
From the beginning of the software industry, people have been responsible for writing programs. A large number of decisions go into every program written. People have to be vigilant not to introduce defective behavior as they make those complex interconnected decisions.
Over time, the level of detail implicit in those decisions has risen to higher and higher abstractions. Early software developers worked at the machine level. Modern software is increasingly written in higher-level languages. In the past few decades, managed runtimes have improved in performance and productivity to the point that it is becoming harder to justify writing code to the metal. Developers are making fewer and fewer detailed decisions. As we continue up the ladder of abstraction, we can use our new vantage point to look across to other islands.
Software is written in islands of behavior. The database is designed to store and query data for a specific application. The business logic operates on objects in memory. The user interface presents data and responds to user inputs. Network APIs handle security and communications. Modern application development is an exercise in bridging those gaps for every application. Between the database and the business logic, developers construct a data access layer either by hand or with an object relational mapper (ORM). Between the business logic and user interface, developers write view models. And between the business logic and network, they design custom controllers, actions, and proxies for bespoke APIs.
Immutable architecture gives us an opportunity to change that. Rather than custom islands of application behavior, we can construct a runtime of application-agnostic components. An immutable runtime will bridge the gaps with generated behaviors. We have already shown how a few of these generic components could work. A generic data store persists facts declared in the Factual Modeling Language and executes generated query pipelines. Those same pipelines are automatically inverted to inform the user interface when a new fact arrives from a network peer. Authorization rules determine which of those incoming facts can be trusted and stored.
With each technical decision that we automate, we connect islands of the system that were once developed separately. Only a couple of gaps remain to be bridged. For one, we need to project the results of a query onto the user interface. And for another, a server must determine which facts to share with a peer. These two gaps can be closed with two final concepts: projections and interest. Once we close these gaps, we will transition from a purely human-driven development paradigm to one that supports higher-level reasoning. We will gain not only productivity and confidence but also a new degree of communication and collaboration.
Projections
Queries in the Factual Modeling Language produce sets of facts. While these result sets are useful for a developer, they are not approachable in their raw form to a user. An immutable runtime needs to transform raw facts into objects that the user can more easily consume. To bridge the gap between query results and user interface, we define a projection.
A projection is a function that maps a group of fact sets into an object structure. The front-end framework can take it from there to produce the user interface. A functional framework such as React would express UI components as a function of the object structure. A data-binding framework such as XAML would use the object structure as a view model. In either case, the framework starts with a projection of the facts, not the facts themselves.
Projections raise the level of granularity. They aggregate several small disparate facts into a cohesive representation. A single query produces a set of facts, all of the same type. These might be all entities that should appear on a list or all possible values of a single property. The user interface, however, will need to combine several result sets. To produce a list, it will need not only the set of entities but also the candidate values of several of their properties.
Defining Projections
The application could perform the second query for each result returned from the first. Doing so would take longer than necessary. This kind of performance problem is commonly known as SELECT N+1. The application executes 1 query to find the entities and then makes N queries to find some property of each of those N entities.
The exact expression is going to differ for each programming language. For example, in Jinaga—an immutable runtime for JavaScript—a projection looks like a JavaScript object literal where the fields are defined using functions. The important part about this pseudocode is that it declares an object structure based on a handful of queries. If this expression were evaluated imperatively, we would have a SELECT N+1 problem. But since this projection is expressed declaratively, we have the opportunity to produce a single combined pipeline.
Projection Pipelines
Like a query, every projection has a starting point. The starting point of the preceding projection is a Restaurant. The projection then defines a set of fields (in this example, just the tables field). Some of these fields are simply functions of the starting point. And some of them, like the one shown earlier, are based on queries.

The projection begins with the pipeline to find tables currently available in a restaurant
If we had more than one field, then we would graft each of the pipelines together at the same starting point. If two fields produced pipelines that followed the same first step, then their pipelines would be grafted after that common step. The pipelines share steps until the point that they diverge. An example of a combined pipeline appears in Figure 12-3. In this case, however, we just have the one pipeline, so we continue to the next phase.
In the next phase, the runtime walks recursively down to fields defined on projected entities. In this example, the table entity has three fields: tableNumber, capacity, and server. For two of these fields, the expression simply pulls a value from the fact. For the third, however, it specifies a child query.
