
There are many terms thrown around when one is discussing RDBMSs. The good news is that you don’t need to know all of them to properly back up and recover databases. You do need to know some of them, though—about 20 individual terms. It’s helpful to know:
What all the different storage elements are and what they are called
How these elements are logically organized within the RDBMS
What facilities are in place to protect and back up the data
This information can be complex, because it depends a lot on how you look at the data. This chapter presents this information from first a power user’s, then a DBA’s, point of view. The various building blocks of a database are defined, although we may have to go up and down the building a bit before we’re done!
Before looking at how databases are stored on disk, let’s look at the “user’s” view of a database. This is necessary since some of these terms are used in the definition of the storage elements. It might be more appropriate to call this a "power user’s view,” since many users will have little or no knowledge of any of these terms. But unless they want to start doing the DBA’s job of putting a database together, these terms may be all that they would ever need. The terms are presented in no particular order, since it is very difficult to define one term without using another one. Therefore, it may help some readers to read this section more than once.
This view also could be called the “logical” view, since many of the elements described in this view don’t exist in a physical sense. That fact is one of the many things that differentiate an RDBMS from a simple spreadsheet. A spreadsheet has one table that resides in one physical file. An RDBMS table, on the other hand, gives the appearance that its data is all sitting in one place, but it may be spread out all over the system.
Instance is probably the most difficult term to explain because it means different things to different people—and to different database platforms. The simplest definition is that an instance is a process (or set of processes) on one machine, through which the databases on that machine[55] communicate with shared memory. There often can be multiple databases within an instance, and a database also can be distributed across multiple instances on the same machine or on separate machines within a cluster. (In order to distribute a database across multiple instances, you must use a parallel database product such as Informix Extended Parallel Option (XPO) or Oracle’s Cluster Server (OCS).) Therefore, an instance and a database are two entirely different concepts.
The Sybase term “server” stems from the original intent that each machine/server would have one Sybase instance/server on it, although it is now quite common to have more than one instance on each machine. Informix occasionally uses the term in this manner, and it can be rather confusing. They tend to use server when speaking about the software and instance when speaking about a running engine environment and especially when discussing running multiple instantiations of the server.
If an instance needs to be shut down and restarted for any reason, all databases within that instance are unavailable during the shutdown.[56] Perhaps this helps to understand the original definition, since all of the databases within an instance have a single connection to shared memory, which is provided by the instance. If the instance is shut down, that connection is no longer available. (See Figure 13-1 for a graphical representation of an instance.)
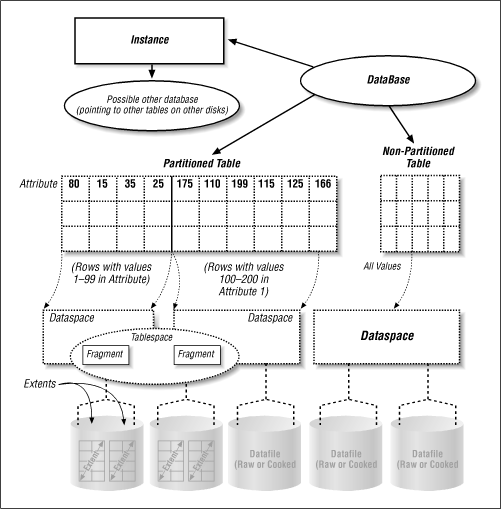
A database is a collection of database objects. It may be a very simple database with one table and no indexes, or it could contain many tables, indexes, and other database objects. (All database products have the ability to have more than one database object and more than one type of database object.) For example, the “customer” database may contain a table that has customer addresses and an index for that table. It also may contain a Binary Large OBject (BLOB) table that contains a scanned-in image of the customer’s contract, a regular table that contains the data from that contract, and an index for that table. Then there might be another database that keeps track of all the widgets that your company sells. (See Figure 13-2 for a graphical representation of a database.)

