
For those not familiar with XQuery—it is like XPath + XSLT + Methamphetamines. | ||
| --Brian McCallister | ||
I bet this is the first chapter in a computer book to open with a line about methamphetamines. And for good reason, I might add! The idea behind that quote is that XQuery is like a jacked up version of XPath with a little XSLT sprinkled in for good measure. In other words, XQuery is a technology that packs some punch when it comes to drilling deep into XML data and extracting exactly the data in which you’re interested. This hour introduces you to XQuery and shows you some practical ways to put the language to use with your own XML code.
In this hour, you’ll learn the following:
What XQuery is
How to write queries using XQuery
What the Saxon XQuery processor has to offer
How to execute your own queries using XQuery
In order to explain what XQuery is, I’ll first talk about the problem it’s designed to solve. As you already know all too well, XML documents have a treelike structure. Let’s say you wanted to find all of the elements in a document named color. Given what you’ve learned so far, you’d probably use the DOM to read the document into your application and then iterate over the entire tree in order to extract all the elements called color. Sounds easy enough, right? Let’s say you wanted to find only the color elements that are inside elements called automobile or you want to return only those color elements that have the value blue. I think you can see where I’m going.
When you use XML for data storage, these sorts of problems are very common, so XQuery was created to simplify handling them. If you have an application that supports XQuery, you can write simple queries to perform all the tasks I mentioned in the previous paragraph and many, many more.
XQuery has been around for quite a while but has been slow to catch on. Part of this probably has to do with the fact that XML has yet to replace relational databases as the data storage medium of choice for modern applications, and it may never do so. However, XML has proven itself useful in just about every role outside of efficient data storage and retrieval, and could therefore benefit from an XML-specific query language. Enter XQuery.
By the Way
For the latest information on XQuery, check out the W3C’s XQuery page at http://www.w3.org/TR/xquery/.
XQuery aims to provide XML developers with the data querying power that SQL (Structured Query Language) provides to database developers. Unlike relational databases, which typically have SQL querying features built into their database management systems, you have to use a special tool in order to execute XQuery queries on XML data. This is primarily because there is no concept of a management system for XML data because the data is simply text. Later in the hour you learn how to use a tool to perform XML queries using XQuery.
By the Way
For a look at how to use SQL to perform queries on a relational database and generate XML results, check out Hour 19, “Using XML with Databases.”
XQuery is one of those technologies that is best understood by jumping in and experimenting with it. So, let’s hit the ground running and look at how XQuery is used to query an XML document. The sample XML document, a trimmed down version of a document included in earlier chapters, shown in Listing 18.1, is used in the examples that follow.
Example 18.1. A Sample XML Document Containing Vehicle Data
1: <?xml version="1.0"?> 2: 3: <vehicles> 4: <vehicle year="2004" make="Acura" model="3.2TL"> 5: <mileage>13495</mileage> 6: <color>green</color> 7: <price>33900</price> 8: <options> 9: <option>navigation system</option> 10: <option>heated seats</option> 11: </options> 12: </vehicle> 13: 14: <vehicle year="2005" make="Acura" model="3.2TL"> 15: <mileage>07541</mileage> 16: <color>white</color> 17: <price>33900</price> 18: <options> 19: <option>spoiler</option> 20: <option>ground effects</option> 21: </options> 22: </vehicle> 23: 24: <vehicle year="2004" make="Acura" model="3.2TL"> 25: <mileage>18753</mileage> 26: <color>white</color> 27: <price>32900</price> 28: <options /> 29: </vehicle> 30: </vehicles>
Now let’s take a look at some simple XQuery queries that can be used to retrieve data from that document. The syntax for XQuery is very lean, and in fact borrows heavily from a related technology called XPath; you learn a great deal more about XPath in Hour 22, “Addressing and Linking XML Documents.” As an example, the query that retrieves all of the color elements from the document is:
for $c in //color return $c
This query returns the following:
<?xml version="1.0" encoding="UTF-8"?> <color>green</color> <color>white</color> <color>white</color>
By the Way
The queries are intended to be typed into an application that supports XQuery, or to be used within XQuery queries that are passed into an XQuery processor. The results of the query are displayed afterward, to show what would be returned.
This query asks to return all of the child elements named color in the document. The // operator is used to return elements anywhere below another element, which in this case indicates that all color elements in the document should be returned. You could have just as easily coded this example as:
for $c in vehicles/vehicle/color return $c
The $c in these examples serves as a variable, or placeholder, that holds the results of the query. You can think of the query results as a loop where each matching element is grabbed one after the next. In this case, all you’re doing is returning the results for further processing or for writing to an XML document.
