
It’s amazing that the amount of news that happens in the world every day always just exactly fits the newspaper. | ||
| --Jerry Seinfeld | ||
What is equally as amazing as Jerry Seinfeld’s newspaper observation is how much news is now read online instead of from the printed page. As a professional nerd, I’m probably not the best example of your “average person” from a tech perspective, but I only read printed newspapers when I have absolutely no access to the Web. I’m actually fairly old school in terms of generally enjoying printed material from newspapers to books to magazines, but for news you can’t beat the immediacy of online publishing. Which brings me to the topic of this final lesson in the book: RSS news feeds.
If you’ve never heard of the term RSS, don’t worry because it’s not as complicated as many of the acronyms you’ve already faced throughout this book. In fact, once you get past the messy history of RSS, you’ll find that it is a fairly simple technology both to understand and to use. I won’t bother telling you what the RSS acronym stands for just yet because it has a different meaning depending on which version of RSS you use. However, I will tell you that RSS has made a significant impact on the Web and how people use it. Increasing numbers of Web users are relying solely on syndicated RSS “news feeds” to find out when there is something of interest worth seeing on a web site, as opposed to actually visiting that site. A story in an RSS feed links directly to the relevant content, allowing you to bypass the main page of the site containing the content.
RSS fits into this book because it is an XML-based technology, which simply means that the language used to code news feeds is an XML markup language. There are a variety of different ways that you can use RSS. You can display RSS feeds from other web sites on your web site, you can build your own library of RSS feeds and view them regularly using special software called a news aggregator, or you can syndicate your own site using RSS so that other people can view your feeds. This hour touches on all of these uses of RSS.
In this hour, you’ll learn
The historical drama of how RSS came to be
How to use a news aggregator to syndicate RSS news feeds
How to create and validate your own RSS documents
How to transform and display RSS news feeds using XSLT
Although the topic has lived slightly beneath the surface of the mainstream Web, few recent web technologies have caused as much excitement and feverish debate as RSS. What is seemingly a very simple technology has caused quite a bit of infighting among its creators, early adopters, and just about anyone else interested enough to weigh in on the matter. Before we get into that, let’s quickly assess what RSS is. RSS is a technology that allows you to syndicate web content, which means that you can subscribe to web sites and easily find out about new publications to a site without actually having to visit the site. Using special software called a news aggregator, you can monitor news feeds from multiple sites and effectively keep tabs on a wide range of information without having to stop by every different site on a regular basis. You can think of RSS as providing somewhat of a “stock ticker” for web content—it allows you to keep constant tabs on when your favorite sites post something new.
Now back to the history of RSS. Before I give you my official history of RSS so that you can understand what exactly this lesson is all about, I’d like to offer up a recount of the origins of RSS as written by a good friend of mine, Stephen Tallent:
“There was a fork in RSS land. The original RSS, version 0.91, 0.92, etc. was just simple XML. A crew didn’t like it, or the persons involved with it, and splintered off and created what they called RSS 1.0, and built it using RDF style XML that bared little to no resemblance to 0.9x other than by name. That of course spawned a huge religious war and the original crew then developed RSS 2.0, having nothing to do with 1.0, and 2.0 was just an enhanced version of 0.92, still using standard XML. Then another whole crew forked off again and started ATOM, but I digress.”
As Stephen points out, RSS has spawned several different versions over the past few years, all of which are still around in one form or another. It all began back in 1999 with the first incarnation of RSS, which originally stood for RDF Site Summary. This version of RSS was created by Netscape and became known as RSS 0.9. By the way, you need to pay close attention to version numbers in this discussion because they have a lot to do with the different flavors of RSS. Netscape quickly followed up on version 0.9 of RSS with version 0.91, and promptly changed the acronym to Rich Site Summary.
By the Way
RDF stands for Resource Description Framework, which is another whole can of beans. For the purposes of this discussion, all you need to know is that RDF is a specification designed to allow web content creators to add metadata to their content.