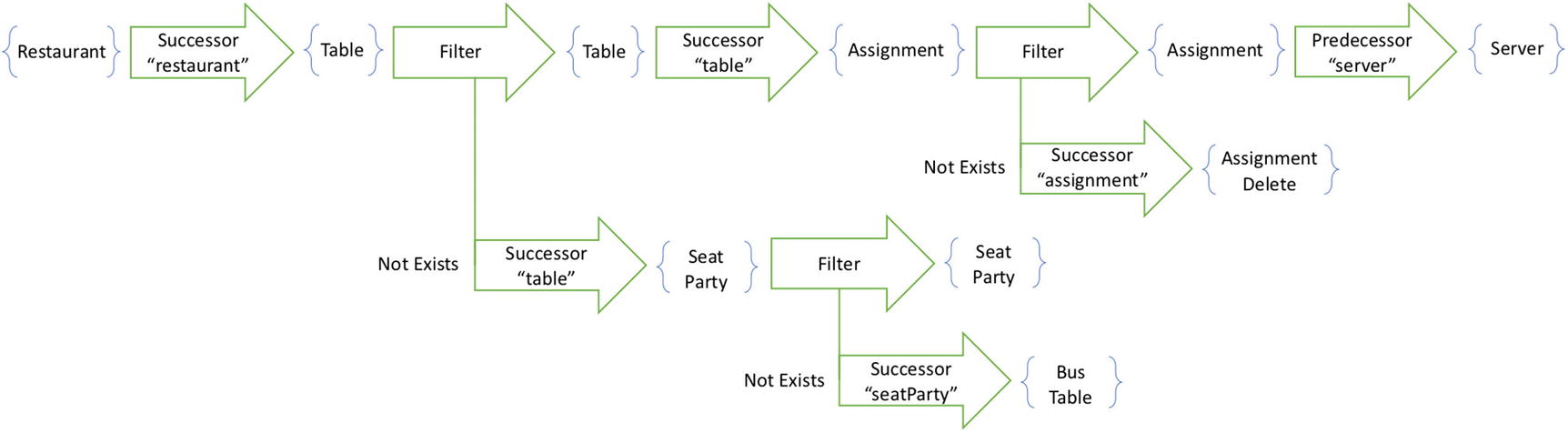
Join the server pipeline to the table pipeline to find all servers at once
Projection pipelines can get large and complex. If it were the responsibility of a human developer to maintain these pipelines and write the corresponding database queries, they could easily make a mistake. But this is a process that can be automated. Starting from the declarative projection, a framework grafts several pipelines into a single composite structure. It computes the inverse of this structure to understand exactly what component state or view model to update when a new fact arrives. It transforms this combined pipeline into a database query to be executed more efficiently against the data store. This avoids the SELECT N+1 problem, while producing an object model that readily supports the user interface.
Interest
The final gap to close is the one between the business logic and the network. In Chapter 11, we manually decided how to share facts with peers. We found pivots within the model—predecessor/successor relationships that crossed regions. These became points of collaboration not only between users but also between nodes. Then we decided how to express that collaboration: queues, topics, REST APIs, webhooks, and others. Now we will examine a way to automate that decision and take it out of the hands of the human software developer. We replace it with an algorithm for automatically determining what facts a node needs to know about. Peers using immutable runtimes will exchange information with peers to express interest in the facts that they want.
A node is interested in a fact if the existence of that fact changes the behavior of the node. The behavior of a node depends upon its projection pipelines and their starting points. If a fact influences the results of a projection from an expected starting point, then the node that presents that projection from that starting point is interested in that fact.
To express interest, a node shares its projection pipelines and starting points with its peers. They determine which facts to share based on that information. So which facts could influence the behavior of a pipeline? Certainly the starting point has a great influence. But of course, the target node already knows about that fact. There is no need to send it a fact that it already knows. Instead, the peer examines the projection pipeline to find other facts that could influence it.
Every step that the pipeline takes visits a new set of facts. If the step finds successors in a certain role of a certain type, then every one of those successors could influence the behavior of the pipeline. The node that uses that projection is interested in all of those successors.
To understand a fact, a node must also know about all of its predecessors. When a node expresses interest in a fact, it implicitly expresses interest in those predecessors. Those facts, of course, have predecessors of their own. The runtime computes the transitive closure of the interest set to find all of the required facts. A predecessor step within the projection pipeline adds no facts to the interest set that would not already be present.
When a pipeline includes a filter, that filter introduces a child pipeline. Any fact that influences the child pipeline influences the behavior of the filter. And so the runtime evaluates the child pipeline recursively. Beyond the filter, the pipeline continues. But only facts that pass the filter can influence the remainder of the pipeline. And so only facts that make it past the filter can further contribute to the interest set. This leads to some interesting and counterintuitive consequences. These are most obvious with respect to two common patterns, both described in Chapter 8: Delete and Period.
