
19
Artificial Intelligence and Machine Learning
In this chapter, you will learn the basic concepts behind artificial intelligence and machine learning. While the chapter is just a very short introduction to a wide subject, you will learn how to perform in practice some simple common machine learning tasks with the Microsoft ML.NET package.
The chapter classifies the basic techniques used in artificial intelligence, how they evolved, and the problems they can solve. Then, it focuses on machine learning, thus classifying the available techniques with their limits, their advantages, and disadvantages. Moreover, the chapter answers questions like: Why does machine learning work? Can I use machine learning for my problem and with the data I have? Which techniques are more adequate for my problem?
While the subject is too wide to be covered in a single chapter, examples of some simple techniques are given.
More specifically, in this chapter, you will learn about the following subjects:
- Introduction to AI and machine learning
- Classification of the main artificial intelligence techniques
- What machine learning is and how it works
- From theory to practice: the role of a software architect in a machine learning project
- How to use ML.NET Model Builder to start applying machine learning in your projects
As a software architect, you will probably lead projects that will require you to understand the basic AI and ML concepts presented here. So let’s get started!
Technical requirements
This chapter requires the free Visual Studio 2022 Community edition or better with all database tools installed. The code for this chapter is available at https://github.com/PacktPublishing/Software-Architecture-with-C-10-and-.NET-6-3E.
Introduction to AI and machine learning
What has changed in artificial intelligence in the last 20 years? Basically, almost nothing! At least in the algorithmic theories behind the various artificial intelligence techniques. For sure, there have been new applications of existing theories, and minor refinements, but mainly more computational power! That’s where the cloud and big data come in! That’s why the cloud triggered a revival of artificial intelligence.
A renewed interest in neural networks started when video cards gave the possibility to customize the operations performed on each pixel by providing chunks of code called pixel shaders. The initial purpose was empowering 3D rendering with photo-realistic effects and special effects, but in a short time, developers realized that video cards were powerful processors capable of executing single instructions (the ones provided by pixel shaders) in parallel on millions of data (all pixels). They are SIMD (Single Instruction Multiple Data) parallel machines – exactly what is needed to simulate neural networks where the same neuron simulation instructions must be executed on all simulated neurons simultaneously. As a consequence, most video card producers started building special video cards to be used as SIMD machines, which are the ones used in the cloud to simulate neural networks and to perform statistical and linear programming computations on big amounts of data.
New kinds of SIMD machines were conceived and are used in famous clouds, but this great progress just involves SIMD machines. No commercial MIMD (Multiple Instruction Multiple Data) machine capable of executing trillions of different chunks of code on different data has been conceived, so big parallelism is available only if the same instruction must be executed on big amounts of data. The main difficulty with massively parallel MIMD machines is communications among millions of executing software chunks and their assignment to idle processors.
Accordingly, neural networks, statistical computations, and linear programming techniques, which may benefit from SIMD machines, become the artificial intelligence battle horse that comes with various famous clouds! In fact, other artificial intelligence techniques that we are going to describe would require MIMD machines to gain benefit from the computational power offered by the cloud. Notwithstanding this, you may find services based on them that some companies offer in the cloud to take advantage of the SaaS (Software as a Service) model and scalability offered by the cloud, instead of the massive computational power of SIMD.
In the next section, we will discuss the most common artificial intelligence techniques, and their applications.
Classification of the most common artificial intelligence techniques
Artificial intelligence has a very vague definition: a bunch of software techniques that simulate human behavior. The most famous and objective definition is the one based on the so-called Turing test. Software passes the Turing test if a human speaking with it either through a keyboard or through an audio device is not able to understand if they are speaking with a machine or with another human. Needless to say, nowadays no software can pass the Turing test!
Therefore, at the moment, AI software is just able to mimic human behavior in very particular circumstances and in very limited domains of knowledge.
In the remainder of this section, we will describe the main AI techniques, each in a separate subsection. We will limit this to artificial reasoning techniques. Perception techniques (computer vision, language, and speech understanding) will be described shortly, in the next section about machine learning.
Heuristic search
Heuristic search tries to find a solution to a problem by exploring all possibilities with a tree search and with the help of a heuristic function that selects the most promising tree node to expand. Among the various search techniques, alpha-beta search is used for playing games against a human adversary (chess machines, for instance). Alpha-beta search looks at the best “move,” trying to forecast the best “moves” of the human adversary in the search. The A* algorithm, instead, explores all possibilities with only the purpose of solving a problem, such as simplifying a mathematical expression, performing a symbolic integration, solving a puzzle, and so on.
Both A* and alpha-beta search use a heuristic function to score each tree node that, for instance, represents a chessboard state, and then expand the node with the highest score with further moves/modifications. Here, exploring means creating another child state, by performing a move in the parent state, for instance, moving a chess piece in a tree node representing a chessboard. Thus, exploring the consequences of all possible moves, one after the other.
The basic idea behind A* and alpha-beta search is a “what if” search performed to a certain depth, whose purpose is to decide the most promising move.
In alpha-beta search, software moves (alpha) are interleaved with the forecasts of opponent moves (beta). During the alpha stage, the software selects the node with the highest score, while during the beta stage, the software selects the node with the lowest score because it tries to forecast the opponent’s behavior.
There are also variations of alpha-beta for N players, and variations for probabilistic games or puzzles. The main difference with the probabilistic game versions of these algorithms is that the score is multiplied by the probability assigned to each position.
There are theorems ensuring that these algorithms work properly and find the best solution if the heuristic function satisfies some constraints. Unluckily, these constraints are rarely met in practical difficult problems.
More complex search techniques use constraint propagation and least commitment to cut the search tree. Constraint propagation uses constraints imposed by a previous choice to cut further choices, thus reducing the possible moves in each state. For instance, in the eight queens problem (placing eight queens on a chessboard so that none of them threatens another one), when a new queen is placed on the chessboard, all newly threatened positions are removed from the set of possible positions for the other queens, thus reducing the further possible moves. Least commitment tries to delay all choices till constraints coming from other choices make them univocal.
Heuristic search and all its variations were initially conceived for enabling software to play games and solve puzzles but then became the basis of almost all artificial intelligence reasoning algorithms.
The next subsection describes a logical language AI software used for modeling reality, and for reasoning about it.