It wasn’t long at all before Netscape began to back away from RSS, and ultimately ceased development on it. Ironically, RSS was just starting to gain in popularity, so a group called RSS-DEV took up the cause and continued working on the project. This is where the first drama officially takes place in the RSS story. Back in 1997, a guy by the name of Dave Winer of Userland Software created a technology similar in some ways to RSS. Just after the creation of the RSS-DEV group, Winer entered the RSS fray by releasing his own version of RSS 0.91, which had the advantage of already being used by his company’s products. The RSS-DEV group followed up with RSS 1.0 and Winer countered with RSS 0.92. Winer’s branch of RSS became known as the Userland branch due to its heavy usage within his company.
In 2002, the most stable version of RSS was published by Winer in the form of RSS 2.0, with the acronym changing once more to become Really Simple Syndication. RSS 2.0 was designed to be compatible with RSS 0.92, and also includes features that allow it to be extended to support additional features such as media objects. The RSS-DEV group continued down their path and released a draft of RSS 1.1 in 2005. As of this writing, RSS 2.0 is the de facto standard version of RSS while RSS 1.1 is still somewhat of an “emerging technology.”
To summarize, there are two main functional branches of RSS that you may encounter as you begin to explore syndication around the Web. Different versions of RSS within each branch are reasonably similar to each other. Following are the two branches and the versions of RSS that fit into each:
RSS 1 Branch—RSS 0.90, 1.0, and 1.1
RSS 2 Branch—RSS 0.91–0.94 and 2.0
So the question you have to be asking yourself is why I’m bothering to painstakingly document all of the different versions of RSS so carefully? The reason is because the underlying XML language varies quite a bit based upon the RSS language that you choose to use when syndicating your web content. Without knowing what they are and a little about how they differ, you wouldn’t know which flavor of RSS to choose. But I’ll help you. Given the current state of affairs, it makes sense to focus on the latest version of RSS, which is RSS 2.0. All of the latest RSS-powered web browsers and news aggregator software supports RSS 2.0, which is really all you need to know. The remainder of this hour focuses on RSS 2.0 as you learn more about news feeds and how they are created and syndicated.
By the Way
I stopped short of mentioning Atom in this brief historical discussion of RSS. You can think of Atom as a third branch of RSS that competes more with RSS 2.0. There are strong voices arguing for both technologies, so all I can really tell you is that RSS 2.0 seems to have the widest industry support at the moment, which is why I’ve chosen to cover it exclusively in this lesson. The good news is that if you get comfortable with RSS 2.0 you won’t have much trouble learning Atom if the tide should eventually turn away from RSS 2.0.
Before you face the prospect of creating your own RSS news feeds, it’s important to explore existing news feeds and learn how they work. The easiest way to do this is by installing news aggregator software and exploring feeds for yourself. One of the most popular news aggregators available now is FeedDemon, which is available in a free trial version online at http://www.feeddemon.com/. FeedDemon is a standalone desktop application that is completely independent of your web browser.
If you want a more integrated RSS experience, you may want to look into an aggregator that ties into Microsoft Outlook, such as NewsGator (http://www.newsgator.com/). NewsGator is an Outlook plug-in that integrates news feeds into Outlook by establishing a News folder under the normal Personal Folders commonly used in Outlook. NewsGator also offers a free web-based version of its news aggregator called NewsGator Online. This is a great way to gain an introduction to news feeds because it is free and easy to use. Interestingly enough, NewsGator recently purchased Bradbury Software, the maker of FeedDemon, so don’t be surprised if FeedDemon is eventually marketed as a desktop edition of NewsGator.
By the Way
Just in case you think I’m being a bit partial to NewsGator, some other popular online news aggregators include Bloglines (http://www.bloglines.com/), NewsIsFree (http://www.newsisfree.com/), and Microsoft’s experimental start.com (http://www.start.com/). Google News (http://www.newsisfree.com/) can even be considered an aggregator of sorts, although it doesn’t provide as much flexibility as a true RSS feed manager. Google News is perhaps more powerful as a feed generator because you can use it to easily syndicate Google News categories and even Google searches.