Interest in Deleted Entities
The Delete pattern uses a fact to indicate that an entity has been deleted. When a node learns about that fact, it loses interest in all information about the entity—all information, that is, except for the fact that it has been deleted. That has to be preserved.
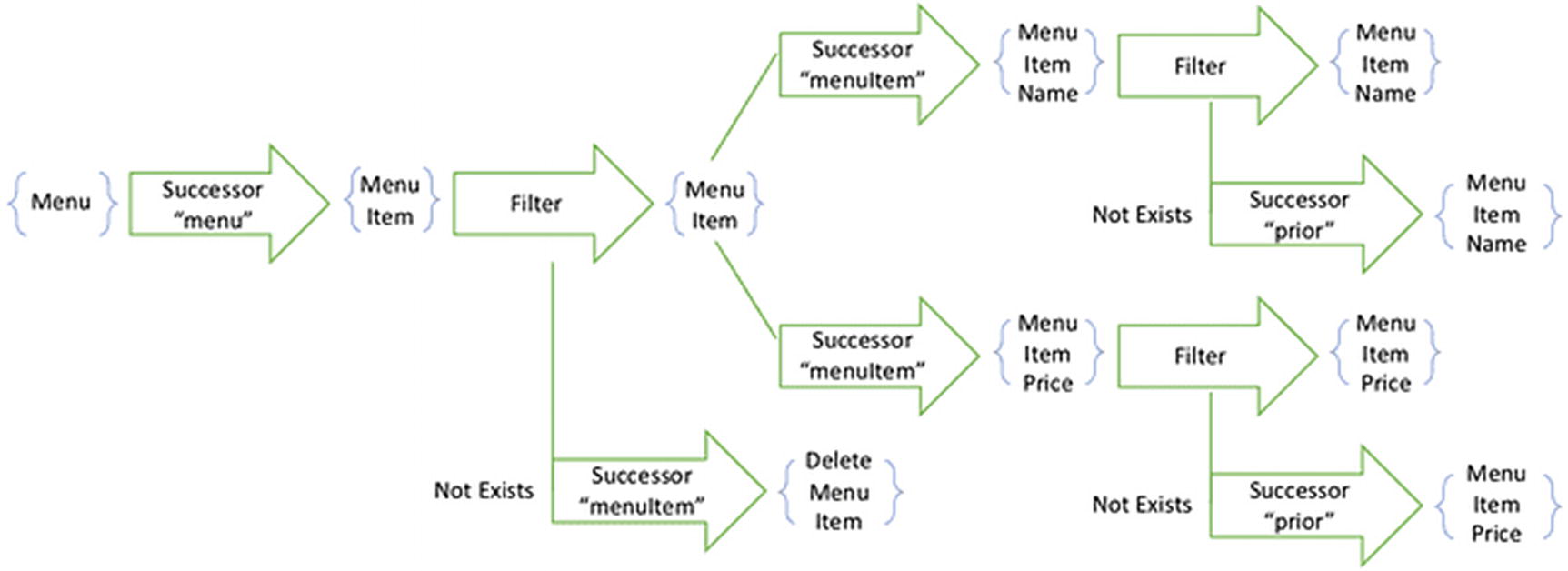
A projection pipeline that gets the names and prices of all items on a menu
In order to execute that filter, the node needs to know about the menu items and their deletions. It remains permanently interested in those facts. After the filter are the steps that explore the properties of the menu item. Those steps will never see a deleted menu item. And so, even though a node is interested in the entity and its deletion, it is not interested in the properties of deleted entities.
This is a subtle and important optimization of the interest set. You might think that a node will not be interested in the deleted entities at all. Once an entity is excluded by the deletion filter, then it no longer appears on the user interface. If it does not appear, then why would a node be interested in it?
The reason for the continued interest becomes clearer as you consider how interest propagates through a network of nodes. Suppose a new node comes online and does not learn about deleted menu items. Then suppose that it communicates with a peer that has not yet learned that a particular menu item has been deleted. The peer will helpfully tell the new node about the menu item, its names, and its prices. The new node will believe that this menu item exists and display it to its user. And so a node that does not retain interest in deletion facts will incorrectly display deleted entities.
