
As mass storage performance is dominated by the physical attributes of the disk, a networked application is dominated by the network link over which it is operating. Every other part of a computer is at least an order of magnitude faster than its network connection.
Writing good networked game code requires embracing the limitations and problems inherent in networked communications. You have to know what is really going on behind the scenes in order to get good results. Despite this, it is possible to build compelling, rich networked worlds with limited resources.
There are three fundamental issues when it comes to networking: throughput, latency, and reliability. Throughput you are already familiar with from previous discussions—the rate at which data is transferred. Latency is the time for a message to travel from one end of the connection to the other. Round trip time (RTT) is the time for a trip to one end of a connection and back.
Reliability is an issue that most other types of hardware don’t present. If you draw a triangle with the graphics card, either it works immediately, or it is time to reboot. If you write some data to memory, it just works. If you want to read something from disk, you generally don’t have to worry about any complex error scenarios.
Network data transmission is a different story. Not only can packets be out of order, but they can be corrupted, truncated, or even lost! At its lowest level, you might never know what happened to a packet you’ve sent.
Any successful networking system has to handle these issues.
Nearly every operating system ships with an implementation of Berkeley Sockets. On Mac and Linux, it is a derivative of the original implementation. On Windows, there is WinSock, which is a superset of the Berkeley API. There are a few other variant technologies, but in general, when it comes to networking, Berkeley has set the standard.
The first distinction in networking is in regards to reliability. You can either handle it yourself, or leave it up to the operating system. This is the difference between UDP and TCP. In UDP, the User Datagram Protocol, you can send and receive datagrams, but there is no concept of a fixed connection. Datagrams may be lost, received multiple times, delivered out of order, corrupted, or fail in many other ways. If you want your data to be sent reliably or in a specific order, you have to do it yourself. On the other hand, the true nature of the network is exposed to you, and you have a lot less OS involvement in the process.
TCP, the Transmission Control Protocol, lets you send data as if you were working with a file stream. Data is sent in order with guaranteed delivery. On the other end, the networking stack (typically provided by the OS but sometimes by software running on the network card itself) ensures that data is also received by the application on the other end in the same order with nothing missing. This is done at some cost to efficiency.
Another distinction in networking is between client/server architectures and peer-to-peer. Different games use different approaches in this area. Depending on the type of game and number of players, one or the other might give better results. This is a discussion well outside the scope of this performance-oriented chapter, so we encourage you to review the resources mentioned at the end of this chapter if you want to learn more.
Those are the basics. Now we’ll talk in some more detail about types of reliability and how they play out in a real-time game networking context.
There are two main conditions for thinking about network transmission: reliability and order.
Data delivery can be reliable or unreliable. Reliable means that, unless the connection completely fails, the data will arrive on the other side. Unreliable means that any specific piece of data might be lost, although the success rate is usually quite high.
Delivery can be ordered or unordered. Ordered delivery ensures that if you send messages 1,2,3, they will arrive in that order. If packets arrive out of order, data is buffered until the missing pieces arrive. Unordered delivery means that data is processed in the order it is received, so our example might arrive 3,1,2 or in any other order.
This gives us a nice four-quadrant diagram:
Ordered, Guaranteed | Unordered, Guaranteed |
Ordered, Unguaranteed | Unordered, Unguaranteed |
In the next few sections, you’ll see that different types of game traffic fall into different quadrants.
One point to understand is that TCP is implemented in terms of raw datagram delivery. In other words, it sits on top of the functionality that the UDP layer exposes. So you can do everything that TCP does in your own protocols, with the added benefit that you have much more direct control over what is going on.
At the end of this chapter, we will discuss various middleware, some open source and some closed source, which can help you on your way to having a working networked game.
We’ve described how raw data delivery works—how to get buffers of bytes from place to place on the Internet in different ways. Once you have the ability to control how your data flows, you can move on to discussing the different delivery needs for different kinds of data. The two main types of data for game networking are events and most-recent-state data.
