
Chapter 11. The Apache Database Framework
Many web applications involve an SQL database back end. The classic architecture for this is LAMP: Linux, Apache, MySQL, and Perl, Python, or PHP. LAMP has been in widespread use for a full decade, and in terms of its fundamental architecture has remained essentially unchanged since mod_perl introduced the persistent database connection in 1996. In addition to LAMP and other applications, databases are used in a number of stand-alone applications, such as authentication, logging, and dynamic configuration.
This chapter describes the Apache database framework, by exploring the following topics:
- The need for a new framework
- The DBD architecture
- The
apr_dbdAPI (database operations) - The
ap_dbdAPI (database connection management) - Applications (i.e., using DBD in your modules)
- Writing a DBD driver to support a back-end database
11.1. The Need for a New Framework
11.1.1. Apache 1.x/2.0 Versus Apache 2.2
With Apache 1.x and 2.0, modules requiring an SQL back end had to take responsibility for managing it themselves. Apart from reinventing the wheel, this approach can be very inefficient, for example, when each of several modules maintains its own connection. An analogy can be drawn to MS-DOS in the late 1980s, when every software application was supplied on a huge pile of floppy disks comprising mostly different drivers for every possible printer. This situation was eventually resolved when the operating system provided a single printing API to which both applications and printer drivers were expected to conform, thereby relieving application developers of an unnecessary burden.
Another reason for updating the original LAMP architecture was to improve the scalability of database applications. LAMP itself improved on the simplest CGI model by providing a persistent database connection, which is ideal for the Apache 1.x architecture (and the nonthreaded Prefork MPM in Apache 2). But the threaded MPMs in Apache 2 enable an altogether more efficient and scalable architecture, based on connection pooling.
Apache 2.2 and later provide the ap_dbd API for managing database connections (including optimized strategies for threaded and nonthreaded MPMs), while APR 1.2 and later provide the apr_dbd API for interacting with the database. New modules should use these APIs for all SQL database operations. Existing applications should be upgraded to use them where feasible, either transparently or as a recommended option to their users.
11.1.2. Connection Pooling
There is a fundamental mismatch between the (connectionless and stateless) HTTP protocol and the connection-oriented architecture of most, if not all, databases. This can easily lead to inefficiency in web-database applications.
11.1.2.1. The Simple CGI Model
The simplest form of dynamic web application is exemplified by CGI, in which a script external to the webserver takes responsibility for processing a request. If the script needs to use a database, it has to open and log into the database server, do its work, and then close the connection when it’s finished. Creating a new connection for every request imposes a heavy overhead, and it makes CGI unsuitable for any but low-volume database applications.[1]
11.1.2.2. The Classic LAMP Model
The LAMP architecture deals with this problem by opening a persistent database connection and reusing it over many requests. In this way, it avoids the overhead of opening a new connection for every request. Unfortunately, this scheme brings its own problem: The overhead incurred by holding a large number of database connections open seriously limits the scalability of this architecture. This situation is made worse by the fact that every server process has to maintain its connection even when serving requests that make no use of the database, since such requests represent the vast majority of requests at most sites (even when pages are database-driven, contents such as images and stylesheets are usually static).