One other option in regard to accessing news feeds is a browser-based feed reader such as Apple’s Safari RSS browser. Safari incorporates RSS into its core, effectively making site syndication a standard component of the browser experience. Apparently other browser vendors are taking note as Microsoft has already announced RSS support in its next version of Internet Explorer. You can also install RSS plug-ins for existing browsers, such as the Sage RSS aggregator for Mozilla Firefox (http://sage.mozdev.org/).
Just so you have a good picture in your mind of how news aggregators work, let’s take a quick look at a couple of examples of how to access syndicated RSS feeds. Figure 24.1 shows the NewsGator Online web-based news aggregator in action.
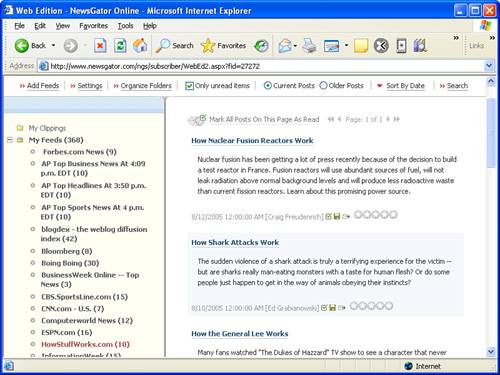
Figure 24.1. NewsGator Online serves as a decent news aggregator without you having to purchase or download anything.
In the figure, NewsGator Online is being used to view the HowStuffWorks.com RSS feed. This feed is regularly updated with links to articles about how things work. For example, in the figure there are articles listed ranging from how nuclear fusion reactors work to how shark attacks work to how the General Lee car (from The Dukes of Hazzard television show and movie) works.
If you want a more full-featured news aggregator that gives you much more control over news feeds, you may want to consider using a desktop or plug-in aggregator. Figure 24.2 shows the FeedDemon desktop aggregator as I’m viewing some very familiar content.
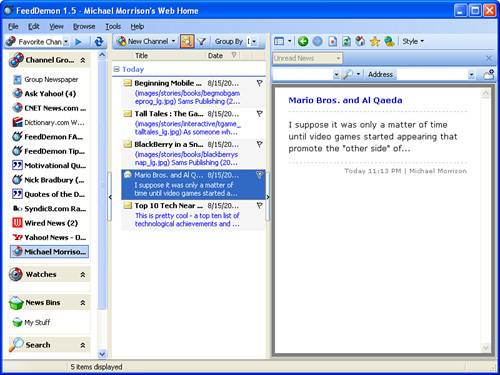
If you pay close attention to the figure, you’ll notice that the news feed being accessed is my very own news feed as syndicated from michaelmorrison.com. FeedDemon makes it possible to easily manage quite a few feeds without feeling as if you’re totally overburdened with information. After you get comfortable using a news aggregator such as FeedDemon, you’ll quickly realize how much more efficiently you can access and process web content. I rarely find myself hopping from site to site now that I can conveniently keep tabs on favorites via news feeds.
It’s time to get down to the business of sorting out exactly how XML fits into the RSS 2.0 picture. As you know by now, RSS 2.0 is an XML markup language used to syndicate web content. You may be pleasantly surprised by the relative simplicity of the RSS 2.0 language. When it comes right down to it, there isn’t all that much information associated with an RSS news feed, and this simplicity translates directly over to the RSS language.
By the Way
For the sake of brevity, from here on when I mention RSS, please assume that I’m referring to RSS 2.0.
Before getting any deeper into the RSS language, it’s important to clarify a few terms. An RSS news item is a discrete piece of content that ultimately resolves to a specific link to a resource on a web site. A collection of related news items can be gathered together into a channel. As an example, if you wanted to divide your news feeds into three categories for Entertainment, Sports, and Technology, each of these categories would constitute a channel. Each piece of syndicated content (each story) within a given category constitutes a news item. An RSS document is broken down into a channel that contains news items, as shown in Figure 24.3.
