
Many of the architectural choices that we make constrain the way in which messages are delivered and the way in which they are processed. Two common examples of message delivery are REST APIs and service busses. Which one you choose often dictates how messages are processed. In a REST API, a message is sent as a synchronous HTTP request. The server processes the request and sends back the response. In a service bus, a message is sent asynchronously by pushing it to a queue or publishing it to a topic. The recipient processes the message as it pulls it from the queue and publishes the result, if any, for downstream consumption. Patterns for communication and processing are tightly bound.
Immutable architectures give us a way to separate those two concepts. We can make choices about communication based on how close the sender is to the recipient, whether they are controlled by the same organization or whether they are more or less permanently connected. On the other hand, we can make choices about processing based on how a conversation is intended to progress and whether the initiator expects a response. We can choose how to exchange facts between nodes irrespective of our choice of how those nodes process the messages.
The models that we have analyzed and constructed define what the nodes are talking about. They do not define how those nodes will talk. To maximize autonomy, each node will have just the subset of the model that it requires to serve its users and make its decisions. They all participate in an information exchange to share subsets with one another. To make the most appropriate communication choices, we need to understand those subsets, the needs of each node, and the constraints of different communication protocols.
Delivery Guarantees
As the parable of the Two Generals taught us, a node cannot know whether the message it just sent will be received. It has no guarantee based solely on the sending of the message. Instead, it only learns about successful delivery when it receives a subsequent message from the remote node. Knowledge is delayed. Guarantees can only be fulfilled by retrying until that knowledge arrives.

The OSI model of network communication divides protocols into seven layers of abstraction
At the network layer, no communication protocol offers a delivery guarantee. The network is concerned with addressing, routing, and error correction, but not with delivery. It is not responsible for establishing long-lived connections between nodes, retrying failed packets, or even reporting on success or failure.
At the next level up, the transport layer takes on the responsibility of reporting successful delivery back to the sender. It provides confirmation, but not necessarily disconfirmation. It is often not possible to prove that a message was not received. But ultimately, the transport layer must give up at some point. It cannot make a guarantee before sending a message that it will keep trying until the message is received.
It is only at the application layer that protocols begin to offer such guarantees. If a message is given to a durable protocol, then it will do everything that it can to ensure that the message makes it to the intended recipient. It will keep trying to send the message until it knows that it was received. It will resume after a power failure. Some protocols even make additional promises about the order, uniqueness, and latency of delivery. The more a durable protocol promises, the more expensive it will be. We will therefore accept the weakest promise that we can tolerate.
Best Effort
The term “best effort” is an unfortunate moniker. While it would seem to imply that there is no greater effort that could be applied to solving the problem of delivery, it in fact means the opposite. A best-effort service will not try to resend a message upon failure. In fact, it will not even report on the success or failure of delivery. It is the quality-of-service (QOS) equivalent of a shrug.
All protocols at some point are built on best-effort layers. In most modern applications, this usually means the Internet Protocol (IP). Some protocols extend that limited quality of service up to the application layer. These include User Datagram Protocol (UDP) and IP multicast. When latency is more important than delivery, these are appropriate choices. They can be used alongside more durable protocols to provide services such as presence, streaming, and health monitoring.
To build on top of a best-effort protocol, the recipient must provide feedback upon receipt. This gives the sender confirmation that the message has been delivered.
Confirmation
At the transport layer of the OSI model, some protocols rely upon confirmation that a packet has been received. This is often done to throttle communications, holding some packets back until earlier packets have been confirmed. But in many cases, this is also used to establish a duplex connection between the two nodes. The most prominent example is the Transmission Control Protocol (TCP), which is built on top of IP.
When a duplex—or two-way—connection has been established, each node knows that it can successfully route packets to the other. That connection offers a tunnel through which messages can be sent and received. Peers can rely upon the fact that if bytes are received, they arrive in order and with a very low probability of error. As long as the connection remains open and has not timed out, the TCP protocol will retry packets until they have been confirmed. No application intervention is required.
Many application protocols rely upon duplex connections to provide delivery confirmation to their consumers. The examples are too numerous to examine, but certainly the best known and most widely used is the Hypertext Transfer Protocol (HTTP). Despite “hypertext” in the name, this protocol has become the de facto standard of all sorts of information exchange on the Web, not only HTML but also SOAP, JSON, and gRPC. HTTP upholds delivery guarantees by constraining how nodes may change state upon receipt of various messages.
Safe Methods
The HTTP specification speaks of two properties of methods: safety and idempotence. The first category of methods that we will examine are those that have the property of safety. A safe method does not change the state of the server upon receipt. Verbs like GET and OPTIONS are safe.
Upon receiving a safe request, a server may retrieve information, but it may not alter its state in any observable way. Caching a response, while technically a state change, is not directly observable to a client. Caches are therefore allowed for servers processing safe methods.
As a client, you can feel confident in sending a safe request that you will not trigger any unwanted state changes. You can retry a GET on a different connection if you did not receive a response. The server should theoretically respond in the same way, assuming that no state changes occurred in the interim. Of course, there is no way for the client or the protocol to enforce this convention . It is entirely up to the server to refrain from changing state in response to a safe method.
Idempotent Methods
The second property of methods that HTTP defines is idempotence. This promises that the state of the server will change only upon the first receipt of a distinct message, not a subsequent receipt. All safe methods are by default idempotent; the server will not change state on even the first receipt, let alone the second one. And so the second category that we examine are idempotent, but not safe.
As we’ve learned in Chapter 4, idempotence is an important property of a message handler. It allows peers to retry messages without fear of changing state. If the first message was indeed received, then the second receipt will not change state further. In HTTP, PUT, PATCH, and DELETE are examples of idempotent verbs.
While idempotence is required for reliable message delivery, the reason for these verbs being labeled idempotent is not to permit retries and recover from duplication. It is simply based on the semantics of updating, patching, or deleting a resource. An update sets the state of a resource to a known quantity. A patch sets only some of the properties, but still to known quantities. Logically, one would anticipate that upon duplication, the resource is already in the desired state. Updating or patching the resource would have no effect. A similar argument applies for deleting an already-deleted resource.