11.1.2.3. Taking Advantage of Apache 2
With Apache 2 and threaded MPMs, a range of altogether more efficient and scalable options become possible. Starting from what we already have, we can list our options:
- Classic CGI: one connection per request
- Classic LAMP: one persistent connection per thread
- Alternative LAMP: one persistent connection per process, with a mechanism for a thread to take and lock it for the duration of a request
- Connection pooling: more than one connection per process, but fewer than one per thread, with a mechanism for a thread to take and lock a connection from the pool
- Dynamic connection pooling: a variable-size connection pool, which will grow or shrink according to actual database traffic levels
Looking at these options in order, we can see the advantages and drawbacks of each one. We have already dealt with the first two possibilities. The third dispenses with the LAMP overhead at the cost of preventing parallel accesses to the back end. It may be an efficient solution in some cases, but it clearly presents its own problems when servicing concurrent requests.
The fourth and fifth options present an optimal solution whose scalability is limited only by the available hardware and operating system. The ratio of back-end connections to threads can reflect the proportion of the total traffic that requires the back end. Put in simple terms, if one in every five requests to the webserver requires the database, then a pool might have one connection per five threads. The optimal solution to managing back-end connections is a dynamic pool whose size is driven by actual demand rather than best-guess configuration.
11.2. The DBD Architecture
Figure 11-1 shows the four-layer DBD architecture in Apache. At the top, application modules implement functionality requiring use of the database. mod_dbd manages the database connections on behalf of modules, and apr_dbd provides an API for common SQL/database operations. Finally, drivers provide implementations of the API based on various SQL database packages, using the functions provided by the respective databases’ client libraries.
Figure 11-1. Apache DBD architecture
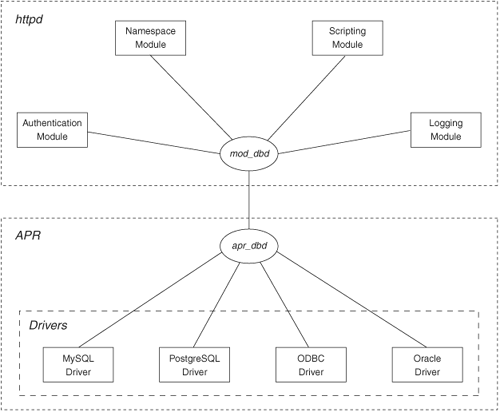
Drivers are available at the time of writing for PostgreSQL 7+, MySQL 4.1+, SQLite 2/3, and Oracle 8+. If your application wants to use a database for which no apr_dbd driver is yet available, you are strongly urged to write a driver for your back end, so that other DBD applications will have the option to reuse it. We describe how to write a driver at the end of this chapter.
11.3. The apr_dbd API
apr_dbd is a simple unified API for accessing SQL databases, in the tradition of Perl’s DBI/DBD. The nearest C equivalent, libdbi,[2] has sometimes been used for Apache modules, but is not an ideal fit for working with Apache; it is also licensed on terms that would make it problematic for the ASF to distribute. apr_dbd is, by design, integrated with Apache and APR, and it is built on key APR structures. In particular, all resource management in apr_dbd is based on APR pools, making it easy to use safely in Apache.
apr_dbd is a small API that supplies only a limited number of core functions likely to be of general interest. Modules that need to perform functions not supported have several options:
- Extend the
apr_dbdAPI. If you think your extensions are of general interest, you might consider proposing them for inclusion in a future release of the standard API. - Use
