
Distributed Objects and the Enterprise
A decade or so ago, the term enterprise computing became a major part of the information technology lexicon. Today, much of the major development in the area of IT technology is that of enterprise computing. But what does enterprise computing mean?
Perhaps the most basic definition of enterprise computing is that it’s essentially distributed computing. Distributed computing is just what the name implies, a distributed group of computers working together over a network. In this context, a network can be a proprietary network or the Internet.
The power of distributed computing is that computers can share the work. In a truly distributed environment, you do not even need to know what computer is actually servicing your request—in fact, it might be better that you don’t know. For example, when you shop online, you connect to a company’s web site. All you know is that you are connecting using a URL. However, the company will connect you to whatever physical machine is available.
Why is this desirable? Suppose that a company has a single machine to service all the requests. Then consider what would happen if the machine crashes. Now let’s suppose that the company can distribute the online activities over a dozen machines. If one of the machines goes down, the impact will not be as devastating.
Also consider the situation when you download files from a web site. You probably have encountered the situation in which the download site provides you with links to a number of sites, and then asks you to choose the site closest to you. This is a means of distributing the load over the network. Computer networks can balance the load themselves. Figure 13.7 provides a diagram of how a distributed system might look.
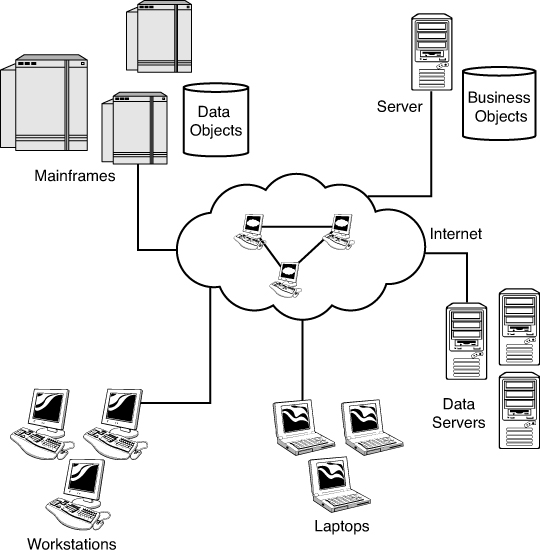
Figure 13.7. Distributed computing.
This book is focused on objects and object-oriented concepts. So in many ways, the entities we are interested in are called distributed objects. That objects are totally self-contained makes them perfect for distributed applications. The thrust of this chapter is this: If an application (client) requires the service of some object (server), that web service can reside anywhere on the network and doesn’t really care what is consuming it. Let’s explore some of the technologies (past and present) that exist for distributed objects.
Remember that many of these technologies are not necessarily considered state-of-the-art but are still in play as legacy systems. For example, CORBA is not nearly as common as it was when the first edition of this book was written in the late 1990s. A shopping cart is now much more likely to be implemented via some sort of web services or maintained directly in the native format of the website rather than use a CORBA interface. SOAP and XML and the SOA architecture are far more common today; however, a bit of a historical background can be highly instructive to understand how the technologies have evolved.
The Common Object Request Broker Architecture (CORBA)
One of the primary tenets of this book is that objects are totally self-contained units. With this in mind, it doesn’t take much imagination to consider sending objects over a network. In fact, we have used objects traveling over a network in many of the examples throughout this book.
The entire premise of the enterprise is built on the concept of distributed objects. Many advantages exist to using distributed objects; perhaps the most interesting is that a system can theoretically invoke objects anywhere on the network. This is a powerful capability and is the backbone for much of today’s Internet-based business. Another major advantage is that various pieces of a system can be distributed across multiple machines across a network.
The idea of accessing and invoking objects across a network is a powerful technique. However, there is one obvious fly in the ointment—the recurring problem of portability. Although we can create a proprietary distributed network, the fact that it is proprietary leads to obvious limitations. The other problem is that of programming language. Suppose a system written in Java would like to invoke an object written in C++. In the best of all worlds, we would like to create a nonproprietary, language-independent framework for objects in a distributed environment. This is where CORBA made a major contribution to the development community as the Internet was first becoming a major force in the marketplace in the mid 1990s.
The main premise of CORBA is this: Using a standard protocol, CORBA allows programs from different vendors to communicate with each other. This interoperability covers hardware and software. Thus, vendors can write applications on various hardware platforms and operating systems using a variety of programming languages, operating over different vendor networks.
