
Built-in datatypes
Primitive datatypes
Derived datatypes
User-derived datatypes
Perhaps the most widely used product of the W3C XML Schema project is the datatype work. It was made a separate Part 2 of the XML Schema spec, with the intention “that it be usable outside of the context of XML Schema for a wide range of other XML-related activities”.
In this chapter, we describe the basic concepts of XML datatypes, with an emphasis on those that are built into the specification.
The XML Schema Datatypes spec defines two categories of datatype: primitive and derived. All primitive datatypes are defined in the spec and are therefore among the built-in datatypes. You may not create your own primitive datatype.
A derived datatype is defined in terms of one or more existing datatypes. It might be a specialized or extended version of another datatype. You may make your own derived datatypes. The spec also includes several among its built-in datatypes, which are therefore supported by every implementation.
Figure 21-1 illustrates the built-in datatypes, showing the derivations.
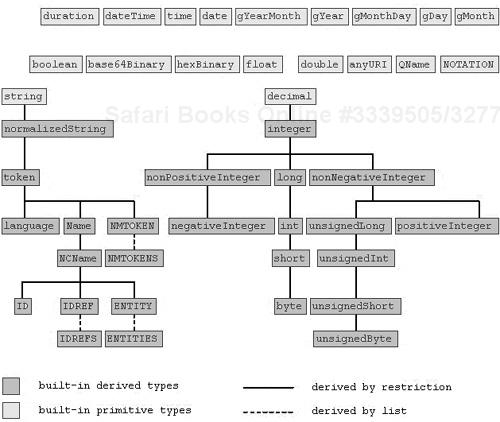
The primitive datatypes are the building blocks of all others. Most are also useful just by themselves.
The first five we will cover include common datatypes in most programming languages and database management systems.
string
An arbitrarily long sequence of characters. You might use this for a
titleelement’s datatype.
boolean
True and false values. The data may be any one of the following strings:
falseor0for false values ortrueor1for true values. You might use this for a datatype that represented whether a checkbox in a graphical user interface should be turned on by default (true) or turned off by default (false).
decimal
Arbitrary precision decimal numbers. These can represent anything numerical: height, weight, financial amounts, etc. Decimal numbers may have a fractional part that follows a period as in
5.3. Decimal numbers may be preceded by a plus (+) or minus (-) sign to represent whether they are negative or positive.
float
Single precision 32-bit floating point numbers. This is a form of number that is very efficient for numerical computation on 32-bit computers. Floats may have a fractional part and may also be preceded by a plus or minus sign. Compared to decimals, floats are less precise. They are an approximation. Sometimes the number you put into the computer will not be exactly the number you get out later![1]
double
Double precision 64-bit floating point numbers. These numbers are more precise than single-precision floats but are still approximations.[2]
anyURI
This extremely important primitive datatype is used for URIs (typically URLs). These may include so-called fragment identifiers after a pound sign.
QName
This primitive datatype is based on the XML namespaces specification. It stands for a namespace-qualified name. In other words, a
QNameis a name that may have a colon in it. If it does, the text before the colon should be a namespace prefix for a namespace that has been declared. If it does not, the names should be interpreted as belonging to the default namespace. See Chapter 16, “Namespaces”, on page 376 for more information on namespaces.
NOTATION
This datatype corresponds to the XML
NOTATIONattribute type.
There are two datatypes for representing binary data. The first is called hexBinary because it uses the hex notation, popular among practitioners of the occult and programmers of the UNIX operating system. There are sixteen hex digits.[3] The digits 0 through 9 represent the same thing they do in ordinary decimal numbers. The letter a represents 10, b represents 11 and so forth through f representing 15. Hex is popular not only because of its mystical powers but also because a few simple calculations can turn two hex digits into a value between 0 and 255, which is exactly the amount that can be held in a single byte.
The other datatype is called base64Binary because it represents base64-encoded data. Base64 is not as simple to translate into bytes without a computer but uses less space than hex. Hex doubles the size of the data. Base64 increases it by only a third, approximately.
The remaining primitive datatypes are all related to time: durations in this section and absolute dates and times in the next.
The duration datatype is based on the ISO 8601 date format standard. It represents a length of time, such as an hour or 3.56 seconds. Durations can be represented with a precision of seconds or fractions of a second. They can also span thousands of years.
A duration always starts with P; for example, P2Y. The 2Y that follows the P means two years (the gestation period for some elephants!).
