
To complete this journey I want to share with you some success cases. As you might have realized by now, you’re not the only one having these types of issues; a lot of companies struggle when scaling their successful products, especially when those products are massively successful, like PayPal or Netflix.
In this final chapter, I’m hoping to shed some light into how the big companies are solving the types of problems you and others like you are having.
PayPal
PayPal can definitely be considered one of the early adopters of Node.js for enterprise solutions. Back in 2013 they saw the opportunity to move away from a front-end/back-end type of development group and into a unified full-stack one.
They did this gradually, but started to incorporate Node.js into their team. The first thing they looked at was Express.js, but as happens with many tools, once they started to use it to build their large-scale solutions, they realized it was not enough.
Lusca provides a layer of security to your microservices. It provides Cross Site Request Forgery, Content Security Policy X-Frame options and more completely out of the box.
Kappa provides an NPM proxy, capable of creating private NPM repos without having to duplicate the entire registry.
Makara provides internationalization support on top of Dust.js, which is a templating library. This is perfect if you’re not just creating APIs, but also working on the front-end of your application as well.
Adaro is simply a wrapper on top of Dust.js. It is already in use if you’re using Makara, but if you’re not, you can simplify your work by using Adaro.
The interesting aspect of this transformation is that because they were hesitant about going all in with Node.js at that moment, once they decided to try it with a new application, they did it by developing the same app in Java as well (which was their language of choice until that moment). They started working on the Node.js version two months after the Java project had started and with just two developers.

Performance comparison between Node.js and Java versions of the same app2
In the end, this new approach for PayPal turned out to be a great move. It didn’t just increase the performance of their apps (an example of one is shown in Figure 7-1), but it also helped reduce development time compared to their old Java-based workflow.
Uber

Monolithic initial Uber architecture
After they started growing out of control and realized this monolithic-based architecture wasn’t going to work, they went for a microservices-based approach. The problem? They needed high levels of reliability; the platform had to be up at all times (ideally, it would need to be able to recover from errors on its own) and needed to grow fast and automatically whenever the traffic required it to.
So, because of that particular set of needs, a regular set of microservices wouldn’t cut it, in fact, none of the standard solutions at the time did, so they ended-up building their own: Ringpop.
A membership protocol for the nodes of the cluster. This works based on a SWIM gossip protocol variation. It works very similarly to Redis cluster mode: every node of the cluster knows about the others, and can be notified if a new one appears, as well as being notified when existing members are down. Figure 7-3 shows a simplified version of the communication protocol and how a new node can notify any existing one to be added into the group.
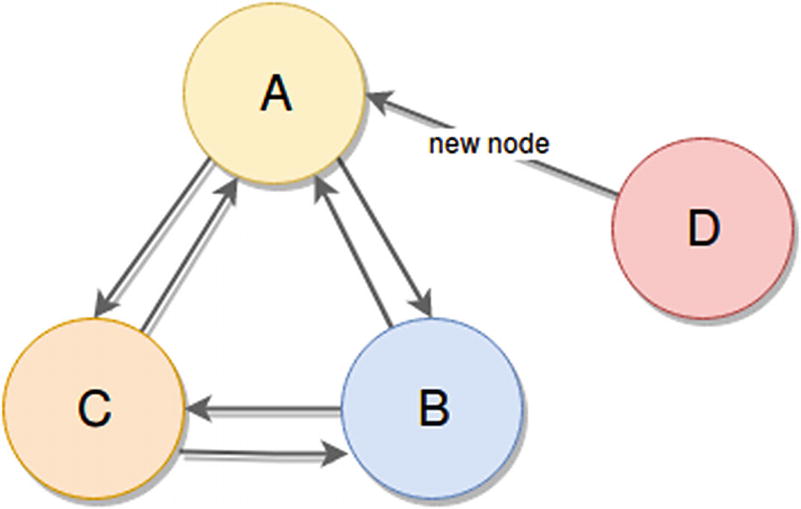
Gossip-based cluster example
A consistent hashing mechanism to equally distribute workload amongst worker nodes. This makes sure the cluster is load-balanced by itself, taking the need for load balancing off the developer.