One element of database architecture that is slightly related to the database is the schema. Although the parallel is not exactly the same, comparing a database to a Unix box may help to explain the difference between a database and a schema. If you think of the database as a Unix server and database objects as filesystems, the schema could be the password file and set of Unix permissions that grant a user access to that machine and to the various filesystems and files within that machine. Some database products allow multiple schemas per databases; others do not.[57]
A table is a grouping of related information. (That is why it is called a relation in formal database terminology.) Information is grouped in such a way that data is not replicated between tables except when necessary. In the previous example, the customer database could contain the “customer information” table, and each customer is given a unique account number. Then the BLOB table that stores the customer’s signed contract would need to store only the customer’s account number to be able to tie the two pieces of information together. (BLOB data is discussed later in this chapter.) That method takes up less space than storing the customer’s whole name with the contract. The order table would contain that account number as well, and it might list what a customer ordered only by part number. If you wanted to see the details about that part number, the instance could reference the “parts” database using that part number. (See Figure 13-2 and Figure 13-3 for graphical representations of a table.)
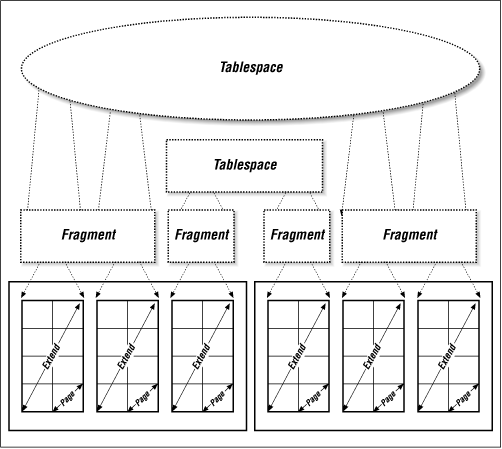
A related term is a view , which usually refers to a virtual table. For example, you may put together a view that references the customer, order, and parts tables to present a united view of information about a given customer. Data often is replicated in a virtual view, but since it’s a virtual table, it doesn’t take up extra storage space on the disk; A view normally is constructed on the fly from the results of a SELECT statement.
An index is a special-purpose table that allows for quicker lookups of a normal table. A table is indexed by the value that you usually would use to look up a record (row). For example, the customer database might be indexed by last name if customers frequently call in and do not know their account number. It has a unique ability when recovering a database, since you can always recreate an index from an existing table instead of recovering it.
|
Term |
Informix |
Oracle |
Sybase |
|---|---|---|---|
|
BLOB space |
BLOBspace, Smart BLOBspace |
BLOB, CLOB, BFILE data types |
Image data type |
BLOB data has grown in popularity within the last few years. It refers to anything that does not fit into a “normal” table. This may range from a large piece of text data to a scanned-in image. Most databases use the term “BLOB” to refer to both types, but Oracle8 differentiates between Character LOB (text) and Binary LOB (graphics and the like) data. Oracle and Sybase store BLOB data inside a normal table by using a special data type. Oracle8 also allows you to store BLOB data in the regular filesystem and have it referenced in the database by using the BFILE data type. (I have seen custom data types that do this in other databases as well.) Informix, the first to offer this type of storage, has a special dataspace—called a BLOBspace—reserved just for BLOB data. (Dataspaces are defined later.) Informix Universal Data Option also has what it calls a “Smart BLOBspace,” which allows BLOB data to contain nonstandard information that can be used to manage the BLOB data in a “smart” way.
If the BLOB data is stored inside the database, it presents no unique backup requirements. However, the use of the BFILE data type and custom data types that allow the storage of the BLOB data outside the database (i.e., in the filesystem) are a different story. While they may provide many performance enhancements, they do present a unique backup challenge. The BLOB data needs to be backed up in sync with the database data. That is because the database is keeping track of what files are where. Suppose a piece of BLOB data was inserted at 11:00. If you back up the filesystem at 10:00 and the database at 12:00, the database will know about a file that exists out on the filesystem, but that file will not be found on your filesystem backup. Even more confusion may be added if the filesystem backup spans the time of the database backup. In other words, it begins at 10:00 and ends at 4:00, although the database backup begins at 12:00 and is done by 2:00.