Unfortunately, this line of reasoning only considers duplicates without intervening changes. If the resource changes between the original update and the duplicate, then the duplicate will reset the state of the resource back to a previous state. An eventually consistent handling of the message would ignore the duplicate , rather than applying it.
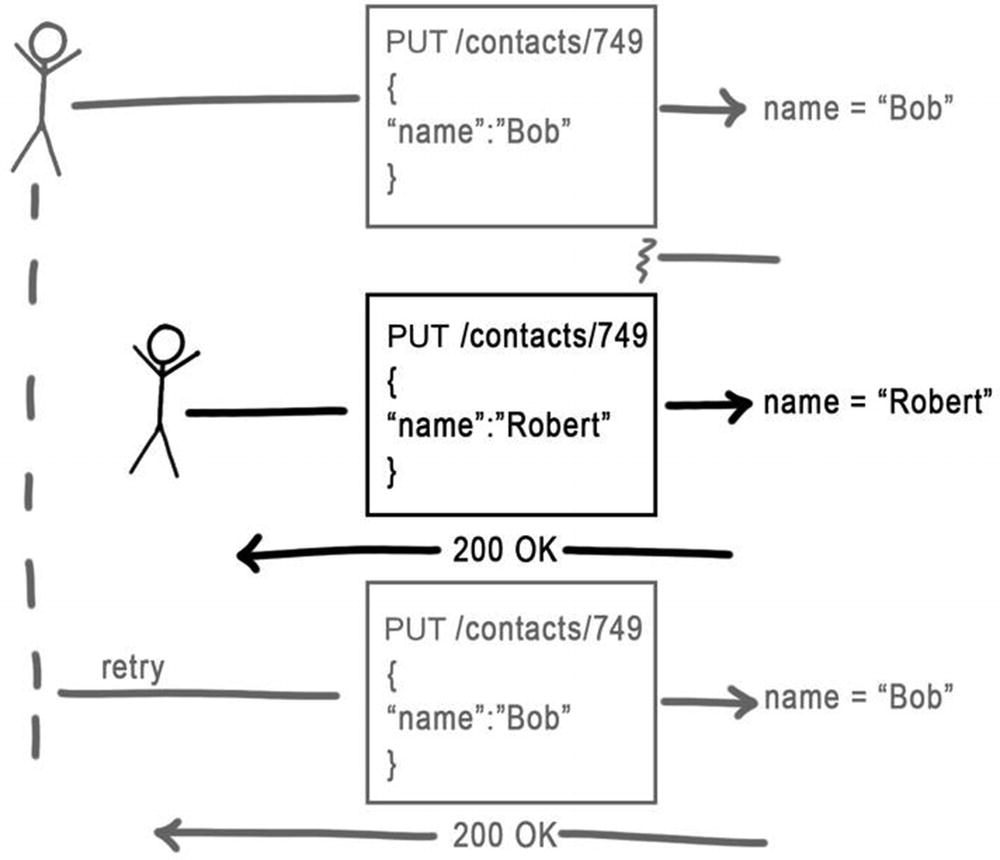
A server responding to a duplicate request after a different request has intervened
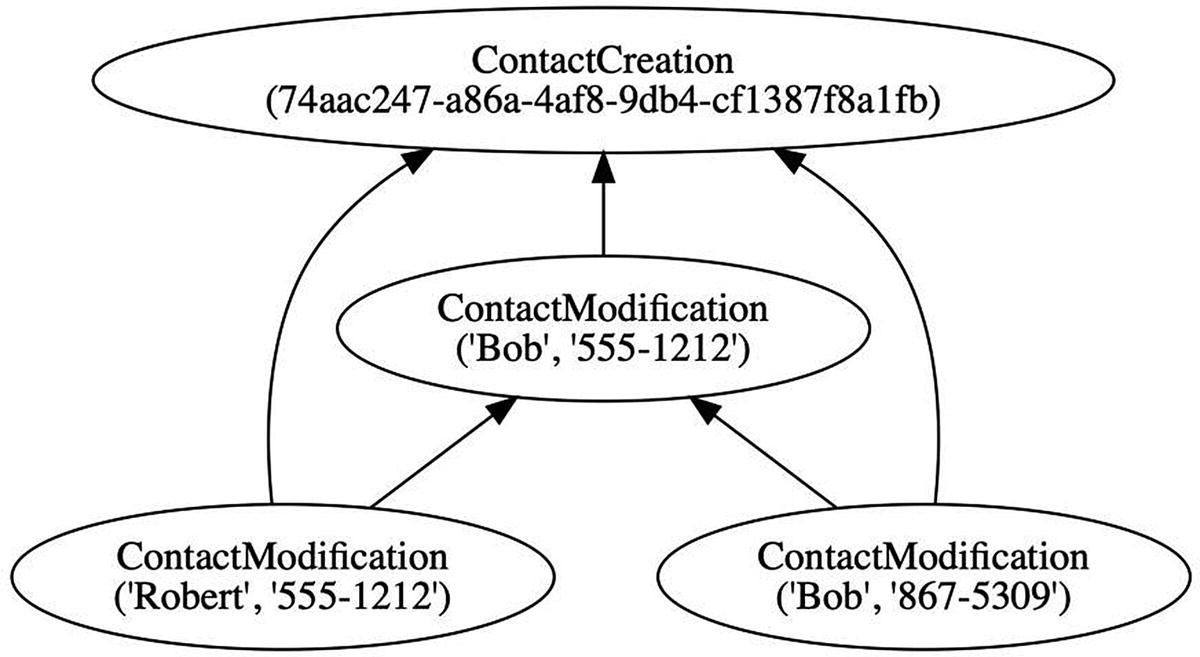
A data structure that allows a resource to have multiple simultaneous versions is both idempotent and commutative
The HTTP guarantee of idempotence is only semantic. The kinds of actions that idempotent verbs represent tend to bring a resource to a known state, even after the second application. But they offer no protection against message duplication. HTTP offers no guarantees of commutativity.
Non-idempotent Methods
The third category to consider are the methods that are neither safe nor idempotent. These methods offer no guarantees. They may change state upon every receipt. The POST verb is an example of this kind.
