
3
SOFTWARE DEVELOPMENT MODELS

You don’t write great code by following a fixed set of rules for every project. For some projects, hacking out a few hundred lines of code might be all you need to produce a great program. Other projects, however, could involve millions of code lines, hundreds of project engineers, and several layers of management or other support personnel; in these cases, the software development process you use will greatly affect the project’s success.
In this chapter, we’ll look at various development models and when to use them.
3.1 The Software Development Life Cycle
During its life, a piece of software generally goes through eight phases, collectively known as the Software Development Life Cycle (SDLC):
- Product conceptualization
- Requirement development and analysis
- Design
- Coding (implementation)
- Testing
- Deployment
- Maintenance
- Retirement
Let’s look at each phase in turn.
Product conceptualization
A customer or manager develops an idea for some software and creates a business case justifying its development.
Often, a nonengineer envisions a need for the software and approaches a company or individual who can implement it.
Requirement development and analysis
Once you have a product concept, the product requirements must be outlined. Project managers, stakeholders, and clients (users) meet to discuss and formalize what the software system must do to satisfy everyone. Of course, users will want the software to do everything under the sun. Project managers will temper this expectation based on the available resources (for example, programmers), estimated development times, and costs. Other stakeholders might include venture capitalists (others financing the project), regulatory agencies (for example, the Nuclear Regulatory Commission if you’re developing software for a nuclear reactor), and marketing personnel who might provide input on the design to make it saleable.
By meeting, discussing, negotiating, and so on, the interested parties develop requirements based on questions like the following:
- For whom is the system intended?
- What inputs should be provided to the system?
- What output should the system produce (and in what format)?
- What types of calculations will be involved?
- If there is a video display, what screen layouts should the system use?
- What are the expected response times between input and output?
From this discussion, the developers will put together the System Requirements Specification (SyRS) document, which specifies all the major requirements for hardware, software, and so on. Then the program management and system analysts use the SyRS to produce a Software Requirements Specification (SRS) document,1 which is the end result of this phase. As a rule, the SRS is for internal consumption only, used by the software development team, whereas the SyRS is an external document for customer reference. The SRS extracts all the software requirements from the SyRS and expands on them. Chapter 10 discusses these two documents in detail (see “The System Requirements Specification Document” on page 193 and “The Software Requirements Specification Document” on page 194).
Design
The software design architect (software engineer) uses the software requirements from the SRS to prepare the Software Design Description (SDD). The SDD provides some combination, but not necessarily all, of the following items:
- A system overview
- Design goals
- The data (via a data dictionary) and databases used
- A data flow (perhaps using data flow diagrams)
- An interface design (how the software interacts with other software and the software’s users)
- Any standards that must be followed
- Resource requirements (for example, memory, CPU cycles, and disk capacity)
- Performance requirements
- Security requirements
See Chapter 11 for further details on the contents of the SDD. The design documentation becomes the input for the next phase, coding.
Coding
Coding—writing the actual software—is the step most familiar and fun to software engineers. A software engineer uses the SDD to write the software. WGC5: Great Coding will be dedicated to this phase.
Testing
In this phase, the code is tested against the SRS to ensure the product solves the problems listed in the requirements. There are several components in this phase, including:
Unit testing Checks the individual statements and modules in the program to verify that they behave as expected. This actually occurs during coding but logically belongs in the testing phase.
Integration testing Verifies that the individual subsystems in the software work well together. This also occurs during the coding phase, usually toward the end.
System testing Validates the implementation; that is, it shows that the software correctly implements the SRS.
Acceptance testing Demonstrates to the customer that the software is suitable for its intended purpose.
WGC6: Testing, Debugging, and Quality Assurance will cover the testing phase in detail. Chapter 12 describes the software test case and software test procedure documents you’ll create to guide testing.
Deployment
The software product is delivered to the customer(s) for their use.
Maintenance
Once customers begin using the software, chances are fairly high that they’ll discover defects and request new functionality. During this time, the software engineers might fix the defects or add the new enhancements, and then deploy new versions of the software to the customer(s).
Retirement
Eventually in some software’s life, development will cease, perhaps because the development organization decides to no longer support or work on it, it is replaced by a different version, the company making it goes out of business, or the hardware on which it runs becomes obsolete.
3.2 The Software Development Model
A software development model describes how all the phases of the SDLC combine in a software project. Different models are suitable for different circumstances: some emphasize certain phases and deemphasize others, some repeat various phases throughout the development process, and others skip some phases entirely.
There are eight well-respected software development models and dozens, if not hundreds, of variations of these eight models in use today. Why don’t developers just pick one popular model and use it for everything? The reason, as noted in Chapter 1, is that practices that work well for individuals or small teams don’t scale up well to large teams. Likewise, techniques that work well for large projects rarely scale down well for small projects. This book will focus on techniques that work well for individuals, but great programmers must be able to work within all design processes if they want to be great programmers on projects of all sizes.
In this chapter I’ll describe the eight major software models—their advantages, disadvantages, and how to apply them appropriately. However, in practice, none of these models can be followed blindly or expected to guarantee a successful project. This chapter also discusses what great programmers can do to work around the limitations of a model forced on them and still produce great code.
3.2.1 The Informal Model
The Informal model describes software development with minimal process or discipline: no formal design, no formal testing, and a lack of project management. This model was originally known as hacking2 and those who engaged in it were known as hackers. However, as those original hackers grew up and gained experience, education, and skills, they proudly retained the name “hacker,” so the term no longer refers to an inexperienced or unskilled programmer.3 I’ll still use the term hacking to mean an informal coding process, but I’ll use informal coder to describe a person who engages in hacking. This will avoid confusion with differing definitions of hacker.
In the Informal model, the programmer moves directly from product conceptualization to coding, “hacking away” at the program until something is working (often not well), rather than designing a robust, flexible, readable program.
Hacking has a few advantages: it’s fun, done independently (though certainly many people participate in group events like hackathons), and the programmer is responsible for most design decisions and for moving the project along, so they can often get something working faster than could a software engineer following a formal development process.
The problem with the Informal model is that its conscious lack of design may lead to an invalid system that doesn’t do what end users want, because their requests weren’t considered in the requirements and software specifications—if those even exist—and often the software isn’t tested or documented, which makes it difficult for anyone other than the original programmer to use it.