Instead of measuring in years, you could measure in months: P3M would be three months (the amount of time it takes to get a new phone line installed in some cities).
You can also measure in years and months: P1Y3M means one year and three months (the shelf-life of a boy band). You can also count in days (with or without years or months): P3D (length of the Battle of Gettysburg).
But wait...that’s not all. Durations can get as fine grained as a fraction of a second. If you want to deal in time units shorter than a day you use the designator T after you’ve listed all of the day/month/year parts (or directly after the P if you are interested only in hour/minute/second units).
For instance P1YT1M represents one year and one minute (which is the amount of time that a VCR with a P1Y warranty is likely to survive). As you can see, M represents both month and minute, which is why you must include the T designator that separates the date part from the time part. If you have an hour, a minute or a second part you must have the T.
In addition to minutes you may use H for hour and S for second. S is the only part of the duration that may have a fractional part. PT3M43.13S represents three minutes and 43.13 seconds (the world record for running a mile).
The different parts of the date and time must always come in the same order: P, years, months, days, T, hours, minutes, seconds. Remember that the P is always required and the T is required if there are hours/minutes/seconds. Everything else is optional.
The date datatype represents a specific calendar date in the form YYYY-MM-DD. For instance the date of the Beatles’ debut on Ed Sullivan would be 1964-02-09 – February 9th, 1964.
Negative dates are also allowed, to represent BCE (BC) dates. For instance -0133-06-01 represents the approximate date of a Roman slave revolt lead by a man called Aristonicus – June 1, 133 BCE.
The time datatype represents a time that recurs every day. Times have the form hh:mm:ss. The seconds may have a fractional part. So 14:12:34.843 represents 2:12 and 34.843 seconds in the afternoon. It is not legal to leave the seconds out, even if they are not relevant: 14:12:00.
To indicate that the time is expressed in coordinated universal time (UTC), also known as Greenwich mean time (GMT), add a Z to the end of the time: 14:20:00Z.
It is also possible (and a good idea!) to specify a time zone for a time, as an offset from GMT. Do this by appending a - or + sign and a number of hours and minutes in the form hh:mm, such as 08:15:00-08:00 (8:15 Pacific time) or 11:20:00+03:30 (11:20 Tehran time). The time zone is optional but if you leave it out then it will be impossible to compare times across time zones.
As you might guess, it is possible to combine a date and time into a dateTime. A dateTime has a T between the date and time parts: 1929-10-29T11:00:00-05:00.
The gDay, gMonth and gMonthDay datatypes represent a day that recurs every month (e.g. the first or fifteenth day of each month), a month that recurs every year (let’s say July – or any other month!) and a particular date that recurs every year (such as Valentine’s day). The g in their names indicates that they are based on the Gregorian calendar.
The gDay datatype is in the form ---DD. There are three leading dashes, so the 8th of every month would be ---08.
The gMonth datatype, --MM, is similar. However, there are only two leading dashes, so every June would be --06.
The gMonthDay datatype is in the form --MM-DD. For instance, Caesar’s “Ides of March” (March 15th) would be --03-15 and a gMonth of --02 represents the month of February of every year.
These datatypes represent durations from the very first instant of the date to the very last. To improve precision, any of them may be followed by a time zone indicator.
The gYear and gYearMonth represent particular years or months in history or in the future. The year is a four-digit number and a gYearMonth is a four-digit number followed by a two-digit number: 2002-06. Either may be preceded by a negative sign (-) to represent BCE dates. They may also be followed by a time zone indicator.
The derived datatypes are based on the primitive ones. The XML Schema Datatypes spec defines some derived datatypes and provides facilities for users to define their own.
The ones defined in the spec are listed below. They fall into several categories.
These are numeric datatypes more specific (restricted) than the primitive datatypes.
integer
Decimal number (no matter how large or small) with no fractional part.
positiveInteger
Integer greater than zero.
negativeInteger
Integer less than zero.
nonPositiveInteger
Integer less than or equal to zero.
nonNegativeInteger
Integer greater than or equal to zero.
