
chapter 10
Testing Evidence
of Construct Validity
The Multitrait—Multimethod Model
The application illustrated in this chapter uses confirmatory factor analysis (CFA) procedures to test hypotheses bearing on construct validity. Specifically, hypotheses are tested within the framework of a multitrait—multimethod (MTMM) design by which multiple traits are measured by multiple methods. Following from the seminal work of Campbell and Fiske (1959), construct validity research typically focuses on the extent to which data exhibit evidence of (a) convergent validity, the extent to which different assessment methods concur in their measurement of the same trait (i.e., construct; ideally, these values should be moderately high); (b) discriminant validity, the extent to which independent assessment methods diverge in their measurement of different traits (ideally, these values should demonstrate minimal convergence); and (c) method effects, an extension of the discriminant validity issue. Method effects represent bias that can derive from use of the same method in the assessment of different traits; correlations among these traits are typically higher than those measured by different methods.
In the time since its inception, the original MTMM design (Campbell & Fiske, 1959) has been the target of much criticism as methodologists uncovered a growing number of limitations in its basic analytic strategy (see, e.g., Marsh, 1988, 1989; Schmitt & Stults, 1986). Although several alternative MTMM approaches have been proposed in the interim, the analysis of MTMM data within the framework of covariance structure modeling has gained the most prominence and has been the most widely applied methodological strategy (Eid et al., 2008). Within this analytic context, some argue for the superiority of the correlated uniquenesses (CU) model (Kenny, 1976, 1979; Kenny & Kashy, 1992; Marsh, 1989), whereas others support the general CFA (Conway, Scullen, Lievens, & Lance, 2004; Lance, Noble, & Scullen, 2002) or composite direct product models (Browne, 1984b). Nonetheless, a review of the applied MTMM literature reveals that the general CFA model1 has been, and continues to be, the method of choice (Kenny & Kashy, 1992; Marsh & Grayson, 1995). The popularity of this approach likely derives from Widaman's (1985) seminal paper in which he proposed a taxonomy of nested model comparisons. (For diverse comparisons of the correlated uniquenesses, composite direct product, and general CFA models, readers are referred to Bagozzi, 1993; Bagozzi & Yi, 1990; Byrne & Goffin, 1993; Coenders & Saris, 2000; Hernández & González-Romá, 2002; Lance et al., 2002; Marsh & Bailey, 1991; Marsh, Byrne, & Craven, 1992; Marsh & Grayson, 1995; Tomás, Hontangas, & Oliver, 2000; Wothke, 1996). More recent MTMM research, however, has tested various aspects of the correlated traits—correlated methods minus one (CT—C[M–1]) model introduced by Eid (2000; see also Geiser, Eid, & Nussbeck, 2008; Maydeu-Olivares & Coffman, 2006; Pohl & Steyer, 2010): these include examination of specified correlated residuals (Cole, Ciesla, & Steiger, 2007; Saris & Aalberts, 2003), and applications to longitudinal (Courvoisier, Nussbeck, Eid, Geiser, & Cole, 2008; Grimm, Pianta, & Konold, 2009; LaGrange & Cole, 2008) and multilevel (Hox & Kleiboer, 2007) data. (For comparisons of diverse variants of these models, readers are referred to Eid et al., 2008; Pohl & Steyer, 2010; Saris & Aalberts, 2003.)
The present application is taken from a study by Byrne and Bazana (1996), which was based on the general CFA approach to MTMM analysis and based on the early work of Widaman (1985). The primary intent of the original study was to test for evidence of convergent validity, discriminant validity, and method effects related to four facets of perceived competence (social, academic, English, and mathematics) as measured by self-, teacher, parent, and peer ratings for early and late preadolescents and for adolescents in grades 3, 7, and 11, respectively. For our purposes here, however, we focus only on data for late preadolescents (grade 7; n = 193). (For further elaboration of the sample, instrumentation, and analytic strategy, see Byrne & Bazana, 1996.) In addition, however, given that the CU model has become a topic of considerable interest and debate over the past few years, I consider it worthwhile to include this model also in the present chapter. However, given that the CU model represents a special case of, rather than a nested model within, the general CFA framework, I delay discussion and application of this model until later in the chapter.
Rephrased within the context of an MTMM design, the model of interest in this chapter is composed of four traits (social competence, academic competence, English competence, and math competence) and four methods (self-ratings, teacher ratings, parent ratings, and peer ratings). A schematic portrayal of this model is presented in Figure 10.1.
