
2.5. Design and Test Driven Development
As we've said, TDD is not about testing; it's more of a design technique. But how can writing tests before you write the code encourage a good design? Simply taking the time to stop and think before you write code can have a huge impact on the design of a system. This leads to an important question: what is a good design?
Well-designed software is the subject of many different books. However, we follow a core set of concepts focused on the SOLID principles outlined by Robert Martin (a.k.a. Uncle Bob). SOLID is a set of five principles based on the best practices for object-oriented development.
The SOLID design principles started as a reply to a 1995 newsgroup thread entitled "The Ten Commandments of OO Programming." This reply was formed by Robert Martin (Uncle Bob), and has become a great set of standards that many developers follow.
The principles encompassed in SOLID have been around for years, but many developers tend to ignore these principles that have been proven to aid in creating great software.
2.5.1. S — The Single Responsibility Principle
"There should never be more than one reason for a class to change."
—— Robert Martin (Uncle Bob) http://www.objectmentor.com/resources/articles/srp.pdf
The first principle defined in SOLID is that each class should have a single responsibility. A responsibility is defined here as being a reason to change. If a class has multiple responsibilities, then there are multiple reasons why it could change. If each class only has its own responsibilities, then they will be more focused, isolated, and easier to test as a result.
For example, consider the Customer class in Figure 2-2.
Figure 2-2. Customer class model with multiple responsibilities

This class has two different responsibilities which breaks this principle. One role for the Customer class in Figure 2-2 is storing the domain information about the customer, for example their name and address. The second role is the ability to persist this information. If you wanted to add more information about the customer, then that would cause it to change. If you were to change the way you persisted the customer, then that would also cause the same class to change.
This is not ideal. Ideally, there would be two separate classes with each focused on their own roles in the system, as shown in Figure 2-3.
Figure 2-3. Customer class and Repository class model each with separate responsibilities
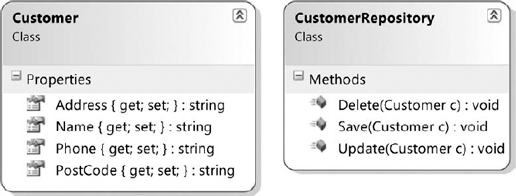
Figure 2-3 splits the original design into two classes. The system is now more isolated and each class focuses on its own responsibility. As your system is now more decoupled, if you wanted to change how you persisted a Customer object you would either change the CustomerRepository object or create a separate class without having to modify the Customer class.
When you attempt to understand a class to modify it, you tend to attempt to understand all the roles a class performs as a whole, even if there are a lot of roles. It can be a daunting task to be faced with a new section of the system because there is so much to understand. If your classes were more isolated, with correct responsibilities, then your code would be easier to understand because you would be able to process the information in small chunks.
From the viewpoint of TDD and testability, the tests you write are now more focused. If you wanted to test either a Customer object or an object dependent on the Customer object, you wouldn't need to be concerned with the persistence side. If you had to initiate a database connection every time you created a Customer object, then your tests would become more heavyweight and take much longer to execute. As with the code, the tests that are created for these objects are now also easier to understand due to the more focused isolation.
However, one of the difficult facts about this principle is identifying the actual requirements. As mentioned, the Single Responsibility Principle defines a responsibility as a "reason for change." If you look at a class and can identify more than one reason why it might need to change, then it has more than one responsibility.
2.5.2. O — The Open Closed Principle
"Software entities (classes, modules, functions, etc) should be open for extension but closed for modification."
—— Robert Martin (Uncle Bob) http://www.objectmentor.com/resources/articles/ocp.pdf
This principle is focused on creating decoupled, extendable systems so that when changes are required, they can be achieved in an effective fashion with very little impact and overall cost.
The term open refers to the fact that an item should be extendable and abstract. This means that if you need to change some of the behavior of the class, you can achieve it without having to change the code. An example of this is to replace the dependencies of different parts of the system by providing a different implementation or take advantage of inheritance and override selected behavior. To do this, you need to think about extensibility and how your application is coupled together.
The term closed relates to the first principle of the Single Responsibility Principle (SRP): a class should be closed from requiring modifications to be made when adding new or changing functionality. When reviewing your code, if you find that a section of code needs to be changed every time you implement new functionality, then it isn't closed.
In real-world terms, a class can never be closed from modifications; however, you can make huge gains by thinking about how you structure your code so that it is as closed as it possibly can be. Remember that SOLID is a set of principles, not hard and fast rules.
First, you'll look at an example which violates the openclosed principle, as shown in Figure 2-4. Imagine you have a system that needs to decide which company should be used for shipping a particular order. This could be based on a number of different criteria; however, in this example it is simply based on the postcode.
Figure 2-4. Order and OrderShipper class model

In this first example, you have an OrderShipping. The special casing of the terms already clues the reader in to the fact that they are methods and objects with a method called ShipOrder. Based on the Order object, this method decides which company is the most appropriate and starts processing the shipment:
public void ShipOrder(Order o)
{
int i;
if(o.PostCode.StartsWith("A"))
{
//Do processing for CompanyA
}
else if (o.PostCode.StartsWith("B") || int.TryParse(o.PostCode, out i))
{
//Do processing for CompanyB
}
else if (o.PostCode.StartsWith("C"))
{
//Do processing for CompanyC
}
}This method has a number of problems. First, it's breaking the first principle of SRP, but more importantly it is an expensive design to work with when you want to make changes. If you wanted to add a new shipper to the list, you would have to add another additional if statement to the list. If one of your existing shippers changed the rules, then you would need to go back and modify this single method. Imagine if the system grew from three shippers to a thousand shippers. This single method will soon become uncontrollable, not maintainable, and as a result a lot more likely to contain bugs.
Here's the same scenario, but following the openclose principle instead.
In Figure 2-5 you can see that the shipping process has been decoupled. Every company now has its own object within the system, associated together by a common interface. If a new shipper needs to be added, you can simply create a new object and inherit from this interface.
Figure 2-5. Decoupled class model

Each of the objects implements two methods: one is based on whether they can ship the order, and the other is based on processing the actual order. The CanHandle method takes the logic from the previous example and has extracted it into its own class and method:
public bool CanHandle(Order o)
{
if (o.PostCode.StartsWith("A"))
return true;
return false;
}Also, Figure 2-5 introduces a ShipmentController. This simply asks all the shippers if they can ship the order; if they can, the controller then calls Process and stops:
public void ShipOrder(Order o)
{
foreach (var company in shipmentCompanies)
{
if (company.CanHandle(o))
{
company.Process(o);
break;
}
}
}The resulting code is not only more readable and maintainable — it's also more testable. The logic for each company can now be tested in isolation to ensure it meets the correct requirements, and you can test that the ShipmentController is correctly calling the items by using a stub IShipper object. Stubs is a concept that we'll cover later in the Stubs and Mocks section. For now, simply by following this principle, you have made your tests easier to write and maintain and have improved the quality of the code.
Although you have improved the code, there are still problems. If you add a new shipper, you'll need to inform the ShipmentController about the new shipper. This is far from being a disaster, because you could implement support for automatically identifying all the shippers within the system. But you need to weigh this option against the cost of implementation, testing, and maintenance to decide if this would be worth the effort, compared to manually editing the constructor of ShipmentController.
2.5.3. L — The Liskov Substitution Principle
"Classes must be able to use objects of derived classes without knowing it."