apr_dbd_native()to obtain a “native” database handle. This gives you the full API of the underlying database, albeit at the expense of portability. - Implement functions as SQL statements.
- Implement functions in an embedded language provided by the database.
The API defines six data types, which are used as opaque pointers in applications:
apr_dbd_driver_t—a driverapr_dbd_t—a database handleapr_dbd_prepared_t—an SQL-prepared statementapr_dbd_results_t—a results set from a select statementapr_dbd_row_t—a row from a results setapr_dbd_transaction_t—an SQL transaction
Instantiation of the types is the responsibility of driver modules, and is different for each driver.
The anatomy of a typical apr_dbd application is, in outline form:
- Initialize (
apr_dbd_init). - Get a driver handle (
apr_dbd_get_driver). - Open a database connection (
apr_dbd_open). - Perform database operations (query, select, and so on).
- Close the connection (
apr_dbd_close).
When writing an application module, we delegate initialization and the management of drivers and connections to mod_dbd. All the application needs to deal with is the required database operations and (optionally) preparing statements in advance.
11.3.1. Database Operations
The database operations fall into several categories:
- Preparing SQL statements
- SQL statements that don’t return a results set
- SQL statements that do return a results set
- Operations on a results set
- SQL transactions
- Miscellaneous operations (escape strings, handle errors)
Let’s look at each of these in turn.
11.3.1.1. SQL Statements, Format Strings, Data Types, and Labels
apr_dbd uses the word Query to describe a database query (such as SQL INSERT or UPDATE) that doesn’t return a results set, and Select for a query such as SELECT that returns results. There are three variants of each Query and Select:
apr_dbd_queryandapr_dbd_selectexecute an SQL statement supplied verbatim.apr_dbd_pqueryandapr_dbd_pselectexecute a prepared statement with arguments supplied in anargc/argvform.apr_dbd_pvqueryandapr_dbd_pvselectexecute a prepared statement with arguments supplied as aNULL-terminatedvarargslist.
Different database drivers support different statement formats. Consider, for example, a simple statement to look up a password for a user. The statement, though trivial, differs for different drivers:
- MySQL:
SELECT password FROM users WHERE username = ? - PostgreSQL:
SELECT password FROM users WHERE username = $1 - Oracle:
SELECT password FROM users WHERE username = :user
apr_dbd_prepare supports a unified format for all drivers:
apr_dbd:SELECT password FROM users WHERE username = %s
This is based on stdio-like format string syntax, so an integer variable is %d, a floating-point number is %f, and a large object is %L. At present, there is no consistency between different drivers in what they support beyond the basic %s. Drivers may also support a “%123s” format, to indicate that a field in the database is of (maximum) size 123 and so cannot accommodate a larger value.
A prepared statement in any driver may be assigned a label in apr_dbd_prepare. This parameter is optional (it may be NULL) and may materially affect how the statement is prepared. Applications must follow two rules to use this technique efficiently:
- When preparing a statement for regular reuse (e.g., at server start-up), assign it a label.
- When preparing a statement for one-off use (e.g., during processing of a connection or request), do not assign it a label.
When assigning statements in a module, you should take care to ensure that all labels are globally unique for the connection. Recommended practice is to use a namespace associated with your module, together with a counter. For example:

11.3.1.2. Results Sets (Cursors)
Each successful select operation will create a results set, corresponding to an SQL cursor. Queries may run synchronously and permit random access to any row by number, or they may run asynchronously and permit only sequential access to rows. Asynchronous operation is generally faster (especially for larger queries) with drivers that support it. This determination is made by a random argument to the apr_dbd_select-family functions. Applications expecting unspecified or large results sets should set this parameter to 0 (sequential access only), as this approach may be significantly faster and more efficient. For example, the PostgreSQL driver uses asynchronous operation when random access is not required.
There is no explicit apr_dbd function to clear or destroy a cursor, but it is important that you do one of the following:
- In sequential access mode, you must loop through all results until
apr_dbd_get_rowreturns-1, indicating the end of the results. - In random access mode, accessing an invalid row number with
apr_dbd_get_rowwill clear the cursor.
11.3.1.3. Transactions
Transactions in apr_dbd correspond closely to SQL transactions. Transaction behavior depends on transaction mode, which is either APR_DBD_TRANSACTION_COMMIT (the default) or APR_DBD_TRANSACTION_ROLLBACK; either of these modes can be ORed with APR_DBD_TRANSACTION_IGNORE_ERRORS. Transactions follow these rules:
- When not in a transaction, all database operations are treated as in autocommit-on-success mode.
- The transaction maintains a success-or-error state. If any database operation generates an error, the transaction is put into an error state.
- When the transaction is in an error state, no further database operations are performed while the transaction is in effect, and attempted operations will immediately return with an error.
APR_DBD_TRANSACTION_IGNORE_ERRORScan be used to override this behavior. - When a transaction is ended, it will either
COMMITorROLLBACK. If the transaction is in an error state or ifAPR_DBD_TRANSACTION_ROLLBACKis set, it willROLLBACK; otherwise, it willCOMMIT. Within a transaction, nothing is committed or rolled back (unless you execute an SQLCOMMITorROLLBACKusingapr_dbd_query).
A limitation of the current implementation is that you cannot reliably have more than one concurrent transaction open on a single database connection (although some drivers may support this behavior). This constraint is not a problem in most modules, but it does mean that modules should follow some simple guidelines:
- When a module implements more than one hook involving database access, do not leave a transaction open between hooks.
- Filters execute effectively in parallel, so you should not use transactions except within a single call.
If you need to violate these rules, you’ll have to open a private connection for your module with ap_dbd_open. Otherwise, this tactic is generally worth avoiding, as it is inefficient for a request to use more than one database connection.
11.3.2. API Functions
The full apr_dbd API is defined in apr_dbd.h. Note that some functions return an int instead of apr_status_t. Unless otherwise indicated, these functions return zero to indicate success or an error number from the underlying database on error. These error numbers can be used with apr_dbd_error to return a printable error message from the underlying database.
APU_DECLARE(apr_status_t) apr_dbd_init(apr_pool_t *pool);
Once-only initialization. Use the pool to register cleanups for shutdown.
![]()
Get a driver by name.
![]()
Open a connection to a back end. ptmp is a working pool, and params is a driver-dependent connection string. Returns a connection in handle.
![]()
Close a back-end connection.
APU_DECLARE(const char*) apr_dbd_name(const apr_dbd_driver_t *driver);
Get the name of a driver.
![]()
Return a native database handle of the underlying database.
Check the status of a database connection. This function may attempt to reconnect if an error is encountered; it may also return APR_ENOTIMPL.
![]()
Select a database name. This may be a no-op if it is not supported.
![]()
Start a transaction if supported. This may be a no-op. If a non-null *trans argument is supplied, it will be reused.
![]()
End a transaction, executing a COMMIT if all is well, or a ROLLBACK if there’s an error or if the transaction mode is rollback.
![]()
Return the transaction mode.
![]()
Set the transaction mode (commit/rollback; ignore or abort on error). Returns the transaction mode we just set.
![]()
Execute an SQL query statement that doesn’t return a results set, passed as a literal string. Sets *nrows to the number of rows affected.
Execute an SQL query that returns a results set in *res. The query is a literal string statement. If random is zero, the query may run asynchronously and all results must be accessed in a for-next loop; if it is nonzero, the query runs synchronously and results can be accessed by row number.
![]()
Return the number of columns in a results set.
![]()
Return the number of rows in a results set, or -1 if the query was asynchronous.
![]()
Get a row from a results set. If the query was synchronous, it gets row rownum; otherwise, rownum is ignored. If the query was asynchronous or if rownum is -1, it gets the next row. The function returns 0 on success, -1 for rownum out of range or end-of-data, or an error. It automatically deletes the results set when -1 is returned.
![]()
Return an entry from a row.
![]()
Return the name of a column in the results set.
Get the current error message (if any). errnum is an error code from the operation that returned an error, but it may be ignored by the driver.
![]()
Escape a string so it is safe for query/select. The returned string is allocated from pool.
![]()
Prepare a statement, allocated from pool and returned in statement. If label is non-null, supply a label for it.
![]()
Like apr_dbd_query, but executes a prepared query, with arguments supplied using the argc/argv convention.