You may have observed this behavior in some popular synchronization engines. For example, if you use Microsoft Active Directory, it is possible to observe lingering objects if a domain controller is disconnected beyond the tombstone lifetime.1 A tombstone in Active Directory is a record of an entity’s deletion. It is analogous to a Delete fact . Active Directory does not preserve tombstones indefinitely. Instead, it defines a lifetime of between 60 and 180 days, depending upon the operating system. If a node is disconnected for longer than that lifetime, or if the clocks have drifted significantly, then its peers may discard the tombstone. That causes the deleted entity to magically reappear.
The only truly fool-proof way of defending a node against deleted entities is for it to continue to be interested in the entity facts and their deletion facts. A node needs to learn about the tombstones no matter how old they are. This seems like a large set of data to retain, but in fact it prevents an even larger set of data from lingering. Sharing this complete list of tombstones prevents a node from becoming interested in all of the property changes and other actions associated with these entities.
Retaining interest in deleted entities has traditionally been one of the more controversial results of immutable architectures. I have had countless conversations with peers who attempt to solve the problem with rules about when a system can forget about entities. The results are always similar to the lingering-object issue that Active Directory faces. If you remain unconvinced, then perhaps the interaction between interest and the Period pattern will provide a more palatable solution. Periods are a way of imposing lifetimes on interest without falling into lingering-object defects.
Interest in Past Periods
The Period pattern describes regularly occurring spans of time during which activities take place. The duration of a period is a time frame that makes sense for the application: a date of business, a calendar month, an academic semester, or a fiscal year. When an activity occurs at a particular node, that node believes the system to be in one single period. It records the activity as a successor of the period fact.
Each node determines its own interest set. Different nodes will express interest in different periods. Nodes closer to the edge of the network tend to operate only within recent periods. A point of sale terminal might only display data within the current date of business. It serves the needs of its users in the short term and leaves long-term history to reporting servers living closer to the center of the network.
To respect the bandwidth and storage limitations of smaller edge devices, we wish to limit their interest set to only the more recent periods. Nodes get to choose the starting points of their projection pipelines. If those pipelines start with the current period, then the node is no longer interested in the past.
The period clock advances for each individual edge node. Close to a time boundary, different nodes might believe the system to be in different periods. But this will not cause any problems sharing facts with more central nodes. Edge node clocks don’t need to agree so long as central nodes accept facts outside of what they believe to be the current period.
To apply this solution, a node starts its projections not from a top-level owner, but from a period defined within that owner. For example, the front-of-house terminal within a restaurant that the host uses would begin not from the Restaurant fact , but from a successor RestaurantDateOfBusiness . As its clock progresses, the front-of-house terminal loses interest in the previous date of business for the restaurant. Instead, it starts its projection pipelines from the new date of business. It communicates out to its peers the starting point of the pipeline as the date changes.
This strategy allows edge nodes to limit their storage requirements, while central nodes take on the storage burden. Different nodes get to decide their own interest set. Edge nodes express interest in recent periods by providing a pipeline that starts with a period. Central nodes express interest in deep history by starting from the periods’ predecessor.
Sharing Interest
Each node is responsible for defining its own interest set. It does so by defining its own projection pipelines and starting points. For the node to receive the facts that it expresses interest in, it must share those projection pipelines and starting points with its peers.
An application-agnostic immutable architecture will include a network protocol for exchanging pipelines and starting points. Rather than requiring human developers to design a bespoke API for the application at hand, it will adapt its behavior as the application is developed. The behavior of network interaction is generated based on pipelines, starting points, and authorization and distribution rules.
A node expresses interest over an application-agnostic network protocol by providing its projection pipelines and starting points. The peer then executes the pipeline to find facts that the node is interested in. Based on the permanence of the relationship with the node, it may decide to cache those facts and invert the pipeline in order to invalidate the cache. Or it may decide that the node is ephemeral, like a mobile device, and rely upon it to maintain bookmarks as described in Chapter 11.
The starting points for projection pipelines depend upon the purpose that the node serves. Personal devices such as mobile devices tend to start with the User fact of the individual who owns the device. All other projections are reachable via navigation from the results of the first. The node grafts all of those pipelines together in order to produce one single structure originating from the User fact. All groups to which that user gains membership, all entities that that user creates, and all decisions made by or for that user are all reachable from this one all-encompassing projection pipeline.
Nodes more central to the network tend to be shared by many users. These belong to organizations. The organization will be represented by a fact within a multi-tenant model. The projections that these kinds of nodes tend to run will produce organization-wide reports, websites, and publicly facing APIs. Their projection pipelines will start from the organization fact.
Starting points will change slowly as shared nodes are reconfigured for different tenants, new users log in to personal devices, or the period clock advances. Projection pipelines will also change slowly, as new versions of software are installed on each device. An application-agnostic protocol allows each node to exchange information about these slow changes to update their peers about the sets of facts in which they are interested.
