
Chapter 3. The Structure of a Modern Web Application
Prior to being able to effectively evaluate a web application for recon purposes, it is best to gain an understanding of the common technologies that many web applications share as dependencies.
These dependencies span from JavaScript helper libraries and predefined CSS modules all the way to web servers and even operating systems.
By understanding the role of these dependencies and their common implementation in an applications stack—it becomes much easier to quickly identify them and look for misconfigurations.
Modern Versus Legacy Web Applications
Today’s web applications are often built on top of technology that didn’t exist ten years ago.
The tools available for building web applications have advanced so much in that timeframe that sometimes it seems like an entirely different specialization today.
A decade ago, most web applications where built using server-side frameworks that rendered an HTML/JS/CSS page that would then be sent to the client. Upon needing an update the client would simply request another page from the server to be rendered and piped down over HTTP.
Shortly after that, web applications began making use of HTTP more frequently with the rise of AJAX (asynchronous JavaScript and XML) allowing network requests to be made from within a page session via JavaScript.
Today many applications actually are more properly represented as two or more applications communicating via a network protocol, versus a single monolithic application. This is one major architectural difference between the web applications of today and the web applications of a decade ago.
Often times today’s web applications are comprised of several applications connected with a Representational State Transfer (REST) API. These API’s are stateless and only exists to fulfill requests from one application to another. This means they don’t actually store any information regarding the requester.
Many of today’s client (UI) applications run in the browser in ways more akin to a traditional desktop application. These client applications manage their own lifecycle loops, request their own data, and do not require a page reload after the initial bootstrap is complete.
It is not uncommon for a standalone application deployed to a web browser to communicate with a multitude of servers. Consider an image hosting application that allows user login—it likely will have a specialized hosting/distribution server located at one URL, and a separate URL for managing the database and logins.
It’s safe to say that today’s applications are often actually a combination of many separate but symbiotic applications working together in unison. This can be attributed to the development of more cleanly defined network protocols and API architecture patterns.
The average modern day web application probably makes use of several of the following technologies:
-
REST API
-
JSON or XML
-
JavaScript
-
SPA Framework (React, Vue, EmberJS, AngularJS)
-
An authentication and authorization system
-
One or more webservers (typically on a Linux server)
-
One or more webserver software packages (ExpressJS, Apache, NginX)
-
One or more databases (MySQL, MongoDB, etc.)
-
A local data store on the client (Cookies, Web Storage, IndexDB)
Note
This is not an exhaustive list, and considering there are now billions of individual websites on the internet—it is not feasible to cover all web application technologies in this book.
You should make use of other books and coding websites like Stack Overflow if you need to get up to speed with a specific technology not listed in this chapter.
Some of these technologies existed a decade ago, but it wouldn’t be fair to say they have not changed in that timeframe. Databases have been around for decades, but NoSQL databases and client-side databases are definitely a more recent development. The development of full-stack JavaScript applications was also not possible until NodeJS and NPM began to see rapid adoption.
The landscape for web applications has been changing so rapidly in the last decade or so that many of these technologies have gone from unknown to nearly everywhere.
There are even more technologies on the horizon: for example the Cache API for storing requests locally and Web Sockets as an alternative network protocol for client to server (or even client to client) communication. Eventually browsers intend to fully support a variation of assembly code known as web assembly, which will allow non JavaScript languages to be used for writing client-side code in the browser.
Each of these new and upcoming technologies bring with it new security holes to be found and exploited for good or for evil. It is an exciting time to be in the business of exploiting or securing web applications.
Unfortunately I cannot give an explanation regarding every technology in use on the web today—that would require it’s own book! But the remainder of this chapter will give an introduction to the technologies listed above. Feel free to focus on the ones you are not yet intimately familiar with.
REST API’s
REST stands for “Representational State Transfer”, which is a fancy way of defining an API that has a few unique traits:
-
It must be separate from the client REST API’s are designed for building highly scalable but also simple web applications. Separating the client from the API but following a strict API structure makes it easy for the client application to request resources from the API without being able to make calls to a database or perform server-side logic itself.
-
It must be stateless REST API’s are by design API’s that only take inputs and provide outputs. The API’s must not store any state regarding the client connecting. This does not mean however, that a REST API cannot perform authentication / authorization—instead authorization should be tokenized and sent on every request.
-
It must be easily cacheable In order to properly scale a web application delivered over the internet a REST API must be able to easily mark it’s responses as cachable or not. Because REST also includes very tight definitions on what data will be served from what endpoint, this is actually very easy to configure on a properly designed REST API. Ideally the caches should be programmatically managed as to not accidentally leak privileged information to another user.
-
Each endpoint should define a specific object or method. Typically these are defined hierarchically for example
/moderators/joe/logs/12_21_2018. In doing so, REST API’s can easily make use of HTTP verbs like GET, POST, PUT, DELETE. As a result of this, one endpoint with multiple HTTP verbs becomes self documenting.