Thus, the Informal model works for small, throwaway programs intended for use only by the programmer who coded them. For such projects, it’s far cheaper and more efficient to bang out a couple hundred lines of code for limited and careful use than to go through the full software development process. (Unfortunately, some “throwaway” programs can take on a life of their own and become popular once users discover them. Should this happen, the program should be redesigned and reimplemented so it can be maintained properly.)
Hacking is also useful for developing small prototypes, especially screen displays intended to demonstrate a program in development to a prospective customer. One sticky problem here, though, is that clients and managers may look at the prototype and assume that a large amount of code is already in place, meaning they may push to further develop the hacked code rather than start the development process from the beginning, which will lead to problems down the road.
3.2.2 The Waterfall Model
The Waterfall model is the granddaddy of software development models, and most models are a variation of it. In the Waterfall model, each step of the SDLC is executed sequentially from beginning to end (see Figure 3-1), with the output from each step forming the input for the next step.
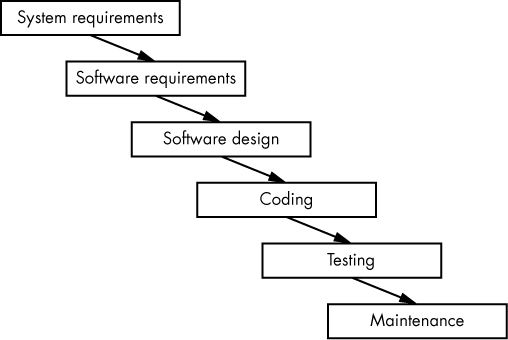
Figure 3-1: The Waterfall model
You begin the Waterfall model by producing the SyRS. Once the system requirements are specified, you produce the SRS from the SyRS. When the software requirements are specified, you produce the SDD from the SRS. You then produce source code from the SDD and test the software. Then you deploy and maintain the software. Everything in the SLDC happens in that order, without deviation.
As the original SDLC model, the Waterfall model is usually very simple to understand and apply to a software development project because each step is distinct, with well-understood inputs and deliverables. It’s also relatively easy to review work performed using this model and verify that the project is on track.
However, the Waterfall model suffers from some huge problems. The most important is that it assumes that you perform each step perfectly before progressing to the next step, and that you’ll find errors early in one step and make repairs before proceeding. In reality, this is rarely the case: defects in the requirements or design phases are typically not caught until testing or deployment. At that point, it can be very expensive to back up through the system and correct everything.
Another disadvantage is that the Waterfall model doesn’t allow you to produce a working system for customers to review until very late in the development process. I can’t count the number of times I’ve shown a client static screenshots or diagrams of how code would work, received their buy-in, and then had them reject the running result. That major disconnect in expectations could have been avoided had I produced a working prototype of the code that would have allowed customers to experiment with certain aspects of the system during the requirements phase.
Ultimately, this model is very risky. Unless you can exactly specify what the system will do before you start the process, the Waterfall model is likely inappropriate for your project.
The Waterfall model is appropriate for small projects of, say, less than a few tens of thousands of code lines involving only a couple of programmers; for very large projects (because nothing else works at that level); or when the current project is similar to a previous product that employed the Waterfall model during development (so you can use the existing documentation as a template).
3.2.3 The V Model
The V model, shown in Figure 3-2, follows the same basic steps as the Waterfall model but emphasizes the development of testing criteria early in the development life cycle. The V model is organized so the earlier steps, requirements and design, produce two sets of outputs: one for the step that follows and one for a parallel step during the testing phase.
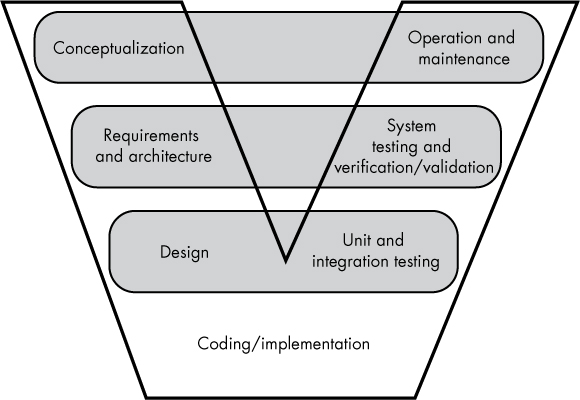
Figure 3-2: The V model
In Figure 3-2, the items on the left side of the V link straight across to the items on the right side: at each design stage, the programmer is thinking about how to test and use the concepts being modeled. For example, during the requirements and architecture phase, the system architect designs the system acceptance tests that will verify that the software correctly implements all the requirements. During the design phase, the system designer implements the software’s unit and integration tests.
The big difference here from the Waterfall model is that the engineer implements test cases and procedures early on, so by the time coding begins, the software engineer can use existing test procedures to verify the code’s behavior during development. Known as test-driven development (TDD), in this approach the programmer constantly runs tests throughout the development process. Continuous testing allows you to find bugs much sooner and makes it cheaper and faster to correct them.
That said, the V model is far from perfect. Like its parent, the Waterfall model, the V model is too simple, and requires too much perfection in the early stages in order to prevent disasters in the later stages. For example, a defect in the requirements and architecture phase might not surface until system testing and validation, resulting in expensive backtracking through the development. For this reason, the V model doesn’t work well for projects whose requirements are subject to change throughout a product’s lifetime.
The model often encourages verification at the expense of validation. Verification ensures that a product meets certain requirements (such as its software requirements). It’s easy to develop tests that show the software is fulfilling requirements laid out in the SRS and SyRS. In contrast, validation shows that the product meets the needs of its end users. Being more open-ended, validation is more difficult to achieve.
It’s difficult, for example, to test that the software doesn’t crash because it tries to process a NULL pointer. For this reason, validation tests are often entirely missing in the test procedures. Most test cases are requirements-driven, and rarely are there requirements like “no divisions by zero in this section of code” or “no memory leaks in this module” (these are known as requirement gaps; coming up with test cases without any requirements to base them on can be challenging, especially for novices).
3.2.4 The Iterative Model
Sequential models like Waterfall and V rely on the assumption that specification, requirements, and design are all perfect before coding occurs, meaning users won’t discover design problems until the software is first deployed. By then it’s often too costly (or too late) to repair the design, correct the software, and test it. The Iterative model overcomes this problem by taking multiple passes over the development model.
The hallmark of the Iterative model is user feedback. The system designers start with a general idea of the product from the users and stakeholders and create a minimal set of requirements and design documentation. The coders implement and test this minimal implementation. The users then play with this implementation and provide feedback. The system designers produce a new set of requirements and designs based on the user feedback, and the programmers implement and test the changes. Finally, users are given a second version for their evaluation. This process repeats until the users are satisfied or the software meets the original goals.