Events are discrete messages you want to send, like chat messages or events such as a lightning strike in-game or a signal indicating the end of the round. They are basically equivalent to remote procedure calls (RPCs). They are often ordered and reliable. A game will usually have many different kinds of network events that are sent.
Most-recent-state data is what makes the game go around, and they’re a big optimization opportunity. Most games have a lot of objects that need to be approximately consistent on all the nodes in the network, and for which only the current state is relevant.
A good example is a door. You can model it as a single bit, and players only care about whether the door is currently open or closed. Suppose that you have a maze with thousands of doors in it. You assign each door a shared ID that is the same between client and server. Then, as doors change state, you send the latest state in unguaranteed, unordered packets. If a packet is lost, it’s not a big deal—just note that you need to resend whatever updates were in that packet, and when you do resend, send the latest state. If packets are duplicated or received out of order, you need to use information from your protocol to reject the old or already-processed data. In the case of TCP, this is easy; in the case of UDP, it’s slightly trickier.
This not only works for doors, but it also works for nearly everything else in a game world. Colors of trees, locations of power-ups, and even the position and status of other players can all be tracked this way.
The only situation that this approach is not good for is when you need to simulate exactly the behavior of a game entity on every peer. Most recent state only gives approximate results. For instance, the player character that a client controls needs to exactly match, at every tick, the player’s input. Otherwise, control feels loose and laggy, cheating is possible, and artifacts may occur, such as remote players walking through walls.
The solution is for the client to send a stream of its moves to the server. Then the server can play them back to mimic the client’s moves exactly. The server, if it is authoritative, can also send a full precision update of the player character’s state to the client in every packet, so the client has the best and freshest information. (You can replace client with “player’s node” and server with “the other peers” if you are working in a P2P environment.)
Before we move on to what data gets sent, let’s talk about how it should be encoded and why encoding matters. The previous section presented a networking strategy—a bunch of small chunks of data encoding various pieces of game state. And even if your networking doesn’t work with exactly the same types of data, it probably still has lots of small pieces of data being transmitted—this is typical in games. Lots of small packets means lots of overhead.
First, bandwidth drives fidelity. That is, the more effectively you can use your bandwidth, or the more bandwidth you can use, the more state updates you can send. The more updates you can send, the more consistent the world state will be for everyone. In the ideal case, everyone would be able to get full precision world state information in every packet. But this is rarely possible, so the system must be able to send as much game state as possible in every packet.
You want your updates to be as small as possible. How do you do this? The basic tool at your disposal is how you pack your data. At minimum, you want a bit stream where you can write values with varying numbers of bits. That way, if you have a flag, it only takes one bit; if you have a state that can have one of four values, you only need two bits. You should be able to encode floats with varying precision as well. Things like health often don’t need more than seven or eight bits to look correct to clients, even if you use full floats internally. Integers often fall into a known range, and can be encoded more efficiently (and validated) with this knowledge.
After you use a bitstream to pack your data, you can add all sorts of interesting encoding techniques. See Figure 11.1 for a visualization of how the approaches will layer. Huffman encoding is useful for strings. You might also want to have a shared string table that you can index into instead of sending full strings. You can use LZW compression for bulk data. There are more advanced techniques like arithmetic coders that can take advantage of statistical knowledge of what data looks like.
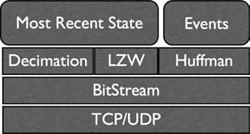
Figure 11.1. View of the game protocol-encoding stack. At the lowest level is the network transport that transmits bytes. Above this, the bitstream, which allows bit-level encoding. Above this, various context-specific options like LZW, Huffman encoding, or decimation. And on top, the various kinds of updates that your game sends.
The smaller your updates are, the more you can send in each packet, the more effectively you can prioritize them, and the better your user’s experience will be.