The General CFA Approach to MTMM Analyses
In testing for evidence of construct validity within the framework of the general CFA model, it has become customary to follow guidelines set forth by Widaman (1985). As such, the hypothesized MTMM model is compared with a nested series of more restrictive models in which specific parameters are either eliminated or constrained equal to zero or 1.0. The difference in χ2 (Δχ2) between these competing models provides the yardstick by which to judge evidence of convergent and discriminant validity. Although these evaluative comparisons are made solely at the matrix level, the CFA format allows for an assessment of construct validity at the individual parameter level. A review of the literature bearing on the CFA approach to MTMM analyses indicates that assessment is typically formulated at both the matrix and the individual parameter levels; we examine both in the present application.
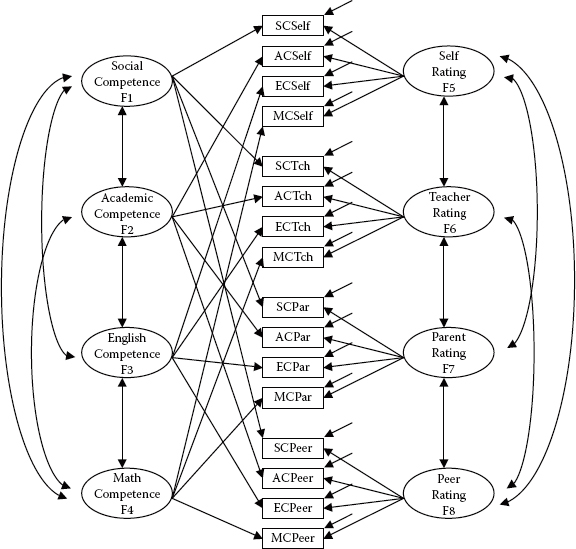
Figure 10.1. Hypothesized correlated traits/correlated methods (CTCM) MTMM model.
The Hypothesized Model
The MTMM model portrayed in Figure 10.1 represents the hypothesized model and serves as the baseline against which all other alternatively nested models are compared in the process of assessing evidence of construct and discriminant validity. Clearly, this CFA model represents a much more complex structure than any of the CFA models examined thus far in this book. This complexity arises primarily from the loading of each observed variable onto both a trait and a method factor. In addition, the model postulates that, although the traits are correlated among themselves, as are the methods, any correlations between traits and methods are assumed to be zero.2
Testing for evidence of convergent and discriminant validity involves comparisons between the hypothesized model (Model 1) and three alternative MTMM models. We turn now to a description of these four nested models; they represent those most commonly included in CFA MTMM analyses.
Model 1: Correlated Traits and Correlated Methods (CTCM)
The first model to be tested (Model 1) represents the hypothesized model shown in Figure 10.1 and serves as the baseline against which the three alternative general CFA models are compared. As noted earlier, because its specification includes both trait and method factors, and allows for correlations among traits and among methods, this model is typically the least restrictive.
Before working through these analyses, however, I need first to clarify both the names of the variables and one aspect of the model structure. First, the observed variables occupying the first small rectangle in each set of four rectangles shown in the center of the figure (SCSelf, SCTch, SCPar, SCPeer) represent general Social Competence (SC) scores as derived from self-, teacher, parent, and peer ratings. Likewise, for each of the remaining traits (Academic SC, English SC, and Math SC) there are ratings by self, teacher, parents, and peers. Second, note that although the traits and methods are correlated among themselves, there are no double-headed curved arrows indicating correlations among traits and methods.
Mplus Input File Specifications and Output File Results
Let's move on now to a review of the input file for Model 1, which is shown in Figure 10.2.
Input File 1
At least four aspects of this first input file are of particular import. First, although I have referred to this model as Model 1 in the group of four general CFA models to be tested, I caution you not to include the term Model 1 in the TITLE command as it triggers the program to think you are working with a multigroup model. As a result, you will receive the following error message:

Figure 10.2. Mplus input file for test of correlated traits/correlated methods (CTCM) MTMM model.
*** ERROR in MODEL command
Unknown group name 1 specified in group-specific MODEL command.
Second, note that the first variable in each congeneric set of indicator variables (e.g., SCSELF) is accompanied by an asterisk, thereby indicating that it is to be freely estimated rather than fixed to a value of 1.0 by default. Alternatively, as in Chapter 8, model identification is accomplished by fixing each of the factor variances to 1.0 (F1 - F8@1).