One big advantage of the Iterative model is that it works reasonably well when it’s difficult to completely specify the software’s behavior at the beginning of the development cycle. System architects can work from a general road map to design enough of the system for end users to play with and determine which new features are necessary. This avoids spending considerable effort producing features end users want implemented differently or don’t want at all.
Another advantage is that the Iterative model reduces time to market risk. To get the product to market quickly, you decide on a subset of features the final product will have and develop those first, get the product working (in a minimalist fashion), and ship this minimum viable product (MVP). Then, you add functionality to each new iteration to produce a new enhanced version of the product.
Advantages of the Iterative model include:
- You can achieve minimal functionality very rapidly.
- Managing risk is easier than in sequential models because you don’t have to complete the entire program to determine that it won’t do the job properly.
- Managing the project as it progresses (toward completion) is easier and more obvious than with sequential models.
- Changing requirements is supported.
- Changing requirements costs less.
- Parallel development is possible with two (or more) sets of teams working on alternate versions.
Here are some disadvantages of the Iterative model:
- Managing the project is more work.
- It doesn’t scale down to smaller projects very well.
- It might take more resources (especially if parallel development takes place).
- Defining the iterations might require a “grander” road map of the system (that is, going back to specifying all the requirements before development starts).
- There might be no limit on the number of iterations; hence, it could be impossible to predict when the project will be complete.
3.2.5 The Spiral Model
The Spiral model is also an iterative model that repeats four phases: planning, design, evaluation/risk analysis, and construction (see Figure 3-3).

Figure 3-3: The Spiral model
The Spiral model is heavily risk-based: each iteration assesses the risks of going forward with the project. Management chooses which features to add and omit and which approaches to take by analyzing the risk (that is, the likelihood of failure).
The Spiral is often called a model generator or meta model because you can use further development models—the same type or a different one—on each spiral. The drawback is that the resulting model becomes specific to that project, making it difficult to apply to others.
One key advantage of the Spiral model is that it involves end users with the software early and continuously during development by producing working prototypes on a regular basis. The end user can play with these prototypes, determine if development is on the right track, and redirect the development process if needed. This addresses one of the great shortcomings of the Waterfall and V models.
A drawback of this approach is that it rewards “just good enough” design. If the code can be written “just fast enough” or “just small enough,” further optimization is delayed until a later phase when it’s necessary. Similarly, testing is done only to a level sufficient to achieve a minimal amount of confidence in the code. Additional testing is considered a waste of time, money, and resources. The Spiral model often leads to compromises in the early work, particularly when it’s managed poorly, which leads to problems later in development.
Another downside is that the Spiral model increases management complexity. This model is complex, so project management requires risk analysis experts. Finding managers and engineers with this expertise is difficult, and substituting someone without appropriate experience is usually a disaster.
The Spiral model is suitable only for large, risky projects. The effort (especially with respect to documentation) expended is hard to justify for low-risk projects. Even on larger projects, the Spiral model might cycle indefinitely, never producing the final product, or the budget might be completely consumed while development is still on an intermediate spiral.
Another concern is that engineers spend considerable time developing prototypes and other code needed for intermediate versions that don’t appear in the final software release, meaning the Spiral model often costs more than developing software with other methodologies.
Nevertheless, the Spiral model offers some big advantages:
- The requirements don’t need to be fully specified before the project starts; the model is ideal for projects with changing requirements.
- It produces working code early in the development cycle.
- It works extremely well with rapid prototyping (see the next section, “The Rapid Application Development Model”), affording customers and other stakeholders a good level of comfort with the application early in its development.
- Development can be divided up and the riskier portions can be created early, reducing the overall development risk.
- Because requirements can be created as they’re discovered, they are more accurate.
- As in the Iterative model, functionality can be spread out over time, enabling the addition of new features as time/budget allows without impacting the initial release.
3.2.6 The Rapid Application Development Model
Like the Spiral model, the Rapid Application Development (RAD) model emphasizes continuous interaction with users during development. Devised by James Martin, a researcher at IBM in the 1990s, the original RAD model divides software development into four phases (see Figure 3-4).
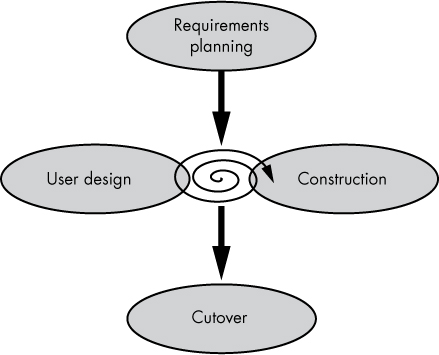
Figure 3-4: The RAD model
Requirements planning A project’s stakeholders come together to discuss business needs, scope, constraints, and system requirements.
User design End users interact with the development team to produce models and prototypes for the system (detailing inputs, outputs, and computations), typically using computer-aided software engineering (CASE) tools.
Construction The development team builds the software using tools to automatically generate code from the requirements and user design. Users remain involved during this phase, suggesting changes as the UI comes to life.
Cutover The software is deployed.
RAD is more lightweight than Spiral, with fewer risk mitigation techniques and fairly light documentation needs, meaning it works well for small to medium-sized projects. Unlike other models, traditional RAD heavily depends on very-high-level languages (VHLLs), user interface modeling tools, complex libraries and frameworks of existing code, and CASE tools to automatically generate code from requirements and user interface models. In general, RAD is practical only when there are CASE tools available for the specific project problems. Today, many generic language systems support a high degree of automatic code generation, including Microsoft’s Visual Basic and Visual Studio packages, Apple’s Xcode/Interface Builder package, Free Pascal/Lazarus, and Embarcadero’s Delphi (Object Pascal) package.
The advantages of the RAD model are similar to those of the Spiral model:
- The customer is involved with the product throughout development, resulting in less risk.
- RAD reduces development time because less time is spent writing documentation that must be rewritten later when the specifications inevitably change.
- The RAD model encourages the fast delivery of working code, and testing (and defect mitigation) is more efficient. Developers spend more time running the code, testing for problems.
Like any development model, RAD has some disadvantages as well:
- RAD requires Grand Master–level software engineers who have the experience to short-circuit much of the heavyweight development process found in other models. Such resources are scarce in many organizations.
- RAD requires continuous interaction with end users, which may be limited on many projects.