There are only two ways to resolve this conflict. The easiest way is to shut down the database or put it in read-only mode during the entire time of your filesystem backup. This may be impractical for many environments. The second way is to use the snapshot concept. This allows you to take a “snapshot” of the entire filesystem in just a few seconds and then take all night to back it up. This provides a consistent picture of the filesystem at a certain point in time. (See Section 19.1.5 in Chapter 19.)
This generic term refers to any type of table within a database. All database objects are tables by its strictest definition, but the term table usually refers to a simple table, as discussed earlier. So we use the term object to describe any type of table that may be in a database. This includes, but is not limited to, simple tables, indexes, BLOB tables, stored procedures, and triggers.
A row (called a tuple in formal database terminology) is a collection of related attributes. For example, there may be a row that contains all the basic information about a customer such as her name, address, account number, and phone number (this is also similar to a row in a spreadsheet). Each row has at least one unique attribute, such as the account number, to distinguish it from other rows. A row is also sometimes called a “record.” (See Figure 13-1 for a graphical representation of a row.)
An attribute is the basic element of data within a table. It is a single value, such as a customer’s name or Zip Code. An attribute may be very small, such as a Zip Code, or very large, such as a BLOB. An attribute is the value that a database user changes when performing a “transaction.” (Transactions are covered later in this chapter.) (See Figure 13-1 for a graphical representation of an attribute.)
The DBA has to know quite a bit more about the database than even the most sophisticated power user, since the DBA must create databases, tune them, back them up, and recover them in the case of failure. DBAs also know a programming language called SQL that allows them to construct precise types of queries to increase the usability of the database. Good DBAs also need to know quite a bit about operating system technology, so that they can efficiently use the storage capabilities of their operating environment.
The good news is that, unless you’re a DBA, you won’t need to know all of that to properly back up and recover databases. This section describes the physical elements of database storage and how they are combined with the logical elements discussed earlier.
The bad news is that, unlike the terms in the user’s view, the elements in the database view are called something different in almost every product. Often, the same term presented in the previous section is used to describe different types of elements in different products. This took quite a bit of work to be able to discuss them all in a single chapter. It often was very difficult to find a generic term that would apply to all of them without confusing things. Therefore, the “Term” column often contains a word that was coined just for that purpose. This generic term is used throughout this chapter when discussing the different types of storage elements and how they fit together. The product-specific terms are used only when referring to the products themselves. It should be noted that some of the coined terms that follow may be useful only when discussing things with someone else that has read this chapter. If you are discussing storage elements with a particular DBA who has not read this chapter, be sure to use the appropriate terms for the product that DBA knows.
The page , also called a block, is the basic building block of every database. It is the smallest amount of data that is moved in an I/O operation. It is similar to, although not exactly the same as, a filesystem block. (You can have a 2-K block inside a database that sits on a filesystem that has an 8-K block size.[58]) It is usually 2 K or 4 K in size, but some database products allow you to specify a custom page size for your environment. Whatever size the page is, it is the smallest atomic entity within a database. When one modifies a table within a database, it eventually will modify one or more pages stored somewhere on disk. (See Figure 13-2 and Figure 13-3 for graphical representations of a page.)
A
datafile
is where the data is
stored. This may be a raw [59]
device (e.g.,
/dev/rdsk/c0t0d0s3), a cooked device (e.g., /dev/dsk/c0t0d0s3), or
a cooked file (e.g.,
/oracle/data/dbs01.dbf ). Some products require
the use of raw partitions, while others merely suggest it. Some
products allow a mixture of raw and cooked files. The only real
difference to the DBA is how they are initially created and how they
are backed up. Other than that, they look the same within the
database. (See Figure 13-2 and Figure 13-3 for graphical representations of a page.)
