
As the developer of content for a project using Git, you should create your own private copy, or clone, of a repository to do your development. This development repository should serve as your own work area where you can make changes without fear of colliding with, interrupting, or otherwise interfering with another developer.
Furthermore, because each Git repository contains a complete copy of the entire project as well as the entire history of the project, you can feel free to treat it as if it is completely and solely yours. In effect, it actually is!
One benefit of this paradigm is that it allows each developer complete control within her working directory area to make changes to any part, or even to the whole system, without worrying about interaction with other development efforts. If you need to change a part, you have the part and can change it in your repository without affecting other developers. Likewise, if you later realize that your work is not useful or relevant, you can throw it away without affecting anyone else or any other repository.
As with any software development, this is not an endorsement to conduct wild experimentation. Always consider the ramifications of your changes, because ultimately you may need to merge your changes into the master repository. It will then be time to pay the piper, and any arbitrary changes may come back to haunt you.
Faced with a wealth of repositories that ultimately contribute to one project, it may seem difficult to determine where you should do your development. Should your contributions be based on the “main” repository directly? Or perhaps on the repository where other people are focused on some particular feature? Or maybe a “stable” branch of a release repository somewhere?
Without a clear sense of how Git can access, use, and alter repositories, you may be caught in some form of the “can’t get started for fear of picking the wrong starting point” dilemma. Or perhaps you have already started your development in a clone based on some repository you picked and now realize that it isn’t the “right” one. Sure, it is related to the project and may even be a “good” starting point, but maybe there is some missing feature found in a different repository. It may even be hard to tell until well into your development cycle.
Another frequent starting-point dilemma comes from a need for project features that are being actively developed in two different repositories. Neither of them is, by itself, the correct clone basis for your work.
You could just forge ahead with the expectation that your work, and the work in the various other repositories, will all be unified and merged into one master repository. You are certainly welcome to do so, of course. But remember that part of the gain from a distributed development environment is the ability to do concurrent development. Take advantage of the fact that the other published repositories with early versions of their work are available.
Another pitfall comes if you start with a repository that is at the cutting edge of development and find that it is too unstable to support your work—or that it is abandoned in the middle of your work.
Fortunately, Git supports a model where you can essentially pick any arbitrary repository from a project as your starting point, even if it is not the perfect one, and then convert, mutate, or augment that repository until it does include all the right features.
If you later wanted to separate your changes back out to different respective upstream repositories, you may have to make judicious and meticulous use of separate topic branches and merges to keep it all straight.
On one hand, you can fetch branches from multiple remote repositories and combine them into your own, yielding the right mix of features that are available elsewhere in existing repositories. On the other hand, you can reset the starting point in your repository back to a known stable point earlier in the history of the project’s development.
The first and simplest kind of repository mixing and matching is to switch the basis (usually called the clone origin) repository, the one you regard as your origin and with which you synchronize regularly.
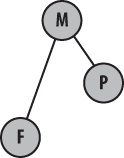
For example, suppose you need to work on feature
F and that you decide to clone your repository from
the mainline, M, as shown in Figure 12-1.

You work for a while before learning that there is a better
starting point closer to what you would really like, but it is in
repository P. One reason you might want to make
this sort of change is to gain functionality or feature support that
is already in repository P.
Another reason stems from longer-term planning. Eventually, the
time will come when you need to contribute the development that you
have done in repository F back to some upstream
repository. Will the maintainer of repository M
accept your changes directly? Perhaps not. If you are confident that
the maintainer of repository P will accept them,
then you should arrange for your patches to be readily applicable to
that repository instead.
Presumably, P was once cloned from
M, or vice versa, as shown in Figure 12-2. Ultimately, P
and M are based on the same repository for the same
project at some point in the past.
The question often asked is whether repository
F, originally based on M, can
now be converted so that it is based on repository
P, as shown in Figure 12-3. This is easy to do
using Git, because it supports a peer-to-peer relationship between repositories and provides the
ability to readily rebase branches.

As a practical example, the kernel development for a particular architecture could be done right off of the mainline Linus Kernel repository. But Linus won’t take it. If you started working on, say, PowerPC changes and did not know that, you would likely have a difficult time getting your changes accepted.
However, the PowerPC architecture is currently maintained by Ben Herrenschmidt; he is responsible for collecting all PowerPC-specific changes and, in turn, sending them upstream to Linus. To get your changes into the mainline repository, you must go through Ben’s repository first. You should therefore arrange to have your patches be directly applicable to his repository instead—and it’s never too late to do that.
In a sense, Git knows how to “make up the difference” from one repository to the next. Part of the peer-to-peer protocol to fetch branches from another repository is an exchange of information stating what changes each repository has or is missing. As a result, Git is able to fetch just the missing or new changes and bring them into your repository.
Git is also able to review the history of the branches and determine where the common ancestors from the different branches are, even if they are brought in from different repositories. If they have a common commit ancestor, Git can find it and construct a large, unified view of the commit history with all the repository changes represented.
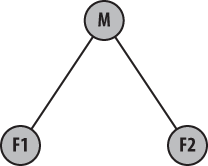
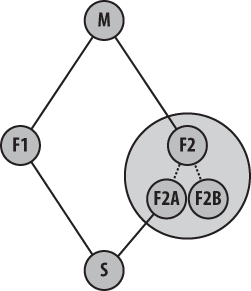
As another example, suppose the general repository
structure looks like Figure 12-4.
