
 CHAPTER 1
CHAPTER 1
Motion Planning — Introduction
Midway along the journey … I woke to find myself in a dark wood, for I had wandered off from the straight path.
– Dante Alighieri, The Divine Comedy, “Inferno”
1.1 INTRODUCTION
In a number of Slavic languages the noun “robota” means “work”; its derivative “robotnik” means a worker. The equivalent of “I go to robota” is a standard morning sentence in many East European homes. When in 1921 the Czech writer Karel Capek needed a new noun for his play R.U.R. (Rossum's Universal Robots), which featured a machine that could work like a human, though in a somewhat mechanical manner, he needed only to follow Slavic grammar: Chopping off “a” at the end of “robota” not only produced a new noun with a similar meaning but moved it from feminine to masculine. It was just what he wanted for his aggressive machines that eventually rebelled against the humankind and ran amok. The word robot has stuck far beyond Capek's wildest expectations— while, interestingly, still keeping his original narrow meaning.
Among the misconceptions that society attaches to different technologies, robotics is perhaps the most unlucky one. It is universally believed that a robot is almost like a human but not quite, with the extent of “not quite” being the pet project of science fiction writers and philosophers alike. The pictures of real-life robots in the media, in which they look as close to a human as, say, a refrigerator, seem to only insult the public's insistence on how a robot should look.
How much of “not quite”-ness is or ever will be there is the subject of sometimes fierce arguments. It is usually agreed upon that high intelligence is a must for a robot, as is a somewhat wooden personality. And, of course, the public refuses to take into account the tender age of the robotics field. One standard way of expressing the “not quite”-ness is a jerky motion sold as robot motion in Hollywood movies and by young people imitating a robot on street corners. Whatever future improvements the public is willing to grant the field, a smooth motion and a less-than- wooden personality are not among them. A robotics professional will likely give up when hearing from friends or school audiences that the best robots are found in Disneyworld. (“What do you mean? Last week I myself talked to one in Disneyworld in Orlando.” Don't try to tell him he actually spoke to an operator in the nearby building.)
It would not be fair to blame Karel Capek, or Disney, or Hollywood for the one-dimensional view of robotics. The notion of a robotic machine goes far back in time. People have always dreamt of robots, seeing them as human-like machines that can serve, fascinate, protect, or scare them. In Egyptian temples, large figurines moved when touched by the morning sun rays. In medieval European cities, bronze figures in large tower clocks moved (and some still move) on the hour, with bells ringing.
Calling on human imagination has been even easier and more effective than relying on physical impersonation. Jewish mysticism, with its Cabbala teachings and literary imagery, has also favored robots. Hence the image of Golem in Cabbala, a form that is given life through magic. In the Hebrew Bible (Psalms 139:16) and in the Talmud, Golem is a substance without form. Later in the Middle Ages the idea took the form; it was said that a wise man can instill life in an effigy, thus creating a Golem with legs and arms and a head and mighty muscles. A “typical” Golem became a human-like automaton, a robot.
Perhaps the best-known such story is of Rabbi Loew of sixteenth-century Prague, in Czechia. (The Rabbi's somewhat scary gravestone still greets the visitor in the Jewish cemetery at Prague's center.) Rabbi Loew created his Golem from clay, to serve as his servant and to help protect the Jews of Prague. Though the creature was doing just that, saving Jews of Prague from many calamities by using its great strength and other supernatural skills, with time it became clear that it was getting out of hand and becoming dangerous to its creator and to other Jews. Rabbi Loew thus decided to return the Golem back to its clay immobility, which he achieved using a secret Cabbalistic formula. He then exiled the figure to the attic of his Prague synagogue, where it presumably still is, within two blocks from Loew's grave. This story became popular through the well-written 1915 novel called Der Golem, by a German writer Gustav Meyrink, and the 1920 movie under the same title by the German director Paul Wegener (one can still find it in some video shops). The Golem, played by Wegener himself, is an impressive figure complete with stiff “robotic” movement and scary square-cut hairdo.
We still want the helpful version of that robot—in fact, we never wanted it more. The last 40 years have seen billions of dollars, poured by the United States, European, Japanese, and other governments, universities, and giant companies into development of robots. As it often happens with new technologies, slow progress would breed frustration and gaps in funding; companies would lose faith in quick return and switch loyalties to other technologies. Overall, however, since 1960 the amount of resources poured by the international community into robotics has been steadily going up. For what it's worth, even the dream of an anthropomorphic likeness is well and alive, even among professionals and not only for toy robots. Justifications given—like “people feel comfortable with a human-looking robot,” as if people would feel less comfortable with a dishwasher-shaped robot—may sound somewhat slim; nevertheless, the work on anthropomorphic robots still goes on, especially in Japan and from time to time in the United States and Europe.
The reasons behind the strong interest in robotics technology have little to do with Hollywood dreams. Producing a machine that can operate in a reasonably arbitrary environment will allow us to automate a wide span of tasks.
If some of us feel that we have more than enough automation already, this feeling is not necessarily due to our ambivalence about machines. It is hard to feel a need for something that does not exist. Think, for example, of such modern-day necessities as paper towels and paper napkins. Who would think of “needing” them back in the nineteenth century, before they became available?
To have a sense of what is the “right” amount of automation, consider the extent of automation in today's industrialized world, and then consider the kind of automation we may have if the right technology becomes available. Wouldn't we welcome it if our dishwashers knew how to collect dirty dishes from the table, drop the solid waste into the waste basket, slightly rinse the dishes under the faucet, put them into the dishwashing basin—and only then proceed to what today's dishwashers do—and later of course put the clean dishes and silverware where they belong? More seriously, wouldn't we embrace a machine capable of helping an old person prolong her independent living by assisting with simple household chores such as answering the doorbell, serving food, and bringing from the closet clothing to wear? How about a driverless security car patrolling the streets and passing along information to the police control room; automatic waste collection and mail delivery trucks; driverless tractors and crops picking machines in farms? There is no end to this list.
Then there are tasks in which human presence is not feasible or highly undesired, and for which no expense would be too big: demining of minefields in countries after war (there is no shortage of these in recent years); deep-sea oil exploration; automatic “repairmen” of satellites and planet exploration vehicles; and so on. For example, unlike the spectacular repairs of the Hubble Space Telescope by astronauts, no human help will be feasible to its one-million-miles-away replacement, the James Webb Space Telescope—only because the right robots do not exist today. Continuing our list in this fashion and safely assuming the related automation will be feasible at some point, observe that only a small fraction, perhaps 5% or so, of tasks that could and should be automated have been automated today. Robotics is the field we turn to when thinking about such missing automation. So, why don't we have it? What has been preventing this automation from becoming a reality?
It may sound surprising, but by and large the technology of today is already functionally ready for many of the applications mentioned above. After all, many factory automation machines have more complex actuators—which translates into an ability to generate complex motion—than some applications above require. They boast complex digital control schemes and complex software that guides their operation, among other things. There is no reason why the same or similar schemes could not be successful in designing, say, a robot helper for the homes of elderly individuals. So, why don't we have it? What is missing? The answer is, yes, something is missing, but often it is not sophistication and not functional abilities.
