
Chapter 10. Extending the API
One of the major innovations in Apache 2 is the flexible and extensible API, which brings a hugely enhanced level of modularity and an applications architecture that is limited only by the developer’s imagination. We have encountered Apache’s hooks in earlier chapters, but we haven’t yet seen the full power they offer us, nor the other mechanisms for extending not merely the program, but also the API.
In this chapter, we will demonstrate a number of ways to extend the Apache API:
- Implementing new API functions
- Taking a closer look at hooks
- Implementing new hooks
- The provider API
- Providing a service
You should familiarize yourself with these techniques, as selecting an appropriate extension framework may mean the difference between an ill-fitting and hard-to-maintain application architecture and one that is elegant, maintainable, and extensible.
10.1. Implementing New Functions in Apache
10.1.1. Exporting Functions
Any module can export a function for use by other modules. At its simplest, it need only provide a header file that defines exported functions. Other modules can then #include the relevant header file and use the functions.
We saw an example of this in Chapter 6, where our mod_choices used functions exported by the XSLT filter module mod_transform to select a stylesheet:
mod_transform_set_XSLT(r, fmt->name);
To support this, all mod_transform has to do is export the relevant functions in a header file mod_transform.h:
![]()
In this instance, mod_choices depends explicitly on mod_transform, so this simple approach is sufficient. It does, however, introduce one support issue: mod_choices cannot be loaded before mod_transform in httpd.conf. To do so would cause a fatal error, because the symbol mod_transform_set_XSLT is unresolved when mod_choices tries to load.
In other cases, this approach can be more of a problem. Let’s look at a couple of examples:
mod_includerequires a CGI module (mod_cgiormod_cgid) if it is to process<!--#exec cgi=…-->directives. But these directives are rarely used, andmod_includecan do everything else it needs without CGI. Thus it is undesirable formod_includeto require CGI support.mod_publishercan work with form inputs provided thatmod_formhas parsed them into an appropriateapr_table. However, most users ofmod_publisherleave the task of working with form inputs to the content generator. As a consequence, we should be able to runmod_publisherwithout having to installmod_form.mod_authnz_ldapdepends onmod_ldapfor basic LDAP functions. Earlier versions of Apache requiredmod_ldapto be loaded before other LDAP modules. In Apache 2.2, LDAP modules can be loaded in any order.
10.1.2. Optional Functions
APR provides a solution to this dilemma: Optional functions can be exported by one module and imported by another without creating a dependency. To see how this process works, let’s consider the simple example of mod_form, a module whose purpose is to parse data from an HTML form (application/x-www-form-urlencoded) into an apr_table.
mod_form provides two functions to other modules:
form_datareturns the table of all key/value pairs parsed.form_valuereturns the value of a given key in the table.
mod_form could, of course, export these functions the simple way:
![]()
Unfortunately, that creates a dependency we prefer to avoid. Instead, mod_form exports them as optional functions, using the following declarations:
![]()
Implementing the Functions
Implementing these functions requires two things in mod_form itself. First, it needs the functions, which are straightforward and can be declared as static:
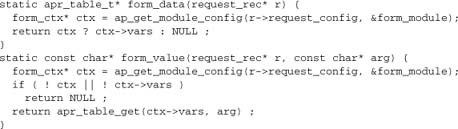
Here, ctx->vars is the table into which mod_form has parsed any available form data.
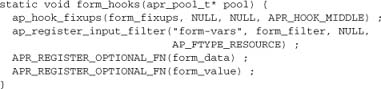
Second, mod_form needs to export the functions as optional functions by registering them in the form_hooks callback (where, of course, the module’s own callbacks are also registered):
Using the Functions
Now, a client module such as mod_sql or mod_publisher, having #included mod_form.h, just needs to retrieve the optional function. Both modules just retrieve the data to their own tables, during per-request initialization:
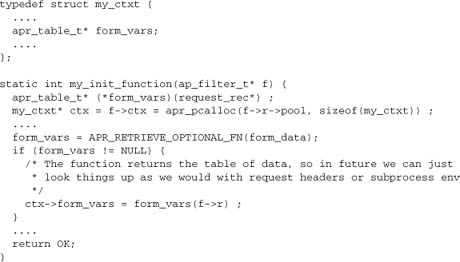
In this case, if mod_form isn’t available, the client modules will still work, albeit without the capability of accessing data from form inputs.
10.2. Hooks and Optional Hooks
In the preceding chapters, we discussed the Apache processing hooks. In Apache 1.x, this would have been the whole story: A fixed sequence of hooks was hardwired into the server.
