
Communication protocols
Service discovery
REST
XML Signature
If you are involved with information technology – and haven’t spent the last five years installing Wi-Fi access points on Mars – you’ve heard of Web services.
In fact, you may have heard of it in breathless terms as a “revolution”. The last time there was so much revolutionary talk in the air, there was also tea in Boston harbor.
You can understand the hype if you look back at recent history. Before the Web, it was very difficult to distribute information so that anybody could access it using any computer system. The Web standards made computer-to-human communication easy and automatic. XML has begun to make computer-to-computer communication easier as well.
Web services is trying to go further in this direction. It is a term for services supported by a new set of XML-based protocols intended to make computer-to-computer communications not just easy, but standardized and automatic.[1]
Computers are like humans in that they cannot communicate with each other except by means of a shared language. Just like humans, they also cannot communicate if both parties speak at the same time. There must be some concept of back and forth, send and receive, talk and listen. The specification of how this happens is termed a protocol.
XML is not a protocol. XML is the shared language; it helps define what the terms of discussion are. But XML does not itself say anything about who speaks first, what they may say, what is appropriate in response, and other requirements of transmission.
Protocols are seldom used in isolation. They build on other protocols and standards. For example, the Web services protocols use XML as the data representation. They use Web communication protocols such as HTTP to move the XML around the Internet, but offer additional functions.
The SOAP messaging protocol is an example.[2] The SOAP spec defines a standardized carrier document – sort of an envelope – in which another document – the payload – is transported.
SOAP is the protocol beloved of large software companies. For many, the use of SOAP is implied by the term “Web services”, but others do without it. We’ll look at two well-known Web services, one SOAPless and one SOAPy.
Amazon’s Web service has an interesting business model. The service is free to use; it earns its money by increasing Amazon’s sales. It is essentially a search service for Amazon’s product line, but because the line in many areas is comprehensive, the service has research value as well: “How many books did Paul Prescod write? Did he ever record a DVD?”
Amazon has long had a model whereby “associates” can earn money by directing book buyers to the Amazon site. Amazon’s Web service allows these vendors to integrate more tightly with Amazon’s underlying databases.
Some even set up their own virtual store-fronts, selling books as if they were full-service retailers but allowing Amazon to do the actual fulfillment and billing. Entrepreneurial developers have created software that allows anyone to build a virtual storefront on top of the Amazon Web service in hours.
One innovative associate allows people to choose things from Amazon and then purchase them using currencies that Amazon does not support. The associate does the appropriate currency trading for you behind the scenes.
Everyone benefits from the Web service. The associates make more money by selling more products. The Web service gives them very accurate and timely information. When Amazon changes a price, they know quickly. Amazon makes a profit on most books it sells, so it benefits from giving the associates the tools they need to build their storefronts and sell books.
From the earliest days of the Amazon associates program, Amazon supplied HTML graphics and search boxes for associates to include on their Web pages. The links created by that HTML markup caused HTML pages to be displayed. That was o.k. for end users who wanted to buy books, but it was a nuisance for programmers who needed to integrate Amazon search results into complex Web pages or other applications.
In a nutshell: Amazon delivered renditions when the programmers needed abstractions!
Amazon’s browser style is pretty elaborate, as you can see from the search results page in Figure 19-1. It shows that the most popular book about the keyword “genome” is called “Genome” and is by “Matt Ridley”. It costs $11.20 at Amazon.
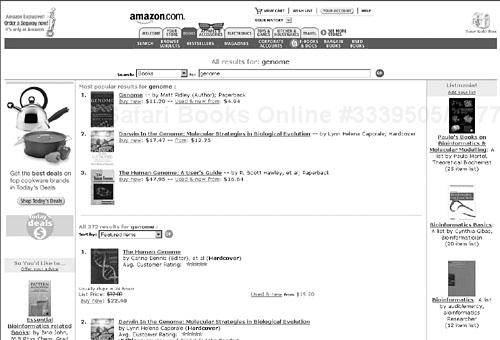
It follows from the elaborate formatting that the corresponding HTML source is pretty elaborate as well, as you can see in Example 19-1. A programmer looking for the facts about the top search result has to ignore things in the HTML pages that are helpful to people but irrelevant to computers, such as fonts, tabular layouts, line breaks, and so forth.