The semantics of POST make it likely that a change will in fact occur. In response to this request, a server creates a new resource and returns its identity in a 201 Created response. Presumably, the identity of the resource was not already known to the client before the request. If it was, the response would not need to include the URL. We can reasonably assume that in most implementations of POST, the identity was generated on the server.
When the identity is generated on the server, then there is little a client can do to prevent duplication. If the connection is lost before it receives the 201 Created response, the client has no recourse but to try again or report the error to the user (who is likely to try again). A second try will likely result in the creation of a second resource. HTTP makes no guarantee that the server will do any different .
Retry Within a Connection
Whatever the state-change guarantee of the HTTP method, the transport layer can only provide confirmation within the scope of a connection. Connections are relatively short-lived and reside entirely in memory. They represent a single-threaded communication channel between two peers.
Applications built on connection-oriented protocols need not retry messages on the same connection. TCP guarantees byte order, which implies that the retry would not be received until after the original message. But if the connection fails, then all bets are off. The sender has no knowledge of whether unconfirmed messages were received or not.
A connection can use delivery confirmation to guarantee that a message has been received. It cannot guarantee that a message will be received at some point in the future. Confirmation is a necessary, but not sufficient condition for durability. While HTTP only forwards the connection semantics from the transport layer, other application-layer protocols add durability.
Durable Protocols
When the user of an application initiates a command, they would like to have some confidence that the effect of their command will last. The protocols described in the previous section will simply force them to wait until a remote peer confirms receipt of their message. But doing so robs the user of some autonomy. They can no longer make a decision and issue a command without involving the remote peer. To have the greatest autonomy, they should be able to work in isolation. And so they demand more from their protocol.
A durable protocol is one that guarantees that a message will eventually be delivered. Delivery confirmation is necessary, but not sufficient. Durable protocols need to continue to retry until such confirmation is received, even over long periods of time or power outages. Durable protocols therefore require durable storage at the sending side, which can only be provided at the application layer of the OSI model. Two of the most common forms of durable message storage are queues and topics. Popular examples of these forms are Advanced Message Queueing Protocol (AMQP) and Apache Kafka.
Queues
AMQP is a standard application-layer protocol for exchanging messages in queues. It is implemented by such queueing systems as RabbitMQ, Apache ActiveMQ, and Azure Service Bus. AMQP is a configurable protocol, offering several levels of service. Some of those service levels provide at least once delivery or the guarantee that the sender will keep trying until a message is received. This promise survives beyond a single connection or session. It even survives power outages.
To provide this guarantee, AMQP implementations store messages on the client side. When a user publishes a message to an AMQP provider, it stores the message immediately, before contacting any remote peers. At that point, the application can be assured that the message will be delivered. The engine begins the background process of creating a connection, transmitting messages, and receiving confirmations. Once a message is confirmed, it can be removed from client storage. Until then, it must be preserved.
Topics
Where AMQP defines queues, Kafka defines topics. A topic is a persistent stream of records. Unlike a queue, records in a topic are not removed when they are consumed. This allows a Kafka topic to support multiple subscribers, each of which receives all messages.
In addition to multiple subscribers, message retention allows topics to provide a stronger delivery guarantee. Since all past messages are still in storage, a topic can determine whether a message is a duplicate. It can ignore the duplicate, preventing it from being sent to the subscribers. This level of guarantee is referred to as exactly once delivery.
Duplicate detection only lasts as long as the messages are persisted. Not all topic implementations store messages indefinitely. Kafka topics, for example, have a configurable retention period that defaults to 7 days. If a duplicate message arrives after the retention period expires, then it will be sent to subscribers.
For immutable architectures, at least once delivery is sufficient. Such applications are based on data structures that persist historical facts indefinitely. If a duplicate is received, it will be detected, as the fact is already in storage. And since records are identified by their content-based address, collisions are prevented at the storage level. Even though a durable protocol might offer exactly once delivery guarantees, enabling that configuration might prove to be as expensive as it is unnecessary.
Message Processing
In addition to delivery guarantees, we must also consider the timing of message processing when evaluating communication protocols. Synchronous protocols require that the message be processed immediately upon receipt, as the peer is actively waiting on the result. Asynchronous protocols allow the recipient to process the message later. These protocols tend to offer greater autonomy, as remote nodes are not waiting on one another.
An application based on immutable architecture tends to value autonomy over most other factors. Each node has precisely the subset of information that it needs to support the decisions that it and its users will need to make. Therefore, asynchronous protocols tend to be preferred.
Most Protocols Are Asynchronous
This choice between synchronous and asynchronous message processing is not completely isolated from the choice of delivery guarantee. A protocol offering only best-effort delivery is not going to inform the client node about the success or failure of the message. It is certainly not going to wait for the server to process the request. These protocols therefore only support asynchronous message processing.
On the other extreme, protocols that offer durability guarantees will make that promise immediately upon storing the message on the client side. The actual communication with the server might take place shortly thereafter or might be deferred for a long period of time. The protocol has no way of signaling back to the client application that the message has been delivered. Such protocols therefore typically do not require that the remote peer process the request immediately and tend to be asynchronous in nature. Immutable architectures favor these kinds of protocols.
Only in the middle , where the client application receives a delivery confirmation, does it make sense to require synchronous message processing. The client application is actively waiting on a response. That response could well include the results of processing the message.
HTTP Is Usually Synchronous
HTTP by default is a synchronous protocol . When a client sends a request, it waits for the server to make a response. That response is both a delivery confirmation and the results of the message processing. HTTP response codes include such information as whether a resource was created (201 Created), whether the client was authorized to access that resource (403 Forbidden), or whether the processing resulted in a conflict (409 Conflict). These responses imply at least some degree of synchronous processing.
HTTP does not, however, require that the server process the response immediately. Some HTTP response codes (most notably 202 Accepted) are intended to reflect that the processing will happen asynchronously. In this case, information about the outcome of the process is not included within the response. It only serves as delivery confirmation.