First-order calculus
First-order calculus describes world facts with predicates such as OnTable(X), OnTop(X, Y), and adds general laws called axioms, such as Human(X) => Mortal(X). Predicates may contain either variables or constants. Usually, general laws may contain both constants and variables, while facts contain just constants, in which case they are said to be grounded. Predicates can be combined with the usual &&, !, and || logical operators of propositional logic. Also the Human(X) => Mortal(X) proposition can be rewritten in terms of these operators as Mortal(X) || !Human(X). Together with constants and variables, inside predicates, we can also have functional and mathematical operators, like in the example Solution(AX+B, -B/A), which states the rule for solving first-degree equations. It is worth pointing out that, since the above is a general law, B and A are also variables – not mathematical variables but logical ones. The different mathematical roles played by A, B, and X in the equation can be made explicit by rewriting the previous rule as:
Parameter(A) && Parameter(B) && Unknown(X) => Solution(AX+B, -B/A)
We may deduce new logical propositions from axioms and facts by applying inference rules. A famous inference rule is modus ponens, which applies a proposition such as Human(X) => Mortal(X) to a fact matching its left side to get a fact from its right side:
Human(Mother(John))) , Human(X) => Mortal(X) -| Mortal(Mother(John))
Where the -| symbol means logical consequence. It is worth mentioning that as a consequence of matching Human(X) to Human(Mother(John))), the X variable gets bound to Mother(John), so the right side of the general axiom gets bound to Mother(John), too. This way, the right side of the implication becomes specific to Mother(John), thus yielding Mortal(Mother(John)).
Let’s apply modus ponens to a more complex case:
Parameter(5)
Parameter(2)
Unknown(S)
Parameter(A) && Parameter(B) && Unknown(X) => Solution(AX+B, -B/A)
------------------------------
Solution(5S+2, -2/5)
Where the horizontal dotted line means logical consequence, too. Software that uses inference rules to verify if a proposition is a logical consequence of facts and axioms is called a theorem prover.
Since it is not easy to implement a procedure that methodically tries all possible applications of modus ponens, theorem provers use another inference rule called clause resolution, which enables the usage of A* search.
Clause resolution applies to propositions called clauses that are the logical || of predicates and negated predicates. Thus, the first step of a clause resolution theorem prover is the transformation of the whole database of facts and axioms into the logical && of a set of clauses.
The clause resolution inference rule takes two clauses that have some predicate in common and some others that are not in common and creates a new clause as shown below:
(A1, A2,…An, B1, B2, …Bl), (!A1, !A2,…!An, C1, C2, …Cm) -| (B1, B2, …Bl, C1, C2, …Cm)
That is, the predicates that are in common must be negated in the second clause. In the resulting clause, they are removed, and the remaining predicates are put together.
Let’s prove Solution(5S+2, -2/5) with clause resolution. Instead of proving the clause, it is easier to use reductio ad absurdum. That is, the goal proposition to prove is negated and added to the facts. If the goal is provable, then we should be able to prove the absurd, that is, the empty clause. Clause resolution starts from the initial negated clause: !Solution(5S+2, Y):
!Solution(5S+2, Y)
Take: Solution(AX+B, -B/A) || !Parameter(A) || !Parameter(B) || !Unknown(X)
------------------------------
!Parameter(5) || !Parameter(2) || !Unknown(S) [Y=-5/2, A=5, B=2, X=S]
Take: Parameter(5)
------------------------------
!Parameter(2) || !Unknown(S) [Y=-5/2, A=5, B=2, X=S]
Take: Parameter(2)
------------------------------
!Unknown(S) [Y=-5/2, A=5, B=2, X=S]
Take: Unknown(S)
------------------------------
[Y=-5/2, A=5, B=2, X=S]
Take: means we take the clause that follows from the database to combine it with the current result. The first application of the rule takes the axioms for solving first-degree equations in clause format and yields its premises adapted with some variables replaced. To apply clause resolution, variables must be matched to get identical values. In this stage, we also find that Y must be equal to -5/2. All relevant variable matches are shown in square brackets.
In the end, when we get the empty clause, the set of all variable matches contains the solution Y=-5/2. This means that the Solution(5S+2, Y) clause is true with Y=-5/2.
Several attempts can be organized in an A* search, and several heuristics proved to cut the search without missing the solution. However, we can’t discuss them for lack of space.
Like most A* searches, clause resolution also has an exponential computational cost. Therefore, it can’t be applied to wide bases of knowledge.
At the moment, the usage of clause resolution is limited to the formal proof that device drivers work properly and to answering systems such as chatbots. Chatbots translate queries received in natural language into clauses to prove and apply them to a pre-existing knowledge base of facts and rules, to get answers in the form of variable matches as in the case of Solution(5S+2, Y) and Y=-5/2.
Several other systems use the same logic-based language to model reality, but with more efficient problem-specific algorithms. The next subsection looks at planners.
Planners
Planners are software that tries to find plans made of several actions to achieve goals. Reality is modeled with a logical && of predicates, and planner actions modify these sets of predicates by removing some predicates and adding other predicates. Each action can be performed only if some predicates are true, that is, if some conditions are met. These enabling predicates are called action preconditions.
In the domain of playing cards, the ones below are possible actions:
Stack(x, y) : //moves a playing card from the table to the top of another
Preconditions: OnTable(x), Clear(x), Clear(y)
Add list: OnTop(x, y),
Delete List: Clear(y), OnTable(x)
Unstack(x, y) : //moves a playing card from the top of another to the table
Preconditions: OnTop(x, y), Clear(x)
Add list: OnTable(x), Clear(y)
Delete List: OnTop(x, y)
Move(x, y, z): //moves a playing card from the top of y, to the top of z
Preconditions: OnTop(x, y), Clear(x), Clear(z)
Add list: OnTop(x, z), Clear(y)
Delete List: Clear(z), OnTop(x, y)
Where Clear(x) means that x has no playing card over it, OnTable(x) means that x is on the table, and OnTop(x, y) means that x is over y.
The simplest planners are the so-called linear planners. They are called linear because they try to avoid a tree search. Basically, they build the action sequence in reverse order. Starting from the goal they must reach, they recursively try to meet the preconditions of each action by adding new actions till all preconditions are met in the initial state of the world. Unluckily, during this process, the Delete List of an action can destroy the preconditions of a previously added action. When this happens, the planner tries to invert the execution order of the two actions so that the Delete List removal takes place only after the other action has been executed. If reordering fails, patching actions are added to restore the deleted preconditions.