—— Robert Martin (Uncle Bob) http://www.objectmentor.com/resources/articles/lsp.pdf
The Liskov Substitution Principle is based on the concept that all implementations should program against the abstract class and should be able to accept any subclass without side effects. Classes should never be aware of any subclass or concrete implementation, instead it should only be concerned with the interface. The aim here is that you can replace the functionality with a different implementation without modifying the code base.
The example in Figure 2-6 violates the principle. You have a simple string formatter and all the formatters inherit from IFormatter. As such, you should be able to use any formatter in exactly the same fashion.
Figure 2-6. Class diagram of principal
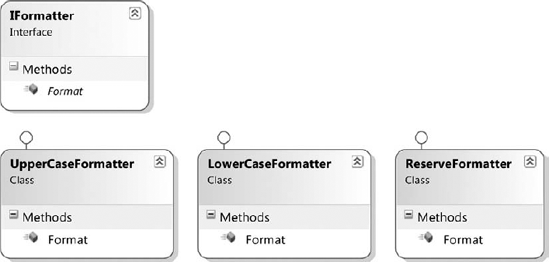
However, the Format method for each class handles empty strings in a slightly different way. For example, the uppercase formatter is shown next:
class UpperCaseFormatter: IFormatter
{
public string Format(string s)
{
if(String.IsNullOrEmpty(s))
throw new ArgumentNullException("s");
return s.ToUpper();
}
}Although many might consider throwing an exception to be bad practice, in the right scenario this could be acceptable. However, for the lowercase formatter in the same scenario it would return null:
class LowerCaseFormatter: IFormatter
{
public string Format(string s)
{
if (String.IsNullOrEmpty(s))
return null;
return s.ToLower();
}
}This breaks the principle. The expectation of how you expect the implementations to work is different. Imagine if you had a large number of different implementations, each behaving slightly differently: your implemented code would be chaos. Instead, you want a consistent view of how the code should work with each implementation being constant. For example, it should return String.Empty:
if (String.IsNullOrEmpty(s)) return String.Empty;
Another common cause for breaking this principle is when implementers demand more information than stated by the method signature or interface. In the following class, the correct interface has been implemented, but a new public property has also been added for total width:
class PaddingStringFormatter: IFormatter
{
public int TotalWidth { get; set; }
public string Format(string s)
{
return s.PadLeft(TotalWidth, '_'),
}
}When a developer comes along who wants to use the previous class, they need to cast the formatter argument down to the concrete instance. I'm sure you've encountered code similar to this before:
class Implementor
{public void OutputHelloWorld(IFormatter formatter)
{
string s = "Hello World";
PaddingStringFormatter padder = formatter as PaddingStringFormatter;
if(padder != null)
{
padder.TotalWidth = 20;
s = padder.Format(s);
}
Console.WriteLine(s);
}
}Ideally, you want to move away from code such as this, because it causes a lot more coupling to occur. When it comes to testing, it is also much more difficult, because you need to be aware of the internals of a method and how this affects execution.
The Liskov substitution principle was introduced by Barbara Liskov during a 1987 keynote titled "Data Abstraction and Hierarchy." In 1968, Liskov was the first woman in the United States to be awarded a Ph.D. from a computer science department (Stanford University). More recently, Liskov was awarded with the 2008 Turning Award for her contributions to practical and theoretical foundations of programming languages and system design.
2.5.4. I — Interface Segregation Principle
"Clients should not be focused to depend upon interfaces that they do not use."
—— Robert Martin (Uncle Bob) http://www.objectmentor.com/resources/articles/isp.pdf
This principle states that interfaces should have high cohesion to allow clients to keep their implementation as minimal as possible. Simply put, clients should not be forced to depend upon interfaces that they do not use.
This principle is often broken without people realizing about the possible implications. For example, it's often broken in parts of the .NET Framework, particularly ASP.NET. The main cause of this principle being broken is when a particular interface is too large with too many unrelated methods. As a result of implementing a simple interface, the concrete implementation must implement nonrequired methods to get the desired effect.
The result of heavy interfaces is a large amount of unwanted boiler plate code, making your objects move heavyweight and memory intensive. The interfaces also tend to be more confusing making it more difficult to know which methods you use.
In an ideal scenario, your interfaces should be lightweight and simple to implement allowing for an accurate description of what the class actually does. As with before, let's start with a simple example that breaks this principle, as shown in Figure 2-7.
Imagine you have extended your shipment options.
Figure 2-7. Two implementations of the IShipper interface

Next you can see the ability to add some personalization to an item:
interface IShipper
{
bool CanHandle(Order o);
void Process(Order o);
void AddGiftWrapping(Order o);
void HandDeliver(Order o);
void AddSpecialMessage(Order o, string message);
}The previous listing looks similar to a sensible interface. It defines what a shipper might have to do. However, if you look at the implementation you will notice the problem. Although your PersonalShipper object is fine, because the object requires all the methods to fulfill all the different options, your GenericShipper object doesn't offer any customization, but is still required to implement those additional methods. The result is that the code is littered with the following methods, which throw a NotSupportedException exception:
public void HandDeliver(Order o)
{
throw new NotSupportedException("We do not support this option");
}As the principle states, your GenericShipper object is dependent upon methods that it does not require. Ideally, you want to separate out the interface into two objects: one for the generic shipper and one for a shipper that supports personalization (as shown in Figure 2-8).
Figure 2-8. Shipper implementations with focused interfaces

With the two separate interfaces, it becomes easier to see what each shipper actually provides in terms of functionality. You have seen the distinction between PersonalShipper and GenericShipper very clearly from looking at the Classes interface. Although the implementation of PersonalShipper is identical, apart from implementing the new IPersonalisedShipper, your GenericShipper code is much shorter and simpler to maintain.
Although this principle is great from the code point of view, how does it affect testing and testability? As your interfaces are more focused, your client classes are also more focused, and as a result you do not have as much code to test. Before, you would have had to test the nonrequired methods and hence waste time or leave them untested, which affects your code coverage.
2.5.5. D — The Dependency Inversion Principle
"A. High-level modules should not depend upon low- level modules. Both should depend upon abstractions.
B. Abstractions should not depend upon details. Details should depend upon abstractions."
—— Robert Martin (Uncle Bob) http://www.objectmentor.com/resources/articles/dip.pdf
When developing your system, if you have considered the other four principles you would have a decoupled and isolated system. However, at some point, all your isolated components will need to talk to each other. In the situation where you have dependencies within your system, you should then use abstractions as a way to manage them. By depending upon the abstractions and not the concrete class, you can interchange implementations when required.
The first term that needs to be defined in more detail is dependency. What is a dependency? In the context of this book, dependency is a low-level class that a higher-level class must use to fulfill its requirements. A simple example is that a text formatter shouldn't be concerned with how to actually obtain the text; if the formatter could only process text from a file called MyImportantDocument.docx, it would be extremely limiting. The formatter should be flexible enough to cope with many different ways of obtaining the text. By removing this lower-level dependency, your higher-level formatter can be more effectively reused.
The inversion part simply says that the dependency should come from outside and be placed into the class to use. Generally dependencies are created inside other classes and as such are closed. Inversion simply states that the dependency should be created outside the class and injected in.
A common example of this is the business logic and data access problem. You have two separate, isolated parts of the application that need to talk to each other. A common pattern is that the business logic would have created an instance of the DataAccess class and callmethods on it as represented in Figure 2-9.