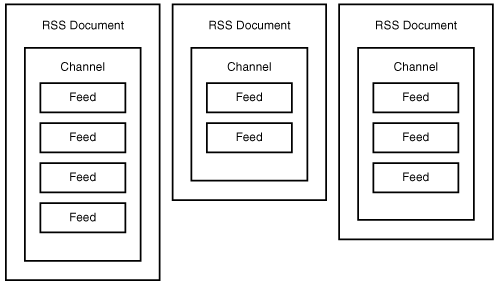
Notice in the figure how each document is limited to a single channel that contains multiple items. There is a lot of flexibility in terms of how many items you assign to a channel even though you can only specify one channel per document.
Getting back to the RSS language, any news item can be described using only a few pieces of information:
Title— The title of the news item
Description— A brief one or two sentence description of the item
Link— The URL of the web resource associated with the item
Publication Date— The publication date of the news item
These conceptual item descriptors translate directly to the RSS language. More specifically, a news item in RSS is coded using <title>, <description>, <link>, and <pubDate> tags. The following is an example of how these tags are used to code a real news item:
<title>My Car Has a Virus!</title> <description>This is a little disturbing but I suppose it was inevitable – wireless networking technologies are now potentially opening up automobiles to computer viruses.</description> <link>http://www.michaelmorrison.com/mambo/index.php?option= com_content&task=view&id=229&Itemid=37</link> <pubDate>Tue, 02 Aug 2005 10:20:44 CST</pubDate>
By the Way
The only tags absolutely required for a news item are <title> and <description>. If you leave out the <link> tag, the description of the item serves as its content. There are several other optional tags that you can use to provide further details about a news item, such as <author>, <enclosure>, and <guid> to name a few.
As you can see, the news item flows directly from the four tags I just mentioned. But these tags don’t tell the entire story. All this code shows is a snippet of code for a specific news item. What you don’t see is how that item fits into a channel, as well as how that channel fits into an entire RSS document. A few more tags are required to complete the equation. More specifically, the <item> and <channel> tags are used to further add structure to an RSS document.
The <item> tag represents a single news item, and in fact, encloses the four item descriptor tags you just learned about. So, you can add the enclosing <item> tag to expand the previous news item listing to look like this:
<item> <title>My Car Has a Virus!</title> <description>This is a little disturbing but I suppose it was inevitable – wireless networking technologies are now potentially opening up automobiles to computer viruses.</description> <link>http://www.michaelmorrison.com/mambo/index.php?option= com_content&task=view&id=229&Itemid=37</link> <pubDate>Tue, 02 Aug 2005 10:20:44 CST</pubDate> </item>
Nothing changed in the code other than the <title>, <description>, <link>, and <pubDate> tags being placed as children of the <item> tag. You can probably now guess that each individual news item within an RSS document takes the form of this code. But you still haven’t found out how these items relate to a channel.
The <channel> tag is used to code the channel in an RSS document. The <channel> tag consists of several child tags that are used to describe the channel, followed by one or more child <item> tags that describe the individual news items. The tags used to describe a channel are actually the same as those used to describe a news item, minus the <pubDate> tag: <title>, <description>, and <link>. In this case, the tags are describing the channel itself, as opposed to a specific news item. Following is an example of a channel coded with these tags:
<channel> <title>Michael Morrison's Blog</title> <description>Technology, entertainment, culture, you name it...</description> <link>http://www.michaelmorrison.com/</link> ... <channel>
By the Way
The only tags absolutely required for a channel are <title>, <description>, and <link>. There are several other optional tags that you can use to provide further details about the channel, such as <copyright>, <language>, and <image> to name a few.
What this example doesn’t show is how the news items themselves (<items>) are contained within the <channel> tag. You see an entire RSS document come together in the next section. For now, there is one more tag to address: the <rss> tag. The <rss> tag is used to mark up the root element of RSS documents. Along with enclosing the rest of the content in the document, the <rss> tag also serves to identify the version of the RSS feed via the version attribute. In the case of RSS 2.0, you set this attribute to 2.0, as this example shows:
<rss version="2.0"> ... </rss>
You’ve now seen all of the pieces and parts that go into a basic RSS document. The next section pulls together what you’ve learned about the RSS language and guides you through the creation of a complete RSS document that contains several news feeds.