Linear planners work in linear time with occasional exponential search in the case of action reordering and action patching. They work well when actions rarely interfere with each other. Otherwise, planners based on an A* search work better.
There is also a recent algorithm that works in cubic time, but it can’t use predicates, just single propositional variables. Thus, instead of having a single predicate, OnTable(x), we must have several propositional variables, OnTableCard1, OnTableCard2, and so on – one for each card.
Since the world descriptions used in robot planning are finite, the operation of replacing all predicates with propositional variables can always be performed, but it causes an explosion of variables if there are predicates with several arguments. Actual software based on this algorithm uses several techniques to discard useless variables, but still, this way, this algorithm can be inconvenient.
Planners have several applications, such as robotics, the implementation of video game characters, and automatic software generation.
Heuristic rules, neural networks, and Bayesian networks
The complexity of handling complex domains of knowledge with first-order calculus techniques leads to a heuristic approach that replaces rigorous inference rules with rules of thumb. Human experts of any knowledge domain never perform detailed and rigorous chains of logical inferences but use heuristic rules to jump to complex inferences and reach the desired conclusions, chaining just a few powerful heuristic rules.
Thus, experts need just a few reasoning steps to reach their conclusions. Heuristic rules take a format like:
From P1(…), P2(…), … Conclude C1(…), C2(…).
Where both Pn and Cn are usual predicates. Heuristic rules can be chained in complex recursive ways, in that they are like inference rules, but they are more powerful and don’t require detailed reasoning that involves the first principles of a domain of knowledge.
Software based on heuristic rules is called expert systems. Their main problem and bottleneck is the extraction of the heuristic rules from human experts.
This started a strong interest in machine learning and building expert systems that can get their knowledge from examples.
The neural networks that will be analyzed in more detail in the next section are able to learn from examples, but they can’t process predicates, just propositional variables. Therefore, knowledge must be expressed in terms of just propositional variables that can be either true or false. Actually, neural networks are also able to attach a reliability score to the truth of each proposition.
While the main problem of expert systems is the acquisition of their knowledge from human experts, expert systems based on neural networks suffer from the following problems:
- While for planners, propositional logic works well enough, it is inadequate for general reasoning.
- Neural networks are not able to perform recursive reasoning; they just apply a predefined number of stages of heuristic rules one after the other. Unluckily, several common reasoning tasks need complex recursive reasoning. For instance, understanding that a geometric point is reachable from another requires the recursive application of a reachability rule (a straight line meeting two points that does not cross obstacles).
- Expert systems based on neural networks are neither able to explain their conclusions nor to list the rules they use. In fact, the rules learned are stored in the way the nodes of the network work and are not explicitly represented.
The above problems limit the application of expert systems based on neural networks. At the moment, they are used just for recognizing typical patterns such as the patterns used in spam emails or suspicious financial transactions, and for classifying data, images, and sounds.
Bayesian networks are another type of expert system that can extract their knowledge from examples. They suffer from problems 1 and 2 of neural networks but can explain their behavior. That’s why they are used in medical and diagnostic expert systems.
Bayesian networks are built from raw data by computing conditional probabilities of events. For instance, when analyzing raw data, we can compute the probability of symptoms given a disease. Then, using algorithms based on Bayes’ theorem, these probabilities can be inverted to yield the probability of a disease given some symptoms.
We will finish this short review with the optimization of search algorithms with so-called truth maintenance systems.
Truth maintenance systems
Truth maintenance systems (TMSes) were conceived to optimize search algorithms by using what has been learned during the exploration of a node in other nodes.
To use truth maintenance systems, search problems must be represented as follows:
- The purpose of the search is to find appropriate values for a list of variables,
V1, V2, ...Vn. - In the tree search, nodes are expanded by making assumptions on the values of the variables defined at point 1. Therefore, each tree node describes the state of the world under some assumptions on the values of some of these variables.
- Each node is represented by a logical
&&of predicates. New predicates are added to this conjunction of predicates by applying logical rules to the current set of assumptions. - Each predicate stores with it the assumptions used to prove it.
- Logical rules verify if a node is an acceptable solution or if it is a failure.
Failures are reached when logical rules allow the demonstration of a contradiction, that is, the demonstration of an empty clause like in (A), (!A) -| (), which proves the empty clause with an application of clause resolution. Whenever a failure is reached, the assumptions associated with the contradiction are stored in a database, so that the problem solver avoids testing the same combination of assumptions in the exploration of other nodes. The database can be optimized using rules of propositional logic each time new contradictory assumptions are added, and it relies on complex indices to ensure high-performance queries.
The most famous TMS is the ATMS (Assumption-based Truth Maintenance System). It doesn’t explore all nodes separately, but instead, each predicate stores all the combinations of assumptions that make it true that have been discovered so far. Each combination of assumptions is called a possible world. Possible worlds correspond to the search nodes of classical tree search.
Logical inferences are applied to predicates to get other predicates. When this is done, the problem solver computes all possible worlds of the newly added predicates. This way, a single inference explores several possible worlds simultaneously in parallel. When a contradiction is reached, all its possible worlds are declared inconsistent, and the associated assumptions are declared incompatible. All possible worlds that are discovered to contain incompatible assumptions are removed from all predicates.
This way, at each inference, an ATMS processes in parallel several possible worlds, that is, several nodes of a classical problem solver. Discovering a contradiction corresponds to recognizing failures in nodes of classical problem solvers, but with ATMS this takes place in parallel on several possible nodes simultaneously.
By representing assumptions as bits of bit vectors, all ATMS operations can be performed efficiently. Therefore, the ATMS makes possible the exploration of complex search graphs in acceptable times.
Moreover, since an ATMS can find not only a single solution but all solutions, it is also easy to pick up the best solution.
ATMSes are used mainly in diagnostic tasks, that is, in reasoning on how complex equipment works to discover the causes of malfunctions. In these cases, assumptions represent malfunctions of equipment components, so each possible world represents a set of device malfunctions, and the result is the collection of all sets of device malfunctions that may cause the observed equipment malfunction.