What is missing are two skills. One absolutely mandatory, is a local nature and is a seemingly trivial “secondary” ability in a machine not to bump into unexpected objects while performing its main task—be it walking toward a person in a room with people and furniture, helping someone to dress, replacing a book on the shelf, or “scuba-diving” in an undersea cave. Without this ability the robot is dangerous to the environment and the environment is dangerous to the robot—which for an engineer simply means that the robot cannot perform tasks that require this ability. We can call this ability collision avoidance in an uncertain environment.
The other skill, which we can call motion planning, or navigation, is of a global nature and refers to the robot ability to guarantee arrival at the destination. The importance of this skill may vary depending on a number of circumstances.
For humans and animals, passing successfully around a chair or a rock does not depend on whether the chair or the rock is in a position that we “agreed” upon before we started. The same should be true for a robot—but it is not.
Let us call the space in which the robot operates the robot workspace, or the robot environment. If all objects present in the robot workspace could be described precisely, to the smallest detail, automating the necessary motion would present no principal difficulties. We would then be in the realm of what we call the paradigm of motion planning with complete information. Though, depending on details, the problem may require an inordinate computation time, this is a purely geometric problem, and the relevant software tools are already there. Algorithmic solutions for this problem started appearing in the late 1970s and were perfected in the following decades.
A right application for such a strategy is, for example, one where the motion has to be repeated over and over again in exactly the same workspace, precisely as it happens on the car assembly line or in a car body painting booth. Here complete information about all objects in the robot environment is collected beforehand and passed to the motion planning software. The computed motion is then tried and optimized via special software or/and via many trial-and-error improvements, and only then used. Operators daily make sure that nothing on the line changes; if it does purposely, the machine's software is updated accordingly. Advantages of this strategy are obvious: It delivers high accuracy and repeatability, consistent quality, with no coffee breaks. If the product changes, say, in the next model year, a similar “retraining” procedure is applied.
We will call tasks and environments where this approach is feasible structured tasks and structured environments, which signifies the fact that objects in the robot environment are fully known and predictable in space and time. Such environments are, as a rule, man-made.
An automotive assembly line is a perfect example of a structured environment: Its work cells are designed with great care, and usually at a great cost, so as to respect the design constraints of robots and other machinery. A robot in such a line always “knows” beforehand what to expect and when. Today the use of robotics on such lines is an extremely successful and cost-effective proposition, in spite of their high cost.
Unfortunately, some tasks—in fact, the great majority of tasks we face every day—differ in some fundamental ways from those on the automotive assembly line. We live in the world of uncertainty. We deal with unstructured tasks, tasks that take place in an unstructured environment. Because of unpredictable or changing nature of this environment, motions that are needed to do the job are not amenable to once-and-for-all calculation or to honing via direct iterative improvement. Although some robots in the structured automotive environment are of great complexity, and functionally could be of much use in unstructured tasks, their use in an unstructured environment is out of the question without profound changes in their design and abilities. Analyzing this fact and finding ways of dealing with it is the topic of this book.
Sometime in the late 1950s John McCarthy, from Stanford University [who is often cited as father of the field of artificial intelligence (AI)], was quoted as saying that if the AI researchers had as much funding as NASA was given at the time to put a man on the moon, then within 10 years robot taxi cabs would roam the streets of San Francisco. McCarthy continued talking about “automatic chauffeurs” until at least the late 1990s. Such loyalty to the topic should certainly pay off eventually because the automatic cab drivers will someday surely appear.
Today, over 40 years since the first pronouncement, we know that such a robot cannot be built yet—at any cost. This statement is far from trivial—so it is not surprising that many professional and nonprofessional optimists disagree with it. Not only it is hard to quantify the difficulties that prevent us from building such machines, but these difficulties have been consistently underestimated. As another example, in 1987, when preparing an editorial article for the special issue on robot motion planning for the IEEE Transactions on Robotics and Automation, this author was suggested to take off from the Foreword a small paragraph saying that in the next 10 years—that is, between 1987 and 1997—we should not expect a robot capable of, say, tying one's shoelaces or a necktie. The text went on to suggest that the main bottleneck had less to do with lacking finger kinematics and more with required continuous sensing and accompanying continuous sensor data processing. “This sounds too pessimistic; ten years is a long time; science and technology move fast these days,” the author was told. Today, almost two decades later, we still don't have robots of this level of sophistication—and not for a lack of trying or research funding. In fact, we can confidently move the arrival of such robots by at least another decade.
One way to avoid the issue is to say that a task should be “well engineered.” This is fine except that no task can be likely “well engineered” unless a technician has a physical access to it once or twice a day, as in any automotive assembly line. Go use this recipe with a robot designed to build a large telescope way out in deep space!
Is the situation equally bleak in other areas of robotics? Not at all. In recent years robotics has claimed many inroads in factory automation, including tasks that require motion planning. Robots in automotive industry are today among the most successful, most cost-effective, and most reliable machines. Robot motion planning algorithms have penetrated areas far from robotics, from designing quick-to-disassemble aircraft engines (for part replacement at the airport gate) to studies of folding mechanisms of DNA molecules.
It is the unstructured environment where our success stops. We have difficulty moving robots into our messy world with its unending uncertainty. That is where the situation is bleak indeed—and that is where robotics is needed badly.
The situation is not black and white but rather continuous. The closer a task is to that in a fully structured environment, the better the chance that today's approaches with complete information will apply to it. This is good news. When considering a robot mission to replace the batteries, gyroscopes, and some scientific instruments of the aging Hubble Space Telescope, NASA engineers were gratified to know that, with the telescope being a fully man-made creature, its repair presents an almost fully structured task. The word “almost” is not to be overlooked here—once in a while, things may not be exactly as planned: The robot may encounter an unscrewed or bent bolt, a broken cover, or a shifted cable. Unlike an automotive plant, where operators check out the setup once or twice a day, no such luxury would exist for the Hubble ground operators. Although, luckily, the amount of “unstructuredness” is small in the Hubble repair task, it calls for serious attention to sensing hardware and to its intimate relation to robot motion planning. Remarkably, even the “unstructuredness” that small led to the project's cancellation.
A one-dimensional picture showing the effect of increase in uncertainty on the task difficulty, as one moves from a fully structured environment to a fully unstructured environment, is shown in Figure 1.1. An automotive assembly line (the extreme left in the figure) is an example of a fully structured environment: Line operators make sure that nothing unexpected happens; today's motion planning strategies with complete information can be confidently used for tasks like robot welding or car body painting.
As explained above, the robot repair of the Hubble Telescope is slightly to the right of this extreme. Just about all information that the robot will need is known beforehand. But surprises—including some that may be hard to see from the ground—cannot be ruled out and must be built in the mission system design. In comparison with this task, designing a robot taxi driver carries much more uncertainty and hence more difficulty. Though the robot driver will have electronic maps of the city, and frequent remote updates of the map will help decrease the uncertainty due to construction sites or street accidents, there will still be a tremendous amount of uncertainty caused by less than ideally careful human car drivers, bicyclists, children running after balls, cats and dogs and squirrels crossing the road, potholes, slippery road, and so on. These will require millions of motion planning decisions done on the fly. Still, a great many objects that surround the robot are man-made and well known and can be preprocessed.

