
The Move into the Second Tier
The move toward 2-tier systems was born from the desire to share data between multiple applications which are installed on different machines. To do this, a separate database server machine is required. Figure 1.2 shows how this is achieved. The application now consists of presentation and business logic. Data is accessible through a remote connection to a database on another machine. Any changes to the Data Access logic should not affect the Presentation or Business logic in the application.
Figure 1.2. 2-tier scenario.
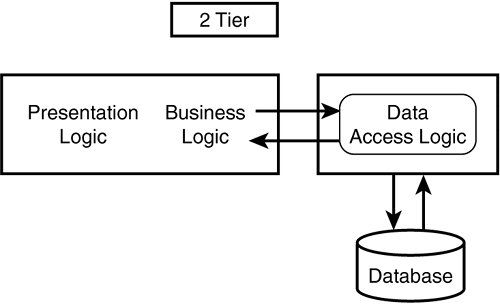
As indicated by Figure 1.2, splitting out Data Access Logic into a second tier keeps the data access independent and can deliver a certain amount of scalability and flexibility within the system.
The advantage of having the Data Access Logic split into a separate physical environment means that not only can data be shared, but any changes to the data access logic are localized in that second tier. In fact, the whole of the second tier could be replaced with a different database vendor or implementation as long as the interface between the two tiers remains the same.
This provides an alternative way of looking at the program logic. Each functional component from the monolithic system could be regarded as a separate layer.
The logical division into layers of functionality can be based on the different responsibilities of parts of the code, namely,
Presentation Logic— This dictates how the user interacts with the application and how information is presented.
Business Logic— This houses the core of the application, namely the rules governing the business processes (or any other functionality) embedded in the application.
Data Access Logic— This governs the connection to any data sources used by the application (typically databases) and the provision of data from those data sources to the business logic.
In Figure 1.2 there are two logical layers but the Presentation and Business Logic layers are still lumped together as one piece of potentially monolithic code.
One of the central problems faced by application developers using the type of architecture shown in Figure 1.2 is that the client is full of business code and it still needs to know details about the location of data sources. Because there is such a concentration of functionality on the client, this type of client is generally termed a thick client. Thick clients usually need to be updated whenever the application changes.
Because the users of a thick client application have much of the application code installed on their local systems, there is a need to install fresh copies of the updated application when changes are made. This presents a serious manageability issue in terms of roll out and version control and puts constraints on the client systems.
With the advent of the Internet, a standard user interface—the web browser— has become the preferred, and sometimes only, user interface. The ubiquitous acceptance of the web browser as the primary user interface has forced developers to move most of their business logic into the back end application. Because the application logic associated with a client is no longer resident on the user's machine, this type of client is known as a thin client. If a 2-tier system is to be adapted for use on the Internet, the thick client part, that contains the business logic and the presentation logic, must be re-written to run on a Web server.
Maintaining separate versions of an application for thick and thin clients leads to larger maintenance and development costs and is best avoided. An alternative strategy is needed, hence the current trend to using three or more tier architectures.