
Chapter 6. Pointers and References
Reasonably direct access to memory is one of C’s biggest features for folks who work on low-level problems like device drivers or embedded systems. C gives you the tools to micromanage your bytes. That can be a real boon when you need to worry about every bit of free memory, but it can also be a real pain to worry about every bit of memory you use. When you want that control, though, it’s great to have the option. This chapter covers the basics of finding out where things are located in memory (their address) as well as storing and using those locations with pointers, variables that store the address of other variables.
Addresses in C
We’ve touched on the notion of pointers when we discussed using
scanf() to read in base types like integers and floats versus reading in
a string as a character array. You may recall for numbers, I mentioned the
required & prefix. That prefix can be thought of as an “address
of” the operator or function. It returns a numeric value that tells you
where the variable following the & is located in memory. We can actually
print that location out. Take a look at
ch06/address.c:
#include <stdio.h>intmain(){intanswer=42;doublepi=3.1415926;printf("answer's value: %d",answer);printf("answer's address: %p",&answer);printf("pi's value: %0.4f",pi);printf("pi's address: %p",&pi);}
In this simple program, we create two variables and initialize them. We use a
few printf() statements to show both their values and their locations in memory.
If we compile and run this example, here’s what we’ll see:
ch06$ gcc address.c ch06$ ./a.out answer's value: 42 answer's address: 0x7fff2970ee0c pi's value: 3.1416 pi's address: 0x7fff2970ee10
Note
I should say here is roughly what we’ll see; your setup will likely differ from mine, so the addresses likely won’t match exactly. Indeed, simply running this program successively will almost certainly result in different addresses as well. Where a program is loaded into memory depends on myriad factors. If any of those factors are different, the addresses will probably be different as well.
In all of the examples that follow, it is more useful to pay attention to which addresses are close to which other addresses. The exact values are not important.
Getting the value stored in answer or pi is straightforward and something we’ve been doing since Chapter 2. But playing with the address of a variable is new. We even needed a new printf() format specifier, %p, to print them! The mnemonic for that format specifier is “pointer,” which is closely related to “address.” Typically, pointer refers to a variable that stores an address, even though you will see people talk about a specific value as a pointer. You will also run across the term reference, which is synonymous with pointer but is more often used when talking about function parameters. For example, tutorials online will say things like “when you pass a reference to this function….” They mean you are passing the address of some variable to the function rather than the value of the variable.
But back to our example. Those printed pointer values sure look like big numbers! This won’t always be the case, but on systems with gigabytes or even terabytes of RAM that use logical addresses to help separate and manage multiple programs, it’s not uncommon. What do those values represent? They are the slots within our process’s memory where our variables’ values are kept. Figure 6-1 illustrates the basic setup in memory of our simple example.
Even without figuring out the exact decimal value of the addresses, you can see they are close together. In fact, the address for pi is four bytes bigger than the address for answer. An int on my machine is four bytes, so hopefully you can see the connection. A double is eight bytes on my system. If we added a third variable to our example, can you guess what address it would have?
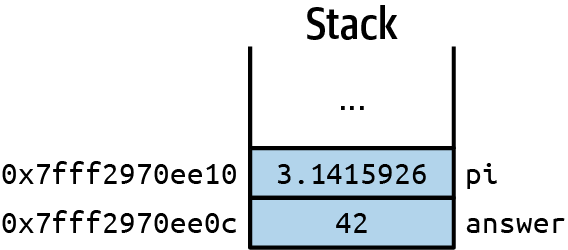
Figure 6-1. Variable values and addresses
Let’s go ahead and try it together. The program ch06/address2.c
adds another int variable and then prints its value and address:
#include <stdio.h>intmain(){intanswer=42;doublepi=3.1415926;intextra=1234;printf("answer's value: %d",answer);printf("answer's address: %p",&answer);printf("pi's value: %0.4f",pi);printf("pi's address: %p",&pi);printf("extra's value: %d",extra);printf("extra's address: %p",&extra);}
And here’s the output of our three-variable version:
ch06$ gcc address2.c ch06$ ./a.out answer's value: 42 answer's address: 0x7fff9c827498 pi's value: 3.1416 pi's address: 0x7fff9c8274a0 extra's value: 1234 extra's address: 0x7fff9c82749c
Hmm, actually the variables are not stored in the order we declared them. How strange!