Figure 2-9. Business Logic with an implicit link to DataAccess
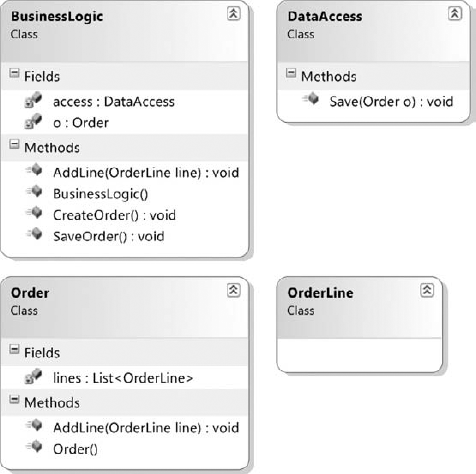
The constructor of the BusinessLogic class would reassemble the following listing:
private DataAccess access;
public BusinessLogic()
{
access = new DataAccess();
}A developer using the BusinessLogic class would have no idea how, or even if, the underlying system was accessing data until something went wrong. This common pattern is far from ideal. You want the dependency to be very clear, but also in control of the object which requires the dependency.
An improved example would look similar to Figure 2-10.
Figure 2-10. Dependency has been split and now explicit
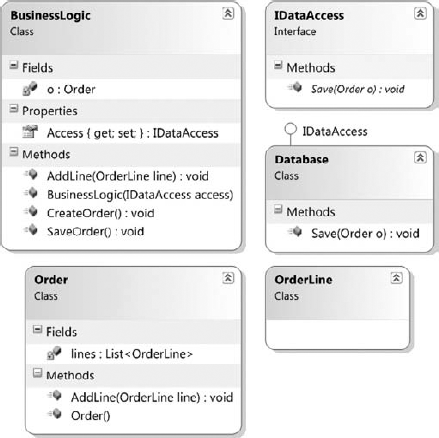
Next, a new interface for defining a DataAccess object is included, as this allows you to have different implementations of the data access. In this case, you simply have the Database class. Your BusinessLogic class has a constructor that takes in an IDataAccess object as shown next:
public IDataAccess Access { get; set; }
public BusinessLogic(IDataAccess access)
{
Access = access;
}Now, the higher-level business logic does not depend on concrete implementation of the lower-level Data Access class.
From the point of view of an implementer of the BusinessLogic class, the dependency is quite apparent. There is a clear boundary between the two different parts of the system. Sometimes dependencies can hide themselves in unusual ways until they start to cause major problems. This is one example of where TDD can identify your dependencies much earlier in the process and change the way you develop software. As you want your unit tests to be nicely isolated and focused, you will find that if you are greeted with a dependency on a more complex or external part of the system then your tests will become much more difficult to write. When you see this issue in your tests, then you will know that you need to do something about it.
In this scenario, if you abstract and decouple the dependencies the DataAccess layer will no longer cause you problems when testing the BusinessLayer, because your tests will be in control of this external dependency.
However, if you have isolated all of your dependencies, and the user of the object is responsible for constructing the dependencies, then your code is quickly going to be difficult to manage.
Imagine the following scenario — your business logic code has dependencies on your Data Access layer, a user management system, and your shipment system. The Data Access layer also depends on a configuration object. The class diagram would look similar to Figure 2-11.
Figure 2-11. Decoupled system design with multiple dependencies
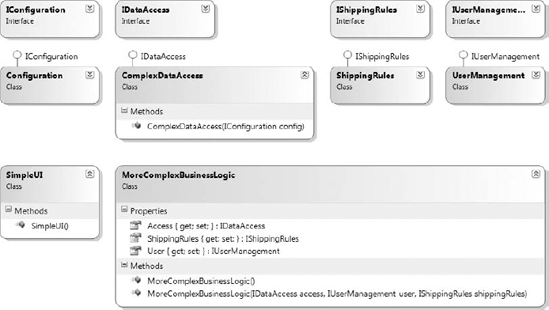
This is a well-designed, decoupled system. In theory, it should be good. However, if you need to construct a BusinessLogic class, then the code would look like this:
internal class SimpleUI
{
public SimpleUI()
{IConfiguration config = new Configuration();
IDataAccess access = new ComplexDataAccess(config);
IUserManagement management = new UserManagement();
IShippingRules shippingRules = new ShippingRules();
MoreComplexBusinessLogic logic = new MoreComplexBusinessLogic(access,
management, shippingRules);
}
}You can imagine that this would soon become extremely difficult to manage. If you introduced a new dependency, you would have to change a lot of the code. You could introduce a helper method, or you could have a parameter default constructor, which automatically defines the default objects to use:
internal class MoreComplexBusinessLogic
{
public IDataAccess Access { get; set; }
public IUserManagement User { get; set; }
public IShippingRules ShippingRules { get; set; }
public MoreComplexBusinessLogic(IDataAccess access, IUserManagement user,
IShippingRules shippingRules)
{
Access = access ?? new ComplexDataAccess(new Configuration());
User = user ?? new UserManagement();
ShippingRules = shippingRules ?? new ShippingRules();
}
public MoreComplexBusinessLogic(): this(null, null, null)
{}
}Managing dependencies via constructor overloading is bad! This is because you still have all the problems you had before as the concrete dependencies are still being hidden. If you removed or changed the ShippingRules object, then this constructor would break — even if you never used the overloaded version. It also causes confusion as you will never be 100 percent sure of which default implementation is being used and if that is even the correct set of objects to use. The result could be that the system only fails at runtime. The only advantage is that you can construct a new BusinessLogic with a single line of code, and this is still not a good enough reason.
Yet, you do want to be able to easily add new dependencies into a system without having to go back and update all the construction set-up code that you want to be a single line. The answer to this problem is to use an Inversion of Control, IoC, framework to support this scenario.
Inversion of Control is another one of those principles that has been around for years. A Google search will turn up a bunch of IoC frameworks for the .NET platform, but you don't have to download a large framework that someone else developed to take advantage of IoC. There are many situations where developers cannot use an open source framework. Because IoC is a pattern, don't be afraid to create your own framework.
As with unit testing frameworks, there are a number of different IoC frameworks, each targeting and solving a particular problem in a particular way, yet the core concept is the same. In the next few examples we will be using a very simplistic 33 line IoC framework created by Ken Egozi.
The first major concept with an IoC has to do with the ways you set up your configuration and the mapping between the interface and concrete implementation. You should simply register all the interfaces using generics. The Register method will keep the mappings in memory, so this method only needs to be called the first time your application is initialized:
static class IoCRegister
{
public static void Configure()
{
IoC.Register<IConfiguration, Configuration>();
IoC.Register<IDataAccess, ComplexDataAccess>();
IoC.Register<IUserManagement, UserManagement>();
IoC.Register<IShippingRules, ShippingRules>();
}
}In the UI for this example, the Configure method is called to set up the mappings. You will need to ask the IoC framework to resolve and initialize an instance of the MoreComplexBusinessLogic class. Under the covers, it will resolve all the dependencies for the constructor of each object based on our configuration:
internal class SimpleUI
{
public SimpleUI()
{
IoCRegister.Configure();
MoreComplexBusinessLogic logic = IoC.Resolve<MoreComplexBusinessLogic>
();
}
}The result is that the dependency for the ComplexDataAccess object is automatically resolved. If you want to add a new dependency to the constructor, you would simply need to register it in one location for the rest of the system to pick up and use the new object. This makes managing your dependencies very effective and maintainable.