A transparent “handle or forward” mechanic, which makes sure the developer doesn’t need to know each and every single node of the cluster, instead of that, they can simply send a request to any one that’s already known, and if that node is not able to handle the request, it’ll forward it to the one that can.
Essentially this library gives the team everything they needed to create an architecture capable of handling the high level of traffic they get every day; and they were kind enough to open source it, so not only can you use it on your own projects, you can also contribute to it and help make it grow and improve.
LinkedIn is another company that underwent a drastic transformation for some of their services once they started growing massively. But in this case, they didn’t migrate off of Java; they migrated from a Ruby on Rails application into a Node.js setup.
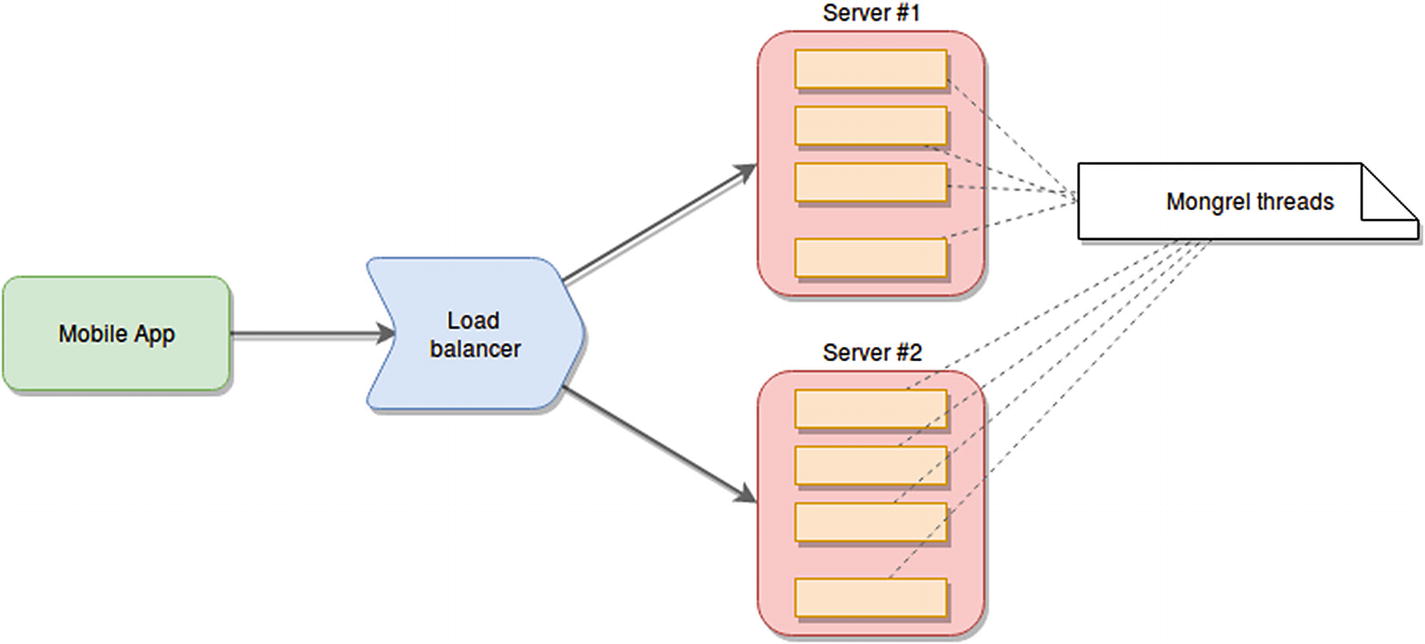
Estimated mobile API architecture based on RoR plus Mongrel
With Node.js they wanted to move away from that model and into a stateless event-based system, capable of simplifying the interaction between client and server to a single request.