Figure 1.1 An increase in uncertainty, from a fully structured environment to a fully unstructured environment, spells an increase in difficulty when attempting to automate a task using robots.
Not so with mountain climbing—this task seems to present the extreme in unstructured environment. While the robot climber would know exactly where its goal is, its every step is unlike the step before, and every spike driven in the wall may be the last one—solely due to the lack of complete input information. A tremendous amount of sensing and appropriate intelligence would be needed to compensate for this uncertainty. While seemingly a world apart and certainly not as dangerous, the job of a robot nurse would carry no less uncertainty. Similar examples can be easily found for automating tasks in agriculture, undersea exploration, at a construction site on Earth or on the moon, in a kindergarten, and so on.1
In terms of Figure 1.1, this book can be seen as an attempt to push the envelope of what is possible in robotics further to the right along the uncertainty line. We will see, in particular, that the technology that we will consider allows the robot to operate at the extreme right in Figure 1.1 in one specific sense—it makes a robot safe to itself and to its environment under a very high level of uncertainty. Given the importance of this feature and the fact that practically all robots today operate at the line's extreme left, this is no small progress. Much, but certainly not everything, will also become possible for robot motion planning under uncertainty.
What kind of input information and what kind of reasoning do we humans use to plan our motion? Is this an easy or is it a difficult skill to formalize and pass along to robots? What is the role of sensing—seeing, touching, hearing—in this process? There must be some role for it—we know, for instance, that when a myopic person takes off his glasses, his movement becomes more tentative and careful. What is the role of dynamics, of our mass and speed and accelerations relative to the surrounding objects? Again, there must be some role for it—we slow down and plan a round cornering when approaching a street corner. Are we humans universally good in motion planning tasks, or are some tasks more difficult for us than others? How is it for robots? For human–robot teams?
Understanding the issues behind those questions took time, and not everything is clear today. For a long time, researchers thought that the difficulties with motion planning are solely about good algorithms. After all, if any not-so-smart animal can successfully move in the unstructured world, we got to be able to teach our robots to do the same. True, we use our eyes and ears and skin to sense the environment around us—but with today's technology, don't we have more than enough sensor gadgetry to do the job?
The purpose of this book is to identify those difficulties, see why they are so hard, attempt solutions, and try to identify directions that will lead us to conquering the general problem. A few points that will be at the center of our work should be noted. First, we will spend much effort designing motion planning algorithms. This being the area that humans deal with all the time, it is tempting to try to use human strategies. Unfortunately, as often happens with attempts for intelligent automation, asking humans how they do it is not a gratifying experience. Similar to some other tasks that humans do well (say, medical diagnostics), we humans cannot explain well how we do it. Why did I decide to walk around a table this way and not some other way, and how did this decision fit into my plan to get to the door? I can hardly answer. This means that robot motion planning strategies will not likely come from learning and analysis of human strategies. The other side of it is, as we will see, that often humans are not as good in motion planning as one may think.
Second, the above example with moving in the dark underlines the importance of sensing hardware. Strategies that humans and animals use to realize safe motion in an unstructured environment are intimately tied to the sensing machinery a species possesses. When coming from the outside into a dark room, your movement suddenly changes from brisk and confident to slow and hesitant. Your eyes are of no use now: Touching and listening are suddenly at the center of the motor control chain. Your whole posture and gait change. If audio sources disappear, your gait and behavior may change again. This points to a strong connection between motion planning algorithms and sensing hardware. The same has to be true for robots.
We will see that today's sensing technology is far from being adequate for the task in hand. In an unstructured environment, a trouble may come from any direction and affect any point of the robot body. Robot sensing thus has to be adequate to protect the robot's whole body. This calls for a special sensing hardware and specialized sensor data processing. One side effect of this circumstance is that algorithms and sensing hardware are to be addressed in the same book—which is not how a typical textbook in robotics is structured. Hence we hope that a reader knowledgeable in the theory of algorithms will be tolerant of the material on electronics, and we also hope that a reader comfortable with electronics will be willing to delve into algorithms.
Third, human and animals' motion planning is tied to the individual's kinematics. When bending to avoid hitting a low door opening, one invokes multiple sequences of commands to dozens of muscles and joints, all realized in a complex sequence that unfolds in real time. Someone with a different kinematics due to an impaired leg will negotiate the same door as skillfully though perhaps very differently. Expect the same in robots: Sensor-based motion planning algorithms will differ depending on the robot kinematics.
Aside from raising the level of robot functional sophistication, providing a robot with an ability to operate in an unstructured world amounts to a jump in its universality. This is not to say that a robot capable of moving dirty dishes from the table to a dishwasher will be as skillful in cutting dead limbs from trees. The higher universality applies only to the fact that the problem of handling uncertainty is quite generic in different applications. That is, different robots will likely use very similar mechanisms for collision avoidance. A robot that collects dishes from the table can use the same basic mechanism for collision avoidance as a robot that cuts dead limbs from trees.
As said above, we are not there yet with commercial machines of this kind. The last 40 years of robotics witnessed a slow and rather painful progress—much slower, for example, than the progress in computers. Things turned out to be much harder than many of us expected. Still, today's robots in automation-intensive industries are highly sophisticated. What is needed is supplying them with an ability to survive in an unstructured world. There are obvious examples showing what this can give. We would not doubt, for example, that, other issues aside, a robot can move a scalpel inside a patient's skull with more precision than a human surgeon, thus allowing a smaller hole in the skull compared to a conventional operation. But, an operating room is a highly unstructured environment. To be useful rather than to be a nuisance or a danger, the robot has to be “environment-hardened.”
There is another interesting side to robot motion planning. Some intriguing examples suggest that it is not always true that robots are worse than people in space reasoning and motion planning. Observations show that human operators whose task is to plan and control complex motion—for example, guide the Space Shuttle arm manipulator—make mistakes that translate into costly repairs. Attempts to avoid such mistakes lead to a very slow, for some tasks unacceptably slow, operation. Difficulties grow when three-dimensional motion and whole-body collision avoidance are required. Operators are confused with simultaneous choices—say, taking care of the arm's end effector motion while avoiding collision at the arm's elbow. Or, when moving a complex-shaped body in a crowded space, especially if facing simultaneous potential collisions at different points of the body, operators miss good options. It is known that losing a sense of direction is detrimental to humans; for example, during deep dives the so-called Diver's Anxiety Syndrome interferes with the ability of professional divers to distinguish up from down, leading to psychological stress and loss in performance.
Furthermore, training helps little: As discussed in much detail in Chapter 7, humans are not particularly good in learning complex spatial reasoning tasks. These problems, which tend to be explained away as artifacts of poor teleoperation system design or insufficient training or inadequate input information, can now be traced to the human's inherent relatively poor ability for spatial reasoning.