Example 19-1. Partial HTML source of Figure 19-1
<table border=0 cellpadding=3 width=100%>
<tr valign=top> <td> <font size=-1><b>1.</b></font></td>
<td align=center width=60>
<font face=verdana,arial,helvetica size=-1>
<a href=/exec/.../sr=2-1/ref=sr_2_1/103-5013077-5501429>
<img src="http://...PIt.arrow,TopLeft,-1,-17_SCTHUMBZZZ_.jpg"
width=42 height=66 align=left border=0></a>
</font>
</td>
<td width=100% valign=top>
<font face=verdana,arial,helvetica size=-1>
<a href=/exec/.../sr=2-1/ref=sr_2_1/103-5013077-5501429>
<b>Genome</b></a>
-- by Matt Ridley (Author); Paperback
<br>
<span class=small>
<a href=/exec/.../ref=sr_2_1/103-5013077-5501429>
Buy new</a></span>: <b class=price>$11.20</b>
--
<a
href=http://.../all/ref=sr_pb_a/103-5013077-5501429>
Used & new from</a>: <b class=price>$3.95</b>
</font>
</b>
A program that analyzes a rendition to find abstract data is said to be screen scraping. Such programs are difficult to write because there is no guaranteed pattern of formatting markup. Worse yet, the program might break any time that Amazon decides to change the layout of the search results.
The Amazon Web service eliminates the need for screen scraping by returning abstract XML documents. That makes it easy for programs to find the desired information elements.
Using the Web service, it is possible to construct queries similar to those that Amazon’s user interface allows: search by author, search by ISBN, search by keyword, and so forth.
Consider Example 19-2, which shows the Web service query for books about “genome”. You can actually type this query in a browser’s address pane and see a rendition of the XML document that the service would return to a program.[3]
Example 19-2. Web service query (split into two lines to fit page width of this book)
http://rcm.amazon.com/e/cm?t=encyclozine&l=st1 &search=genome&mode=books&pk102&o=1&f=xml
If you ask the browser to “View Source”, you will see the XML source of the search result, as shown in Example 19-3.[4]
Example 19-3. Partial XML source of Example 19-2 search result
<?xml version="1.0" encoding="ISO-8859-1"?>
<catalog>
<keyword>genome</keyword>
<product_group>Books</product_group>
<product>
<ranking>1</ranking>
<title>Genome</title>
<asin>0060932902</asin>
<author>Ridley, Matt</author>
<image>
http://images.amazon.com/images/P/0060932902.01.MZZZZZZZ.jpg
</image>
<small_image>
http://images.amazon.com/images/P/0060932902.01.TZZZZZZZ.jpg
</small_image>
<our_price>$11.20</our_price>
<list_price>$14.00</list_price>
<release_date>20001003</release_date>
<binding>Paperback</binding>
<availability> </availability>
<tagged_url>http://www.amazon.com:80/exec/obidos/redirect?
tag=encyclozine&creative=9441&camp=1793
&link_code=xml&path=ASIN/0060932902</tagged_url>
</product>
-- more products here --
</catalog>
As you can see, Example 19-3 yields much of the same information as Example 19-1. The top-ranked book about the keyword “genome” is called “Genome” and is by “Matt Ridley”. It costs $11.20 at Amazon, which is a few dollars cheaper than its $14.00 list price. But unlike the HTML, this XML is about as straightforward as you could hope for.
This Web service is SOAPless; Amazon offers a SOAPy version as well, which returns a substantially more complex document. We’ll look at a SOAP-based service next, but instead of Amazon we’ll use the equally famous Google.
The Google Web service allows programmers to treat Google as if it were a massive database of information about the Web. Or to be more precise, they now have access to the real database that underlies the Google search engine. Now, for example, a programmer can write a program that compares the change in popularity of different slang terms from day to day.
Google provides three different operations:
search
performs a traditional Google search
spelling
checks the spelling of a word and returns a suggestion if it is misspelled: Did you mean “handbook”?
cache
returns the version of a page that Google stored the last time its spider crawled the Web
Example 19-4 illustrates the result of a search query for “XML Handbook”. The return element is the payload of a SOAP message. It contains the Google search result.