By the Way
Back in Hour 13, “Access Your iTunes Music Library via XML,” you learned about XML’s role in Apple’s iTunes digital music service. RSS factors heavily into iTunes when publishing podcasts to the iTunes online service. There is an entire set of iTunes-specific tags that you use to code podcast RSS feeds. <itunes:author>, <itunes:summary>, and <itunes:duration> are examples of some of the tags you must include when coding a podcast as a news feed. To learn more, visit Apple’s online podcast publishing tutorial at http://phobos.apple.com/static/iTunesRSS.html.
You’re finally ready to assemble a complete RSS news feed. So without further ado, take a look at Listing 24.1, which contains the complete source code for an RSS feed that is loosely based on my own personal blog.
Example 24.1. The RSS Code for a Sample Blog
1: <?xml version="1.0" ?>
2:
3: <rss version="2.0">
4: <channel>
5: <title>Michael Morrison's Blog</title>
6: <description>Technology, entertainment, culture, you name it...
</description>
7: <link>http://www.michaelmorrison.com/</link>
8:
9: <item>
10: <title>My Car Has a Virus!</title>
11: <description>This is a little disturbing but I suppose it was inevitable –
12: wireless networking technologies are now potentially opening up
13: automobiles to computer viruses.</description>
14: <link>http://www.michaelmorrison.com/mambo/index.php?option=
15: com_content&task=view&id=229&Itemid=37</link>
16: <pubDate>Tue, 02 Aug 2005 10:20:44 CST</pubDate>
17: </item>
18:
19: <item>
20: <title>Smart Personal Objects</title>
21: <description>The technology is a couple of years old and it has yet to
22: catch on in any real sense but I think it has some interesting potential.
23: I'm referring to Microsoft's SPOT (Smart Personal Object Technology),
24: which is currently deployed in several smart watches that are capable
25: of receiving data over a wireless wide area radio network.</description>
26: <link>http://www.michaelmorrison.com/mambo/index.php?option=
27: com_content&task=view&id=227&Itemid=37</link>
28: <pubDate>Thu, 28 Jul 2005 00:17:07 CST</pubDate>
29: </item>
30:
31: <item>
32: <title>RFID Pajamas</title>
33: <description>Not sure how I feel about this one. A children's apparel
34: maker in California is set to launch a line of pajamas with RFID chips
35: sewn into them that can be used to track children.</description>
36: <link>http://www.michaelmorrison.com/mambo/index.php?option=
37: com_content&task=view&id=223&Itemid=37</link>
38: <pubDate>Mon, 18 Jul 2005 13:10:42 CST</pubDate>
39: </item>
40: </channel>
41: </rss>This code reveals how a complete RSS document pulls together the different tags you’ve learned about to describe multiple news items within a single channel. The first step is to specify details about the channel, which are handled in lines 5 through 7. Once the channel is in place, you can then start listing out the news items. Each of the three news items in this example use the <title>, <description>, <link>, and <pubDate> tags to flesh out their details. Notice that the <pubDate> tag uses a consistent format throughout all of the items for specifying the date and time (lines 16, 28, and 38).
By the Way
If you specify a “pubDate” that is in the future, some news aggregators may elect not to display the item until that date and time.
Hopefully you now have a pretty good feel for how an RSS document is structured. Even so, you don’t have to trust my good word entirely. Instead, I encourage you to use a really handy online tool called the Feed Validator to make sure that your RSS feeds are coded properly. The Feed Validator is available online at http://www.feedvalidator.org/. Its job is to read an RSS feed and make sure that it validates against the RSS specification.
Once the mmblog.xml sample RSS document receives a clean bill of health from the Feed Validator, it’s ready to be posted online where other people can syndicate it using their own news aggregator of choice. But your work isn’t over. Not only is it important to know how to create RSS documents—it’s just as useful knowing how to transform and display them.