An extent is a number of pages that are logically grouped together and are considered “logically contiguous.” They may or may not be physically contiguous. (If the pages in an extent are physically contiguous, that means that they are physically next to each other.) Informix extents are physically contiguous, while others may or may not be, depending on when and how they were created. All extents are considered logically contiguous, since they are treated as a single block of storage that is allocated to a table. Extents do not span more than one datafile, but a datafile may contain any number of extents. The actual size of an extent is determined by the database platform. (See Figure 13-2 and Figure 13-3 for graphical representations of an extent.)
A fragment is a collection of logically contiguous extents that may or may not be physically contiguous. Informix calls this a " tblspace.” This is not to be confused with what Oracle calls a “tablespace”! (See the sidebar Tablespace or Tblspace?.) In Sybase, an allocation unit is the smallest block of storage that is given to a database, and it is 32 extents.
Again, this is where more of the confusion comes in. A tablespace (in this context) is defined as “the space that a table occupies,” not to be confused with a dataspace, which is “the space that a table goes in.” When one creates a table, it usually is created on or in a dataspace (defined next), which may contain that table and many others. The quantity of physical storage space that this tabletakes up is referred to as its “tablespace.” Informix calls this a “tblspace” as well but also uses the term for the fragments that make up a tblspace (see the sidebar Tablespace or Tblspace?). (See Figure 13-2 and Figure 13-3 for a graphical depiction of a tablespace.)
A dataspace is a much larger storage element that may contain one or more tablespaces (as defined previously; not to be confused with what Oracle calls a “tablespace”) and consists of one or more datafiles. (See Figure 13-2 and Figure 13-3 for a graphical depiction of a dataspace.) A table is created in a dataspace (e.g., create table in dataspace alpha). Both Informix and Oracle require you to create dataspaces before you can create a database. Informix and Oracle also create a dataspace prior to creating a new instance. When creating an instance, you specify which datafile will be the main (or system) dataspace. Informix and Oracle then create this dataspace for you automatically.
A DBA simply tells Sybase to “create a database on these devices.” When you do this, Sybase creates the default tablespace or segment. Sybase allows you to then create a table within a database, and it gets stored on the same dataspace as the rest of the tables in the database. If you do not define a custom user segment, all tables will be created in the default segment. However, you can create a segment that consists of one or more datafiles and then create a table on that segment. Therefore, when you use segments in Sybase, they serve the same function as dbspaces in Informix and tablespaces in Oracle. However, since many Sybase DBAs do not define custom user segments, they do not think of segments as dataspaces.
One of the biggest advancements in RDBMS technology is the ability to partition a table across multiple dataspaces. Typically, a table had to be contained within a dataspace, as described before. Now you can specify that a table is partitioned across multiple tablespaces based on the values of certain attributes. For example, you could create a table that is partitioned across dataspaces A and B. You could specify that all records with value 1-100 in attribute A go to dataspace A, and all records with value 101-200 in attribute A go to dataspace B. (See Figure 13-3 for a graphical depiction of a partitioned table.) A partitioned table does not present any unique backup requirements. Informix says that a table is partitioned into multiple fragments.
|
Term |
Informix |
Oracle |
Sybase |
|---|---|---|---|
|
Master database |
Sysmaster, onconfig file, rootdb |
Control file |
Master database |
Each instance has some way of keeping track of all the storage
elements that it has at its disposal. This master
database
keeps track of all the devices and
their status. It keeps track of any information that all the
databases need to have access to. If multiple databases are allowed,
it needs to keep track of them as well. Sybase has a special database
to do this, and Oracle has what it calls a control
file, which keeps track of this information. Informix also
has a special database, called the Sysmaster,
that keeps track of the status of every object within an instance.
However, some information is tracked by the
onconfig
file and reserved pages within the
rootdb
.