Third, as noted earlier and consistent with Figure 10.1, all correlations among trait and method factors are fixed to zero. Finally, given the complexity of this hypothesized model, I strongly recommend that you include the TECH1 option in the OUTPUT command as it is a boon in helping you to determine if you have specified the model correctly.
Output File 1
In reviewing results related to this initial test of the CTCM model, we find that although model estimation terminated normally, the output included the two warning messages shown in Figure 10.3. Both warnings address the issue of nonpositive matrices and represent a common occurrence in analysis of MTMM models based on the general CFA model. Indeed, so pervasive is this problem that the estimation of proper solutions may be regarded as a rare find (see, e.g., Kenny & Kashy, 1992; Marsh, 1989). Although these results can be triggered by a number of factors, one likely cause in the case of MTMM models is overparameterization of the model (Wothke, 1993), with this condition likely occurring as a function of the complexity of model specification. It is the very commonality of these improper solutions that has motivated researchers, such as those noted earlier, to seek alternative approaches to the analysis of MTMM data.
Typically, when these improper solutions occur, the offending parameter represents a negative variance associated either with a residual or with a factor, which is consistent with the messages reported in Figure 10.3. Indeed, a review of the parameter estimates revealed a negative variance associated with the residual ACSELF as reported in Table 10.1.

Figure 10.3. Mplus output file warning message related to test of correlated traits/correlated methods (CTCM) MTMM model.
Table 10.1 Mplus Output:
Residual Error Variance and R-Square Estimates for Model 1
(Correlated Traits/Correlated Methods)
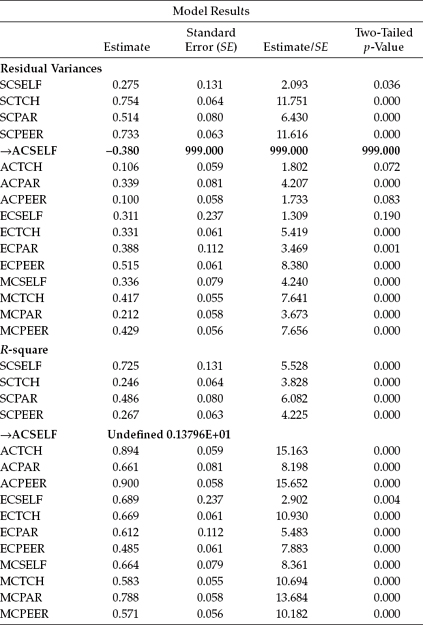
Table 10.2 Mplus Output: Selected Goodness-of-Fit Statistics for Model 1 (Correlated Traits/Correlated Methods)
| The Model Estimation Terminated Normally: Tests of Model Fit |
||
| Chi-Square Test of Model Fit | ||
| Value | 77.164 | |
| Degrees of freedom | 77 | |
| p–value | 0.4733 | |
| CFI/TLI | ||
| CFI | 1.000 | |
| TLI | 1.000 | |
| Root Mean Square Error of Approximation (RMSEA) | ||
| Estimate | 0.003 | |
| 90 percent confidence interval (CI) | 0.000 | 0.041 |
| Probability RMSEA <= .05 | 0.990 | |
| Standardized Root Mean Square Residual (SRMR) | ||
| Value | 0.042 | |
One approach to the resolution of this improper outcome is to impose an equality constraint between parameters having similar estimates (Marsh et al., 1992). However, specification of an equality constraint between the residuals of ACSELF and ECSELF (see the similarity of estimates in Table 10.1) only yielded a different error message that there was no convergence. A second approach to addressing the presence of a negative variance, however, is to simply fix the parameter to a value of zero. Addition of this constraint for the ACSELF residual led to a proper solution. Goodness-of-fit statistics for this model are reported in Table 10.2.
As evidenced from these results, the fit between this respecified CTCM model and the data must be considered perfect. Indeed, had additional parameters been added to the model as a result of post hoc analyses, I would have concluded that the results were indicative of an overfitted model. However, because this was not the case, I can only presume that the model fits the data exceptionally well. We turn now to an examination of Model 2, the first of three MTMM models against which the modified Model 1 will be compared.
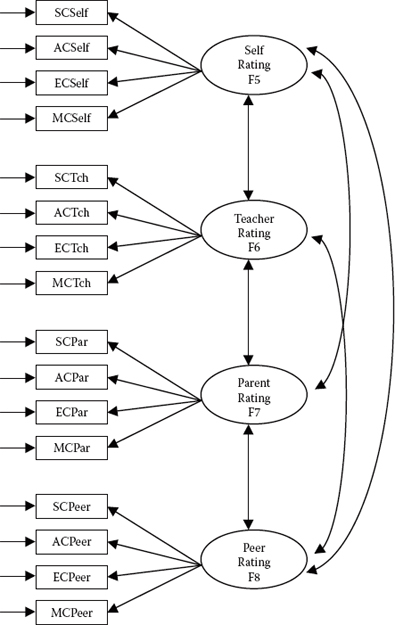
Figure 10.4. Hypothesized no traits/correlated methods (NTCM) MTMM model.