TMSes finish our short review of artificial intelligence. The next section moves on to machine learning.
What is machine learning and why does it work?
Speaking of expert systems, we said that machine learning was conceived to avoid the time-consuming process of extracting knowledge from human experts. There are cases where knowledge can’t be extracted at all from humans, such as computer vision and the recognition of some activity patterns. Each human has the knowledge needed for computer vision but this knowledge is stored on a subconscious level so it can’t be extracted. Moreover, by empowering software with the capability to learn, we might also furnish it with capabilities that no human has. This is the case of machine learning used in fraud detection, spam detection, and hacker attack prevention.
In the next subsection, we give some definitions and analyze machine learning’s main features.
Machine learning basics
The purpose of machine learning can be defined as follows:
Given a set F of functions and a set I of available information, find a function f in F that is compatible with the information I with a given approximation.
The way approximation is measured depends on the nature of F, if it is a set of real-valued functions, the approximation is measured with the maximum error, or with the average error in the values returned by the solution f. In the case of discrete values, such as the classification of an object image, it can be the probability that f returns a wrong value.
Approximations are unavoidable, since, in general, I itself contains errors. PAC (Probable Approximate Correct) approximation is adequate for both discrete and real-valued functions:
The solution f of a machine learning problem is PAC with parameters ![]() and
and ![]() if the probability of f returning an error higher than
if the probability of f returning an error higher than ![]() is less than
is less than ![]() .
.
In the case of discrete-valued functions, it is enough to take ![]() .
.
For what concerns the source of information I, below are some examples:
- A set of examples. A set of
(x, f(x))pairs, which is called the training set. This kind of learning is called supervised learning because it needs to be told that for some values,xgives the rightf(x). - The success or failure of an overall task after assuming a value
f(x)for a valuex. In this case, there is no teacher, but the software tests itsf(x)guess by using it in real-world experiments, therefore we speak of unsupervised learning. Formally, in this case, we have triples(x, f(x), success/failure). - Natural language teaching with an unreliable teacher. The actual knowledge is received by an unreliable teacher that sometimes may also give inaccurate information. This kind of learning is called learning by being told.
- Pre-existing knowledge. In this case, some of the previous sources of information are used to change pre-existing knowledge. This kind of learning is called knowledge revision.
Supervised learning is more common and easier to design. However, it has the disadvantage of requiring a human teacher that furnishes the actual values of f(x) in the training set.
Unsupervised learning doesn’t require any teacher since the software itself is able to learn from its errors. However, hoping that the software might learn while doing its actual job is just a pipe dream.
The difficulty of unsupervised learning is that once we get a failure, we don’t know which of the choices made by the software is responsible for that failure, so we are forced to add a punishment score to all choices involved in a plan. With this technique, reaching reliable learning might require an unacceptable number of experiments.
Unsupervised learning is possible in practice under one or more of the following constraints:
- The software can organize its controlled experiments. This way, it can test just one or two hypotheses at a time, and a punishment/reward algorithm can converge in an acceptable time.
- Hypotheses to test are not generated with zero knowledge, but by getting reasonable guesses by reasoning from first principles. Thus, the software can somehow simulate the real world and can test hypotheses in this simulated world before trying them in the actual world. For instance, we can guess that a given chess move is convenient under certain circumstances by performing an alpha-beta search after that move to verify the consequences of that move.
At the moment, the only practical applications of unsupervised learning are improvements of heuristic functions used in A* and alpha-beta search. Most other applications never left the research stage. Among them is Lenat’s Eurisko system, which was able to discover all relevant number theory concepts and theorems.
Eurisko selects interesting hypotheses by performing mathematical experimentation, tests them extensively, and then relies on them to do further experimentation. Eurisko was able to reach remarkable results because it conforms to both constraints 1 and 2 listed above.
Learning by being told is used in practical search and question-answering systems. For instance, it is possible to process natural language most asked questions, to extract the knowledge needed by a chatbot.
Azure Bot Service offers this kind of service. The OpenAI GPT3 natural language processing system was mainly conceived for building question-answering systems by processing huge amounts of natural language text.
The basic idea behind these question-answering systems is learning the associations between questions and answers found in natural language text. In a few words, these systems are not able to understand the text and to create models of the phenomena they read about, but they learn just associations of phrases and concepts found in the text.
Knowledge revision is easy when the algorithms used for learning are incremental, otherwise, the only way out is to rerun the initial training set upgraded with the new data.
Learning based on neural networks is incremental so knowledge revision with neural networks is easy. On the contrary, learning based on probabilistic and linear programming algorithms is rarely incremental. Thus, for instance, learning based on the support vector algorithm, which we will describe later in this section, is not incremental.
Also learning based on a logical representation of reality can be easily made incremental. It is enough to use a truth maintenance system and to associate with each learned proposition an assertion.
This way, when newly added knowledge creates contradictions, it is easy to compute all options for removing the contradiction, that is, to compute all assertion removal options.
All ATMS algorithms can be enhanced with the addition of probabilities to assertions and possible worlds. This way, the system can do the following:
- Select the least probable assertion whose removal avoids the contradiction.
- Compute the total entropy of all possible contradiction removal actions.
- If that entropy is too high, meaning there is no worst assertion to remove, ATMS algorithms can easily compute the experiment whose result can minimize the entropy. That is, ATMS algorithms can easily compute the experiment that better clarifies what is the wrong assertion to remove.
In the remainder of the chapter, we will focus on supervised learning because it is the most used and because it is more adequate for understanding the basics of machine learning.
The next subsection gives the basics for computing the order of magnitude of the examples needed for a given learning task, and thus for verifying if a learning task is affordable.
How many examples do I need to learn my function?
Suppose the function we are learning has values in a domain with D elements and takes values in a codomain with C elements. Then, knowing its value at a given point reduces all possibilities by 1/C. Accordingly, each example in the training set reduces the possibilities of 1/C, and m examples reduce the possibilities of 1/Cm.
Now if the space F of possible solutions has cardinality |F|, then with m examples we restrict the number of possible solutions to |F|/Cm. To finalize the learning task, we need to reduce this number to 1. Therefore, we must have:
|F|/Cm ≤ 1 → Cm ≥ |F| → mlogC≥log|F|→ m≥log|F|/logC [1]
Now, if F is the set of all possible functions with the given domain and codomain, we have:
|F| = CD
Replacing this value in the previous equation, we get:
m≥DlogC/logC → m≥D (2)
Therefore, when set F (where we search our solution) is the set of all functions with the given domain and codomain, our examples must give the value of the function in all domain points!
