
Knowing the Difference Between the Interface and the Implementation
As we saw in Chapter 1, one of the keys to building a strong OO design is to understand the difference between the interface and the implementation. Thus, when designing a class, what the user needs to know and what the user does not need to know are of vital importance. The data hiding mechanism inherent with encapsulation is the means by which nonessential data is hidden from the user.
Caution
Do not confuse the concept of the interface with terms like graphical user interface (GUI). Although a GUI is, as its name implies, an interface, the term interfaces, as used here, is more general in nature and is not restricted to a graphical interface.
Remember the toaster example in Chapter 1? The toaster, or any appliance for that matter, is plugged into the interface, which is the electrical outlet—see Figure 2.1. All appliances gain access to the required electricity by complying with the correct interface: the electrical outlet. The toaster doesn’t need to know anything about the implementation or how the electricity is produced. For all the toaster cares, a coal plant or a nuclear plant could produce the electricity—the appliance does not care which, as long as the interface works as specified, correctly and safely.
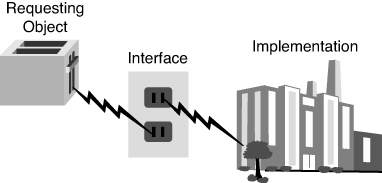
Figure 2.1. Power plant revisited.
As another example, consider an automobile. The interface between you and the car includes components such as the steering wheel, gas pedal, brake, and ignition switch. For most people, aesthetic issues aside, the main concern when driving a car is that the car starts, accelerates, stops, steers, and so on. The implementation, basically the stuff that you don’t see, is of little concern to the average driver. In fact, most people would not even be able to identify certain components, such as the catalytic converter and gasket. However, any driver would recognize and know how to use the steering wheel because this is a common interface. By installing a standard steering wheel in the car, manufacturers are assured that the people in their target market will be able to use the system.
If, however, a manufacturer decided to install a joystick in place of the steering wheel, most drivers would balk at this, and the automobile might not be a big seller (except for some eclectic people who love bucking the trends). On the other hand, as long as the performance and aesthetics didn’t change, the average driver would not notice if the manufacturer changed the engine (part of the implementation) of the automobile.
It must be stressed that the interchangeable engines must be identical in every way—as far as the interface goes. Replacing a four-cylinder engine with an eight-cylinder engine would change the rules and likely would not work with other components that interface with the engine, just as changing the current from AC to DC would affect the rules in the power plant example.
The engine is part of the implementation, and the steering wheel is part of the interface. A change in the implementation should have no impact on the driver, whereas a change to the interface might. The driver would notice an aesthetic change to the steering wheel, even if it performs in a similar manner. It must be stressed that a change to the engine that is noticeable by the driver breaks this rule. For example, a change that would result in noticeable loss of power is actually changing the interface.
Properly constructed classes are designed in two parts—the interface and the implementation.
The Interface
The services presented to an end user compose the interface. In the best case, only the services the end user needs are presented. Of course, which services the user needs might be a matter of opinion. If you put 10 people in a room and ask each of them to do an independent design, you might receive 10 totally different designs—and there is nothing wrong with that. However, as a general rule, the interface to a class should contain only what the user needs to know. In the toaster example, the user needs to know only that the toaster must be plugged into the interface (which in this case is the electrical outlet) and how to operate the toaster itself.
The Implementation
The implementation details are hidden from the user. One goal regarding the implementation should be kept in mind: A change to the implementation should not require a change to the user’s code. This might seem a bit confusing, but this goal is at the heart of the design issue. If the interface is designed properly, a change to the implementation should not require a change to the user’s code. Remember that the interface includes the syntax to call a method and return a value. If this interface does not change, the user does not care whether the implementation is changed. As long as the programmer can use the same syntax and retrieve the same value, that’s all that matters.
We see this all the time when using a cell phone. To make a call, the interface is simple—we either dial a number or select an entry in the address book. Yet, if the provider updates the software, it doesn’t change the way you make a call. The interface stays the same regardless of how the implementation changes. However, I can think of one situation when the provider did change the interface—when my area code changed. Fundamental interface changes, like an area code change, do require the users to change behavior. Businesses try to keep these types of changes to a minimum, for some customers will not like the change or perhaps not put up with the hassle.
Recall that in the toaster example, although the interface is always the electric outlet, the implementation could change from a coal power plant to a nuclear power plant without affecting the toaster. One very important caveat should be made here: The coal or nuclear plant must also conform to the interface specification. If the coal plant produces AC power, but the nuclear plant produces DC power, a problem exists. The bottom line is that both the user and the implementation must conform to the interface specification.
An Interface/Implementation Example
Let’s create a simple (if not very functional) database reader class. We’ll write some Java code that will retrieve records from the database. As we’ve discussed, knowing your end users is always the most important issue when doing any kind of design. You should do some analysis of the situation and conduct interviews with end users, and then list the requirements for the project. The following are some requirements we might want to use for the database reader:
• We must be able to open a connection to the database.
• We must be able to close the connection to the database.
• We must be able to position the cursor on the first record in the database.
• We must be able to position the cursor on the last record in the database.
• We must be able to find the number of records in the database.
• We must be able to determine whether there are more records in the database (that is, if we are at the end).