- RAD may be difficult to schedule and control. Managers who live and die by Microsoft Project will find it difficult to deal with the uncertainties in the RAD model.
- Unless carefully managed, RAD can rapidly devolve into hacking. Software engineers might forgo formal design methodologies and just hack away at the code to make changes. This can be especially troublesome when end users start making suggestions “just to see what the result will look like.”4
- RAD doesn’t work well for large system development.
3.2.7 The Incremental Model
The Incremental model is very similar to the Iterative model, with the main difference being in planning and design. In the Iterative model, the system design is created first and software engineers implement various pieces at each iteration; the initial design defines only the first piece of working code. Once the program is running, new features are designed and added incrementally.
The Incremental model emphasizes the “keep the code working” concept. When a base product is operational, the development team adds a minimal amount of new functionality at each iteration, and the software is tested and kept functional. By limiting new features, the team can more easily locate and solve development problems.
The advantage of the Incremental model is that you always maintain a working product. The model also comes naturally to programmers, especially on small projects. The disadvantage is that it doesn’t consider the product’s full design in the beginning. Often, new features are simply hacked on to the existing design. This could result in problems down the road when end users request features that were never considered in the original design. The Incremental model is sufficient for small projects but doesn’t scale well to large projects, where the Iterative model might be a better choice.
3.3 Software Development Methodologies
A software development model describes what work is done but leaves considerable leeway as to how it is done. This section looks at some development methodologies and processes you can apply to many of the models just discussed.
The Belitsoft company blog5 describes software methodology as follows:
A system of principles, as well as a set of ideas, concepts, methods, techniques, and tools that define the style of software development.
Thus, we can reduce the concept of software methodology to one word: style. There are various styles you can use when developing software.
3.3.1 Traditional (Predictive) Methodologies
The traditional methodology is predictive, meaning that management predicts which activities will take place, when they will take place, and who will do them. These methodologies work hand in hand with linear/sequential development models, like the Waterfall or V model. You could use prediction with other models, but those are designed to purposely avoid the problems that predictive methodologies are prone to.
Predictive methodologies fail when it’s impossible to predict changes in future requirements, key personnel, or economic conditions (for example, did the company receive the expected additional financing at some milestone in the project?).
3.3.2 Adaptive Methodologies
The Spiral, RAD, Incremental, and Iterative models came about specifically because it’s usually difficult to correctly predict requirements for a large software system. Adaptive methodologies handle these unpredictable changes in the workflow and emphasize short-term planning. After all, if you’re planning only 30 days in advance on a large project, the worst that can happen is you have to replan for the next 30 days; this is nowhere near the disaster you’d face in the middle of a large Waterfall/Predictive-based project, when a change would force you to resync the entire project.
3.3.3 Agile
Agile is an incremental methodology that focuses on customer collaboration, short development iterations that respond to changes quickly, working software, and support for individuals’ contributions and interactions. The Agile methodology was created as an umbrella to cover several different “lightweight” (that is, nonpredictive) methodologies, including Extreme Programming, Scrum, Dynamic System Development Model (DSDM), Adaptive Software Development (ASD), Crystal, Feature-Driven Development (FDD), Pragmatic Programming, and others. Most of these methodologies are considered “Agile,” although they often cover different aspects of the software development process. Agile has largely proven itself on real-world projects, making it one of the currently most popular methodologies, so we’ll dedicate a fair amount of space to it here.
NOTE
For a detailed list of the principles behind Agile, see the Agile Manifesto at http://agilemanifesto.org/.
3.3.3.1 Agile Is Incremental in Nature
Agile development is incremental, iterative, and evolutionary in nature, and so works best with Incremental or Iterative models (using Spiral or RAD is also possible). A project is broken down into tasks that a team can complete in one to four weeks, which is often called a sprint. During each sprint, the development team plans, creates requirements, designs, codes, unit-tests, and acceptance-tests the software with the new features.
At the end of the sprint, the deliverable is a working piece of software that demonstrates the new functionality with as few defects as possible.
3.3.3.2 Agile Requires Face-to-Face Communication
Throughout the sprint, a customer representative must be available to answer questions that arise. Without this, the development process can easily veer off in the wrong direction or get bogged down while the team waits for responses.
Efficient communication in Agile requires a face-to-face conversation.6 When a developer demonstrates a product directly to the customer, that customer often raises questions that would never come up in an email or if they’d just tried the feature on their own. Sometimes, offhand remarks in a demo can result in a burst of divergent thinking that would never happen if the conversation weren’t in person.
3.3.3.3 Agile Is Focused on Quality
Agile emphasizes various quality-enhancing techniques, such as automated unit testing, TDD, design patterns, pair programming, code refactoring, and other well-known best software practices. The idea is to produce code with as few defects as possible (during initial design and coding).
Automated unit testing creates a test framework that a developer can automatically run to verify that the software runs correctly. It’s also important for regression testing, which tests to ensure the code still works properly after new features have been added. Manually running regression tests is too labor-intensive, so it generally won’t happen.
In TDD, developers write automated tests prior to writing the code, which means that the test will initially fail. The developer runs the tests, picks a test that fails, writes the software to fix that failure, and then reruns the tests. As soon as a test succeeds, the developer moves on to the next failing test. Successfully eliminating all the failed tests verifies that the software meets the requirements.
Pair programming, one of Agile’s more controversial practices, involves two programmers working on each section of code together. One programmer enters the code while the other watches, catching mistakes onscreen, offering design tips, providing quality control, and keeping the first programmer focused on the project.
3.3.3.4 Agile Sprints (Iterations) Are Short
Agile methodologies work best when the iterations are short—from one week to (at most) a couple of months. This is a nod to the old adage “If it weren’t for the last minute, nothing would ever get done.” By keeping iterations short, software engineers are always working during the last minute, reducing fatigue and procrastination and increasing project focus.
Hand in hand with short sprints are short feedback cycles. A common Agile feature is a brief daily stand-up meeting, typically no more than 15 minutes,7 where programmers concisely describe what they’re working on, what they’re stuck on, and what they’ve finished. This allows project management to rearrange resources and provide help if the schedule is slipping. The meetings catch any problems early rather than wasting several weeks before the issue comes to project management’s attention.
3.3.3.5 Agile Deemphasizes Heavyweight Documentation
One of the Waterfall model’s biggest problems is that it produces reams of documentation that is never again read. Overly comprehensive, heavyweight documentation has a few problems:
- Documentation must be maintained. Whenever a change is made in the software, the documentation must be updated. Changes in one document have to be reflected in many other documents, increasing workload.