Model 2: No Traits/Correlated Methods (NTCM)
Specification of parameters for this model is portrayed schematically in Figure 10.4 and, within the context of the related Mplus input file, in Figure 10.5. Of major importance with this model is the total absence of trait factors. It is important to note also that for purposes of comparison across all four general CFA MTMM models, the constraint of ACSELF at zero was maintained throughout. Goodness-of-fit for this NTCM model proved to be poor (χ2[99] = 335.635; CFI = 0.829; RMSEA = 0.111; SRMR = 0.084).

Figure 10.5. Mplus input file for test of no traits/correlated methods (NTCM) MTMM model.
Model 3: Perfectly Correlated Traits/Freely Correlated Methods (PCTCM)
In reviewing the schematic presentation of Model 3 in Figure 10.6, together with its input file specification in Figure 10.7, we can see that, as with the hypothesized CTCM model (Model 1), each observed variable loads on both a trait and a method factor. However, in stark contrast to the CTCM Model 1, this MTMM model argues for trait correlations that are perfect (i.e., they are equal to 1.0); consistent with both Models 1 and 2, the method factors are freely estimated.
In reviewing the input file in Figure 10.7, you will quickly note that, as with specification for Model 1 (see Figure 10.2), all correlations between traits and methods are fixed to 0.0. In addition, however, all correlations among the traits are fixed to a value of 1.00, and, as noted above, ACSELF was fixed at zero. Although goodness-of-fit results for this model (Model 3) were substantially better than for Model 2, they nonetheless were indicative of only a marginally well-fitting model and one that was somewhat less well fitting than Model 1( χ2[83] = 216.164; CFI = 0.904; RMSEA = 0.091; SRMR = 0.071).
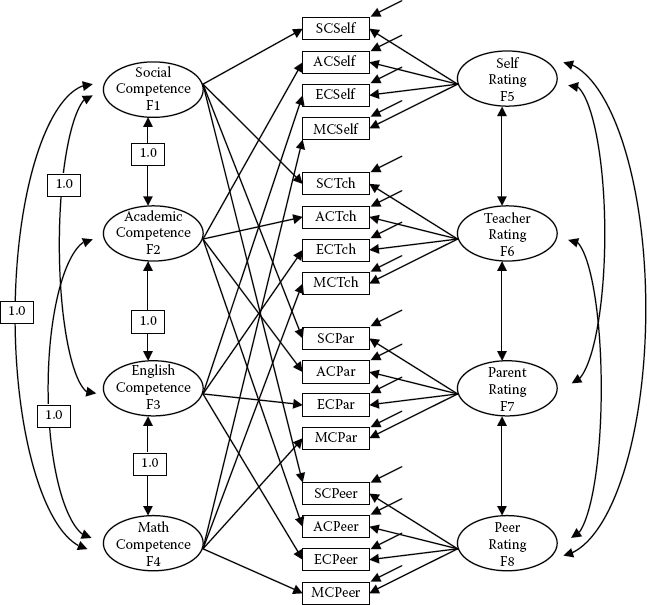
Figure 10.6. Hypothesized perfectly correlated traits/correlated methods (CTCM) MTMM model.
Model 4: Freely Correlated Traits/Uncorrelated Methods (CTUM)
This final MTMM model is portrayed in Figure 10.8 and specified in its related input file (see Figure 10.9). It differs from Model 1 only in the absence of specified correlations among the method factors. Goodness-of-fit results for this model revealed an exceptionally good fit to the data (χ2[83] = 111.117; CFI = 0.980; RMSEA = 0.042; SRMR = 0.067).