Second, prioritize data intelligently. With each packet, you want to start filling it with the most important data and only send less important data if you have space. With most recent state data, you want a heuristic that not only takes into account how long it has been since each object has been updated, but also how close it is to the player and how important it is for game purposes. A projectile moving toward the player at high speed is a lot more important than a vehicle driving slowly away in the distance.
Third, only send what you must. This saves bandwidth and prevents cheating. Checking can take a little work, but if you have any sort of zone, potentially visible set, or at a minimum a frustum, it works out pretty well—you only need to be mostly accurate to cut down on the worst offenses. You could also cast rays from the player’s eye position to potentially networked objects to determine if they should be considered visible. Skipping updates for invisible objects has big benefits. Ideally, the client will have no idea what is happening in the world other than what is directly relevant for the player, which saves on both bandwidth and on processing power.
Culling (i.e., only sending what you must) is different than prioritizing updates. In the case of low priority updates, you may still want the object to be known to the client. For instance a tree might be very low priority but still relevant. On the other hand, even though the movements of an enemy on the other side of a wall are highly relevant to a player, you might want to purposely omit information about it from the network stream until it is very nearly visible to the player, to prevent cheating.
There are a few other things to keep in mind with your packets. Make sure they are not too big. The maximum safe size for general Internet traffic is about 1,400 bytes—any bigger and you risk packets getting lost, corrupted, or truncated. A quick explanation of this limit: the MTU for Ethernet traffic is 1,500 bytes. Since most of the Internet runs over Ethernet, it is a good base size to plan around. If you then subtract some space for headers, compression/transmission overhead, etc., you end up with 1,400 bytes. Choosing this size also gives you some wiggle room if you end up needing to go a few bytes over sometimes.
Make sure that you send packets regularly. Routers allocate bandwidth to those who use it. If your bandwidth usage varies over time, routers tend to give bandwidth to other users. So the best policy is to send packets of fixed size at a fixed rate. For instance, you might send an 800-byte packet 10 times a second, using 8KB/sec of bandwidth. You can tune this based on player connection, server load, and many other factors.
Using fixed bandwidth/packet rate also exposes potential problems immediately for users. So instead of letting them get into the game, start doing something, and then experiencing bad play when the link becomes saturated with updates, if they can’t support the required traffic levels, the game fails immediately.
Optimizing your networking code follows the same cycle—profile, change, and measure again—as every other kind of optimization work. The bottlenecks are quite a bit different, though. Computation is usually not a bottleneck because the network link is so much slower. Usually, you are optimizing for user experience, which means minimizing latency and maintaining fidelity.
The first order of business is getting the OS to do what you want. Most applications just want to get bits from one end of a TCP connection to another in bulk—for instance, an FTP client—they don’t want to deal with the innards of the transport. The OS caters to this by default, but there is a cost in latency.
If your network IO thread is also your main game thread, you want to use nonblocking IO, so that you can do other productive work like drawing frames while waiting for your data to arrive. This is done on most operating systems by setting a flag—fcntl or ioctl are the usual APIs. write() and send() return once the data is in the queue to transmit, but read and recv can either wait until data is available to return, or return and indicate that no data was available. If the connection is set to be blocking, they will wait, which makes simple protocols work properly by default, since the connection acts just like a normal file stream. If the connection is set to nonblocking, then the application can detect that there is no new data and intelligently deal with it.
And that is the key to performant networking—dealing with it. The key to good networking performance is embracing the fundamental issues of networking. The OS will attempt to isolate you from this by buffering and delaying data so it looks like a linear stream, which is quite counter to what’s happening behind the scenes.
Speaking of buffering, if you are working with TCP, you need to be aware of Nagle’s Algorithm. Sending many small packets increases networking overhead, as the overhead for a TCP packet is about 40 bytes—41 bytes for each byte of network traffic is pretty useless! John Nagle’s enhancement is to combine writes so that full packets are sent. The flag that controls this is TCP_NODELAY (part of POSIX, so present on all OSes), and if you want to have more control over how your TCP packets are sent, it’s wise to set it.