You now know enough about the RSS language and how RSS documents are structured that you should be able to put together your own simple web-based news aggregator. To make things more interesting, it’s worth designing your news reader so that it can accommodate multiple separate RSS feeds (channels), as opposed to just reading and displaying items from a single document. To make this possible, you need to create a custom XML document to describe each unique feed source.
Pulling together multiple RSS feeds into a single XML document doesn’t require much information. In fact, all you really need to know is the URL for each RSS document. Listing 24.2 contains the code for an XML document that describes multiple RSS feed sources.
Example 24.2. An XML Document (feedtest.xml) for Managing RSS Feeds
1: <?xml version="1.0" ?> 2: <?xml-stylesheet href="feeder.xsl" type="text/xsl"?> 3: 4: <feeds> 5: <feed src="http://www.michaelmorrison.com/mmblog.xml"/> 6: <feed src="http://www.wired.com/news/feeds/rss2/0,2610,,00.xml"/> 7: <feed src="http://rss.cnn.com/rss/cnn_topstories.rss"/> 8: </feeds>
By the Way
Notice that the first feed in the feedtest.xml sample document (line 5) is the familiar mmblog.xml document that you created in the previous section.
As you can see, this document is very straightforward in terms of using a custom <feed> tag with a single attribute, src, to represent each unique RSS feed source (lines 5 through 7). All of the feeds in the document are stored within a parent <feeds> tag (line 4), which serves as the root element for the document. Aside from the feeds themselves, the key to this document lies in line 2 where the stylesheet feeder.xsl is linked. This XSLT stylesheet provides all the functionality required to read the feeds, format the content within them, and display the results in a web browser.
The feedtest.xml sample document doesn’t contain much information but it’s just enough to grab feed data and transform it for display purposes. The feeder.xsl stylesheet is responsible for reading each feed source in the sample document and processing the RSS code to display the individual news stories in each feed. Listing 24.3 contains the complete code for this XSLT stylesheet.
Example 24.3. The feeder.xsl XSLT Stylesheet for Transforming RSS Feeds into HTML Web Pages
1: <?xml version="1.0"?>
2: <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
3: <xsl:template match="feeds">
4: <html><head><title>Today's News</title></head>
5: <style>
6: <xsl:comment>
7: h1 {
8: width=600px;
9: font-family:verdana, arial;
10: font-size:12pt;
11: font-weight:bold;
12: color:#FFFFFF;
13: background-color:#660000;
14: }
15:
16: p {
17: width=600px;
18: font-family:verdana, arial;
19: font-size:9pt;
20: color:#333333;
21: }
22:
23: .date {
24: color:#999999;
25: }
26:
27: a:link {
28: font-weight:bold;
29: text-decoration:none;
30: color:#660000;
31: }
32:
33: a:hover {
34: font-weight:bold;
35: text-decoration:none;
36: color:#990000;
37: }
38:
39: a:visited {
40: font-weight:bold;
41: text-decoration:none;
42: color:#333333;
43: }
44: </xsl:comment>
45: </style>
46:
47: <body>
48: <xsl:apply-templates/>
49: </body>
50: </html>
51: </xsl:template>
52:
53: <xsl:template match="feed">
54: <xsl:apply-templates select="document(@src)"/>
55: </xsl:template>
56:
57: <xsl:template match="channel">
58: <h1><xsl:value-of select="title"/></h1>
59: <xsl:apply-templates select="item"/>
60: </xsl:template>
61:
62: <xsl:template match="item">
63: <p>
64: <xsl:element name="a">
65: <xsl:attribute name="href">
66: <xsl:apply-templates select="link"/>
67: </xsl:attribute>
68: <xsl:value-of select="title"/>
69: </xsl:element>
70: <br />
71: <xsl:value-of select="description"/>
72: <br />
73: <span class="date">
74: <xsl:if test="pubDate">
75: <xsl:value-of select="pubDate"/>
76: </xsl:if>
77: </span>
78: </p>
79: </xsl:template>
80: </xsl:stylesheet>Similar to other XSLT stylesheets that you’ve seen throughout the book, this stylesheet begins with a healthy dose of CSS code thanks to an internal CSS stylesheet (lines 5 through 45) that takes care of formatting the resulting HTML code so that it looks more appealing. This CSS code applies a maroon color scheme with neatly styled headings and story titles, not to mention graying the date of each story so that it doesn’t compete as much with the description of the story. You see the visual impact of these styles in just a moment.