2.5.6. Do You Need SOLID?
At this point you should have an understanding of the principles that are encompassed in SOLID and how it fits into software development. However, do you need it? Yes, you do need these principles in place because they provide a good definition and guideline for object-oriented (OO) design. Many people claim to understand OO design; however, as you've seen demonstrated previously, many people get it wrong and still don't fully understand what makes for a good OO design. By having the principles in place, you create a foundation to build upon.
It is important to remember that these are just principles and shouldn't be simply followed. It is important to understand them and how they apply to your code, becomes sometimes your requirements force you to break a principle. If you do, you need to understand the problems that might occur and, ideally, look at alternative approaches. Your aim is to make the tests as easy to write as possible. This is why you want to keep your code decoupled. Your tests should also be focused on the functionality of the class: if you see your tests are doing lots of different tasks and functions, your class may have too many responsibilities.
2.5.7. Pair Programming and Technical Code Reviews
Sadly, people don't link TDD to Design, they link TDD to testing. TDD is not about testing; it is about design with the tests being a nice side effect. When you're creating your tests, if you don't stop and look at the code in a critical way, you miss a large part of the advantage of TDD. Two concepts that support this process are pair programming and technical code reviews.
Pair programming is focused on two developers sitting at the same workstation helping each other write a certain piece of functionality. One person is typing the code, while the other person is reviewing. The person typing, often called driving, can focus on the code, while the second person can focus on the overall picture, making sure the coder hasn't missed anything and thinking about what is required next. If the reviewer thinks they have a better idea for the implementation, they can swap roles. Swapping roles frequently is an important part of pair programming, with each of the two developers writing code and touching the keyboard. The advantage here is that the developers share their experience and learn together. If you have inexperienced members on the team, getting them to pair program can increase their confidence and experience more quickly than if they were left on their own. It's important to note that pair programming is not just for junior/senior combinations. The spirit of pair programming is that two sets of eyes/brains are working on a problem and therefore are able to help each in a direction that a single mind might not have taken.
Even when pair programming, the code should still be written using TDD. And there are all kinds of different techniques to use: one very popular technique is that one person writes the test while the other person implements the code to make the test pass. All the same coding and design principles apply; there is just the benefit of two heads working on the code, which should result in fewer defects and more code maintainability.
Another technique, often overlooked with pair programming, is that of code reviews. Although pairing is a targeted form of code review, a larger technical code review should still be performed. Code reviews are useful points within the project where you can sit as a team and review the tests and the code. It is an opportunity to look at the big picture while still focusing on the implementation and finer details. The aim should be to identify and remove code smells. Smells are parts of the code that don't feel right, go against the SOLID principles, and generally show that the code has not been designed in the best possible fashion.
During the review, the tests can help guide the process providing documentation about how the code is expected to work. This is also a good time to verify that the tests are being developed correctly.
2.5.8. Test Smells
Similar to the previously defined code smells, there is also the concept of test smells. As with code smells, test smells indicate a problem with your test code. There are varieties of different issues that can affect your test code, some affect the maintenance but others affect the reliability of your tests.
The most common problem is related to the reliability of the tests. As mentioned before, you need confidence in your tests. However, one of the most serious test smells, referenced to as fragile tests, can make you lose this all-important confidence.
2.5.8.1. Fragile Tests
The term fragile test covers a large number of different problem areas, yet the core result is a loss in confidence and increased maintenance with decreased productivity. Fragile tests are one of the main areas why people fail to see the benefit in unit tests.
A common scenario is when tests fail because of the outside environment. This could be due to particular files required to be in a particular location with certain data, for example, configuration files or image files that have to be loaded. When you have this situation, developers may be unaware of the dependent test and change the test file or simply remove it without realizing what they are doing.
Other problems exist when the tests need to interact with external services. External services could range from online web services to inhouse messaging services, but essentially is a service beyond the control of the unit test and the system. When tests have to deal with these services they are at risk of failing because either the service was down or there were network issues or latency issues. When a test fails for this reason, it can be extremely difficult to identify the reason. Sometimes the test will pass, and other times it will fail. Ideally you should decouple the use of the service, allowing yourself to unit test the system and take advantage of mock objects to replicate the external service together with a separate set of integration tests for end-to-end testing, as covered in Chapter 4. Mock objects are a difficult concept to understand; we will spend some time later in this chapter within the Stubs and Mocks section defining exactly what a mock object is.
Databases are similar to both environment and online services. If your tests interact with a database server, such as SQL Server, it could cause them to become fragile. Databases suffer from various problems, such as a nonexistent database or a changed schema. Also, the server itself might not be accessible, credentials might have changed, or it might have simply crashed — all resulting in the test failing.
Problems are not only with the environment. Sometimes it is due to the way that the tests have been developed, oftentimes being too coupled to your implementation. A common problem occurs when you change a piece of functionality that has a knock on effect for tests in a completely different section. This comes back to dependencies. When your code has lots of layers and is communicating between these different layers, changes can have ripple effects throughout the system. However, it sometimes relates to the fact that your tests are over-specified and are testing too much. If you remember the best practices we talked about earlier in this chapter, each test should focus on one fact. If your tests are over-specified, then each test will verify every aspect of the state of the object. For example, the following test should verify that a user can log in successfully:
[Test]
public void User_Has_Logged_In_Successfully()
{
LoginController c = new LoginController();
bool result = c.Login("username", "password");
Assert.IsTrue(result);
Assert.AreEqual("username", c.Username);
Assert.AreEqual("password", c.Password);
Assert.AreEqual(DateTime.Now.Day, c.LoginTime.Day);
Assert.AreEqual(DateTime.Now.Hour, c.LoginTime.Hour);
Assert.AreEqual(120, c.LoginExpiry);
Assert.AreEqual("Index", c.RedirectPage);
}Although the first three lines of code in the previous listing implement the entire test, the developer has also verified many other aspects of how they expect the controller to work, moving beyond the scope of the test. Even though all these should be tested, they should be separated into different tests. Imagine if every test within your system had the following assertion: by changing the LoginExpiry property, all your tests would fail, and you would have to modify each test manually to reflect the change.
2.5.8.2. Production Bugs
It's extremely difficult to remove every last production bug. Airlines and other mission critical systems put a huge amount of focus and energy on ensuring that no production bugs occur. This level of energy is not generally required for most line-of-business applications; bugs are bad, but they are unlikely to kill anyone. However, the more production bugs that occur, the more our users are going to be unhappy — this will reflect poorly on the development team.
Although we have stressed the fact that TDD is predominantly a design tool, TDD should also reduce the amount of regressions and production bugs. Regressions are bugs that occur after the feature has already been tested, and they are responsible for a large part of the problems with software. Having your test suite in place should allow you to catch these issues as they occur, allowing you to fix the problems before they ever reach the tester or end-user. If you are still experiencing production bugs, it indicates a problem with your existing unit tests.
When production bugs occur, the first area of concern would be if automated tests actually exist for the system. If they do exist, are they focusing on the correct areas of the application? If you are experiencing many regression bugs around a particular area of the system, it suggests that it may be a good area to provide extra coverage.
Another problem that can cause production bugs is when the tests have been created but they are either not verifying the correct part of the system, or they are not self-verifying. Even if the code does not work, the tests would never alert you to the problem. This is a problem because it gives you false confidence in your system that results in you performing less manual testing, which results in the production bugs appearing.
Even if you have your tests in place, if they are not being executed then you will never be aware of the issues they might discover. Developers should be executing the unit tests constantly while they are making changes, together with your build server on every commit. If a test does fail, then you should react quickly and fix it as soon as possible. A failing test indicates one of two problems, either your code is wrong or the test is wrong. If the test is no longer valid, change it or remove it. Not having a green bar is a major problem as it leads to the broken windows syndrome.