However, trying to get TCP to do exactly what you want can be a fool’s errand. Sometimes, you’ll have to make do with TCP. But in most cases, it’s better to implement your own solution on top of UDP, because in addition to things like Nagel’s algorithm, there’s an unspecified amount of buffering and processing that happens not only in the networking stack in the operating system, but also potentially at every node along the route between you and the peer you are connected to. Traffic shapers and intelligent routers can buffer or even modify data en route based on the whims of network administrators. Virus scanners will delay delivery until they can determine that the data is free of viruses. Because TCP is easier to understand and work with on a per-connection basis, it is more often molested en route to client or server.
UDP is a much better option in terms of control. Because it is connectionless, most routing hardware and software leaves it alone, choosing either to send it or drop it. The bulk of Internet traffic is over TCP, so UDP often flies below the radar. Since it foregoes a stream abstraction, it’s not as easy to modify, either. It also directly exposes the nature of networked data transfer to you, so that you can intelligently handle lost, delayed, or out-of-order data.
Another issue that frequently comes up with networking is the desire to do more than there is bandwidth available to do. This is one of the main reasons why compression is such a well-developed field. For your typical telecommunications giant, bandwidth is a major limiting factor—the more phone calls they can fit on an intercontinental fiber optic link, the better their bottom line.
Compression lets you trade computing power, quality, and latency for reduced bandwidth usage. For instance, you can run a raw image through JPEG and get a much smaller representation of nearly the same thing. But you must have the whole image ready for compression to start, and you also have to wait for it to finish before you can send it.
The best way to optimize for bandwidth usage is to add some (or use existing) counters that count how many bytes or bits each type of data is using—a simple network profiler. From there, you can easily identify the largest consumer and work on reducing it, either by sending it less often or by making it take less data when you do send it.
Another source of performance overhead is the cost per connection. This is, of course, more of a concern for servers, although P2P nodes can be affected, too. For most networked services, sufficient popularity is indistinguishable from a denial of service attack. So you need to consider the costs related to each connection, both during the connection process as well as while the connection is active.
The risk during the connection process is that the server can allocate resources for that connection before it is sure it is a valid user. With poorly designed code, an attacker can initiate a large number of connections cheaply, using up all the server’s resources. Even in legitimate cases, a client might be unable to fully connect due to high traffic or firewalls, and keep retrying, wasting resources.
A good solution is to use client puzzles, small computational problems that clients must give the solution for before they are allowed to continue connecting. The server doesn’t have to maintain any state per clients until they solve the puzzle, so it’s very difficult for a DoS situation to occur.
Computational complexity and resource use when connections have been made are also important. If every connection takes up 100MB of RAM, you won’t be able to support as many users as if each one takes 100KB. Similarly, if you have algorithms that are O(n3), it will directly impact your ability to scale user count. Optimizing algorithms is well-trodden ground at this point in the book, so the only advice we need to add is to make sure you profile any networked application under heavy load. A good journaling system can be very useful in doing this.
Watch out for DNS lookups. Resolving a host name such as www.google.com to an IP address can be costly. The default APIs (gethostbyname) can block for a very long time (seconds to minutes) if they are trying to connect to an unknown host or one with slow name resolution. This isn’t a big deal for, say, a command line tool like ping, but for an interactive application it can be a big problem.
The common solution is to put DNS lookups on their own thread so that they are nonblocking. There are libraries and often OS APIs for doing asynchronous DNS lookups, too.
Any game can run well on a fast connection to a nearby server. The real test is what happens when a few packets get lost, or the player is on a bad connection, or there’s a misbehaving router in the way. The trick to good networking is embracing failure.
Assume high latency: Test with an artificial delay in your packet transmission/reception code. Latency of 100ms is a good starting assumption for hosts on the same coast as the player (Valve’s source engine, for instance, is configured with this assumption), and some players will encounter latency up to 500ms. You’ll have to figure out yourself where the bar is in terms of playable latency for your game, but make sure the system won’t break due to short-term problems—even the best connections can have bad days (or milliseconds).