Here, some mainline repository, M, will ultimately
collect all the development for two different features from
repositories F1 and F2.
However, you need to develop some super feature,
S, that involves using aspects of features found
only in F1 and features found only in
F2. You could wait until F1 is
merged into M and then wait for
F2 to also be merged into M.
That way, you will then have a repository with the correct, total
basis for your work. But, unless the project strictly enforces some
project life cycle that requires merges at known intervals, there is
no telling how long the process might take.
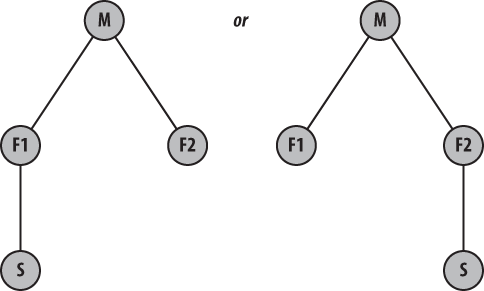
You might start your repository, S, based off
of the features found in F1 or, alternatively, off
of F2, as shown in Figure 12-5. However, with Git it is
possible to instead construct a repository, S, that
has both F1 and F2 in it; this
is shown in Figure 12-6.
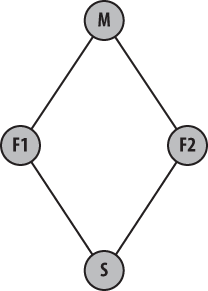
In these pictures, it is unclear whether repository
S is composed of the entirety of
F1 and F2 or just some part of
each. In fact, Git supports both scenarios. Suppose repository
F2 has branches F2A and
F2B with features A and
B, respectively, as shown in Figure 12-7. If your
development needs feature A but not
B, you can selectively fetch just that
F2A branch into your repository,
S, along with whatever part of
F1 is also needed.
Again, the structure of the Linux kernel exhibits this issue. Let’s say you are working on a new network driver for a new PowerPC board. You will likely have architecture-specific changes for the board that will need code in the PowerPC repository maintained by Ben. Furthermore, you will likely need to use the Networking Development “netdev” repository maintained by Jeff Garzik. Git will readily fetch and make a union repository with branches from both Ben’s and Jeff’s branches. With both basis branches in your repository, you will then be able to merge them and develop further on them.
Anytime you clone a repository, the action can be viewed as forking the project. Forking is functionally equivalent to “branching” in some other version control systems, but Git also has a separate concept called “branching,” so don’t call it that. Unlike a branch, a Git fork doesn’t exactly have a name. Instead, you simply refer to it by the filesystem directory (or remote server, or URL) into which you cloned.
The term “fork” comes from the idea that when you create a fork, you create two simultaneous paths that the development will follow. It’s like a fork in the road of development. As you might imagine, the term “branch” is based on a similar analogy involving trees. There’s no inherent difference between the branching and forking metaphors—the terms simply capture two intents. Conceptually, the difference is that branching usually occurs within a single repository, whereas forking usually occurs at the entire repository level.
Although you can fork a project readily with Git, doing so may be more of a social or political choice than a technical one. For public or open source projects, having access to a copy or clone of the entire repository, complete with its history, is both an enabler of forking and a deterrent to forking.
Tip
GitHub.com, an online Git hosting service, takes this idea to the logical extreme: everybody’s version is considered a fork, and all the forks are shown together in the same place.
Historically, forking a project was often motivated by perceptions of a power grab, reluctance to cooperate, or the abandonment of a project. A difficult person at the hub of a centralized project can effectively grind things to a halt. A schism may develop between those in charge of a project and those who are not. Often the only perceived solution is to effectively fork a new project. In such a scenario, it may be difficult to obtain a copy of the history of the project and start over.
Forking is the traditional term for what happens when one developer of an open source project becomes unhappy with the main development effort, takes a copy of the source code, and starts maintaining his own version.
Forking, in this sense, has traditionally been considered a negative thing; it means the unhappy developer couldn’t find a way to get what he wanted from the main project. So he goes off and tries to do it better by himself, but now there are two projects, almost the same. Obviously neither one is good enough for everybody, or one of them would be abandoned. So most open source projects make heroic efforts to avoid forking.
Forking may or may not be “bad.” On the one hand, perhaps an alternate view and new leadership is exactly what is needed to revitalize a project. On the other hand, it may simply contribute to strife and confusion on a development effort.
In contrast, Git tries to remove the stigma of forking. The real problem with forking a project is not the creation of an alternate development path. Every time a developer downloads or clones a copy of a project and starts hacking on it, she has created an “alternative development path,” if only temporarily.
In his work on the Linux kernel, Linus Torvalds eventually realized that forking is a problem only if the forks don’t eventually merge back together. Thus, he designed Git to look at forking totally differently: Git encourages forking. But Git also makes it easy for anyone to merge two forks whenever they want.
Technically, reconciling a forked project with Git is facilitated by its support for large-scale fetching and importing one repository into another, and for extremely easy branch merging.
Although many social issues may remain, fully distributed repositories seem to reduce tensions by lessening the perceived importance of the person at the center of a project. Because an ambitious developer can easily inherit a project and its complete history, he may feel it is enough to know that, if needed, the person at the center could be replaced and development could still continue!