CORBA, and similar technologies like DCOM, can be considered the middleware for a variety of computer software applications. Whereas CORBA represents only one type of middleware (later we will see some other implementations, like Java’s RMI), the concepts behind middleware are consistent, regardless of the approach taken. Basically, middleware provides services that allow application processes to interact with each other over a network. These systems are often referred to as multi-tiered systems. For example, a three-tiered system is presented in Figure 13.8. In this case, the presentation layer is separated from the data layer by the allocation layer in the middle (middleware is often associated with object-relational mapping systems). These processes can be running on one or more machines. This is where the term distributed comes into play. The processes (or as far as this book is concerned, the objects) are distributed across a network. This network can be proprietary, or it might be the Internet.
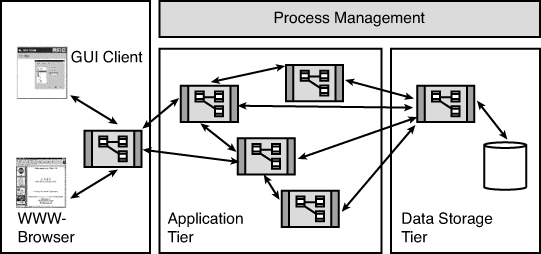
Figure 13.8. A three-tiered system.
This is where objects fit into the picture. The OMG states: “CORBA applications are composed of objects.” So, as you can tell, objects are a major part of the world of distributed computing. The OMG goes on to say that these objects “are individual units of running software that combine functionality and data, and that frequently (but not always) represent something in the real world.”
One of the most obvious examples of such a system is that of a shopping cart. We can relate this shopping cart example to our earlier discussions on the instantiation of objects. When you visit an e-commerce site to purchase merchandise, you are assigned your own individual shopping cart. Thus, each customer has a unique shopping cart. In this case, each customer will have an object, which includes all the attributes and behaviors of a shopping cart object.
Although each customer object has the same attributes and behaviors, each customer will have different attribute assignments, such as name, address, and so on. This shopping cart object can then be sent anywhere across the network. Other objects in the system represent merchandise, warehouses, and so on.
One of the benefits of using CORBA to implement a system such as our shopping cart application is that the objects can be accessed by services written in different languages. To accomplish this task, CORBA defines an interface to which all languages must conform. The CORBA concept of an interface fits in well with the discussion we had about creating contracts in Chapter 8, “Frameworks and Reuse: Designing with Interfaces and Abstract Classes.” The CORBA interface is called the Interface Definition Language (IDL). For CORBA to work, both sides of the wire, the client and server, must adhere to the contract as stated in the IDL.
Yet another term we covered earlier in the book is used in this discussion—marshaling. Remember that marshaling is the act of taking an object, decomposing it into a format that can be sent over a network, and then reconstituting it at the other end. Thus, by having both the client and the server conform to the IDL, an object can be marshaled across a network regardless of the programming language used.
All the objects that move around in a CORBA system are routed by an application called an Object Request Broker (ORB). You might have already noticed that the acronym ORB is actually part of the acronym CORBA. The ORB is what makes everything go in a CORBA application. The ORB takes care of routing requests from clients to objects, as well as getting the response back to the appropriate destination.
Again, we can see how CORBA and distributed computing works hand-in-hand with the concepts we have studied throughout this book. The OMG states that
This separation of interface from implementation, enabled by OMG IDL, is the essence of CORBA.
Furthermore,
Clients access objects only through their advertised interface, invoking only those operations that the object exposes through its IDL interface, with only those parameters (input and output) that are included in the invocation.
To get a flavor of what the IDL looks like, consider the e-business example we used in Chapter 8. In this case, let’s revisit the UML diagram of Figure 8.7 and create a subset of the Shop class. If we decide to create an interface of Inventory, we could create something like the following:
interface Inventory {
string[] getInventory ();
string[] buyInventory (in string product);
}
In this case, we have an interface that defines how to list and purchase inventory. This interface is then compiled into two entities:
• Stubs that act as the connection between the client and the ORB
• A skeleton that acts as the connection between the ORB and the object
These IDL stubs and skeletons form the contract that all interacting parties must follow. Figure 13.9 shows an illustration of how the various CORBA parts interact.
