce and supported by the company’s own Salesforce architect.
The project sponsor promises to have someone investigate the issue. Unfortunately, that’s the last Yana hears of it. It seems that Matt had indicated that major delays would happen to the project if they had to retroactively write a complete set of unit tests. In keeping with TruckCo’s normal way of operating, this is seen as unacceptable, and the dummy unit test issue is ignored.
Therefore, the practice keeps accelerating as the project falls more behind, and toward go-live, almost every new unit test written is a dummy. While the automated scanner lists an impressive 90% coverage, Yana doubts if the real number is any higher than 10%.
A few weeks before go-live, a list of last-minute changes comes in from business stakeholders. Yana can’t see any way that they can be incorporated, but Matt agrees to deliver them.
The last period is a flurry of changes back and forth with lots of bugs discovered by testers, followed by fixes that often lead to further regression issues. This continues unabated into the actual UAT period, which finds another large number of issues. However, no one takes the decision to halt the go-live, and on the appointed day, the supply chain application goes live.
As users start onboarding on the application, several breaking bugs are discovered in the main flows. These occurred in areas that had been tested and found working just weeks before go-live and had also been part of user training.
The application must be taken down, and an escalation meeting is called. Here, the fundamental soundness and quality of the application are put into serious question and a new initiative is agreed upon to look into the quality issues and devise a way of fixing them before the application can be brought back online.
Problem
Dummy unit tests seek to address a very simple question: how do you get around the hard 75% unit test limit for production deployment in Salesforce? It’s common for long-running Salesforce projects to find that they are under the limit either for a specific deployment or in general.
Many teams find this limit annoying. This is especially true, when developers are coming to the platform from other technologies where no such limit existed or when under pressure, or when they are doing something “simple”.
Proposed solution
The solution proposed is to create dummy unit tests that just optimize for code coverage and don’t really test anything. This is another of the few anti-patterns that edge close to just being bad practice. You can see an example of a dummy test in the following code snippet:
@isTest
class dummyTest{
static testMethod void notRealTest(){
//assume A is a class with two methods
A aInstance = new A();
aInstance.methodA();
aInstance.methodB();
//nothing is done to test anything
}
}However, it is something that can be tempting and that otherwise serious Salesforce practitioners sometimes may engage in. When you are under pressure to meet a sprint goal or deployment deadline, it can seem like a waste of time to write a bunch of unit tests just to get the coverage up.
But obviously, this attitude fails to acknowledge the real value provided by unit tests and the reason why the coverage is mandatory: code without good unit tests is much more brittle and prone to regression errors than code that has them. Therefore, skipping them, even when you are under pressure, is a genuinely bad idea.
Results
This pattern tends to lead to death of a thousand cuts. While you probably don’t experience ill effects in the short term, after a while you don’t have any real unit tests to rely on.
Even worse, you may still psychologically project a false sense of security, if you still think you’ve only cut the corners in a few places and generally can rely on your testing. Basically, you are cheating the system and probably releasing poor-quality code. Also, you are creating a major amount of technical debt that the organization will at some point have to pay off.
Better solutions
The solution to this anti-pattern is simple: build good unit tests and meet the minimum thresholds, always. You should never compromise on the minimum bar as it will lead to deteriorating code quality and hence delivery quality over time.
There is a lot of guidance available on building good unit tests, so let us just rehearse a few basic points:
- A unit test should test a single functionality in the code
- The test should be written before the code it is testing
- The test should be written in such a way that it can be easily repeated
- The test should be independent of other tests
- The test should not rely on org data but should create its own test data, ideally using a test data factory
- The test should be concise
- Assertions should be used to check that the expected results are obtained
- The test should test both positive and negative cases
- The test should be run often, preferably automatically
- The test should be easy to understand and maintain
It is a rare anti-pattern that can be avoided just by following good practice, so be sure to avoid this one.
Knowing the takeaways
In this section, we will abstract a bit from the specific patterns and instead try to pull out the wider learning points you can use in your day-to-day work as a Salesforce architect or in preparing for the CTA Review Board.
When architecting Salesforce solutions, you should be mindful of the following:
- Don’t put all your eggs in one basket. Plan smaller releases wherever possible to de-risk and get feedback.
- Confront the tough decisions that can come from having to break down functionality into smaller buckets. Don’t just accept a statement that everything must be there from day one.
- Always confront the key architectural trade-offs early on in your project timeline. They usually don’t get easier to manage as time goes by.
- Communicate clearly and openly about the trade-offs that need to be made and the options for doing so. Trying to please everybody and sweep things under the rug is a recipe for disaster.
- Don’t allow team rivalries or organizational silos to dictate your development model, whether for package-based development or otherwise.
- Instead, ensure that your development model is consistent with the architecture you are pursuing and that components and packages are structured accordingly.
- Unit testing is a requirement in Salesforce for a reason. Don’t compromise just because you are under pressure.
- Writing good-quality unit tests will ensure that you have higher code quality and fewer regression issues.
In preparing for the CTA Review Board, you should be mindful of the following:
- Prefer an agile, multi-release process when faced with a big complex scenario, rather than a single big-bang release.
- Some scenarios, however, do seem written more toward a waterfall/big-bang approach. This may be an area where best practices for the board and for reality can diverge.
- You should be very clear about the trade-offs you are making and include them in your justification.
- If you fail to make an appropriate choice, it will with near certainty make your solution unravel during Q&A.
- Package-based development is the up-and-coming development model for Salesforce projects, but that doesn’t mean it will be right for your scenario.
- If it is, having some words to say about a good package structure will potentially give you some extra kudos.
- Know the minimum limits for unit testing and when they are applied so that you can answer if asked.
- Also, be prepared to answer general questions about what makes good unit tests and how to use them to improve code quality.
We have now covered the material for this chapter and are ready to proceed. First, however, we will summarize our learning.
Summary
In this chapter, we have seen examples of how the development life cycle can be impacted by anti-patterns at different levels of abstraction. At the highest level, how you deal with key trade-offs and how you structure your releases have a huge impact on the potential success of your project.
However, we also saw that technical elements such as how your structure your packages and whether you write good unit tests can be major contributors to project success or failure. That means you must master all of these levels to be a successful architect in this domain.
For many architects, this domain can be a bit of a lower priority relative to solution architecture or the hardcore technical domains. However, paying insufficient attention to these issues can lead to serious project failures just as easily as a badly designed solution.
With that being said, we will now continue to our last domain—namely, communication—and see how we can mess up our Salesforce projects by communicating in the wrong way.