If you look closely, you can see that answer is still stored first (address 0x…498),
followed by extra four bytes later (0x…49c), followed by pi four bytes after that
(0x…4a0). The compiler will often arrange things in a way it deems efficient—and
that efficient ordering won’t always line up with our source code. So even though
the order is a little surprising, we can still see that the variables all stack on top
of each other with exactly as much space as their type dictates.
The NULL Value and Pointer Errors
The stdio.h header includes a handy value, NULL, that we can use whenever we need to talk about an “empty” or uninitialized pointer. You can assign NULL to a pointer variable or use it in a comparison to see if a particular pointer is valid. If you like always assigning an initial value to your variables when you declare them, NULL is the value to use with pointers. For example, we could declare two variables, one double and one pointer to a double. We’ll initialize them with “nothing,” but then fill them in later:
doublepi=0.0;double*pi_ptr=NULL;// ...pi=3.14156;pi_ptr=π
You should check for NULL pointers anytime you can’t trust where a pointer came from.
Inside a function where a pointer was passed to you, for example:
doublemessyAreaCalculator(doubleradius,double*pi_ptr){if(pi_ptr==NULL){printf("Could not calculate area with a reference to pi!");return0.0;}returnradius*radius*(*pi_ptr);}
Not the easiest way to calculate the area of a circle, of course, but the if statement at the beginning is a common pattern. It’s a simple guarantee that you have something to work with. If you forget to check your pointer and try dereferencing it anyway, your program will (usually) halt, and you’ll probably see an error like this:
Segmentation fault (core dumped)
Even if you can’t do anything about the empty pointer, if you check before using it, you can give the user a nicer error message and avoid crashing.
Arrays
What about arrays and strings? Will those go on the stack just like simpler types? Will they have addresses in the same general part of memory? Let’s create a couple array variables and see where they land and how much space they take up. ch06/address3.c has our arrays. I’ve added a size printout so that we can easily verify how much space is allocated:
#include <stdio.h>intmain(){chartitle[30]="Address Example 3";intpage_counts[5]={14,78,49,18,50};printf("title's value: %s",title);printf("title's address: %p",&title);printf("title's size: %lu",sizeof(title));printf("page_counts' value: {");for(intp=0;p<5;p++){printf(" %d",page_counts[p]);}printf(" }");printf("page_counts's address: %p",&page_counts);printf("page_counts's size: %lu",sizeof(page_counts));}
And here is our output:
title's value: Address Example 3
title's address: 0x7ffe971a5dc0
title's size: 30
page_counts' value: { 14 78 49 18 50 }
page_counts's address: 0x7ffe971a5da0
page_counts's size: 20
The compiler rearranged our variables again, but we can see that the page_counts array is 20 bytes (5 x 4 bytes per int) and that title gets an address 32 bytes after page_counts. (You can ignore the common parts of the address and do a little math: 0xc0 – 0xa0 == 0x20 == 32.) So what’s in the extra 12 bytes? There is some overhead for an array, and the compiler has kindly made room for it. Happily, we (as programmers or as users) do not have to worry about that overhead. And as programmers we can see the compiler definitely sets aside enough room for the array itself.
Local Variables and the Stack
So where exactly is that “room” being set aside? In the largest terms, the room
is allocated from our computer’s memory, its RAM.
In the case of variables defined
in a function (and remember from “The main() Function” that main() is a function),
the space is allocated on the stack. That’s the term for the spot in memory where all
local variables are created and kept as you make various function calls. Organizing and
maintaining these memory allocations is one of the primary jobs of your operating system.
Consider this next small program,
ch06/do_stuff.c.
We have the main() function as usual,
and another function, do_stuff(), that, well, does stuff. Not fancy stuff, but it
still creates and prints the details of an int variable. Even
boring functions
use the stack and help illustrate how function calls fit together in
memory!
#include <stdio.h>voiddo_stuff(){intlocal=12;printf("Our local variable has a value of %d",local);printf("local's address: %p",&local);}intmain(){intcount=1;printf("Starting count at %d",count);printf("count's address: %p",&count);do_stuff();}
And here’s the output:
ch06$ gcc do_stuff.c ch06$ ./a.out Starting count at 1 count's address: 0x7fff30f1b644 Our local variable has a value of 12 local's address: 0x7fff30f1b624
You can see the addresses of count in main() and local in do_stuff() are near each
other. They are both on the stack. Figure 6-2 shows the
stack with a little more
context.

Figure 6-2. Local variables on the stack
This is where the name “stack” comes from: the function calls stack up.