In the current application landscape, most traffic over the public Internet is based on HTTP. Asynchronous protocols are not quite as popular outside of the firewall. AMQP can be tunneled over TLS and is sometimes exposed on the Internet. But more frequently, it is kept secured within an organizations datacenter, or exposed on the boundary between organizations. Mobile applications favor HTTP over other protocols, and browser-based clients use HTTP almost exclusively. Perhaps in the future, using asynchronous protocols on the Internet will become more commonplace. But for now, attaching a public client to a server usually involves HTTP . But this does not mean that we have to use it synchronously. Even request/response protocols can be used asynchronously.
Data Synchronization
The word “synchronization” is another unfortunate term when applied to data. Synchronization literally means to make two systems progress at the same time, or at least the same rate. Two people can synchronize their watches so that they both read the same time. But synchronizing data is specifically not about time. The goal is autonomy, not synchrony. What we seek when we synchronize data is consistency . If you ask two nodes the same question, they will give the same answer. They can do this because they have the same information, not because they are operating at the same time.
Nodes in an immutable architecture have a subset of data at their disposal. This allows the users and processes on that node to make decisions without consulting other nodes. The procedure that we refer to as data synchronization is just the process of exchanging immutable facts with peer nodes so that their data structures converge. Each node will have only the subset that it requires, but where those subsets overlap, the rules of conflict-free replicated data types (CRDT) guarantee that consistency has been reached when the procedure is complete.
Building on top of immutable data structures, we can now decide independently which protocols to use in this procedure. What kind of delivery guarantees do we require? Should messages be processed synchronously or asynchronously? Are we restricted to common open protocols, or can we choose bespoke options with more desirable characteristics? Will peers be addressable, or will we have to wait for them to call us? Will nodes be permanently connected, or will they connect only occasionally?
To answer these questions, we will examine three main use cases. Each of these represents a different communication structure that is commonly found in immutable architectures. Each one requires a slightly different set of protocol choices.
For communication between servers within an organization, we will favor less ubiquitous but more asynchronous protocols such as AMQP and Kafka. This will help us to build an immutable microservices architecture. For communications between organizations, we will instead favor the more common REST APIs and webhooks, leading to lower infrastructure coupling. And for occasionally connected clients like mobile apps and progressive web apps (PWAs), we will use HTTP as an asynchronous protocol.
Within an Organization
Data synchronization within an organization is a bit of a luxury. One group controls all of the servers, all of the data stores, and the entire network. We have the luxury of selecting our preferred tools, meaning that we can use AMQP or Kafka if we choose. We also have the luxury of a fast, always-available connection between microservices. We will not abuse this luxury by calling from one to the other on every request, but we can keep their data stores synchronized.
With this kind of luxury, it is easy to get complacent. Intraorganizational architectures will sometimes share databases between services. They will often relax security controls within the firewall. And they will ignore versioning concerns, since they could deploy both sides of a connection at the same time. Each of these compromises to architectural integrity comes at a cost to future flexibility. They increase the coupling between services for the sake of convenience. When deploying microservices within a single organization, you can take advantage of the luxuries that you have while still avoiding unnecessary coupling.
To understand exactly how we are going to synchronize data between microservices, we must first determine what they are. Then we can analyze the boundaries between them to decide the best means of integration. The outcome of the analysis from Chapter 5 is your guide to where the boundaries should be drawn.
Pivots
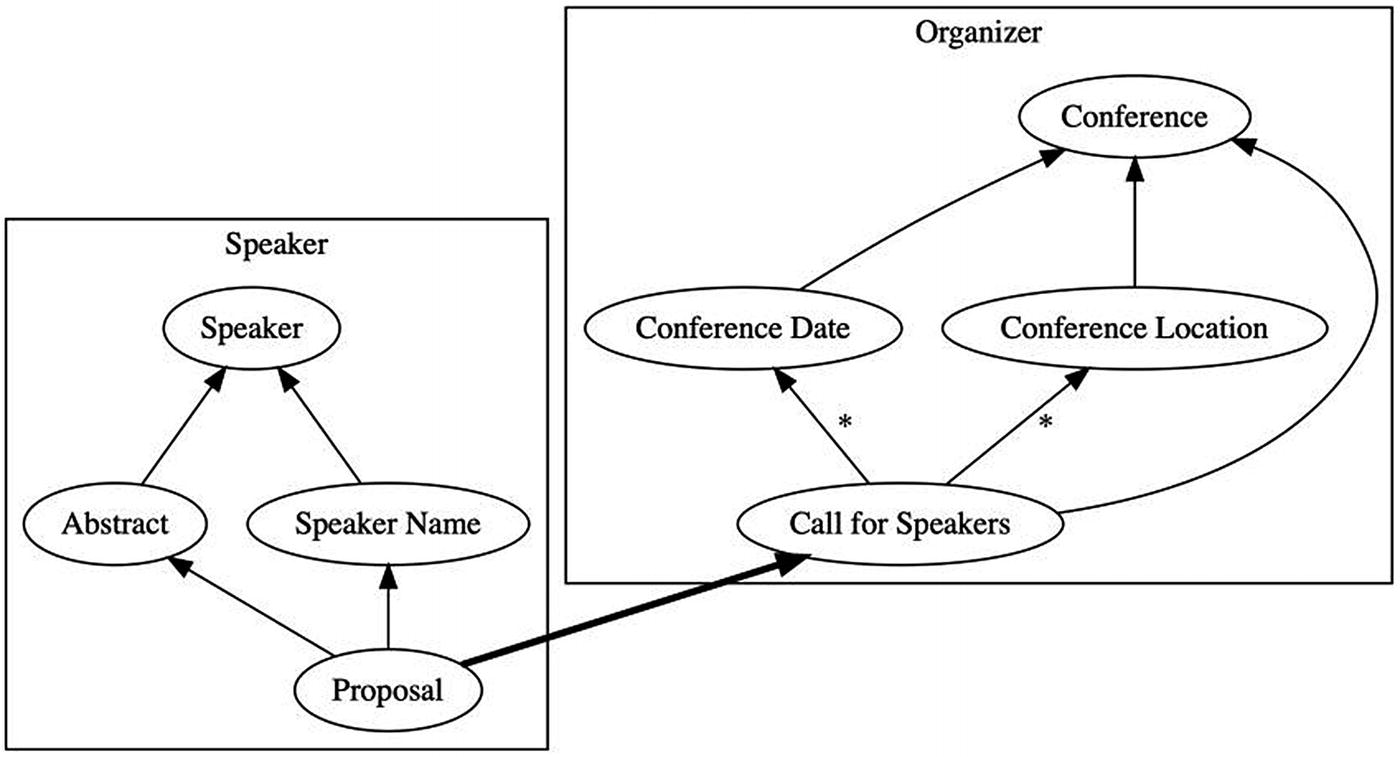
When producing a historical model, we identified regions. These were areas of the model in which all of the facts originated from a particular actor. When a predecessor/successor relationship crosses a boundary between two regions, two actors are collaborating with one another. I call such a predecessor/successor relationship a pivot.