The Broken Windows SyndromeThis syndrome originally related to crime within urban areas. It states that if a building has a few broken windows then vandals are a lot more likely to cause more damage. The same is true for unit tests, if you have broken tests, then developers are a lot more likely to leave more tests broken. To ensure this does not happen, fix tests as soon as possible. |
If you have failing tests then it is difficult to identify which tests fail for a particular reason. The tests could always have failed, but they could also be newly failing regression tests. The result is that tests might fail without you realizing, resulting in errors being released.
2.5.8.3. Slow Tests
One reason why people do not execute their tests is that they are slow. Slow running tests are a problem because they decrease the motivation for running and writing tests. Writing tests is all about being in the mindset of wanting to write the tests, anything to distract from this mindset is bad. Imagine you were happily writing code, but after every new addition or change to a method you had to wait three minutes before you could continue. Imagine it was not three minutes, but thirty minutes or three hours. You would either only run them once a day, or not run them at all, which would lead to production bugs.
You should be running your unit tests constantly. After every method, you'll want to run your tests to verify it worked and nothing else broke. If you cannot do this, then you are going to lose a lot of the benefit.
With this in mind, how can you ensure your tests are quick, or at least not painfully slow? Tests are slow because they have to access external resources. Limiting the amount of interaction with external resources will keep your tests fast. External resources include the external environment, such as the IO, network, or UI. All these cause delays.
One potential solution to this is to separate your unit tests and integration tests into two separate solutions. Your unit tests can stay fast and focused taking advantage of mocks and stubs, and your integration tests can be used for tests that must interact with the external services.
Slow running tests don't just affect the individual developer — they can also affect the entire team. Because the unit tests should be run as part of every build, if your tests are slow, then your builds will take longer to come through, and it will take longer to determine if it failed. The team will start to dislike you because it will affect their productivity.
2.5.8.4. Long Set-Up Time for Coding
Finally, test smells are not always related to the execution; they can also relate to the development of the tests. This test smell relates to how much effort it takes to have the object constructed in a testable state. You will find that if your system has not been designed with testability in mind, then the amount of set-up code required will overshadow the interaction with the system and the verification that it worked correctly.
This test smell is generally a result of an over-specified test or an over-coupled system. The result may be that the class has too many responsibilities, which results in a lot of set-up code. Other causes could include the set-up of test data, which the test will use when it is interacting with the system.
If all the set-up code is valid then you can limit the fact. By taking advantage of test helper methods, the set-up code can be shared amongst your tests. This has the advantage of reduced maintenance, but will also keep your test readable.
Fundamentally, SOLID is about breaking dependencies within your system. Dependencies are the main reason why people find unit testing and TDD difficult. If you can manage to break down your task and code into small enough blocks, then you will find TDD a much simpler process. As mentioned earlier in this chapter, you still need access to these dependencies when testing. This is where mocks and stubs can help.
2.5.9. Stubs and Mocks
As we briefly mentioned during the section on the SOLID principles, dependencies are a problem. The SOLID principles include techniques and ways of thinking to help us break those dependencies. Stubs and mocks, otherwise known as test doubles, replicate those external dependencies when testing the code that interacts with them.
Going back to the previous Business Logic and Data Access scenario, when you want to test your ProcessOrder method you need an IDataAccess object. The tests want to be in control of this object.
If the tests are not in control of the object, in terms of knowing which methods had been called or what data to return, then you will need to spend a lot of time setting up the environment and running verifications against the Data Access layer to ensure ProcessOrder worked correctly. Ideally you want to know that ProcessOrder correctly called your Save method. You would have other tests focused around the DataAccess object and the Save method. For now, you simply need to verify that the two are communicating correctly and that the logic within ProcessOrder is correct.
This is where mocks and stubs are useful. They allow the test to be in control of the dependency and then verify everything worked as expected. For the system to be in control of this dependency, then it must look like the real implementation. This is achieved by the test double implementing the required interface, in the previous case with IDataAccess. From the viewpoint of implementing code, it would be identical and would treat it the same as if it was the real object. Of course, if you have broken the Liskov Substitution Principle and are attempting to downcast the object to a concrete class, then this will not be possible. After the tests are in control of the double, they can set up the object to behave how it should. For example, this includes setting the expectations for the methods that should be called or setting known return values for certain method calls.
2.5.9.1. The Difference Between Mocks and Stubs
Although mocks and stubs have a similar task, there is an important difference between them. It's very common that these uses are often confused and used in the wrong situation.
A stub object is the simpler of the two objects. The role of a stub is to simulate input and allow the method or class under test to perform a desired action. Stubs are more about enabling something to happen. For this reason, stubs are generally used for state verification. Your test will create your stub, inject it into the class under test, and perform the desired action. Under the covers, your class will interact with the stub and as a result be in a different state after it has finished. This state could be setting a property or returning a particular return value. The test can then verify that the object is within the expected state.
To create a stub, you don't need a powerful framework or special technique. All you need to know is the interface or abstract class you want to stub and how to inject it into the class under test, be it via the constructor or a public property. The following is a classic example of how a stub might work:
[Test]
public void ProcessOrder_sends_Email_if_Order_Is_Successful()
{
StubMailServer stub = new StubMailServer();
BusinessLogic b = new BusinessLogic(stub);
b.ProcessOrder(new Order());
Assert.IsTrue(stub.MessageSent);
}public class StubMailServer: IMailServer
{
public bool MessageSent {get; set;}
public void Send(string to, string message)
{
MessageSent = true;
}
}Another possible use of stub objects is to make existing objects easier to test by overriding their default behavior. Given the previous example, you could have implemented your stub object similar to the StubMailServer example. This would have allowed you to keep the rest of the class intact, but replacing the specific part that interacted with the external system, which caused the system to be harder to test:
public class StubMailServer: RealSmtpMailServer
{
public bool MessageSent {get; set;}
public override void Send(string to, string message)
{
MessageSent = true;
}
}One problem with having a manually created stub for each object is that it can be expensive to maintain. Most of the mocking frameworks we will discuss can also create stub objects using a similar API to the mock object.
A mock on the other hand is a lot more powerful. A mock object provides the same functionality of a stub in terms of returning known results, but mock objects also record the interaction that the class under test performs. The mock objects remember all method calls, arguments provided, number of times a method has been called and the order, along with many other properties. The result is that the test has a huge amount of information that it can use to verify that the system is working as expected. With a mock, you set up your expectations about how you predict your class to interact with the external dependency, which will be the mock. If the class does not interact with the mock in the way it expects, the test will fail. For this reason, mocks are generally used for behavior verification. Behavior verification is verifying that the class under test interacts and behaves with your mock object in the way you expected. Mocks and behavior verification are often used when the state cannot be verified.
Unlike stubs, mocks are created using frameworks to enable them to have the additional functionality previously described. The framework will be responsible for constructing the mock object, remembering the interactions, and verifying that they are correct.