If do_stuff() were to call some other function, that function’s variables
would pile on top of local. And when any function completes, its variables are
popped off the stack. That stacking can go on quite awhile, but not forever.
If you don’t provide a proper base case for a recursive function like those in
“Recursive Functions”, for example, this runaway stack allocation is what
eventually causes your program to crash.
You might have caught that the addresses in Figure 6-2 are actually decreasing. The start of the stack can either be at the beginning of the memory allocated to our program and addresses will count up, or at the end of the allotted space and addresses will count down. Which version you see depends on the architecture and operating system. The idea of the stack and its growth, though, remains the same.
The stack also houses any parameters that get passed to a function as well as any loop or other variables that get declared later in the function. Consider this snippet:
floataverage(floata,floatb){floatsum=a+b;if(sum<0){for(inti=0;i<5;i++){printf("Warning!");}printf("Negative average. Be careful!");}returnsum/2;}
In this snippet, the stack will include space for the following elements:
-
the
floatreturn value fromaverage()itself -
the
floatparametera -
the
floatparameterb -
the
floatlocal variablesum -
the
intvariableifor the loop (only ifsum < 0)
The stack is pretty versatile! Pretty much anything having to do with a particular function will get its memory from the stack.
Global Variables and the Heap
But what about global variables that are not connected to any particular function? They get allocated in a separate part of memory called the heap. If “heap” sounds a little messy, it is. Any bit of memory your program needs that isn’t part of the stack will be in the heap. Figure 6-3 illustrates how to think about the stack and the heap.
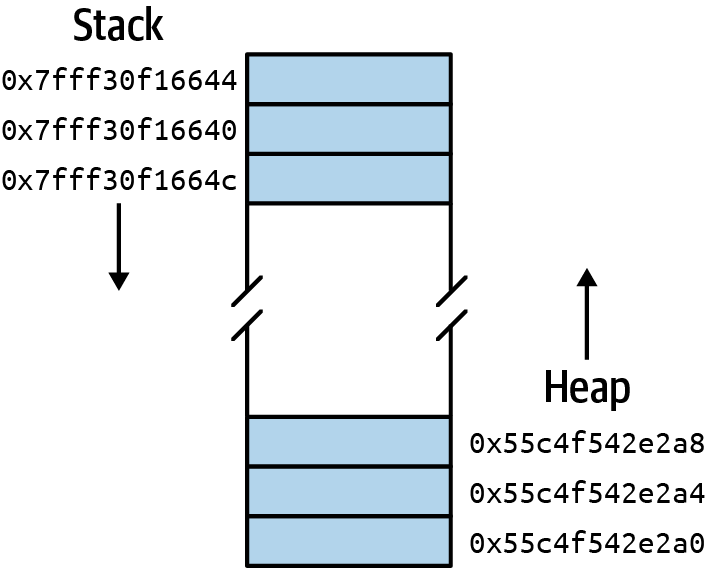
Figure 6-3. Stack versus heap memory
The stack and the heap share one logical lump of memory given to your program when you run it. As you make function calls, the stack will grow (down from the “top” in this case). As functions complete their call, the stack shrinks. Global variables make the heap grow (up from the “bottom”). Large arrays or other structures may also be allocated in the heap. (“Managing Memory with Arrays” in this chapter looks at how you can manually use memory in this space.) You can free up some parts of the heap to make it shrink, but global variables remain as long as your program is executing.
We’ll look in more detail at how these two parts of memory interact in “Stacks and heaps”. As both the stack and the heap grow, the free space in the middle gets smaller and smaller. If they meet, you’re in trouble. If the stack cannot grow any further, you won’t be able to call any more functions. If you call a function anyway, you will likely crash your program. Similarly, if there is no space left for the heap to grow, but you try to request some space, the computer has no choice but to halt your program.
Managing to stay out of this trouble is your job as the programmer. C won’t stop you from making a mistake, but in turn, it gives you room to be quite clever when circumstances dictate. Chapter 10 looks at several of those circumstances on microcontrollers and discusses some tricks for navigating them.
Pointer Arithmetic
Regardless of where your variables store their contents, C allows you to work directly with the addresses in a powerful (and potentially dangerous) way. We aren’t limited to printing out the address of a variable for simple inspection. We can store it in another variable. And we can use that other variable to get to the same bit of data and manipulate it.
