
Registries for Web Services
As you saw on Day 3, “Naming and Directory Services,” naming and directory services are an important part of any distributed environment. J2EE uses JNDI as a way of accessing information about application resources and the location of remote services, such as EJBs and databases.
Because Web Services also operate in a distributed environment, Web Service-oriented naming and directory services are required. In fact, the scope of such services is broader under the Web Services model than under J2EE, because the service will hold organizational and business information as well as Web Service metadata and location information. In Web Service terms, the place to find this information is called a registry or repository.
What Is a Web Service Registry?
As discussed yesterday, a Web Service client can retrieve information about the Web Service it wants to use from a registry. The registry contains information about the service being offered (from currency conversion to the supply of 10-ton trucks). This information includes details about the organization offering the service, the technical access information for the service (interface and transport), and where to find the service.
Tools can be built to browse and search this Web Service registry information. The information retrieved can then be plugged into client applications so that they can integrate with the supplier of the service. This integration can range from fully manual, where a human selects the interface and writes client code to invoke it, to fully automatic, where the selection and invocation are performed by the client application itself.
Why Do I Need One?
To cooperate, applications need information about what services exist and where to find them. You can do this manually by exchanging service definition files, such as WSDL documents. This procedure is reasonably okay when interacting with known business partners. However, manual exchange does have some drawbacks because it does not allow you to find new suppliers of services, and your information must be updated whenever a service location changes.
One alternative is to exchange service information in a partially dynamic way with your business partners by obtaining service definition information from the server on which the service itself is located. Such a mechanism is described in the Web Service Inspection Language (WSIL or WS-Inspection) specification. Again, this method of interaction is reasonably okay if you already know where the server is.
To engage in fully dynamic Web Service use, what you really need to do is search for companies or services that match a specific profile (type of business, type of service, location of business, and so on). From this list, you can choose an appropriate service, and then retrieve its technical information with the minimum of fuss. At runtime, it is possible to check the service information again in case the service location has changed.
How Do They Work?
There are two basic ways of finding information in a registry. One way is to drill-down, starting at a known location. Under this model, you can iterate through the registry entries below the current location and potentially recurse down through their children or follow links from them to find the information you require. The alternative mechanism is to globally search the registry for the information you require. In this case, you would search based on a particular piece of information about the service you require, such as the organization's name, its line of business, or the interface definition of the service for which you are looking. The use of these three types of search criteria (frequently called white, yellow, and green pages, respectively) provide you with a lot of flexibility for locating the Web Service you need.
What will usually happen is that you will use some form of search to locate an initial registry entry, such as the top-level registry entry describing an organization's business, and then drill down from there to examine the services available.
One issue here is that for searches to be effective, people must agree on ways of describing and categorizing information. This gives rise to classification systems or taxonomies. There are various common taxonomies set up by industry standards bodies to classify information in their particular areas. Such taxonomies can be used as part of the classification of a Web Service in a registry to help clients find the right form of service. Some examples of useful taxonomies include the North American Industry Classification System (NAICS) and the United Nations Standard Products and Code System (UNSPSC).
Types of Registry
Web Service registries come in a variety of forms:
Global registries are publicly available and open to all types of business— This is similar in concept to the global Domain Name System (DNS) that lets you find anyone's Internet Protocol (IP) assigned to the hostname that forms part of their Uniform Resource Locator (URL).
Private registries can be set up behind organizational firewalls— These will facilitate the location of Web Services on a company's intranet.
Site-specific registries will list all of the services offered at the site associated with the registry— For example, acme.com could host a registry service that helped you to locate all Web Services provided by acme.com.
Marketplace registries are set up and maintained by a market maker (a third party or industry consortium)— Such registries may or may not be publicly available, but will provide some form of selection or quality check on the providers of services before including them in the registry.
There is a good whitepaper about Web Service registry styles on the Web Services part of IBM's DeveloperWorks site at http://www-106.ibm.com/developerworks/webservices/library/ws-rpu1.html.
Just before leaving the general topic of Web Service registries, it is worth considering how your application—and your business—will actually use Web Services. If you are looking to use Web Services provided by suppliers as part of a supply chain, you may want to use some of the dynamic capabilities of a Web Service registry to locate suppliers and services. However, not all of the information you require will be found dynamically. In real life business terms, you will not necessarily change your supplier of ball bearings from minute to minute. There are other criteria by which you choose your business partners (quality, timeliness, trust, and so on). Therefore, for most applications, the selection of suppliers will usually take place at human speeds and involve humans in the selection. After the selection is made, dynamic lookups can be performed to discover and use the technical service interface and location information.