Of course, it’s important to notice that the code that kicks off the XSLT stylesheet takes place in the feeds template, which is applied to the <feeds> tag in the XML document. In fact, the entire HTML document structure, including the internal CSS style sheet, is contained within the feeds template. This makes sense considering that the <feeds> tag serves as the root element of the feed source XML document.
A much smaller template called feed takes care of transforming each individual feed source. This template simply calls the XSLT document() function while passing in the value of the src attribute (line 54). The end result is that the feed source is read and pulled into the stylesheet where it can be processed as an RSS document. This single line of code is what brings the remaining XSLT templates into play: channel and item.
The channel template simply writes the title of the channel to the HTML page as an <h1> heading tag (line 58), and then hands off the remaining RSS news items to the item template (line 59). From there, the item template does the vast majority of work in terms of transforming RSS data into HTML data that is browser-friendly.
The item template starts by creating an anchor element that serves as a link for the news item title to the actual web resource for the item (lines 64 to 69). The description of the news item is then included as normal paragraph text (line 71), followed by the publish date (lines 73 to 77), which is styled using the CSS date style rule that was defined earlier in the document (lines 23 to 25). Because the <pubDate> tag is optional, an XSLT if conditional is employed to make sure that the publish date is transformed only if it actually exists.
This wraps up the XSLT stylesheet, which you can now use as your own homemade RSS aggregator. Figure 24.4 shows the feedtext.xml example as viewed in Internet Explorer with all of its feeds transformed and cleanly formatted.
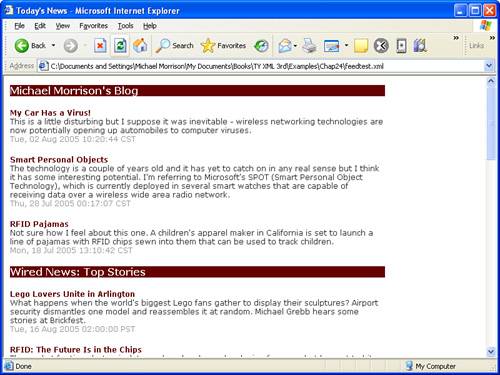
Figure 24.4. The sample feed viewer does a decent job of serving as a simplified news aggregator thanks to a clever XSLT stylesheet.
Although I certainly recommended a more full-featured RSS news aggregator for day-to-day news viewing, there’s nothing stopping you from using this example as a news aggregator. Just doctor the feedtest.xml document to include your own choice set of RSS feeds, and you’re good to go!
This hour introduced you to one of the more popular XML-based technologies in use today, RSS. Even though RSS has a somewhat confusing history, the resulting technology is relatively easy to understand and employ. Fortunately, you have lots of options when it comes to how you use RSS. If nothing else, as a web user you’ll likely find RSS to be extremely useful as a means of keeping tabs on web sites that you might otherwise never take the time to visit regularly. Taking things a step further, you may elect to provide your own RSS news feeds for your own web pages. You might even get more ambitious and expand on the example in this chapter to develop a more full-featured news aggregator of your own. Regardless of how you choose to use RSS, it’s an XML technology that is worth exploring and keeping tabs on.
The Workshop is designed to help you anticipate possible questions, review what you’ve learned, and begin learning how to put your knowledge into practice.
1. | Modify the |
2. | One topic this lesson did not cover is how to transform normal web pages into RSS news feeds so that you don’t have to manually create an RSS document each time something changes on your web site. Try your hand at creating an XSLT stylesheet that automatically generates an RSS document from an existing XHTML web page. |