Take a look at ch06/pointer.c to see an example of using a variable that points to another variable. I’ve called out a few key concepts in working with pointers:
#include <stdio.h>intmain(){doubletotal=500.0;intcount=34;doubleaverage=total/count;printf("The average of %d units totaling %.1f is %.2f",count,total,average);// Now let's reproduce some of that work with pointersdouble*total_ptr=&total;int*count_ptr=&count;printf("total_ptr is the same as the address of total:");printf("total_ptr %p == %p &total",total_ptr,&total);// We can manipulate the value at the end of a pointer// with the '*' prefix (dereferencing)printf("The current total is: %.1f",*total_ptr);// Let's pretend we forgot two units and correct our count:*count_ptr+=2;average=*total_ptr/*count_ptr;printf("The corrected average of %d units totaling %.1f is %.2f",count,total,average);}
We start with a normal set of variables and perform a simple calculation.

Next, we create new variables with corresponding pointer types. E.g., we create
total_ptrof typedouble *as a pointer to ourtotalvariable of typedouble.
You can dereference pointers to use or alter the things they point to.

Lastly, we prove that the original, non-pointer variables were in fact changed by the work we did with their pointer counterparts.
Here’s the output:
ch06$ gcc pointer.c ch06$ ./a.out The average of 34 units totaling 500.0 is 14.71 total_ptr is the same as the address of total: total_ptr 0x7ffdfdc079c8 == 0x7ffdfdc079c8 &total The current total is: 500.0 The corrected average of 36 units totaling 500.0 is 13.89
That output isn’t very exciting, but again, it proves we were able to edit the
value of variables like count via the count_ptr pointer. Manipulating data through pointers is pretty advanced stuff. Don’t worry if this topic still feels a little overwhelming. Keep trying the examples and you’ll get more comfortable with the syntax, which in turn will help you think about using pointers with your own future projects.
Array Pointers
We have actually worked with a pointer already, although it was very cleverly
disguised as an array. Recall our expanded use of the scanf() function in
“scanf() and Parsing Inputs”. When we wanted to scan in a number, we had to use
& with the name of the numeric variable. But scanning strings did not require
that syntax—we simply gave the name of the array. That is because arrays
in C are already pointers, just pointers with an expected structure to make
reading and writing array elements easy.
It turns out that you can work with the contents of an array without the convenience of the square brackets. You can use exactly the same dereferencing we just saw in the previous example. With dereferencing, you can add and subtract simple integers to the array variable to get at individual elements in that array. But this type of thing is best discussed over code. Check out ch06/direct_edit.c:
#include <stdio.h>intmain(){charname[]="a.c. Programmer";printf("Before manipulation: %s",name);*name='A';*(name+2)='C';printf("After manipulation: %s",name);}
We declare and initialize our string (
chararray) as usual.We can dereference the array variable to read or alter the first character. This is equivalent to
name[0] = A.We can also dereference an expression involving our array variable. We can add or subtract
intvalues, which translates to moving forward or backward in the array by one element. In our code, this line is equivalent toname[2] = C.And you can see the array variable itself is “unharmed,” although we did successfully edit the string.
Go ahead and compile and run the program. Here’s the output:
ch06$ gcc direct_edit.c ch06$ ./a.out Before manipulation: a.c. Programmer After manipulation: A.C. Programmer
This type of math and dereferencing works on arrays of other types, as well. You might see pointer arithmetic in loops that process arrays, for example, where incrementing the array pointer amounts to moving to the next element in the array. This use of pointers can be remarkably efficient. But while the simple manipulations in direct_edit.c might have been faster historically, modern C compilers are very (very!) good at optimizing your code.
Tip
I recommend concentrating on getting the answer you want before worrying about performance. Chapter 10 looks at memory and other resources on the Arduino platform where such worrying is a bit more justified. Even there, optimizing won’t be your first concern.
Functions and Pointers
Where pointers really start to make a difference in your day-to-day life as a programmer is when you attach them to the parameters or return values of functions. This feature allows you to create a piece of shareable memory without making it global. Consider the following functions from ch06/increment.c:
voidincrement_me(intme,intamount){// increment "me" by the "amount"me+=amount;printf(" Inside increment_me: %d",me);}voidincrement_me_too(int*me,intamount){// increment the variable pointed to by "me" by the "amount"*me+=amount;printf(" Inside increment_me_too: %d",*me);}
The first function, increment_me(), should feel familiar. We have passed values
to functions before. Inside increment_me(), we can add amount to me and get
the correct answer. However, we did pass only the value of count from our
main() method. That should mean that the original count variable will remain
untouched.