Want to modify the moderator account “joe”, PUT /moderators/joe. Want to delete the 12_21_2018 log? All it takes is a simple deduction: DELETE /moderators/joe/logs/12_21_2018.

Figure 3-1. Swagger—an automatic API documentation generator designed for easy integration with REST APIs. Because REST APIs follow a well defined architectural pattern, tools like Swagger can easily integrate into an application and document the endpoints so it is easier for other developers to pick up an endpoint’s intentions.
In the past, most web applications used SOAP structured API’s. REST has several advantages over SOAP:
-
Requests target data, not functions
-
Easy Caching of requests
-
Highly scalable
Furthermore, while SOAP API’s must utilize XML as their in-transit data format REST API’s can accept any data format, but typically JSON is used. JSON is much more lightweight (less verbose) and easier for humans to read than XML which also gives REST an edge against the competition.
Here is an example payload written in XML.
<user><username>joe</username><password>correcthorsebatterystaple</password><email>[email protected]</email><joined>12/21/2005</joined><client-data><timezone>UTF</timezone><operating-system>Windows 10</operating-system><licenses><videoEditor>abc123-2005</videoEditor><imageEditor>123-456-789</imageEditor></licenses></client-data></user>
And similarly, the same payload written in JSON.
{"username":"joe","password":"correcthorsebatterystaple","email":"[email protected]","joined":"12/21/2005","client_data":{"timezone":"UTF","operating_system":"Windows 10","licenses":{"videoEditor":"abc123-2005","imageEditor":"123-456-789"}}}
Most modern web applications you will run into either make use of RESTful API’s, or a REST-like API that serves JSON. It is becoming increasingly rare to encounter SOAP API’s and XML outside of specific enterprise apps that maintain such rigid design for legacy compatibility.
Understanding the structure of REST API’s is important as you attempt to reverse engineer a web applications API layer. Mastering the basic fundamentals of REST APIs will give you an advantage as you will find many API’s you wish to investigate follow REST architecture—but additionally many tools you may wish to use or integrate your workflow with will be exposed via REST API’s.
JavaScript Object Notation (JSON)
REST is an architecture specification which defines how HTTP verbs should map to resources (API endpoints & functionality) on a server.
Most REST API’s today use JSON as their in-transit data format.
Consider this: an application’s API server must communicate with its client (usually some code in a browser or mobile app). Without a client/server relationship we cannot have stored state across devices, and persist that state between accounts. All state would have to be stored locally.
Because modern web applications require a lot of client/server communication (for the downstream exchange of data, and upstream requests in the form of HTTP verbs)—it is not feasible to send data in ad-hoc formats. The in-transit format of the data must be standardized.
JSON is one potential solution to this problem. JSON is an open-standard (aka not proprietary) file format that meets a number of interesting requirements:
-
It is very lightweight (reduces network bandwidth)
-
It requires very little parsing (reduces server / client hardware load)
-
It is easily human readable
-
It is hierarchical (can represent complex relationships between data)
-
JSON objects are represented very similarly to JavaScript objects, making consumption of JSON and building new JSON Objects quite easy in the browser.
All major browsers today support the parsing of JSON natively (and fast!), which in addition to the bullet points above makes JSON a great format transmitting data between a stateless server and a web browser.
The following JSON:
{"first":"Sam","last":"Adams","email":"[email protected]","role":"Engineering Manager","company":"TechCo.","location":{"country":"USA","state":"california","address":"123 main st.","zip":98404}}
Can be parsed into a Javascript object in the browser easily:
constjsonString=`{"first": "Sam","last": "Adams","email" "[email protected]","role": "Engineering Manager","company": "TechCo.","location": {"country": "USA","state": "california","address": "123 main st.","zip": 98404}}`;// convert the string sent by the server to an objectconstjsonObject=JSON.parse(jsonString);
JSON is flexible, lightweight and easy to use. It is not without it’s drawbacks, as any lightweight format has tradeoffs compared to heavyweight alternatives. These will be discussed later on in the book we we evaluate specific security differences between JSON and it’s competitors, but for now it’s important to just grasp that a significant amount of network requests between browsers and servers are sent as JSON today.
Get familiar with reading through JSON strings, and consider installing a plugin in your browser or code editor to format JSON strings. Being able to rapidly parse these and find specific keys you are looking for will be very valuable when penetration testing a wide variety of API’s in a small timeframe.
JavaScript
Throughout this book we will continually discuss “client & server” applications.
A server is a computer (typically a powerful one) which resides in a data center (sometimes called “the cloud”) and is responsible for handling requests to a website. Sometimes these servers will actually be a cluster of many servers, other times it might just be a single light-weight server used for development or logging.