By the Way
If you’re familiar with the for loop in a programming language such as BASIC, Java, or C++, the for construct in XQuery won’t be entirely foreign, even if it doesn’t involve setting up a counter as in traditional for loops.
As the previous code reveals, a / at the beginning of a query string indicates the root level of the document structure or a relative folder level separation. For example, the query that follows wouldn’t return anything because color is not the root level element of the document.
/color
All of this node addressing syntax is technically part of XPath, which makes up a considerable part of the XQuery technology. You learn a great deal more about the ins and outs of XPath in Hour 22. As you can see, aside from a few wrinkles, requesting elements from an XML document using XQuery/XPath isn’t all that different from locating files in a file system using a command shell.
In XQuery/XPath, expressions within square brackets ([]) are subqueries. Those expressions are not used to retrieve elements themselves but to qualify the elements that are retrieved. For example, a query such as
//vehicle/color
retrieves color elements that are children of vehicle elements. On the other hand, this query
//vehicle[color]
retrieves vehicle elements that have a color element as a child. Subqueries are particularly useful when you use them with filters to write very specific queries.
Continuing along with the vehicle code example, let’s say you want to find all of the option elements that are grandchildren of the vehicle element. To get them all from the sample document, you could just use the query vehicles/vehicle/options/option. However, let’s say that you didn’t know that the intervening element was options or that there were other elements that could intervene between vehicle and option. In that case, you could use the following query:
for $o in vehicles/vehicle/*/option return $o
Following are the results of this query:
<?xml version="1.0" encoding="UTF-8"?> <option>navigation system</option> <option>heated seats</option> <option>spoiler</option> <option>ground effects</option>
The wildcard (*) matches any element. You can also use it at the end of a query to match all the children of a particular element.
After you’ve mastered the extraction of specific elements from XML files, you can move on to searching for elements that contain information you specify. Let’s say you want to find higher-level elements containing a particular value in a child element. The [] operator indicates that the expression within the square braces should be searched but that the element listed to the left of the square braces should be returned. For example, the following expression would read “return any vehicle elements that contain a color element with a value of green:
for $v in //vehicle[color='green'] return $v
Here are the results:
<?xml version="1.0" encoding="UTF-8"?>
<vehicle year="2004" make="Acura" model="3.2TL">
<mileage>13495</mileage>
<color>green</color>
<price>33900</price>
<options>
<option>navigation system</option>
<option>heated seats</option>
</options>
</vehicle>The full vehicle element is returned because it appears to the left of the search expression enclosed in the square braces. You can also use Boolean operators such as and and or to string multiple search expressions together. For example, to find all of the vehicles with a color of green or a price less than 34000, you would use the following query:
for $v in //vehicle[color='green' or price<'34000'] return $v
This query results in the following:
<?xml version="1.0" encoding="UTF-8"?>
<vehicle year="2004" make="Acura" model="3.2TL">
<mileage>13495</mileage>
<color>green</color>
<price>33900</price>
<options>
<option>navigation system</option>
<option>heated seats</option>
</options>
</vehicle>
<vehicle year="2004" make="Acura" model="3.2TL">
<mileage>18753</mileage>
<color>white</color>
<price>32900</price>
<options/>
</vehicle>The != operator is also available when you want to write expressions to test for inequality. Additionally, there are actually three common Boolean operators: and, or, and not. For example, you can combine these operators to write complex queries, such as this:
for $v in //vehicle[not(color='blue' or color='green') and @year='2004'] return $v
This example is a little more interesting in that it looks for vehicles that aren’t blue or green but that are in the model year 2004. Following are the results:
<?xml version="1.0" encoding="UTF-8"?>
<vehicle year="2004" make="Acura" model="3.2TL">
<mileage>18753</mileage>
<color>white</color>
<price>32900</price>
<options/>
</vehicle>You might be wondering about the at symbol (@) in front of the year in the query. If you recall from the vehicles sample document (Listing 18.1), year is an attribute, not a child element—@ is used to reference attributes in XQuery. More on attributes in a moment.