We will learn in Chapter 7 that in some tasks that involve space reasoning, robots can think better than humans. Note the emphasis: We are not saying that robots can think faster or compute more accurately or memorize more data than humans—we are saying that robots can think better under the same conditions.
This suggests a good potential for a synergism: In tasks that require extensive spatial reasoning and where human and robot thinking/planning abilities are complementary, human–robot teams may be more successful than each of them separately and more successful than today's typical master–slave human–robot teleoperation systems are. When contributing skills that the other partner lacks, each partner in the team will fully rely on the other. For example, a surgeon may pass to a robot the subtask of inserting the cutting instrument and bringing it to a specific location in the brain.
There are a number of generic tasks that require motion planning. Here we are interested in a class of tasks that is perhaps the most common for people and animals, as well as for robots: One is simply requested to go from location A to location B, typically in an environment filled with obstacles. Positions A and B can be points in space, as in mobile robot applications, or, in the case of robot manipulators, they may include positions of every limb.
Limiting our attention to the go-from-A-to-B task leaves out a number of other motion planning problems—for example, terrain coverage, map-making, lawn mowing [1]; manipulation of objects, such as using the fingers of one's hand to turn a page or to move a fork between fingers; so-called power grips, as when holding an apple in one's hand; tasks that require a compressed representation of space, such as constructing a Voronoi diagram of a given terrain [2]; and so on. These are more specialized though by no means less interesting problems.
The above division of approaches to the go-from-A-to-B problem into two complementary groups—(1) motion planning with complete information and (2) motion planning with incomplete information—is tied in a one-to-one fashion to still another classification, along the scientific tools in the foundation of those approaches. Namely, strategies for motion planning with complete information rely exclusively on geometric tools, whereas strategies for motion planning with incomplete information rely exclusively on topological tools. Without going into details, let us summarize both briefly.
1. Geometric Approaches. These rely, first, on geometric properties of space and, second, on complete knowledge about the robot itself and obstacles in the robot workspace. All those objects are first represented in some kind of database, typically each object presented by the set of its simpler components, such as a number of edges and sides in a polyhedral object. According to this approach, then, passing around a hexagonal table is easier than passing around an octagonal table, and much easier than passing around a curved table, because of these three the curved table's description is the most complex.
Then there is an issue of information completeness. We can hear sometimes, “I can do it with my eyes shut.” Note that this feat is possible only if the objects involved are fully known beforehand and the task in hand has been tried many times. A factory assembly line or the list of disassembly of an aircraft engine are examples of such structured tasks. Objects can be represented fully only if they allow a final size (practical) description. If an object is an arbitrary rock, then only its finite approximation will do—which not only introduces an error, but is in itself a nontrivial computational task.
If the task warrants a geometric approach to motion planning, this will likely offer distinctive advantages. One big advantage is that since everything is known, one should be able to execute the task in an optimal way. Also, while an increased dimensionality raises computational difficulties—say, when going from two-dimensional to three-dimensional space or increasing the robot or its workspace complexity—in principle the solution is still feasible using the same motion planning algorithm.
On the negative side, realizing a geometric approach typically carries a high, not rarely unrealistic, computational cost. Since we don't know beforehand what information is important and what is not for motion planning, everything should be in. As we humans never ask for “complete knowledge” when moving around, it is not obvious how big that knowledge can be even in simple cases. For example, to move in a room, the database will have to include literally every nut and bolt in the room walls, every screw holding a seat in every chair in the room, small indentations and extensions on the robot surface etc. Usually this comes to a staggering amount of information. The number of those details becomes a measure of complexity of the task in hand.
Attempts have been made to connect geometric approaches with incomplete sources of information, such as sensing. The inherent need of this class of approaches in a full representation of geometric data results in somewhat artificial constructs (such as “continuous” or “X-ray” or “seeing-through” sensors) and often leads to specialized and hard-to-ascertain heuristics (see some such ideas in Ref. 3).
With even the most economical computational procedures in this class, many tasks of practical interest remain beyond the reach of today's fastest computers. Then the only way to keep the problem manageable is to sacrifice the guarantee of solution. One can, for example, reduce the computational effort by approximating original objects with “artificial” objects of lower complexity. Or one can try to use some beforehand knowledge to prune nonpromising path options on the connectivity graph. Or one can attempt a random or pseudorandom search, checking only a fraction of the connectivity graph edges. Such simplification schemes leave little room for directed decision-making or for human intuition. If it works, it works. Otherwise, a path that has been left out in an attempt to simplify the problem may have been the only feasible path. The ever-increasing power of today's computer make manageable more and more applications where having complete information is feasible.
The properties of geometric approaches can be summarized as follows (see also Section 2.8):
(a) They are applicable primarily to situations where complete information about the task is available.
(b) They rely on geometric properties (dimensions and shapes) of objects.
(c) They can, in principle, deliver the best (optimal) solution.
(d) They can, in principle, handle tasks of arbitrary dimensionality.
(e) They are exceedingly complex computationally in more or less complex practical tasks.
2. Topological Approaches. Humans and animals rarely face situations where one can approach the motion planning problem based on complete information about the scene. Our world is messy: It includes shapeless hard-to-describe objects, previously unseen settings, and continuously changing scenes. Even if faced with a “geometric”-looking problem, say, finding a path from point A to point B in a room with 10 octagonal tables, we would never think of computing first the whole path. We take a look at the room, and off we go. We are tuned to dealing with partial information coming from our sensors. If we want our robots to handle unstructured tasks, they will be thrown in a similar situation.
In a number of ways, topological approaches are an exact opposite of the geometrical approaches. What is difficult for one will be likely easy for the other.
Consider the above example of finding a path from point A to point B in a room with a few tables. The tables may be of the same or of differing shapes; we do not know their number, dimensions, and locations. A common human strategy may look something like this: While at A, you glance at the room layout in the direction of point B and start walking toward it. If a table appears on your way, you walk around it and continue toward point B. The words “walking around” mean that during this operation the table is on the same side from you (say, on the left). The table's shape is of no importance: While your path may repeat the table's shape, “algorithmically” it is immaterial for your walk around it whether the table is circular or rectangular or altogether highly nonconvex. Why does this strategy represent a topological, rather than geometric, approach? Because it relies implicitly on the topological properties of the table—for example, the fact that the table's boundary is a simple closed curve—rather than on its geometric properties, such as the table's dimensions and geometry.
We will see in Chapter 3 that the aforementioned rather simplistic strategy is not that bad—especially given how little information about the scene it requires and how elegantly simple is the connection between sensing and decision-making. We will see that with a few details added, this strategy can guarantee success in an arbitrarily complex scene; using this strategy, the robot will find a path if one exists, or will conclude “there is no path” if such is the case.
On the negative side, since no full information is available in this process, no optimality of the resulting path can be guaranteed. Another minus, as we will see, is that generalizations of such strategies to arm manipulators are dependent on the robot kinematics. Let us summarize the properties of topological approaches to motion planning:
(a) They are suited to unstructured tasks, where information about the robot surroundings appears in time, usually from sensors, and is never complete.