A client on the other hand is any device a user has access to, that a user manipulates in order to make use of a web application. A client could be a mobile phone, a mall kiosk, or a touchscreen in an electric car—but for our purposes it will usually just be a web browser.
Servers can be configured to run almost any software you could imagine, in any language you could imagine. Web servers today run on Python, Java, JavaScript, C++, etc.
Clients on the other hand, in particular the browser do not have that luxury. JavaScript is not only a programming language, but the sole programming language for client-side scripting in web browsers.
Throughout this book many code examples will be written in JavaScript, when possible the back-end code examples will be written using a JavaScript syntax as well so that no time is wasted context switching.

Figure 3-2. JavaScript—a dynamic programming language that was originally designed for use in internet browsers. JavaScript now is used in many applications from mobile to IoT.
I’ll try to keep the JavaScript as clean and simple as possible, but might use some constructs that JavaScript supports that are not as popular (or well known) in other languages.
Furthermore, JavaScript is a unique language as development is tied to the growth of the browser, and it’s partner the DOM. As a result of this, there are some quirks you might want to be aware of before heading forwards.
Variables and Scope
In ES6 JavaScript (a recent version), there are four ways to define a variable:
// global definitionage=25;// function scopedvarage=25;// block scopedletage=25;// block scoped, without re-assignmentconstage=25;
These all may appear similar, but they are functionally very different.
age = 25 Without including an identifier like var, let, or const any variable you define will get hoisted into global scope. This means that any other object defined as a child of the global scope will be able to access that variable. Generally speaking, this is considered a bad practice and we should stay away from it. (it could also be the cause of significant security vulnerabilities or functional bugs).
It should be noted that all variables lacking an identifier will also have a pointer added to the window object in the browser:
// define global integerage=25;// direct call (returns 25)console.log(age);// call via pointer on window (returns 25)console.log(window.age);
This of course can cause namespacing conflicts on window (an object the browser DOM relies on to maintain window state), which is another good reason to avoid it.
var age = 25 Any variable defined with the identifier var is scoped to the nearest function, or globally if there is no outer function block defined (in the global case, it appears on window similarly to an identifier-less variable as above).
This type of variable is a bit confusing, which is probably part of the reason let was eventually introduced.
constfunc=function(){if(true){// define age inside of if blockvarage=25;}/** logging age will return 25** this happens because the var identifier binds to the nearest* function, rather than the nearest block.*/console.log(age);};
In the example above, a variable is defined using the var identifier with a value of 25. In most other modern programming languages, age would be undefined when trying to log it. Unfortunately, var doesn’t follow these general rules and scopes itself to functions rather than blocks. This can lead new JavaScript developers down a road of debugging confusion.
let age = 25 ECMAScript 6 (a specification for JavaScript) introduced let and const—two ways of instantiating an object that act more similarly to those in other modern languages.
As you would expect let is block scoped. That means:
constfunc=function(){if(true){// define age inside of if blockletage=25;}/** This time, console.log(age) will return `undefined`.** This is because `let`, unlike `var` binds to the nearest block.* Binding scope to the nearest block, rather than the nearest function* is generally considered to be better for readability, and* results in a reduction of scope-related bugs.*/console.log(age);};
const age = 25 const much like let is also block scoped, but also cannot be reassigned. This makes it similar to a final variable in a language like Java.
constfunc=function(){constage=25;/** This will result in: TypeError: invalid assignment to const `age`** Much like `let`, `const` is block scoped.* the major difference is that `const` variables do not support* reassignment after they are instantiated.** If an object is declared as a const, it's properties can still be* changed. As a result, `const` ensures the pointer to `age` in memory* is not changed, but does not care if the value of `age` or a property* on `age` changes.*/age=35;};
In general, you should always strive to use let and const in your code to avoid bugs and improve readability.
Functions and Context
In JavaScript, functions are Objects. That means they can be assigned and re-assigned using the variables and identifiers from the last subchapter.
These are all functions:
// anonymous functionfunction(){};// globally declared named functiona=function(){};// function scoped named functionvara=function(){};// block scoped named functionleta=function(){};// block scoped named function without re-assignmentconsta=function(){};// anonymous function inheriting parent context()=>{};// immediately invoked function expression (IIFE)(function(){})();
The first function is an anonymous function—that means it can’t be referenced after it is created.
The next four are simply functions with scope specified based on the identifier provided. This is very similar to how we created variables for age previously.
The sixth function is a short-hand function, it shares context with it’s parent. (more on that soon).
The final function is a special type of function you will probably only find in JavaScript, known as an IIFE—self-invoking-function-expression. This is a function that fires immediately when loaded and runs inside of its own namespace—these are used by more advanced JavaScript developers to encapsulate blocks of code from being accessible elsewhere.