Examining Evidence of Construct Validity at the Matrix Level
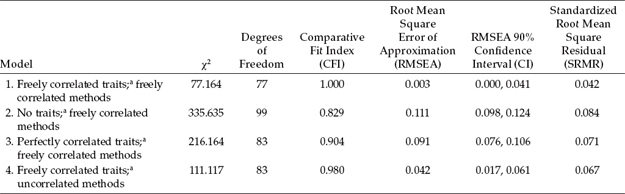
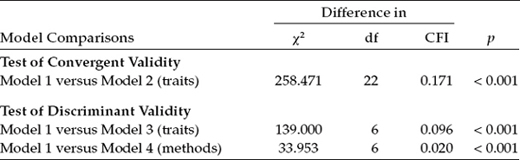
Now that we have examined goodness-of-fit results for each of the four general CFA MTMM models, we can turn to the task of determining evidence of construct and discriminant validity. Accordingly, we ascertain information at the matrix level only through the comparison of particular pairs of models. A summary of goodness-of-fit statistics related to all four MTMM models is presented in Table 10.3, and a summary of model comparisons in Table 10.4.
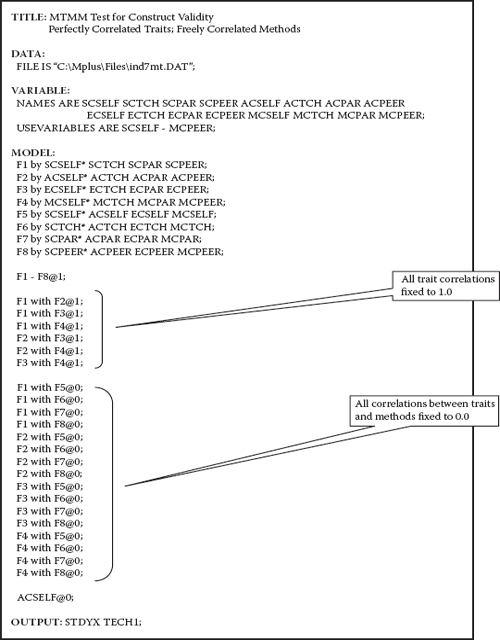
Figure 10.7. Mplus input file for perfectly correlated traits/correlated methods (CTCM) MTMM model.
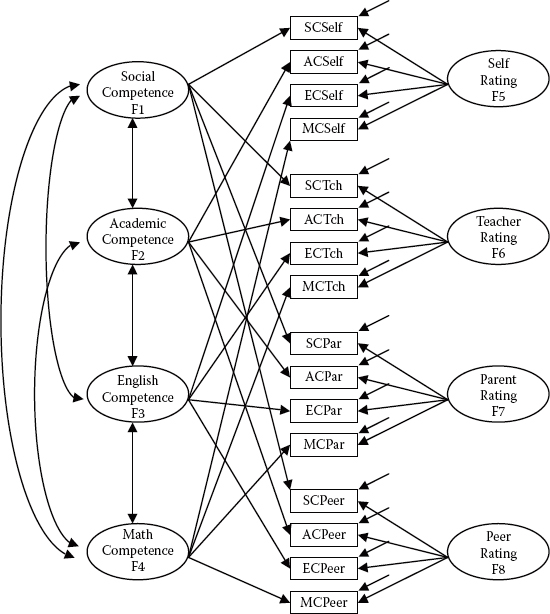
Figure 10.8. Hypothesized correlated traits/uncorrelated methods (CTUM) MTMM model.
Determining Evidence of Convergent Validity
As noted earlier, one criterion of construct validity bears on the convergent validity, the extent to which independent measures of the same trait are correlated (e.g., teacher and self-ratings of social competence); these values should be substantial and statistically significant (Campbell & Fiske, 1959). Using Widaman's (1985) paradigm, evidence of convergent validity can be tested by comparing a model in which traits are specified (Model 1) with one in which they are not (Model 2), the difference in χ2 (Δχ2) between these two nested models providing the basis for judgment; a significant difference in χ2 values supports evidence of convergent validity. In an effort to provide indicators of nested model comparisons that were more realistic than those based on the χ2 statistic, Bagozzi and Yi (1990), Widaman (1985), and others have examined differences in CFI values. However, until the work of Cheung and Rensvold (2002), these ΔCFI values have served in only a heuristic sense as an evaluative base upon which to determine evidence of convergent and discriminant validity. As noted in Chapter 9, these authors examined the properties of 20 goodness-of-fit indices within the context of invariance testing and arbitrarily recommended that ΔCFI values should not exceed 0.01. Although the present application does not include tests for invariance, the same principle holds regarding model comparisons. As shown in Table 10.4, the Δχ2 is highly significant (χ2[22] = 258.471, p < 0.001),3 and the difference in practical fit (ΔCFI = 0.171) substantial, thereby arguing for the tenability of this criterion (i.e., evidence of convergent validity).
