
Chapter 14. Denial of Service (DoS)
Perhaps one of the most popular types of attacks, and most widely publicized is the distributed denial of service (DDoS) attack.
This attack is a form of denial of service (DoS), in which a large network of devices flood a server with requests—hence slowing down the server or rendering it unusable for legitimate users.
DoS attacks come in many forms, from the well known distributed version which involves thousands or more coordinated devices—to code level DoS that affects a single user as a result of a faulty REGEX implementation which results in long times to validate a string of text.
DoS attacks also range in seriousness from reducing an active server to a functionless electric bill, to causing a user’s web page to load slightly slower than usual or pausing their video mid-buffer.
Because of this, it is very difficult to test for DoS attacks (in particular, the less severe ones) and most bug bounty programs outright ban DoS submissions in order to prevent bounty hunters from interfering with regular application usage.
Warning
Due to the fact that DoS vulnerabilities interfere with the usage of normal users via the application—it is most effective to test for DoS vulnerabilities in a local development environment where real users will not have service interruption.
With special cases as the exception, DoS attacks usually do not cause permanent damage to an application—but do interfere with the usability of an application for legitimate users. Depending on the specific DoS attack, sometimes it can be very difficult to find the DoS sink that is degrading the experience of your users.
Regex DoS (ReDoS)
Regular-expression based DoS vulnerabilities are some of the most often found forms of DoS in web applications today.
Generally speaking, these vulnerabilities range in risk from very minor to medium—often depending on the location of the REGEX parser.
Taking a step back—REGEX or Regular Expressions are often used in web applications to validate form fields and make sure the user is inputing text that the server expects.
Often times this means making the user experience such that the user can only input characters into a password field that the application has opted to accept, or only put a max amount of characters into a comment such that the full comment would display nicely when presented in the UI.
Regular expressions where originally designed by mathematicians studying formal language theory—regular expressions allowed mathematicians to define sets and subsets of strings in a very compact manner.
Almost every programming language on the web today includes its own REGEX parser, with JavaScript in the browser being no exception.
In JavaScript, REGEX are usually defined one of two ways:
constmyREGEX=/username/;// literal definition
constmyREGEX=newRegExp('username');// constructor
A complete lesson on regular expressions is beyond the scope of this book, but it is important to note that regular expressions are generally fast, and very powerful ways of searching or matching through text. They are definitely worth learning at least the basics of.
For this chapter’s sake, we should just know that anything between two forward slashes in JavaScript is a REGEX literal: /test/.
REGEX can also be used to match ranges:
constlowercase=/[a-z]/;constuppercase=/[A-Z]/;constnumbers=/[0-9]/;
We can combine these with logical operators, like “OR”:
constyouori=/you|i/;
And so on.
You can test if a string matches a regular expression easily in JavaScript:
constdog=/dog/;dog.test('cat');// falsedog.test('dog');// true
As mentioned, regular expressions are generally parsed really fast. It’s rare a regular expression functions slowly enough to slow down a web application.
That being said, regular expressions can be specifically crafted to run slowly. These are called malicious regexes (or sometimes “evil regex”), and are a big risk of allowing users to provide their own regular expressions for use in other web forms or on a server.
Malicious REGEX’s can also be introduced to an application accidentally, although this is probably a rare case where a developer was not familiar enough with REGEX to avoid a few common mistakes.
Generally speaking, most malicious REGEX are formed using the plus “+” operator which changes the REGEX into a “greedy” operation. Greedy REGEX test for one or more matches, rather than stopping at the first match found.
Next off, the malicious REGEX will result in backtracking whenever it finds a failure case.
Consider the REGEX: /^((ab)*)+$/
This REGEX does the following:
-
At start of line defines capture group ((ab)*)+
-
(ab)* suggests matching between 0 and infinite combinations of “ab”
-
+ suggests finding every possible match for #2
-
$ suggests matching until the end of the string
Testing this REGEX with the input abab will actually run pretty quick and not cause much in the way of issues.
Expanding the pattern outwards, ababababababab will also run quite fast.
If we modify the pattern above, to abababababababa with an extra “a”—suddenly the regex will evaluate slowly potentially taking a few milliseconds to complete.
This occurs because the REGEX is valid until the end, in which case the engine will backtrack and try to find combination matches.
-
(abababababababa) is not valid
-
(ababababababa)(ba) is not valid
-
(abababababa)(baba) is not valid
-
many iterations later: (ab)(ab)(ab)(ab)(ab)(ab)(ab)(a) is not valid
Essentially, because the REGEX engine is attempting to exhaustively try all possible valid combinations of (ab)—it will have to complete a number of combinations equal to the length of the string before determining the string itself is not valid (after checking all possible combinations).