But increment_me_too() uses a pointer. Instead of a simple value, we can now
pass a reference to count. In this approach, we should find that count has been updated
once we return to main(). Let’s test that expectation. Here’s a minimal
main() method that tries both functions:
intmain(){intcount=1;printf("Initial count: %d",count);increment_me(count,5);printf("Count after increment_me: %d",count);increment_me_too(&count,5);printf("Count after increment_me_too: %d",count);}
And here’s what we get for output:
ch06$ gcc increment.c ch06$ ./a.out Initial count: 1 Inside increment_me: 6 Count after increment_me: 1 Inside increment_me_too: 6 Count after increment_me_too: 6
Excellent. We got exactly the behavior we wanted. The increment_me() function
does not affect the value of count passed in from main(), but increment_me_too()
does affect it. You will often see the terms “pass by value” and
“pass by reference” to distinguish the way a function handles the
arguments passed to it. And note that in the case of increment_me_too(), we
have one reference parameter and one value parameter. There is no restriction
on mixing the types. As the programmer, you just have to make sure you use your
function correctly.
Functions can also return a pointer to something they have created in the heap. This is a popular trick in external libraries, as we’ll see in Chapters 9 and 11.
Managing Memory with Arrays
If you know ahead of time you want a large chunk of memory, say, to store image or audio data, you can allocate your own arrays (and structures; see “Defining Structures”). The result of the allocation is a pointer that you can then pass to any functions that might need to work with your data. You don’t duplicate any storage this way, and you can check to make sure you got all the memory you need before you have to use it. That is a definite boon when working with content from unknown sources. If sufficient memory is not available, you can provide a polite error message and ask the user to try again rather than simply crashing without an explanation.
Allocating with malloc()
While we’ll typically reserve heap work for larger arrays, you can allocate anything you want there. To do so, you use the malloc() function and provide
it a quantity in bytes that you need. The malloc() function is defined in
another header, stdlib.h, so we have to include that header, similar to how we include stdio.h.
We’ll see more of the functions that stdlib.h provides in
“stdio.h”, but for now, just add this line at the top,
below our usual include:
#include <stdio.h>#include <stdlib.h>// ...
With this header included, we can create a simple program that illustrates the memory allocation of global and local variables as well as our own, custom bit of memory in the heap. Take a look at ch06/memory.c:
#include <stdio.h>#include <stdlib.h>intresult_code=404;charresult_msg[20]="File Not Found";intmain(){chartemp[20]="Loading ...";intsuccess=200;char*buffer=(char*)malloc(20*sizeof(char));// We won't do anything with these various variables,// but we can print out their addressesprintf("Address of result_code: %p",&result_code);printf("Address of result_msg: %p",&result_msg);printf("Address of temp: %p",&temp);printf("Address of success: %p",&success);printf("Address of buffer (heap): %p",buffer);}
The global declarations of result_code and result_msg as well as
the local variables temp and success should be familiar.
But look at how we declared buffer. You can see the use of malloc()
in a real program. We asked for 20 characters of space. You can specify a
simple number of bytes if you want, but it is usually safer (indeed, often
necessary) to use sizeof, as
shown in this example. Different systems will have different rules regarding
type sizes and memory allocation, and sizeof provides an easy guard against
unwitting mistakes.
Let’s take a look at the addresses of our variables in the output:
ch06$ gcc memory.c ch06$ ./a.out Address of result_code: 0x55c4f49c8010 Address of result_msg: 0x55c4f49c8020 Address of temp: 0x7fffc84f1840 Address of success: 0x7fffc84f1834 Address of buffer (heap): 0x55c4f542e2a0
Again, don’t worry about the exact value of those addresses. What we’re
looking for here is their general location. Hopefully, you can see that the
global variables and the buffer pointer we created in the heap manually with
malloc() are all in roughly the same spot. Likewise, the two variables
local to main() are similarly grouped, but in a separate spot.
So malloc() makes room for your data in the heap. We’ll make use of this
allocated space in “Pointers to Structures”, but we need to look at a
closely related function, free(), first. When you allocate memory using malloc(), you
are responsible for returning that space when you are done.