So, it appears that, in general, there is no way to learn something with a reduced set of examples! To overcome this problem, we must apply Occam’s Razor principle. Occam’s Razor principle basically says that laws of nature are simple, so for each phenomenon, we must look for the simplest rule that explains our data.
Therefore, we must not consider all functions with the given domain and codomain, but just the simpler ones, thus reducing |F| from CD to a smaller value. Thus, we must change F by modulating somehow the simplicity of the solution we are looking for.
There are two measures of simplicity we can use:
- Smoothness. If our solutions are real-valued or if they map topological spaces into topological spaces, we may require they are continuous, and we may give limits on how quickly their values change when we move from one point in the domain to another. A good way of formalizing this constraint is by requiring that our solution is Lipschitz continuous, that is,
|f(x1)-f(x2| < K|x1-x2|for all points and for a given real constantK.Kmeasures the function’s maximum speed of change. - If the function can be computed with code, we measure simplicity with the length of this code. Therefore, the simplest functions are the ones that require less code. For each function, the minimum code for implementing it in each language is called its Kolmogorov complexity.
It can be proven that definition 1 is a particular case of definition 2, that is, that smoother functions require less code. However, we maintain two different definitions because each of them leads to different machine learning techniques.
By changing the smoothness or code length constraints, we can change the cardinality |F|. However, what is the right level of smoothness or code length for each machine learning task?
It can be found with the iterative algorithm below:
- Split all available examples into two equal sets
S1andS2, and start with high simplicity (very smooth or very short).S1is called the training set whileS2is called the control set. - Apply your machine learning algorithm to
S1. - If the solution doesn’t perform well on
S1, decrease the simplicity and repeat. Otherwise, move to the next point. - If the solution doesn’t perform well on
S2, the training set is too small and you need more examples.
In step 4, you might try a level of simplicity that is in between the current one and the previous one, because the failure might depend on too big of a jump in simplicity.
Failures at point 2 are due to too high simplicity that prevents the fit with the training set. Say you are trying to fit a complex curve with a simple straight line.
Failure at point 3 may be due either to a too-small training set or to the fact that the solution is too specific to the training set, so it doesn’t match the control set. This means that generality is low, hence simplicity is too low. However, if we slowly decreased the simplicity according to Occam’s Razor principle, the problem can’t be the simplicity and must be the small number of examples.
The next subsection discusses machine learning algorithms based on smoothness.
Learning smooth functions
Let’s show how the smoothness constraint is able to decrease the cardinality of the space of possible solutions F. Suppose we are looking for a sampled smooth real-valued function that can have a maximum change of 0.1 when you move from one sample to the next sample. Below is an example:

Figure 19.1: 0.1-smooth function
When we pass from one domain point to the next one, there are three possibilities, either the function value doesn’t change, it increases by 0.1, or it decreases by 0.1. Therefore, each time we move right, we must multiply by 3 the total possibilities. Therefore, the total number of functions is:
3*3*3…3 = 3D
Replacing the above value for |F| in Equation [1], we get:
m≥log3D /logC → m≥Dlog3/logC
This means that the function can be univocally defined with the knowledge of its values in a percentage Dlog3/logC of all its domain points. If we suppose that the codomain possible value C is 10,000, we get about 10% of the domain points.
Restricting F to smooth functions is not able to reduce the training set too much because this kind of learning relies on continuous function interpolation. Therefore, it works only if examples are densely and fairly distributed in the domain. Interpolation doesn’t furnish acceptable results on points that are far from the interpolation points.
Equations like the one-dimensional continuous functions above can be found, in general, for all Lipschitz continuous functions defined on Rn. The higher the dimension n of the domain is, the worse the reduction of |F| is.
However, we know that neural net-based learners can recognize objects after they have been trained with hundreds of samples. How is this possible?
First, computer vision cloud services have already been pre-trained to recognize objects in general, before we use them on our samples. However, this doesn’t solve the mystery, because it is difficult to understand how someone was able to pre-train them.
The final answer is symmetry! Actual learners exploit symmetries that are implicit in a problem to learn with an acceptable training set.
For example, let’s consider the problem of finding the likelihood from 0 to 1 that an 8-bit 800x800 image contains a cat. In this case, the domain cardinality is 8(800x800), a huge number. Also, reducing that number by 10% or to 1% doesn’t turn it into an acceptable number.
Computer vision learners are organized into layers and each layer exploits symmetries. The point is that what has been learned in a portion of the image can also be applied to all parts of the image obtained by translating this portion of the image’s x and y coordinates. Neural nets that exploit translational symmetry are called convolutionary. The actual learning is performed on small nxn squares that are moved throughout the image where n is something like 4. These moving windows extract the so-called image features. Examples of features are segments of region boundaries, boundary normal, and so on.
Features are then organized into small bi-dimensional maps. Therefore:
- The actual learning is performed in small domains.
- Since learning windows are moved on the image, each single image is used in several learning steps, so each image furnishes several examples for the training set.
Similar considerations also apply to speech understanding. Therefore, we may conclude that smooth functions-based learning can be applied in the following situations:
- The domain is small.
- The problem can be turned into a small-domain problem by exploiting symmetries.
Moreover, smooth functions-based learning requires:
- Big training sets (at least during pre-training)
- Big computational power
That is why this kind of learning is mainly offered in cloud services like Azure and is applied mainly in computer vision, speech/natural language understanding, and pattern recognition, while it can’t be applied when complex reasoning chains are needed. Examples of pattern recognition are spam recognition and fraud detection.
The next topic gives a short review of neural networks.
Neural networks
Neural networks rely on a single computational node called an artificial neuron that has several inputs and a single output that computes the so-called logistic function on its inputs:

Figure 19.2: Logistic function
Where wj is multiplicative coefficients associated at each neuron input, and b is called the neuron threshold. Both the coefficients and the threshold are the output of the learning process.
Arrays of neurons are arranged into layers, where the output of all neurons of each layer relates to an input of all neurons of the next layer as shown below:

Figure 19.3: Neural net
The first layer of neurons relates to the function input, while the last neuron outputs are connected to the function output.