This group allows data to be restricted to values that specific computers can handle efficiently. Most modern computers handle everything from 8-bits to 32-bits well. A 64-bit computer handles long and unsignedLong most efficiently and other values less so.
byte
8-bit signed number (between -128 and 127)
unsignedByte
8-bit non-negative number (between 0 and 255)
short
16-bit number (between -32768 and 32767)
unsignedShort
16-bit non-negative number (between 0 and 65535)
int
32-bit number (between -2147483648 and 2147483647)
unsignedInt
32-bit non-negative number (between 0 and 4294967295)
long
64-bit number (between -9223372036854775808 and 9223372036854775807)
unsignedLong
64-bit non-negative number (between 0 and 18446744073709551615) (whew!)
Several derived datatypes are based on XML attribute types and other constructs. We list only the basic ones.
Some derived datatypes emulate XML attribute types. They are easy to recognize because they are the only built-in datatypes with upper-case names.
ID
An identifier unique to a single element in a document.
IDREF
A reference to a unique ID in the document.
There are other datatypes for XML constructs.
normalizedString
This datatype is for strings in which whitespace characters such as carriage return and tab characters should be replaced by spaces. If you use this datatype or derive from it, the schema processor will handle this normalization for you.
The XML Schema definition language (XSDL) provides a facility for defining user-derived datatypes, using the simpleType definition element.
The element must contain a child element for the desired form of derivation: list, union, or restriction.
derivation by list
Derivation by list is quite straightforward. You merely take an existing datatype (like
gYear) and create a new datatype that accepts a list of them (we could call itgYears).
derivation by union
This sort of derivation merges two or more datatypes into one that supports values of either sort. For instance a datatype representing months might allow either
gMonthintegers or string names by deriving by union fromNameandgMonth.
derivation by restriction
This form of derivation narrows down the values allowed by an existing datatype. For instance you could take the datatype
gYearand restrict it to years in a particular century.
The child element might optionally be preceded by an annotation element, as shown in Example 21-1.
Note

Annotation elements can hold more than documentation, and XSDL elements in general have other properties that support self-documentation and application processing of schema definitions. As these facilities are not germane to deriving datatypes for general use, they are discussed in 22.3.2, “Schema components”, on page 472.
Example 21-1. A simpleType definition
<xsd:simpleType name="mynewType">
<xsd:annotation>
<xsd:documentation>Important new type</xsd:documentation>
</xsd:annotation>
<xsd:restriction base="someOtherType">
...
</xsd:restriction>
</xsd:simpleType>
You derive by list when you want to allow occurrences of the datatype in the document to contain multiple values rather than just one. For instance to allow multiple dates you could derive a dates datatype[4] from the primitive date datatype, as in Example 21-2.
Caution
Items in lists are always separated by whitespace. If a datatype allows embedded whitespace (such as string), deriving a list from it may produce unexpected results.
Example 21-2. Deriving a list from a named datatype
<xsd:simpleType name="dates">
<xsd:annotation>
<xsd:documentation>Multiple dates</xsd:documentation>
</xsd:annotation>
<xsd:list itemType="xsd:date"/>
</xsd:simpleType>
In Example 21-2, the list was derived from an existing named datatype. It is also possible to derive a list from a newly-defined anonymous datatype. Rather than putting an itemType attribute on the list, you would merely put a simpleType element in the list element content.
The embedded simpleType will be used just as if you had defined it elsewhere, given it a name and referred to it with the itemType attribute. Example 21-3 demonstrates.
Derivation by union is a way of combining existing datatypes into one datatype. For instance you might want to allow dates to be specified according to any one of:
the built-in Gregorian
datedatatype,a notation based on the ancient Aztec calendar, or
the Hebrew calendar.
If we define our datatypes so that they are syntactically distinct then we can easily create a union of them. One way to easily distinguish Aztec and Hebrew dates is to start them with the letters A and H, respectively, because we know that built-in dates start with a number. Example 21-4 demonstrates such a union datatype.
Example 21-4. Union datatype
<xsd:simpleType name="AnyKindaDate">
<!-- we could put an annotation here -->
<xsd:union memberTypes="myns:AztecDate myns:HebrewDate xsd:date">
<!-- we could put another annotation here -->
</xsd:union>
</xsd:simpleType>
If we carelessly defined our notations so that some Aztec dates could also be recognized as Hebrew or Gregorian dates, then the Aztec interpretation would win over the other ones because it is listed first in the memberTypes attribute.
Instead of – or in addition to – a memberTypes attribute, you could also put simpleType elements within the union to define anonymous in-line datatypes, just as we did for lists. Unlike lists, however, which are derived from a single datatype, we can define as many anonymous datatypes as we like. Each of them contributes to the union just as if it had been defined externally and referenced.