Example 19-4. Google query result
<?xml version='1.0' encoding='UTF-8'?>
<SOAP-ENV:Envelope
xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:xsi="http://www.w3.org/1999/XMLSchema-instance"
xmlns:xsd="http://www.w3.org/1999/XMLSchema">
<SOAP-ENV:Body>
<ns1:doGoogleSearchResponse
xmlns:ns1="urn:GoogleSearch"
SOAP-ENV:encodingStyle=
"http://schemas.xmlsoap.org/soap/encoding/">
<return xsi:type="ns1:GoogleSearchResult">
<documentFiltering
xsi:type="xsd:boolean">false</documentFiltering>
<estimatedTotalResultsCount
xsi:type="xsd:int">120000</estimatedTotalResultsCount>
<directoryCategories
xmlns:ns2="http://schemas.xmlsoap.org/soap/encoding/"
xsi:type="ns2:Array"
ns2:arrayType="ns1:DirectoryCategory[0]">
</directoryCategories>
<searchTime xsi:type="xsd:double">0.071573</searchTime>
<resultElements
xmlns:ns3="http://schemas.xmlsoap.org/soap/encoding/"
xsi:type="ns3:Array"
ns3:arrayType="ns1:ResultElement[0]">
</resultElements>
<endIndex xsi:type="xsd:int">0</endIndex>
<searchTips xsi:type="xsd:string"></searchTips>
<searchComments xsi:type="xsd:string"></searchComments>
<startIndex xsi:type="xsd:int">0</startIndex>
<estimateIsExact
xsi:type="xsd:boolean">false</estimateIsExact>
<searchQuery
xsi:type="xsd:string">xml handbook</searchQuery>
</return>
</ns1:doGoogleSearchResponse>
</SOAP-ENV:Body>
</SOAP-ENV:Envelope>
Example 19-4 is clearly not the poster child for XML’s simplicity and elegance. But computers have an easier time reading it than do humans.
For example, if you examine the document carefully you can see an estimatedTotalResultsCount element containing the number of hits for this query. A program or XPath expression can find it much more easily than you can. Still, the complexity required by SOAP has somewhat tarnished a mostly positive reaction to Google’s service.
And yet Google’s result format is considered simple for a SOAP service. So why get involved with SOAP’s complexity in the first place? We’ll explore that question next.
One of the more advanced ideas underpinning Web services is that of service discovery. At present, humans generally decide with whom a program should share information. The purchasing agent for Miracle Cleanser tells his computer that the order for the “free if you act now” scrub brushes should be sent to the High-on-the-Hog Bristle Company.
Some believe that with Web services, that won’t be necessary. The purchasing program can search for a supplier using an elaborate registry system called Universal Description, Discovery, and Integration (UDDI).[5] A UDDI registry contains three classes of information:
white pages
They contain general contact information about organizations.
yellow pages
These list organizations by business category or location.
green pages
These include the technical aspects of conducting business, including Web service descriptions and schemas.
The green page Web Service descriptions are expressed in XML conforming to the Web Services Description Language (WSDL).
A WSDL service description in turn affects the structure of the SOAP messages that are used in conjunction with the service. It indicates the operations that the service performs, the message structure for requesting each operation, and the message structures that the operation returns.
This dynamic interaction between SOAP and WSDL is what makes this model of service discovery possible. (We discuss UDDI and WSDL in detail in Chapter 23, “Web services technologies”, on page 484.)
SOAP is not without its critics, who argue that it doesn’t do enough to warrant its complexity and attendant costs. They observe that in most SOAP services the HTTP Web protocol is doing the heavy work of moving data from place to place, and XML is describing the data that is being moved.
Worse yet, they point out that SOAP doesn’t use HTTP and XML in the way they were designed to be used. Instead of treating XML documents as persistent resources with Web addresses (URIs), SOAP treats them as transient messages sent to objects that are completely outside the Web or XML framework.
A second generation of Web services is now being developed that is integrated with the architecture of the Web: Web URIs address XML documents that can be retrieved via the Web’s HTTP. This architecture has been named REST. (You don’t want to know why.)[6] It is also referred to as XML over HTTP.
Developers who use REST techniques say it is a more productive way to build Web Services because it builds on techniques that are known to work.
Users seem to agree. The Amazon.com Web service is available in both the REST form that we discussed earlier and in a SOAP version. At the time of writing, Amazon reports that the REST service gets 85% of the use!