- Many documents are difficult to write prior to the code. More often than not, such documents are updated after the code is written and then never read again (a waste of time and money).
- An iterative development process quickly destroys coherence between code and documentation. Therefore, properly maintaining the documentation at each iteration doesn’t fit well with the Agile methodology.
Agile emphasizes just barely good enough (JBGE) documentation—that is, enough documentation so the next programmer can pick up where you left off, but no more (in fact, Agile emphasizes JBGE for most concepts, including design/modeling).
Many books have been written on Agile development (see “For More Information” on page 69). This is not one of them, but we’ll look at a couple of the different methodologies under the Agile umbrella. These methodologies are not mutually exclusive; two or more can be combined and used on the same project.
3.3.4 Extreme Programming
Extreme Programming (XP) is perhaps the most widely used Agile methodology. It aims to streamline development practices and processes to deliver working software that provides the desired feature set without unnecessary extras.
XP is guided by five values:
Communication Good communication between the customer and the team, among team members, and between the team and management is essential for success.
Simplicity XP strives to produce the simplest system today, even if it costs more to extend it tomorrow, rather than producing a complicated product that implements features that might never be used.
Feedback XP depends upon continuous feedback: unit and functional tests provide programmers with feedback when they make changes to their code; the customer provides immediate feedback when a new feature is added; and project management tracks the development schedule, providing feedback about estimates.
Respect XP requires that team members respect one another. A programmer will never commit a change to the code base that breaks the compilation or existing unit tests (or do anything else that will delay the work of other team members).
Courage XP’s rules and practices don’t line up with traditional software development practices. XP requires the commitment of resources (such as an “always available” customer representative or pair programmers) that can be expensive or difficult to justify in older methodologies. Some XP policies like “refactor early, refactor often” run counter to common practice such as “if it ain’t broke, don’t fix it.” Without the courage to fully implement its extreme policies, XP becomes less disciplined and can devolve into hacking.
3.3.4.1 The XP Team
Paramount to the XP process is the XP whole team concept: all members of the team work together to produce the final product. Team members are not specialists in one field, but often take on different responsibilities or roles, and different team members might perform the same role at different times. An XP team fills the following roles with various team members.
A customer representative
The customer representative is responsible for keeping the project on the right track, providing validation, writing user stories (requirements, features, and use cases) and functional tests, and deciding the priorities (release planning) for new functionality. The customer representative must be available whenever the team needs them.
Not having an available customer representative is one of the largest impediments to successful XP projects. Without continuous feedback and direction from the customer, XP degenerates into hacking. XP doesn’t rely on requirements documentation; instead, the representative is a “living version” of that documentation.
Programmers
Programmers have several responsibilities on an XP team: working with the customer representative to produce user stories, estimating how resources should be allocated for those stories, estimating timelines and costs to implement stories, writing unit tests, and writing the code to implement the stories.
Testers
Testers (programmers who implement or modify a given unit run unit tests) run the functional tests. Often, at least one of the testers is the customer representative.
Coach
The coach is the team leader, typically the lead programmer, whose job is to make sure the project succeeds. The coach ensures the team has the appropriate work environment; fosters good communication; shields the team from the rest of the organization by, for example, acting as a liaison to upper management; helps team members maintain self-discipline; and ensures the team maintains the XP process. When a programmer is having difficulty, coaches provide resources to help them overcome the problem.
Manager/tracker
The XP project manager is responsible for scheduling meetings and recording their results. The tracker is often, but not always, the same as the manager, and is responsible for tracking the project’s progress and determining whether the current iteration’s schedule can be met. To do so, the tracker checks with each programmer a couple of times a week.
Different XP configurations often include additional team roles, such as analysts, designers, doomsayers, and so on. Because of the small size of XP teams (typically around 15 members) and the fact that (paired) programmers constitute the majority of the team, most roles are shared. See “For More Information” on page 69 for additional references.
3.3.4.2 XP Software Development Activities
XP uses four basic software development activities: coding, testing, listening, and designing.
Coding
XP considers code to be the only important output of the development process. Contrary to the “think first, code later” philosophy of serial models like Waterfall, XP programmers start writing code at the beginning of the software development cycle. After all, “at the end of the day, there has to be a working program.”8
XP programmers don’t immediately start coding, but are given a list of small and simple features to implement. They work on a basic design for a particular feature and then code that feature and make sure it’s working before expanding in increments, with each increment working correctly to ensure that the main body of code is always running. Programmers make only small changes to the project before integrating those changes into the larger system. XP minimizes all noncode output, such as documentation, because there is very little benefit to it.
Testing
XP emphasizes TDD using automated unit and functional tests. This allows XP engineers to develop the product right (verification via automated unit tests) and develop the right product (validation via functional tests). WGC6: Testing, Debugging, and Quality Assurance will deal more exclusively with testing, so we won’t go too far into it here; just know that TDD is very important to the XP process because it ensures that the system is always working.
Testing in XP is always automated. If adding one feature breaks an unrelated feature for some reason, it’s critical to immediately catch that. By running a full set of unit (and functional) tests when adding a new feature, you can ensure that your new code doesn’t cause a regression.
Listening
XP developers communicate almost constantly with their customers to ensure they’re developing the right product (validation).
XP is a change-driven process, meaning it expects changes in requirements, resources, technology, and performance, based on feedback from customers as they test the product throughout the process.
Designing
Design occurs constantly throughout the XP process—during release planning, iteration planning, refactoring, and so on. This focus prevents XP from devolving into hacking.
3.3.4.3 The XP Process
Each cycle of XP produces a software release. Frequent releases ensure constant feedback from the customer. Each cycle consists of a couple of fixed-period blocks of time known as iterations (with no more than a couple of weeks for each iteration). Cycles, as shown in Figure 3-5, are necessary for planning; the middle box in this figure represents one or more iterations.
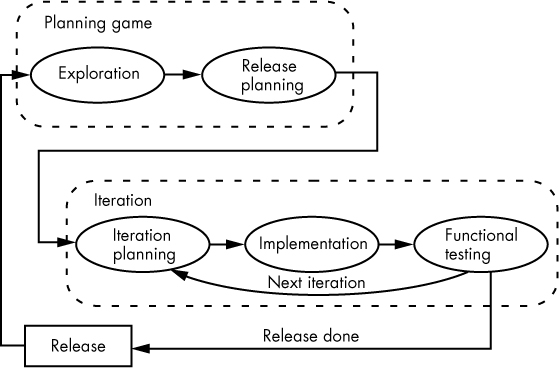
Figure 3-5: An XP cycle
In the planning game, the XP team decides which features to implement, estimates their costs, and plans the release. During the exploration step, the customer defines the feature set and developers estimate costs and time requirements for those features. The next section (under “User stories”) describes the mechanism customers use to specify features.