For example in the following listing, you ask the mocking framework to generate an instance of an object which inherits from a particular class — in this case the Mail Server interface. The second line defines how you expect the object to be used. Finally, the last line verifies that all the expectations that were previously defined were met, after you have interacted with your object under test:
IMailServer mock = MockRepository.GenerateMock<IMailServer>();
mock.Expect(m => m.Send("Test User", "Order Confirmed"));
mock.VerifyAllExpectations();Given this, a test which uses a mock object might look something similar to this:
[Test]
public void ProcessOrder_sends_Email_if_Order_Is_Successful()
{
Order order = new Order {To = "Test User"};
IMailServer mock = MockRepository.GenerateMock<IMailServer>();
mock.Expect(m => m.Send("Test User", "Order Confirmed"));
BusinessLogic b = new BusinessLogic(mock);
b.ProcessOrder(order);
mock.VerifyAllExpectations();
}For the test to pass, the ProcessOrder information would need a method implementation similar to the method in the following listing:
public void ProcessOrder(Order order)
{
MailServer.Send(order.To, "Order Confirmed");
}With this in place, the test would pass. If something changed and the expectations were not met, an expectation would be thrown when you call VerifyAllExpectations, which would cause the test to promptly fail.
With the previous test, a framework called Rhino Mocks was used to create the mock object. Rhino Mocks is an extremely popular open source framework. The framework has two different types of syntax for creating and managing your mock objects; the first is Arrange Act Assert (AAA) with the second being RecordPlayback.
2.5.9.2. Rhino Mocks
The AAA syntax was introduced in Rhino Mocks 3.5 and takes advantage of C# 3.0 features such as lambda expressions and extension methods to improve the readability of your test code when creating mock objects.
Before we hop into Rhino Mocks, let's first define a few C# 3.0 features that help make Rhino Mocks possible. Lambda expressions simply put are anonymous functions that create delegates or expression trees. Extension methods allow you to define additional methods on existing objects without having to subclass the object. This means you can add additional methods without affecting the actual object; however, when reading the code it feels much more natural and human readable.
When using mock objects, the most common use case is to define expected behavior on method calls returning known result values. Using the AAA syntax, an example of defining expectation would be as follows:
ICalc mock = MockRepository.GenerateMock<ICalc>(); mock.Expect(m => m.Add(1, 1)).Return(2);
With this example, we asked the RhinoMocks MockRepository to generate a mock object which implements the ICalc interface. Due to the namespaces included, the mock objects have a set of extension methods added to them which were not on the original interface. The Expect method allows you to define the method calls in which the object should expect to receive. Rhino Mocks uses the concept of fluent interfaces to join method calls together. The aim is that the method calls should be more human readable as they should flow as a natural language. In this case, the return result of Expect has a method called Return, which we then call with the argument of 2.
If you now call the mock.Add method with the arguments 1,1, then the value returned will be 2:
Assert.AreEqual(2, mock.Add(1,1));
If you call the mock object with another value, then it will cause an error because the test was not expecting that to happen and as such it should fail the test. This is one of the advantages of a mock object in that it is testing the behavior and the interactions between the class under test and the mock.
Finally, calling VerifyAllExpectations will verify that the previous exceptions were met — for example, the method was called as you expected:
mock.VerifyAllExpectations();
In certain situations, for example simulating faults when a method is called, you might want to throw an exception instead of returning a value. With the AAA syntax this is very simple. By using the Throw extension method, you can define the exception which should be thrown from the mock object:
mock.Expect(m => m.Divide(0, 1)).Throw(new DivideByZeroException("Error"));When it comes to properties and events you need to use a slightly different syntax. First, you need to tell Rhino Mocks to treat the value as a property and then set the value of the property as normal. The next time you call the property, it will be treated as a mock value:
SetupResult.For(mock.Value).PropertyBehavior(); mock.Value = 2; Assert.AreEqual(2, mock.Value);
With events, you need to first gain access to the event raiser — in this case the event is called Event — and then use the Raise event passing in the values for the event itself:
mock.GetEventRaiser(v => v.Event += null).Raise("5");The other approach with Rhino Mocks is the Record and Playback model. This is a two-stage process; the first stage is Record. This is where you define how you expect the mock to be interacted with. The second stage is Playback — this is where you place your test code and it interacts with the mock object. To make this code easier to understand, it's beneficial to add a using statement to define the scope of the Rhino Mock recording session. This is because the internal stages that Rhino Mocks uses to signal the change between recording and playback is automatically called, as is the statement to verify the expectations that occurred. To manage the state, a MockRepository object is required.
An example of a test using the Record and Playback approach follows. Here you are defining the expectations of how Add should work within the Record using statement. Within the playback section, you have our test and assertion code:
MockRepository mocks = new MockRepository();
ICalc mock = mocks.CreateMock<ICalc>();
using (mocks.Record())
{
Expect.Call(mock.Add(1,1)).Return(2);
}
using (mocks.Playback())
{
Assert.AreEqual(2, mock.Add(1,1));
}With this in place, you can begin using Rhino Mocks with either syntax to begin mocking your complex external dependencies. However, Rhino Mocks has some limitations on the type of objects it can mock. First, it can only create mock objects for interfaces and abstract classes. Rhino Mocks is unable to mock concrete implementations. Rhino Mocks is also unable to mock a private interface.
2.5.9.3. TypeMock Isolator
Rhino Mocks is not the only mocking framework available. TypeMock has a product named Isolator which is an advanced mocking framework. TypeMock is fundamentally different than Rhino Mocks in the fact that it uses intermediate language (IL) injection to replace mock real implementations with the mock representations at runtime. It does this by using the Profiler APIs within the .NET Framework to change the IL that is about to be executed by the unit test runner with the mock setup defined previously within the unit test. The advantage of this is that it removes all the limitations which exist with Rhino Mocks.
TypeMock can mock any object used within your system at any point. Unlike Rhino Mocks, with TypeMock you no longer need to worry about how to inject the model into the system, for example, via the constructor as TypeMock you can mock objects at any level. The other advantage is that the mock object doesn't need to inherit from an interface as it can mock the concrete implementations. This means that you can mock objects which aren't in your control, for example in the third-party framework which hasn't considered testability. This also means that you can mock parts of the .NET Framework itself.
However, this leads to a number of concerns of which you need to be aware. Although it shouldn't stop you from using the product, you should be aware that they exist. First, because you don't need to worry about how you inject the mock, you no longer have the same worries about separating concerns and dependency injection. This could lead to some problems when you attempt to replace the dependency with a different implementation. In a similar fashion, because it can mock concrete classes, you no longer need to be concerned with programming against abstracts and your tests don't encourage you to follow this pattern. Finally, due to the depth of access TypeMock has, it can lead to over-specified tests as you can mock methods multiple layers down, where before you might have mocked the dependency at a higher level. This becomes a problem when you change or replace the logic in your code.
However, TypeMock is great for legacy applications. By having more control, TypeMock allows you to start adding unit tests to an existing application with relative ease compared to Rhino Mocks.
2.5.9.4. Mocking Anti-Patterns
As with all techniques, there are various anti-patterns, or smells, of which you should be aware. We have detailed how TypeMock introduces some concerns for certain people; however, there are more general concerns.
Mocking any part of the .NET Framework is a bad approach to take. As I described in the interface separation principle, most objects are very heavyweight and intercoupled, so mocking objects such as the IDbConnection is going to take a very long time and will be hard to utilize effectively. This is the same for certain third-party frameworks, which have very heavy interfaces with a tight coupling. A more successful approach would be to abstract away from the concrete information using wrappers and abstracts to hide the underlying implementation.
However, for certain parts of the .NET Framework it is not possible because they don't expose interfaces, such as the core parts of ASP.NET. This leads into another anti-pattern when it comes to mocking and that is sealed classes. Even though not providing an interface is limiting, having a sealed class completely closes the door on mocking and stubbing (except TypeMock). By having a sealed class you limit any overriding or extending ability to allow certain parts to be replaced. As such, it can make it increasingly difficult to mock out that particular section.