A model highlighting the pivots, where arrows cross region boundaries
During the analysis phase, a region represented the responsibilities of a single actor or set of actors. As we transition into implementation, we will construct a microservice for each audience. And so each region now represents a microservice. In this example, conference organizers have a microservice for collecting proposals and defining schedules. Speakers have a microservice for viewing calls, submitting proposals, and learning about acceptance. Finally, attendees have a microservice for viewing a conference schedule, selecting sessions to attend, and submitting ratings. The pivots are points of integration among these microservices.
The microservice at the head of a pivot needs to publish the predecessor fact so that the microservice at the tail can subscribe to it. Let’s begin with the topmost predecessor in the causal chain, the call for speakers. This fact is in the organizer microservice.
Multiple Subscribers
Pivots at the top of the causal chain tend to be places where facts are published for multiple subscribers. The publisher might not have one specific use case in mind, and future subscribers could be added at any time. But even when there is a known use case, as in this example, sending a message to a specific subscriber introduces unnecessary coupling. And so top-level pivots are good candidates for topics, such as those provided by Kafka.
The microservice at the head of the arrow publishes a message to a topic when the predecessor fact is created. This message includes all of the information contained in the fact and all of its predecessors. To compute the set of all facts included in the message, perform a transitive closure over the predecessors. Recursively visit the predecessor relationships until the entire set is gathered. The message should contain all of this information, and only this information.
Two problems arise when publishing a message that contains more than the transitive closure of the predecessors. The first is that message is not deterministic. If the message contains internal database IDs, the time of creation, or any other detail not already part of the facts, then running the process again produces a different message. The process could be repeated for any number of reasons: there was an infrastructure glitch, the fact was produced by two redundant instances, the user clicked the submit button twice, and so on. If any of these situations arise, we want the process of generating a message from a fact to be deterministic, so that the downstream consumer can practice idempotence and ignore the duplicate.
The second problem is that the message might contain information in successor facts. Successors can be created either before or after the message is published. If the message contains successor information, then subscribers will not learn of new successors created after the fact. In the example in Figure 11-4, the transitive closure of the call for speakers fact includes the conference. It does not include times or rooms. If speakers needed to know (for some reason) the number of rooms at the conference, this information might or might not be available at the time of publication. If a room is added later, they will not learn about it.
There are some successors that you will want subscribers to learn about. For example, the conference date (not shown in Figure 11-4) will be an important part of knowing whether to submit a proposal. Given that that is likely to be a mutable property of a conference, it will be modeled as a successor. Analysts have two options for resolving this problem: they can turn the successor into a predecessor of the published fact, or they can publish the successor.

A call for speakers is a transaction that captures the current date and location
To publish the successor , produce an additional topic. Subscribers to the pivot can also subscribe to this topic. They will correlate the messages between the two topics using their common predecessor, in this case the conference. If the conference date is changed after the call for speakers has been published, then the subscriber will see that change and update their data store.
Responses
Facts on the tail of a pivot represent responses to messages. Responses are directed back toward earlier microservices. It therefore makes sense to use queues instead of topics for these kinds of messages. The producer of the original message includes the name of a response queue. Subscribers post response messages to the given queue. This manages coupling between publisher and subscriber, because the queue name is provided dynamically. In Figure 11-4, the proposal fact is a response to the call for speakers. It is directed toward the organizer microservice. That microservice will therefore create and manage a queue specifically for accepting proposals.
A proposal gathers together all of the facts that will be necessary for the organizer to make a decision
Since the speaker microservice knows about the call for speakers topic, it is tempting to also have it know about the proposal queue. Doing so would seem not to increase coupling between the two services. But that would be a mistake. Only the organizer microservice knows how it will respond to proposals. It might change the topology in a future release. It alone should be responsible for deciding where the response queue is located.
Pivots further down in the causal chain also represent responses. In Figure 11-4, the reject and accept facts are responses to the proposal. These kinds of responses should follow the same pattern. When the speaker microservice generates the proposal message, it includes the name of its own response queue .
Notifications
Not all responses are direct successors of pivots. And not all two-way conversations between microservices appear as arrows crossing region boundaries in both directions. Sometimes the relationships are hidden a little deeper in the model.
Every conversation between microservices ends with a message that has no response. This message serves only as a notification. It informs the recipient of the outcome of a process. These appear as leaves in the model below pivots. The rate fact is an example in Figure 11-4.
When a conference attendee rates a session that they have attended, they are simply giving feedback to the organizer. They do not expect any response to that rating. There is therefore no further pivot below the rate fact indicating that the conversation continues. The rating is pushed to a queue that the organizer provides, just as any other response. The name of that queue will be included in the schedule message, as that is the predecessor of the nearest pivot.
Between Organizations
When servers are not under our direct control, we lose a bit of the luxury that we might have had within a single organization. We can no longer choose from all available protocols to select the best possible fit. And we don’t have any governance over the way in which peer systems will be modeled. Partners might not even be using immutable architecture. We adapt by implementing additional constraints and transforming our services to be more familiar.
One of the constraints of crossing organization boundaries is that the communication protocols need to be supported by both sides. This usually means that asynchronous protocols like AMQP are replaced by synchronous protocols like HTTP. The timing of message processing is not the issue; it is simply adoption. The more widely adopted protocols today tend to be those that support synchronous processing by default. A compromise can often be reached by using HTTP in an asynchronous manner.