During release planning, the customer negotiates with the developers on the features to implement in the given iteration. The developers commit to the release plan, and engineers are assigned various tasks. At the end of release planning, the process enters the steering phase, during which the customer ensures that the project remains on track.
After the overall plan is determined, the process for the current release enters an inner loop consisting of three steps: iteration planning, implementation, and functional testing. Iteration planning is the planning game scaled down for a single feature.
The implementation step is the coding and unit testing of the feature. The developer writes a set of unit tests, implements just enough code to make the unit tests succeed, refactors the code as necessary, and integrates the changes into the common code base.
During the last step of the iteration, customers perform functional testing. Then the process repeats for the next iteration, or a release is produced if all iterations are completed for the current release.
3.3.4.4 XP Software Development Rules
XP implements the four software development activities—coding, testing, listening, and designing—using 12 simple rules:9
- User stories (planning game)
- Small releases (building blocks)
- Metaphors (standardized naming schemes)
- Collective ownership
- Coding standard
- Simple design
- Refactoring
- Testing
- Pair programming
- Onsite customer
- Continuous integration
- Sustainable pace
Each rule is described next, along with its advantages and disadvantages.
User stories
User stories describe a simplified set of use cases, written by the customer, that define the system’s requirements. The project team uses this set, which should provide only enough detail to estimate how long it will take to implement the feature, to estimate the cost and plan the system’s development.
At the beginning of a project, the customer generates 50 to 100 user stories to use during a release planning session. Then the customer and the team negotiate which features the team will implement in the next release. The customer, possibly with help from a developer, also creates functional tests from the user stories.
Small releases
Once a piece of software is functional, the team adds one feature at a time. Other features are not added until that new feature is written, tested, debugged, and incorporated into the main build. The team creates a new build of the system for each feature it adds.
Metaphors
XP projects revolve around a story about the system’s operation that all stakeholders can understand. Metaphors are naming conventions used within the software to ensure that operations are obvious to everyone; they replace a complex business process name with a simple name. For example, “train conductor” might describe how a data acquisition system operates.
Collective ownership
In XP, the entire team owns and maintains all source code. At any time, any team member can check out code and modify it. During reviews, no one is singled out for coding mistakes. Collective code ownership prevents delays and means one person’s absence doesn’t hinder progress.
Coding standard
All XP members must adhere to common coding standards concerning styles and formats. The team can develop the standards or they can come from an outside source, but everyone must follow them. Coding standards make the system easier to read and understand, especially for newcomers getting up to speed with the project, and help the team avoid having to waste time later refactoring the code to bring it into compliance.
Simple design
The simplest design that meets all the requirements is always chosen. At no time does the design anticipate features that have yet to be added—for example, adding “hooks” or application programming interfaces (APIs) that allow future code to interface with the current code. Simple design means just enough to get the current job done. The simplest code will pass all the tests for the current iteration. This runs counter to traditional software engineering, where software is designed as generically as possible to handle any future enhancements.
Refactoring
Refactoring code is the process of restructuring or rewriting the code without changing its external behavior, to make the code simpler, more readable, or better by some other improvement metric.
WGC5: Great Coding will go into refactoring in much greater detail. See “For More Information” on page 69 for additional references on refactoring.
Testing
XP uses a TDD methodology, as discussed in “XP Software Development Activities” on page 57.
Pair programming
In pair programming, one programmer (the driver) enters code, and the second programmer (the navigator) reviews each line of code as it’s written. The two engineers change roles throughout and pairs are often created and broken apart.
It’s often difficult to convince management that two programmers working together on the same code are more productive than they are working separately on different pieces of code. XP evangelists argue that because the navigator is constantly reviewing the driver’s code, a separate review session isn’t needed, among other benefits:10
Economic benefits Pairs spend about 15 percent more time on programs than individuals, but the code has 15 percent fewer defects.11
Design quality Two programmers produce a better design because they bring more experiences to the project. They think about the problem in different ways, and they devise the solution differently based on their driver/navigator roles. A better design means the project requires less backtracking and redesign throughout its life cycle.
Satisfaction A majority of programmers enjoy working in pairs rather than alone. They feel more confident in their work and, as a result, produce better code.
Learning Pair programming allows pair members to learn from each other, increasing their respective skills. This cannot happen in solo programming.
Team building and communication Team members share problems and solutions, which helps spread the intellectual property (IP) around and makes it easier for others to work on a given code section.
Overall, the research on the effectiveness of pair programming is a mixed bag. Most published papers from industry sources talk about how well pair programming has worked, but papers describing its failure in industry (versus academic) settings generally don’t get published. Research by Kim Man Lui and Andreas Hofer considers three types of pairings in pair programming: expert–expert, novice–novice, and expert–novice.
Expert–expert pairing can produce effective results, but two expert programmers are likely to use “tried and true” methods without introducing any new insight, meaning the effectiveness of this pairing versus two solo expert programmers is questionable.
Novice–novice pairing is often more effective than having the partners work on solo projects. Novices will have greatly varying backgrounds and experiences, and their knowledge is more likely to be complementary than overlapping (as is the case for expert pairs). Two novices working together are likely to work faster on two projects serially rather than they would working independently on their own project in parallel.
Expert–novice pairing is commonly called mentoring. Many XP adherents don’t consider this to be pair programming, but mentoring is an efficient way to get a junior programmer up to speed with the code base. In mentoring, it’s best to have the novice act as the driver so they can interact with and learn from the code.
—C. A. R. Hoare
—Gordon Bell
—Jeff Sickle
—Brian Kernighan and P. J. Plauger
—Chris Wenham
—John Carmack
—Chris Sacca
Though supporting evidence for pair programming is anecdotal and essentially unproven, XP depends on pair programming to replace formal code reviews, structured walk-throughs, and—to a limited extent—design documentation, so it can’t be forgone. As is common in the XP methodology, certain heavyweight processes like code reviews are often folded into other activities like pair programming. Trying to eliminate one rule or subprocess will likely open a gap in the overall methodology.