If we wanted to, we could define a union of two different kinds of lists. Perhaps we would allow a list of Hebrew dates or a list of Aztec dates. Conversely, we could define a list of a union datatype. For instance, a list derived from AnyKindaDate would be a list of a union.
Many complex combinations of different kinds of derivation are possible.
Another way to derive a datatype is by restriction. In this case, you add constraints to an existing datatype, either built-in or user-derived.
By definition, a datatype derived by restriction is more constraining than its base datatype. Any value that conforms to the new derived datatype would also have to conform to the original base datatype.
Restrictions are created with the restriction element. You may have a single restriction as a child of the simpleType element. You can refer to a named base datatype with the base attribute, or define an anonymous base datatype by including a simple type in the content.
There is a fixed list of ways that you can constrain a given datatype. These are called constraining facets. There are twelve of them, each represented by a specific element type. They occur as sub-elements of the restriction element. The allowable ones depend on the base datatype.
They have several points in common:
They all allow a single optional
annotationsub-element and no other.Each has a required
valueattribute that specifies the constraining value. The exact meaning and allowable values of the attribute depend on the specific facet and the base datatype.They work together.
The last item requires some explanation.
If you define a datatype with a minimum value and then refine it by restriction to make a new datatype with a maximum value, the new datatype has both the minimum value constraint from the base datatype and the maximum value constraint from the derived datatype. If you defined yet a third datatype by restriction based on the new datatype, it would add still other restrictions.
This principle applies even when the same facet is applied at two different levels. So you could define a datatype that represents the set of numbers greater than 10,000 by setting a minimum value constraint. In a datatype derived from that you could set another minimum value constraint raising the minimum value to 20,000.
Values must now be both greater than 10,000 and greater than 20,000, which is the same as saying just that they must be greater than 20,000. In one sense both restrictions apply, but really the more constraining derived datatype overrides the base datatype.[5]
This section describes the twelve facet elements that are used when deriving by restriction. They fall into six categories: range, length, decimal digit, enumeration, white space, and pattern.
The simplest kind of restriction available for numeric and date datatypes is a range restriction. For instance we might want to define a user-derived datatype called “publication year” as a year that must fall between 1000 and 2100. Example 21-5 defines a pubYear datatype with these characteristics.
Example 21-5. Defining a restricted range integer datatype
<xsd:simpleType name="pubYear">
<xsd:annotation>
<xsd:documentation>A publication year</xsd:documentation>
</xsd:annotation>
<xsd:restriction base="xsd:gYear">
<xsd:minInclusive value="1000"/>
<xsd:maxInclusive value="2100"/>
</xsd:restriction>
</xsd:simpleType>
The minInclusive element sets the minimum value allowed for the new pubYear datatype and the maxInclusive element sets the maximum value allowed.
Alternatively, we could use the maxExclusive and minExclusive elements. They also set upper and lower bounds, but the bounds exclude the named value. In other words, a maxExclusive value of 2100 allows 2099 but not 2100.
There are three length constraining facets: minLength and maxLength, which work together or separately to set lower and upper bounds on a value’s length, and a facet called simply length which requires a specific fixed length.
Length means slightly different things depending on the datatype that it is restricting.
list
If the datatype is a list (e.g.
IDREFS) then the length facets constrain the number of items in the list.
string
If the datatype derives from string (directly or through multiple levels of derivation) then the length facets constrain the number of characters in the string.
binary
Applied to a binary datatype, length facets constrain the number of bytes of decoded binary data.
There are two facets that only apply to decimal numbers and types derived from them. These are totalDigits and fractionDigits.
The first constrains the maximum number of digits in the decimal representation of the number and the second constrains the maximum number of digits in the fractional part (after the .). For instance it would make sense when dealing with dollars to constrain the fractionDigits to two.
You can also define a datatype as a list of allowable values by using several enumeration elements. In Example 21-6, we define a dayOfWeek datatype.