(b) They rely on topological, rather than geometrical, properties of space.
(c) They cannot in principle deliver an optimal solution.
(d) They cannot in principle handle tasks of arbitrary dimensionality, and they require specialized algorithms for each type of robot kinematics.
(e) They are usually simple computationally: If a technique is applicable to the problem in hand, it will likely be computationally easy.
1.2 BASIC CONCEPTS
This section summarizes terminology, definitions, and basic concepts that are common to the field of robotics. While some of these are outside of this book's scope, they do relate to it in one way or another, and knowing this relation is useful. In the next chapter this material will be used to expand on common technical issues in robotics.
1.2.1 Robot? What Robot?
Defining what a robot is is not an easy job. As mentioned above, not only scientists and engineers have labored here, but also Hollywood and fiction writers and professionals in humanities have helped much in diffusing the concept. While this fact will not stand in our way when dealing with our topic, starting with a decent definition is an old tradition, so let us try.
There exist numerous definitions of a robot. Webster's Dictionary defines it as follows:
A robot is an automatic apparatus or device that performs functions ordinarily ascribed to humans, or operates with what appears to be almost human intelligence.
Half of the definition by Encyclopaedia Britannica is devoted to stressing that a robot does not have to look like a human:
Robot: Any automatically operated machine that replaces human effort, though it may not resemble human beings in appearance or perform functions in a humanlike manner.
These definitions are a bit vague, and they are a bit presumptuous as to what is and is not “almost human intelligence” or “a humanlike manner.” One senses that a chess-playing machine may likely qualify, but a machine that automatically digs a trench in the street may not. As if the latter does not require a serious intelligence. (By the way, we do already have champion-level chess-playing machines, but are still far from having an automatic trench-digging machine.) And what about a laundry washing machine? This function has been certainly “ordinarily ascribed to humans” for centuries. The emphatic “automatic” is also bothersome: Isn't what is usually called an operator-guided teleoperation robot system a robot in spite of not being fully automatic?
The Robotics Institute of America adds some engineering jargon and emphasizes the robot's ability to shift from one task to another:
A robot is a reprogrammable multifunctional manipulator designed to move material, parts, tools, or specialized devices through variable programmed motions for the performance of a variety of tasks.
Somehow this definition also leaves a sense of dissatisfaction. Insisting solely on “manipulators” is probably an omission: Who doubts that mobile vehicles like Mars rovers are robots? But “multifunctional”? Can't a robot be designed solely for welding of automobile parts? And then, is it good that the definition easily qualifies our familiar home dishwasher as a robot? It “moves material” “through variable programmed motions,” and the user reprograms it when choosing an appropriate cycle.
These and other definitions of a robot point to dangers that the business of definitions entails: Appealing definition candidates will likely invite undesired corollaries.
In desperation, some robotics professionals have embraced the following definition:
I don't know what a robot is but will recognize it when I see one.
This one is certainly crisp and stops further discussion, but it suffers from the lack of specificity. (Try, for example, to replace “robot” by “grizzly bear”—it works.)
A good definition tends to avoid explicitly citing material components necessary to make the device work. That should be implicit and should leave enough room for innovation within the defined function. Implicit in the definitions above is that a robot must include mechanics (body and motors) and a computing device. Combining mechanics and computing helps distinguish a robot from a computer: Both carry out large amounts of calculations, but a computer has information at its input and information at its output, whereas a robot has information at its input and motion at its output.
Explicitly or implicitly, it is clear that sensing should be added as the third necessary component. Here one may want to distinguish external sensing that the machine uses to acquire information about the surrounding world (say, vision, touch, proximity sensing, force sensing) from internal sensing used to acquire information about the machine's own well-being (temperature sensors, pressure sensors, etc.). This addition would help disqualify automobiles and dishwashers as robots (though even that is not entirely foolproof).
Perhaps more ominously, adding “external” sensing as a necessary component may cause devastation in the ranks of robots. If the robot uses sensing to obtain information about its surroundings, it would be logical to suggest that it must be using it to react to changes in the surrounding world. The trouble is that this innocent logic disqualifies a good 95–98% of today's robots as robots, for the simple reason that all those robots are designed to work in a highly structured environment of a factory floor, which assumes no unpredictable changes.
With an eye on the primary subject of this book—robots capable of handling tasks in an unstructured environment—we accept that reacting to sensing data is essential for a robot's being a robot. The definition of a robot accepted in this text is as follows:
A robot is an automatic or semiautomatic machine capable of purposeful motion in response to its surroundings in an unstructured environment.
Added in parentheses or seen as unavoidably tied to the defined ability is a clause that a robot must include mechanical, computing, and sensing components.
While this definition disqualifies many of today's robots as robots, it satisfies what for centuries people intuitively meant by robots—which is not a bad thing. Purists may still point to the vagueness of some concepts, like “purposeful” (intelligent) and “unstructured.” This is true of all other attempts above and of human definitions in general. Be it as it may, for the purpose of this book this is a working definition, and we will leave it at that.
1.2.2 Space. Objects
A robot operates in its environment (workspace, work cell). The real-world robot environment appears either in two-dimensional space (2D), as, for example, with a mobile robot moving on the hospital floor, or in three-dimensional space (3D), as with an arm manipulator doing car body painting.
Robot workspace is physical continuous space. Depending on approaches to motion planning, one can model the robot workspace as continuous or discrete. Robotics deals with moving or still objects. Each object may be
- A point—for example, an abstract robot automaton used for algorithm development
- A rigid body—for example, boxes in a warehouse, autonomous vehicles, arm links
- A hinged body made of rigid bodies—for example, a robot arm manipulator
The robot environment may includes obstacles. Obstacles are objects; depending on the model used and space dimensionality, obstacles can be
- Points
- Polygonal (polyhedral) objects, which can be rigid or hinged bodies
- Other analytically described objects
- Arbitrarily shaped (physically realizable) objects
1.2.3 Input Information. Sensing
Similar to humans and animals, robots need input information in order to plan their motion. As discussed above, there may be two situations: (a) Complete information about all objects in the robot environment is available. (b) There is uncertainty involved; then the input information is, by definition, incomplete and is likely obtained in real time from robot's sensors.
Note the algorithmic consequences of this distinction. If complete information about the workspace is available, a reasonable method to proceed is to build a model of the robot and its workspace and use this model for motion planning. The significant effort that is likely needed to build the model will be fully justified by the path computed from this model. If, however, nothing or little is known beforehand, it makes little sense to spend an effort on building a model that is of doubtful relevance to reality.
In the above situation (b), the robot hence needs to “think” differently. From its limited sensing data, it may be able to infer some topological properties of space. It may be able to infer, for example, whether what it sees from its current position as two objects are actually parts of the same object. If the conclusion is “yes,” the robot will not be trying to pass between these two “objects.” If the conclusion is “no,” the robot will know that it deals with separate objects and may choose to pass between them. The objects’ actual shapes will be of little concern to the robot.
