
This is also a relatively new problem for backup software products. It used to be that the backup drive was the bottleneck in any backup system. For many years, the optimum speed of most backup drives was less than 1 MB per second. Since disks were able to supply data much faster than that, the only other potential bottleneck would be the network. Therefore, even a 10-MB network could stream a backup device at its full speed.
Those days are gone. There are now backup drives that can write three times as fast as many disk drives. Backup drives now use Fast-Wide SCSI, large buffers, and sometimes write multiple streams of data to the drive at once. Fibre-channel backup drives are now available. The result is that many backup drives can write at 10 MB/s or faster. The difficulty with most of these drives, though, is that they are "streaming” tape drives. This means that you must supply them with a steady stream of incoming data equivalent to their maximum throughput. If not, the drive will not stream, resulting in a significantly slower transfer rate than it is capable of. This problem, of course, affects only streaming tape drives. It does not affect backup drives that simulate a disk drive, such as Magneto-Optical, CD, and DVD drives.
All streaming tape drives are designed to write most effectively at their optimum speed. If they are supplied with data at a slower rate than that, the result may be surprising. What begins to happen is referred to as “repositioning.” See Section 18.3 of Chapter 18 for more information on this concept. The drive spends most of its time repositioning and has less time to actually write data. The result is that it will write at a small fraction of its maximum data rate.
When would this happen? Consider a single-threaded backup process such as dump or tar. It will encounter many potential bottlenecks before getting to the drive. The first obstacle is the disk itself, which may not be capable of supplying data at a sufficient rate. Another is the SCSI bus and system to which the drive is connected. It may be busy satisfying other I/O requests, hence impacting the data rate that can be transferred across the bus. The next, of course, is the network. If it’s a 10-Mb network, the best possible data rate is less than 1 MB/s. The final possible bottleneck is the system to which the backup drive is connected. Any one of these bottlenecks could slow the data rate to less than the optimal speed for the backup drive. If that happens, a tape drive stops streaming and begins repositioning in order to keep in pace with the incoming data. When this happens, it becomes the new bottleneck. What can be done about this? Most commercial backup products solve this problem by implementing multithreaded backups. Multithreaded backups can read data from several systems and several disks at one time and supply the data from all of these threads to the backup drive simultaneously. The data from these different sources is then “interleaved” onto the volume. The backup drive is thus always being supplied with a sufficient stream of data, so it can write at its maximum speed. A cautious administrator learning of this feature for the first time might be worried. Some administrators don’t like the fact that their data is spread out all over the volume. However, this feature is really the only way to stream a backup drive that can read or write at speeds faster than a disk. This is why most commercial backup products implement multithreading.
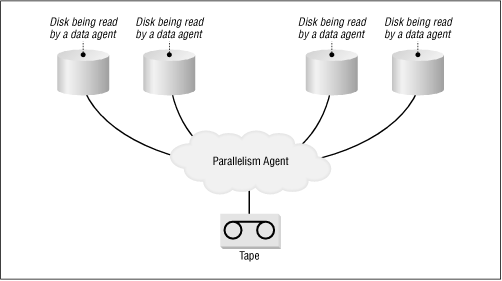
Different backup software vendors use different terms for this feature. It often is referred to as " parallelism” or “interleaving.” As in Figure 5-1, which depicts parallelism, there are several processes called data agents (DA for short) reading from disks at one time. Those processes feed their data streams to the parallelism agent (PA for short), which does the actual job of interleaving the separate streams together into one stream, which then gets written to the backup drive.
Parallelism can be done in one of two ways.
Backup software products accomplish the first type of interleaving by leaving the file intact. Each DA would read a file and then tell the PA it was ready to send this file. The PA then would read the entire file from the DA and write it to the backup volume as one contiguous section. The PA then would look to see which DA had the next available file ready. This works fine for small files that are coming from systems that are all the same speed. However, if a DA on a relatively slow system has a large file, it will occupy the PA’s time during the transmission of that entire file. The result is that the backup drive may slow down when such large files are backed up. This type of parallelism is illustrated in Figure 5-2.

Most backup software products that support parallelism use a method known as block-level parallelism, also referred to as record-level parallelism. With this method, each file is split into multiple blocks of data. These blocks then are written to the volume in a noncontiguous fashion, interleaved with other blocks of data from other files or systems. This is the most efficient way, since it means that the data needed by the parallelism agent can be taken from any disk on any system that is being backed up by this backup definition, so the PA never has to wait on a DA. Unlike file-level parallelism, no single system or disk can cause a bottleneck.
Notice in Figure 5-3 that each file is split into multiple blocks, labeled “Block 1,” “Block 2,” etc. File one is a large file and took up many blocks. It was coming from a slow system, which was not able to supply data very fast. File three, on the other hand, came from a much faster system. That explains why blocks 2 and 3 are together. This is why block-level parallelism is so efficient. Faster disks and faster systems will be allowed to send the data as fast as they can to the volume, while slower systems will get a block in every so often. All the while, the volume is recording away.

There is a downside to block-level parallelism—slower restores. Just how slow the restores will be is determined by how the product handles parallelism during a restore. If the product is using block-level parallelism, then during a restore the backup drive normally will be given a list of instructions like the following:
Position to block 1000
Read one block of data
Position to block 1003
Read one block of data
Position to block 1010
Read one block of data
There is a completely different way to speed up restores of parallelized data. The software could read the volume continuously, disregarding blocks that it doesn’t need. (This actually is taking a step back in technology, but unfortunately it’s the only way to get some of the modern backup drives to perform well during a restore of interleaved data.) The lesson to learn here is to test every product’s ability to restore interleaved data.