Since it is possible to prove that the logistic function is complete in the space of continuous functions, each continuous function can be approximated with a multilayer neural net, if it contains enough nodes.
The fewer neurons we have in the net, the smoother the functions it can approximate are, and the smaller |F| is.
Neural net learning computes all neurons’ parameters and is based on the so-called back-propagation algorithm. This algorithm is easily parallelizable on programmable graphic cards and searches the function that minimizes the square average error with the input examples with a gradient method.
Unluckily, the gradient method is just ensured to find local minima, and not the absolute minima, so ensuring that a neural network works properly is quite tricky. That is why complex problems are not solved with a single multilayer network, but by connecting several multilayer networks in complex architectures.
Neural nets are successfully used in computer vision, speech/text understanding, classification, and pattern recognition problems. There are theorems stating that specific neural network architectures ensure PAC learning with approximation if we have enough examples.
The next topic discusses a linear algorithm that was designed for classification problems.
The support vector algorithm
The support vector algorithm finds a plane in Rn that better separates the positive instances of a concept from the negative ones. Suppose, for instance, we have arrays of n real financial data. Then, each financial sample is represented by a point in Rn. Suppose that a teacher classifies all these points as being associated with fraud or not, thus creating two sets of points.
The support vector algorithm finds the hyperplane that has the maximum distance from these two sets, and that, accordingly, best separates them.
If such a plane exists (it doesn’t exist if the two sets are intermixed), its equation can be used to forecast if a new financial point is associated with fraud or not.
In text classification and in other problems, planes are not adequate for separating concepts, so a change of variable is performed on the initial data to transform the plane into a different kind of surface. Unluckily, finding the right surface shape for each problem is more an art than a science, and several attempts are needed before reaching acceptable results.
There are theorems stating that specific variable transformation ensures PAC learning with approximation if we have enough examples.
In the next subsection, we will move on to a powerful kind of learning called induction learning, based on learning a function in the form of a small computer program.
Learning small computer programs: induction-based learning
Induction-based learning applies Occam’s Razor principle in its more general form: find a short algorithm that explains the data. In this case, simplicity is represented by program length. The shorter the maximum allowed length, the smaller |F| is. Therefore, we start from a very short maximum length and then increase the length till an acceptable solution is found that matches both the training set and the control set.
Induction can furnish very low |F|, and therefore induction-based learning requires a very low number of examples because it looks for the more general algorithm that generates the example instead of simply interpolating the example points. Unluckily, it is very difficult to learn with induction, since learning can succeed only if we use a programming language that is adequate for the problem we are trying to solve.
In other words, the language used must already contain among its primitives all the main algorithms used in the domain of knowledge it must operate in. Otherwise, the induction learner must discover them from scratch before being able to solve the main learning problem.
Therefore, induction learning is more adequate for maintaining continuously growing computer algorithm libraries for a given knowledge domain than for solving isolated problems.
Let’s look at a simple example of how induction learning works. Which is the simplest function that creates the following sequence?
2 -> 8, 4 -> 32, 5 -> 50, 7 -> 98, 8 -> 128, 10 -> 200
We can use the last three examples as the control set and the first three as the training set.
A few attempts with simple combinations of the four +, / , *, and – operators easily yield a solution that immediately also satisfies the control set:
Y=2X2
Let’s compute the number of examples needed for induction learning. If we set a limit L for the binary length of the algorithm, we have |F|=2L. Replacing this value in Equation [1], we get:
m≥log2L/logC → m≥Llog2/logC
The number of needed examples is always less than the maximum allowed number of bits. If we zip the initial code, we get a smaller algorithm. So, we can also achieve good results with L=100. If all examples use at least 10 different codomain values, we have:
m≥100log(2)/log(10)=100*0.30=30
That is, the algorithm can be found with just 30 examples!
The advantage of induction learning is that it requires few examples, but unluckily it is very difficult to implement.
Induction learning is a code generation problem whose input is not specifications but examples. Like most code generation problems, it can be solved with the planning techniques we analyzed in the previous section. In this case, actions are language statements that operate on data structures.
The general technique for generating an algorithm that conforms with the given samples is as follows:
- Use a planner to achieve the given output for each example starting from the associated input.
- Merge all plans found this way in a single plan by adding
ifstatements and by matching similar actions in the various plans. - Simplify the code with some
if-simplification rules commonly used by compilers. - Infer repeating patterns and transform the repeated instructions into loops.
While steps 1–3 are quite easy to perform since they rely on standard Boolean algebra transformations, loop inference is very difficult. There are no general rules for it, but just heuristics, like the ones that are taught in programming courses.
Learning the structure of a Bayesian network expert system is considered a particular case of induction learning. However, it is quite easy to implement since Bayesian networks have no loops or recursive rule applications, that is, they miss step 4 of the previous recipe. There are efficient and deterministic algorithms based on Bayes theorem for performing Bayesian network learning.
From theory to practice: the role of a software architect in an ML project
After this short description of the main techniques used in artificial intelligence and the basic principles behind machine learning, it is time to understand how you, as a software architect, will act in projects where ML is essential to deliver the best solution for your customer.
Today it is common to hear from customers their desire to deliver a solution where AI is included. As you could see in the sections above, there is no way to do so without data. Machine learning is not magic, and to have a good solution, you must apply science. This is one of the first messages you must transmit to your team as a software architect – there is no ML without planning the way you will have the data needed to achieve the goal of the required prediction. The next subsections will describe the steps needed to deliver a machine learning solution.
Step 1 – Define your goal
The better you describe your goal, the easier you will find a solution. You may find this first step interesting, but unfortunately, you will find people wanting to apply ML without a goal. This is just impossible; defining the goal will ensure success in your development. As a software architect, you are the person to ask this of the customer, product owner, or any other person that wants to apply ML in a system.
In Chapter 1, Understanding the Importance of Software Architecture, we described Design Thinking and Design Sprint to understand the product you are building. This approach can be useful here, since you will find the person to deliver the prediction provided by the machine learning.
Once you have defined your goal, it is time to provide and prepare data that will help you in the process of achieving this goal. Let’s discuss this in the next step.