Like apr_dbd_select, but executes a prepared query, with arguments supplied using the argc/argv convention.
![]()
Like apr_dbd_pquery, but uses arguments supplied in a varargs list.
![]()
Like apr_dbd_pselect, but uses arguments supplied in a varargs list.
11.4. The ap_dbd API
Whereas apr_dbd provides an API for SQL operations, ap_dbd is exported by mod_dbd (Chapter 10) and manages database connections on behalf of a module. Its work includes management of a dynamic pool of persistent database connections (or of a single persistent connection, in the case of a nonthreaded platform), so that application modules never need concern themselves with connection management.
The ap_dbd API provides one data type and five functions.

The ap_dbd_t object comprises a driver handle, a database handle, and a hash table of prepared statements indexed by label. These are available for use in apr_dbd operations.
The functions are shown here:

Given that most modules concern themselves with processing an HTTP request or, more rarely, a TCP connection, they should normally use ap_dbd_acquire or ap_dbd_cacquire. These functions can be used any number of times within the processing of a request or connection, and are guaranteed to return the same connection handle every time they are called within the lifetime of the request. For example, a database authentication module, a content generator, and a database logging module will all share a single connection, making for efficient use of resources. This scheme is strongly recommended for most modules.
By contrast, ap_dbd_open obtains a different database connection in every call. Modules using ap_dbd_open will be those needing a connection with a lifetime incompatible with the acquire/cacquire functions, and those whose use of apr_dbd_transactions is incompatible with the guidelines given previously.
Finally, ap_dbd_prepare is intended only for the configuration phase; it will not work if used later.
11.5. An Example Application Module: mod_authn_dbd
The DBD framework evolved in public for two years before the release of Apache 2.2 made it a standard component. As a consequence, a number of applications have been developed using precursors to the current DBD framework. These include this author’s mod_sql, a module implementing a namespace for SQL in XML using the xmlns filter framework,[3] so that queries can be embedded in XML and executed in a filter. Let’s use DBD authentication as a simple example here.[4]
mod_authn_dbd is an authentication module. As described in Chapter 7, its purpose is to verify a password supplied by a user. The module implements an ap_provider comprising two functions to retrieve an encrypted password from an SQL database: one for a user (HTTP basic authentication) and one for a user+realm (digest authentication). In the interest of brevity, we’ll confine our discussion to one of these functions.
Authentication is a task that involves frequent repetition of a small number of SQL queries that can be specified in the server configuration, so preparing the statements at start-up time offers obvious benefits in this case. We will do so by exposing the SQL queries as configuration directives, and then using ap_dbd_prepare from our handler for those directives. First, here are our directives:

They will typically take the following form:
AuthDBDUserPWQuery "SELECT password FROM authn WHERE username = %s"
To prepare that SQL statement for frequent reuse, our configuration function uses ap_dbd_prepare as an optional function:
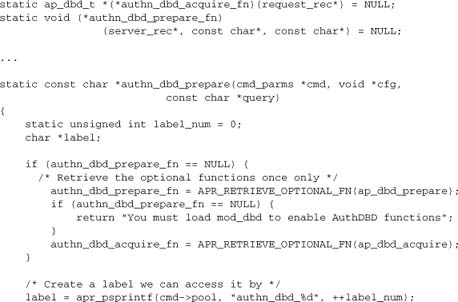

When we need to authenticate a user, we will execute one of the queries we just prepared. Here’s the function to look up a user’s password in the database:

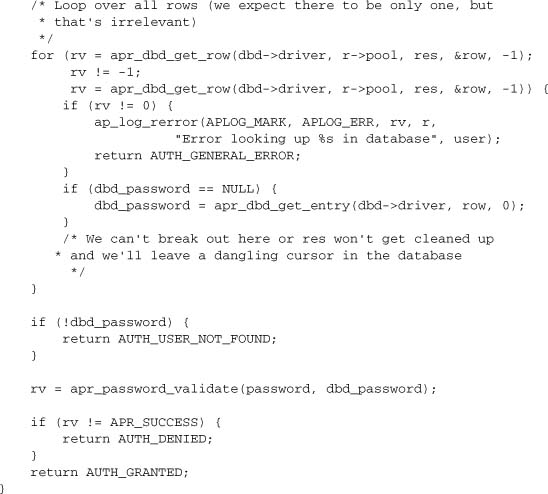
11.6. Developing a New DBD Driver
Sometimes you may wish to use Apache with a particular database that isn’t currently supported by the DBD framework. The recommended way to do so is to add support for your database to Apache/APR by writing a new driver. This approach offers several benefits over simply managing the database from within your own module:
- Architecture: You get the benefit of
mod_dbd’s connection strategies optimized for performance and scalability on both threaded and nonthreaded platforms. - Reusability: By writing an
apr_dbddriver, you make support for your chosen back end available to other modules, including your own, those distributed with Apache itself, and third-party modules. - Scrutiny: If you write a new driver and contribute it to the ASF (subject to any relevant intellectual property concerns), your work will be seen by other programmers, and it may be extended and improved.
Let’s look at the anatomy of a driver. Third-party authors to date have most often taken the PostgreSQL driver as a reference implementation. We’ll take the MySQL driver[5] as a case study to explain the elements of a driver.
11.6.1. The apr_dbd_internal.h Header File
As we saw earlier, applications access the apr_dbd API by including apr_dbd.h. Besides the public API, drivers need additional declarations in an extended API private to the apr_dbd subsystem. It is exposed in a private header file apr_dbd_internal.h (which, in turn, includes apr_dbd.h). This serves two purposes over and above the public API:
- It defines the
apr_dbd_driver_tstruct, which every driver implements. - It exports a thread mutex for the
apr_dbdsystem.
The apr_dbd_driver_t object is a struct comprising a name together with a number of functions corresponding to the apr_dbd API. The role of a driver is to export an apr_dbd_driver_t object, along with implementations of the functions. Partial implementations may be adequate for some purposes, so some functions may do nothing except return APR_ENOTIMPL.
11.6.2. Exporting a Driver
Given that the purpose of our driver is to export an apr_dbd_driver_t object, let’s start by doing exactly that. Here’s the declaration from the MySQL driver:
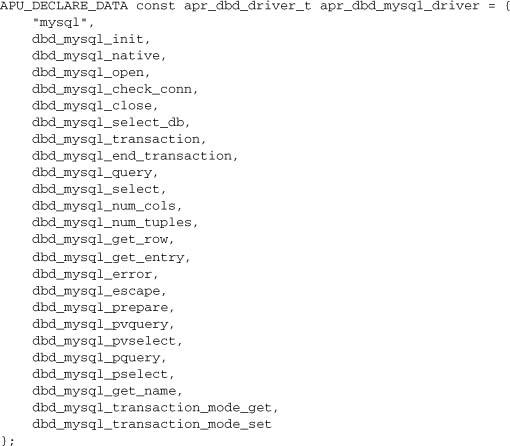
To complete the driver, all that remains is to implement each of these apr_dbd functions using the MySQL client API. To do so, we need to implement the apr_dbd data types. Apart from the driver (which is defined by apr_dbd_internal.h), these data types are private to the driver module itself, and will differ between drivers. Here are the definitions we use for MySQL (these are probably the simplest of any driver):

In summary, and setting aside housekeeping, we’re mapping the apr_dbd API to MySQL:
- The handle object
apr_dbd_tis aMYSQLhandle. - The
apr_dbdprepared statement is aMYSQL_STMT. - The
apr_dbdresults and row objects map to multiple MySQL objects.
11.6.3. The Driver Functions
To complete our driver, let’s describe the functions.
init
dbd_mysql_init is called once only, when the driver is initialized. MySQL requires us to initialize it with my_init to ensure the client library will be thread safe and reentrant, and to call another function on exit:

native
dbd_mysql_native returns a native handle for applications wanting functionality beyond the scope of the apr_dbd API:

open
dbd_mysql_open opens a new connection to a back-end database. Because the API constrains the parameters to be passed in a single string argument, this function has to be parsed to extract the arguments to the native function mysql_real_connect. This parsing may be reused in other drivers—for example, the Oracle driver copied this code.



check_conn
This function checks that a connection is still good. If the back end doesn’t support such an operation, it may return APR_ENOTIMPL.

close
This function closes a back-end connection.

select_db
This optional function selects a different database.

transaction_start
This function starts an SQL transaction. We do so using the C API, but could also have implemented it by executing an SQL statement.