What type of sensing is suitable for a competent motion planning? It turns out that just about any sensing is fine: tactile, sonar, vision, laser ranger, infrared proximity, and so on. We will learn a remarkable result that says that even the simplest tactile sensing, when used with proper motion planning algorithms, can guarantee that the robot will reach its target (provided that the target is reachable). In fact, we will consistently prefer tactile sensing when developing algorithms, before attempting to use some richer sensing media; this will allow us to clarify the issues involved. This is not to say that one should prefer tactile sensors in real tasks: As a blind person will likely produce a more circuitous route than a person with vision, the same will be true for a robot.
Being serious about collision avoidance means that robot motion planning algorithms must protect the whole robot body, every one of its points. Accordingly, robot sensors must provide sufficient input information. Intuitively, this requirement is not hard to understand for mobile robots. Existing mobile robots typically have a camera or a range finder that rotates as needed, or sonar sensors that cover the whole robot's circumference.
Intuition is less helpful when talking about arm manipulators. Again, sensors can be of any type: tactile, proximal, vision, and so on. What is harder to grasp but is absolutely necessary is a guarantee that the arm has sensing data regarding all points of its body. No blind spots are allowed.
We tend not to notice how strictly this requirement is followed in humans and animals. We often tie our ability to move around solely with our vision. True, when I walk, my vision is typically the sole source of input information. I may not be aware of, and not interested in, objects on my sides or behind me. If something worthwhile appears on the sides, I can turn my head and look there.
However, if I attempt to sit down and the seat will happen to have a nail sticking out of it, I will be quickly made aware of this fact and will plan my ensuing motions quickly and efficiently. If a small rock finds its way into my shoe, I will react equally efficiently. The sensor that I use in these cases is not vision, but is the great many tactile sensors that cover my whole skin. Vision alone would never be able to become a whole-body sensor.
Think of this: If among millions and millions of spots inside and outside of our bodies at least one point would not be “protected” by sensing, in our unstructured messy world sooner or later that very point would be assaulted by some hostile object. Evolution has worked hard on making sure that such situations do not occur. Those of our forbears millions of years ago who did not have a whole-body sensing have no offspring among us.
The fact that losing some type of sensing is a heavy blow to one's lifestyle is a witness to how important all our sensing systems are. Blind people have to make special precautions and go through special training to be able to lead a productive life. People suffering from diabetes may incur a loss of tactile facilities, and then they are warned by their doctors to be extra careful when handling objects: A small cut may become a life-threatening wound if one's sensors sound no alarm.
People tend to think that vision is more essential for one's survival than tactile sensing. Surprisingly, the reality is the other way around. While many blind people around us have productive lives, the human ability to function decreases much more dramatically if their tactile system is seriously damaged. This has been shown experimentally [4]. Today's knowledge suggests that a person losing his or her tactile facilities completely will not be able to survive, period.
Animals are similarly vulnerable. Some are able to overcome the deficit, but only at a high cost. If a cat loses its tactile sensing (say, if the nerve channel that brings tactile information to the brain is severed), the cat can relearn some operational skills, but its locomotion, gait, behavior, and interaction with the surrounding world will change dramatically [5].2
One can speculate that the reason for a higher importance of tactile sensing over vision for one's survival is that tactile sensing tends to have no “blind spots” whereas vision does by definition have blind spots. Vision improves the efficiency of one's interaction with the environment; tactile sensing is important for one's very survival. In other words, our requirement of a whole-body robot sensing is much in line with live nature.
Similarly, it is not uncommon to hear that for robot arm manipulators “vision should be enough.” Vision is not enough. Sooner or later, some object occluded from the arm's cameras by its own links or by power cables will succeed in coming through, and a painful collision will occur. Whole-body sensing will prevent this from happening. This suggests that our robots need a sensitive skin similar to human skin, densely populated with many sensors.
Whether those sensors are tactile or proximal, like infrared sensors, is a matter of efficiency, not survival. Be it as it may, motion planning algorithms developed for simpler sensing can then be expanded to more sophisticated sensing. This point is worth repeating, because misunderstanding is not uncommon:
When we develop our motion planning algorithms based on tactile sensing, this does not mean we suggest tactile sensing as a preferable sensing media, nor does it mean that the algorithms are applicable solely to tactile sensing. As we will see, expanding algorithms to more complex sensing is usually relatively easy, and usually results in higher efficiency.
1.2.4 Degrees of Freedom. Coordinate Systems
It is known from mechanics that depending on space dimensionality and object complexity, there is a minimum number of independent variables one needs to define the object's position and orientation in a unique way. These variables are called the object's degrees of freedom (DOF). The reference (coordinate) system expressed in terms of object's DOF is called the configuration space (C-space). C-space is hence a special representation of the robot workspace (W-space). From a textbook on mechanics, the minimum number of DOF that a rigid body needs for an arbitrary motion is
| In 2D, if only translation is allowed: | 2 |
| In 2D, translation plus orientation allowed: | 3 |
| In 3D, if only translation is allowed: | 3 |
| In 3D, translation plus orientation allowed: | 6 |
For example, for a planar (2D) case with a rigid object free to translate and rotate, the object is defined by three DOF (x, y, θ): two Cartesian coordinates (x, y) that define the object's position, plus its orientation angle θ.
A robot arm manipulator's DOF also determine its ability to move around. Specific values of all robot's DOF signify the specific arm configuration of its links and joints. Shown in Figure 1.2a is a revolute planar (2D) arm with two links. Its two DOF, two rotation angles, allow an arbitrary position of its endpoint in the robot workspace, but not an arbitrary orientation. The 3-link 3-DOF planar arm manipulator shown in Figure 1.2b can provide an arbitrary position and an arbitrary orientation at its endpoint.
The DOF that a robot arm possesses are usually realized via independent control means, such as actuators (motors), located in the arm's joints. Joints connect together the arm's links. Links and joints can be designed in different configurations: The most common are the sequential linkage, which is similar to the kinematics of a human arm, like in Figure 1.2, and the parallel linkage, where links form a parallel structure. The latter is used in some spatial applications, such as a universal positioner for various platforms. We will be interested in only sequential linkages.
The most popular types of joints are revolute joints, where one link rotates relative to the other (like in the human elbow joint), and sliding joints (also called prismatic joints), where one link slides relative to the other. The arm shown in Figure 1.2a has two revolute joints, of which the first joint is located in the arm's fixed base. The freely moving distal link or links on a typical arm manipulator is called the end effector. The end effector can carry a tool for doing the robot's job; this can be some kind of a gripper, a screwdriver, a paint or welding gun, and so on. The arm end effector may have its own DOF.
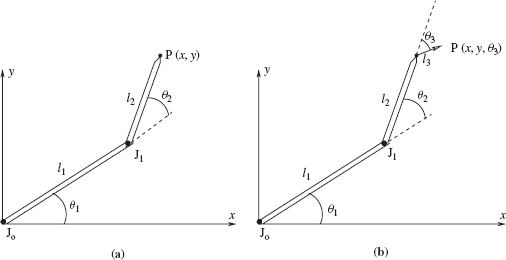
Figure 1.2 (a) A simple planar arm manipulator with two links (l1, l2), and two revolute joints (J0, J1). The robot base coincides with joint J0 and is fixed in 2D space. This 2 DOF manipulator can bring its end effector to any point P(x, y) within its workspace; the end effector's orientation at each such point will then be defined by the orientation of link l2. (b) Same arm with added third revolute link (hand), l3; now the end effector can be put in any arbitrary position of workspace with arbitrary orientation, P(x, y, θ3).