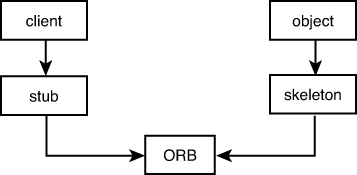
Figure 13.9. CORBA parts.
The really interesting thing about all this is that when a client wants the service of some object, it does not need to know anything about the object it is requesting, including where it resides. The client simply invokes the object (and the service) it wants. To the client, it appears that this invocation is local, as though it’s invoking an object that’s on the local system. This invocation is passed through the ORB. If the ORB determines that the desired object is a remote object, the ORB routes the request. If everything works properly, the client will not know where the actual object servicing it resides. Figure 13.10 shows how the ORB routing works over a network.
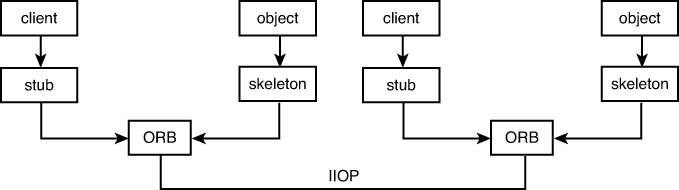
Figure 13.10. ORB routing.
In this section, we have covered some of the original, and fundamental, topics of distributed computing as developed by pioneering technologies such as CORBA, DCOM, and RMI. In the next sections, we continue the discussion with more recent implementations—web services such as SOAP and XML and the SOA architecture are far more common today.
Web Services Definition
Web services have evolved quickly over the past several years. In fact, when the first edition of this book was published, much of the current technology was in its infancy. At this point in time, we will use the W3C general definition of a web service as a “client and a server that communicate using XML messages using the SOAP (Simple Object Access Protocol) standard.”
SOAP is a communication protocol used for sending messages over the Internet. SOAP is theoretically platform and language independent and is based on XML. SOAP communicates between applications using the HTTP protocol, because it is common for user client applications to utilize browsers. SOAP extends the functionality of HTTP to provide more functional web services.
Since early on in the evolution of distributed computing, remote procedure calls (RPC) have been a part of the equation. The primary motivation for SOAP is to perform remote procedure calls over HTTP using XML. With all these brief descriptions out of the way, we can describe SOAP in a nutshell: SOAP is XML-based and is a protocol for distributed applications.
The major drawback with technologies such as CORBA and DCOM is that they are basically proprietary and have their own binary formats. SOAP is text-based, being written in XML, and is considered much simpler to use when compared to CORBA and DCOM. This is similar to the advantages outlined in the section “Using XML in the Serialization Process” of Chapter 12, “Persistent Objects: Serialization, Marshaling, and Relational Databases.”
In effect, to work as seamlessly as possible, CORBA and DCOM systems must communicate with similar systems. This is a significant limitation in the current technological environment, because you don’t really know what is on the other side of the wire. Therefore, perhaps the biggest advantage that SOAP has going for it is that it has most of the major software companies on board with its standard.
As described over and over in this book, one of the major advantages of object technology is that of wrappers. SOAP can be thought of as a wrapper that, although not an exact replacement for technologies like DCOM, Enterprise JavaBeans, or CORBA, it does “wrap” them for more efficient use over the Internet. This “wrapping” capability allows companies to standardize their own network communications, even though there may be disparate technologies within the company itself.
Whatever the description of SOAP, it is important to note that, as basic HTML, SOAP is a stateless, one-way messaging system. Because of this and other features, SOAP is not a total replacement for technologies like DCOM, Enterprise JavaBeans, CORBA, or RMI—it is a complementary technology.
In keeping with the theme of this book, the following SOAP example focuses on object concepts and not any specific SOAP technology, coding or otherwise.
For this example, let’s create a Warehouse application. This application utilizes a browser as the client, which then uses a set of web services to transact business with a Warehouse system that resides somewhere on the network.
We use the following model for our SOAP example. Figure 13.11 provides a visual diagram of the system.
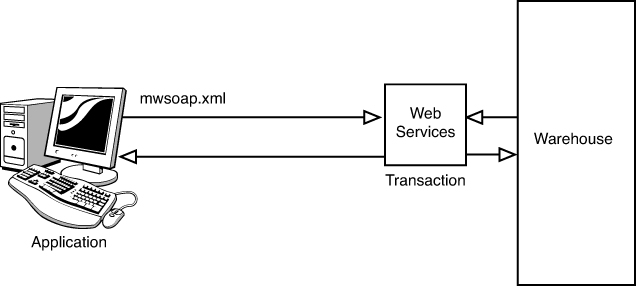
Figure 13.11. SOAP example.