Likewise, Apache 2 has a de facto “standard” sequence of hooks that are available in a default installation, and that reflect the older architecture. However, hooks in Apache 2 serve a more general purpose. Any module can extend the API by providing additional hooks or optional hooks, extending an invitation to other modules to provide their own behavior at this point. For example, mod_proxy provides hooks into the request it is making to the back-end server, and mod_dav provides optional hooks for implementing additional HTTP methods. Both modules are characterized by being extensible—that is, you can plug in more modules. In fact, they depend on additional modules implementing the hooks provided. They are extending the API by providing these additional hooks.
10.2.1. A Closer Look at Hooks
Before we look at implementing a new hook, let’s take a closer look at the kind of hooks we’ve seen already. Recall these examples from Chapters 5 and 6:
![]()
Both of these hooks appear in a register_hooks function, which is run at server start-up. The respective modules are registering their own functions to play some part in Apache’s behavior. But what exactly does that mean?
A hook is simply a point in Apache’s processing where a module can insert its own function to implement new behavior. Any module can extend the API by providing additional hooks or optional hooks, thereby extending an invitation to other modules to provide their own behavior at this point. The calling code implements one of the following logics:
- Run all functions registered on this hook in order.
- Run functions registered on this hook until one returns any value other than
DECLINED. - Run all functions until and unless one returns an error (that is, anything other than
OKorDECLINED).
Implementing a hook is done by means of macros defined in apr_hooks.h, apr_optional_hooks.h, and ap_config.h. The three logics, respectively, are associated with
AP_IMPLEMENT_EXTERNAL_HOOK_VOIDAP_IMPLEMENT_EXTERNAL_HOOK_RUN_FIRSTAP_IMPLEMENT_EXTERNAL_HOOK_RUN_ALL
(or their APR versions when working outside the context of httpd).
For reasons we’ll discuss later in this chapter, a module outside the Apache core should normally implement any hooks as optional hooks. Only one standard macro is defined for optional hooks, but any of the previously mentioned functions can also be treated as an optional hook by client modules.
When a module implements a hook (though not an optional hook), it exports a hook function such as ap_hook_handler or ap_hook_translate_name. As we saw in Chapter 6, a sequence of them appear in the request processing cycle. The core also implements other standard hooks.
Initialization at Server Start-up
test_config—hook into configuration testingoptional_fn_retrieve—run before anything else after all modules are loadedpre_config—run before processing configuration directivespost_config—run after processing configuration directivesopen_logs—run when Apache opens its log filespre_mpm—run ahead of the MPM launching worker processes and/or threadschild_init—run after anhttpdchild has forked, but before it becomes multithreaded or starts to accept connections
Hooks into the Core Exported by mpm_common
monitor—polled in the parent processfatal_exception—run when Apache crashes
There are also hooks into connection creation and processing, request creation, and protocol handling. In addition, a number of hooks are exported not by the core, but rather by the standard modules. The latter functions are implemented as optional hooks.
10.2.2. Order of Execution
Returning to the hooks in our earlier modules, we had
![]()
In each case, the first argument is the function we are hooking in to Apache. The other three arguments are concerned with the order of execution when multiple modules have inserted functions on the same hook.
The final argument is an expression indicating where the function should run. For the majority of modules, it really doesn’t matter whether their functions run before or after others on the same hook; such modules should use APR_HOOK_MIDDLE. Other modules may need to run a function either before or after “all other” functions on the same hook have run; these modules can use APR_HOOK_FIRST or APR_HOOK_LAST. The values APR_HOOK_REALLY_FIRST and APR_HOOK_REALLY_LAST are also available, although they are seldom appropriate and may give unexpected behavior. For example, a REALLY_LAST function may never run if it follows an Apache standard function that never returns DECLINED.
The two NULL values are the predecessors and successors of our function, and they offer fine control. Instead of expressing a general desire to run before or after other (unspecified) modules, they offer the opportunity to name other modules explicitly. They are appropriate for closely related modules whose functions, if both modules are present, must run in a particular order. These arguments take the form of a NULL-terminated list of modules that must run before or after ours.
An example arises in the authorization modules, where several modules require mod_authz_owner (if present) to run before their own hooks. Here’s how mod_authz_groupfile declares it:

10.2.3. Optional Hooks Example: mod_authz_dbd
mod_authz_dbd is, in part, a standard authorization (authz) module, implementing group access by means of SQL queries (i.e., checking an SQL database for whether a user is a member of a group). In addition to this standard function, it implements login and logout functions that work by setting a flag in the database to indicate whether the user is currently logged in.
Although mod_authz_dbd manages the server state, it doesn’t care about the client. Nevertheless, a server that implements login/logout may also wish to manage the client state—for example, by setting a cookie or other session token. Ideally, the client session should be tied to the server session, so the two always remain in agreement. mod_authz_dbd supports this approach by exporting an optional hook. A module managing a client session can use this hook to implement its client-side login and logout exactly when the server successfully performs these functions.
Exporting an Optional Hook
mod_authz_dbd exports the hook by declaring it in a header file and implementing it in the C file. This is made very simple by the macros from apr_hooks.h and apr_optional_hooks.h.
First, here is the declaration in mod_authz_dbd.h:
![]()
This declares an external hook called client_login, with arguments consisting of the preprocessor namespace AP (implemented by Apache) and the C namespace authz_dbd. The template for a client_login function is also determined by the arguments:
int func(request_rec*, int, const char*)
The implementation in mod_authz_dbd.c is almost as simple. A macro expands to implement a function authz_dbd_run_client_login:
![]()
Finally, there is a call to run the functions registered for the hook in the function implementing server-side login/logout:
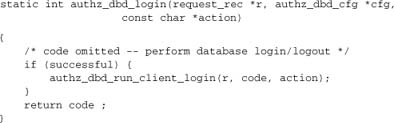
That’s all! Now a module implementing client sessions can hook a function straight into authz_dbd_login:

Now our client_cookie function runs whenever someone successfully logs in or out through mod_authz_dbd.
We could have implemented this function as a non-optional hook, by replacing the macro APR_IMPLEMENT_OPTIONAL_HOOK_RUN_ALL with APR_IMPLEMENT_EXTERNAL_HOOK_RUN_ALL from apr_hooks.h. Then a client function could use the familiar form of declaration:
![]()
The drawback is that this approach would cause a fatal link error if the client session module is loaded before mod_authz_dbd. Hence we follow the general advice to use optional hooks in non-core modules.
Note: This has nothing to do with security, for which only the server protection matters. The session is managed from both the server side and the client side for the convenience of legitimate users accessing the system as designed.
10.3. The Provider API
The ap_provider API provides yet another means for modules to extend the Apache API in a manner slightly reminiscent of exporting a Java interface or C++ virtual base class. A module exporting a new API defines an interface and leaves it to others to implement providers for the interface. A provider is typically implemented in another module, and it instantiates the interface with its own behavior.
The provider API is most useful when we need to support several distinct behaviors in a particular situation, and it works well when the available options will be controlled directly by a server administrator in httpd.conf. It ensures that new modules can add new behaviors without affecting existing code or users.
Within the Apache core distribution, the main example demonstrating the ap_provider API is the authentication framework (others occur in mod_proxy and mod_cache). Authentication in Apache 2.2 comprises several well-defined tasks (see Chapter 7). One of those tasks is looking up a username/password to verify the credentials presented. This lookup can be done in many ways, so we need an API for modules to implement it. This functionality is implemented by exporting a provider API. Each lookup module works by registering its own implementation of the provider.
Two standard modules export the API:
mod_auth_basicimplements HTTP basic authentication.mod_auth_digestimplements HTTP digest authentication.
The standard lookup modules that implement providers include the following:
mod_authn_filelooks up a username/password in a classichtpasswdfile.mod_authn_dbmlooks it up in a DBM database (withapr_dbm).mod_authn_dbdlooks it up in an SQL database (withapr_dbd).mod_authn_ldaplooks it up in an LDAP directory.mod_authn_anonallows anonymous authentication, by substituting simple rules for any lookup.
These lookup modules can be used with either of the modules exporting the API.
A slightly more complex example is the XML namespace framework. It is based on an output filter that parses XML on the fly using a SAX2 parser, and it enables modules to process different XML namespaces in the markup. This offers a modular and far faster alternative to XSLT filtering for a range of applications involving post-processing of XML, as well as options for embedded processing and scripting.
At the time of writing, two modules export the namespace framework:
mod_xmlnsis a minimal implementation.mod_publisherimplements the namespace framework in the context of an extremely feature-rich, general-purpose rewriting module for both HTML and XML.
Namespace modules will work with either of those modules.
To illustrate the provider API, let’s look at the XML namespace API (Figure 10-1). The module providing the namespace filter is a SAX2 parser; current implementations are mod_publisher and mod_xmlns. Let’s look at mod_xmlns, whose sole function is to provide the namespace API. In Figure 10-1, we show XHTML, annotations, SQL queries, and Dublincore metadata, each of which is implemented by a separate module. The key part of the API is for mod_xmlns to enable these modules to register themselves and take charge of processing selected markup.
Figure 10-1. XML namespace API
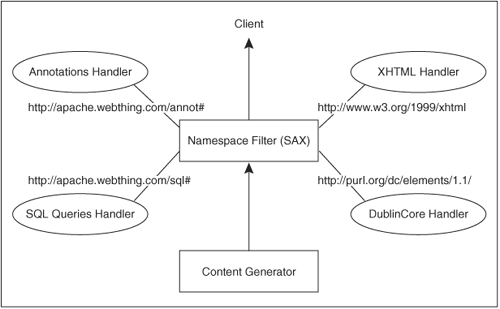
The key configuration directive provided by mod_xmlns is
XMLNSUseNamespace namespace-uri [action] [version]
A namespace module works by registering a provider for namespace-uri with the server. XMLNSUseNamespace then activates the provider as a handler for XML elements in the namespace. For example,
XMLNSUseNamespace http://www.w3.org/1999/xhtml On 1.0
activates handler version 1.0 of provider http://www.w3.org/1999/xhtml (which ensures that XHTML is Appendix C–compliant and can be served to real-life Web browsers as HTML). Other events may be handled by another handler. For example, if the source document also provides metadata as RDF (such as mod_choices), any Dublincore[1] metadata elements can be served to HTML browsers as <META> elements with
XMLNSUseNamespace http://purl.org/dc/elements/1.1/ On xhtml
which registers a handler for the Dublincore namespace.
10.3.1. Implementation
Unlike the API extensions we have looked at so far, the provider API works solely on a global lookup table. It doesn’t need to export any function declarations, and in principle it might not need a header file at all, although in practice it is likely to export a declaration of the provider structure it implements.
In the case of mod_xmlns, the provider implements a configuration directive, so the API is exported from a configuration handler function:

The key to the API is ap_lookup_provider. If a module implementing a provider for the requested URI and version is loaded, it will be configured as active for XML events in the URI’s namespace according to the value of onoff. The parser will then dispatch every XML event in the namespace to the registered provider when a document is parsed.
10.3.2. Implementing a Provider
The handler in the preceding example is treated as void*, but, of course, it is known to mod_xmlns. It is actually a struct, defined in the header file xmlns.h (which is common to both mod_publisher and mod_xmlns):

A provider module works by implementing one or more xmlns structures, and registering them as providers for xmlns. An example is mod_xhtml, which registers three providers for two namespaces:


As we can see, the xmlns struct is closer to the module struct itself than to the single-purpose optional function or hook. In general, the provider API is well suited to supporting new classes of applications, in which implementing a provider will be the sole or main purpose of a new module. Similarly, within the standard Apache 2.2 distribution, each of the mod_authn_* modules implements a provider for authentication.
10.4. Providing a Service
The final way to extend Apache for the benefit of other modules is to provide a general-purpose service. This doesn’t offer a separate means of extending the API, but rather represents an optional extension of the Apache core implemented in a module. In fact, most of Apache’s core functions are implemented by a number of standard modules, so we could simply describe this approach as extending the Apache core.
10.4.1. Example: mod_dbd
A prime example is mod_dbd, which is Apache’s provider for the database framework (Chapter 11). The purpose of mod_dbd is to provide a service to modules needing an SQL back end. It improves the efficiency and scalability of Apache + SQL architectures over classic LAMP in two important ways:
- It provides a dynamic pool of connections that can be shared across threads in an efficient manner.
- It provides connections that can be shared by different modules using a database, including authentication, scripting languages such as PHP and Perl, and logging.
mod_dbd exports a simple API that hides the complexities of managing the connections, including the pool itself and the alternative single persistent connection when running on a nonthreaded platform. The core of mod_dbd is an apr_reslist, the APR structure for managing a dynamic pool of resources. The reslist is the key to the service provided by mod_dbd.
To implement a reslist service, mod_dbd must
- Provide a constructor and a destructor function for the
reslist. - Call
apr_reslist_createto set up thereslist. - Provide accessor functions to acquire a resource from the
reslist, and then return it or mark it as invalid. - Ensure
apr_reslist_destroyis called at process shutdown to clean up.
Caution
This discussion is focused on the apr_reslist. However, mod_dbd also needs to work when the APR has been built without threads, such that apr_reslist is not available. The actual mod_dbd code uses constructs like

in many places. We’ll ignore these cases for the sake of brevity.
10.4.2. Implementing the reslist
First. let’s consider the constructor and destructor. These functions are callbacks for apr_reslist, which determines their function signatures:



dbd_destruct is a wrapper having the signature required by the reslist, whereas dbd_close can be passed to apr_pool_cleanup functions.

Now that we have our callbacks, let’s look at the function that creates the reslist. Note that svr->dbpool here is an apr_reslist_t*.

This function in itself is not thread safe: It sets a field in the server configuration, which is common to all threads. The appropriate hook for it in the Apache architecture is child_init, which runs after an Apache child process is created but before it creates its own pool of threads or (crucially) accepts asynchronous incoming connections. This order of operations should be normal practice for modules using a reslist.
In the case of mod_dbd, there’s an additional complication: The dbd_setup function may fail. We want it to recover smoothly if the database is down when Apache is started, but becomes available later. Specifically, if the database access fails, we want to try again each time a client module asks for a connection, until we find that the database is up:

But now we’re working in a thread, so we need to acquire a thread mutex before running dbd_setup.
At this point, we have the core of our service: a reslist managing the objects we’re interested in. The remainder of the module consists of two components:
- Client API: the functions we export for other modules
- Configuration functions for a systems administrator to manage the resource
For the purposes of our discussion here, the most important consideration is the API. It comprises five functions: ap_dbd_open, ap_dbd_close, ap_dbd_acquire, ap_dbd_cacquire, and ap_dbd_prepare. We’ll explore usage of these functions in Chapter 11. For now, we’re just interested in implementing them. Here are the basic open and close functions:
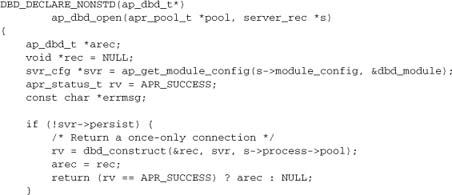
If the database is down when we try to connect at server start-up, svr->dbpool will be NULL. We try to make this connection again now. If successful, this request takes the overhead of connecting to the database, but subsequent requests are spared it.

The core of this function is the acquisition of a resource from the reslist. Normally, we will just get an ap_dbd_t* from the pool, but apr_reslist may call our constructor internally if sufficient connections are not available in the pool.

We also check that the connection is valid, provided the driver supports this ability. If a database connection has been lost, we mark it as invalid, so apr_reslist can destroy it and remove it from the pool.

