
At first, Git’s automatic merging support seems nothing short of magical, especially compared to the more complicated and error-prone merging steps needed in other version control systems.
Let’s take a look at what’s going on behind the scenes to make it all possible.
In most version control systems, each commit has only
one parent. On such a system, when you merge
some_branch into my_branch, you
create a new commit on my_branch with the changes
from some_branch. Conversely, if you merge
my_branch into some_branch, this
creates a new commit on some_branch containing the
changes from my_branch. Merging branch A into
branch B and merging branch B into branch A are two different
operations.
However, Git designers noticed that each of these two operations
results in the same set of files when you’re done. The natural way to
express either operation is simply to say “Merge all the changes
from some_branch and
another_branch into a single branch.”
In Git, the merge yields in a new tree object with the merged files, but it also introduces a new commit object on only the target branch. After these commands:
$git checkout my_branch$git merge some_branch
the object model looks like Figure 9-10.
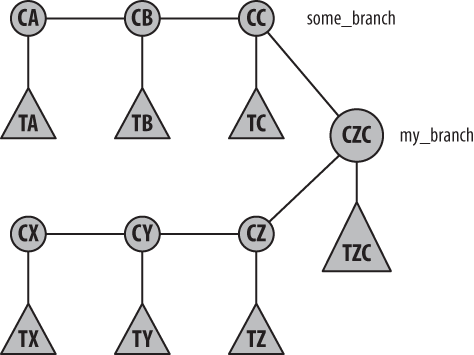
In Figure 9-10, each
C is a commit object
and each xT represents
the corresponding tree object. Notice how there is one common merged
commit (xCZC) that has both CC
and CZ as commit parents, but it has only one
resulting set of files represented in the TZC tree.
The merged tree object symmetrically represents both source branches
equally. But since my_branch was the checked-out
branch into which the merge happened, only
my_branch has been updated to show the new commit
on it; some_branch remains where it was.
This is not just a matter of semantics. It reflects Git’s underlying philosophy that all branches[21] are created equal.
Imagine if some_branch had contained
not just one new commit but instead 5 or 10 or even 100s of commits.
In most systems, merging some_branch into
my_branch would involve producing a single diff,
applying it as a single patch onto my_branch, and
creating one new element in the history. This is called a
squash commit because it “squashes” all the individual
commits into one big change. As far as the history of
my_branch is concerned, the history of
some_branch would be lost.
In Git, the two branches are treated as equals, so it’s improper
to squash one side or the other. Instead, the entire history of
commits on both sides is retained. As users, you can see from Figure 9-10 that you pay for this
complexity. If Git had made a squash commit, you wouldn’t have to see
(or think about) a diagram that diverges and then rejoins again. The
history of my_branch could have been just a
straight line.
Note
Git can make squash commits if desired. Just give the
--squash option to git merge or git
pull. Beware, however! Squashing commits will upset Git's
history, and that will complicate future merges because the squashed
commits alter the original commit history (see Chapter 10).
The added complexity might appear unfortunate, but it is actually quite worthwhile. For example, this feature means that the git blame and git bisect commands, discussed in Chapter 6, are much more powerful than equivalents in other systems. And, as you saw with the recursive merge strategy, Git is able to automate very complicated merges as a result of this added complexity and the resulting detailed history.
Tip
Although the merge operation itself treats both parents as
equals, you can choose to treat the first parent as special when you
go back through the history later. Some commands, such as
git log and gitk, support the
--first-parent option, which follows only the first parent of every merge.
The resulting history looks much the same as if you had used --squash on all your merges.
You might ask wouldn’t it be possible to have it both ways: a
simple, linear history with every individual commit represented? Git
could just take all the commits from some_branch
and apply them, one by one, onto my_branch. But
that wouldn’t be the same thing at all.
An important observation about Git’s commit histories is that each revision in the history is real. (You can read more about treating alternate histories as equal realities in Chapter 12.)
If you apply a sequence of someone else’s patches on top of your version, you will create a series of entirely new versions with the union of their changes and yours. Presumably you will test the final version as you always would. But what about all those new intermediate versions? In reality, those versions never existed: nobody actually produced those commits, so nobody can say for sure whether they ever worked.
Git keeps a detailed history so that you can later revisit what your files were like at a particular moment in the past. If some of your merged commits reflect file versions that never really existed, then you’ve lost the reason for having a detailed history in the first place!
This is why Git merges don’t work that way. If you were to ask,
“What was it like five minutes before I did the merge?”
the answer would be ambiguous. You have to ask about either
my_branch or some_branch
specifically, since both were different five minutes ago and Git can
give the answer for each one.
Even though you almost always want the standard history merging behavior, Git can also apply a sequence of patches (see Chapter 13). This process is called rebasing and is discussed in Chapter 10. The implications of changing commit histories are discussed in Changing Public History.