Step 2 – Provide and prepare data
As we described here, there is no machine learning without data. This means you must properly collect data to enable ML studies. As a software architect, you must coordinate the data engineering process so it gives the best results for data scientists, without causing damage to the solution in production.
We discuss data storage in Chapter 8, How to Choose Your Data Storage in the Cloud. The data engineering process consists of defining the best approach for collecting, storing, and preparing data that will be analyzed. According to the kind of data you have in your project, you must organize a different approach to do so.
The basic concept behind this process is called ETL – Extract-Transform-Load. In Azure, you will find Azure Data Factory is a serverless service for doing so. You can develop solutions with Azure Data Factory using its own interface, .NET, and Python.
Azure Data Factory works by creating pipelines where you get information through datasets, transforming them with activities according to a mapped data flow.
As soon as you are sure you have enough data to start analyzing the problem, it is time to put the data scientist and ML engineers to work, where they will be able to train and deploy the model. This will be better discussed in the next step.
Step 3 – Train, tune, and deploy your model
Assuming you already have the goal defined, and you have got a good dataset for solving the problem, it is time to train your model. This is where data scientists will spend their time.
Today we have an enormous number of solutions that can help data scientists train, evaluate, and tune their models. During this process, the scientist will have to decide the best kind of model that will find the goal solution, where we can number anomaly detection, classification, clustering, recommendation, regression, statistical functions, text analytics, image classification, and cognitive solutions.
This book does not intend to detail each kind of model, but it does indicate that as a software architect, you will encounter them in ML projects. More than that, in an enterprise solution, you may decide on the technology that will be used by the data science team. In this case, you may consider the Azure Machine Learning service. This is the second generation of the service provided by Microsoft Azure. The first one was called Machine Learning Studio.
To create the environment in your Azure account, you must just search for Machine Learning while creating a resource in Azure. There are several steps you will need to follow, which consist of setting up a storage account where the experiments will be stored, Application Insights for monitoring the models, Azure Key Vault for storing secrets to access computers and sensitive data, and Azure Container Registry to store Docker images that will be used during training and deployment. It is worth mentioning that you do not pay for the machine learning workspace itself, but for the computing resources needed to train and deploy the models.

Figure 19.4: Creating a machine learning workspace in Azure
In this new generation, there is also a GUI called Azure Machine Learning Studio, where data scientists and ML engineers can collaborate to deliver a more professional ML pipeline. Once you have created Azure Machine Learning in your Azure account, you will be able to access the GUI at https://ml.azure.com/.
It is important to say that, once they have a model trained with substantial results, ML engineers take the action of deploying this model, so that the solution can effectively access this information. The good thing about Azure Machine Learning Studio is that it delivers tools for both training and deploying a model. This collaborative approach is where Microsoft works better, since many other tools can do the same thing, but not in a connected way like what Azure Machine Learning Studio offers.

Figure 19.5: Azure Machine Learning Studio
The most common way to deploy trained models is by delivering a Web Service API, which can be handled by any kind of application. Once the model is deployed, you can go to the last and more desirable step, which includes testing the results in an application.
Step 4 – Test the trained model and feed back on it
In most scenarios, the trained model is a unit that includes a public function that receives the data input to predict the expected data output with a percentage of accuracy. This means that, from a developer perspective, the result of a machine learning process is a single call in a method, which can be exposed in an encapsulated class or an API, deployed as a web service in a container.
As a software architect, one of the major concerns you will have will be exactly where this unit is. In some scenarios, there is no way to have the prediction method in the cloud, basically because of latency or costs. So, you will need to choose the best solution according to the requirements provided.
Besides, you will also be responsible for clarifying that ML models have an error rate. To reduce it, you will also need to design a solution that can provide feedback to data scientists, so they can improve the model they are designing. Therefore, we can consider ML projects as a continuous improvement solution.
ML.NET – Machine learning made for .NET
Especially for developers, the usage of the Azure Machine Learning service can be considered too far from their reality. For this reason, in 2018, Microsoft made a project public that it has been working on since 2002, in the Microsoft Research team. This project is called ML.NET.
ML.NET is an open source and cross-platform machine learning framework supported on Windows, Linux, and macOS where we can use C# or F# as the primary language for preparing data, training, tuning, and deploying machine learning models. You can also make predictions using the trained model result.
It delivers a bunch of algorithms and tasks to train a model. With this structure, ML.NET can deliver solutions for sentiment analysis, topic categorization, price predictions, customer segmentation, anomaly detections, recommendations, and ranking. It can import OMNX and TensorFlow deep learning models for image classification and object detection, and it also has tools to transform data and evaluate the model created.
You will find plenty of ML.NET samples at https://github.com/dotnet/machinelearning-samples/
The trained model is basically a ZIP file that can be loaded in .NET applications, which enables its use in any x64 or x86 processor running web apps, services, microservices, desktop apps, Azure functions, and console applications.
The good thing is that the ML.NET team has created a tool that enables an easier way to create trained models, considering you already have a data model designed. This tool is called ML.NET Model Builder and we are going to use it in the WWTravelClub scenario in the next section.
ML.NET Model Builder
ML.NET Model Builder is a user interface that helps us out with the creation of ML models inside Visual Studio. You can add this tool by managing Visual Studio extensions.
Figure 19.6: ML.NET Model Builder extension
For the scenario we are going to follow during this section, we will remind ourselves of one of the desires from the WWTravelClub case – place recommendations. The data structure that we have in this scenario is described below.

Figure 19.7: WWTravelClub data structure
This data structure is represented by three CSV files in the demo: places.csv, users.csv, and ratings.csv. The main CSV file that will be used for the training is ratings.csv. All these CSV files can be found at GitHub in the chapter project sample called Recommendation. Using the console app as the basis, you can select to add a machine learning model to your project as shown in the screenshot below.

Figure 19.8: Adding a machine learning model
As soon as you select adding an ML model, the next screen will appear, asking you to define which scenario you want to build. As you can see in the screenshot, there are several scenarios where you can use this Wizard. For the demo we are building, you can select the Recommendation option.

Figure 19.9: Selecting a machine learning scenario
Depending on the scenario you have chosen, the training environment will change. For instance, Object detection will require an Azure training environment, while Image classification will let you decide between the local and an Azure environment. For the Recommendation scenario, we only have the Local option to process the training.