• We must be able to position the cursor at a specific record by supplying the key.
• We must be able to retrieve a record by supplying a key.
• We must be able to get the next record, based on the position of the cursor.
With these requirements in mind, we can make an initial attempt to design the database reader class by creating possible interfaces for these end users.
In this case, the database reader class is intended for programmers who require use of a database. Thus, the interface is essentially the application-programming interface (API) that the programmer will use. These methods are, in effect, wrappers that enclose the functionality provided by the database system. Why would we do this? We explore this question in much greater detail later in the chapter; the short answer is that we might need to customize some database functionality. For example, we might need to process the objects so that we can write them to a relational database. Writing this middleware is not trivial as far as design and coding go, but it is a real-life example of wrapping functionality. More important, we may want to change the database engine itself without having to change the code.
Figure 2.2 shows a class diagram representing a possible interface to the DataBaseReader class.

Figure 2.2. A Unified Modeling Language class diagram for the DataBaseReader class.
Note that the methods in this class are all public (remember that there are plus signs next to the names of methods that are public interfaces). Also note that only the interface is represented; the implementation is not shown. Take a minute to determine whether this class diagram generally satisfies the requirements outlined earlier for the project. If you find out later that the diagram does not meet all the requirements, that’s okay; remember that OO design is an iterative process, so you do not have to get it exactly right the first time.
For each of the requirements we listed, we need a corresponding method that provides the functionality we want. Now you need to ask a few questions:
• To effectively use this class, do you, as a programmer, need to know anything else about it?
• Do you need to know how the internal database code opens the database?
• Do you need to know how the internal database code physically positions itself over a specific record?
• Do you need to know how the internal database code determines whether any more records are left?
On all counts, the answer is a resounding no! You don’t need to know any of this information. All you care about is that you get the proper return values and that the operations are performed correctly. In fact, the application programmer will most likely be at least one more abstract level away from the implementation. The application will use your classes to open the database, which in turn will invoke the proper database API.
Creating wrappers might seem like overkill, but there are many advantages to writing them. To illustrate, there are many middleware products on the market today. Consider the problem of mapping objects to a relational database. Some OO databases may be perfect for OO applications. However, one small problem exists: Most companies have years of data in legacy relational database systems. How can a company embrace OO technologies and stay on the cutting edge while retaining its data in a relational database?
First, you can convert all your legacy, relational data to a brand-new OO database. However, anyone who has suffered the acute (and chronic) pain of any data conversion knows that this is to be avoided at all costs. Although these conversions can take large amounts of time and effort, all too often they never work properly.
Second, you can use a middleware product to seamlessly map the objects in your application code to a relational model. This is a much better solution as long as relational databases are so prevalent. Some might argue that OO databases are much more efficient for object persistence than relational databases. In fact, many development systems seamlessly provide this service.
However, in the current business environment, relational-to-object mapping is a great solution. Many companies have integrated these technologies. It is common for a company to have a website front-end interface with data on a mainframe.
If you create a totally OO system, an OO database might be a viable (and better performing) option; however, OO databases have not experienced anywhere near the growth that OO languages have.
Let’s return to the database example. Figure 2.2 shows the public interface to the class, and nothing else. When this class is complete, it will probably contain more methods, and it will certainly contain attributes. However, as a programmer using this class, you do not need to know anything about these private methods and attributes. You certainly don’t need to know what the code looks like within the public methods. You simply need to know how to interact with the interfaces.
What would the code for this public interface look like (assume that we start with a Oracle database example)? Let’s look at the open() method:
public void open(String Name){
/* Some application-specific processing */
/* call the Oracle API to open the database */
/* Some more application-specific processing */
};
In this case, you, wearing your programmer’s hat, realize that the open method requires String as a parameter. Name, which represents a database file, is passed in, but it’s not important to explain how Name is mapped to a specific database for this example. That’s all we need to know. Now comes the fun stuff—what really makes interfaces so great!
Just to annoy our users, let’s change the database implementation. Last night we translated all the data from an Oracle database to an SQLAnywhere database (we endured the acute and chronic pain). It took us hours—but we did it.
Now the code looks like this:
public void open(String Name){
/* Some application-specific processing
/* call the SQLAnywhere API to open the database */
/* Some more application-specific processing */
};
To our great chagrin, this morning not one user complained. This is because even though the implementation changed, the interface did not! As far as the user is concerned, the calls are still the same. The code change for the implementation might have required quite a bit of work (and the module with the one-line code change would have to be rebuilt), but not one line of application code that uses this DataBaseReader class needed to change.
By separating the user interface from the implementation, we can save a lot of headaches down the road. In Figure 2.3, the database implementations are transparent to the end users, who see only the interface.
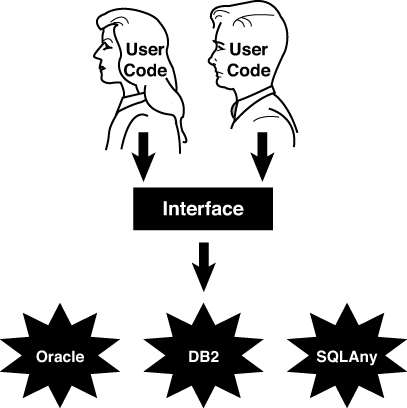
Figure 2.3. The interface.