What is context?
If you can write code in any other (non-JavaScript) language, there are five things you will need to learn to become a good JavaScript developer: Scope, Context, Prototypal Inheritance, Asynchrony, and the Browser DOM.
Every function in JavaScript has it’s own set of properties and data attached to it. We call these the function’s “context”.
Context is not set in stone, and can be modified during runtime. Objects stored in a function’s context can be referenced using the keyword this.
constfunc=function(){this.age=25;// will return 25console.log(this.age);};// will return undefinedconsole.log(this.age);
As you can imagine, many annoying programming bugs resulted as a result of context being hard to debug—especially when some object’s context has to be passed to another function.
JavaScript introduced a few solutions to this problem to aid developers in sharing context between functions:
// create a new getAge() function clone with the context from ageData// than call it with the param 'joe'constgetBoundAge=getAge.bind(ageData)('joe');// call getAge() with ageData context and param joeconstboundAge=getAge.call(ageData,'joe');// call getAge() with ageData context and param joeconstboundAge=getAge.apply(ageData,['joe']);
These three functions, bind, call and apply allow developers to move context from one function to another. The only difference between call and apply is one takes list of arguments (call) and the other takes an array of arguments (apply).
The two can be interchanged easily:
// destructure array into listconstboundAge=getAge.call(ageData,...['joe']);
Another new addition to aid programmers in managing context is the arrow func‐ tion, also called “short hand function”. This function inherits context from its parent, allowing context to be shared from a parent function to the child without requiring explicit calling/applying or binding.
// global contextthis.garlic=false;// soup recipeconstsoup={garlic:true};// standard function attached to soup objectsoup.hasGarlic1=function(){console.log(this.garlic);}// true// arrow function attached to global contextsoup.hasGarlic2=()=>{console.log(this.garlic);}// false
Mastering these ways of managing context will make reconnaissance through a JavaScript based server, or client much easier and much faster. You might even find some language-specific vulnerabilities that arise from these complexities.
Prototypal Inheritance
Unlike many traditional server-side languages that suggest using an class-based inheritance model, JavaScript has been designed with a highly flexible prototypal inheritance system.
Unfortunately, because few languages make use of this type of inheritance system—it is often disregarded by developers, many of whom try to convert it to a class based system.
In a class based system, classes operate like blueprints defining objects. In class based systems, classes can inherit from other classes and create hierarchical relationships in this manner.
In a language like Java, subclasses are generated with the extends keyword or instanced with the new keyword.
JavaScript does not truly support these types of classes, but because of how flexible prototypal inheritance is—it is possible to mimic the exact functionality of classes with some abstraction on top of JavaScript’s prototype system.
In a prototypal inheritance system, like in JavaScript—any object created has a property attached to it called prototype. The prototype property, comes with a constructor property attached which points back to the function who owns the prototype.
This means that any object can be used to instantiate new objects, since the constructor points to the object that contains the prototype containing the constructor.
This may be confusing, but here is an example:
/** A vehicle pseudo-class written in JavaScript.** This is simple on purpose, in order to more clearly demonstrate* prototypal inheritance fundamentals.*/constVehicle=function(make,model){this.make=make;this.model=model;this.=function(){return`${this.make}:${this.model}`;};};constprius=newVehicle('Toyota','Prius');console.log(prius.());
When any new object is created in JavaScript, a separate object is also created called __proto__. This object points to the prototype who’s constructor was invoked during the creation of said object.
This allows for comparison between objects like such:
constprius=newVehicle('Toyota','Prius');constcharger=newVehicle('Dodge','Charger');/** As we can see, the "prius" and "charger" objects where both* created based off of "Vehicle".*/prius.__proto__===charger.__proto__;
Often times the prototype on an object will be modified by developers, leading to confusing changes in a web application’s functionality.
Most notably, because all objects in JavaScript are mutable by default—a change to prototype properties can happen at any time during runtime.
Interestingly, this means that unlike in more rigidly designed inheritance models—JavaScript inheritance trees can change at runtime. Objects can morph at runtime as a result of this:
constprius=newVehicle('Toyota','Prius');constcharger=newVehicle('Dodge','Charger');/** This will fail, because the Vehicle object* does not have a "getMaxSpeed" function.** Hence, objects inheriting from Vehicle do not have such a function* either.*/console.log(prius.getMaxSpeed());// Error: getMaxSpeed is not a function/** Now we will assign a getMaxSpeed() function to the prototype of Vehicle,* all objects inheriting from Vehicle will be updated in realtime as* prototypes propagate from the Vehicle object to it's children.*/Vehicle.prototype.getMaxSpeed=function(){return100;// mph};/** Because the Vehicle's prototype has been updated, the* getMaxSpeed function will now function on all child objects.*/prius.getMaxSpeed();// 100charger.getMaxSpeed();// 100
Prototypes take a while to get used to, but eventually their power and flexibility outweigh any difficulties present in the learning curve.