Async over HTTP
External organizations will often need to publish messages to your services. Semantically, these are commands, instructing your service to perform some kind of business function. In a historical model, these are simply predecessors of a pivot, created in a remote region of the model. If we were working entirely within the scope of a single organization, we might choose a topic or queue to publish these messages. But since we are providing an endpoint for a partner, we will instead use HTTP. We can design the endpoint with additional constraints, not part of the HTTP specification, to make it work well with immutable architectures.
According to the HTTP specification, POST is neither required to be safe nor idempotent. However, an endpoint provided to partner organizations will clearly benefit from idempotence. This does not rule out HTTP POST. It only means that we implement the server to uphold stronger guarantees than the specification requires.
First, we ensure that the body of the message contains enough information to generate a unique identity. When we receive this request, we will generate a fact. The contents of this new fact need to be completely determined by the contents of the message. We will not use the time of receipt, a server-generated ID, or any other nondeterministic data to produce this fact. This guarantees that if the partner repeats this request, they will generate the same fact. That is the first step to making POST idempotent.
Second, we generate the URL of the resource using only information from the new fact and computing the transitive closure of the new fact to find the graph of all predecessors. Pull fields from these predecessors, and assemble them into a path. Append that path to the host name of the exposed endpoint to compose the URL. Assuming that we have used all of the fields, this generates a one-to-one mapping between facts and URLs. When the partner makes a subsequent call to the endpoint, we will be able to pull the components out of the path and reconstruct the fact.
And third, respond to the POST immediately after the new fact is stored. Do not wait until the request is processed. Before storing the fact, you will have the opportunity to run the authorization rules to make sure the partner is authorized to make this request. But there is no need to wait until the request is processed. You can complete processing asynchronously.
An endpoint implemented according to these constraints will be idempotent. Any subsequent POST of the same request will yield the existing fact. Because the service is using content-addressed storage, it will recognize that the fact already exists. It simply responds with the same URL as it had originally produced.
Such an endpoint is also durable. It does not respond until the fact is stored. A side effect of storing the fact might also be adding it to a topic or queue for further processing. The delivery confirmation of 201 Created indicates that this storage has occurred and has been committed. The sender may stop sending at that point; the message has been saved.
Finally, this endpoint is location independent. The URL does not contain any server-generated IDs. If the request had been handled by a different server, it would have produced the same URL and the same fact. We are free to reorganize our infrastructure, fail over to a backup datacenter, or mirror requests to different geographical regions . None of these implementation details will be visible to our partners.
Webhooks
If our infrastructure were completely within our control, we could just post responses to a queue. When working with partners, though, we sometimes don’t have the luxury of using queueing protocols. Yet we still want to pass the names of queues across organizational boundaries to reduce coupling between peer services.
The equivalent of a response queue in HTTP is a webhook. A webhook is an HTTP endpoint intended for use as a callback, a place to which to send responses. One service registers a webhook with another by providing an endpoint URL. The other service POSTs to this endpoint whenever there is new information to report about the topic.
A response in a historical model appears as the immediate or eventual successor of a pivot. We should generate webhooks based on the pivot’s predecessor. As described previously, compute the transitive closure of the predecessor and extract all fields of those facts. Construct a path and append it to a host name. That URL can now be used as a webhook. The service listening at that host can reconstruct the predecessor from the path.
Since the path contains all of the information necessary to reconstruct the predecessor, the body of the message does not need to include it. The body is all of the information necessary to create the successor fact except for the predecessor identified in the path. The service handling the webhook will follow all of the constraints of the command endpoint described earlier to ensure that responses are idempotent, durable, and location independent .
Emulating REST
In many integrations , an organization that has adopted immutable architecture will be integrating with one that has not. We might not have the luxury of defining the API so that it works well with immutability. We might have to adhere to an API that the partner has defined or provide one that is more familiar to them. In those situations, we can both consume and implement REST APIs from immutable services.
To consume a REST API from an immutable model, apply the Outbox pattern as described in Chapter 8. The Outbox pattern creates a bridge between a historical model and a third-party API. The caller maps facts that the partner needs to know about into API calls. They record a journal of the responses from those API calls indexed by the hash of the facts. While this pattern cannot turn a REST API into an idempotent, durable data exchange, it provides at least a little protection against infrastructure failures. The rest is up to the partner.
To produce a REST API with an immutable model, we apply the Structural patterns in Chapter 8 to map all of the incoming requests into semantically equivalent facts. A POST maps to an Entity fact and likely one or more Mutable Property facts. A PUT or PATCH maps to one or more Mutable Properties. A DELETE generates a Delete fact. Based on the semantics of the domain, other patterns could be brought into play.
Where possible, generate URLs as described previously using only information found in the transitive closure. Ideally, all of the information needed to generate the fact will be present in the request. That would produce a truly idempotent API. However, this will not always be possible. In particular, Mutable Property facts cannot be generated based only on the desired value of those properties. They need to know their predecessors, which is not something traditionally given in a REST API.
If the query results in one fact, and the value of that fact matches the desired value in the PUT or PATCH, then ignore the request. The property already unambiguously has the desired value. But if the number of results is not 1, or the current value is different, then create a new property fact having these results as predecessors. This algorithm allows the client to resolve conflicts by putting the desired value. Unfortunately, it does not capture what the client actually believed the original value to be and therefore record the real causal graph. Only a client participating in the immutable model and using an appropriately designed API could do that.
To GET a resource from a historical model, you will need to run several property queries. Generate the starting entity fact from the URL as described previously. Then run queries for all properties that you intend to return. If any of those queries returns more than one result, apply a conflict resolution function to determine the desired result. REST consumers are not used to properties having more than one value. Do not save the results of your conflict resolution. GETs are supposed to be safe.
A REST API produced from a historical model will compromise some of the benefits of immutability. It will only be as idempotent as a traditional REST implementation. It will not have the commutativity guarantees of an end-to-end immutable architecture. But it will be more familiar to partners who have not yet adopted these strategies .