Figure 19.10: Selecting the training environment
As soon as you decide on the environment, it is time to define the data that will be used to train the model. You may choose between a text file or a SQL Server table. There is some advice for each column desired in this interface that can help you out with the decision of which ones you will select to get the prediction you have as a goal. You may also ignore columns from the dataset that are not important for the training, using the Advanced data options link.
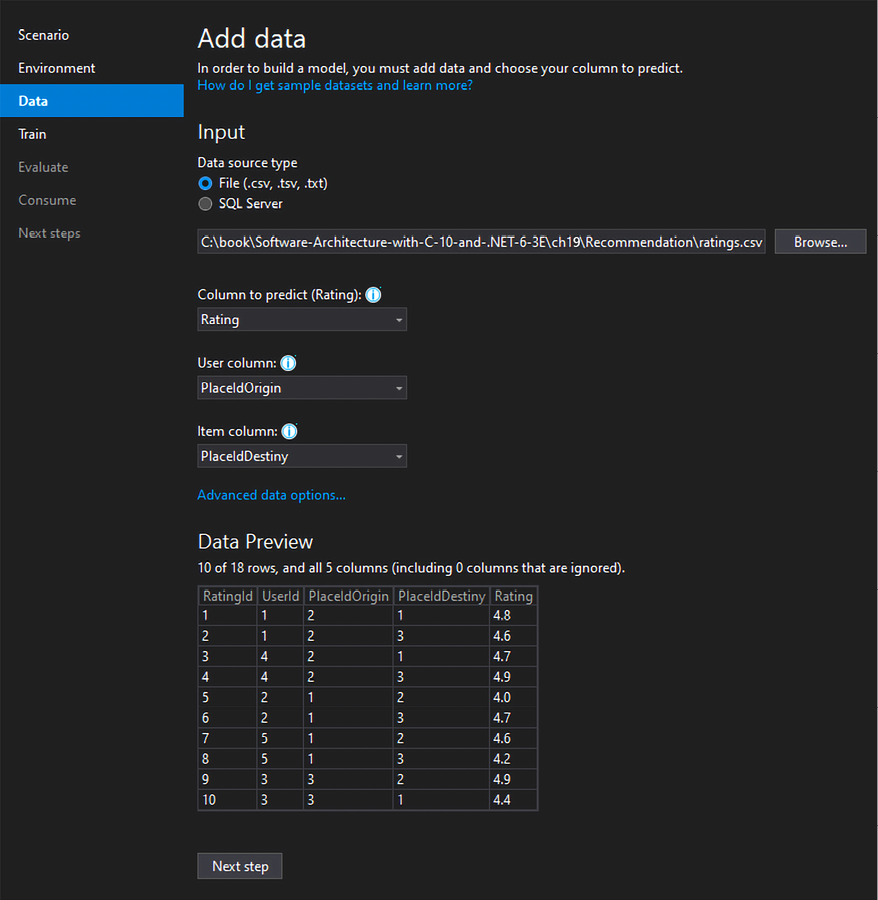
Figure 19.11: Defining the data information
The training itself is the next step and as soon as it closes, you will receive a resume of what has happened during the period you spent training. The more data that you have, the more it takes to have the model trained. It is worth mentioning that ML.NET Model Builder will explore more than one model during its training process, so you will have the best option decided by the wizard.

Figure 19.12: Model being trained
The wizard also gives you the possibility to evaluate the results of the model you have trained, so you can check the consistency of the data you have provided and the results that were predicted.

Figure 19.13: Trained model evaluation
And to finish, the model gives you an opportunity to create your console app or Web API from a project template. It is worth mentioning that the Web API template already considers .NET 6 as a platform.
Figure 19.14: Project template for creating a console app/Web API
The template itself already inserts Swagger documentation, described in detail in Chapter 13, Applying Service-Oriented Architectures with .NET. With small adjustments, you have an API that can predict how well a person who has visited a place will rate a trip to a second place, according to the former experiences of other users from the original place. This shows how useful ML can be to deliver a better experience to the end user. And this also shows how useful ML.NET can be for developers.
Summary
In this chapter, we gave a short description of the main techniques used in artificial intelligence, one based on symbolic reasoning and one based on neural networks and other numeric techniques.
Then, we explained the basic principles behind machine learning and described various kinds of learning, and then focused on supervised learning and discussed how to verify if we have enough examples for our learning task.
Later, we described in more detail learning techniques adequate for learning smooth functions, focusing on neural networks and on the support vector algorithm, and then techniques based on induction.
Then we presented four steps to turn machine learning projects into practical software solutions, especially using the Azure Machine Learning service.
Finally, we presented an alternative to Azure Machine Learning – using ML.NET, especially by using ML.NET Model Builder, which is a great tool for easily creating models for console and API predictions.
Questions
- What search techniques are fundamental in artificial intelligence?
- Since induction learning requires fewer examples, why don’t we use it in all problems?
- What is the main advantage of neural net expert systems and Bayesian networks over classical expert systems?
- Is it true that layered neural nets can approximate any real-valued continuous function?
- Is it true that layered neural nets’ learning always converges toward the best solution?
- What are the 4 steps for turning an ML project from theory into practice?
- How can ML.NET help developers to deliver machine learning solutions?
Further reading
With regard to artificial intelligence and machine learning in general, instead of listing hundreds of references, we simply recommend Russel and Norvig, Artificial Intelligence, a modern approach, PRENTICE HALL, and the references reported there.
For information on the ATMS, it is not available in books or on websites, but most papers on it are collected in issue 28 (1986) of Artificial Intelligence.
The following are some books and links you may consider reading to gather more information in relation to this chapter:
- https://dotnet.microsoft.com/apps/machinelearning-ai/ml-dotnet/model-builder
- https://dotnet.microsoft.com/apps/machinelearning-ai/ml-dotnet
- https://azure.microsoft.com/en-us/services/machine-learning/mlops/
- https://docs.microsoft.com/en-us/azure/data-factory/
- https://docs.microsoft.com/en-us/azure/machine-learning/overview-what-is-azure-machine-learning
- https://dotnet.microsoft.com/learn/ml-dotnet/what-is-mldotnet
- https://docs.microsoft.com/en-us/dotnet/machine-learning/
- https://docs.microsoft.com/en-us/dotnet/machine-learning/how-does-mldotnet-work