Prototypes are especially important to understand when delving into JavaScript security, because few developers fully understand them.
Additionally, due to the fact that prototypes propagate to children when modified—a special type of attack is found in JavaScript-based systems called “Prototype Pollution”. This attack involves modification to a parent JavaScript object, hence unintentionally changing the functionality of children objects.
Asynchrony
Asynchrony is one of those “hard to figure out, easy to remember” concepts that seem to come along frequently in network programming.
Because browsers must communicate with servers on a regular basis, and the time between request and response is non-standard (aka factor in payload size, latency, server processing time)—asynchrony is used often on the web to handle such variation.
In a synchronous programming model, operations are performed in the order they occur. For example:
console.log('a');console.log('b');console.log('c');// a// b// c
In the case above, the operations occur in order—hence reliably spelling out “abc” every time these three functions are called in the same order.
In an asynchronous programming model, the three functions may be read in the same order by the interpreter each time—but may not resolve in the same order.
Consider this example relying on an asynchronous logging function:
// --- Attempt #1 ---async.log('a');async.log('b');async.log('c');// a// b// c// --- Attempt #2 ---async.log('a');async.log('b');async.log('c');// a// c// b// --- Attempt #3 ---async.log('a');async.log('b');async.log('c');// a// b// c
The second time the logging functions where called, they did not resolve in order. Why?
When dealing with network programming, often requests take variable amounts of time, time-out and operate unpredictably.
In JavaScript-based web applications, this is often handled via asynchronous programming models rather than simply waiting for a request to complete prior to initiating another. The benefit of doing so is a massive performance improvement, that can be dozens of times faster than the synchronous alternative.
Instead of forcing requests to complete one after another, we initiate them all at the same time and than program what they should do upon resolution—prior to resolution occurring.
In older versions of JavaScript, this was usually done with a system called callbacks:
constconfig={privacy:public,acceptRequests:true};/** First request a user object from the server.* Once that has completed, request a user profile from the server.* Once that has completed, set the user profile config.* Once that has completed, console.log "success!"*/getUser(function(user){getUserProfile(user,function(profile){setUserProfileConfig(profile,config,function(result){console.log('success!');});});});
While callbacks are extremely fast and efficient, compared to a synchronous model—they are very difficult to read and debug.
A later programming philosophy suggested creating a re-usable object that would call the next function once a given function was completed. These are called promises, and are used in many programming languages today.
constconfig={privacy:public,acceptRequests:true};/** First request a user object from the server.* Once that has completed, request a user profile from the server.* Once that has completed, set the user profile config.* Once that has completed, console.log "success!"*/constpromise=newPromise((resolve,reject)=>{getUser(function(user){if(user){returnresolve(user);}returnreject();});}).then((user)=>{getUserProfile(user,function(profile){if(profile){returnresolve(profile);}returnreject();});}).then((profile)=>{setUserProfile(profile,config,function(result){if(result){returnresolve(result);}returnreject();});}).catch((err)=>{console.log('an error occured!');});
Both of the above accomplish the same exact application logic. The difference is in readability and organization. The promise based approach can be broken up further, grows vertically instead of horizontally and makes error handling much easier.
Promises and callbacks are interoperable and can be used together, depending on programmer preference.
The latest method of dealing with asynchrony is that of the async function. Unlike normal function objects, these functions are designed to make dealing with asynchrony a cake-walk.
Consider the following async function:
constconfig={privacy:public,acceptRequests:true};/** First request a user object from the server.* Once that has completed, request a user profile from the server.* Once that has completed, set the user profile config.* Once that has completed, console.log "success!"*/constsetUserProfile=asyncfunction(){letuser=awaitgetUser();letuserProfile=awaitgetUserProfile(user);letsetProfile=awaitsetUserProfile(userProfile,config);};setUserProfile();
You may notice this is so much easier to read—great, that’s the point!
Async functions turn functions into promises. Any method call inside of the promise with “await” before it will halt further execution within that function until the method call resolves.
Code outside of the async function can still operate as normal.
Essentially, the async function turns a normal function into a promise. You will see these more and more in client-side code, and JavaScript-based server side code as time goes on.