Another anti-pattern is over-mocking and over-specified tests within a system. This is a common problem within systems where developers think that everything needs to be mocked and as a result the unit tests simply duplicate a large part of the internal implementation. To start with, this is bad because the tests don't actually test that it is working as expected, just that it is working as the tests define. Second, if the internal structure of the code changes then the tests are likely to fail because the two implementations do not match. For example, if you were mocking your data access and your unit tests for the business layer and it replicated exactly the same SQL code which would be executed on the database, then your business knows far too much about the underlying implementation and your tests have over-specified what they expect to happen. Instead, you should consider refactoring your code to improve testability, or look at using a stub object and state verification.
2.5.9.5. TDD Recap
TDD provides a number of advantages when developing your code, for example, helping you identify code and design smells earlier in the process. However, TDD is not a silver bullet. It will not solve all your design issues and bugs without even trying. TDD requires the correct mindset of the developer to be constantly writing in the test first fashion to get maximum benefit. It also requires the developer to understand good design principles such as SOLID to be able to identify and resolve the problems that TDD brings to the surface. If they are unable to recognize these benefits, then TDD will not seem as beneficial.
TDD also has a problem because of its name. Because the concept includes the term "test," everyone immediately thinks it is another form of software testing. In fact it's a development approach, which has more advantages than just testing software. This confusion around naming is one of the reasons that led to the naming within the xUnit framework: using the Fact attribute to define which methods to execute. The confusion is not only developer-to-developer, but also is passed on to the customer. When talking to customers, customers get confused by having a set of tests which demosrate that their requirements have been implemented as expected. The problem is that customers are generally nontechnical and most unit tests reference technical details, and don't provide enough information about the requirement without first understanding the code. As a result, people have come up with a different development approach called Behavior Driven Development or BDD.
2.5.10. Moving Beyond TDD to BDD
Behavior Driven Development (BDD) attempts to build on top of the fundamentals of TDD and the advantages it offers; however, it also attempts to go a step further by making the concept more accessible to developers, to the other members of the team, and to the customer. Dan North is one of the leaders within the BDD community, and he had the realization that the "test method names should be a sentence." The fundamental concept is that if the tests are given an effective name, then they are a lot more focused. This is the same concept he applies with his TDD naming convention for exactly the same reason.
Yet BDD is more than just how you name your tests as it dives deep into agile testing and interacts more with the customer than TDD previously did. One of the core aims of BDD is to take more advantage of the design and documentation which TDD provides by having human readable test method names together with the use of stories and scenarios to provide more context to what is being tested and how.
To provide this level of functionality, BDD has two main types of frameworks: the first type is a specification framework and the second is the scenario runner.
The specification framework is aimed at providing examples and specs about how your objects should work as isolated units. The aim is to provide examples of how the objects are expected to behave. If the objects do not match the defined behavior then it is marked as a failure. If they do meet the desired behavior, then they are marked as a pass. Most of the specification frameworks available for .NET and other languages follow a similar pattern and language when writing the examples. First there is a Because or Describe section, which provides the outline and context to what the examples are covering for the reader. The next sections are It blocks; these provide the examples about what should have occurred after the action happened. Generally you only have one action block with multiple different example blocks to describe the outcome.
Historically, the Ruby community has been the main promoters of the development approach, and due to the readable and dynamic nature of their language means BDD is the perfect fit. For .NET, there has been a number of attempts; however, they are all constrained by the C# language which requires the additional syntax and metadata about classes and methods. Currently machine.specification appears to be the cleanest BDD framework for .NET. By taking advantage of C# 3.0, they have managed to create a syntax that reads very naturally:
[Subject(typeof(Account), "Balance transfer")]
public class when_transferring_amount_between_two_accounts:
with_from_account_and_to_account
{
Because of = () =>
fromAccount.Transfer(1, toAccount);
It should_debit_the_from_account = () =>
fromAccount.Balance.ShouldEqual(0);
It should_credit_the_to_account = () =>
toAccount.Balance.ShouldEqual(2);
}However, with the rise of IronRuby you can now use the RSpec and Cucumber BDD frameworks created for Ruby against C# objects. This allows you to have the best of both worlds.
Historically the .NET development stack has been criticized by other development communities by not adapting to change very quickly. Ruby developers have been using testing tools such as RSpec since 2007 and more recently the Cucumber framework. With the introduction of the Dynamic Language Runtime (DLR), languages such as Ruby and Python can be run on the .NET platform.
Many of the cutting edge testing tools are being developed on these platforms. Don't be afraid to step outside the box, and experiment with languages such as IronRuby and IronPython or with tools such as RSpec and Cucumber. Examples of RSpec and Cucumber can be found in Chapter 6.
After the tests have been executed using a test runner, the different sections within the example are converted into a readable format, which can then be shown to a nontechnical person to discuss whether the behavior is correct. On the other side is the scenario runner. Although the specification framework focused on objects as isolated units, the scenario runner is focused on the end-to-end tests, otherwise known as integration tests (covered in Chapter 4) or acceptance tests (covered in Chapter 6). This scenario runner is based on describing how the application will be used, sometimes based on how users will interact via the UI but other times simply driving the engine API. Similar to the specification framework, a scenario framework is aimed at describing behavior while taking advantage of design and documentation but this time at the application level.
As with the specification framework, the scenario framework also has syntax to describe the different parts. The first stage is the story itself. This has three different stages:
As a [. . .]
I want [. . .]
So that [. . .]
An example might be
Story: Transfer money from savings account
As a saving account holder
I want to transfer money from savings account
So that I can pay my bills
From the viewpoint of the reader of the story, this example should provide them with some context into what you are doing and the reasons for it. From the viewpoint of the customer, this should match a valid user story that they want the system to implement; as such this should feel very natural and familiar to them. It's important to keep all technical content out of the scenario and use the business domain language to help customers keep with this familiarity.
After you have defined the story, you need to define the scenario and steps. The steps have three separate stages:
Given [. . .]
When [. . .]
Then [. . .]
This example outlines the different stages that need to be set up and then verify that the behavior was correct. The Given step is where you set up your scenario; When is where actions are performed; Then is the verification stage.
Scenario: Savings account is in credit
Given a balance of 400
When I transfer 100 to cash account
Then cash account balance should be 100
And savings account balance should be 300
The use of And allows you to chain steps together. The previous example provides one scenario about how you expect the story to work — as you progress you would add more scenarios to the story. You can then use the scenario runner to create test methods attached and execute them using the runner in a similar fashion to your specification framework. Then, you can go to your customer with a readable report and ask them if it is implemented correctly.
2.5.11. What Makes a Good Test?
When it comes to the topic of what makes a good unit test, there are as many opinions as there are bugs in production code found with a well-defined set of unit tests. We will start with a concept that most developers believe in.
There is no point in writing a test if it's useless. When you are writing your tests, take care to ensure that you have confidence that your unit test tests the code thoroughly. Many developers have good intentions and plan on maintaining tests, but soon get dragged down in the repetitive work of creating a test and making sure it passes. This leads to developers creating tests that are useless and detrimental to the project. These tests can be problematic because they provide a false sense of security. A new developer might come to the project to see that there are unit tests in place and feel that it is safe to begin large refactorings. A developer should be able to depend on the fact that the tests in the system test the code properly and were not blindly thrown together as another cobbled together feature. Unit tests should create confidence in the code you have created. When writing code, always keep in the back of your mind, "How am I going to test this?"