Just to make sure you understand subqueries, what if you wanted to retrieve just the options for any white cars in the document? Here’s the query:
//vehicle[color='white']/options
And here's the result:
<?xml version="1.0" encoding="UTF-8"?> <options> <option>spoiler</option> <option>ground effects</option> </options> <options/>
Let’s break down that query. Remember that // means “anywhere in the hierarchy.” The //vehicle part indicates that you’re looking for elements inside a vehicle element. The [color='white'] part indicates that you’re interested only in vehicle elements containing color elements with a value of white. The part you haven’t yet seen is /options. This indicates that the results should be any options elements under vehicle elements that contain a color element matching white.
The next thing to look at is attributes. When you want to refer to an attribute, place an @ sign before its name. So, to find all the year attributes of vehicle elements, use the following query:
//vehicle/@year
You can write a slightly different query that returns all of the vehicle elements that have year attributes as well:
//vehicle[@year]
This naturally leads up to writing a query that returns all the vehicle elements that have a year attribute with a certain value, say 2005. That complete query is
for $v in //vehicle[@year="2005"] return $v
Thus far I’ve focused solely on tweaking queries and returning the raw result, which is a collection of nodes. Realistically, you will often want to further process the results of a query to extract information from the nodes and transform it for display purposes or to pass along to another application or service. It’s very straightforward to further process query results and package them within other surrounding XML code to effectively create transformed data. You can even transform query results into HTML code that can be viewed as a web page.
The key to incorporating query results into surrounding code is curly braces ({}), which you use to surround query data. Before you can do that, however, you need to know how to access the content within a node. You do this by calling the XQuery data() function and supplying it with the node in question. Following is an example of formatting a query result:
for $c in //color
return <p>Vehicle color: {data($c)}</p>When executed on the vehicle sample document, this code results in the following:
<?xml version="1.0" encoding="UTF-8"?> <p>Vehicle color: green</p> <p>Vehicle color: white</p> <p>Vehicle color: white</p>
As you can see, the value of each color element is extracted and included in a <p> tag that would be suitable for inclusion within an HTML document.
You can also process attributes directly from a query string to get more interesting results, as in the following query:
xquery version "1.0";
<p>
Following are all of the white vehicles:<br />
{ for $v in //vehicle[color='white']
return <div>{data($v/@year)} - {data($v/@make)} - {data($v/@model)}</div>
}
</p>This code demonstrates how a query can be placed within other XML (XHTML) code by enclosing it in {}. The resulting XHTML code is then readily viewed within a web browser:
<?xml version="1.0" encoding="UTF-8"?> <p> Following are all of the white vehicles:<br/> <div>2005 - Acura - 3.2TL</div> <div>2004 - Acura - 3.2TL</div> </p>
One last trick for formatting queries involves the XQuery order by statement, which allows you to set the order of query results. Following is the same query you just saw, except this time the query results are ordered by price:
xquery version "1.0";
<p>
Following are all of the white vehicles:<br />
{ for $v in //vehicle[color='white']
order by $v/price
return <div>{data($v/@year)} - {data($v/@make)} - {data($v/@model)}</div>
}
</p>Because the price isn’t shown in the output, this ordering isn’t quite so meaningful in this particular example, but it will be as you explore more interesting examples a little later in the hour.
None of this XQuery stuff would mean much if you didn’t have a tool that can process and return query results. One such tool that I’ve found to be particularly useful is Saxon, which was developed by Michael Kay. Saxon comes in two versions, a commercial version and a free open source version. You’ll find that the free open source version of Saxon will probably serve your needs just fine, at least for now as you learn the ropes of XQuery. If you have some grand plans for XQuery in the works, by all means check into the full commercial version of XQuery as well. You can find both versions online at http://www.saxonica.com/.
Saxon is a command-line tool that you use to execute XQuery queries. Saxon is built as a Java application, so you’ll need to have the Java runtime installed in order to run Saxon. You can download the Java runtime (J2SE) from http://java.sun.com/j2se/1.4.2/download.html. After downloading and installing both Java and Saxon, it’s important to set the Java CLASSPATH environment variable before attempting to run Saxon. The purpose of this variable is to let Java know where all of the executable class files are located when it tries to run an application. In the case of Saxon, you’re interested in letting Java know about the file saxon8.jar, which is located in the main Saxon folder, usually saxon.
To set the CLASSPATH variable for Saxon, just issue this command at the command line:
set classpath=%classpath%;saxonsaxon8.jar
By the Way
You may want to double-check the Saxon documentation for your specific version to make sure the .JAR file has the same name as I’ve mentioned here (saxon8.jar). If not, just change the code to match the file you have.