Losing Interest
As time passes, nodes will lose interest in facts. When an entity is deleted, nodes will no longer be interested in their properties and relationships with other entities. As the clock advances, nodes lose interest in the day-to-day decisions that occurred within a period. Even though facts are immutable and cannot conceptually be deleted, it sometimes makes sense for a node to practically delete data.
Nodes at the edge of a network tend to be personal devices. These are relatively small machines with limited storage, bandwidth, and connections. To respect their limits, it is practical to avoid storing and transmitting facts that they have lost interest in.
Through query inversion, a node can recognize when a new fact has removed other facts from its interest set. It can tell, for example, that a Delete fact has caused the filter of a pipeline to become false and therefore remove all of the properties of that entity from its interest set. An application-agnostic runtime could remove such facts from storage. Before this strategy is applied, however, a couple of caveats must be observed.
First, before the facts are removed, the edge node must have shared those facts with more permanent peers. If the user of a personal device has modified the property of an entity just as another user has deleted it, then the device might learn about the deletion before it has a chance to upload the property change. If the property change—which the device is no longer interested in—is deleted from storage, then no other node will ever learn of it. When the deleted entity is restored, or a historical report is run, the user’s decision will be lost.
The second caveat is that no other node can depend upon this device as a source of facts. Edge devices tend to connect to more central devices to receive new facts. The only facts that they upload are the ones that the user of the device created themselves. But if the personal device is also a server of an even more removed edge device, then its data store cannot be purged. A laptop to which a companion device is attached must retain the history of facts that its satellite might need, even if it itself has lost interest in them.
If query inversion proves to be too complex or cumbersome for an application-agnostic runtime, a simpler strategy exists. The runtime could periodically swap one data store into the background and start filling up a new store. Projections are served out of both data stores, the background one providing stability of past data and the foreground one contributing freshness of new events. Over time, all of the facts that the node is interested in are copied to the foreground store, and all of the outgoing facts are drained from the background queue. A that point of quiescence, the background store can be purged with no loss of information or change of behavior.
Whatever the strategy , it is important to recognize the difference between the practicality of purging facts and the inductive rigor of retaining interest. A node must retain interest in deleted entities and their tombstones in order to correctly defend against lingering objects. As long as a node is interested in a fact, that fact cannot be purged. Only under the strictest of conditions can facts be removed from storage. This can only happen on edge nodes, only after durably sharing that fact with a more central node, and only when interest is truly lost.
Immutable Runtimes
With the introduction of projections and interest, the last of the gaps have been bridged. We can now generate the connections among business logic, user interface, and network communications. Generating behavior is not just about making things easier. With end-to-end behavior generation, we can ensure correctness of applications to a degree that would not otherwise be possible. This gives developers the freedom to explore different solution spaces without being locked into the first one that works. And it gives organizations the autonomy to innovate their business processes even while integrating with other organizations.
There are several ways to generate behavior. Generating behavior might mean generating code. Some code generators are used as templates or scaffolds. Once the code is generated, the developers own it. They are responsible for modifying and maintaining it. Other code generators are run as part of the build process. They produce files that are not intended for the developers to modify. They transpile one language to another so that a domain-specific language can be easily consumed by a general-purpose language.
Generating behavior might also mean altering behavior at runtime to match a specification. Managed runtimes alter their behavior in response to the programs that they execute. Garbage collection, reflection, and serialization are generated behaviors that emerge during runtime. No code generator or transpiler produces a program that performs these operations. The runtime provides these services as they are needed.
Let’s imagine an application development solution that uses all of these techniques to generate the behavior of a distributed system. It will make low-level implementation decisions on behalf of the developer to bridge the gaps among storage, business logic, user interface, security, and network communications. It will also bridge the gaps between applications running on different nodes, even those deployed at different times and authored by different organizations. For some aspects of behavior generation, it will rely upon code generation, allowing developers to write directly in the Factual Modeling Language and producing code in their preferred general-purpose language. For other aspects, it will use managed runtimes, permitting behavior to change without compiling or deploying new code. The goal is not rapid application development. It is correctness and autonomy.
Model Generation
Our aspirational application development process begins with a description of the problem domain. We will describe the entities, properties, activities, relationships, and decisions inherent within that domain. All of those concepts are modeled as historical facts. The tool we will use in that description is of course the Factual Modeling Language.