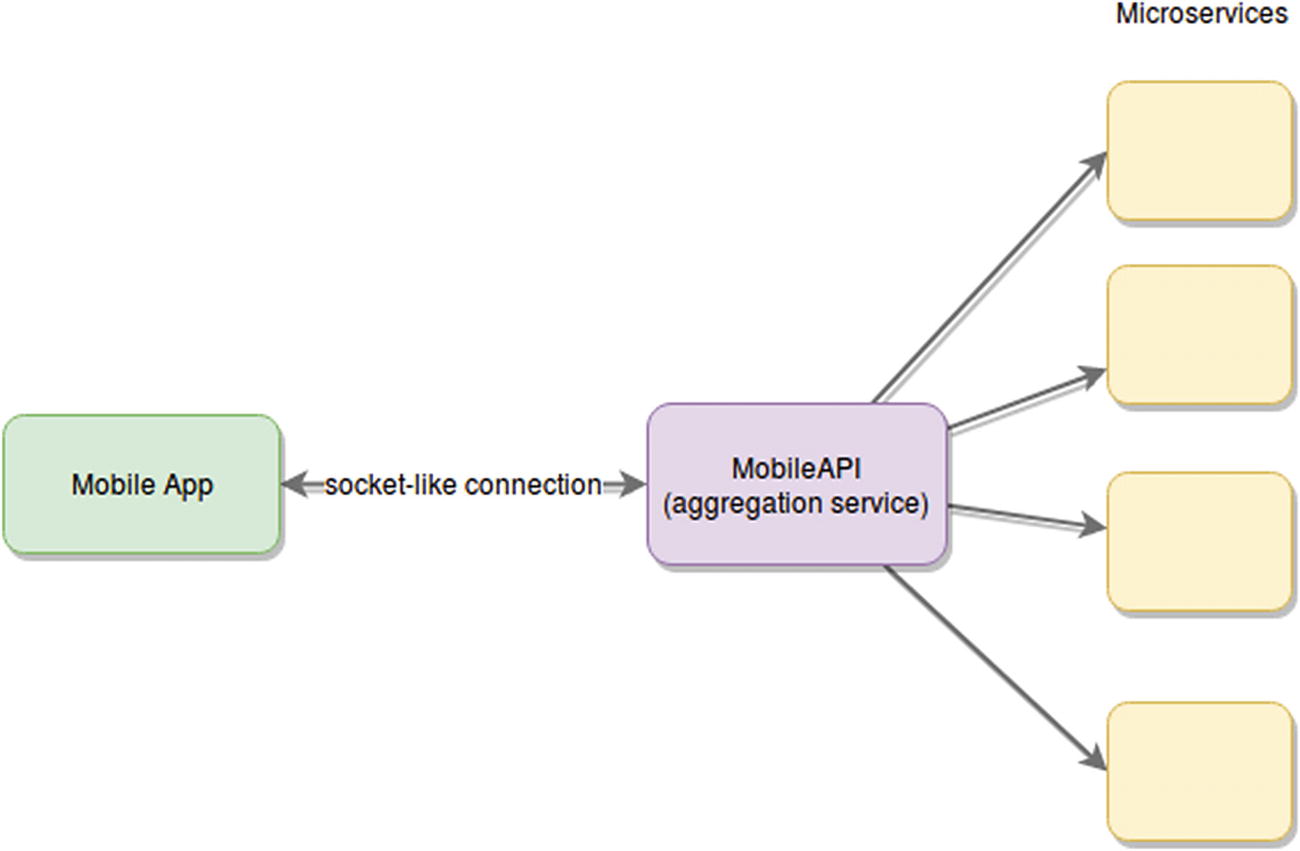
Estimated change on architecture
With this new setup, they drastically reduced the number of servers they needed, from 30 to only 3, simplifying the effort required to maintain the infrastructure.
Note
The comparison here is not meant to state that Node.js is faster than Ruby on Rails, because there are many factors to take into consideration. They didn’t just change their programming language and everything started to work; they changed their entire architecture and tech stack.
Biggest Challenges
According to LinkedIn’s engineers, some of the biggest challenges they met while changing their entire architecture and tech stack were monitoring and profiling.