Occasionally Connected Clients
The third common scenario for integrating with an immutable architecture is to support offline mobile or web clients. Whereas most mobile apps and websites in use today must have a continuous connection to a back-end API, an offline client can interact with the user even when that connection is interrupted. They have their own storage, their own outbound message queue, and can participate in conflict detection and resolution. Native mobile applications have storage capabilities from the operating system; web clients can use advanced browser features, operating as progressive web apps (PWAs).
Mobile and web applications designed to be used in this way are typically offline first. All of the data presented to the user is loaded from local storage, not an API call. Every user action is stored locally and pushed to a queue, not sent to the server. Synchronizing local storage with server history takes place in the background. The user can see the progress of that activity, but they are not blocked by it.
Occasionally connected clients will greatly outnumber servers. They will come online with nothing more than a download or a bookmark from the user. They might be used for a long period of time, or they might be visited once and quickly abandoned. When a client leaves the ecosystem, the server will not receive any notification. It would therefore be wasteful for servers to keep track of meta-information on behalf of the clients. The protocol for synchronizing an occasionally connected client puts the storage burden entirely on the client.
Client-Side Queue
As the user interacts with the client application, it will generate facts. These facts will be stored in its local subset of the historical graph. They will also be added to an outgoing queue. The user is permitted to continue interacting with the application as soon as the fact is stored and the message is queued. They do not have to wait for it to be sent to the server.
Mobile applications can use a local SQLite, Core Data, or Realm database for both fact and queue storage. To design the fact storage, see all of the advice given in Chapter 10. The outgoing queue is simply a record of which facts have not yet been sent to the server. It could be as simple as a table of foreign keys into the fact storage.
Progressive web applications can use IndexedDB to store facts and queues. This browser feature is not as rich as a SQL database. Instead, it is simply a set of name/value pair collections. Consider using one collection per type of fact. The keys of these collections are the hashes of the facts. In addition, the PWA has a collection for the outbound queue, indexed using a monotonically increasing key.
To send the outgoing messages to the server, the mobile application or PWA calls an HTTP endpoint. This is not a RESTful endpoint providing the usual semantics of POST, PUT, PATCH, and DELETE. That kind of endpoint compromises the value of an immutable architecture and is intended for use by clients that do not participate in the historical model. Instead, this is a more constrained endpoint to which messages can be POSTed in an idempotent and commutative way, as described for intraorganizational command transfer.
To reduce latency and make the most efficient use of the network, clients will batch several outbound facts into a single request. The contents of a POST will be a collection of facts of various types. My favorite way to encode a batch is as a JSON object in which the keys are base-64 encoded hashes. This makes it easy for the server to find incoming facts by their hash and helps to ensure that a fact is not unnecessarily duplicated within the same batch. The body of each fact contains the type, the fields, and the hashes of its predecessors.
Assuming that the predecessors were already known to the server before the upload began, it would have no trouble finding them by their hash and establishing the link in its own database. However, this assumption cannot be guaranteed in practice. A client might not be talking to the same server from one session to the next. Servers may be spread across different datacenters to gain redundancy or geographic proximity. It is therefore wise to include the transitive closure over the predecessors of all outgoing facts. This is why it is important to eliminate unnecessary duplication within the batch.
When the server receives the batch, it must store each of the facts in turn. Storing a fact requires executing authorization queries and setting up foreign keys. For those reasons, the server must have already stored the predecessors. It therefore processes the incoming batch in topological order. It recursively visits all predecessors before handling each message. When it visits a fact, it first looks in a temporary data structure to see if it has already visited that fact. If not, it verifies the hash, then looks in its own database for that record. If it is present, it moves on. If not, it runs the authorization rules and saves the new fact.
When it is done, the server responds with a 200 OK message. After that, the client can delete all facts sent in the batch from its outbound queue. The client continues until the queue is empty .
Client-Side Bookmark
Because clients outnumber servers, all of the meta-information is kept on the client. This includes the outbound queue that we just discussed. And it also includes information about inbound facts. Rather than keeping a per-client queue on the server, each client keeps its own bookmark.
A bookmark is a placeholder within a sequence of facts. It identifies the last fact that the client has received and stored. The client can ask for a batch of facts greater than a given bookmark, and the server will respond with both a collection of facts and a new bookmark. That new bookmark corresponds to the last fact in the batch.
Because we need to know which facts came after a given bookmark, these identifiers must be totally ordered. A total order is one that allows us to compare any two elements in the sequence. We can tell for sure whether one element is before or after another. In every other sense, however, facts are partially ordered. You know that a predecessor came before a predecessor, but you cannot compare two facts that are not causally related. Furthermore, facts are usually identified by their hash, which does not obey any kind of order. We therefore need a new method of identifying facts for use with a bookmark.
The identity of a fact within a sequence must be monotonically increasing. Later facts cannot be given identifiers less than or equal to earlier ones. If that were ever violated, then a client using a bookmark from an earlier fact would miss later facts on subsequent requests. Timestamps alone are not sufficient for this purpose, as two facts could be stored at exactly the same time. An auto-incremented ID is the best choice. Even then, extra precautions must be taken to avoid reading a later ID before earlier IDs have been committed. One such precaution is to remove facts from the end of the batch until one is found that is old enough for concurrent writes to have settled. This implies that clients might not receive the absolute latest information until a subsequent read, but it mitigates against writes that happen out of order of ID allocation.
Imposing a total order on a partially ordered collection has a serious drawback. It means that bookmarks are location specific. If the mobile device or PWA were to connect to a different server on a subsequent fetch, the bookmark that it received from the last fetch would be meaningless. Different back-end nodes might have put the partially ordered facts into different total orders. For this reason, the client needs to keep a separate bookmark for each data store it contacts.
A datacenter having a load-balanced cluster of servers all sharing a common database is not a concern. No matter which server the client uses, the shared database generates the monotonically increasing IDs. The issue only arises when servers use different data stores. So bookmarks are really per database, not per server. Each database should generate its own unique identifier and use that to distinguish its bookmarks from those of other databases.