It takes a good deal of trust to rely on a Web service from outside your company, possibly from a supplier who is known only to your computer! In fact, the software industry may have to scale back its (revenue) hopes and ambitions for Web services for precisely that reason.
But it’s not going to quit without trying, so there has been a flurry of development in security standards and tools. Two security issues that are vital for Web services messages concern hiding them from prying eyes and verifying whom they’re from: encryption and identification.
You may have created a ZIP archive with a tool that gives you the option of protecting the archive with a password. If you send such a password-protected archive to a friend, he’ll be prompted for the password in order to open the archive. Without the password, the archive is indecipherable.
In cryptographic terms, that password is a key with which the sending system encrypts the ZIP archive. Since the sender and recipient both use the same key, the process is called symmetric cryptography – the fastest kind.
The problem with symmetric cryptography is communicating the key. How can you do that securely? You could encrypt it, but then you would need to transmit the key to the original key, and so on.
And what if the key is stolen?
A popular solution to this, er, key problem is called public key cryptography, which is asymmetric cryptography. Instead of a single symmetric key, shared by both parties, there is a mathematically-related pair of keys. You keep your own private key and you distribute a related public key to your friends so they can send you encrypted email. They encrypt their messages to you by using your public key, but you decrypt them using your private key.[7]
A system for deploying public key cryptography is called a public key infrastructure (PKI). It requires a means of managing public keys. The certificates that are the cause of so many mysterious messages from your Web browser are actually descriptions of public keys, digitally signed by a Certification Authority (CA).
One of the most basic security questions is “Who goes there?” – the question of user identification.
For documents, the classic means of identification is the signature. The signed name provides identification and the uniqueness of handwriting provides a (less-than-perfect!) means of authentication.
Just as in the written world, the digital signature is intended to identify and authenticate the author of a machine-readable document. The authentication is provided by public key encryption – but operating in reverse! A digital signature is encrypted with the signer’s private key and decrypted with the public key.
XML Signature is a W3C specification for representing digital signatures in XML. With XML Signature, it is possible to attach signatures to any object, whether it be XML or binary, standardized or proprietary.
When you sign a printed contract, your signature goes on the last or only piece of paper of the contract (and perhaps you also initial every page). That way, the signature cannot be shifted to a different contract from the one you signed originally. This procedure maintains the integrity of the signed contract.
Similarly, an XML signature is generated in a way that binds it to a single object. The receiver can check that the object has not changed by looking at a summary (hash) of it embedded in the signature. The digital signature acts as a seal, but without the messy hot wax!
The receiver can also, of course, use the sender’s public key to check that the signature was generated by his private key. If both tests are successful, then the recipient has got exactly the message that was signed and knows exactly who sent it.
Just as with printed signatures, digital signatures serve as a basis for non-repudiation. In other words, they prove that you endorsed the signed content. If you claim that you did not agree to a (digital) contract that has your (digital) signature, you had better have proof that your (private) key was stolen!
[1] These services are sometimes referred to by Microsoft as XML Web Services, no doubt to distinguish them from the general class of Web-based services – such as online psychic readings! However, the rest of the IT industry, with its usual aversion to the precise use of English, seems happy with Web services alone. So despite the ambiguity, we too use the shorter term.
[2] SOAP is considered a Web services protocol even though it has other uses and actually pre-dates the Web services hype by several years.
[3] Well, you once could have. As we went to press, Amazon changed its Web service interface and now requires a “developer’s token” in its queries.
[4] Note that in reality the content of tagged_url has no white space. It was broken into three lines in order to fit this book’s page width.
[5] Given the problems that even humans have in evaluating service offerings and providers – plus the many intangibles often involved in a decision – some some skepticism may be warranted. Full realization of service discovery would seem to require both artificial intelligence from the computer and genuine faith from the humans!
[6] Web pages are representations of resources. An application changes state as it traverses links to transfer from one page to another, hence Representational State Transfer (REST). We warned you that you didn’t want to know why!
[7] At least that’s the way it seems, but because symmetric cryptography is so much faster, the sender’s software actually encrypts the message with a randomly-generated symmetric key. It then encrypts the symmetric key with your public key so your software can decrypt it with your private key, and then use the decrypted symmetric key to decrypt the message. Whew!