Browser DOM
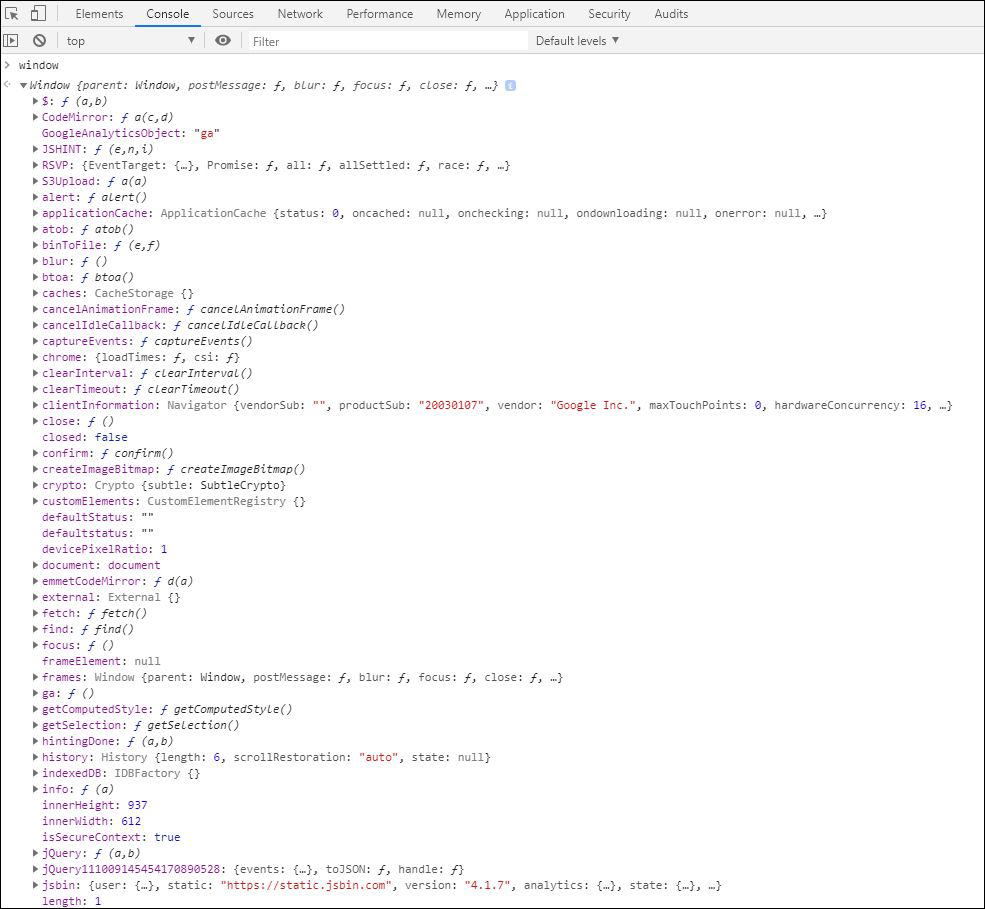
Figure 3-3. Document Object Model (DOM)—a hierarchical representation data used to manage state in modern web browsers. The specification is maintained by W3C DOM and WHATWG DOM committees, but implemented in all major browsers. Shown is the window object, one of the top-most standard objects defined by the DOM specification.
You should have sufficient understanding of asynchronous programming—the model that is dominate on the web and in client/server applications.
With that information in your head, the final JavaScript related concept you should be aware of is that of the browser DOM.
JavaScript is a programming language, and like any good programming language it relies on a powerful standard library. This library, unlike standard libraries in other languages—is known as the Document Object Model (DOM).
It provides routine functionality which is well tested and performant, and is implemented to a standard across all major browsers so your code should function identically or nearly identically regardless of the browser it is run on.
Unlike other standard libraries, the DOM exists not to plug functionality holes in the language or provide common functionality (that is a secondary function of the DOM) but mainly to provide a common interface from which to define a hierarchical tree of of nodes which represents a web page.
You have probably accidentally called a DOM function, and assumed it was a JS function. An example of this is document.querySelector() or document.implementation.
The main objects that make up the DOM are window and document—each carefully defined in a specification maintained by an organization called WhatWG: https://dom.spec.whatwg.org/
Regardless of if you are a JavaScript developer, web application pen tester, or security engineer—developing a deep understanding of the browser DOM and it’s role in a web application is crucial to spotting vulnerabilities that become evident at the presentation layer in an application.
Consider the DOM to be the framework from which JavaScript-based applications are deployed to end-users, and keep in mind that not all script-related security holes will be as the result of improper JavaScript, but sometimes by improper browser DOM implementation.
SPA Frameworks

Figure 3-4. VueJS—a popular single-page application framework that builds on top of web components.
Older websites where usually built on a combination of ad-hoc script to manipulate the DOM, and a lot of re-used HTML template code.
This was not a scalable model, and while it worked for delivering static content to an end-user—it did not work for delivering complex, logic rich applications.
Desktop application software at the time was robust in functionality, allowing for users to store, and maintain application state. Websites in the old days did not provide this type of functionality, although many companies would have preferred to deliver their complex applications by the web as it provided many benefits from ease of use to piracy prevention.
Single Page Web Application (SPA) frameworks where designed to bridge the functionality gap between websites and desktop applications.