Deallocating with free()
As you might recall in the discussion of Figure 6-3, if you use up too much of the stack or the heap—or enough of both—you will run out of memory and your program will crash. One of the benefits of working with the heap is that you have control over when and how memory is allocated from and returned to the heap. Of course, as I just noted, the flipside of this benefit is that you have to remember to do the “giveing back” part yourself. Many newer languages work to relieve the programmer of that burden, as it is all too easy to forget to clean up after yourself. Perhaps you have even heard of the quasi-official term for this issue: a memory leak.
To return memory and avoid such leaks in C, you use the free() function
(also from stdlib.h). It’s pretty straightforward to use—you just
pass the pointer returned from your corresponding malloc() call. So to free
up buffer when you’re done using it, for example:
free(buffer);
Easy! But again, it’s remembering to use free() that is the difficulty.
That might not seem like such a problem, but it gets increasingly tricky when
you start using functions to create and remove bits of data. How many times did
you call the create functions? Did you call a reciprocal remove function for
each one? What if you try to remove something that was never allocated? All of
these questions make keeping track of your memory usage as troublesome as it is
vital.
C Structures
As you tackle more interesting problems, your data storage needs will get more complex. If you are working with LCD displays, for example, you will work with pixels that need a color and a location. That location itself will be made up of x and y coordinates. While you can create three separate arrays (one for all the colors, one for all the x coordinates, and finally one for the y coordinates), that collection will be difficult to pass to and from functions and opens up several avenues for bugs—like adding a color but forgetting one of the coordinates. Fortunately, C includes the struct facility to create better containers for your new data needs.
To quote K&R: “A structure is a collection of one or more variables, possibly of different types, grouped together under a single name for convenient handling.”1 They go on to note that other languages support this idea as a record. Searching online today you would also encounter the term composite type. Whatever you call it, this variable grouping feature is very powerful. Let’s see how it works.
Defining Structures
To create your own structures, you use the struct keyword and name followed by
your list of variables inside curly braces. Then you can access those variables
by name much like you access the elements of an array by index. Here’s a quick
example we could use with a program for bank accounts:
structtransaction{doubleamount;intday,month,year;};
We now have a new “type” we can use with our variables. Instead of
int or char[], we have struct transaction:
intmain(){intcount;charmessage[]="Your money is safe with us!";structtransactionbill,deposit;// ...}
The count and message declarations should look familiar. The next line
declares two more variables, bill and deposit, who share the new
struct transaction type. You can use this new type anywhere you have
been using native types like int. You can create local or global variables
with struct types. You can pass structures to functions or return them
from functions. Working with structures and functions
tends to rely more on pointers, but we’ll look at those details in
“Functions and Structures”.
Your structure definitions can be quite complex. There is no real restriction
on how many variables they can contain. A structure can even contain nested
struct definitions! You don’t want to go overboard, of course, but
you do have freedom to create just about any kind of record you can imagine.
Assigning and Accessing Structure Members
Once your structure type is defined, you can declare and initialize variables of that type using syntax similar to how we handle arrays. For example, if you know a structure’s values ahead of time, you can use curly braces to initialize your variable:
structtransactiondeposit={200.00,6,20,2021};
The order of the values inside the braces needs to match the order of the variables
you listed in the struct definition. But you can also create a structure variable
and fill it in after the fact. To indicate which field you want to assign, you
use the “dot” operator. You give the structure variable’s name
(bill or deposit in our current example), a period,
and then the member of the structure you are interested in, like day or amount.
With this approach, you can make assignments in any order you like:
bill.day=15;bill.month=7;bill.year=2021;bill.amount=56.75;
Regardless of how you filled the structure, you use the same dot notation to access a structure’s contents anytime you need them.
For example, to print any details from a transaction, we specify the transaction variable (bill or deposit in our case), the dot, and the field we want, like this:
printf("Your deposit of $%0.2f was accepted.",deposit.amount);printf("Your bill is due on %d/%02d",bill.month,bill.day);
We can print these inner elements to the screen. We can assign new values to them.
We can use them in calculations. You can do everything with the pieces inside your
structure that you do with other variables.
The point of the structure is simply to make it easier
to keep related pieces of data together. But these structures also keep data distinct.
Consider assigning the amount variable in both our bill and our deposit:
deposit.amount=200.00;bill.amount=56.75;
There is never any confusion over which amount you mean, even though we used the amount name in both assignments. If we add some tax to our bill after it was set up, for example, that will not affect how much money we include in our deposit:
bill.amount=bill.amount+bill.amount*0.05;printf("Our final bill: $%0.2f",bill.amount);// $59.59printf("Our deposit: $%0.2f",)// $200.00
Hopefully, that separation makes sense. With structures, you can talk about bills and deposits as entities in their own right, while understanding that the details of any individual bill or deposit remain unique to that transaction.