transaction_end
This function ends a transaction, issuing a COMMIT if the transaction has executed successfully, or a ROLLBACK if an error occurred or if the mode was rollback.

transaction_mode_get
This function returns the current transaction mode.

transaction_mode_set
This function sets the transaction mode.

query
This function executes a one-off SQL query supplied as a simple string.

select
This function executes a one-off query that returns a results set. The last argument seek determines whether random access to results (i.e., get a row by row number) is required, or whether we will simply process results sequentially. This decision determines whether our driver uses mysql_store_result or the more efficient

num_cols
This function returns the number of columns in a results set.

num_tuples
This function returns the number of rows in a results set. If random access is not available (so that rows are accessed sequentially in a loop), it returns -1.

get_row
This function retrieves a row from a results set. If random access is available, we can select a row by number; otherwise, we simply get the next row.
A return value of -1 indicates end-of-data, and any other nonzero return value indicates an error. Drivers must clear the results set when this happens, to avoid a resource leak.

get_entry
This function returns a value from the row, as a string.

get_name
This function gets the name of a column in the results set.

error
In the event of a database error, this function returns a human-readable error message.

escape
This function escapes any characters in a string that would be unsafe or ambiguous to store as is in the database or to use in a query.

prepare
This function prepares an SQL statement. As discussed earlier, it supports %s format for arguments to a statement as well as the native ? form. This driver (currently) makes no attempt to support different data types, and it makes no use of the label argument.


pvquery and pquery
These functions execute a prepared statement using arguments supplied either as argc/argv (pquery) or varargs (pvquery). The latter form may support different data types (the Oracle driver does), but in this case we support only strings. These two functions are almost identical, so we’ll just reproduce one of them here.
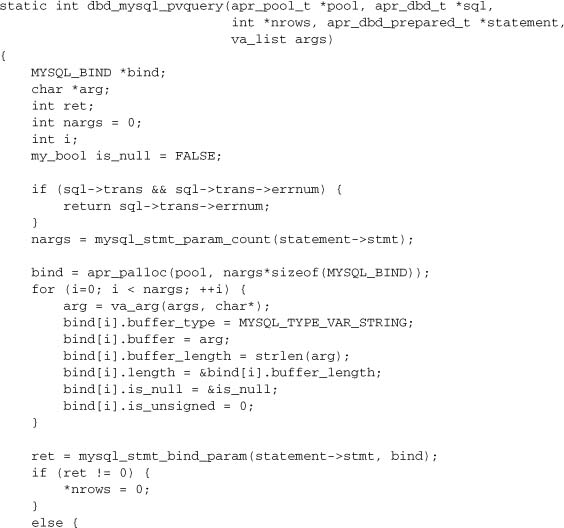

pselect and pvselect
These functions execute a prepared statement that returns a results set. As is the case with pquery/pvquery, they are essentially identical. In this driver, unlike the simple select function, no distinction is made between random and sequential access in the MySQL client library. Thus all we do with the random argument is save it for the benefit of the num_tuples and get_row functions.



11.7. Summary
The DBD API is one of the most recent innovations in Apache, having first appeared in Apache 2.2. It represents probably the most important fundamental advance in architecture for database applications since mod_perl introduced (what is now known as) LAMP in the mid-1990s. In this chapter we looked at the following topics:
- The need for a new framework
- The DBD architecture: a common API, plus connection pooling
- The
apr_dbdAPI (database objects and operations) - The
ap_dbdAPI (database connection management) - An example of using DBD in a module
- Writing a DBD driver to support a back-end database
It is anticipated that the DBD framework will support a new generation of web-database applications, including both C modules and LAMP applications running under the scripting modules. Programmers working in scripting languages should see the database objects and apr_dbd methods exposed in their language. In a case such as Perl, which has its own mature DBI/DBD framework, apr_dbd will be presented as a DBD provider instance such as DBD::APR. However, the details of scripting implementations are the business of the developers of the scripting modules and, therefore, are outside the scope of this book.