
Arrays and Strings
This chapter covers a wide range of problems involving strings and arrays. Since Java strings and arrays are common topics for developers, I will briefly introduce them via several headlines that you must remember. However, if you need to deep dive into this topic, then consider the official Java documentation (https://docs.oracle.com/javase/tutorial/java/).
By the end of this chapter, you should be able to tackle any problem involving Java strings and/or arrays. It is highly likely that they will show up in a technical interview. So, the topics that will be covered in this chapter are pretty short and clear:
- Arrays and strings in a nutshell
- Coding challenges
Let's start with a quick recap of strings and arrays.
Technical requirements
All the code present in this chapter can be found on GitHub at https://github.com/PacktPublishing/The-Complete-Coding-Interview-Guide-in-Java/tree/master/Chapter10.
Arrays and strings in a nutshell
In Java, arrays are objects and are dynamically created. Arrays can be assigned to variables of the Object type. They can have a single dimension (for example, m[]) or multiple dimensions (for example, as a three-dimensional array, m[][][]). The elements of an array are stored starting with index 0, so an array of length n stores its elements between indexes 0 and n-1 (inclusive). Once an array object is created, its length never changes. Arrays cannot be immutable except for the useless array of length 0 (for example, String[] immutable = new String[0]).
In Java, strings are immutable (String is immutable). A string can contain ASCII characters (unprintable control codes between 0-31, printable characters between 32-127, and extended ASCII codes between 128-255) and Unicode characters. Unicode characters less than 65,535 (0xFFFF) are represented in Java using the 16-bit char data type (for example, calling charAt(int index) works as expected – index is the index varying from 0 to string length - 1). Unicode characters that exceed 65,535 until 1,114,111 (0x10FFFF) don't fit into 16 bits (Java char). They are stored as 32-bit integer values (known as code points). This aspect is detailed in the Coding challenge 7 – Extracting code points of surrogate pairs section.
A very useful class for manipulating strings is StringBuilder (and the thread-safe StringBuffer).
Now, let's look at some coding challenges.
Coding challenges
In the following 29 coding challenges, we'll tackle a set of popular problems encountered in Java technical interviews done by medium to large companies (including Google, Amazon, Flipkart, Adobe, and Microsoft). Besides these 29 coding challenges (discussed in this book), you may like to check out the following non-exhaustive list of strings and arrays coding challenges that you can find in my other book, Java Coding Problems (https://www.amazon.com/gp/product/1789801419/), published by Packt as well:
- Counting duplicate characters
- Finding the first non-repeated character
- Reversing letters and words
- Checking whether a string contains only digits
- Counting vowels and consonants
- Counting the occurrences of a certain character
- Removing white spaces from a string
- Joining multiple strings with a delimiter
- Checking whether a string is a palindrome
- Removing duplicate characters
- Removing a given character
- Finding the character with the most appearances
- Sorting an array of strings by length
- Checking that a string contains a substring
- Counting substring occurrences in a string
- Checking whether two strings are anagrams
- Declaring multiline strings (text blocks)
- Concatenating the same string n times
- Removing leading and trailing spaces
- Finding the longest common prefix
- Applying indentation
- Transforming strings
- Sorting an array
- Finding an element in an array
- Checking whether two arrays are equal or mismatched
- Comparing two arrays lexicographically
- Minimum, maximum, and average of an array
- Reversing an array
- Filling and setting an array
- Next greater element
- Changing array size
The 29 coding challenges tackled in this chapter are not covered in the preceding challenges and vice versa.
Coding challenge 1 – Unique characters (1)
Google, Adobe, Microsoft
Problem: Consider a string that can contain ASCII and Unicode characters ranging between 0-65,535. Write a snippet of code that returns true if this string contains unique characters. The whitespaces can be ignored.
Solution: Let's consider the following three valid given strings:

Figure 10.1 – Strings
First of all, it is important to know that we can fetch any character between 0 and 65,535 via the charAt(int index) method (index is the index varying from 0 to string length – 1) because these characters are represented in Java using the 16-bit char data type.
A simple solution to this problem consists of using a Map<Character, Boolean>. While we loop the characters of the given string via the charAt(int index) method, we try to put the character from index into this map and flip the corresponding boolean value from false to true. The Map#put(K k, V v) method returns null if there was no mapping for the given key (character). If there is a mapping for the given key (character), then Map#put(K k, V v) returns the previous value (in our case, true) associated with this key. So, when the returned value is not null, we can conclude that at least one character is duplicated, so we can say that the given string doesn't contain unique characters.
Moreover, before trying to put a character in the map, we ensure that its code ranges between 0 and 65,535 via String#codePointAt(index i). This method returns the Unicode character at the specified index as an int, which is known as the code point. Let's see the code:
private static final int MAX_CODE = 65535;
...
public static boolean isUnique(String str) {
Map<Character, Boolean> chars = new HashMap<>();
// or use, for(char ch : str.toCharArray()) { ... }
for (int i = 0; i < str.length(); i++) {
if (str.codePointAt(i) <= MAX_CODE) {
char ch = str.charAt(i);
if (!Character.isWhitespace(ch)) {
if (chars.put(ch, true) != null) {
return false;
}
}
} else {
System.out.println("The given string
contains unallowed characters");
return false;
}
}
return true;
}
The complete application is called UniqueCharacters.
Coding challenge 2 – Unique characters (2)
Google, Adobe, Microsoft
Problem: Consider a string that can contain only characters from a-z. Write a snippet of code that returns true if this string contains unique characters. The whitespaces can be ignored.
Solution: The solution presented in the preceding coding challenge covers this case as well. However, let's try to come up with a solution specific to this case. The given string can contain only characters from a-z, so it can only contain ASCII codes from 97(a) to 122(z). Let's consider that the given string is afghnqrsuz.
If we recall our experience from Chapter 9, Bit Manipulation, then we can think of a bit mask that covers a-z letters with bits of 1, as shown in the following figure (the bits of 1 correspond to the letters of our string, afghnqrsuz):

Figure 10.2 – Unique characters bit mask
If we represent each letter from a-z as a bit of 1, then we obtain a bit mask of the unique characters, similar to the one shown in the preceding image. Initially, this bit mask contains only 0s (since no letter has been processed, we have all bits equal to 0 or they're unset).
Next, we peek at the first letter from the given string and we compute the subtraction between its ASCII code and 97 (the ASCII code of a). Let's denote this with s. Now, we create another bit mask by left shifting 1 by s positions. This will result in a bit mask that has the MSB of 1 followed by s bits of 0 (1000...). Next, we can apply the AND[&] operator between the bit mask of unique characters (which is initially 0000...) and this bit mask (1000...). The result will be 0000... since 0 & 1 = 0. This is the expected result since this is the first processed letter, so there are no letters being flipped in the bit mask of unique characters.
Next, we update the unique character's bit mask by flipping the bit from position s from 0 to 1. This is done via the OR[|] operator. Now, the bit mask of unique characters is 1000.... There is a single bit of 1 since we flipped a single bit; that is, the one corresponding to the first letter.
Finally, we repeat this process for each letter of the given string. If you encounter a duplicate, then the AND[&] operation between the bit mask of unique characters and the 1000... mask corresponding to the currently processed letter will return 1 (1 & 1 = 1). If this happens, then we have found a duplicate, so we can return it.
In terms of code, we have the following:
private static final char A_CHAR = 'a';
...
public static boolean isUnique(String str) {
int marker = 0;
for (int i = 0; i < str.length(); i++) {
int s = str.charAt(i) - A_CHAR;
int mask = 1 << s;
if ((marker & mask) > 0) {
return false;
}
marker = marker | mask;
}
return true;
}
The complete application is called UniqueCharactersAZ.
Coding challenge 3 – Encoding strings
Problem: Consider a string given as a char[], str. Write a snippet of code that replaces all whitespaces with a sequence, %20. The resulting string should be returned as a char[].
Solution: Consider that the given char[] represents the following string:
char[] str = " String with spaces ".toCharArray();
The expected result is %20%20String%20%20%20with%20spaces%20%20.
We can solve this problem in three steps:
- We count the number of whitespaces in the given char[].
- Next, create a new char[] that's the size of the initial char[], str, plus the number of whitespaces multiplied by 2 (a single whitespace occupies one element in the given char[], while the %20 sequences will occupy three elements in the resulting char[]).
- Lastly, we loop the given char[] and create the resulting char[].
In terms of code, we have the following:
public static char[] encodeWhitespaces(char[] str) {
// count whitespaces (step 1)
int countWhitespaces = 0;
for (int i = 0; i < str.length; i++) {
if (Character.isWhitespace(str[i])) {
countWhitespaces++;
}
}
if (countWhitespaces > 0) {
// create the encoded char[] (step 2)
char[] encodedStr = new char[str.length
+ countWhitespaces * 2];
// populate the encoded char[] (step 3)
int index = 0;
for (int i = 0; i < str.length; i++) {
if (Character.isWhitespace(str[i])) {
encodedStr[index] = '0';
encodedStr[index + 1] = '2';
encodedStr[index + 2] = '%';
index = index + 3;
} else {
encodedStr[index] = str[i];
index++;
}
}
return encodedStr;
}
return str;
}
The complete application is called EncodedString.
Coding challenge 4 – One edit away
Google, Microsoft
Problem: Consider two given strings, q and p. Write a snippet of code that determines whether we can obtain two identical strings by performing a single edit in q or p. More precisely, we can insert, remove, or replace a single character in q or in p, and q will become equal to p.
Solution: To better understand the requirements, let's consider several examples:
- tank, tanc One edit: Replace k with c (or vice versa)
- tnk, tank One edit: Insert a in tnk between t and n or remove a from tank
- tank, tinck More than one edit is needed!
- tank, tankist More than one edit is needed!
By inspecting these examples, we can conclude that we are one edit away if the following occurs:
- The difference in length between q and p is not bigger than 1
- q and p are different in a single place
We can easily check the difference in length between q and p as follows:
if (Math.abs(q.length() - p.length()) > 1) {
return false;
}
To find out whether q and p are different in a single place, we have to compare each character from q with each character from p. If we find more than one difference, then we return false; otherwise, we return true. Let's see this in terms of code:
public static boolean isOneEditAway(String q, String p) {
// if the difference between the strings is bigger than 1
// then they are at more than one edit away
if (Math.abs(q.length() - p.length()) > 1) {
return false;
}
// get shorter and longer string
String shorter = q.length() < p.length() ? q : p;
String longer = q.length() < p.length() ? p : q;
int is = 0;
int il = 0;
boolean marker = false;
while (is < shorter.length() && il < longer.length()) {
if (shorter.charAt(is) != longer.charAt(il)) {
// first difference was found
// at the second difference we return false
if (marker) {
return false;
}
marker = true;
if (shorter.length() == longer.length()) {
is++;
}
} else {
is++;
}
il++;
}
return true;
}
The complete application is called OneEditAway.
Coding challenge 5 – Shrinking a string
Problem: Consider a given string containing only letters a-z and whitespaces. This string contains a lot of consecutive repeated characters. Write a snippet of code that shrinks this string by counting the consecutive repeated characters and creating another string that appends each character and the number of consecutive occurrences. The whitespaces should be copied in the resulting string as they are (don't shrink the whitespaces). If the resulting string is not shorter than the given string, then return the given string.
Solution: Consider that the given string is abbb vvvv s rttt rr eeee f. The expected result will be a1b3 v4 s1 r1t3 r2 e4 f1. To count the consecutive characters, we need to loop this string character by character:
- If the current character and the next character are the same, then we increment a counter.
- If the next character is different from the current character, then we append the current character and the counter value to the final result, and we reset the counter to 0.
- In the end, after processing all the characters from the given string, we compare the length of the result with the length of the given string and we return the shortest string.
In terms of code, we have the following:
public static String shrink(String str) {
StringBuilder result = new StringBuilder();
int count = 0;
for (int i = 0; i < str.length(); i++) {
count++;
// we don't count whitespaces, we just copy them
if (!Character.isWhitespace(str.charAt(i))) {
// if there are no more characters
// or the next character is different
// from the counted one
if ((i + 1) >= str.length()
|| str.charAt(i) != str.charAt(i + 1)) {
// append to the final result the counted character
// and number of consecutive occurrences
result.append(str.charAt(i))
.append(count);
// reset the counter since this
// sequence was appended to the result
count = 0;
}
} else {
result.append(str.charAt(i));
count = 0;
}
}
// return the result only if it is
// shorter than the given string
return result.length() > str.length()
? str : result.toString();
}
The complete application is called StringShrinker.
Coding challenge 6 – Extracting integers
Problem: Consider a given string containing whitespaces and a-z and 0-9 characters. Write a snippet of code that extracts integers from this string. You can assume that any sequence of consecutive digits forms a valid integer.
Solution: Consider that the given string is cv dd 4 k 2321 2 11 k4k2 66 4d. The expected result will contain the following integers: 4, 2321, 2, 11, 4, 2, 66, and 4.
A straightforward solution will loop the given string character by character and concatenate sequences of consecutive digits. A digit contains ASCII code between 48 (inclusive) and 97 (inclusive). So, any character whose ASCII code is in the range [48, 97] is a digit. We can also use the Character#isDigit(char ch) method. When a sequence of consecutive digits is interrupted by a non-digit character, we can convert the harvested sequence into an integer and append it as a list of integers. Let's see this in terms of code:
public static List<Integer> extract(String str) {
List<Integer> result = new ArrayList<>();
StringBuilder temp = new StringBuilder(
String.valueOf(Integer.MAX_VALUE).length());
for (int i = 0; i < str.length(); i++) {
char ch = str.charAt(i);
// or, if (((int) ch) >= 48 && ((int) ch) <= 57)
if (Character.isDigit(ch)) {
temp.append(ch);
} else {
if (temp.length() > 0) {
result.add(Integer.parseInt(temp.toString()));
temp.delete(0, temp.length());
}
}
}
return result;
}
The complete application is called ExtractIntegers.
Coding challenge 7 – Extracting the code points of surrogate pairs
Problem: Consider a given string containing any kind of characters, including Unicode characters, that are represented in Java as surrogate pairs. Write a snippet of code that extracts the code points of the surrogate pairs in a list.
Solution: Let's consider that the given string contains the Unicode characters shown in the following image (the first three Unicode characters are represented in Java as surrogate pairs, while the last one is not):