The client sends all of its bookmarks with the request. The server determines which bookmark is associated with the database it is using. If the client has no bookmark for that database, it starts at the beginning. The server then responds with a batch of facts, the database ID, and the new bookmark. The client stores all of those facts and updates its bookmark for that specific database. It repeats until the request yields no new facts.
In most network topologies, including a database ID is an overabundance of caution. The entire population of mobile clients can be served from a single database. As long as that remains true, then the clients will each have one bookmark that marches steadily forward. However, if the day ever comes that the database needs to fail over to a standby, then there is no guarantee that the order of insertions will be consistent between the two. Clients will find themselves redownloading the data set, but they will be able to detect and ignore duplicates. They will also be guaranteed not to miss any information as a result of data stored in different orders across different databases .
Choosing a Subset
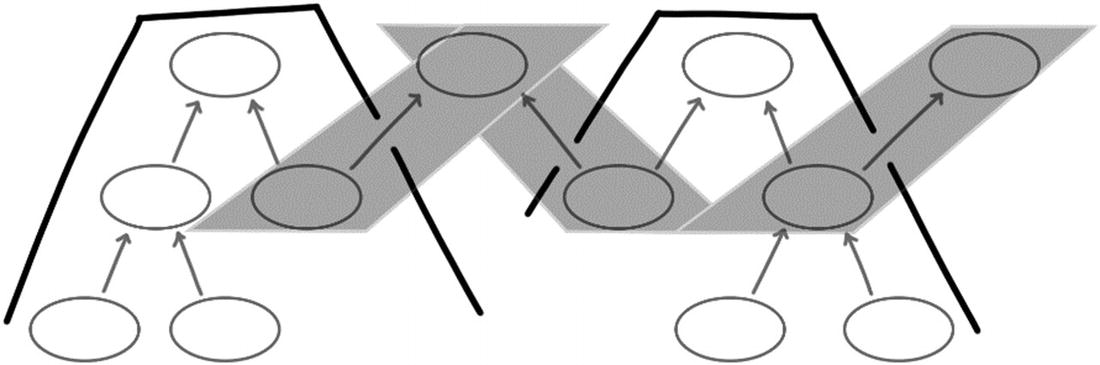
A mobile or PWA client rarely needs to fetch the entire contents of the data model. These clients will have a single user, and that user will have access to only a subset of the data. Occasionally connected clients should fetch only the facts that their user needs. Based on an understanding of the model and how it will be used, we can divide facts into subsets. A particular user will have access to a small number of these subsets. The client will therefore need to keep track of separate bookmarks. It has one bookmark per database per subset.

A subset of a model is the cone of direct and indirect successors of a given root
There are two kinds of facts that make for good subset roots: groups and periods. A group is a top-level fact participating in the Membership pattern defined in Chapter 8. A membership fact has two predecessors: a group and a user. It grants the user membership into the group and therefore access to its resources. Membership facts often determine authorization and distribution rules. A user need not see facts outside of the groups of which he is a member.
A period is a near top-level fact participating in the Period pattern. This fact breaks successors down across time. A natural clock within the problem domain moves forward and points to the current period. This might be a date of business at a restaurant or a semester at a school. New facts are added to the current period. So client apps can focus only on recent periods and ignore older ones.
The facts downloaded to a device include the cone of successors of a root and all of their predecessors

A secret channel is a group to which collaborators are invited
If we were to construct an occasionally connected mobile app or PWA for this model, SecretChannel would be an excellent choice of a fact that identifies a subset. If the user of the app is the creator or a collaborator in the channel, then they would expect all of the messages to be downloaded to their device. The group defines a subset of the graph containing the transitive closure of its successors.

The subset of facts under Alice includes her channel, but not the messages in her channel
The algorithm for identifying facts within a subset boils down to a recursive traversal of the graph. Start at the identified root. Recursively visit all successors of that fact. Add that successor and its transitive closure of predecessors to the subset. If the visited fact is not itself a root, continue with its successors. This will give the set of facts that an occasionally connected client needs to serve its user.
Each client keeps a different set of bookmarks for each root. When it fetches facts from the server, it identifies the root by hash. The server responds with a batch of facts that are in that subset. In the case of the model in Figure 11-10, the first root is the logged in user. That fetches the channels that they have created and the invitations that have been sent to them. With that information, the client makes additional requests for each of those channels. This fetches the subset of messages that the user can see. And each channel has its own bookmark.
Avoiding Redundant Downloads
With queues for uploading facts and bookmarks for downloading them, we are starting to construct an algorithm for background data synchronization in an occasionally connected app. But as we put the two together, a problem emerges. All of the facts that a client uploads will be appended to the total order on the server. They will be greater than the client’s bookmark. That means that they will be downloaded again to the client the next time it fetches. This is a waste of bandwidth.
We would like the client to fetch only the facts that it itself did not upload. We can get close to this behavior by simply performing the download first, then the upload. The client downloads facts greater than its current bookmark. It stops when the fetch returns no new facts. Then it uploads batches from its outgoing queue. It stops when the queue is empty.
At that point—ideally—the only facts greater than its bookmark would be the ones it just uploaded. So if we could update the bookmark without redownloading those facts, we would avoid the redundancy. The problem is that other facts may have been added in the meantime. Other clients might have uploaded their facts, or other processes might have created information that should be sent to the client. And so we cannot assume that we can update the bookmark without missing something that happened concurrently.
A good optimization is to send with the fetch request a list of hashes. These are the facts that the client just finished uploaded. The server will filter out these facts from the response. In the ideal scenario, no new facts have been added, and so the entire download batch is filtered. In this case, the server returns an empty collection and a new bookmark. The client updates their bookmark, and we have avoided redundant downloads.
If, on the other hand, new facts were added concurrently, then the server would return only those new facts. It would also return the latest bookmark, including the new and the filtered facts. Upon seeing that response, the client would store the concurrent facts and update its bookmark. We achieve the correct behavior and avoid the redundant downloads.
This solution keeps all of the meta-information on the client. The client keeps track of the uploaded fact hashes in memory during the background sync operation. The server receives this information in the request and only uses it to filter that response. It does not store any per-client information in order to optimize network usage. And if something fails on the client, then it simply falls back to the correct, if suboptimal, redownloading of facts.