SPA frameworks allow for the development of complex JavaScript-based applications that store their own internal state, are comprised of reusable UI components each of whom has it’s own self-maintained lifecycle from rendering to logic execution.
SPA frameworks are rampant on the web today, backing the largest and most complex applications (aka Facebook, Twitter, YouTube) where functionality is key and near-desktop like application experiences are delivered.
Some of the largest open source SPA frameworks today are: ReactJS, EmberJS, VueJS, AngularJS.
These are all built on top of JavaScript and the DOM, but bring with them added complexity from both security and functionality perspectives.
Authentication and Authorization Systems
In a world where most applications consist of both clients (browsers / phones) and servers, and servers persist data originally sent from a client—systems must be in place to ensure future access of persisted data comes from the correct user.
We use the term “authentication” to describe a flow that allows a system to identify a user. In other words, authentication systems tell us that “joe123” is actually “joe123” and not “susan1988”.
The term “authorization” is used to describe a flow inside of a system for determining what resources “joe123” has access to, as apposed to “susan1988”. For example, “joe123” should be able to access his own uploaded private photos and “susan1988” should be able to access hers—but they should not be able to access each other.
Both of these processes are critical to the functionality of a web application, and both are functions in a web application where proper security controls are critical.
Authentication
Early authentication systems where simple in nature, take for example HTTP Basic Auth.
HTTP Basic Auth performs authentication by attaching an Authorization header on each request. The header consists of a string containing: Basic: <base64-encoded username:password>.
The server receives the username:password combination and on each request checks it against the database.
Obviously, these type of authentication scheme has several flaws—for example it was very easy for the credentials to be leaked in a number of ways from compromised wifi over HTTP to simple cross-site scripting attacks.
Later authentication developments included digest authentication, which employs cryptographic hashes instead of base64 encoding. After digest authentication, a multitude of new techniques and architectures would pop up for authentication—including those that do not involve passwords or require external devices.
Today, most web applications chose from a suite of authentication architectures depending on the nature of the business.
For example, the OAuth protocol is great for websites that want to integrate with larger websites. OAuth allows for a major website (aka, Facebook, Google, etc.) to provide a token verifying a user’s identity to a partner website.
OAuth can be useful to a user because the user’s data only needs to be updated on one site, rather than multiple—but OAuth can be dangerous because one compromised website could result in multiple compromised profiles.
HTTP Basic Auth and Digest authentication are still used widely today, with Digest being more popular as it has more defenses against interception and replay attacks. Often these are coupled with tools like 2FA to ensure that authentication tokens are not compromised, and that the identity of the logged in user has not changed.
Authorization
Authorization is the next step after authentication. Authorization systems are more difficult to categorize, as authorization very much depends on the business logic inside of the web application.
Generally speaking, well designed applications will have a centralized authorization class which will be responsible for determining if a user has access to x resources or functionality.
Poorly architected applications will implement checks on a per-API basis which manually reproduce authorization functionality. Often times, if you can tell that an application re-implements authorization checks in each API—that application will likely have several API’s where the checks are not sufficient simply due to human error.
Some common resources that should always have authorization checks: settings/profile updates, password resets, private message reads/writes, any paid functionality and any elevated user functionality (aka moderation functions).
Web Servers

Figure 3-5. Apache—one of the largest and most frequently implemented web server software packages. Apache has been in development since 1995.
A modern client-server web application relies on a number of technologies built on top of each other for the server-side component and client-side components to function as intended.
In the case of the server, application logic runs on top of a software-based web server package so that application developers do not have to worry about handling requests and managing processes.
The web server software of course runs on top of an operating system (usually some Linux distro like Ubuntu, CentOS, RedHat) which runs on top of physical hardware in a data center somewhere.
But as far as web server software goes, there are a few big players in the modern web application world.
Apache still serves nearly half of the websites in the world, so we can assume Apache serves the majority of web applications as well. Apache is open source, has been in development for around 25 years and runs on almost every Linux distro as well as some Windows servers.
Apache is great not only due to its large community of contributors and open source nature, but also because of how easily configurable and pluggable it has become. It’s a flexible webserver that you will likely see for a long time.
Apache’s biggest competitor is Nginx, pronounced (Engine “X”). Nginx runs around 30% of the web, and is growing rapidly.
Although Nginx can be used for free, it’s parent company (currently F5 Networks) uses a paid+ model where support and additional functionality comes at a cost.
The main use case for Nginx is that of extremely high concurrent connections. Web applications which are serving many users simultaneously may see large performance improvements switching from Apache to Nginx, as Nginx’s architecture has much less overhead per connection.
Behind Nginx is Microsoft IIS, although the popularity of Windows based servers has diminished due to expensive licenses and lack of compatibility with Unix-based OSS packages. IIS is the correct choice of webserver when dealing with many Microsoft specific technologies, but may be a burden to companies trying to build on top of open source.