To use tools, the end effector needs to be put not only in a particular position but also at a particular orientation: For example, not only the screwdriver's blade has to be in the screw's slot, but its axis has to be perpendicular to the surface into which a screw is driven. In the human arm, it is of course the hand that handles the tool orientation, a relatively compact device, compared with the rest of the arm, with its own (many) DOF.
A similar organization of kinematics is common to robot arm manipulators: The robot's DOF are divided into the major linkage, relatively long links whose function is to bring the end effector to the vicinity of the job to be done, and the more compact minor linkage (called the wrist or hand), which is the end effector proper. Although from the theoretical standpoint such division is not necessary, it is useful from the design considerations. Often a real arm's major linkage consists of three DOF, and its minor linkage presents a 3-DOF hand.
The values of all robot arm DOF define its coordinates in physical space. A given position plus orientation can be described via two coordinate (reference) systems: Cartesian coordinates and joint (joint space) coordinates. The latter are also called configuration space coordinates. As long as both systems describe the robot configuration—that is, position plus orientation—in a unique way, they are equivalent. For the 3-link 3-DOF arm manipulator shown in Figure 1.2b, its Cartesian coordinates are (x, y, θ3), and its configuration space coordinates are (θ1, θ2, θ3).
Typically, the user is interested in defining the robot's paths in terms of Cartesian coordinates. Robot's motors are controlled, however, in terms of joint values (that is, configuration space coordinates). Hence a standard task in robot motion planning and control is translation from one reference system to the other. This process gives rise to two problems: (a) direct kinematics—given joint values, find the corresponding Cartesian coordinates—and (b) inverse kinematics—given the robot's Cartesian coordinates, find the corresponding joint values. As we will see in the next chapter, calculation of inverse kinematics is usually significantly more difficult than the calculation of direct kinematics.
1.2.5 Motion Control
The robot's path is a curve that the robot's end effector (or possibly its some other part) moves along in the robot workspace. To be physically realizable, each point of the path must be associated with the joint values that fully describe the robot position and orientation in the respective configuration. The term trajectory is used sometimes to designate a path geometry plus timing, velocity, and acceleration information along the path.3
As used in robotics, the term motion control or motion control system refers to the lower-level control functions, such as algorithmic and electronic and mechanical means that direct individual motors, as opposed to motion planning, which signifies the upper-level control—that is, control that requires some intelligence. This is not to say that motion control is a simple matter—robot controllers are often quite sophisticated. The control means are used to realize a given path or trajectory with required fidelity. While control means are beyond the scope of this book, for completeness we will review them briefly in the next chapter.
Depending on the number of DOF available for motion planning, we distinguish between three types of systems:
- Holonomic Systems. These have enough DOF for an arbitrary motion. The minimum number of those is equal to the dimensionality of the corresponding C-space: For example, 6 is the minimum number of DOF a 3D arm manipulator needs to realize an arbitrary motion in space without obstacles.
- Nonholonomic Systems. These are systems with constraints on their motion. For example, a car is a nonholonomic system: with its 2-DOF control—forward motion and steering—it cannot execute a lateral motion; this creates a well-known difficulty in parallel car parking. Note that a car's C-space is 3D, with its axes being two position variables (x, y) plus the orientation angle.
- Redundant Systems. Those with the number of DOF well above the minimum necessary for holonomic motion. Humans, animals, and some complex robots present redundant systems.
A serious analysis of holonomic and nonholonomic systems requires more rigorous mathematical definitions. These will be introduced later as needed.
1.2.6 Robot Programming
A robot executes a given motion because it is programmed to do so. The meaning of the words robot motion programming is not dissimilar to what an adult does when teaching a child how to walk.
One can distinguish between two basic approaches to robot motion programming:
- Explicit robot motion programming—when every robot configuration along the path is prescribed explicitly. One variation of this is when a set of configurations is given explicitly beforehand, and the robot interpolates configurations between the set points using some rule.
- Task-level robot motion programming—in which contents-based subtasks are given, such as “Grasp a part” or “Insert a peg in a hole,” and the robot figures out further details on its own.
The “subtask” above can be a complex motion or procedure that has been programmed separately beforehand. For example, details of the task “Grasp a part” may differ from one task instantiation to the other, depending on the sensing data. Clearly, task-level programming is, in general, preferable to explicit programming. It is also significantly more difficult to realize because it requires much beforehand knowledge on the part of the robot.
The “programming” of a dancer or a gymnast is clearly closer to the task-level approach than to the explicit programming. The choreographer can, for example, say to the ballerina, “Here you do a pirouette followed by an arabesque.” A pirouette is a rather complex combination of little motions that the ballerina learned while at school. The motions have been “programmed” into her, so just naming it is sufficient for her to know what to do. The same is so for an arabesque. On the other hand, this does not mean the pirouette will be exactly the same at all times: For instance, the ballerina may slightly deviate from her usual pirouette when seeing another dancer backing up toward her.
Another classification of robot motion programming is given by different types of robot teaching systems. A robot teaching system is a specific technique for robot programming. The following list applies primarily to robot arm manipulators; the corresponding analogues for mobile robots are simpler and present a subset of this list:
- Manually guiding a robot through the path in real time
- Point-to-point guidance, with an automatic generation of the time pattern
- Teach pendant
- Off-line programming, procedural languages
- Automatic programming using the task database
In manual guidance systems, a specially trained technician grabs the end tool of the robot and performs the actual operation by moving it along the required motion. The system automatically records all robot configurations along the path, which can then be reproduced faithfully. The arm may be specially mechanically balanced for easier motion, or be even completely replaced by a mockup arm that includes all electronic means to document the motion in system's memory. This is similar to the situation when the choreographer physically moves a dancer's arm through the air, “That's how you do it.” For example, in preparation for a robot painting of a car body, an experienced human painter moves the arm with the attached painting gun through the necessary motion, actually painting a car body; the recorded motion is then used to paint a batch of car bodies.
While looking attractively simple, manual guidance systems are hard to realize. For example, during actual job execution the robot must produce a perfectly painted surface after a single motion, whereas a human painter can usually use his powerful visual feedback to detect mistakes along the way and then touch the paint here and there if needed. Various techniques have been designed to mathematically “massage” the technician-taught motion to perfection—for example, to assure the path curve smoothness or the robot end effector uniform speed.
The point-to-point teaching is a variation of the previous technique that disposes with the real-time teaching. Here the human “teacher” brings the robot end tool into the right position, pushes a button to save the corresponding robot configuration in the robot memory, and goes to the next point, and so on, until a set of points representing the whole path is accumulated. The set must then be “massaged” in the above fashion, which is more difficult than in a manual guidance system because the teaching session was removed from the real-time operation and hence likely misses some important dynamic characteristics.