The first thing that the application runtime needs to do is translate fact declarations into data types in a general-purpose language. This is best accomplished with a code generator running continuously during the build process. The output of this code generator is native code so that it can be understood within the integrated development environment (IDE) and type checker. But it is not intended for developers to modify after generation.
The defining characteristic of facts is that they are immutable. A few general-purpose programming languages support immutable data structures, but most default to mutability. The code generator should use appropriate language idioms to discourage modification of the objects representing facts. In languages that have strong protection semantics like Java and C#, this is almost entirely possible. But languages like JavaScript with weak or no protection, it is simply up to the developer not to mutate these generated data structures.
The generated code needs to preserve the structure of the facts. It should be able to compute the canonical hash of a fact from the properties of an object. It should help in determining when a fact already exists and when it is being created for the first time. It needs to understand the predecessor/successor relationships so that developers can express queries. Some of these behaviors can be written into the code, some can be extracted via reflection, and others require that the generated code preserve structural details at runtime.
Query Execution
After the developer has specified just a few layers of the data model, they can begin writing queries. In the application development cycle, queries provide the first chance for a developer to test their hypotheses. They have expressed the structure of the entities and decisions in terms of facts with the belief that these facts will support the requirements of the finished software. If they can write a query that satisfies a requirement, then they have more confidence that the model is correct.
It is vital that a developer have a way to iterate on a model and set of queries quickly, especially during the early phases of application development. A complete immutable runtime should include a playground in which developers can define facts, create instances, and then run queries. Think of this as the equivalent of a SQL design tool like MySQL Workbench, pgAdmin, or Microsoft SQL Server Management Studio (SSMS) . It is an exploratory and diagnostic tool for the developer, not for the application.
For an application to execute a query requires an application runtime. The runtime framework translates a query expressed in Factual or in the native language into a pipeline. From there, the pipeline can be executed against any number of data stores, grafted into projection pipelines, or inverted. The pipeline is just a data structure internal to the immutable runtime that can be manipulated for several purposes.
In some incarnations of our aspirational application development system, a code generator turns Factual queries into a pipeline description stored within the code. It generates the function that is the entry point for executing this pipeline, providing the necessary type casts to ensure that the function takes the appropriate starting point and produces the appropriate fact set. In other incarnations, the runtime is able to convert a native language query—such as .NET Linq—into a pipeline. It is careful to validate that the query does not stray outside of the set of capabilities of the deliberately limited Factual query.
Testing
As the application developer iterates over the model and queries, they will want to encode their expectations in repeatable tests. Automated testing has long been a cornerstone of agile application development, even becoming the driving force of application design in test-driven development (TDD). In the application development cycle envisioned here, testing plays a diminished role. Tests do not drive the design or even prove correctness. They simply check our work.
When humans are responsible for designing the ins and outs of software systems, they will inevitably make mistakes. These mistakes lead to defective behavior. We call them “bugs” and pretend that they are inevitable. But as we’ve seen several times throughout this book, it is possible to prove theorems about the behavior of software. If humans write the data access layer, business logic services, and view models for the user interface, then it is possible for them to introduce bugs. But if an immutable runtime is computing query inverses according to mathematically proven rules, then we can have confidence that the UI will be updated correctly when state changes. There is little value in testing the generated behavior of the runtime. Tests should focus on validating the intent of the program, not just the implementation.
The developer writes tests in their preferred general-purpose language using the generated code and immutable runtime. The tests execute against an application-agnostic data store that operates completely in memory. This will almost certainly be different from the persistent data store used in production. But the developer is not testing that different data stores correctly execute queries. They are testing that they have written the queries that match their intent.
User Interaction
After the developer has iterated a few times over the model, queries, and tests, they reach a point where they have confidence that the system described meets the intended requirements. At this point, they can begin mapping that description to the user interface. The UI has evolved in parallel, as a series of wireframes. Now, it becomes augmented with Factual queries and mathematical formulas. When we have both a description of the intended UI and a declaration of a model and queries, we can finally start bringing the two together.
The developer declares a projection in their general-purpose language. Projections incorporate queries, which the code generator has converted into functions. The projection mixes these functions with the aggregation and calculation tools that the language itself provides. In Linq, for example, the generated function might return an IQueryable . This represents the query itself, not its results. The language features already built into Linq can compose IQueryable streams, map them through lambdas and other native features, and construct a complex object perfectly suited to support the user interface.
Based on the target UI platform, the immutable runtime provides additional support. In an Extensible Application Markup Language (XAML) application, the runtime implements the INotifyPropertyChanged event in order to translate from query inversion to data binding. In a React application, the runtime stores the projected data in component state and provides hooks for efficient access. No matter what front-end technology is chosen, the developer works at the level of declarative projection based on queries over immutable facts.