Example 21-6. Defining an enumerated datatype
<xsd:simpleType name="workday">
<xsd:restriction base="xsd:string">
<xsd:enumeration value="Sunday"/>
<xsd:enumeration value="Monday"/>
<xsd:enumeration value="Tuesday"/>
<xsd:enumeration value="Wednesday">
<xsd:annotation>
<xsd:documentation>Halfway there!</xsd:documentation>
</xsd:annotation>
</xsd:enumeration>
<xsd:enumeration value="Thursday"/>
<xsd:enumeration value="Friday">
<xsd:annotation>
<xsd:documentation>Almost done!</xsd:documentation>
</xsd:annotation>
</xsd:enumeration>
<xsd:enumeration value="Saturday"/>
</xsd:restriction>
</xsd:simpleType>
Note that an enumeration element, like all facet-constraining elements, may have an annotation sub-element.
Enumeration elements work together to restrict the value to one of the enumeration values. Enumeration elements are so strict that they supersede any of the base datatype’s constraints. Where other constraints say things like “the value must be higher than X or look like Y”, enumerations say: “the value must be one of these values and not anything else”.
The enumeration values must be legal values of the base datatype. Therefore, if an enumeration datatype derives from another enumeration datatype, the derived datatype may only have values that the base datatype has.
The whiteSpace facet is a little bit different from the others. Rather than constraining the value of a datatype, it constrains the processing. The facet can have one of three values:
preserve
The datatype processor will leave the whitespace alone.
replace
Whitespace of any kind is changed into space characters.
collapse
Sequences of whitespace are collapsed to a single space and leading and trailing whitespace is discarded.
The built-in datatypes all use the value collapse, except for string and types derived from it. Those types include normalizedString, which in turn is a base type for token. As we discussed in 21.1.2.2.2, “Other XML constructs”, on page 451, all of the datatypes that represent names of things (language, Name, NMTOKEN, etc.)derive from tokens.
The most sophisticated and powerful facet is the pattern facet. Patterns have a value attribute that is a regular expression.
The regular expressions that constrain datatypes are based on those used in various programming languages. They have especially close ties to the Perl programming language which integrates regular expressions into its core syntax.
Note
The full regular expression language is quite complicated because of deep support for Unicode. There are also shortcuts to reduce the size of regular expressions. We do not cover all of these. Instead we concentrate on those regular expression features that are used most of the time.
Example 21-7 illustrates some interesting patterns. We’ll explain what goes into them in the following sections.
Example 21-7. Pattern examples
<xsd:simpleType name="even-number">
<xsd:restriction base="xsd:decimal">
<xsd:pattern value="d*[02468]"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:simpleType name="old-fashioned-domain-name">
<xsd:restriction base="xsd:string">
<xsd:pattern value="w+.(com|net|org|gov)"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:simpleType name="phone-number">
<xsd:restriction base="xsd:string">
<xsd:pattern value="(d{3}-)?d{3}-d{4}"/>
</xsd:restriction>
</xsd:simpleType>
The simplest regular expression is just a character. a is a regular expression that matches the character “a”. There is only one string in the world that matches this string.
If we put other letters beside the “a” then the regular expression will match them in order. abcd matches “a” and then “b” and then “c” and then “d”. Once again there is only one string that matches that expression.
A slightly more sophisticated regular expression will match one or more occurrences of the last letter “d”: abcd+. The plus symbol means “one or more of this thing”, where “this thing” is whatever comes just before the plus symbol–typically a character. There are also ? and * symbols available. They stand for “zero or one of the thing” and “zero or more of the thing”. We call these quantifiers.
There is another quantifier that uses curly braces ({}) with one or two numbers between them. The quantifier {3} means that there should be three occurrences of the thing.
So ba{3}d matches “baaad”. It is also possible to express a range: ba{3,7}d matches “baaad”, “baaaad”, “baaaaad”, “baaaaaad” and “baaaaaaad”. The lower bound can go as low as zero, in which case the item is optional (just as if you had used a question mark).
The upper bound can be omitted like this: ba{3,}d. That means that there is no upper bound. That expression is equivalent to baaaa*d which is itself equivalent to baaa+d. All three expressions match three or more occurrences of the middle letter “a”.
We can put these ideas together. For instance ab{2,5}c+d{4} matches one “a” followed by two to five “b”s followed by one or more “c”s followed by exactly 4 “d”s. Example 21-8 demonstrates.
Regular expressions use the | symbol to represent alternatives.
Consider the regular expression yes+|no+. It matches “yes”, “yess”, “yesss”, “no”, “noo”, “nooo” and so forth.
If we want to repeat the whole word yes, we can use parentheses. The regular expression (yes)+|(no)+ matches the strings “yes”, “yesyes”, “yesyesyes”, “no”, “nono”, “nonono”.