There are many smaller webservers out there, and each has their own security benefits and downsides. Becoming familiar with the big-3 will be useful as you move on throughout this book and learn how to find vulnerabilities that stem from improper configuration—rather than just vulnerabilities present in application logic.
Server-Side Databases
Once a client sends data to be processed to a server, the server must often persist this data so that it can be retrieved in a future session.
Storing data in memory is not reliable in the long term, as restarts and crashes could cause data loss. Additionally, random access memory is quite expensive when compared to disk.
When storing data on disk, proper precautions need to be taken to ensure the data can be reliably and quickly retrieved, stored and queried. Almost all of today’s web applications store their user submitted data in some type of database—often varying the database used dependent on the particular business logic and use case.
SQL databases are still the most popular general-purpose database on the market. SQL query language is strict, but reliably fast and easy to learn. SQL can be used for anything from storage of user credentials to even managing JSON objects or small image blobs. The largest of these are PostgreSQL, Microsoft SQL Server, MySQL and SQLite.
When more flexible storage is needed, schemaless “NoSQL” databases can be employed. Databases like MongoDB, DocumentDB, and CouchDB store information as loosely structured “documents” which are flexible and can be modified at any time but are not as easy or efficient at querying or aggregating.
In today’s web application landscape, more advanced and particular databases also exist. Search engines often employ their own highly specialized databases that must be synchronized with the main database on a regular basis. An example of this is the widely popular Elastic Search.
Each of these different types of database carries unique challenges and risks. SQL injection is a well known vulnerability archetype which is effective against major SQL databases when queries are not properly formed—but injection style attacks can occur against almost any database if a hacker is willing to learn the database’s query model.
It is wise to consider that many modern web applications can employ multiple databases at the same time, and often do. Applications with sufficiently secure SQL query generation, may not have sufficiently secure MongoDB or Elastic Search queries and permissions.
Client-Side Data Stores
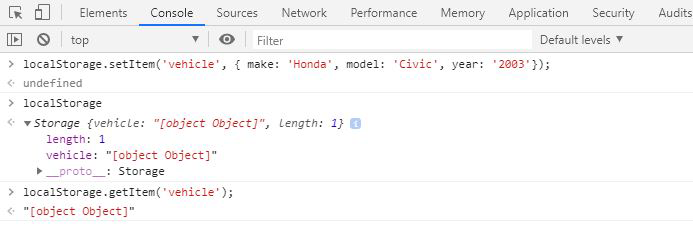
Figure 3-6. Local Storage—a powerful and persistent key/value store supported by all modern browsers. Allows web applications to maintain state even when the browser or tab is closed.
Traditionally, minimal data was stored on the client because of technical limitations and cross-browser compatibility issues. This is rapidly changing.
Many applications now store significant application state on the client, often in the form of configuration data or large scripts that would cause network congestion if they had to be downloaded on each visit.
In most cases, a browser-managed storage container called local storage is used for storing and accessing key:value data from the client. Local storage follows browser enforced same origin policy (SOP) which prevents other domains (websites) from accessing each other’s locally stored data.
A subset of local storage called session storage operates identically, but persists data only until the tab is closed. This type of storage can be used when data is more critical and should not be persisted if another user makes use of the same machine.
Tip
In poorly architected web applications, client-side data stores may also reveal sensitive information such as authentication tokens or other secrets.
Finally, for more complex applications—browser support for IndexedDB is found in all major web browsers today. IndexedDB is a JavaScript based OOP database capable of storing and querying asynchronously in the background of a web application.
Because IndexedDB is queryable, it offers a much more powerful developer interface than local storage is capable of. IndexedDB finds use in web based games, and web based interactive applications (like image editors).
You can check if your browser supports IndexedDB by typing the following in the browser developer console: if (window.indexedDB) { console.log('true'); }.
Summary
Modern web applications are built on a number of new technologies not found in older applications.
Because of this increased surface area due to expanded functionality—there are many more forms of attack that can target today’s applications versus the websites of the past.
To be a security expert in today’s application ecosystem, you need to not only have security expertise—but some level of software development skill as well.
The top hackers and security experts of this decade bring with them deep engineering knowledge in addition to their security skills.
They understand the relationship and architecture between the client and the server of an application. They are capable of analyzing an application’s behavior from the perspective of a server, client or the network in between.
The best of the best understand the technologies that power these three layers of a modern web application as well, and as a result of this they understand the weaknesses inherit in different databases, client-side technologies and network protocols.
While you do not need to be an expert software engineer to become a skilled hacker or security engineer, these skills will aid you and you will find them very valuable as they will expedite your research and allow you to see deep and difficult vulnerabilities that you would not otherwise be able to find.