Finally, the developer responds to input events. When a user clicks a button or modifies a field, the developer translates this action into a new fact. The runtime takes all of the necessary actions to bridge the gaps between the user interface and other parts of the system. It stores the fact using the application-agnostic data store. It queues the fact to be shared with more central nodes. It determines interest to push it out to peers. And it runs query inverses to determine which other parts of the user interface have been affected. The human developer is no longer on the hook for any of these technical decisions.
User interaction might not take the form of a UI that appears on a web page or mobile device. It might be an API consumed by non-immutable systems. These techniques still apply, just with some technical modifications. URLs map to starting points. Projections map query results onto data structures. Those data structures are then translated into JSON, XML, or some other transport format. And operations such as POST and PUT map to creation of new facts that represent creation and updates of entities. The biggest difference is that APIs tend to rely less upon real-time updates than user interfaces do. And so inverses play a lesser role, that of invalidating caches rather than pushing updates.
Developers may choose to implement another layer of tests at this stage. They have tested the queries and the model that went into the projections. Now they have an opportunity to test the projections themselves. They can express the intent that when a user presses a certain button, data should appear in a certain list. That intent can be tested against the projection—the view model or component state—rather than against the user interface itself. This gives developers a tool for validating interaction scenarios without taking a dependency upon more malleable user interface components. And these tests can still be run using an in-memory data store with no loss of confidence .
Collaboration
The final phase of the aspirational application development cycle is to define the collaboration between users, between systems, and between nodes. The behaviors taken by one actor will have an impact on the behaviors observed by another actor. We express these points of collaboration in an immutable application using interest.
The application developer registers all of their projection pipelines with the runtime. This represents the intent that the application expresses interest in every fact necessary to update its interface. Developers might take this opportunity to optimize projections to produce better interest calculations or provide additional projections that support other features of the application. But the default position of registering the set of projections used in the UI should produce reasonable results.
Next, application developers trigger interest from certain starting points. For example, when the user logs in, they will inform the runtime that the set of projections starting from that user have become active. This will trigger the runtime to start pulling related facts so that the projections will be updated as they arrive. If an application includes navigation from one view to the next, the developer has some choices to make. They can graft subsequent screens’ projections onto the end of the primary screen’s projection, thus ensuring that the facts are already available before the user navigates. Or, they can wait until that navigation occurs, minimizing the bandwidth consumed until the user decides what to view. Either of these choices is easily expressed with a few function calls to the immutable runtime.
The runtime for its part shares these projection pipelines with its peers. As the application requests that pipelines be run for a given starting point, the runtime sends out that serialized starting point and the composed interest pipelines. Peers execute the pipelines to determine the facts in the interest set. They also run the transitive closure to find all predecessors of those facts. Finally, they use bookmarks to negotiate which facts the peer already knows about and which need to be shared. As they share facts, the peers update their bookmarks. All of this is accomplished with no additional guidance from the developer.
This is the most natural time for developers to introduce authorization and distribution rules. Immutable runtimes execute authorization rules upon receipt of a new fact to determine for themselves whether to trust and store it. The runtime executes distribution rules as it sends facts to filter out data that a peer does not have permission to see, even if it has expressed interest. These rules could have been expressed earlier in the cycle, but collaboration gives developers the perfect opportunity to validate them.
The few decisions that the developer did make—how to combine projections, when to navigate to new starting points, and authorization and distribution rules—deserve a new layer of tests. The developer writes a set of tests that show that when one user takes an action on one device, another user sees a certain effect on another. They demonstrate that protected data is not visible to a peer and that unauthorized activities will be rejected. These tests are written against projections, as those are the expressions that map most closely to the user’s actual experience. But they incorporate the behavior of the code that registers interest pipelines, starting points, and security rules. During the test, the runtime uses not only an in-memory data store but also an in-process communication simulator. It does not need to set up interconnected nodes or use unreliable infrastructure during the test. This simulator will not be used in the production application, but it enables testing of the important decisions that the developer makes during this phase. The correct behavior of the real communication system is governed by the mathematics of conflict-free replicated data types (CRDTs) and covered by the runtime vendor with its own suite of tests.