Expect packet loss: If you are using UDP, add code to randomly drop packets. Loss rates of 20% are not unheard of. Packet loss tends to be bursty, so your system should be able to tolerate occasional periods of 20–30 seconds where no packets are received at all. (TCP, of course, will simply buffer and resend.)
Everyone is out to get you: A lot of the time, denial of service attacks are planned by hostile hackers. But they are also indistinguishable from periods of high demand. Bugs can also cause DoS scenarios, such as a client who doesn’t respect the timeout period between reconnections. Be paranoid and check everything. A good practice is to figure out what the worst thing that a client/peer could do, assume the client/peer will do it, and fix your code so it won’t break in that scenario.
One of the best ways to give users a great networked experience is to lie to them, blatantly and continuously. No, we don’t mean about your age. We mean about the state of the game.
The human eye is drawn to discontinuous or abrupt movement. If something jerks or pops, it gets attention. If something moves smoothly, even if it doesn’t move quite right, it’s less likely to get attention.
To this end, you want to interpolate and extrapolate whenever you can. If you get a position update for an object, smoothly move the object to that position rather than setting it immediately resulting in a pop. If you don’t get updates for something with predictable movement, you want to extrapolate via a client-side prediction until you get an authoritative update from the server.
This approach is known as dead reckoning. Since many objects tend to move in a reliable pattern, you can use heuristics on many different aspects of the physics for a given object. Linear interpolation may meet your needs for most cases, but if you still aren’t getting what you are looking for, try making educated guesses about the future path due to current velocity, mass, angular velocities, or drag. The more data you use, the better you can guess. But be careful, the longer you wait for the update, the more likely you are to have big errors in your guess. Correcting the “guess” can lead to unnatural movement, popping, or even frustrated players.
Most networking scenarios break down to one of the delivery types we mentioned previously. Let’s go through a few common situations.
A lot of games, even single player games, need to have updates or patches. An MMO might need to stream world resources. Or a game might need to interact with Web services. All of these are situations where you want bulk, guaranteed delivery of in-order data.
The most common solution is to use TCP. In many cases, if that’s all you need, HTTP is a good choice. Libraries like libcurl make it easy to add this functionality. For mass delivery of static data, HTTP is also great because it’s easy to deploy to a server farm or a content delivery network.
Content delivery networks, like CloudFront by Amazon or Akamai’s network, are server farms run by third parties, and are optimized for delivering large amounts of static content. Typically, they charge by the gigabyte of delivered content, and they include an API for uploading your own content to the service. They replicate data out to thousands of servers, eventually reaching edge servers. These edge servers use fast connections and geographic proximity to deliver fast downloads.
Streaming audio and video in real time is more challenging. Imagine a game with voice chat (or even video chat). The user will want to hear what’s being said now, not what was being said in the past, even if it means sacrificing some quality.
This is the simplest lossy scenario, because data only needs to be streamed out as quickly as possible, and if lost, no resending is necessary. You can think of it as a firehose—you let it spray data as fast as it can, and hope enough gets to where it needs to do the job.
This approach requires a lossy codec for your data. Luckily, there are a lot of good algorithms to choose from, since the telecommunications and cable industries have spent a lot of time and money developing them. Techniques like Linear Predictive Encoding are straightforward to implement and give acceptable results, although there are many advanced algorithms available for licensing.
Chat is a common scenario, and fairly easy to support. The messages must have guaranteed, ordered delivery. The bandwidth is not great. The logic is also fairly simple.
However, when you start targeting thousands or more simultaneous users, it becomes challenging—one has only to look at IRC to see the complexities there. But for your typical game of 10–100 players, chat is an easily solvable problem.