Marketplaces can also help here. A marketplace can provide a qualitative judgement of potential suppliers, making the selection of previously unknown suppliers less risky. This type of qualitative judgement already takes place in various areas of business, such as organizations that provide credit ratings for businesses. Employing such a service helps you to manage your risk when selecting potential business partners. Given such a rating ability, if a marketplace can offer five trustworthy and high-quality suppliers, you can potentially spread the load across these equal suppliers. Even so, this type of dynamic interaction is more likely in information-based areas, such as financial data and transactions, than in the realms of 10-ton truck purchase.
ebXML Registry and Repository
One of the principal types of Web Service registry is the ebXML Registry and Repository (R&R). The ebXML R&R plays a central role in the ebXML model of e-commerce, as shown in Figure 21.11.
Figure 21.11. Discovery and negotiation based around an ebXML registry and repository.
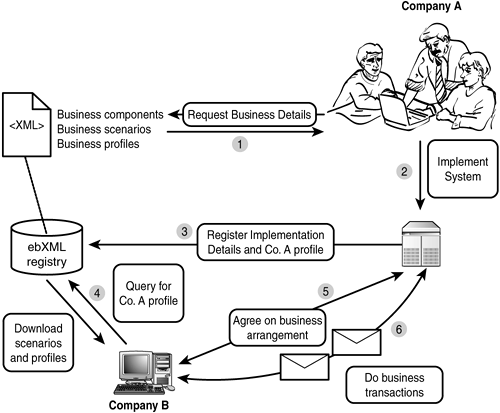
The ebXML R&R acts as a storage area for the central business document definitions, or Core Components, that are used in ebXML business messages. An organization (Company A) that wants to advertise its services in an ebXML R&R will base its service descriptions on these Core Components and will then implement the service (shown as steps 1 and 2). Company A and its services will then be registered in the ebXML R&R (step 3), including a Collaboration Partner Profile (CPP) that describes the different bindings for each service and the roles and workflows associated with it.
When Company B searches the registry for a service, it can select Company A's offering and download the service information (step 4). Company B can then use the information in Company A's CPP to determine how it should interact with Company A's services. It can then contact Company A with a suggested Collaboration Partner Agreement (CPA) that details the bindings and service interactions required (step 5). This CPA forms the basis of the contact between the two companies. When a CPA has been agreed on by the two companies, business transactions can begin between the two new partners according to the terms set out in the CPA (step 6). Messages sent between the partners will reference a CPA identifier (CPAid) to indicate of which interaction they are a part.
UDDI Overview
UDDI defines an information model for a registry of Web Service information and a set of SOAP messages for accessing that information. The information contained can be split into two parts:
Business information— This provides the name and contact information for the business. It also provides a list of the categories (based on the taxonomies mentioned earlier) under which the business should be “registered” to help a user find the business.
Service information— This gives information about which Web Services are offered by the business, their interfaces, and location(s).
At the lowest level, you have the description of a specific Web Service. As you have seen from WSDL, this will contain a description of the service interface and endpoint information telling the user where to find the service. UDDI splits this information between two structures:
A structure called a tModel is used to describe the Web Service's interface, such as the operations, parameters, and data types it uses. Separating such interface information from the service location information means that tModels can be stored independently and shared by multiple different services from different businesses. This greatly aids the discovery of compatible service offerings. Although commonly conceptualised as a Web Service description, the information in a tModel can describe any mechanism for accessing a service, including email, phone, or fax.
If you are building a tModel from a WSDL interface, you would include the WSDL messages, parameters, return values, complex types, PortTypes, and Bindings.
The UDDI bindingTemplate structure uses tModels to define which particular service is being offered and also provides the location of the service. The location information defines specific endpoints at which the service can be found.
Again, in WSDL terms, the extra information in the bindingTemplate correlates to the WSDL port and service information.
At a higher level, a businessService is used for the logical grouping of services, as defined in bindingTemplates. At the top level is a UDDI businessEntity that contains the business information. Each businessEntity contains one or more businessServices.
The UDDI API provides a set of SOAP operations to search for information within this model and to retrieve the relevant parts.