A transaction is an activity within a database that changes one or more attributes within one or more tables. If a user changes a customer’s address, that is a transaction. There are two types of transactions, a simple transaction and a complex transaction. A simple transaction is done in one statement (e.g., update attribute X in table Y to 100). A complex transaction may be much longer, and opens with a begin transaction statement and closes with an end transaction statement. There may be a number of simple statements in between the open and close statements, or there may be a complicated SQL program that updates hundreds of values based on certain parameters. For example, a number of new area codes have been created in several large cities. A complex transaction could be designed that would scan all customer phone numbers and change their area code based on their three-digit exchange. A complex transaction is treated as an "atomic” event—it’s all or nothing. Both the start transaction and end transaction statements are recorded in the transaction log (defined later), and if anything happens before the end transaction statement is recorded, all changes that were made by that transaction are rolled back, or undone. Things that could cause that to happen are the user logging out in the middle, the database being shut down, the system crashing, or even the user changing his mind.
From a data integrity standpoint, it is important to realize what a transaction does. While to a user’s eyes a transaction changes a record in the database, it actually changes one or many pages. It is on the page level that transaction recovery is done. If a given transaction modifies 100 pages and then the transaction does not complete, those 100 pages must be returned to what they looked like before the transaction occurred. This is referred to as rolling back the page to its before image . (The before image is what the page looked like before it was changed.) The following elements describe the facilities that databases have to ensure that this (and other data integrity activities) occurs properly.
The rollback log is the place where the database stores this before image. Informix and Oracle have a dedicated log just for this purpose. The before image of each changed page is stored in this log until the transaction is complete, or committed . Sybase records both the before image and the transaction data in the transaction log. It is important to note that this before image must be physically written to disk before any pages are to be physically changed. That ensures that the before image is available if the system crashes. How this before image is actually used varies widely between database products.
Suppose that a system were to crash in such a way that it needed to be recovered from your latest database backup. If there were no way to redo the transactions that have occurred since the last backup, all such transactions would be lost. A transaction log records each transaction and what pages it changed. This information is used in case of a system crash that requires reentering those transactions. The master database knows what state each datafile is in, and it looks at each of them upon starting up. If it detects any that are corrupt, you have to restore those datafiles from your backup. The master database then looks at the datafile and realizes that it was restored from an earlier point in time. It then goes to the transaction log to “redo” all the transactions that have been recorded since that time. Uncommitted transactions are then rolled back. The actual order of this process differs from product to product. However, the main purpose remains the same. The rollback and transaction logs work together to ensure that all pages are returned to their proper state after a crash or reboot.
Many people have difficulty understanding the difference between the rollback log and the transaction log. Informix’s terminology helps in this case, because their terms physical and logical log illustrate exactly what the logs contain. The physical log contains a physical “image” of a page prior to it being changed by a transaction. It doesn’t know or care how the page was changed; it just knows what it looked like before it was changed. The logical log, on the other hand, keeps track of how the page was changed, so that the database can recreate this change after a recovery.
In order to increase performance, databases keep a lot of data in memory: recently changed pages, commonly accessed pages, before images of modified pages, and the transactions themselves. This means that if the system crashes at some point, some data will be lost, since RAM is volatile. The database needs some way to go back to a time that it knows everything was on disk and nothing was in memory. This point in time is called the checkpoint.
At certain intervals, defined by user-configurable parameters, the database flushes everything to disk. All datafiles and log files are therefore in a consistent state. If the system were to crash without damaging the datafiles, the database would revert to this checkpoint, then replay any completed transactions that have been recorded since that checkpoint, and finally roll back any incomplete transactions. This ensures that the database can always be backed up in a consistent state.
[55] An instance can actually be spread across multiple machines.
[56] That is why it is not correct to say that you are going to stop/start a database. You are actually stopping/starting an instance that contains the database.
[57] I don’t believe that it is necessary to understand schemas in order to properly back up and recover databases. One of my technical reviewers made me put it in.
[58] That is why I prefer the term “page” over the Oracle term, “block.” It helps to differentiate between filesystem blocks and database blocks, or pages. I have seen DBAs and SAs confuse each other talking about what block size a given Oracle database should have.
[59] “Raw” refers to an unbuffered disk device.
Typically these are in /dev/rdsk, or named
/dev/rxxx. The term “cooked” seems a
little silly, but it is simply the opposite of
“raw.”