Developers iterate over these phases, building onto the model, writing new queries, constructing new projections, and enabling more complex collaborations. Through the entire process, the decisions that they make for the current phase are consistent with the ones that they made in the past. The tools enforce that consistency through code generation and type checking. Developers build up a working application over several iterations. At no point can the developer express one intent to the data access layer and a different intent to the networking subsystem. They cannot introduce bugs based on disagreement between islands of behavior. All behavior is generated—whether by transpiled code or interpretive runtime—from the expression of intent. This gives developers the confidence to explore new business solutions, and the autonomy to try new ideas .
Immutable Organizations
As immutable architectures gain acceptance, they will begin as experiments within individual organizations. Application developers will try out the concepts, patterns, and techniques described in this book. They will adopt frameworks that provide immutable runtimes, such as the Correspondence and Jinaga open source projects that the author maintains. As they find success, immutability will find its way into other business units within the organization.
The spread will be gradual. As business units need to integrate with one another, they will be faced with the choice. Do we adopt an immutable collaboration between these services, or do we use a more traditional Simple Object Access Protocol (SOAP), Representational State Transfer (REST), or Enterprise Service Bus (ESB) style interaction? Business units who are slow to adopt immutability will find that they need to implement additional adapter layers and will not get the benefits of eventual consistency and conflict resolution. But those that buy into a new style of application development will soon discover its advantages in rapid and reliable exploration and experimentation.
Decision Substrate
Business units—not departments—will be the driving force of immutability adoption. A business unit includes all functions necessary for the generation of value within one step of the value stream. In order to operate effectively, the unit needs to innovate quickly to respond to changing demands. If they can capitalize on shifts in environmental forces, they can demonstrate value to the whole organization. If they cannot, then their functions may be outsourced. With these pressures at play, business units have found themselves in the past moving to cloud platforms while the organization’s IT department stayed behind with on-premises networks. These same pressures will drive them to adopt more exploratory and autonomous architectures.
Eventually, the backbone of the organization will be a shared distributed immutable data exchange. Business units will independently develop solutions on top of this substrate. Some will be valuable, and others will die away. But those that stick will become the source of reliable business data for other experiments. The immutable data structure that emerges will be the decision infrastructure upon which the organization builds its value stream.
Certainly in the short term, and very likely in the long term as well, immutable applications will run side by side with static applications. These will require integration points. Using the Outbox pattern, webhooks, and emulated mutability, developers of immutable applications will find ways to bridge those gaps. Over time, they will publish those integrations as reusable components for other immutable application developers. The integration points will become small immutable applications living on their own within the architecture, proxies for external services.
Organizations that evolve an immutable decision substrate will find themselves at an advantage over their static counterparts. They will have a reliable log of all business decisions that went into generating value within the company. They will exchange information securely and freely across business unit boundaries. And they will have the freedom to innovate on new solutions without the overhead of large enterprise hegemonies.
Globally Distributed Systems
As powerful as immutable architecture can be within a single application or a single organization, the benefits multiply as immutable organizations integrate with one another. As they discover each other, they will pierce the veil of emulated mutation and expose the immutable facts beneath. They will provide access to their data synchronization protocols so that the two organizations can intermingle their immutable models.
As immutability spreads organization to organization, security boundaries will remain firmly in place. The authorization and distribution rules will continue to control access to sensitive facts. Asymmetric keys will continue to identify individual actors, and their digital signatures and shared keys will continue to protect data at rest and through untrusted nodes. Security concerns will be enforced at the logical boundaries between regions, not just at physical network boundaries and with proprietary APIs.
Organizations will limit coupling between their models by keeping integration points high up in the causal chain. They will agree upon predecessors, and each create their own successor facts. They will evolve these models using structural versioning so that different partners can take their integrations in their own directions without central coordination.
As pairs of immutable organizations join into clusters, they will form networks of interconnected models shared among all participants. They will build upon common application-agnostic network and security protocols, and each maintain their own data stores. From these clusters will emerge a shared global distributed system, exchanging immutable records in a securely integrated history.
In years past , this kind of emergent global network would have seemed ridiculous. But we have already seen two successful examples. The Internet is not a centralized managed set of servers. It is a system of open standards, implemented by a myriad of vendors and operated by a loose consortium of cooperating organizations. And blockchains are not central databases that rely upon physical and network security to control access. They are shared public ledgers of immutable records executing on diverse nodes running competing implementations of an open standard.
Based on these examples, I have confidence that the global immutable network will emerge. It will not have the mutable mindset of REST APIs that bind them to location specificity. Nor will it have the inefficiencies of proof of work locking it into a linear history. Instead, it will apply the findings of decades of mathematical research to produce truly globally distributed systems that are location independent, convergent, secure, and autonomous .