The teach pendant is a hardware accessory for point-to-point teaching. The pendant is a small box connected with the robot by a cable, with a variety of buttons for the operator to generate robot configurations. By intermittently giving increments in robot joint values—or alternatively, in Cartesian positions and orientations of the robot tool—the operator brings the end effector to the desired position, pushes a button to save it, and goes to the next position. This is a tedious process: A reasonably complex path—say, painting a car engine compartment—may require 150–200 or more points, each requiring 40–60 button pushes to produce it. The resulting path will likely need a considerable preprocessing by a special software before being ready for actual use. Most of today's industrial robot programming systems are of this kind.
The off-line programming method is a logical and rather dramatic departure from the techniques above, in that it tries to address their shortcomings by delegating the whole robot programming work to software. After all, each robot configuration along the path is a function of the required path, which is in turn a function of the task to which the motion applies. This motion can in principle be coded in some specialized programming language, the way we write computer programs. Hundreds of robot programming languages have been developed in the last three decades. For a while, some of them became “widely known in narrow circles” of robotics engineers; today almost none of them are remembered. Why so, especially given the remarkable success of computer programming languages?
The main reason for this is, one might say, a linguistic inadequacy of such languages to the problem of describing a motion. The product of a human oral or written speech, or of a computer programming language, is a linear, one-dimensional, discreet set of signals—sounds if spoken and symbols if written. A motion, on the other hand, happens in two- or three-dimensional space and is a continuous phenomenon. It is very difficult to describe in words, or in terms of a computer program, a reasonably complex two- or three-dimensional curve (unless it has a mathematical representation). Try to show your friend a motion—say, try to wave your hand goodbye. Then ask your friend to repeat this motion; he will likely do it quite close to your original motion. Now try to describe this same motion on paper with words. Take your time. Once ready, give your description to another friend, who did not see your motion, and ask him to reproduce the motion from this description. (Writing “Please wave your hand goodbye” is, of course, not allowed). The result will likely be far from the original.
This is undoubtedly the reason why we will never know how people danced in ancient Egypt and Greece and Rome, and even in Europe at the end of the XIX century, until the appearance of moving motion cameras. Unlike the millennia-old alphabets for recording human speech, alphabets for describing motion have been slow to come. Labanotation, the first system for recording an arbitrary (but only human) motion, appeared only in the mid-1920s and is rather clumsy and far from perfect.
The automatic programming technique is a further development in robot teaching techniques, and it is even further removed from using real motion in teaching. Take an example of painting the car engine compartment for a given car model. The argument goes as follows. By the time the robot painting operation is being designed, complete description of the car body is usually in a special database, as a result of the prior design process. Using this database and the painting system parameters (such as dimensions of the paint spray), a special software package can develop a path for the painting gun, and hence for the robot that holds the gun, such that playing that path would result in a complete and uniform paint coverage of the engine compartment. There is no need to involve humans in the actual motion teaching. Only a sufficiently sophisticated manufacturing environment can benefit from this system: Even with the right robot, one will have hard time producing a database necessary to paint one's backyard fence.
While showing an increasing sophistication from the first to the last robot teaching techniques above, from manual guidance to automatic programming of robot motion, each of these techniques has its advantages and its shortcomings. For example, no other techniques can match the ingenious teaching-by-showing ability of the first, manual guidance, method. This has led some researchers to attempt combination techniques from the list above. For example, first a vision system would record the human manually guided motion, and then a special software would try to reproduce it. In conclusion, in spite of a long history (in relative terms of the robotics field), the robot teaching methods can still be said to be in their infancy.
The data “massaging” techniques mentioned above are widely used in manufacturing robot systems. These include, for example,
- Path smoothing
- Straight line interpolation
- Achieving a uniform velocity path
- Manipulating velocity/acceleration profiles along the path
Path smoothing is usually done to improve the system performance. Smoothing the first and second derivatives of the robot path will help avoid jerky motion and sharp turns.
Straight-line interpolation is something different. Many applications—for example, welding two straight line beams along their length—require a straight-line path. Arms with revolute joints, such as in Figure 1.2, tend to move along curved path segments, so approximating a straight-line path takes special care. This is a tedious job, and we will consider it further in the next chapter. The human arm has a similar problem, though we often are not aware of this: Humans are not good in producing straight lines, even with the powerful feedback control help of one's vision.
A uniform velocity path may be needed for various purposes. For a quality weld in continuous welding, the robot has to move the gun with the uniform speed. In the example above with the painting robot, a nonuniform velocity of the painting gun will produce streaks of thinner and thicker paint on the surface that is being painted. Furthermore, note that the meaning of “uniform velocity” in this example must refer not to the velocity at the painting gun endpoint, but to the velocity at an imaginary point in space where paint meets the painted surface. That is the gun aiming point (say, 20 cm away from the gun's endpoint) that has to move with the uniform velocity. This may coincide with the gun endpoint moving sometimes faster and sometimes slower, and sometimes even stopping, with the gun rotating in space.
Manipulating velocity/acceleration profiles presents an extension of the velocity control. Some tasks may require control of the robot linear or angular acceleration—for example, to ascertain a certain pattern of starting and finishing a motion. A good robot system will likely include software that allows creating various profiles of robot velocity and acceleration.
1.2.7 Motion Planning
Motion planning is the single unique defining core of the field of robotics—same as computation is the single unique defining core of the field of computers. Many components and disciplines contribute to producing a good robot—the same is true for a good computer—but it is motion planning that makes a robot a robot.
There are different criteria of quality of robot paths. We may want the robot to do one or more of these:
- Execute a predefined path.
- Find an optimal path (the shortest, or fastest, or one requiring a minimum energy, etc.).
- Plan a “reasonable” path.
- Plan a path that respects some constraints—say, a path that would not make the robot bang into the walls of an automotive painting booth.
Robots in the factory environment tend to follow predefined paths, sometimes with deviations allowed by their programs. Robot car painting operation is a good example. Such tasks often put a premium on path optimization: After all, in a mass production environment, shaving 1–2 sec out of a 50-sec cycle can translate into large savings. On the other hand, for a robot operating in an environment with uncertainty, optimality is ruled out and more often than not is of little concern anyway. For instance, a mobile robot that is used for food and drug delivery in a hospital is expected to go along more or less reasonable, not necessarily optimal, paths. Either of these systems can also be subject to additional constraints: For example, an arm manipulator may need to work in a narrow space between two walls.
1The last example brings in still another important dimension: The allowed uncertainty depends much on what is at stake.
2To be sure, nature has developed means to substitute for an incomplete sensing system. A turtle's shell makes tactile sensing at its back unnecessary. Such examples are rare, and they look more like exceptions confirming the rule.
3In some books, and also here, terms “trajectory” and “path” are used interchangeably.
Sensing, Intelligence, Motion, by Vladimir J. Lumelsky
Copyright © 2006 John Wiley & Sons, Inc.