We can even use parentheses to group the whole expression: (yes|no)+. This expression allows us to match multiple occurrences of “yes” and “no”. For example: “yes”, “no”, “yesyes”, “yesno”, “noyes”, “nono”, “yesyesyes”, “yesnoyes” and so forth.
There are ways to refer to function characters:
So a
b represents the letter “a” followed by a newline followed by “b”.
There are also ways to refer to the characters that would normally be interpreted as symbols. For instance the + character might be necessary in a regular expression involving mathematics.
Convert a symbol into an ordinary character by preceding it with the symbol
. So?is translated into the ordinary character (not special symbol)?.Convert a backslash symbol to a character like this:
\. Convert two of them like this:\\.The symbol characters you need to handle in this way are:
|. -^?*+{ } ( ) [ ]
It is often useful to be able to refer to lists of characters without explicitly listing all of the characters. For instance it would be annoying to need to enter (1|2|3|4|5|6|7|8|9|0) whenever you want to allow a digit.
Plus there are many Unicode characters that are considered digits that are not in this set. Examples include TIBETAN DIGIT ZERO, GUJARATI DIGIT TWO and DINGBAT NEGATIVE CIRCLED DIGIT NINE. It would not be internationally correct to ignore those!
These sets of reusable characters are known as character classes. They are represented by a backslash character followed by a letter.[6]
This particular character class, digits, is represented by d. So d+ means one or more digits, while d+ad{2,5} means one or more digits, and then the letter “a”, and then two to five more digits. The opposite of this character class is indicated by an upper-case D, meaning anything that is not a digit.
Another major character class is indicated simply by a period (.). It matches any character except a newline or linefeed character. So d.g matches “dig” and “dog” but also “d~g” and “d%g”. The middle character could even be Kanji or Cherokee (both components of Unicode!).
The character class s represents any whitespace character (space, tab, newline, carriage return). S is its opposite. It represents any non-whitespace character.
i represents the set of “initial name” characters–basically letters, the underscore and the colon.[7] I is its opposite: anything that is not an initial name character. c represents the set of all name characters. C is its opposite.[8]
w represents what you might call “word” characters: basically letters, digits, and some symbols (e.g. currency, math). That is to say, characters that are not punctuation, separators or the like. w+ will roughly match a word; W represents the opposite – the characters that are not considered word characters.
You can also create character classes in your regular expressions (though you cannot give them fancy backslash-prefixed names!). The syntax to do this is called a character class expression and it uses square brackets ([]).
For instance to represent the first four characters in the alphabet you would say [abcd]. This simple example could just as easily be represented as (a|b|c|d) but the character class notation allows a couple of tricks that are difficult to emulate with the | symbol.
When you construct a character class expression you can specify ranges. For instance [a-z] represents the characters from “a” through “z” in Unicode (which are the same as in the English alphabet). You can even put multiple ranges together: [a-zA-Z0-9].
Inside square brackets, the characters *, +, (,), {,} and ? are just characters. They have no special meaning. Backslash () remains special because we use that to refer to the built-in character classes (d for digits and so forth). Here is a character class that matches all of them and also matches Unicode digit and word characters: [*+(){}dw].
It is also possible to construct a “negative” character class which includes all of the characters that you do not list. You do this by starting your character class expression with a caret (^) symbol. So to match every character except “a” and “z”, you would use the regular expression: [^az]. If you wanted to match everything except the characters from “a” to “z”, you could do that like this: [^a-z].
XML Schema Datatypes provides a useful library of built-in datatypes and a powerful facility for deriving your own from them. These datatypes can be used in XSDL schema definitions, in DTDs, and with non-XSDL schema languages.
[1] If you do use them, they may have exponents (preceded by “e” or “E”, as in “2.5E5”) and may take the values “NaN”, “INF” and “-INF”.
[2] And the same footnote applies!
[3] In fact, hex is short for hexadecimal, which is the base-16 numbering system.
[4] XSDL would call this a simple type, rather than a datatype, but in this chapter it is clearer to call it a datatype.
[5] There is a way to prevent such overrides, but as it is rarely needed, we don’t cover it here.
[6] Note that the backslash does two different jobs. It turns symbol (punctuation) characters into ordinary characters and ordinary letters into character classes.
[7] The class was renamed from the proper XML terminology of name start characters so that
could have its common regular expression meaning of “newline”.