A quick attempt of this using a REGEX engine shows:
| Input | Execution Time |
|---|---|
abababababababababababa (23 chars) |
8ms |
ababababababababababababa (25 chars) |
15ms |
abababababababababababababa (27 chars) |
31ms |
ababababababababababababababa (29 chars) |
61ms |
-
As you can see, the input constructed for breaking the REGEX parser using this evil or malicious REGEX results in the time for the parser to finish matching doubling with every two characters added. This continues onwards and eventually will easily cause significant performance reduction on a web server (if computed serverside) or totally crash a web browser (if computed client side).
Interestingly enough this malicious REGEX is not vulnerable to all inputs, as a chart of properly formed inputs will show:
| Input | Execution Time |
|---|---|
ababababababababababab (22 chars) |
<1ms |
abababababababababababab (24 chars) |
<1ms |
ababababababababababababab (26 chars) |
<1ms |
abababababababababababababab (28 chars) |
>1ms |
This means that a malicious regular expression used in a web application could lay dormant for years until a hacker found an input that caused the REGEX parser to perform significant backtracking—hence appearing out of nowhere.
REGEX DoS attacks are more common than expected, and can easily take down a server or render client machines useless if the proper payload can be found.
It should be noted that open source software (OSS) is often more vulnerable to malicious REGEX as few developers are capable of seeing a malicious REGEX making pull-requests with such features easier than expected.
Logical DoS Vulnerabilities

Figure 14-1. DoS—server resources are drained by an illegitimate user, as a result legitimate users experience performance degradation or loss of service.
REGEX is an easy introduction to DoS vulnerabilities and exploiting DoS because it provides a centralized starting place to researching and attempting attacks (anywhere a REGEX parser is present).
It is important to note however, that due to the expansive nature of DoS—DoS vulnerabilities can be found in almost any type of software!
Logical DoS vulnerabilities are some of the hardest to find and exploit, but appear more frequently in the wild than expected. These require a bit of expertise to pin down and take advantage of, but after mastering techniques for finding a few you will probably be able to find many.
First off, we need to think about what makes a DoS attack work.
Denial of service attacks are usually based around consuming server or client hardware resources—hence leaving them unavailable for legitimate purposes.
This means, we want to first look for occurrences in a web application that are resource intensive. A non extensive list could be:
-
Any operation you can confirm operates synchronously
-
Database writes
-
Drive writes
-
SQL Joins
-
File backups
-
Looping Logical Operations
Often, complex API calls in a web application will contain not only one but multiple of the above operations.
For example, a photo sharing application could expose an API route that permits a user to upload a photo.
During upload, this application could perform:
-
Database writes (store metadata regarding the photo)
-
Drive writes (log that the photo was uploaded successfully)
-
SQL Join (to accumulate enough data on the user and albums to populate the metadata write)
-
File backup (in case of catastrophic server failure)
We cannot easily time the duration of these operations on a server we do not have access to, but we can use a combination of timing and estimation to determine which operations are longer than others.
For example, we could start by timing the request from start to finish. This could be done using the browser developer tools.
We can test if an operation occurs synchronously on the server by making the same request multiple times at once, and seeing if the responses are staggered.
Each time we do this we should script it and average out perhaps 100 API calls so our metrics are not set off by random difference. Perhaps the server gets hit by a traffic spike when we are testing, or begins a resource intensive Cron job. Averaging out request times will give us a more accurate measure of what API calls take significant time.
We can also approximate the structure of back end code by closely analyzing network payloads and the UI. If we know the application supports multiple types of objects:
-
User object
-
Album object (user HAS album)
-
Photo object (album HAS photos)
-
Metadata object (photos HAVE metadata)
We can then see that each child object is referenced by an id:
//photo#1234{image:data,metadata:123abc}
That we might assume that users, albums, photos and metadata are stored in different tables or documents depending on if the database used is SQL or NoSQL.
If in our UI we issue a request to find all metadata associated with a user, then we know a complex joins operation or iterative query must be running on the backend. Let’s assume this operation is found at an endpoint GET /metadata/:userid.
Plus we know that the scale of this operation varies significantly depending on the way a user uses the application, so a power user may require significant hardware resources to perform this operation while a new user would have the operation perform rapidly.
We can test this operation and see how it scales:
| Account Type | Response Time |
|---|---|
New Account (1 album, 1 photo) |
120ms |
Average Account (6 albums, 60 photos) |
470ms |
Power User (28 albums, 490 photos) |
1870ms |
Given the way the operation scales based on user account archetype, we can deduce that we could create a profile designed to eat up server resource time via GET /metadata/:userid.