Monitoring
We covered this in a previous chapter, and it is not only mandatory, but difficult to implement, since it usually requires ad-hoc setups. This is particularly so when you need to move away from standard architectural patterns into specific models that only suit your requirements.
Profiling
Pacemaker implementation monitoring the load of the event loop
That little bit of code simply adds something to the event loop, recording the time at the moment of insertion, and once the callback is executed, the time difference is calculated. By tracking these numbers, you can keep track of spikes on the event-loop, which would indicate the presence of CPU-intensive code in your application.
Netflix
Finally, Netflix is yet another company that can be considered an early adopter of Node.js. They started playing around with it on an enterprise level early on, and were not afraid of showing their results to the industry once they started putting in production their “experiments.”
Like many other companies, by the time they decided to start experimenting with Node.js, they had a full set of monolithic applications written in Java. They were struggling with some aspects of their development flow because of the tech stack in place, having big bulky applications that couldn’t really be tested locally, so every time a change was made, it required up to 40 minutes of wait time for build processes and deployment time. And with the constant development of new and more advanced devices, they suddenly were faced with the requirement of supporting all those devices.
Essentially this made it very difficult to expand and grow without a major effort from the development team.
So the first thing they tried was the microservices route; like many others, they went the REST way. Similarly to what the team at LinkedIn ended up doing, they had a REST API in front of a set of microservices. The instant benefit was that they now had a more flexible and standardized interface they could use to add new devices. That was great, but they also had problems, such as having the API and the microservices managed by two different teams, causing the latter to wait several weeks for the first one to approve and adopt their own changes in order to move them into production.
Furthermore, this was one of those cases where REST is not the right fit for the problems. The developers treated everything as a resource (as one should when it comes to REST), but their UI had far oo many resources that needed to be loaded, so every screen required too many round trips before it could load properly.

High-level architecture of the approach taken by API.NEXT