The file mwsoap.xml is the XML description of the structure of the various transactions handled by the web services. This description of Invoice.xsd is shown in the following code:
<?xml version="1.0" encoding="utf-8"?>
<xs:schema targetNamespace="http://ootp.org/invoice.xsd"
elementFormDefault="qualified" xmlns="http://ootp.org/invoice.xsd"
xmlns:mstns="http://ootp.org/invoice.xsd" xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="Invoice">
<xs:complexType>
<xs:sequence>
<xs:element name="Address" minOccurs="1">
<xs:complexType>
<xs:sequence />
<xs:attribute name="Street" type="xs:string" />
<xs:attribute name="City" type="xs:string" />
<xs:attribute name="State" type="xs:string" />
<xs:attribute name="Zip" type="xs:int" />
<xs:attribute name="Country" type="xs:string" />
</xs:complexType>
</xs:element>
<xs:element name="Package">
<xs:complexType>
<xs:sequence />
<xs:attribute name="Description" type="xs:string" />
<xs:attribute name="Weight" type="xs:short" />
<xs:attribute name="Priority" type="xs:boolean" />
<xs:attribute name="Insured" type="xs:boolean" />
</xs:complexType>
</xs:element>
</xs:sequence>
<xs:attribute name="name" type="xs:string" />
</xs:complexType>
</xs:element>
</xs:schema>
The Invoice.xsd file describes how an invoice is structured and how applications must conform to its definitions. This file is, in effect, a schema in the same way that a schema is used in a database system. Note that, per this Invoice.xsd file, an invoice is composed of an Address and Package. Further, the Address and Package are built of attributes such as Description, Weight, and so on. Finally, these attributes are declared as specific data types, such as string, short, and so on. Figure 13.12 shows graphically what this relationship looks like.
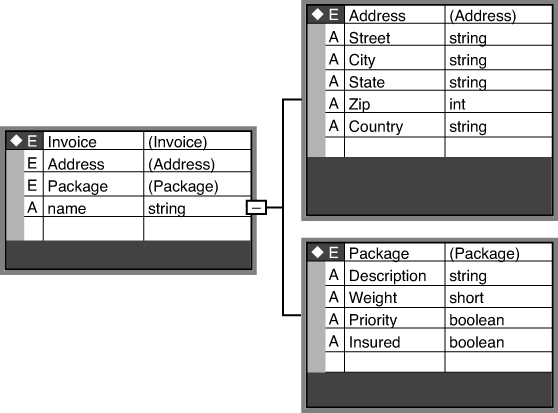
Figure 13.12. Invoice.xsx (visual representation of schema).
In this example, whereas the Invoice.xsd file describes how the data is structured, the mwsoap.xml file represents what the data is. An application, written in a language like C# .NET, VB .NET, ASP.NET, or Java, uses the Invoice.xsd file to construct valid XML files that are then sent to other applications over the network. These applications would use the same Invoice.xsd file to deconstruct the mwsoap.xml file for its use. In many ways, you can think of the Invoice.xsd file as a sort of contract, in a similar way to the concept of a contract covered in Chapter 8.
The following is the mwsoap.xml file that contains specific data embedded in its SOAP/XML format:
<?xml version="1.0" encoding="utf-8"?>
<soap:envelope xmlns:soap="http://www.w3.org/2001/06/soap-envelope">
<soap:Header>
<mySOAPHeader:transaction xmlns:mySOAPHeader="soap-transaction"
soap:mustUnderstand="true">
<headerId>8675309</headerId>
</mySOAPHeader:transaction>
</soap:Header>
<soap:Body>
<mySOAPBody xmlns="http://ootp.org/Invoice.xsd">
<invoice name="Jenny Smith">
<address street="475 Oak Lane"
city="Somewheresville"
state="Nebraska"
zip="23654"
country="USA"/>
<package description="22 inch Plasma Monitor"
weight="22"
priority="false"
insured="true" />
</invoice>
</mySOAPBody>
</soap:Body>
</soap:envelope>
Web Services Code
The only piece of the model left to cover is the code applications themselves. The three classes that correspond to the Invoice, Address, and Package are presented in the following in C# .NET.