Not all XP activities are done in pairs. Many nonprogramming activities are done solo—for example, reading (and writing) documentation, dealing with emails, and doing research on the web—and some are always done solo, like writing code spikes (throwaway code needed to test a theory or idea). Ultimately, pair programming is essential for successful XP ventures. If a team cannot handle pair programming well, it should use a different development methodology.
Onsite customer
As noted many times previously, in XP the customer is part of the development team and must be available at all times.
The onsite customer rule is probably the most difficult to follow. Most customers aren’t willing or able to provide this resource. However, without the continuous availability of a customer representative, the software could go off track, encounter delays, or regress from previous working versions. These problems are all solvable, but their solution destroys the benefits of using XP.
Continuous integration
In a traditional software development system like Waterfall, individual components of the system, written by different developers, are not tested together until some big milestone in the project, and the integrated software may fail spectacularly. The problem is that the unit tests don’t behave the same as the code that must be integrated with the units, typically due to communication problems or misunderstood requirements.
There will always be miscommunication and misunderstandings, but XP makes integration problems easier to solve via continuous integration. As soon as a new feature is implemented, it’s merged with the main build and tested. Some tests might fail because a feature has not yet been implemented, but the entire program is run, testing linkages with other units in the application. Software builds are created frequently (several times per day). As a result, you’ll discover integration problems early when they’re less costly to correct.
Sustainable pace
Numerous studies show that creative people produce their best results when they’re not overworked. XP dictates a 40-hour workweek for software engineers. Sometimes a crisis might arise that requires a small amount of overtime. But if management keeps its programming team in constant crisis mode, the quality of the work suffers and the overtime becomes counterproductive.
3.3.4.5 Other Common Practices
In addition to the previous 12 rules, XP promotes several other common practices:
Open workspace and collocation
The XP methodology suggests open work areas for the entire team, who work in pairs at adjacent workstations. Having everyone together promotes constant communication and keeps the team focused.12 Questions can be quickly asked and answered, and other programmers can inject comments into a discussion as appropriate.
But open workspaces have their challenges. Some people are more easily distracted than others. Loud noise and conversations can be very annoying and break concentration.
Open workspaces are a “best practice” in XP, not an absolute rule. If this setup doesn’t work for a particular pair, they can use an office or cubicle and work without distractions.
Retrospectives/debriefings
When a project is complete, the team meets to discuss the successes and failures, disseminating the information to help improve the next project.
Self-directed teams
A self-directed team works on a project without the usual managerial levels (project leads, senior and junior level engineers, and so forth). The team makes decisions on priorities by consensus. XP teams aren’t completely unmanaged, but the idea here is that given a set of tasks and appropriate deadlines, the team can manage the task assignments and project progress on its own.
3.3.4.6 Problems with XP
XP is not a panacea. There are several problems with it, including:
- Detailed specifications aren’t created or preserved. This makes it difficult to add new programmers later in the project or for a separate programming team to maintain the project.
- Pair programming is required, even if it doesn’t work. In some cases, it can be overkill. Having two programmers work on a relatively simple piece of code can double your development costs.
- To be practical, XP typically requires that all team members be GMPs in order to handle the wide range of roles each member must support. This is rarely achievable in real life, except on the smallest of projects.
- Constant refactoring can introduce as many problems (new bugs) as it solves. It can also waste time when programmers refactor code that doesn’t need it.
- No Big Design Up Front (that is, non-Waterfall-like development) often leads to excessive redesign.
- A customer representative is necessary. Often, the customer will assign a junior-level person to this position because of the perceived costs, resulting in a failure point. If the customer representative leaves before the project is complete, all the requirements that aren’t written down are lost.
- XP is not scalable to large teams. The limit for a productive XP team is approximately a dozen engineers.
- XP is especially susceptible to “feature creep.” The customer can inject new features into the system due to a lack of documented requirements/features.
- Unit tests, even those created by XP programmers, often fail to point out missing features. Unit tests test “the code that is present,” not “the code that should be present.”
- XP is generally considered an “all or nothing” methodology: if you don’t follow every tenet of the “XP religion,” the process fails. Most XP rules have weaknesses that are covered by the strengths of other rules. If you fail to apply one rule, another rule will likely break (because its weaknesses are no longer covered, and that broken rule will break another, ad nauseam).
This small introduction to XP cannot do the topic justice. For more information on XP, see “For More Information” on page 69.
3.3.5 Scrum
The Scrum methodology is not a software development methodology per se, but an Agile mechanism for managing the software development process. More often than not, Scrum is used to manage some other model such as XP.
Beyond engineers, a Scrum team has two special members: the product owner and the scrum master. The product owner is responsible for guiding the team toward building the right product by, for example, maintaining requirements and features. The scrum master is a coach who guides the team members through the Scrum-based development process, managing team progress, maintaining lists of projects, and ensuring team members aren’t held up.
Scrum is an iterative development process like all other Agile methodologies, and each iteration is a one- to four-week sprint. A sprint begins with a planning meeting where the team determines the work to be done. A list of items known as a backlog is assembled, and the team estimates how much time is required for each item on the backlog. Once the backlog is created, the sprint can begin.
Each day the team has a short stand-up meeting during which the members briefly mention yesterday’s progress and their plans for today. The scrum master notes any progress problems and deals with them after the meeting. No detailed discussions about the project take place during the stand-up meeting.
Team members pick items from the backlog and work on those items. As items are removed from the backlog, the scrum master maintains a Scrum burn-down chart that shows the current sprint’s progress. When all the items have been implemented to the product owner’s satisfaction, or the team determines that some items cannot be finished on time or at all, the team holds an end meeting.
At the end meeting, the team demonstrates the features that were implemented and explains the failures of the items not completed. If possible, the scrum master collects unfinished items for the next sprint.
Also part of the end meeting is the sprint retrospective, where team members discuss their progress, suggest process improvements, and determine what went well and what went wrong.
Note that Scrum doesn’t dictate how the engineers perform their jobs or how the tasks are documented, and doesn’t provide a set of rules or best practices to follow during development. Scrum leaves these decisions to the development team. Many teams, for example, employ the XP methodology under Scrum. Any methodology compatible with iterative development will work fine.
Like XP, Scrum works well with small teams fewer than a dozen members and fails to scale to larger teams. Some extensions to Scrum have been made to support larger teams. Specifically, a “scrum-of-scrums” process allows multiple teams to apply a Scrum methodology to a large project. The large project is broken down into multiple teams, and then an ambassador from each team is sent to the daily scrum-of-scrums meeting to discuss their progress. This doesn’t solve all the communication problems of a large team, but it does extend the methodology to work for slightly larger projects.