Figure 10.3 – Unicode characters (surrogate pairs)
In Java, we can write such a string as follows:
char[] musicalScore = new char[]{'uD83C', 'uDFBC'};
char[] smileyFace = new char[]{'uD83D', 'uDE0D'};
char[] twoHearts = new char[]{'uD83D', 'uDC95'};
char[] cyrillicZhe = new char[]{'u04DC'};
String str = "is" + String.valueOf(cyrillicZhe) + "zhe"
+ String.valueOf(twoHearts) + "two hearts"
+ String.valueOf(smileyFace) + "smiley face and, "
+ String.valueOf(musicalScore) + "musical score";
To solve this problem, we must know several things, as follows (it is advisable to keep the following statements in mind since they are vital for solving problems that involve Unicode characters):
- Unicode characters that exceed 65,535 until 1,114,111 (0x10FFFF) don't fit into 16 bits, and so 32-bit values (known as code points) were considered for the UTF-32 encoding scheme.
Unfortunately, Java doesn't support UTF-32! Nevertheless, Unicode has come up with a solution for still using 16 bits to represent these characters. This solution implies the following:
- 16-bit high surrogates: 1,024 values (U+D800 to U+DBFF)
- 16-bit low surrogates: 1,024 values (U+DC00 to U+DFFF)
- Now, a high surrogate followed by a low surrogate defines what is known as a surrogate pair. These surrogate pairs are used to represent values between 65,536 (0x10000) and 1,114,111 (0x10FFFF).
- Java takes advantage of this representation and exposes it via a suite of methods, such as codePointAt(), codePoints(), codePointCount(), and offsetByCodePoints() (take a look at the Java documentation for details).
- Calling codePointAt() instead of charAt(), codePoints() instead of chars(), and so on helps us write solutions that cover ASCII and Unicode characters as well.
For example, the well-known two-hearts symbol (first symbol in the preceding image) is a Unicode surrogate pair that can be represented as a char[] containing two values: uD83D and uDC95. The code point of this symbol is 128149. To obtain a String object from this code point, call the following:
String str = String.valueOf(Character.toChars(128149));
Counting the code points in str can be done by calling str.codePointCount(0,str.length()), which returns 1, even if the str length is 2. Calling str.codePointAt(0) returns 128149, while calling str.codePointAt(1) returns 56469. Calling Character.toChars(128149).length returns 2 since two characters are needed to represent this code point as a Unicode surrogate pair. For ASCII and Unicode 16-bit characters, it will return 1.
Based on this example, we can identify a surrogate pair quite easily, as follows:
public static List<Integer> extract(String str) {
List<Integer> result = new ArrayList<>();
for (int i = 0; i < str.length(); i++) {
int cp = str.codePointAt(i);
if (i < str.length()-1
&& str.codePointCount(i, i+2) == 1) {
result.add(cp);
result.add(str.codePointAt(i+1));
i++;
}
}
return result;
}
Or, like this:
public static List<Integer> extract(String str) {
List<Integer> result = new ArrayList<>();
for (int i = 0; i < str.length(); i++) {
int cp = str.codePointAt(i);
// the constant 2 means a suroggate pair
if (Character.charCount(cp) == 2) {
result.add(cp);
result.add(str.codePointAt(i+1));
i++;
}
}
return result;
}
The complete application is called ExtractSurrogatePairs.
Coding challenge 8 – Is rotation
Amazon, Google, Adobe, Microsoft
Problem: Consider two given strings, str1 and str2. Write a single line of code that tell us whether str2 is a rotation of str1.
Solution: Let's consider that str1 is helloworld and str2 is orldhellow. Since str2 is a rotation of str1, we can say that str2 is obtained by cutting str1 into two parts and rearranging them. The following image shows these words:
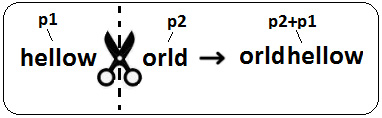
Figure 10.4 – Cutting str1 into two parts and rearranging them
So, based on this image, let's denote the left-hand side of the scissor as p1 and the right-hand side of the scissor as p2. With these notations, we can say that p1 = hellow and p2 = orld. Moreover, we can say that str1 = p1+p2 = hellow + orld and str2 = p2+p1 = orld + hellow. So, no matter where we perform the cut of str1, we can say that str1 = p1+p2 and str2=p2+p1. However, this means that str1+str2 = p1+p2+p2+p1 = hellow + orld + orld + hellow = p1+p2+p1+p2 = str1 + str1, so p2+p1 is a substring of p1+p2+p1+p2. In other words, str2 must be a substring of str1+str1; otherwise, it cannot be a rotation of str1. In terms of code, we can write the following:
public static boolean isRotation(String str1, String str2) {
return (str1 + str1).matches("(?i).*"
+ Pattern.quote(str2) + ".*");
}
The complete code is called RotateString.
Coding challenge 9 – Rotating a matrix by 90 degrees
Amazon, Google, Adobe, Microsoft, Flipkart
Problem: Consider a given n x n matrix of integers, M. Write a snippet of code that rotates this matrix by 90 degrees in a counterclockwise direction without using any extra space.
Solution: There are at least two solutions to this problem. One solution relies on the transpose of a matrix, while the other one relies on rotating the matrix ring by ring.
Using the matrix transpose
Let's tackle the first solution, which relies on finding the transpose of the matrix, M. The transpose of a matrix is a notion from linear algebra that means we need to flip a matrix over its main diagonal, which results in a new matrix denoted as MT. For example, having the matrix M and indices i and j, we can write the following relationship:
Figure 10.5 – Matrix transpose relationship
Once we've obtained the transpose of M, we can reverse the columns of the transpose. This will give us the final result (the matrix M rotated by 90 degrees counterclockwise). The following image clarifies this relationship for a 5x5 matrix:

Figure 10.6 – The transpose of a matrix on the left and the final result on the right
To obtain the transpose (MT), we can swap M[j][i] with M[i][j] via the following method:
private static void transpose(int m[][]) {
for (int i = 0; i < m.length; i++) {
for (int j = i; j < m[0].length; j++) {
int temp = m[j][i];
m[j][i] = m[i][j];
m[i][j] = temp;
}
}
}
Reversing the columns of MT can be done like so:
public static boolean rotateWithTranspose(int m[][]) {
transpose(m);
for (int i = 0; i < m[0].length; i++) {
for (int j = 0, k = m[0].length - 1; j < k; j++, k--) {
int temp = m[j][i];
m[j][i] = m[k][i];
m[k][i] = temp;
}
}
return true;
}
This solution has a time complexity of O(n2) and a space complexity of O(1), so we respect the problem requirements. Now, let's look at another solution to this problem.
Rotating the matrix ring by ring
If we think of a matrix as a set of concentric rings, then we can try to rotate each ring until the entire matrix is rotated. The following image is a visualization of this process for a 5x5 matrix:

Figure 10.7 – Rotating a matrix ring by ring
We can start from the outermost ring and eventually work our way inward. To rotate the outermost ring, we swap index by index, starting from the top, (0, 0). This way, we move the right edge in place of the top edge, the bottom edge in place of the right edge, the left edge in place of the bottom edge, and the top edge in place of the left edge. When this process is done, the outermost ring is rotated by 90 degrees counterclockwise. We can continue with the second ring, starting from index (1, 1), and repeat this process until we rotate the second ring. Let's see this in terms of code:
public static boolean rotateRing(int[][] m) {
int len = m.length;
// rotate counterclockwise
for (int i = 0; i < len / 2; i++) {
for (int j = i; j < len - i - 1; j++) {
int temp = m[i][j];
// right -> top
m[i][j] = m[j][len - 1 - i];
// bottom -> right
m[j][len - 1 - i] = m[len - 1 - i][len - 1 - j];
// left -> bottom
m[len - 1 - i][len - 1 - j] = m[len - 1 - j][i];
// top -> left
m[len - 1 - j][i] = temp;
}
}
return true;
}
This solution has a time complexity of O(n2) and a space complexity of O(1), so we have respected the problem's requirements.
The complete application is called RotateMatrix. It also contains the solution for rotating the matrix 90 degrees clockwise. Moreover, it contains the solution for rotating the given matrix in a separate matrix.
Coding challenge 10 – Matrix containing zeros
Google, Adobe
Problem: Consider a given n x m matrix of integers, M. If M(i, j) is equal to 0, then the entire row, i, and column, j, should contain only zeros. Write a snippet of code that accomplishes this task without using any extra space.
Solution: A naive approach consists of looping the matrix and for each (i, j) = 0, setting the row, i, and column, j, to zero. The problem is that when we traverse the cells of this row/column, we will find zeros and apply the same logic again. There is a big chance that we will end up with a matrix of zeros.
To avoid such naive approaches, it is better to take an example and try to visualize the solution. Let's consider a 5x8 matrix, as shown in the following image:

Figure 10.8 – Matrix containing zeros
The initial matrix has a 0 at (0, 4) and another one at (2, 6). This means that the solved matrix should contains only zeros on rows 0 and 2 and on columns 4 and 6.
An easy-to-implement approach would be storing the locations of the zeros and, at a second traversal of the matrix, set the corresponding rows and columns to zero. However, storing the zeros means using some extra space, and this is not allowed by the problem.
Tip
With a little trick and some work, we can keep the space complexity set to O(1). The trick consists of using the first row and column of the matrix to mark the zeros found in the rest of the matrix. For example, if we find a zero at cell (i, j) with i≠0 and j≠0, then we set M[i][0] = 0 and M[0][j] = 0. Once we've done that for the entire matrix, we can loop the first column (column 0) and propagate each zero that's found on the row. After that, we can loop the first row (row 0) and propagate each zero that's found on the column.
But how about the potential initial zeros of the first row and column? Of course, we have to tackle this aspect as well, so we start by flagging whether the first row/column contains at least one 0:
boolean firstRowHasZeros = false;
boolean firstColumnHasZeros = false;
// Search at least a zero on first row
for (int j = 0; j < m[0].length; j++) {
if (m[0][j] == 0) {
firstRowHasZeros = true;
break;
}
}
// Search at least a zero on first column
for (int i = 0; i < m.length; i++) {
if (m[i][0] == 0) {
firstColumnHasZeros = true;
break;
}
}
Furthermore, we apply what we've just said. To do this, we loop the rest of the matrix, and for each 0, we mark it on the first row and column:
// Search all zeros in the rest of the matrix
for (int i = 1; i < m.length; i++) {
for (int j = 1; j < m[0].length; j++) {
if (m[i][j] == 0) {
m[i][0] = 0;
m[0][j] = 0;
}
}
}
Next, we can loop the first column (column 0) and propagate each zero that was found on the row. After that, we can loop the first row (row 0) and propagate each zero that was found on the column:
for (int i = 1; i < m.length; i++) {
if (m[i][0] == 0) {
setRowOfZero(m, i);
}
}
for (int j = 1; j < m[0].length; j++) {
if (m[0][j] == 0) {
setColumnOfZero(m, j);
}
}
Finally, if the first row contains at least one 0, then we set the entire row to 0. Also, if the first column contains at least one 0, then we set the entire column to 0:
if (firstRowHasZeros) {
setRowOfZero(m, 0);
}
if (firstColumnHasZeros) {
setColumnOfZero(m, 0);
}
setRowOfZero() and setColumnOfZero() are quite simple:
private static void setRowOfZero(int[][] m, int r) {
for (int j = 0; j < m[0].length; j++) {
m[r][j] = 0;
}
}
private static void setColumnOfZero(int[][] m, int c) {
for (int i = 0; i < m.length; i++) {
m[i][c] = 0;
}
}
The application is called MatrixWithZeros.
Coding challenge 11 – Implementing three stacks with one array
Amazon, Google, Adobe, Microsoft, Flipkart
Problem: Write an implementation of three stacks using a single array. The implementation should expose three methods: push(), pop(), and printStacks().
Solution: There are two main approaches to providing the required implementation. The approach that we'll address here is based on interleaving the elements of these three stacks. Check out the following image:

Figure 10.9 – Interleaving the nodes of the stacks
As you can see, there is a single array that holds the nodes of these three stacks, denoted as Stack 1, Stack 2, and Stack 3. The key to our implementation relies on the fact that each node that's pushed onto the stack (the array, respectively) has a backward link to its previous node. The bottom of each stack has a link to -1. For example, for Stack 1, we know that value 2 at index 0 has a backward link to the dummy index -1, value 12 at index 1 has a backward link to the index 0, and that value 1 at index 7 has a backward link to the index 1.
So, a stack node holds two pieces of information – the value and the backward link:
public class StackNode {
int value;
int backLink;
StackNode(int value, int backLink) {
this.value = value;
this.backLink = backLink;
}
}
On the other hand, the array manages a link to the next free slot. Initially, when the array is empty, we can only create free slots, so the links are shaped as follows (notice the initializeSlots() method):
public class ThreeStack {
private static final int STACK_CAPACITY = 15;
// the array of stacks
private final StackNode[] theArray;
ThreeStack() {
theArray = new StackNode[STACK_CAPACITY];
initializeSlots();
}
...
private void initializeSlots() {
for (int i = 0; i < STACK_CAPACITY; i++) {
theArray[i] = new StackNode(0, i + 1);
}
}
}
Now, when we push a node into one of the stacks, we need to find a free slot and mark it as not free. This is done by the following code:
public class ThreeStack {
private static final int STACK_CAPACITY = 15;
private int size;
// next free slot in array
private int nextFreeSlot;
// the array of stacks
private final StackNode[] theArray;
// maintain the parent for each node
private final int[] backLinks = {-1, -1, -1};
...
public void push(int stackNumber, int value)
throws OverflowException {
int stack = stackNumber - 1;
int free = fetchIndexOfFreeSlot();
int top = backLinks[stack];
StackNode node = theArray[free];
// link the free node to the current stack
node.value = value;
node.backLink = top;
// set new top
backLinks[stack] = free;
}
private int fetchIndexOfFreeSlot()
throws OverflowException {
if (size >= STACK_CAPACITY) {
throw new OverflowException("Stack Overflow");
}
// get next free slot in array
int free = nextFreeSlot;
// set next free slot in array and increase size
nextFreeSlot = theArray[free].backLink;
size++;
return free;
}
}
When we pop a node from a stack, we must free that slot. This way, this slot can be reused by a future push. The relevant code is listed here:
public class ThreeStack {
private static final int STACK_CAPACITY = 15;
private int size;
// next free slot in array
private int nextFreeSlot;
// the array of stacks
private final StackNode[] theArray;
// maintain the parent for each node
private final int[] backLinks = {-1, -1, -1};
...
public StackNode pop(int stackNumber)
throws UnderflowException {
int stack = stackNumber - 1;
int top = backLinks[stack];
if (top == -1) {
throw new UnderflowException("Stack Underflow");
}
StackNode node = theArray[top]; // get the top node
backLinks[stack] = node.backLink;
freeSlot(top);
return node;
}
private void freeSlot(int index) {
theArray[index].backLink = nextFreeSlot;
nextFreeSlot = index;
size--;
}
}
The complete code, including the usage of printStacks(), is called ThreeStacksInOneArray.
Another approach to solving this problem is splitting the array of stacks into three distinct zones:
- The first zone is assigned to the first stack and lies at the left-hand side of the array endpoint (while we push into this stack, it grows in the right direction).
- The second zone is assigned to the second stack and lies at the right-hand side of the array endpoint (while we push into this stack, it grows in the left direction).
- The third zone is assigned to the third stack and lies in the middle of the array (while we push into this stack, it may grow in any direction).
The following image will help you clarify these points:

Figure 10.10 – Splitting the array into three zones
The main challenge of this approach consists of avoiding stack collisions by shifting the middle stack accordingly. Alternatively, we can divide the array into three fixed zones and allow the individual stack to grow in that limited space. For example, if the array size is s, then the first stack can be from 0 (inclusive) to s/3 (exclusive), the second stack can be from s/3 (inclusive) to 2*s/3 (exclusive), and the third stack can be from 2*s/3 (inclusive) to s (exclusive). This implementation is available in the bundled code as ThreeStacksInOneArrayFixed.
Alternatively, the middle stack could be implemented via an alternating sequence for subsequent pushes. This way, we also mitigate shifting but we are decreasing homogeneity. However, challenge yourself and implement this approach as well.
Coding challenge 12 – Pairs
Amazon, Adobe, Flipkart
Problem: Consider an array of integers (positive and negative), m. Write a snippet of code that finds all the pairs of integers whose sum is equal to a given number, k.
Solution: As usual, let's consider an example. Let's assume we have an array of 15 elements, as follows: -5, -2, 5, 4, 3, 7, 2, 1, -1, -2, 15, 6, 12, -4, 3. Also, if k=10, then we have four pairs whose sum is 10: (-15 + 5), (-2 + 12), (3 + 7), and (4 + 6). But how do we find these pairs?
There are different approaches to solving this problem. For example, we have the brute-force approach (usually, interviewers don't like this approach, so use it only as a last resort – while the brute-force approach can be a good start for understanding the details of the problem, it is not accepted as the final solution). Conforming to brute force, we take each element from the array and try to make a pair with each of the remaining elements. As with almost any brute-force-based solution, this one has an unacceptable complexity time as well.
We can find a better approach if we consider sorting the given array. We can do this via the Java built-in Arrays.sort() method, which has a runtime of O(n log n). Having a sorted array allows us to use two pointers that scan the whole array based on the following steps (this technique is known as two-pointers and you'll see it at work in several problems during this chapter):
- One pointer starts from index 0 (left pointer; let's denote it as l) and the other pointer starts from (m.length - 1) index (right pointer; let's denote it as r).
- If m[l] + m[r] = k, then we have a solution and we can increment the l position and decrement the r position.
- If m[l] + m[r]<k, then we increment l and keep r in place.
- If m[l] + m[r]>k, then we decrement r and keep l in place.
- We repeat steps 2-4 until l>= r.
The following image will help you implement these steps:
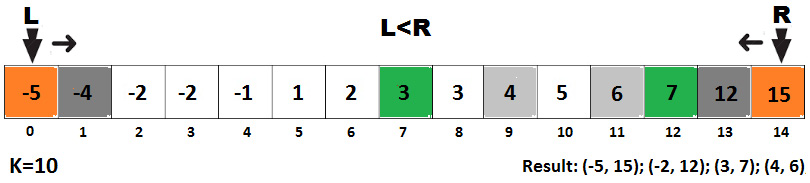
Figure 10.11 – Finding all pairs whose sum is equal to the given number
Keep an eye on this image while we see how it works for k=10:
- l = 0, r = 14 → sum = m[0] + m[14] = -5 + 15 = 10 → sum = k → l++, r--
- l = 1, r = 13 → sum = m[1] + m[13] = -4 + 12 = 8 → sum < k → l++
- l = 2, r = 13 → sum = m[2] + m[13] = -2 + 12 = 10 → sum = k → l++, r--
- l = 3, r = 12 → sum = m[3] + m[12] = -2 + 7 = 5 → sum < k → l++
- l = 4, r = 12 → sum = m[4] + m[12] = -1 + 7 = 6 → sum < k → l++
- l = 5, r = 12 → sum = m[5] + m[12] = 1 + 7 = 8 → sum < k → l++
- l = 6, r = 12 → sum = m[6] + m[12] = 2 + 7 = 9 → sum < k → l++
- l = 7, r = 12 → sum = m[7] + m[12] = 3 + 7 = 10 → sum = k → l++, r--
- l = 8, r = 11 → sum = m[8] + m[11] = 3 + 6 = 9 → sum < k → l++
- l = 9, r= 11 → sum = m[9] + m[11] = 4 + 6 = 10 → sum = k → l++, r--
- l = 10, r = 10 → STOP
If we put this logic into code, then we obtain the following method:
public static List<String> pairs(int[] m, int k) {
if (m == null || m.length < 2) {
return Collections.emptyList();
}
List<String> result = new ArrayList<>();
java.util.Arrays.sort(m);
int l = 0;
int r = m.length - 1;
while (l < r) {
int sum = m[l] + m[r];
if (sum == k) {
result.add("(" + m[l] + " + " + m[r] + ")");
l++;
r--;
} else if (sum < k) {
l++;
} else if (sum > k) {
r--;
}
}
return result;
}
The complete application is called FindPairsSumEqualK.
Coding challenge 13 – Merging sorted arrays
Amazon, Google, Adobe, Microsoft, Flipkart
Problem: Imagine that you have k sorted arrays of different lengths. Write an application that merges these arrays into O(nk log n), where n is the length of the longest array.
Solution: Let's assume that the given arrays are the following five arrays denoted with a, b, c, d, and e:
a: {1, 2, 32, 46} b: {-4, 5, 15, 18, 20} c: {3} d: {6, 8} e: {-2, -1, 0}
The expected result will be as follows:
{-4, -2, -1, 0, 1, 2, 3, 5, 6, 8, 15, 18, 20, 32, 46}
The simplest approach consists of copying all the elements from these arrays into a single array. This will take O(nk), where n is the length of the longest array and k is the number of arrays. Next, we sort this array via an O(n log n) time complexity algorithm (for example, via Merge Sort). This will result in O(nk log nk). However, the problem requires us to write an algorithm that can perform in O(nk log n).
There are several solutions that perform in O(nk log n), and one of them is based on a Binary Min Heap (this is detailed in Chapter 13, Trees and Graphs). In a nutshell, a Binary Min Heap is a complete binary tree. A Binary Min Heap is typically represented as an array (let's denote it as heap) whose root is at heap[0]. More importantly, for heap[i], we have the following:
- heap[(i - 1) / 2]: Returns the parent node
- heap[(2 * i) + 1]: Returns the left child node
- heap[(2 * i) + 2]: Returns the right child node
Now, our algorithm follows these steps:
- Create the resulting array of size n*k.
- Create a Binary Min Heap of size k and insert the first element of all the arrays into this heap.
- Repeat the following steps n*k times:
a. Get the minimum element from the Binary Min Heap and store it in the resulting array.
b. Replace the Binary Min Heap's root with the next element from the array that the element was extracted from (if the array doesn't have any more elements, then replace the root element with infinite; for example, with Integer.MAX_VALUE).
c. After replacing the root, heapify the tree.
The code is too big to be listed in this book, so the following is just the end of its implementation (the heap structure and the merge() operation):
public class MinHeap {
int data;
int heapIndex;
int currentIndex;
public MinHeap(int data, int heapIndex,
int currentIndex) {
this.data = data;
this.heapIndex = heapIndex;
this.currentIndex = currentIndex;
}
}
The following code is for the merge() operation:
public static int[] merge(int[][] arrs, int k) {
// compute the total length of the resulting array
int len = 0;
for (int i = 0; i < arrs.length; i++) {
len += arrs[i].length;
}
// create the result array
int[] result = new int[len];
// create the min heap
MinHeap[] heap = new MinHeap[k];
// add in the heap first element from each array
for (int i = 0; i < k; i++) {
heap[i] = new MinHeap(arrs[i][0], i, 0);
}
// perform merging
for (int i = 0; i < result.length; i++) {
heapify(heap, 0, k);
// add an element in the final result
result[i] = heap[0].data;
heap[0].currentIndex++;
int[] subarray = arrs[heap[0].heapIndex];
if (heap[0].currentIndex >= subarray.length) {
heap[0].data = Integer.MAX_VALUE;
} else {
heap[0].data = subarray[heap[0].currentIndex];
}
}
return result;
}
The complete application is called MergeKSortedArr.
Coding challenge 14 – Median
Amazon, Google, Adobe, Microsoft, Flipkart
Problem: Consider two sorted arrays, q and p (they can have different lengths). Write an application that computes the median value of these two arrays in logarithmic runtime.
Solution: A median value separates the higher half of a data sample (for example, an array) from the lower half. For example, the following image shows the median value of an array with an odd number of elements (left-hand side) and with an even number of elements (right-hand side), respectively:

Figure 10.12 – Median values for odd and even arrays
So, for an array with n number of elements, we have the following two formulas:
- If n is odd, then the median value is given by (n+1)/2
- If n is even, then the median value is given by [(n/2+(n/2+1)]/2
It is quite easy to compute the median of a single array. But how do we compute it for two arrays of different lengths? We have two sorted arrays and we must find something out from them. Having the experience of a candidate that knows how to prepare for an interview should be enough to intuit that the well-known Binary Search algorithm should be considered. Typically, having sorted arrays is something you should take into consideration when implementing the Binary Search algorithm.
We can roughly intuit that finding the median value of two sorted arrays can be reduced to finding the proper conditions that must be respected by this value.
Since the median value divides input into two equal parts, we can conclude that the first condition imposes that the median value of the q array should be at the middle index. If we denote this middle index as qPointer, then we obtain two equal parts: [0, qPointer] and [qPointer+1, q.length]. If we apply the same logic to the p array, then the median value of the p array should be at the middle index as well. If we denote this middle index as pPointer, then we obtain two equal parts: [0, pPointer] and [pPointer+1, p.length]. Let's visualize this via the following diagram:
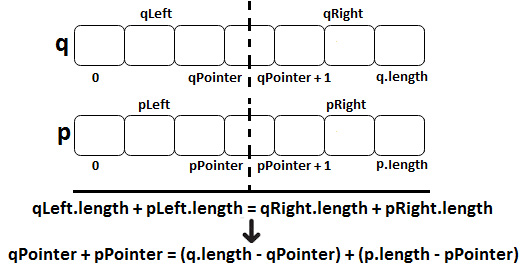
Figure 10.13 – Splitting arrays into two equal parts
We can conclude from this diagram that the first condition that the median value should respect is qLeft + pLeft = qRight + pRight. In other words, qPointer + pPointer = (q.length- qPointer) + (p.length - pPointer).
However, since our arrays aren't the same length (they can be equal, but this is just a special case that should be covered by our solution as well), we cannot simply halve both of them. What we can do is assume that p >= q (if they are not given like this, then we just swap them to force this assumption). Furthermore, under the umbrella of this assumption, we can write the following:
qPointer + pPointer = (q.length- qPointer) + (p.length - pPointer) →
2 * pPointer = q.length + p.length - 2 * qPointer →
pPointer = (q.length + p.length)/2 - qPointer
So far, pPointer can fall in the middle and we can avoid this by adding 1, which means we have the following starting pointers:
- qPointer = ((q.length - 1) + 0)/2
- pPointer = (q.length + p.length + 1)/2 - qPointer
If p>=q, then the minimum (q.length + p.length + 1)/2 - qPointer will always lead to pPointer as a positive integer. This will eliminate array-out-of-bounds exceptions and respects the first condition as well.
However, our first condition is not enough because it doesn't guarantee that all the elements in the left array are less than the elements in the right array. In other words, the maximum of the left part must be less than the minimum of the right part. The maximum of the left part can be q[qPointer-1] or p[pPointer-1], while the minimum of the right part can be q[qPointer] or p[pPointer]. So, we can conclude that the following conditions should be respected as well:
- q[qPointer-1] <= p[pPointer]
- p[pPointer-1] <= q[qPointer]
Under these conditions, the median value of q and p will be as follows:
- p.length + q.length is even: The average of the maximum of the left part and the minimum of the right part
- p.length + q.length is odd: The maximum of the left parts, max(q[qPointer-1], p[pPointer-1]).
Let's try to summarize this in an algorithm with three steps and an example. We start with qPointer as the middle of q (so as, [(q.length - 1) + 0)/2] and with pPointer as (q.length + p.length + 1)/2 - qPointer. Let's go through the following steps:
- If q[qPointer-1] <= p[pPointer] and p[pPointer-1] <= q[qPointer], then we have found the perfect qPointer (the perfect index).
- If p[pPointer-1] >q[qPointer], then we know that q[qPointer] is too small, so qPointer must be increased and pPointer must be decreased. Since the arrays are sorted, this action will result in a bigger q[qPointer] and a smaller p[pPointer]. Moreover, we can conclude that qPointer can only be in the right part of q (from middle+1 to q.length). Go back to step 1.
- If q[qPointer-1] >p[pPointer], then we know that q[qPointer-1] is too big. We must decrease qPointer to get q[qPointer-1] <= p[pPointer]. Moreover, we can conclude that qPointer can be only in the left part of q (from 0 to middle-1). Go to step 2.
Now, let's consider that q={ 2, 6, 9, 10, 11, 65, 67} and p={ 1, 5, 17, 18, 25, 28, 39, 77, 88}, and let's apply the previous steps.
Conforming to our preceding statements, we know that qPointer = (0 + 6) / 2 = 3 and pPointer = (7 + 9 + 1) / 2 - 3 = 5. The following image speaks for itself:
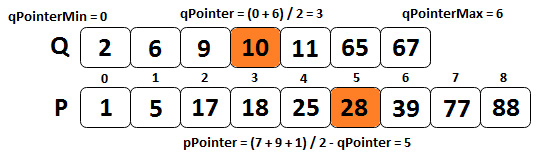
Figure 10.14 – Computing the median value (step 1)
Step 1 of our algorithm specifies that q[qPointer-1] <= p[pPointer] and p[pPointer-1] <= q[qPointer]. Obviously, 9 < 28, but 25 > 10, so we apply step 2 and afterward, go back to step 1. We increase qPointer and decrease pPointer, so qPointerMin becomes qPointer + 1. The new qPointer will be (4 + 6) / 2 = 5 and the new pPointer will be (7 + 9 + 1)/2 - 5 = 3. The following image will help you visualize this scenario:
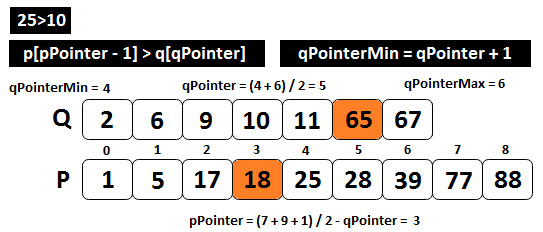
Figure 10.15 – Computing the median value (step 2)
Here, you can see that the new qPointer and new pPointer respect step 1 of our algorithm since q[qPointer-1], which is 11, is less than p[pPointer], which is, 18; and p[pPointer-1], which is 17, is less than q[qPointer], which is 65. With this, we found the perfect qPointer to be 5.
Finally, we have to find the maximum of the left-hand side and the minimum of the right-hand side and, based on the odd or even length of the two arrays, return the maximum of the left-hand side or the average of the maximum of the left-hand side and the minimum of the right-hand side. We know that the maximum of the left-hand side is max(q[qPointer-1], p[pPointer-1]), so max(11, 17) = 17. We also know that the minimum of the right-hand side is min(q[qPointer], p[pPointer]), so min(65, 18) = 18. Since the sum of lengths is 7 + 9 = 16, we compute that the median value is the average of these two, so avg(17, 18) = 17.5. We can visualize this as follows:

Figure 10.16 – Median value (final result)
Putting this algorithm into code results in the following output:
public static float median(int[] q, int[] p) {
int lenQ = q.length;
int lenP = p.length;
if (lenQ > lenP) {
swap(q, p);
}
int qPointerMin = 0;
int qPointerMax = q.length;
int midLength = (q.length + p.length + 1) / 2;
int qPointer;
int pPointer;
while (qPointerMin <= qPointerMax) {
qPointer = (qPointerMin + qPointerMax) / 2;
pPointer = midLength - qPointer;
// perform binary search
if (qPointer < q.length
&& p[pPointer-1] > q[qPointer]) {
// qPointer must be increased
qPointerMin = qPointer + 1;
} else if (qPointer > 0
&& q[qPointer-1] > p[pPointer]) {
// qPointer must be decreased
qPointerMax = qPointer - 1;
} else { // we found the poper qPointer
int maxLeft = 0;
if (qPointer == 0) { // first element on array 'q'?
maxLeft = p[pPointer - 1];
} else if (pPointer == 0) { // first element // of array 'p'?
maxLeft = q[qPointer - 1];
} else { // we are somewhere in the middle -> find max
maxLeft = Integer.max(q[qPointer-1], p[pPointer-1]);
}
// if the length of 'q' + 'p' arrays is odd,
// return max of left
if ((q.length + p.length) % 2 == 1) {
return maxLeft;
}
int minRight = 0;
if (qPointer == q.length) { // last element on 'q'?
minRight = p[pPointer];
} else if (pPointer == p.length) { // last element // on 'p'?
minRight = q[qPointer];
} else { // we are somewhere in the middle -> find min
minRight = Integer.min(q[qPointer], p[pPointer]);
}
return (maxLeft + minRight) / 2.0f;
}
}
return -1;
}
Our solution performs in O(log(max(q.length, p.length)) time. The complete application is called MedianOfSortedArrays.
Coding challenge 15 – Sub-matrix of one
Amazon, Microsoft, Flipkart
Problem: Consider that you've been given a matrix, m x n, containing only 0 and 1 (binary matrix). Write a snippet of code that returns the maximum size of the square sub-matrix so that it contains only elements of 1.
Solution: Let's consider that the given matrix is the one in the following image (5x7 matrix):

Figure 10.17 – The given 5 x 7 binary matrix
As you can see, the square sub-matrix only containing elements of 1 has a size of 3. The brute-force approach, or the naive approach, would be to find all the square sub-matrices containing all 1s and determine which one has the maximum size. However, for an m x n matrix that has z=min(m, n), the time complexity will be O(z3mn). You can find the brute-force implementation in the code bundled with this book. Of course, challenge yourself before checking the solution.
For now, let's try to find a better approach. Let's consider that the given matrix is of size n x n and study several scenarios of a 4x4 sample matrix. In a 4x4 matrix, we can see that the maximum square sub-matrix of 1s can have a size of 3x3, so in a matrix of size n x n, the maximum square sub-matrix of 1s can have a size of n-1 x n-1. Moreover, the following image reveals two base cases that are true for an m x n matrix as well:
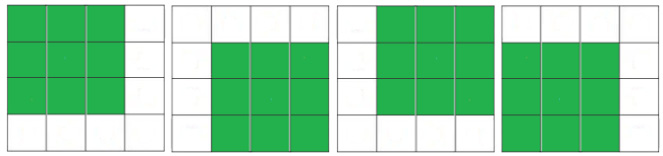
Figure 10.18 – Maxim sub-matrix of 1s in a 4 x 4 matrix
These cases are explained as follows:
- If the given matrix contains only one row, then cells with 1's in them will be the maximum size of the square sub-matrix. Therefore, the maximum size is 1.
- If the given matrix contains only one column, then cells with 1's in them will be the maximum size of the square sub-matrix. Therefore, the maximum size is 1.
Next, let's consider that subMatrix[i][j] represents the maximum size of the square sub-matrix, with all 1s ending at cell (i,j):
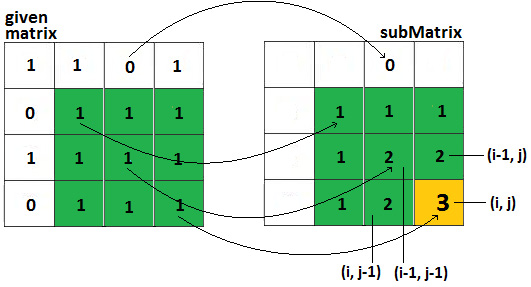
Figure 10.19 – Overall recurrence relation
The preceding figure allows us to establish a recurrence relation between the given matrix and an auxiliary subMatrix (a matrix that's the same size as the given matrix that should be filled in based on the recurrence relation):
- It is not easy to intuit this, but we can see that if matrix[i][j] = 0, then subMatrix[i][j] = 0
- If matrix[i][j] = 1, then subMatrix[i][j]
= 1 + min(subMatrix[i - 1][j], subMatrix[i][j - 1], subMatrix[i - 1][j - 1])
If we apply this algorithm to our 5 x 7 matrix, then we obtain the following result:
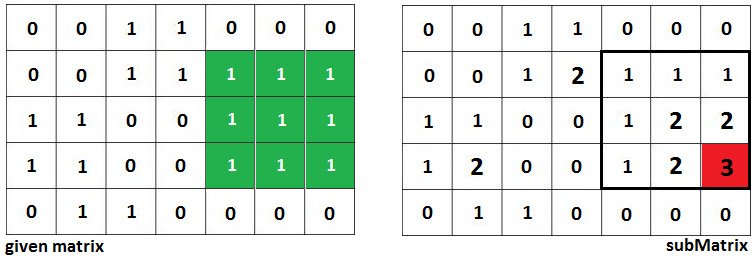
Figure 10.20 – Resolving our 5 x 7 matrix
Gluing together the preceding base cases and the recurrence relations results in the following algorithm:
- Create an auxiliary matrix (subMatrix) of the same size as the given matrix.
- Copy the first row and first column from the given matrix to this auxiliary subMatrix (these are the base cases).
- For each cell from the given matrix (starting at (1, 1)), do the following:
a. Fill up the subMatrix conforming to the preceding recurrence relations.
b. Track the maximum element of subMatrix since this element gives us the maximum size of the sub-matrix containing all 1's.
The following implementation clarifies any remaining details:
public static int ofOneOptimized(int[][] matrix) {
int maxSubMatrixSize = 1;
int rows = matrix.length;
int cols = matrix[0].length;
int[][] subMatrix = new int[rows][cols];
// copy the first row
for (int i = 0; i < cols; i++) {
subMatrix[0][i] = matrix[0][i];
}
// copy the first column
for (int i = 0; i < rows; i++) {
subMatrix[i][0] = matrix[i][0];
}
// for rest of the matrix check if matrix[i][j]=1
for (int i = 1; i < rows; i++) {
for (int j = 1; j < cols; j++) {
if (matrix[i][j] == 1) {
subMatrix[i][j] = Math.min(subMatrix[i - 1][j - 1],
Math.min(subMatrix[i][j - 1],
subMatrix[i - 1][j])) + 1;
// compute the maximum of the current sub-matrix
maxSubMatrixSize = Math.max(
maxSubMatrixSize, subMatrix[i][j]);
}
}
}
return maxSubMatrixSize;
}
Since we iterate m*n times to fill the auxiliary matrix, the overall complexity of this solution is O(mn). The complete application is called MaxMatrixOfOne.
Coding challenge 16 – Container with the most water
Google, Adobe, Microsoft
Problem: Consider that you've been given n positive integers, p1, p2, ..., pn, where each integer represents a point at coordinate (i, pi) . Next, n vertical lines are drawn so that the two endpoints of line i are at (i, pi) and (i, 0). Write a snippet of code that finds two lines that, together with the X-axis, form a container that contains the most water.
Solution: Let's consider that the given integers are 1, 4, 6, 2, 7, 3, 8, 5, and 3. Following the problem statements, we can sketch the n vertical lines (line 1: {(0, 1), (0, 0)}, line 2: {(1, 4), (1,0)}, line 3: {(2, 6), (2, 0)}, and so on). This can be seen in the following graph:
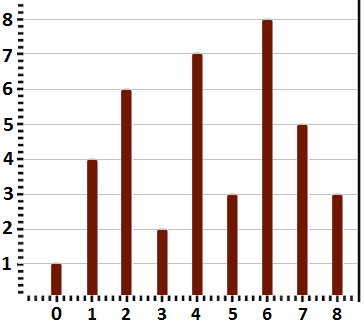
Figure 10.21 – The n vertical line representation
First of all, let's see how we should interpret the problem. We have to find the container that contains the most water. This means that, in our 2D representation, we have to find the rectangle that has the maximum area. In a 3D representation, this container will have the maximum volume, so it will contain the most water.
Thinking about the solution in terms of the brute-force approach is quite straightforward. For each line, we compute the areas showing the rest of the lines while tracking the largest area found. This requires two nested loops, as shown here:
public static int maxArea(int[] heights) {
int maxArea = 0;
for (int i = 0; i < heights.length; i++) {
for (int j = i + 1; j < heights.length; j++) {
// traverse each (i, j) pair
maxArea = Math.max(maxArea,
Math.min(heights[i], heights[j]) * (j - i));
}
}
return maxArea;
}
The problem with this code is that its runtime is O(n2). A better approach consists of employing a technique known as two-pointers. Don't worry – it is a pretty simple technique that it is quite useful to have in your toolbelt. You never know when you'll need it!
We know that we are looking for the maximum area. Since we are talking about a rectangular area, this means that the maximum area must accommodate the best report between the biggest width and the biggest height as much as possible. The biggest width is from 0 to n-1 (in our example, from 0 to 8). To find the biggest height, we must adjust the biggest width while tracking the maximum area. For this, we can start from the biggest width, as shown in the following graph:
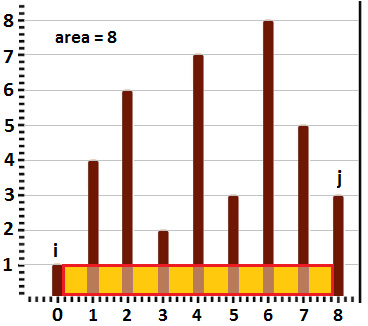
Figure 10.22 – Area with the biggest width
So, if we demarcate the boundaries of the biggest width with two pointers, we can say that i=0 and j=8 (or n-1). In this case, the container that holds the water will have an area of pi* 8 = 1 * 8 = 8. The container cannot be higher than pi = 1 because the water will flow out. However, we can increment i (i=1, pi=4) to obtain a higher container, and potentially a bigger container, as shown in the following graph:

Figure 10.23 – Increasing i to obtain a bigger container
Generally speaking, if pi ≤ pj, then we increment i; otherwise, we decrement j. By successively increasing/decreasing i and j, we can obtain the maximum area. From left to right and from top to bottom, the following image shows this statement at work for the next six steps:

Figure 10.24 – Computing areas while increasing/decreasing i and j
The steps are as follows:
- In the top-left corner image, we decreased j since pi > pj, p1 > p8 (4 > 3).
- In the top-middle image, we increased i since pi < pj, p1 < p7 (4 < 5).
- In the top-right corner image, we decreased j since pi > pj, p2 > p7 (6 > 5).
- In the bottom-left corner image, we increased i since pi < pj, p2 < p6 (6 < 8).
- In the bottom-middle image, we increased i since pi < pj, p3 < p6 (2 < 8).
- In the bottom-right corner image, we increased i since pi < pj, p4 < p6 (7 < 8).
Done! If we increase i or decrease j one more time, then i=j and the area is 0. At this point, we can see that the maximum area is 25 (top-middle image). Well, this technique is known as two-pointers and can be implemented in this case with the following algorithm:
- Start with the maximum area as 0, i=0 and j=n-1
- While i < j, do the following:
a. Compute the area for the current i and j.
b. Update the maximum area accordingly (if needed).
c. If pi ≤ pj, then i++; else, j--.
In terms of code, we have the following:
public static int maxAreaOptimized(int[] heights) {
int maxArea = 0;
int i = 0; // left-hand side pointer
int j = heights.length - 1; // right-hand side pointer
// area cannot be negative,
// therefore i should not be greater than j
while (i < j) {
// calculate area for each pair
maxArea = Math.max(maxArea, Math.min(heights[i],
heights[j]) * (j - i));
if (heights[i] <= heights[j]) {
i++; // left pointer is small than right pointer
} else {
j--; // right pointer is small than left pointer
}
}
return maxArea;
}
The runtime of this code is O(n). The complete application is called ContainerMostWater.
Coding challenge 17 – Searching in a circularly sorted array
Amazon, Google, Adobe, Microsoft, Flipkart
Problem: Consider that you've been given a circularly sorted array of integers with no duplicates, m. Write a program that searches for the given x in O(log n) complexity time.
Solution: If we could solve this problem in O(n) complexity time, then the brute-force approach is the simplest solution. A linear search in the array will give the index of the searched x. However, we need to come up with an O(log n) solution, so we need to tackle the problem from another perspective.
We have enough hints that point us to the well-known Binary Search algorithm, which we discussed in Chapter 7, Big O Analysis of Algorithms and in Chapter 14, Sorting and Searching. We have a sorted array, we need to find a certain value, and we need to do it in O(log n) complexity time. So, there are three hints that point us to the Binary Search algorithm. Of course, the big issue is represented by the circularity of the sorted array, so we cannot apply a plain Binary Search algorithm.
Let's consider that m = {11, 14, 23, 24, -1, 3, 5, 6, 8, 9, 10} and x = 14, and we expected the output to be index 1. The following image introduces several notations and serves as guidance in solving the problem at hand:
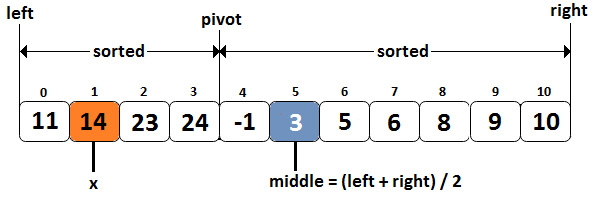
Figure 10.25 – Circularly sorted array and Binary Search algorithm
Since the sorted array is circular, we have a pivot. This is an index pointing to the head of the array. The elements from the left of the pivot have been rotated. When the array is not rotated, it will be {-1, 3, 5, 6, 8, 9, 10, 11, 14, 23, 24}. Now, let's see the steps for the solution based on the Binary Search algorithm:
- We apply the Binary Search algorithm, so we start by computing the middle of the array as (left + right) / 2.
- We check whether x = m[middle]. If so, we return the middle. If not, we continue with the next step.
- Next, we check whether the right-half of the array is sorted. All the elements from the range [middle, right] are sorted if m[middle] <= m[right]:
a. If x > m[middle] and x <= m[right], then we ignore the left-half, set left = middle + 1, and repeat from step 1.
b. If x <= m[middle] or x > m[right], then we ignore the right-half, set right = middle - 1, and repeat from step 1.
- If the right-half of the array is not sorted, then the left-half must be sorted:
a. If x >= m[left] and x < m[middle], then we ignore the right-half, set right = middle- 1, and repeat from step 1.
b. If x < m[left] or x >= m[middle], then we ignore the left-half, set left = middle + 1, and repeat from step 1.
We repeat steps 1-4 as long as we didn't find x or left <= right.
Let's apply the preceding algorithm to our case.
So, middle is (left + right) / 2 = (0 + 10) / 2 = 5. Since m[5] ≠14 (remember that 14 is x), we continue with step 3. Since m[5]<m[10], we conclude that the right-half is sorted. However, we notice that x>m[right] (14 >10), so we apply step 3b. Basically, we ignore the right-half and we set right = middle - 1 = 5 - 1 = 4. We apply step 1 again.
The new middle is (0 + 4) / 2 = 2. Since m[2]≠14, we continue with step 3. Since m[2] >m[4], we conclude that the left-half is sorted. We notice that x>m[left] (14 >11) and x<m[middle] (14<23), so we apply step 4a. We ignore the right-half and we set right= middle - 1 = 2 - 1 = 1. We apply step 1 again.
The new middle is (0 + 1) / 2 = 0. Since m[0]≠14, we continue with step 3. Since m[0]<m[1], we conclude that the right-half is sorted. We notice that x > m[middle] (14 > 11) and x = m[right] (14 = 14), so we apply step 3a. We ignore the left-half and we set left = middle + 1 = 0 + 1 = 1. We apply step 1 again.
The new middle is (1 + 1) / 2 = 1. Since m[1]=14, we stop and return 1 as the index of the array where we found the searched value.
Let's put this into code:
public static int find(int[] m, int x) {
int left = 0;
int right = m.length - 1;
while (left <= right) {
// half the search space
int middle = (left + right) / 2;
// we found the searched value
if (m[middle] == x) {
return middle;
}
// check if the right-half is sorted (m[middle ... right])
if (m[middle] <= m[right]) {
// check if n is in m[middle ... right]
if (x > m[middle] && x <= m[right]) {
left = middle + 1; // search in the right-half
} else {
right = middle - 1; // search in the left-half
}
} else { // the left-half is sorted (A[left ... middle])
// check if n is in m[left ... middle]
if (x >= m[left] && x < m[middle]) {
right = middle - 1; // search in the left-half
} else {
left = middle + 1; // search in the right-half
}
}
}
return -1;
}
The complete application is called SearchInCircularArray. Similar problems will ask you to find the maximum or the minimum value in a circularly sorted array. While both applications are available in the bundled code as MaximumInCircularArray and MinimumInCircularArray, it is advisable to use what you've learned so far and challenge yourself to find a solution.
Coding challenge 18 – Merging intervals
Amazon, Google, Adobe, Microsoft, Flipkart
Problem: Consider that you've been given an array of intervals of the [start, end] type. Write a snippet of code that merges all the intervals that are overlapping.
Solution: Let's consider that the given intervals are [12,15], [12,17], [2,4], [16,18], [4,7], [9,11], and [1,2]. After we merge the overlapping intervals, we obtain the following result: [1, 7], [9, 11] [12, 18].
We can start with the brute-force approach. It is quite intuitive that we take an interval (let's denote it as pi) and compare its end (pei) with the starts of the rest of the intervals. If the start of an interval (from the rest of the intervals) is less than the end of p, then we can merge these two intervals. The end of the merged interval becomes the maximum of the ends of these two intervals. But this approach will perform in O(n2), so it will not impress the interviewer.
However, the brute-force approach can give us an important hint for attempting a better implementation. At any moment of time, we must compare the end of p with the start of another interval. This is important because it can lead us to the idea of sorting the intervals by their starts. This way, we seriously reduce the number of comparisons. Having the sorted intervals allows us to combine all the intervals in a linear traversal.
Let's try and use a graphical representation of our sample intervals sorted in ascending order by their starts (psi<psi+1<psi+2). Also, each interval is always forward-looking (pei>psi, pei+1>psi+1, pei+2>psi+2, and so on). This will help us understand the algorithm that we'll cover soon:
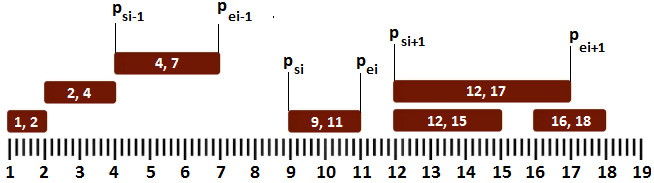
Figure 10.26 – Sorting the given intervals
Based on the preceding image, we can see that if the start of p is greater than the end of the previous p, (psi>pei-1), then the start of the next p is greater than the end of the previous p, (psi+1>pei-1), so there is no need to compare the previous p with the next p. In other words, if pi doesn't overlap with pi-1, then pi+1 cannot overlap with pi-1 because the start of pi+1 must be greater than or equal to pi.
If psi is less than pei-1, then we should update pei-1 with the maximum between pei-1 and pei and move to pei+1. This can be done via a stack, as follows:
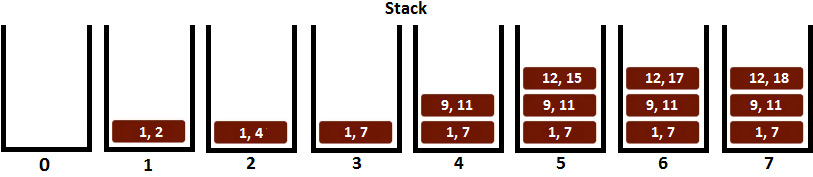
Figure 10.27 – Using a stack to solve the problem
These are the steps that occur:
Step 0: We start with an empty stack.
Step 1: Since the stack is empty, we push the first interval ([1, 2]) into the stack.
Step 2: Next, we focus on the second interval ([2, 4]). The start of [2, 4] is equal to the end of the interval from the top of the stack, [1, 2], so we don't push [2, 4] into the stack. We continue to compare the end of [1, 2] with the end of [2, 4]. Since 2 is less than 4, we update the interval [1, 2] to [1, 4]. So, we merged [1, 2] with [2, 4].
Step 3: Next, we focus on interval [4, 7]. The start of [4, 7] is equal to the end of the interval from the top of the stack, [1, 4], so we don't push [4, 7] into the stack. We continue to compare the end of [1, 4] with the end of [4, 7]. Since 4 is less than 7, we update the interval [1, 4] to [1, 7]. So, we merged [1, 4] with [4, 7].
Step 4: Next, we focus on interval [9, 11]. The start of [9, 11] is greater than the end of the interval from the top of the stack, [1, 7], so intervals [1, 7] and [9, 11] don't overlap. This means that we can push interval [9, 11] into the stack.
Step 5: Next, we focus on interval [12, 15]. The start of [12, 15] is greater than the end of the interval from the top of the stack, [9, 11], so intervals [9, 11] and [12, 15] don't overlap. This means that we can push interval [12, 15] into the stack.
Step 6: Next, we focus on interval [12, 17]. The start of [12, 17] is equal to the end of the interval from the top of the stack, [12, 15], so we don't push [12, 17] into the stack. We continue and compare the end of [12, 15] with the end of [12, 17]. Since 15 is less than 17, we update interval [12, 15] to [12, 17]. So, here, we merged [12, 15] with [12, 17].
Step 7: Finally, we focus on interval [16, 18]. The start of [16, 18] is less than the end of the interval from the top of the stack, [12, 17], so intervals [16, 18] and [12, 17] are overlapping. This time, we have to update the end of the interval from the top of the stack with the maximum between the end of this interval and [16, 18]. Since 18 is greater than 17, the interval from the top of the stack becomes [12, 17].
Now, we can pop the content of the stack to see the merged intervals, [[12, 18], [9, 11], [1, 7]], as shown in the following image:

Figure 10.28 – The merged intervals
Based on these steps, we can create the following algorithm:
- Sort the given intervals in ascending order based on their starts.
- Push the first interval into the stack.
- For the rest of intervals, do the following:
a. If the current interval does not overlap with the interval from the top of the stack, then push it into the stack.
b. If the current interval overlaps with the interval from the top of the stack and the end of the current interval is greater than that of the stack top, then update the top of the stack with the end of the current interval.
- At the end, the stack contains the merged intervals.
In terms of code, this algorithm looks as follows:
public static void mergeIntervals(Interval[] intervals) {
// Step 1
java.util.Arrays.sort(intervals,
new Comparator<Interval>() {
public int compare(Interval i1, Interval i2) {
return i1.start - i2.start;
}
});
Stack<Interval> stackOfIntervals = new Stack();
for (Interval interval : intervals) {
// Step 3a
if (stackOfIntervals.empty() || interval.start
> stackOfIntervals.peek().end) {
stackOfIntervals.push(interval);
}
// Step 3b
if (stackOfIntervals.peek().end < interval.end) {
stackOfIntervals.peek().end = interval.end;
}
}
// print the result
while (!stackOfIntervals.empty()) {
System.out.print(stackOfIntervals.pop() + " ");
}
}
The runtime of this code is O(n log n) with an auxiliary space of O(n) for the stack. While the interviewer should be satisfied with this approach, he/she may ask you for optimization. More precisely, can we drop the stack and obtain a complexity space of O(1)?
If we drop the stack, then we must perform the merge operation in-place. The algorithm that can do this is self-explanatory:
- Sort the given intervals in ascending order based on their starts.
- For the rest of the intervals, do the following:
a. If the current interval is not the first interval and it overlaps with the previous interval, then merge these two intervals. Do the same for all the previous intervals.
b. Otherwise, add the current interval to the output array of intervals.
Notice that, this time, the intervals are sorted in descending order of their starts. This means that we can check whether two intervals are overlapping by comparing the start of the previous interval with the end of the current interval. Let's see the code for this:
public static void mergeIntervals(Interval intervals[]) {
// Step 1
java.util.Arrays.sort(intervals,
new Comparator<Interval>() {
public int compare(Interval i1, Interval i2) {
return i2.start - i1.start;
}
});
int index = 0;
for (int i = 0; i < intervals.length; i++) {
// Step 2a
if (index != 0 && intervals[index - 1].start
<= intervals[i].end) {
while (index != 0 && intervals[index - 1].start
<= intervals[i].end) {
// merge the previous interval with
// the current interval
intervals[index - 1].end = Math.max(
intervals[index - 1].end, intervals[i].end);
intervals[index - 1].start = Math.min(
intervals[index - 1].start, intervals[i].start);
index--;
}
// Step 2b
} else {
intervals[index] = intervals[i];
}
index++;
}
// print the result
for (int i = 0; i < index; i++) {
System.out.print(intervals[i] + " ");
}
}
The runtime of this code is O(n log n) with an auxiliary space of O(1). The complete application is called MergeIntervals.
Coding challenge 19 – Petrol bunks circular tour
Amazon, Google, Adobe, Microsoft, Flipkart
Problem: Consider that you've been given n petrol bunks along a circular route. Every petrol bunk contains two pieces of data: the amount of fuel (fuel[]) and the distance from that current petrol bunk to the next petrol bunk (dist[]). Next, you have a truck with an unlimited gas tank. Write a snippet of code that calculates the first point from where the truck should start in order to complete a full tour. You begin the journey with an empty tank at one of the petrol bunks. With 1 liter of petrol, the truck can go 1 unit of distance.
Solution: Consider that you've been given the following data: dist = {5, 4, 6, 3, 5, 7}, fuel = {3, 3, 5, 5, 6, 8}.
Let's use the following images to get a better understanding of the context of this problem and to support us in finding a solution:
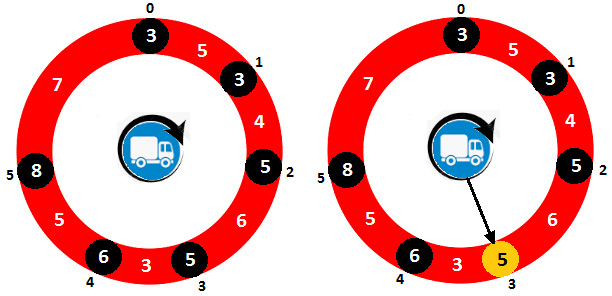
Figure 10.29 – Truck circular tour sample
From 0 to 5, we have six petrol bunks. On the left-hand side of the image, you can see a sketch of the given circular route and the distribution of the petrol bunks. The first petrol bunk has 3 liters of petrol, and the distance to the next petrol bunk is 5 units. The second petrol bunk has 3 liters of petrol, and the distance to the next petrol bunk is 4 units. The third petrol bunk has 5 liters of petrol, and the distance to the next petrol bunk is 6 units, and so on. Obviously, a vital condition if we wish to go from petrol bunk X to petrol bunk Y is that the distance between X and Y is less than or equal to the amount of fuel in the tank of the truck. For example, if the truck starts the journey from petrol bunk 0, then it cannot go to petrol bunk 1 since the distance between these two petrol bunks is 5 units and the truck can have only 3 liters of petrol in the tank. On the other hand, if the truck starts the journey from petrol bunk 3, then it can go to petrol bunk 4 because the truck will have 5 liters of petrol in the tank. Actually, as shown on the right-hand side of the image, the solution to this case is to start from petrol bunk 3 with 5 liters of petrol in the tank – take your time and complete the tour using some paper and a pen.
The brute-force (or naive) approach can rely on a straightforward statement: we start from each petrol bunk and try to make the complete tour. This is simple to implement but its runtime will be O(n2). Challenge yourself to come up with a better implementation.
To solve this problem more efficiently, we need to understand and use the following facts:
- If the sum of fuel ≥ the sum of distances, then the tour can be completed.
- If petrol bunk X cannot reach petrol bunk Z in the sequence of X → Y → Z, then Y cannot make it either.
While the first bullet is a commonsense notion, the second bullet requires some extra proof. Here is the reasoning behind the second bullet:
If fuel[X] < dist[X], then X cannot even reach Y So to reach Z from X, fuel[X] must be ≥ dist[X].
Given that X cannot reach Z, we have fuel[X] + fuel[Y] < dist[X] + dist[Y], and fuel[X] ≥ dist[X]. Therefore, fuel[Y] < dist[Y] and Y cannot reach Z.
Based on these two points, we can come up with the following implementation:
public static int circularTour(int[] fuel, int[] dist) {
int sumRemainingFuel = 0; // track current remaining fuel
int totalFuel = 0; // track total remaining fuel
int start = 0;
for (int i = 0; i < fuel.length; i++) {
int remainingFuel = fuel[i] - dist[i];
//if sum remaining fuel of (i-1) >= 0 then continue
if (sumRemainingFuel >= 0) {
sumRemainingFuel += remainingFuel;
//otherwise, reset start index to be current
} else {
sumRemainingFuel = remainingFuel;
start = i;
}
totalFuel += remainingFuel;
}
if (totalFuel >= 0) {
return start;
} else {
return -1;
}
}
To understand this code, try to pass the given set of data through the code using some paper and a pen. Also, you may wish to try the following sets:
// start point 1
int[] dist = {2, 4, 1};
int[] fuel = {0, 4, 3};
// start point 1
int[] dist = {6, 5, 3, 5};
int[] fuel = {4, 6, 7, 4};
// no solution, return -1
int[] dist = {1, 3, 3, 4, 5};
int[] fuel = {1, 2, 3, 4, 5};
// start point 2
int[] dist = {4, 6, 6};
int[] fuel = {6, 3, 7};
The runtime of this code is O(n). The complete application is called PetrolBunks.
Coding challenge 20 – Trapping rainwater
Amazon, Google, Adobe, Microsoft, Flipkart
Problem: Consider that you've been given a set of bars that are different heights (non-negative integers). The width of a bar is equal to 1. Write a snippet of code that computes the amount of water that can be trapped within the bars.
Solution: Let's consider that the given set of bars is an array, as follows: bars = { 1, 0, 0, 4, 0, 2, 0, 1, 6, 2, 3}. The following image is a sketch of these bars' heights:
Figure 10.30 – The given set of bars
Now, rain is filling up between the spaces of these bars. So, after the rain has fallen, we will have something like the following:

Figure 10.31 – The given bars after rain
So, here, we have a maximum amount of water equal to 16. The solution to this problem depends on how we look at the water. For example, we can look at the water between the bars or at the water on top of each bar. The second view is exactly what we want.
Check out the following image, which has some additional guidance regarding how to isolate the water on top of each bar:

Figure 10.32 – Water on top of each bar
So, above bar 0, we have no water. Above bar 1, we have 1 unit of water. Above bar 2, we have 1 unit of water, and so on and so forth. If we sum up these values, then we get 0 + 1 + 1 + 0 + 4 + 2 + 4 + 3 + 0 + 1 + 0 = 16, which is the precise amount of water we have. However, to determine the amount of water on top of bar x, we must know the minimum between the highest bars on the left- and right-hand sides. In other words, for each of the bars, that is, 1, 2, 3 ... 9 (notice that we don't use bars 0 and 10 since they are the boundaries), we have to determine the highest bars on the left- and right-hand sides and compute the minimum between them. The following image reveals our computations (the bar in the middle ranges from 1 to 9):
Figure 10.33 – Highest bars on the left- and right-hand sides
Hence, we can conclude that a simple solution would be to traverse the bars to find the highest bars on the left- and right-hand sides. The minimum of these two bars can be exploited as follows:
- If the minimum is smaller than the height of the current bar, then the current bar cannot hold water on top of it.
- If the minimum is greater than the height of the current bar, then the current bar can hold an amount of water equal to the difference between the minimum and the height of the current bar on top of it.
So, this problem can be addressed by computing the highest bars on the left- and right-hand sides of every bar. An efficient implementation of these statements consists of pre-computing the highest bars on the left- and right-hand sides of every bar in O(n) time. Then, we need to use the results to find the amount of water on the top of each bar. The following code should clarify any other details:
public static int trap(int[] bars) {
int n = bars.length - 1;
int water = 0;
// store the maximum height of a bar to
// the left of the current bar
int[] left = new int[n];
left[0] = Integer.MIN_VALUE;
// iterate the bars from left to right and
// compute each left[i]
for (int i = 1; i < n; i++) {
left[i] = Math.max(left[i - 1], bars[i - 1]);
}
// store the maximum height of a bar to the
// right of the current bar
int right = Integer.MIN_VALUE;
// iterate the bars from right to left
// and compute the trapped water
for (int i = n - 1; i >= 1; i--) {
right = Math.max(right, bars[i + 1]);
// check if it is possible to store water
// in the current bar
if (Math.min(left[i], right) > bars[i]) {
water += Math.min(left[i], right) - bars[i];
}
}
return water;
}
The runtime of this code is O(n) with an auxiliary space of O(n) for the left[] array. A similar Big O can be obtained by using an implementation based on a stack (the bundled code contains this implementation as well). How about writing an implementation that has O(1) space?
Well, instead of maintaining an array of size n to store all the left maximum heights, we can use two variables to store the maximum until that bar (this technique is known as two-pointers). As you may recall, you observed this in some of the previous coding challenges. The two pointers are maxBarLeft and maxBarRight. The implementation is as follows:
public static int trap(int[] bars) {
// take two pointers: left and right pointing
// to 0 and bars.length-1
int left = 0;
int right = bars.length - 1;
int water = 0;
int maxBarLeft = bars[left];
int maxBarRight = bars[right];
while (left < right) {
// move left pointer to the right
if (bars[left] <= bars[right]) {
left++;
maxBarLeft = Math.max(maxBarLeft, bars[left]);
water += (maxBarLeft - bars[left]);
// move right pointer to the left
} else {
right--;
maxBarRight = Math.max(maxBarRight, bars[right]);
water += (maxBarRight - bars[right]);
}
}
return water;
}
The runtime of this code is O(n) with an O(1) space. The complete application is called TrapRainWater.
Coding challenge 21 – Buying and selling stock
Amazon, Microsoft
Problem: Consider that you've been given an array of positive integers representing the price of a stock on each day. So, the ith element of the array represents the price of the stock on day i. As a general rule, you may not perform multiple transactions (a buy-sell sequence is known as a transaction) at the same time and you must sell the stock before you buy again. Write a snippet of code that returns the maximum profit in one of the following scenarios (usually, the interviewer will give you one of the following scenarios):
- You are allowed to buy and sell the stock only once.
- You are allowed to buy and sell the stock only twice.
- You are allowed to buy and sell the stock unlimited times.
- You are allowed to buy and sell the stock only k times (k is given).
Solution: Let's consider that the given array of prices is prices={200, 500, 1000, 700, 30, 400, 900, 400, 550}. Let's tackle each of the preceding scenarios.
Buying and selling the stock only once
In this scenario, we must obtain the maximum profit by buying and selling the stock only once. This is quite simple and intuitive. The idea is to buy the stock when it is at its cheapest and sell it when it is at its most expensive. Let's identify this statement via the following price-trend graph:

Figure 10.34 – Price-trend graph
Conforming to the preceding graphic, we should buy the stock at a price of 30 on day 5 and sell it at a price of 900 on day 7. This way, the profit will be at its maximum (870). To determine the maximum profit, we can employ a simple algorithm, as follows:
- Consider the cheapest price at day 1 and no profit (maximum profit is 0).
- Iterate the rest of the days (2, 3, 4, ...) and do the following:
a. For each day, update the maximum profit as the max(current maximum profit, (today's price - cheapest price)).
b. Update the cheapest price as the min(current cheapest price, today's price).
Let's apply this algorithm to our data. So, we consider the cheapest price as 200 (price at day 1) and the maximum profit is 0. The following image reveals the computations day by day:
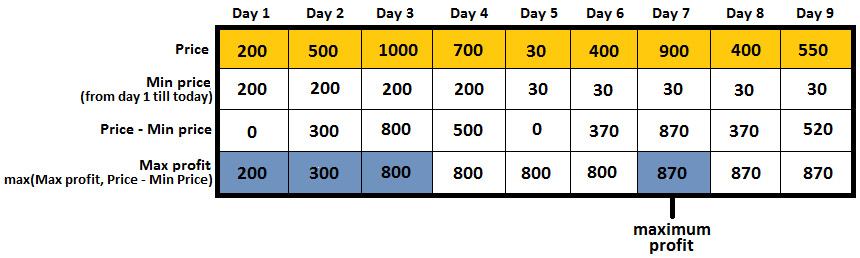
Figure 10.35 – Computing the maximum profit
Day 1: The minimum price is 200; the price on day 1 - minimum price = 0; therefore, the maximum profit so far is 200.
Day 2: The minimum price is 200 (since 500 > 200); the price on day 2 - minimum price = 300; therefore, the maximum profit so far is 300 (since 300 > 200).
Day 3: The minimum price is 200 (since 1000 > 200); the price on day 3 - minimum price = 800; therefore, the maximum profit so far is 800 (since 800 > 300).
Day 4: The minimum price is 200 (since 700 > 200); the price on day 4 - minimum price = 500; therefore, the maximum profit so far is 800 (since 800 > 500).
Day 5: The minimum price is 30 (since 200 > 30); the price on day 5 - minimum price = 0; therefore, the maximum profit so far is 800 (since 800 > 0).
Day 6: The minimum price is 30 (since 400 > 30); the price on day 6 - minimum price = 370; therefore, the maximum profit so far is 800 (since 800 > 370).
Day 7: The minimum price is 30 (since 900 > 30); the price on day 7 - minimum price = 870; therefore, the maximum profit so far is 870 (since 870 > 800).
Day 8: The minimum price is 30 (since 400 > 30); the price on day 8 - minimum price = 370; therefore, the maximum profit so far is 870 (since 870 > 370).
Day 9: The minimum price is 30 (since 550 > 30); the price on day 9 - minimum price = 520; therefore, the maximum profit so far is 870 (since 870 >520).
Finally, the maximum profit is 870.
Let's see the code:
public static int maxProfitOneTransaction(int[] prices) {
int min = prices[0];
int result = 0;
for (int i = 1; i < prices.length; i++) {
result = Math.max(result, prices[i] - min);
min = Math.min(min, prices[i]);
}
return result;
}
The runtime of this code is O(n). Let's tackle the next scenario.
Buying and selling the stock only twice
In this scenario, we must obtain the maximum profit by buying and selling the stock only twice. The idea is to buy the stock when it is as its cheapest and sell it when it is at its most expensive. We do this twice. Let's identify this statement via the following price-trend graph:
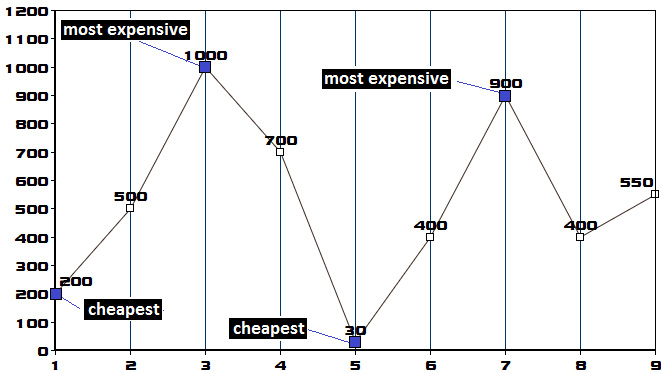
Figure 10.36 – Price-trend graph
Conforming to the preceding graph, we should buy the stock at a price of 200 on day 1 and sell it at a price of 1,000 on day 3. This transaction brings a profit of 800. Next, we should buy the stock at a price of 30 on day 5 and sell it at a price of 900 on day 7. This transaction brings a profit of 870. So, the maximum profit is 870+800=1670.
To determine the maximum profit, we must find the two most profitable transactions. We can do this via dynamic programming and the divide and conquer technique. We divide the algorithm into two parts. The first part of the algorithm contains the following steps:
- Consider the cheapest price at day 1.
- Iterate the rest of the days (2, 3, 4, ...) and do the following:
a. Update the cheapest price as the min(current cheapest price, today's price).
b. Track the maximum profit for today as the max(maximum profit of the previous day, (today price - cheapest price)).
At the end of this algorithm, we will have an array (let's denote it as left[]) representing the maximum profit that can be obtained before each day (inclusive of that day). For example, until day 3 (inclusive of day 3), the maximum profit is 800 since you can buy at a price of 200 on day 1 and sell at a price of 1,000 on day 3, or until day 7 (inclusive of day 7), where the maximum profit is 870 since you can buy at a price of 30 on day 5 and sell at a price of 900 on day 7, and so on.
This array is obtained via step 2b. We can represent it for our data as follows:

Figure 10.37 – Computing the maximum profit before each day, starting from day 1
The left[] array is useful for after we've covered the second part of the algorithm. Next, the second part of the algorithm goes as follows:
- Consider the most expensive price on the last day.
- Iterate the rest of the days from (last-1) to the first day(last-1, last-2, last-3, ...) and do the following:
a. Update the most expensive price as the max(current most expensive price, today's price).
b. Track the maximum profit for today as the max(maximum profit of the next day, (most expensive price - today price)).
At the end of this algorithm, we will have an array (let's denote it as right[]) representing the maximum profit that can be obtained after each day (inclusive of that day). For example, after day 3 (inclusive of day 3), the maximum profit is 870 since you can buy at a price of 30 on day 5 and sell at a price of 900 on day 7, or after day 7 the maximum profit is 150 since you can buy at a price of 400 on day 8 and sell at a price of 550 on day 9, and so on. This array is obtained via step 2b. We can represent it for our data as follows:

Figure 10.38 – Computing the maximum profit after each day, starting from the previous day
So far, we have accomplished the divide part. Now, it's time for the conquer part. The maximum profit that can be accomplished in two transactions can be obtained as the max(left[day]+right[day]). We can see this in the following image:

Figure 10.39 – Computing the final maximum profit of transactions 1 and 2
public static int maxProfitTwoTransactions(int[] prices) {
int[] left = new int[prices.length];
int[] right = new int[prices.length];
// Dynamic Programming from left to right
left[0] = 0;
int min = prices[0];
for (int i = 1; i < prices.length; i++) {
min = Math.min(min, prices[i]);
left[i] = Math.max(left[i - 1], prices[i] - min);
}
// Dynamic Programming from right to left
right[prices.length - 1] = 0;
int max = prices[prices.length - 1];
for (int i = prices.length - 2; i >= 0; i--) {
max = Math.max(max, prices[i]);
right[i] = Math.max(right[i + 1], max - prices[i]);
}
int result = 0;
for (int i = 0; i < prices.length; i++) {
result = Math.max(result, left[i] + right[i]);
}
return result;
}
The runtime of this code is O(n). Now, let's tackle the next scenario.
Buying and selling the stock an unlimited amount of times
In this scenario, we must obtain the maximum profit by buying and selling the stock an unlimited amount of times. You can identify this statement via the following price-trend graph:
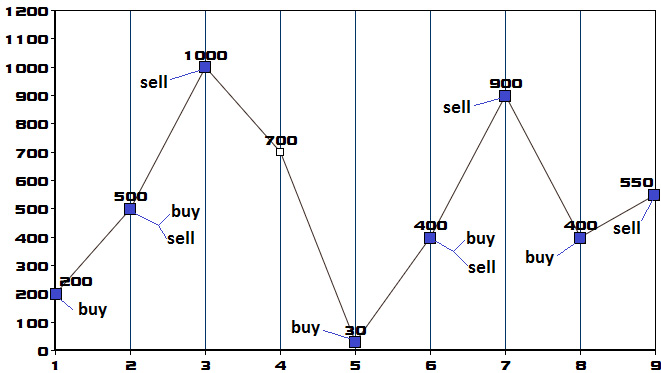
Figure 10.40 – Price-trend graph
Conforming to the preceding graphic, we should buy the stock at a price of 200 on day 1 and sell it at a price of 500 on day 2. This transaction brings in a profit of 300. Next, we should buy the stock at a price of 500 on day 2 and sell it at a price of 1000 on day 3. This transaction brings in a profit of 500. Of course, we can merge these two transactions into one by buying at a price of 200 on day 1 and selling at a price of 1000 on day 3. The same logic can be applied until day 9. The final maximum profit will be 1820. Take your time and identify all the transactions from day 1 to day 9.
By studying the preceding price-trend graphic, we can see that this problem can be viewed as an attempt to find all the ascending sequences. The following graph highlights the ascending sequences for our data:

Figure 10.41 – Ascending sequences
Finding all the ascending sequences is a simple task based on the following algorithm:
- Consider the maximum profit as 0 (no profit).
- Iterate all the days, starting from day 2, and do the following:
a. Compute the difference between the today price and the preceding day price (for example, at the first iteration, compute (the price of day 2 - the price of day 1), so 500 - 200).
b. If the computed difference is positive, then increment the maximum profit by this difference.
At the end of this algorithm, we will know the final maximum profit. If we apply this algorithm to our data, then we'll obtain the following output:
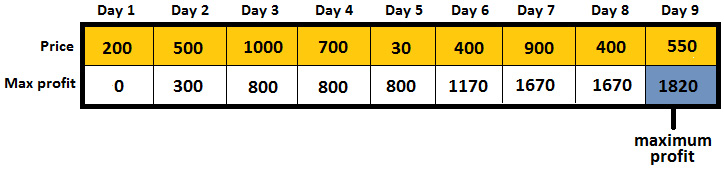
Figure 10.42 – Computing the final maximum profit
Day 1: The maximum profit is 0.
Day 2: The maximum profit is 0 + (500 - 200) = 0 + 300 = 300.
Day 3: The maximum profit is 300 + (1000 - 500) = 300 + 500 = 800.
Day 4: The maximum profit remains 800 since 700 - 1000 < 0.
Day 5: The maximum profit remains 800 since 30 - 700 < 0.
Day 6: The maximum profit is 800 + (400 - 30) = 800 + 370 = 1170.
Day 7: The maximum profit is 1170 + (900 - 400) = 1170 + 500 = 1670.
Day 8: The maximum profit remains 1670 since 400 - 900 < 0.
Day 9: The maximum profit is 1670 + (550 - 400) = 1670 + 150 = 1820.
The final maximum profit is 1820.
In terms of code, this looks as follows:
public static int maxProfitUnlimitedTransactions(
int[] prices) {
int result = 0;
for (int i = 1; i < prices.length; i++) {
int diff = prices[i] - prices[i - 1];
if (diff > 0) {
result += diff;
}
}
return result;
}
The runtime of this code is O(n). Next, let's tackle the last scenario.
Buying and selling the stock only k times (k is given)
This scenario is the generalized version of the Buying and selling the stock only twice. scenario. Mainly, by solving this scenario, we also solve the Buying and selling the stock only twice scenario for k=2.
Based on our experience from the previous scenarios, we know that solving this problem can be done via Dynamic Programming. More precisely, we need to track two arrays:
- The first array will track the maximum profit of p transactions when the last transaction is on the qth day.
- The second array will track the maximum profit of p transactions until the qth day.
If we denote the first array as temp and the second array as result, then we have the following two relations:
temp[p] = Math.max(result[p - 1]
+ Math.max(diff, 0), temp[p] + diff);
result[p] = Math.max(temp[p], result[p]);
For a better understanding, let's put these relations into the context of code:
public static int maxProfitKTransactions(
int[] prices, int k) {
int[] temp = new int[k + 1];
int[] result = new int[k + 1];
for (int q = 0; q < prices.length - 1; q++) {
int diff = prices[q + 1] - prices[q];
for (int p = k; p >= 1; p--) {
temp[p] = Math.max(result[p - 1]
+ Math.max(diff, 0), temp[p] + diff);
result[p] = Math.max(temp[p], result[p]);
}
}
return result[k];
}
The runtime of this code is O(kn). The complete application is called BestTimeToBuySellStock.
Coding challenge 22 – Longest sequence
Amazon, Adobe, Microsoft
Problem: Consider that you've been given an array of integers. Write a snippet of code that finds the longest sequence of integers. Notice that a sequence contains only consecutive distinct elements. The order of the elements in the given array is not important.
Solution: Let's consider that the given array is { 4, 2, 9, 5, 12, 6, 8}. The longest sequence contains three elements and it is formed from 4, 5, and 6. Alternatively, if the given array is {2, 0, 6, 1, 4, 3, 8}, then the longest sequence contains five elements and it is formed from 2, 0, 1, 4, and 3. Again, notice that the order of the elements in the given array is not important.
The brute-force or naive approach consists of sorting the array in ascending order and finding the longest sequence of consecutive integers. Since the array is sorted, a gap breaks a sequence. However, such an implementation will have a runtime of O(n log n).
A better approach consists of employing a hashing technique. Let's use the following image as support for our solution:
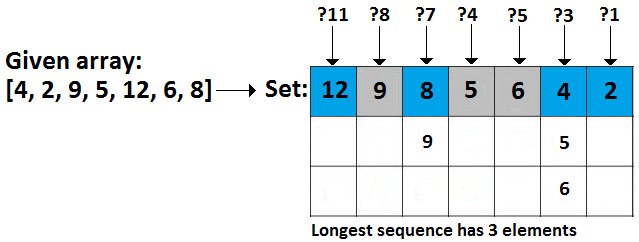
Figure 10.43 – Sequence set
First, we build a set from the given array {4, 2, 9, 5, 12, 6, 8}. As the preceding image reveals, the set doesn't maintain the order of insertion, but this is not important for us. Next, we iterate the given array and, for each traversed element (let's denote it as e), we search the set for e-1. For example, when we traverse 4, we search the set for 3, when we traverse 2, we search for 1, and so on. If e-1 is not in the set, then we can say that e represents the start of a new sequence of consecutive integers (in this case, we have sequences starting with 12, 8, 4, and 2); otherwise, it is already part of an existing sequence. When we have the start of a new sequence, we continue to search the set for the consecutive elements: e+1, e+2, e+3, and so on. As long as we find consecutive elements, we count them. If e+i (1, 2, 3, ...) cannot be found, then the current sequence is complete, and we know its length. Finally, we compare this length with the longest length we've found so far and proceed accordingly.
The code for this is quite simple:
public static int findLongestConsecutive(int[] sequence) {
// construct a set from the given sequence
Set<Integer> sequenceSet = IntStream.of(sequence)
.boxed()
.collect(Collectors.toSet());
int longestSequence = 1;
for (int elem : sequence) {
// if 'elem-1' is not in the set then // start a new sequence
if (!sequenceSet.contains(elem - 1)) {
int sequenceLength = 1;
// lookup in the set for elements
// 'elem + 1', 'elem + 2', 'elem + 3' ...
while (sequenceSet.contains(elem + sequenceLength)) {
sequenceLength++;
}
// update the longest consecutive subsequence
longestSequence = Math.max(
longestSequence, sequenceLength);
}
}
return longestSequence;
}
The runtime of this code is O(n) with an auxiliary space of O(n). Challenge yourself and print the longest sequence. The complete application is called LongestConsecutiveSequence.
Coding challenge 23 – Counting game score
Amazon, Google, Microsoft
Problem: Consider a game where a player can score 3, 5, or 10 points in a single move. Moreover, consider that you've been given a total score, n. Write a snippet of code that returns the number of ways to reach this score.
Solution: Let's consider that the given score is 33. There are seven ways to reach this score:
(10+10+10+3) = 33
(5+5+10+10+3) = 33
(5+5+5+5+10+3) = 33
(5+5+5+5+5+5+3) = 33
(3+3+3+3+3+3+3+3+3+3+3) = 33
(3+3+3+3+3+3+5+5+5) = 33
(3+3+3+3+3+3+5+10) = 33
We can solve this problem with the help of Dynamic Programming. We create a table (an array) whose size is equal to n+1. In this table, we store the counts of all scores from 0 to n. For moves 3, 5, and 10, we increment the values in the array. The code speaks for itself:
public static int count(int n) {
int[] table = new int[n + 1];
table[0] = 1;
for (int i = 3; i <= n; i++) {
table[i] += table[i - 3];
}
for (int i = 5; i <= n; i++) {
table[i] += table[i - 5];
}
for (int i = 10; i <= n; i++) {
table[i] += table[i - 10];
}
return table[n];
}
The runtime of this code is O(n) with O(n) extra space. The complete application is called CountScore3510.
Coding challenge 24 – Checking for duplicates
Amazon, Google, Adobe
Problem: Consider that you've been given an array of integers, arr. Write several solutions that return true if this array contains duplicates.
Solution: Let's assume that the given integer is arr={1, 4, 5, 4, 2, 3}, so 4 is a duplicate. The brute-force approach (or the naive approach) will rely on nested loops, as shown in the following trivial code:
public static boolean checkDuplicates(int[] arr) {
for (int i = 0; i < arr.length; i++) {
for (int j = i + 1; j < arr.length; j++) {
if (arr[i] == arr[j]) {
return true;
}
}
}
return false;
}
This code is very simple but it performs in O(n2) and O(1) auxiliary space. We can sort the array before checking for duplicates. If the array is sorted, then we can compare adjacent elements. If any adjacent elements are equal, we can say that the array contains duplicates:
public static boolean checkDuplicates(int[] arr) {
java.util.Arrays.sort(arr);
int prev = arr[0];
for (int i = 1; i < arr.length; i++) {
if (arr[i] == prev) {
return true;
}
prev = arr[i];
}
return false;
}
This code performs in O(n log n) (since we sort the array) and O(1) auxiliary space. If we want to write an implementation that performs in O(n) time, we must also consider an auxiliary O(n) space. For example, we can rely on hashing (if you are not familiar with the concept of hashing, then please read Chapter 6, Object-Oriented Programming, the Hash table problem). In Java, we can use hashing via the built-in HashSet implementation, so there is no need to write a hashing implementation from scratch. But how is this HashSet useful? While we iterate the given array, we add each element from the array to HashSet. But if the current element is already present in HashSet, this means we found a duplicate, so we can stop and return:
public static boolean checkDuplicates(int[] arr) {
Set<Integer> set = new HashSet<>();
for (int i = 0; i < arr.length; i++) {
if (set.contains(arr[i])) {
return true;
}
set.add(arr[i]);
}
return false;
}
So, this code performs in O(n) time and auxiliary O(n) space. But we can simplify the preceding code if we remember that HashSet doesn't accept duplicates. In other words, if we insert all the elements of the given array into HashSet and this array contains duplicates, then the size of HashSet will differ from the size of the array. This implementation and a Java 8-based implementation that has an O(n) runtime and an O(n) auxiliary space can be found in the code bundled with this book.
How about an implementation that has an O(n) runtime and an O(1) auxiliary space? This is possible if we take two important constraints of the given array into consideration:
- The given array doesn't contain negative elements.
- The elements lies in the range [0, n-1], where n=arr.length.
Under the umbrella of these two constraints, we can employee the following algorithm.
- We iterate over the given array and for each arr[i], we do the following:
a. If arr[abs(arr[i])] is greater than 0, then we make it negative.
b. If arr[abs(arr[i])] is equal to 0, then we make it -(arr.length-1).
c. Otherwise, we return true (there are duplicates).
Let's consider our array, arr={1, 4, 5, 4, 2, 3}, and apply the preceding algorithm:
- i=0, since arr[abs(arr[0])] = arr[1] = 4 > 0 results in arr[1] = -arr[1] = -4.
- i=1, since arr[abs(arr[1])] = arr[4] = 2 > 0 results in arr[4] = -arr[4] = -2.
- i=2, since arr[abs(arr[5])] = arr[5] = 3 > 0 results in arr[5] = -arr[5] = -3.
- i=3, since arr[abs(arr[4])] = arr[4] = -2 < 0 returns true (we found a duplicate)
Now, let's look at arr={1, 4, 5, 3, 0, 2, 0}:
- i=0, since arr[abs(arr[0])] = arr[1] = 4 > 0 results in arr[1] = -arr[1] = -4.
- i=1, since arr[abs(arr[1])] = arr[4] = 0 = 0 results in arr[4] = -(arr.length-1) = -6.
- i=2, since arr[abs(arr[2])] = arr[5] = 2 > 0 results in arr[5] = -arr[5] = -2.
- i=3, since arr[abs(arr[3])] = arr[3] = 3 > 0 results in arr[3] = -arr[3] = -3.
- i=4, since arr[abs(arr[4])] = arr[6] = 0 = 0 results in arr[6] = -(arr.length-1) = -6.
- i=5, since arr[abs(arr[5])] = arr[2] = 5 > 0 results in arr[2] = -arr[2] = -5.
- i=6, since arr[abs(arr[6])] = arr[6] = -6 < 0 returns true (we found a duplicate).
Let's put this algorithm into code:
public static boolean checkDuplicates(int[] arr) {
for (int i = 0; i < arr.length; i++) {
if (arr[Math.abs(arr[i])] > 0) {
arr[Math.abs(arr[i])] = -arr[Math.abs(arr[i])];
} else if (arr[Math.abs(arr[i])] == 0) {
arr[Math.abs(arr[i])] = -(arr.length-1);
} else {
return true;
}
}
return false;
}
The complete application is called DuplicatesInArray.
For the following five coding challenges, you can find the solutions in the code bundled with this book. Take your time and challenge yourself to come up with a solution before checking the bundled code.
Coding challenge 25 – Longest distinct substring
Problem: Consider you've been given a string, str. The accepted characters of str belong to the extended ASCII table (256 characters). Write a snippet of code that finds the longest substring of str containing distinct characters.
Solution: As a hint, use the sliding window technique. If you are not familiar with this technique, then consider reading Sliding Window Technique by Zengrui Wang (https://medium.com/@zengruiwang/sliding-window-technique-360d840d5740) before continuing. The complete application is called LongestDistinctSubstring. You can visit the following link to check the code: https://github.com/PacktPublishing/The-Complete-Coding-Interview-Guide-in-Java/tree/master/Chapter10/LongestDistinctSubstring
Coding challenge 26 – Replacing elements with ranks
Problem: Consider you've been given an array without duplicates, m. Write a snippet of code that replaces each element of this array with the element's rank. The minimum element in the array has a rank of 1, the second minimum has a rank of 2, and so on.
Solution: As a hint, you can use a TreeMap. The complete application is called ReplaceElementWithRank. You can visit the following link to check the code: https://github.com/PacktPublishing/The-Complete-Coding-Interview-Guide-in-Java/tree/master/Chapter10/ReplaceElementWithRank
Coding challenge 27 – Distinct elements in every sub-array
Problem: Consider you've been given an array, m, and an integer, n. Write a snippet of code that counts the number of distinct elements in every sub-array of size n.
Solution: As a hint, use a HashMap to store the frequency of the elements in the current window whose size is n. The complete application is called CountDistinctInSubarray. You can visit the following link to check the code: https://github.com/PacktPublishing/The-Complete-Coding-Interview-Guide-in-Java/tree/master/Chapter10/CountDistinctInSubarray
Coding challenge 28 – Rotating the array k times
Problem: Consider you've been given an array, m, and an integer, k. Write a snippet of code that rotates the array to the right k times (for example, array {1, 2, 3, 4, 5}, when rotated three times, results in {3, 4, 5, 1, 2}).
Solution: As a hint, rely on the modulo (%) operator. The complete application is called RotateArrayKTimes. You can visit the following link to check the code: https://github.com/PacktPublishing/The-Complete-Coding-Interview-Guide-in-Java/tree/master/Chapter10/RotateArrayKTimes.
Coding challenge 29 – Distinct absolute values in sorted arrays
Problem: Consider you've been given a sorted array of integers, m. Write a snippet of code that counts the distinct absolute values (for example, -1 and 1 are considered a single value).
Solution: As a hint, use the sliding window technique. If you are not familiar with this technique, then consider reading Sliding Window Technique by Zengrui Wang (https://medium.com/@zengruiwang/sliding-window-technique-360d840d5740) before continuing. The complete application is called CountDistinctAbsoluteSortedArray. You can visit the following link to check the code: https://github.com/PacktPublishing/The-Complete-Coding-Interview-Guide-in-Java/tree/master/Chapter10/CountDistinctAbsoluteSortedArray
Summary
The goal of this chapter was to help you master various coding challenges involving strings and/or arrays. Hopefully, the coding challenges in this chapter have provided various techniques and skills that will be very useful in tons of coding challenges that fall under this category. Don't forget that you can enrich your skills even more via the book Java Coding Problems (https://www.amazon.com/gp/product/1789801419/), which is published by Packt as well. Java Coding Problems comes with 35+ strings and arrays problems that were not tackled in this book.
In the next chapter, we will discuss linked lists and maps.