The problem with this approach was that it quickly got out of hand, and because of the size of these APIs, the team now had thousands of individual scripts to maintain. With all of them being on the same server instance, those servers needed to be upgraded often due to lack of memory, or to handle I/O operations, for example. So all in all, this new approach was definitely a step in the right direction, but they still had several issues to solve.
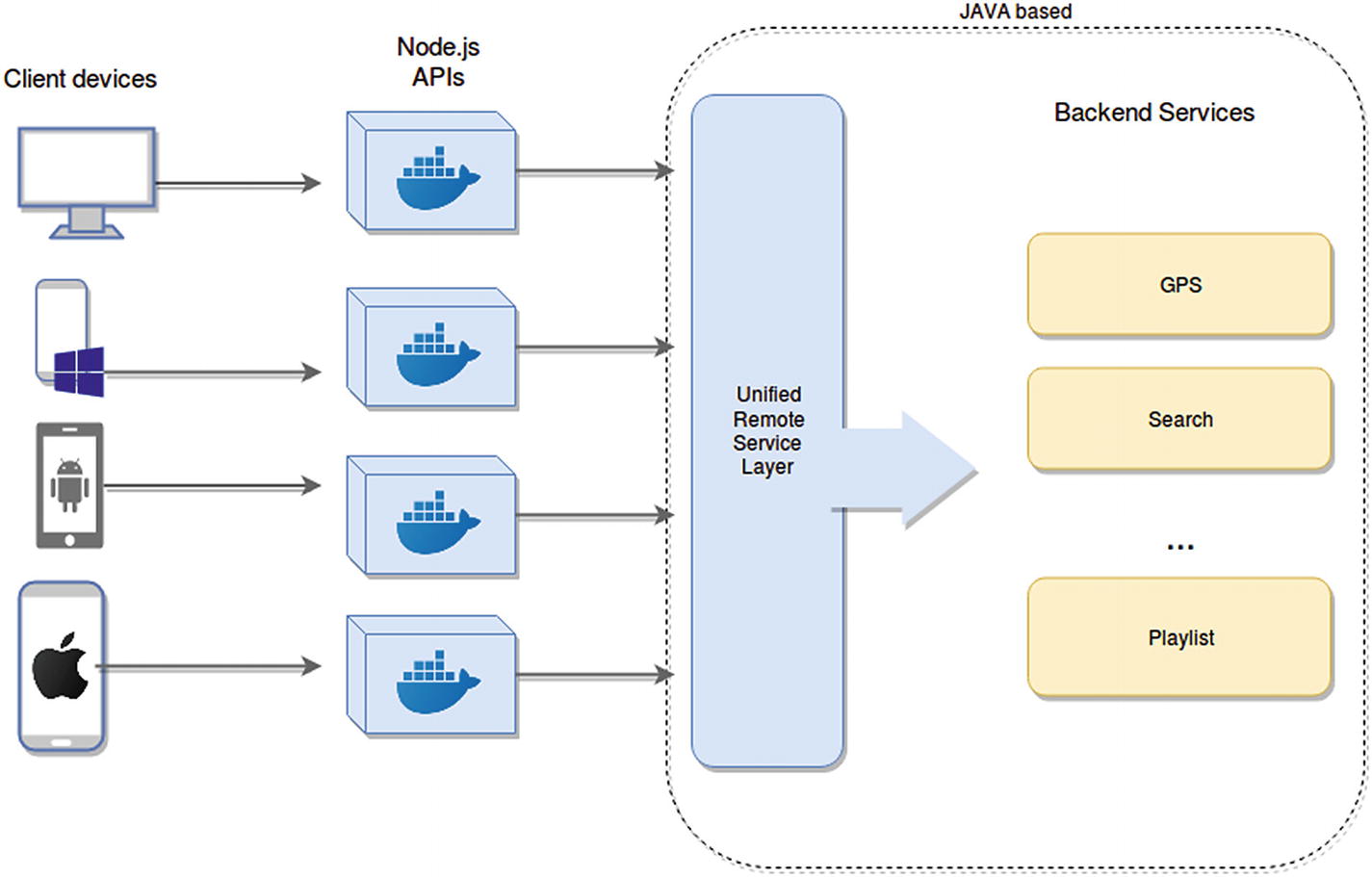
Highly available and scalable new architecture for Netflix’s API
As you can see, they’re isolated thanks to the fact they’re running inside individual Docker containers. With this approach, they managed to improve their developer’s productivity, thanks to having JavaScript everywhere (when it comes to client-facing API development).
Note
This might not be the case for every team, but for this company, it made a lot of sense to have the teams focused on the APIs and the client apps working together as one, and for this, a single programming language made a lot of sense.
Finally, with the Docker approach for their APIs, they also gain productivity since developers can now simply run that container locally and test without having to perform deployments anywhere. One last point to note about this architecture is that it is not purely utilizing Node.js for the entire approach; instead, it’s mixing technologies wherever necessary. Node.js on one side makes a lot of sense for APIs, thanks to the speed of development and their easy access to non-blocking I/O. But at the same time, the Netflix team can keep using their Java-based services without having to rewrite them and still get a lot of performance out of them.
Summary
PayPal extended the tools they were using (Node.js) by making sure they can be used at scale because at the time, Node.js hadn’t had the attention from the enterprise scene that it has now.
Uber went from a monolithic architecture into microservices using custom protocols they open sourced.
LinkedIn went from a Ruby on Rails solution that was not ready to scale (due among other things to the current state of the tech stack they were using) into a custom architecture based on Node.js.
Finally, Netflix went through a set of changes, iterating over their design, looking for weak points and trying to solve them on the next version. At the end (and possibly something they’ll eventually change again) they ended up with a mixed solution, trying to leverage the strengths of each technology without being blinded by just one and using it as a silver bullet.
What you should take away from this chapter, and from this book overall, is this: try to understand how your business is going to impact your product and try to create an architecture that is ready to grow. Take into consideration the industry standards, but don’t be afraid to mix and match styles, creating your own solutions specifically tailored to your business needs.
Thanks so much for reading and working through this book; I hope you were able to get something out of it!