The corresponding close function is simple:

To make this functionality work in the context of a request, we want a slightly higher-level API. A module should be able to acquire a resource from the pool without having to worry about when to close it or whether this or another module also uses the same resource earlier or later in the same request. For this reason, we provide a wrapper function that performs the following tasks:
- Registers a cleanup to run when the request is destroyed (
apr_pool_cleanup_register). - Reserves the connection to the request, and keeps it for the duration of the request. When we open a connection, we store it with
ap_set_module_config, so each subsequent call toap_dbd_acquireneed merely retrieve the stored pointer.
This requires an auxiliary struct and a cleanup function that can be passed to apr_pool_cleanup_register:


At this point, we have written a set of core functions accessing DBD through a reslist, along with some accessor functions. Together, these functions provide a service for modules of many kinds, as described in Chapter 11. Our final task is to export the API in mod_dbd.h. But before doing so, let’s take a look at those declarations.
10.5. Cross-Platform API Builds
All of the preceding examples, as well as many provided elsewhere in this book, use a range of macros in declaring their public/API functions. For example:
![]()
Why aren’t these standard C declarations?
![]()
The answer lies in Apache’s cross-platform support, and specifically in its support for Windows. Whereas most target platforms (e.g., UNIX, Linux, MacOS, BeOS, OS2, Netware) support standard C and use build options to determine the linkage of the compiled and linked module, Microsoft’s Visual C++ uniquely requires some of its build options to be hard-coded into the source. Thus, although it is possible to write modules for any platform using standard C, C++, or any other language with C linkage, those modules cannot be linked on Windows to an executable (dll) that will load as an Apache module. Of course, if we insert the proprietary keywords required by VC++, that’s a syntax error in any standard C compiler.
10.5.1. Using Preprocessor Directives
Apache and APR work around this problem by using preprocessor directives. These directives follow a standard form, and any module that exports functions may have to define a new set. Here are the declarations from mod_dbd.h:

When building on non-Windows platforms, we can simply ignore these macros, as the preprocessor will remove them (or—usually easiest—leave it all to apxs, which ensures that you have the right build options for your platform). On Windows, the build may want some preprocessor macros defined. So, for a Windows build of mod_dbd, we define DBD_DECLARE_EXPORT to export API symbols from mod_dbd.
We do not define AP_DECLARE_EXPORT or any other such symbols, so API functions from the core, from APR, or from any other module are declared as imports.
Here’s what some of the declarations look like in the headers included in mod_dbd.
Before the Preprocessor

After the Preprocessor (Standard C)

After the Preprocessor (Windows)

10.5.2. Declaring the Module API
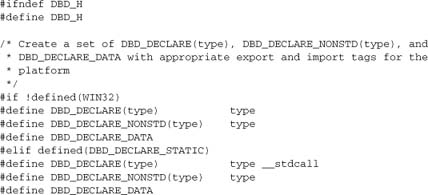
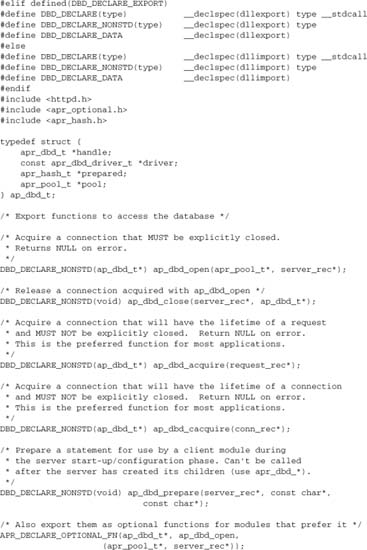
Now that we have dealt with the API macros, we can specify in full the API for our service module mod_dbd:

10.6. Summary
This chapter dealt with several advanced topics:
- Exporting functions from a module
- Optional functions
- A detailed look at hooks
- Optional hooks
- The provider API: exporting an interface
- Providing a service
- Cross-platform builds and declaration macros
Even if these issues are not obviously relevant to your current needs, it is worth familiarizing yourself with these basic techniques. The discussions in Chapter 10 are complemented by some of the techniques covered in Chapter 4, and mod_dbd is an important part of the database infrastructure discussed next, in Chapter 11.