Unit tests should be fast. It's a proven fact that if unit tests take a long time to execute, developers will run these tests less frequently. Unit tests are intended to be run often, and as a general rule of thumb every few minutes. Unit tests should run so fast you should never have to hesitate to run them as shown in Figure 2-12.
Figure 2-12. TestDriven.NET output results
Unit tests should be small. As with other coding design principles, the amount of code added to unit tests should be very small. Unit tests should be thought of as professional code. Keep clutter out of unit tests and limit what is being tested to a minimum.
Unit tests should have a descriptive name. As described previously, unit tests should always have a descriptive name defining what they are verifying and focusing on.
Unit tests should document your intent. Unit tests should be thought of as specifications for your code. A developer should be able to determine the aspect of the code the test is testing from the name of the test.
Don't worry about how long the name of the test methods are — the more descriptive the better. This style can be cumbersome at first, but is easy to get used to after you see the benefits of having a set of tests that are very descriptive:
[Test]
public void Should_Transfer_From_Checking_To_Savings_Successfully()
{
Account checkingAccount = new Account(564858510, 600);
Account savingsAccount = new Account(564858507, 100);
checkingAccount.Transfer(ref savingsAccount, 100);
Assert.IsTrue(savingsAccount.Balance == 200, "Funds not deposited");
Assert.IsTrue(checkingAccount.Balance == 500, "Funds not withdrawn");
}Unit tests should be isolated. Unit tests should only test very small units of code; related classes should not be tested in dependant tests, because they should have their own unit tests to go with them. Tests should not rely on external data such as databases or files on a file system. All the data that is needed for a test to pass should be included in the test. A unit test should not be dependent on the order in which it is run. When unit tests are not isolated, the tests become too closely coupled and lead to poor software design. The test in the next listing is an example of a test that is isolated. The test sets up the business logic and the mail server, but essentially it is only testing the MessageSent function:
[Test] public void ProcessOrder_sends_Email_if_Order_Is_Successful() { StubMailServer stub = new StubMailServer(); BusinessLogic b = new BusinessLogic(stub); b.ProcessOrder(new Order()); Assert.IsTrue(stub.MessageSent); }
Unit tests should be automatic. Most developers have created unit tests before and may not have been aware that indeed they were unit tests. Have you ever created a WinForm with a single button, like Figure 2-13, to test a small section of code, maybe how a date was formatted? This is considered a unit test. Most of the time the form is deleted after you figure out how to perform the task you are looking to accomplish, but why throw this code away? Good unit tests can be run automatically with a push of a button. Using one of the frameworks we have discussed allow unit tests to be automatic, hence the name automated testing.
Figure 2-13. Test that many developers don't realize is a unit test.
Unit tests should be repeatable. To help ensure that unit tests are repeatable, unit tests should be independent from external environments. Databases, system time, and the file system are examples of environments that are not under direct control of the test. A developer should be able to check out a set of the tests and an application from version control, and expect that the tests will pass on any machine they are working on.
Unit tests should focus on one behavior per test. As a general rule of thumb, unit tests should only have one expectation per behavior. In most situations this loosely translates into one assertion per test — hey wait a minute, many of the examples we have shown thus far have had multiple assertions! An assertion doesn't translate strictly to a full expectation. In all our tests, only one behavior has been expected. Take for example the transfer funds test shown previously; there are two assertions, but the expectation is that funds have been transferred from one account to another account. The next listing is an example of a test that tests more than one expectation and should be considered bad practice. This test is expecting that the balance has changed, and also expects that a history transaction item has been added:
[Test] public void Should_Transfer_From_Checking_To_Savings_Successfully() { Account checkingAccount = new Account(564858510, 600); Account savingsAccount = new Account(564858507, 100); checkingAccount.Transfer(ref savingsAccount, 100); Assert.IsTrue(savingsAccount.Balance == 200); Assert.IsTrue(checkingAccount.Balance == 500); Assert.IsTrue(checkingAccount.TransactionHistory.Count > 0); Assert.IsTrue(savingsAccount.TransactionHistory.Count > 0); }
Unit tests should test the inverse relationship of behaviors. A common transaction in the financial world is the transfer of money from one account to another. If you have a transfer funds function, ensure you have assertions that enable the funds to be withdrawn from one account and deposited into another:
[Test] public void Should_Transfer_From_Checking_To_Savings_Successfully()
{ Account checkingAccount = new Account(564858510) {Balance=600}; Account savingsAccount = new Account(564858507) {Balance=100}; checkingAccount.Transfer(ref savingsAccount, 100); Assert.IsTrue(savingsAccount.Balance == 200); Assert.IsTrue(checkingAccount.Balance == 500); }
Unit test failures should be descriptive. Each test should be descriptive about what they are testing and the expected result. This is partly done by the method name, partly by the test code being readable, but also by the assertions having messages which are outputted if they fail.
[Test] public void Should_Transfer_From_Checking_To_Savings_Successfully() { Account checkingAccount = new Account(564858510, 600); Account savingsAccount = new Account(564858507, 100); checkingAccount.Transfer(ref savingsAccount, 100); Assert.IsTrue(savingsAccount.Balance == 200, "Funds not deposited"); Assert.IsTrue(checkingAccount.Balance == 500, "Funds not withdrawn"); }
Tests suites should test boundary conditions. If you are working with an object that could have boundary issues, ensure you are testing them. A general rule of testing boundary conditions is the 0, 1 many rule. This rule states you should test your object, with the boundary conditions, with zero elements, one element, and many elements. In most cases, if your object works with two elements it will work with any number of elements. There are cases where your object has an upper limit; in these cases you should also test upper limits:
[Test] public void Should_Sort_Arrary_With_Empty_Element() { int[] arrayToSort = {}; int[] actual = QuickSort(arrayToSort); Assert.IsTrue(actual.Length == 0, "Sorted empty array"); } [Test] public void Should_Sort_Array_With_One_Element() { int[] arrayToSort = { 29}; int[] actual = QuickSort(arrayToSort); Assert.IsTrue(actual.Length == 2, "Sorted array count"); Assert.IsTrue(actual[0] == 29, "Sorted array one element"); } [Test] public void Should_Sort_Array_With_Eleven_Elements() { int[] arrayToSort = {100,5,25,11,2,6,29,6,26,7,27}; int[] actual = QuickSort(arrayToSort);
Assert.IsTrue(actual.Length == 11, "Sorted array count"); Assert.IsTrue(actual[0] == 9, "Sorted array order first element"); Assert.IsTrue(actual[9] == 100, "Sorted array order last element"); }
Don't think of arrays as the only objects that have boundaries. For instance, if a developer needs to keep track of the age of a person, you would use an integer to keep track of this value. For most applications it does not make sense for a person to be 44,898 years old.
Unit tests should check for ordering. Good unit tests verify that the system is working as expected. It's a common enough scenario to mention that if objects are expected to be in a certain order, there should be a unit test to ensure that the expected order is matched:
[Test] public void Should_Sort_Array_With_Eleven_Elements() { int[] arrayToSort = {100,5,25,11,2,6,29,6,26,7,27}; int[] actual = QuickSort(arrayToSort); Assert.IsTrue(actual.Length == 11, "Sorted array count"); Assert.IsTrue(actual[0] == 9, "Sorted array order first element"); Assert.IsTrue(actual[9] == 100, "Sorted array order last element"); }