Pointers to Structures
If you build a good composite type that encapsulates just the right data, you will likely start using these types in more and more places. You can use them for global and local variables or as parameter types or even function return types. In the wild, however, you will more often see programmers working with pointers to structures rather than structures themselves.
To create (or destroy) pointers to structures, you can use exactly the same operators and
functions that are available for simple types. If you already have a struct variable,
for example, you can get its address with the & operator. If you created an instance
of your structure with malloc(), you use free() to return that memory to the heap.
Here are a few examples of using these features and functions with our struct transaction
type:
structtransactiontmp={68.91,8,1,2020};structtransaction*payment;structtransaction*withdrawal;payment=&tmp;withdrawal=malloc(sizeof(structtransaction));
Here, tmp is a normal struct transaction variable and we initialize it using curly braces. Both payment and withdrawal are declared as pointers. We can assign the address of a struct transaction variable like we do with payment, or we can allocate memory on the heap (to fill in later) like we do with withdrawal.
When we go to fill in withdrawal, however, we have to remember that we have
a pointer, so withdrawal requires dereferencing before we can apply the dot.
Not only that, the dot operator has a higher order of precedence than the dereference operator, so you have to use parentheses to get the operators applied correctly. That can be a little tedious, so we often use an alternate notation for accessing the members of a struct pointer. The “arrow” operator, ->, allows us to use a struct pointer without dereferencing it. You place the arrow between the structure variable’s name and the name of the intended member just like with the dot operator:
// With dereferencing:(*withdrawal).amount=-20.0;// With the arrow operator:withdrawal->day=3;withdrawal->month=8;withdrawal->year=2021;
This difference can be a little frustrating, but eventually you’ll get used to it. Pointers to structures provide an efficient means of sharing relevant information between different parts of your program. Their biggest advantage is that pointers do not have the overhead of moving or copying all of the internal pieces of their structures. This advantage becomes apparent when you start using structures with functions.
Functions and Structures
Consider writing a function to print out the contents of a transaction in a nice format.
We could pass the structure as is to a function. We just use the struct transaction type
in our parameter list and then pass a normal variable when we call it:
voidprintTransaction1(structtransactiontx){printf("%2d/%02d/%4d: %10.2f",tx.month,tx.day,tx.year,tx.amount);}// ...printTransaction1(bill);printTransaction1(deposit);
Pretty simple, but recall our discussion of how function calls work with the stack. In this
example, all of the fields of bill or deposit will have to be put on the stack when we
call printTransaction1(). That takes extra time and space. Indeed, in the very earliest
versions of C, this wasn’t even allowed! That’s obviously not true any longer,
but passing pointers to and from functions is still faster. Here’s a pointer version
of our printTransaction1() function:
voidprintTransaction2(structtransaction*ptr){printf("%2d/%02d/%4d: %10.2f",ptr->month,ptr->day,ptr->year,ptr->amount);}// ...printTransaction2(&tmp);printTransaction2(payment)printTransaction2(withdrawal);
The only thing required to go on the stack was the address of one struct transaction
object. Much cleaner.
Passing pointers this way has an interesting, intended feature: we can change the contents of a structure in the function. Recall from “Passing Simple Types” that without pointers, we end up passing values via the stack that initialize the parameters of the function. Nothing we do to those parameters while inside the function affects the original arguments from wherever the function was called.
If we pass a pointer, however, we can use that pointer to change the insides of the structure. And those changes persist because we are working on the actual structure, not a copy of its values. For example, we could create a function to add tax to any transaction:
voidaddTax(structtransaction*ptr,doublerate){doubletax=ptr->amount*rate;ptr->amount+=tax;}// ... back in mainprintf("Our bill amount before tax: $%.2f",bill.amount);addTax(&bill,0.05);printf("Our bill amount after tax: $%.2f",bill.amount);// ...
Notice that we do not change bill.amount in the main() function. We simply pass
its address to addTax() along with a tax rate.
Here’s the output of those printf()
statements:
Ourbillamountbeforetax:$56.75Ourbillamountaftertax:$59.59
Exactly what we were hoping for. Because it proves so powerful, passing structures by reference is very common. Not everything needs to be in a structure, and not every structure has to be passed by reference, but in large programs, the organization and efficiency you get are definitely appealing.