For chat, you can use things like LZW compression, Huffman encoding, and lookup tables with common words to reduce bandwidth usage. Human language is redundant, so compressible. It is easy to simply call zlib’s compress() on some text before sending it or to look for common words and encoding their table index instead of the actual word.
In addition, because chat is not nearly as latency sensitive as game actions, it can often be sent when convenient instead of at top priority.
Gameplay is more difficult. Latency is very important. In a game like an RTS or an FPS, you only care about the most recent state—unlike chat, where knowing what people have previously said is nearly as important as knowing what they are saying now!
One exception is for the object that is being actively controlled by the player. Obviously, this is less of a concern for an RTS than it is for an FPS. Only sending the most recent state doesn’t feel right when you have direct control. The solution there is to send frequent high-precision updates back from the server, and in addition, to transmit the move from each timestep to the server so that the player’s character exactly matches on client and server.
Beyond looking at latency and other characteristics of a network link, what are the possibilities for optimizing your networking? How can you guide your efforts to improve the play experience most efficiently?
Well, first, make sure that your networking code is executing efficiently. You should carefully identify any bottlenecks or time sinks and optimize them away. Use benchmarks and careful measurements to identify areas of waste with regards to compute or memory. In most games, networking code takes up minimal CPU time compared to rendering, physics, and gameplay.
Second, expose what your networking layer is doing, especially in terms of number of packets sent and how bandwidth is spent in each packet. Adding accounting code so you can dump the average update size for each type of object in the game can be invaluable for identifying problem areas.
Often, one type of object will make up the bulk of your network traffic, either because it is extremely numerous in your game world or it is poorly implemented. To get better network performance, all you have to do is reduce the number of bits spent on that object type, either by sending fewer updates or by reducing the update size. This is where tricks like sacrificing precision or using more efficient encoding come in handy. Look for opportunities to avoid sending updates at all.
Third, be aware of situations when the client and server get out of sync. This is jarring to players and should be minimized, especially when their player character is concerned.
Finally, be aggressive about optimizing for perceived latency. Time how long it takes (with the aid of a video camera) between the user physically manipulating an input and the game reacting. It should take only a single frame to acknowledge input and start giving feedback to the user, if you want your game to feel snappy.
There’s quite a bit of complexity here! While any game that truly maximizes its networked potential will have to take it into account right from the beginning, a lot of the functionality is finicky, difficult to get right, and the same from game to game. In other words, a perfect job for a library to handle for you!
There are a lot of good libraries out there for game networking. We highly recommend OpenTNL (www.opentnl.org). It is open source as well as licensable from GarageGames for commercial use. And, one of your friendly authors worked on it!
Of course, that’s not the only option. RakNet, ENet, and Quazal are also options. Quake 1–3 are all open source, and they all include their networking implementations. Unreal 2 and 3, Unity3D, and Torque have good networking, too.
As far as articles and talks, we can recommend the “Networking for Game Developers” (http://gafferongames.com/networking-for-game-programmers/) series by Glenn Fielder, as well as the “Robust, Efficient Networking” talk Ben Garney gave at Austin GDC ’08 (http://coderhump.com/austin08/). Every game programming gems book has a few good chapters on game networking, too. The original “Tribes” networking paper is instructive (although the docs for OpenTNL subsume it), as is Yahn Bernier’s paper on the networking in Valve’s games (http://developer.valvesoftware.com/wiki/Latency_Compensating_Methods_in_Client/Server_In-game_Protocol_Design_and_Optimization).
If you do decide to do your own networking, we recommend designing it into your game technology from the beginning and testing heavily in adverse conditions. It takes a lot of work to build a solid networked game, and too many games have it tacked on at the end as an afterthought.
Bottom line: Networking in games is about building great experiences for your players. Optimization—minimizing latency and bandwidth and maximizing the feeling of control—is the order of the day. This chapter has outlined the major factors that go into building an optimal networking experience, discussed how you can optimize networking, and given you pointers to resources for integrating good networking into your own game.