If we write a client-side script to re-upload the same or similar images into a wide net of albums, we could have an account with 600 albums and 3500 photos.
Afterwards, simply performing repeated requests against the GET /metadata/:userid endpoint would result in significant reduction in server performance for other users unless the server side code is extremely robust and limits resources on a per request basis.
It’s possible these requests would just time out, sure—but the database would be likely still be coordinating resources even if the server software times out and doesn’t send the result back to the client performing the request.
That’s just an example of how logical DoS attacks are found and exploited, and of course these attacks differ on a case by case basis—hence “logical” as defined by the particular application logic in an application you are exploiting.
Distributed DoS (DDoS)
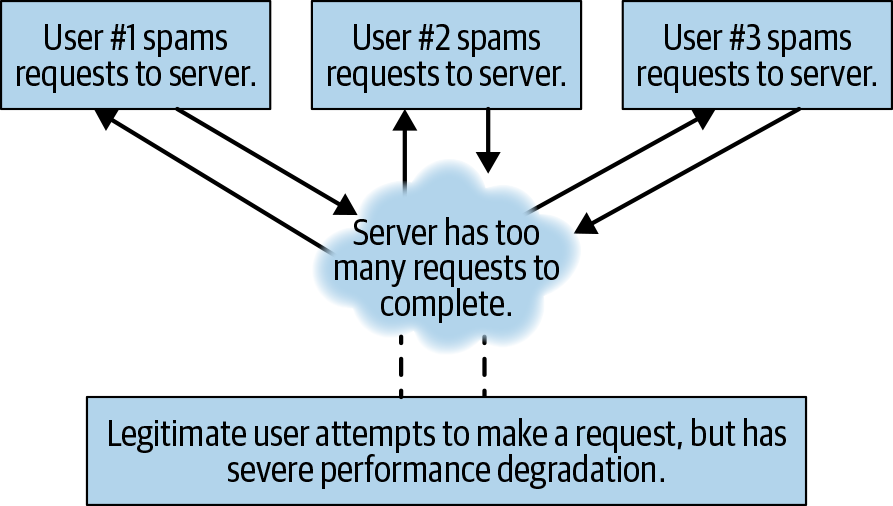
Figure 14-2. DDoS—server resources are drained by an large number of illegitimate users. Because they are requesting en-masse they may even be able to perform standard requests, but at scale this will drown out server resources for legitimate users.
Distributed Denial of Service attacks are a bit outside of the scope of this book to cover comprehensively, but you should be familiar with how they work at least conceptually.
Unlike DoS attacks where a single hacker is targeting either another client or a server to slow down, distributed attacks involve multiple attackers.
The attackers can be other hackers, or networked bots (aka “botnets”).
Theoretically these bots could exploit any type of DoS attack—but on a wider scale. For example, if a server utilizes REGEX in one of it’s API endpoints a botnet could have multiple clients sending malicious payloads to the same API endpoint simultaneously.
In practice however, most DDoS attacks do not perform logical or REGEX based DoS and instead attack at a lower level (usually network level, instead of application level).
Most botnet based DDoS attacks will make requests directly against a server’s IP address, and not against any specific API endpoint. These requests usually are UDP traffic in an attempt to drown out the server’s available bandwidth for legitimate requests.
As you would imagine, these “botnets” are not usually devices all owned by a single hacker—but instead devices that a hacker or group of hackers has taken over via malware distributed on the internet. Real computers owned by real people but with software installed that allows them to be controlled remotely. This is a big issue because it makes detecting the illegitimate clients much harder (are they real users?).
In the case that you gain access to a botnet, or can simulate a botnet for security testing purposes—it would be wise to try a combination of both network and application level attacks.
Any of the aforementioned DoS attacks that run against a server are vulnerable to DDoS. Generally speaking, DDoS attacks are not effective against a single client—although perhaps seeding massive amounts of REGEX vulnerable payloads that would later be delivered to a client device and executed could be in scope for DDoS.
Summary
Classic distributed denial of service (DDoS) attacks are by far the most recognized form of DDoS, but they are just one of many attacks that seek to consume server resources so that legitimate users cannot.
Denial of service attacks can happen at many layers in the application stack—from the client, to the server, and in some cases even at the network layer.
These attacks can affect one user at a time, or a multitude of users and the damage can range from reduced application performance to complete application lockout.
When looking for denial of service attacks, it’s best to investigate which server resources are the most valuable—and start trying to find API’s which make use of those resources.
The value of server resources can differ from application to application, but could be something standard like RAM/CPU usage—or more complicated like functionality performed in a queue (user a → user b → user c, etc).
While typically only causing annoyance or interruption, some DoS attacks can leak data as well. Be on the look out for logs and errors that appear as the result of any DoS attempts.