Warning
This ability to alter the contents of a structure using a pointer is usually desirable. But if for some reason you don’t want to change a member while you’re using a pointer to its structure, be sure not to assign anything to that member. You can, of course, always put a copy of that member’s value into a temporary variable first, and then work with the temporary variable.
Pointer Syntax Recap
I introduced enough new and somewhat esoteric bits of C’s syntax in this chapter that I wanted to recap things here for quick reference:
-
We defined new data types with the
structkeyword. -
We used the “dot” operator (
.) for accessing the contents of a structure. -
We used the “arrow” operator (
->) for accessing the contents of a structure though a pointer. -
We allocated our own space for data using
malloc(). -
We worked with that space using the
&(“address of”) and*(“dereference”) operators. -
When we’re done with the data, we can release its space using
free().
Let’s see these new concepts and definitions in context. Consider the following program, ch06/structure.c. Rather than use callouts in this slightly longer listing, I have added several inline comments to highlight key points. That way you can look up these details quickly here in the book, or in your code editor if you’re working on one of your own programs:
// Include the usual stdio, but also stdlib for access// to the malloc() and free() functions, and NULL#include <stdio.h>#include <stdlib.h>// We can use the struct keyword to define new, composite typesstructtransaction{doubleamount;intmonth,day,year;};// That new type can be used with function parametersvoidprintTransaction1(structtransactiontx){printf("%2d/%02d/%4d: %10.2f",tx.month,tx.day,tx.year,tx.amount);}// We can also use a pointer to that type with parametersvoidprintTransaction2(structtransaction*ptr){// Check to make sure our pointer isn't emptyif(ptr==NULL){printf("Invalid transaction.");}else{// Yay! We have a transaction, print out its details with ->printf("%2d/%02d/%4d: %10.2f",ptr->month,ptr->day,ptr->year,ptr->amount);}}// Passing a structure pointer to a function means we can alter// the contents of the structure if necessaryvoidaddTax(structtransaction*ptr,doublerate){doubletax=ptr->amount*rate;ptr->amount+=tax;}intmain(){// We can declare local (or global) variables with our new typestructtransactionbill;// We can assign initial values inside curly bracesstructtransactiondeposit={200.00,6,20,2021};// Or we can assign values at any time after with the dot operatorbill.amount=56.75;bill.month=7;bill.day=15;bill.year=2021;// We can pass structure variables to functions just like other variablesprintTransaction1(deposit);printTransaction1(bill);// We can also create pointers to structures and use them with malloc()structtransactiontmp={68.91,8,1,2020};structtransaction*payment=NULL;structtransaction*withdrawal;payment=&tmp;withdrawal=malloc(sizeof(structtransaction));// With a pointer, we either have to carefully dereference it(*withdrawal).amount=-20.0;// Or use the arrow operatorwithdrawal->day=3;withdrawal->month=8;withdrawal->year=2021;// And we are free to pass structure pointers to functionsprintTransaction2(payment);printTransaction2(withdrawal);// Add tax to our bill using a function and a pointerprintf("Our bill amount before tax: $%.2f",bill.amount);addTax(&bill,0.05);printf("Our bill amount after tax: $%.2f",bill.amount);// Before we go, release the memory we allocated to withdrawal:free(withdrawal);}
As with most new concepts and bits of syntax, you’ll get more comfortable
with pointers and malloc() as you use them more in your own programs. Creating
a program from scratch that solves a problem you are interested in always
helps cement your understanding of a new topic. I officially give you permission
to go play around with pointers!
Next Steps
We covered some pretty advanced stuff in this chapter. We looked at where data is stored in memory as your program is running and the operators (&, *, ., and ->) and functions (malloc() and free()) that help you work with the addresses of that data. Many books on intermediate and advanced programming will spend multiple chapters on these concepts, so don’t be discouraged if you need to read through some of this material a few more times. As always, running the code with some of your own modifications is a great way to practice your understanding.
We have an impressive array of tools in our C kit now! We can start tackling complex problems and have a good shot at solving them. But in many cases, our problems are not actually novel. In fact, a lot of problems (or at least a lot of the subproblems we find when we break up our real task into manageable pieces) have already been encountered and solved by other programmers. The next chapter looks at how to take advantage of those external solutions.
1 That convenient handling turns out to be very convenient. Kernighan and Ritchie devote an entire chapter of The C Programming Language to this topic. Obviously they go into more detail than I can here, so here’s one more plug for picking up this classic.