You’re now ready to run Saxon but you need to know how to run it. However, before you get to that you need to understand how queries are stored for XQuery. XQuery documents are stored in files with a .XQ file extension. In addition to the query code, all XQuery documents are required to start with the following line of code:
xquery version "1.0";
The query code then follows after this line. So you have an XQuery document with a .XQ file extension and an XML file with probably a .XML file extension, and you’re ready to run the query on the XML document. Just issue the following command at the command line:
java net.sf.saxon.Query -s xmldoc.xml querydoc.xq > outdoc.xml
In this sample command, xmldoc.xml is the XML source document, querydoc.xq is the XQuery document, and outdoc.xml is the output document that the query results are written to. There are numerous other options you can use with Saxon but this basic command is all you need to get going running your own queries.
I promised earlier that I would pull together everything you’ve learned about XQuery and show you a couple of practical examples. The remainder of the lesson focuses on a couple of sample queries that operate on the same XML data. This data is stored in the familiar training log XML document that you’ve seen in earlier lessons. A partial listing of this document is shown in Listing 18.2.
Example 18.2. A Partial Listing of the Training Log XML Document
1: <?xml version="1.0"?> 2: <!DOCTYPE trainlog SYSTEM "etml.dtd"> 3: 4: <trainlog> 5: <!— This session was part of the marathon training group run. —> 6: <session date="11/19/05" type="running" heartrate="158"> 7: <duration units="minutes">45</duration> 8: <distance units="miles">5.5</distance> 9: <location>Warner Park</location> 10: <comments>Mid-morning run, a little winded throughout.</comments> 11: </session> 12: 13: <session date="11/21/05" type="cycling" heartrate="153"> 14: <duration units="hours">2.5</duration> 15: <distance units="miles">37.0</distance> 16: <location>Natchez Trace Parkway</location> 17: <comments>Hilly ride, felt strong as an ox.</comments> 18: </session> 19: 20: ... 21: </trainlog>
The first sample query I want to show you involves plucking out a certain type of training session and then transforming it into a different XML format. This might be useful in a situation where you are interfacing two applications that don’t share the same data format. Listing 18.3 contains the code for the query, which is stored in the file trainlog1.xq.
Example 18.3. A Query to Retrieve and Transform Running Sessions
1: xquery version "1.0";
2:
3: <runsessions>
4: { for $s in //trainlog/session[@type="running"]
5: order by $s/date
6: return <location>{$s/@date} {data($s/location)} ({data($s/distance)}
{data($s/distance/@units)})</location>
7: }
8: </runsessions>To issue this query against the trainlog.xml document using Saxon, just issue the following command from within the main Saxon folder:
java net.sf.saxon.Query -s trainlog.xml trainlog1.xq >output1.xml
By the Way
If you run the sample query from within the main Saxon folder as I’ve suggested, make sure to copy the sample files into that folder so that Saxon can access them. Otherwise, you can add the main Saxon folder to your path and run it from anywhere.
This command executes the query and writes the results to the file output1.xml, which is shown in Listing 18.4.
Example 18.4. The XQuery Results of the Running Query
1: <?xml version="1.0" encoding="UTF-8"?> 2: <runsessions> 3: <location date="11/19/05">Warner Park (5.5miles)</location> 4: <location date="11/24/05">Warner Park (8.5miles)</location> 5: <location date="11/26/05">Metro Center (7.5miles)</location> 6: <location date="11/29/05">Warner Park (10.0miles)</location> 7: <location date="11/31/05">Warner Park (12.5miles)</location> 8: <location date="12/04/05">Warner Park (13.5miles)</location> 9: </runsessions>
As the listing reveals, only the running training sessions are returned, and they are formatted into a new XML structure that is somewhat different than the original training log. The <location> tag may look familiar but it now contains the date attribute, which was previously a part of the <session> tag. The new code also combines the location, distance, and distance units into the content of the <location> tag. And finally, the individual location elements are packaged within a new root element named runsessions.
Although the previous example is certainly interesting in terms of how it transforms XML data, it doesn’t give you anything remarkable to look at. What would be even better is to see the results of a query in a web browser. Of course, this requires transforming query results into HTML code. Listing 18.5 contains a query that grabs every training log session and transforms it into an HTML document with carefully formatted table rows for each row of query data.