3.3.6 Feature-Driven Development
Feature-driven development, one of the more interesting methodologies under the Agile umbrella, is specifically designed to scale up to large projects.
One common thread among most Agile methodologies is that they require expert programmers in order to succeed. FDD, on the other hand, allows for large teams where it is logistically impossible to ensure you have the best person working on every activity of the project, and is worth serious consideration on projects involving more than a dozen software engineers.
FDD uses an iterative model. Three processes take place at the beginning of the project (often called iteration zero), and then the remaining two processes are iteratively carried out for the duration of the project. These processes are as follows:
- Develop an overall model.
- Build a features list.
- Plan by feature.
- Design by feature.
- Build by feature.
3.3.6.1 Develop an Overall Model
Developing an overall model is a collaborative effort between all the stakeholders—clients, architects, and developers—where all team members work together to understand the system. Unlike the specifications and design documents in the serial methods, the overall model concentrates on breadth rather than depth to fill in as many generalized features as possible to define the entire project, and then fill in the depth of the model design’s future iterations, with the purpose of guiding the current project, not documenting it for the future.
The advantage of this approach versus other Agile approaches is that most features are planned from the beginning of the project. Therefore, the design can’t take off in a direction that makes certain features difficult or impossible to add at a later date, and new features cannot be added in an ad hoc fashion.
3.3.6.2 Build a Features List
During the second step of FDD, the team documents the feature list devised in the model development step, which is then formalized by the chief programmer for use during design and development. The output of this process is a formal features document. Although not as heavyweight as the SRS document found in other models, the feature descriptions are formal and unambiguous.
3.3.6.3 Plan by Feature
The plan-by-feature process involves creating an initial schedule for the software development that dictates which features will be implemented initially and which features will be implemented on successive iterations.
Plan by feature also assigns sets of features to various chief programmers who, along with their teams, are responsible for implementing them. The chief programmer and associated team members take ownership of these features and the associated code. This deviates somewhat from standard Agile practice, where the entire team owns the code. This is one of the reasons FDD works better for large projects than standard Agile processes: collective code ownership doesn’t scale well to large projects.
As a rule, each feature is a small task that a three- to five-person team can develop in two or three weeks (and, more often, just days). Each feature class is independent of the others, so no feature depends on the development of features in classes owned by other teams.
3.3.6.4 Design by Feature
Once the features for a given iteration are selected, the chief programmer who owns each feature set forms a team to design the feature. Feature teams are not static; they’re formed and disbanded for each iteration of the design-by-feature and build-by-feature processes.
The feature team analyzes the requirements and designs the feature(s) for the current iteration. The teams decide on that feature’s implementation and its interaction with the rest of the system. If the feature is far-reaching, the chief programmer might involve other feature class owners to avoid conflicts with other feature sets.
During the design phase, the feature teams decide on the algorithms and processes to use, and develop and document tests for the features. If necessary, the chief programmer (along with the original set of stakeholders) updates the overall model to reflect the design.
3.3.6.5 Build by Feature
The build-by-feature step involves coding and testing the feature. The developers unit-test their code and feature teams provide formal system testing of the features. FDD doesn’t mandate TDD, but it does insist that all features added to the system be tested and reviewed.
FDD requires code reviews (a best practice, but not required by most Agile processes). As Steve McConnell points out in Code Complete (Microsoft Press, 2004), well-executed code inspections uncover many defects that testing alone will never find.
3.4 Models and Methodologies for the Great Programmer
A great programmer should be capable of adapting to any software development model or methodology in use by their team. That said, some models are more appropriate than others. If you’re given the choice of model, this chapter should guide you in choosing an appropriate one.
No methodology is scalable up or down, so you’ll need to choose a suitable model and methodology based on the project size. For tiny projects, hacking or a documentation-less version of the Waterfall model is probably a good choice. For medium-sized projects, one of the iterative (Agile) models and methodologies is best. For large projects, the sequential models or FDD are the most successful (although often quite expensive).
More often than not, you won’t get to choose the developmental models for projects you work on unless they’re your personal projects. The key is to become familiar with the various models so you’re comfortable with any model you’re asked to use. The following section provides some resources for learning more about the different software development models and methodologies this chapter describes. As always, an internet search will provide considerable information on software development models and methodologies.
3.5 For More Information
Astels, David R. Test-Driven Development: A Practical Guide. Upper Saddle River, NJ: Pearson Education, 2003.
Beck, Kent. Test-Driven Development by Example. Boston: Addison-Wesley Professional, 2002.
Beck, Kent, with Cynthia Andres. Extreme Programming Explained: Embrace Change. 2nd ed. Boston: Addison-Wesley, 2004.
Boehm, Barry. Spiral Development: Experience, Principles, and Refinements. (Special Report CMU/SEI-2000-SR-008.) Edited by Wilfred J. Hansen. Pittsburgh: Carnegie Mellon Software Engineering Institute, 2000.
Fowler, Martin. Refactoring: Improving the Design of Existing Code. Reading, MA: Addison-Wesley, 1999.
Kerievsky, Joshua. Refactoring to Patterns. Boston: Addison-Wesley, 2004.
Martin, James. Rapid Application Development. Indianapolis: Macmillan, 1991.
Martin, Robert C. Agile Software Development, Principles, Patterns, and Practices. Upper Saddle River, NJ: Pearson Education, 2003.
McConnell, Steve. Code Complete. 2nd ed. Redmond, WA: Microsoft Press, 2004.
———. Rapid Development: Taming Wild Software Schedules. Redmond, WA: Microsoft Press, 1996.
Mohammed, Nabil, Ali Munassar, and A. Govardhan. “A Comparison Between Five Models of Software Engineering.” IJCSI International Journal of Computer Science Issues 7, no. 5 (2010).
Pressman, Robert S. Software Engineering, A Practitioner’s Approach. New York: McGraw-Hill, 2010.
Schwaber, Ken. Agile Project Management with Scrum (Developer Best Practices). Redmond, WA: Microsoft Press, 2004.
Shore, James, and Shane Warden. The Art of Agile Development. Sebastopol, CA: O’Reilly, 2007.
Stephens, Matt, and Doug Rosenberg. Extreme Programming Refactored: The Case Against XP. New York: Apress, 2003.
Wake, William C. Refactoring Workbook. Boston: Addison-Wesley Professional, 2004.
Williams, Laurie, and Robert Kessler. Pair Programming Illuminated. Reading, MA: Addison-Wesley, 2003.