It is important to note that the applications can be of any language. This is the beauty of the SOAP/XML approach. Each application must be able to parse the XML file—and that is basically the only requirement, as shown in Figure 13.13. How an application uses the data extracted is totally up to the application.
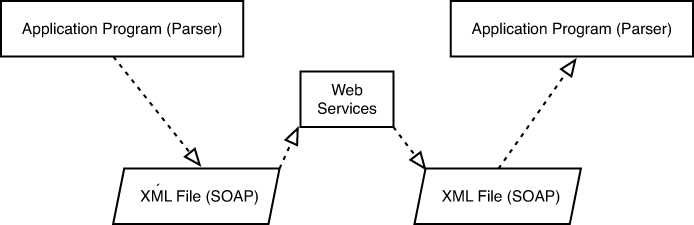
Figure 13.13. Parsing the SOAP/XML file.
As a result of this approach, the specific language, or platform for that matter, is irrelevant. Theoretically, any language can perform a parsing operation, and that is basically what is needed in this SOAP/XML approach.
As developers, it is helpful to take a look at the code directly. In the following sections, the C# .NET code is presented to help illustrate how the system described in Figure 13.12 is implemented. The corresponding VB .NET code is available electronically from the publisher’s web site.
Invoice.cs
The following code is the C# .NET implementation of the Invoice class that is represented in Figure 13.12:
using System;
using System.Data;
using System.Configuration;
using System.Xml;
using System.Xml.Serialization;
namespace WebServices
{
[XmlRoot("invoice")]
public class Invoice
{
public Invoice(String name, Address address, ShippingPackage package)
{
this.Name = name;
this.Address = address;
this.Package = package;
}
private String strName;
[XmlAttribute("name")]
public String Name
{
get { return strName; }
set { strName = value; }
}
private Address objAddress;
[XmlElement("address")]
public Address Address
{
get { return objAddress; }
set { objAddress = value; }
}
private ShippingPackage objPackage;
[XmlElement("package")]
public ShippingPackage Package
{
get { return objPackage; }
set { objPackage = value; }
}
}
}
Representational State Transfer (ReST)
Since the days of the first computer program, developers have constantly walked a fine line between complex and simple architectures. It is the nature of developers to want simply, direct approaches, whereas many business managers prefer structured, more established practices. We can see this is the use of programming languages like Java and .NET versus languages such as Perl and PHP, between XML and JSON, and so on. Web services are also a part of this discussion. Many developers consider technologies such as CORBA, RPC, and SOAP to be fairly complex. Thus, a more “simple: approach, called Representational State Transfer, or ReST, is becoming quite popular.
For example, a SOAP implementation may require various tools (and even have trouble communicating with previous SOAP standards), whereas ReST requires only HTTP support and can function with various technologies, including SOAP.
ReST is a stateless protocol that basically relies on HTTP. Because HTTP is the foundation of the Internet itself, in many ways it can be said that the Internet’s architecture is based on ReST, often called RESTful architectures.
The fundamental feature of ReST is that it uses HTTP requests to create, update, read, and delete data. As a result, ReST can be utilized in place of other technologies, such as RPC, or web services, like SOAP, because it provides all the necessary underlying functionality. In short, ReST is a lightweight approach to web services; however, it is not in any way a standard in the way that XML is (one description of ReST calls it a “style”). Figure 13.14 illustrates the flow of data that is typical of the HTTP requests/responses in a RESTful implementation.
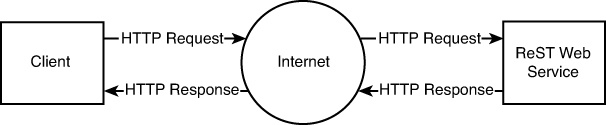
Figure 13.14. RESTful web services.
In fact, although other strategies, such as SOAP, may be considered to be more sophisticated in what they may deliver, a RESTful application will pretty much return either simple text or an XML file. What is delivered is up to the developer. Whereas SOAP is intimately tied to XML, ReST is not. Likewise, ReST requests are primarily simple text parameters and rarely deliver anything more complex. Another point of interest regarding ReST is that it is not inherently object-oriented because it does not really deliver objects, even though objects can be created by parsers by an application.