Example 18.5. A Query to Format Training Sessions into an HTML Document
1: xquery version "1.0";
2:
3: <html>
4: <head>
5: <title>Training Sessions</title>
6: </head>
7:
8: <body style="text-align:center">
9: <h1>Training Sessions</h1>
10: <table border="1px">
11: <tr>
12: <th>Date</th>
13: <th>Type</th>
14: <th>Heart Rate</th>
15: <th>Location</th>
16: <th>Duration</th>
17: <th>Distance</th>
18: </tr>
19: { for $s in //session
20: return <tr> <td>{data($s/@date)}</td> <td>{data($s/@type)}</td>
21: <td>{data($s/@heartrate)}</td>
22: <td>{data($s/location)}</td>
23: <td>{data($s/duration)} {data($s/duration/@units)}</td>
24: <td>{data($s/distance)} {data($s/distance/@units)}</td> </tr>
25: }
26: </table>
27: </body>
28: </html>This query is certainly more involved than anything you’ve seen thus far in this lesson but it really isn’t very complicated—most of the code is just HTML wrapper code to format the query results for display. Pay particular attention to how each piece of XML data is carefully wrapped in a <td> element so that it is arranged within an HTML table (lines 20 through 24).
The following command is all it takes to generate an HTML document using the query in Listing 18.5:
java net.sf.saxon.Query -s trainlog.xml trainlog2.xq >output2.html
Listing 18.6 contains the transformed HTML (XHTML) document that results from this Saxon command.
Example 18.6. The Partial XQuery Results of the Training Session Query
1: <?xml version="1.0" encoding="UTF-8"?> 2: <html> 3: <head> 4: <title>Training Sessions</title> 5: </head> 6: <body style="text-align:center"> 7: <h1>Training Sessions</h1> 8: <table border="1px"> 9: <tr> 10: <th>Date</th> 11: <th>Type</th> 12: <th>Heart Rate</th> 13: <th>Location</th> 14: <th>Duration</th> 15: <th>Distance</th> 16: </tr> 17: <tr> 18: <td>11/19/05</td> 19: <td>running</td> 20: <td>158</td> 21: <td>Warner Park</td> 22: <td>45minutes</td> 23: <td>5.5miles</td> 24: </tr> 25: ... 26: </table> 27: </body> 28: </html>
No surprises here—just a basic HTML document with a table full of training log information. I’ve deliberately only showed the partial results since the table data is actually fairly long due to the number of training log elements. Figure 18.1 shows this web page as viewed in Internet Explorer.
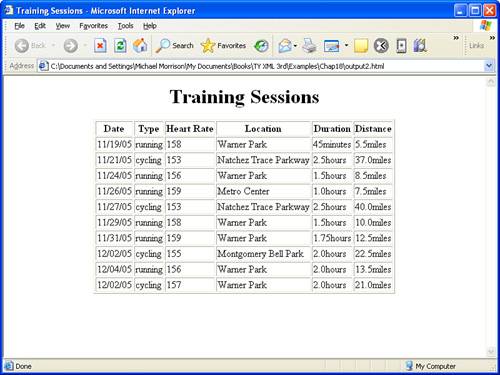
Finally, some visible results from XQuery! XQuery is a powerful technology that makes it possible to drill down into the inner depths of XML code and extract data with a great deal of precision. This hour and the two examples you just saw truly only scratch the surface of XQuery.
This hour introduced you to XQuery, which is a query language that makes it relatively easy to extract specific elements from an XML document. XQuery is analogous to SQL in the relational database world in that it allows you to construct queries that you execute against XML documents to retrieve matching data. In this lesson, you learned how to construct a variety of different kinds of queries using XQuery. You learned that XQuery is closely linked to another XML technology, XPath. You wrapped up the hour by working your way through a couple of interesting XQuery examples, which hopefully reinforced what you learned throughout the lesson as a whole.
Is XQuery supported in any web browsers? | |
Not yet. Unfortunately, none of the major browsers support XQuery just yet, although rumors abound that XQuery support is underway for upcoming releases. | |
How does XQuery differ from XPath? | |
XPath is a language used for addressing within XML documents. XQuery is a query language used to filter data within XML documents. XPath can also be used for pattern matching on XML documents and in fact serves that role within XQuery. Fundamentally, the two languages differ more in purpose than in design. XQuery solves a larger problem and incorporates XPath toward that end. Chapter 22 covers XPath in detail. |
The Workshop is designed to help you anticipate possible questions, review what you’ve learned, and begin learning how to put your knowledge into practice.
1. | Download an implementation of XQuery, such as Saxon, and use it to write some queries against your own XML documents. You can download a free open source version of Saxon from http://www.saxonica.com/. |