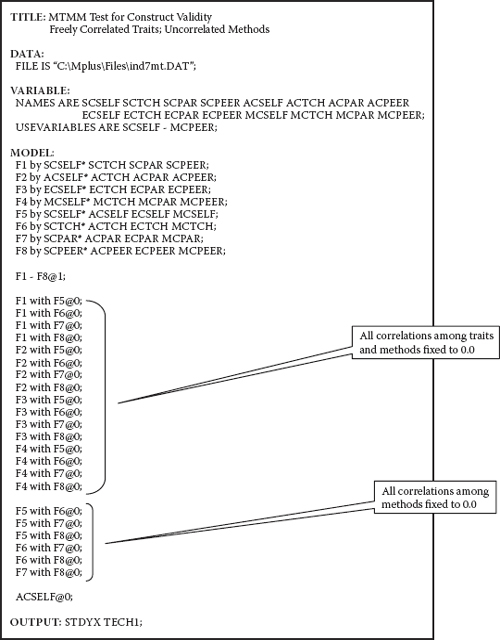
Figure 10.9. Mplus input file for test of correlated traits/uncorrelated methods (CTUM) MTMM model.
Table 10.3 Summary of Goodness-of-Fit Statistics for General Confirmatory Factor Analysis (CFA) Multitrait-Multimethod (MTMM) Models
a Represents respecified model with one residual (ACSELF) fixed at 0.0.
Table 10.4 Differential Goodness-of-Fit Indices for General CFA MTMM Nested Model Comparisons
df = degrees of freedom
Determining Evidence of Discriminant Validity
Discriminant validity is typically assessed in terms of both traits and methods. In testing for evidence of trait discriminant validity, interest focuses on the extent to which independent measures of different traits are correlated; these values should be negligible. When the independent measures represent different methods, correlations bear on the discriminant validity of traits; when they represent the same method, correlations bear on the presence of method effects, another aspect of discriminant validity.
In testing for evidence of discriminant validity among traits, we compare a model in which traits correlate freely (Model 1) with one in which they are perfectly correlated (Model 3); the larger the discrepancy between the χ2 and CFI values, the stronger the support for evidence of discriminant validity. Accordingly, this comparison yielded a Δχ2 value that was statistically significant (χ2[6] = 139.000, p < 0.001) and a difference in practical fit that was fairly large (ΔCFI = 0.096), thereby suggesting only modest evidence of discriminant validity.
Based on the same logic, albeit in reverse, evidence of discriminant validity related to method effects can be tested by comparing a model in which method factors are freely correlated (Model 1) with one in which they are uncorrelated (Model 4). As such, a large Δχ2 (or substantial ΔCFI) argues for the lack of discriminant validity and, thus, for common method bias across methods of measurement. On the strength of both statistical (Δχ2[6] = 33.953) and nonstatistical (ΔCFI = 0.020) criteria, as shown in Table 10.4, it seems reasonable to conclude that evidence of discriminant validity for the methods was substantially stronger than it was for the traits.
Examining Evidence of Construct Validity at the Parameter Level
A more precise assessment of trait- and method-related variance can be ascertained by examining individual parameter estimates. Specifically, the factor loadings and factor correlations of the CTCM model (Model 1) provide the focus here. Because it is difficult to envision the MTMM pattern of factor loadings and correlations from the output when more than six factors are involved, these values have been tabled to facilitate the assessment of convergent and discriminant validity; standardized estimates for the factor loadings are summarized in Table 10.5, and for the factor correlations in Table 10.6. (For a more extensive discussion of these MTMM findings, see Byrne & Bazana, 1996.) We turn first to a review of the trait and method factor loadings reported in Table 10.5.
Determining Evidence of Convergent Validity
In examining individual parameters, convergent validity is reflected in the magnitude of the trait loadings. As indicated in Table 10.5, all trait loadings related to Academic Competence, in addition to English Competence as measured by peers, were found not to be statistically significant. In a comparison of factor loadings across traits and methods, we see that method variance exceeds trait variance in a little over half of the ratings; these include self-ratings of Academic Competence; teacher ratings of Academic, English, and Math Competence; parent ratings of Academic Competence; and peer ratings of all four competence traits.4 Thus, although at first blush evidence of convergent validity appeared to be fairly good at the matrix level, more in-depth examination at the individual parameter level reveals the attenuation of traits by method effects related mainly to teacher and peer ratings, thereby tempering evidence of convergent validity (see also Byrne & Goffin, 1993, with respect to adolescents).
Table 10.5 Trait and Method Loadings for General CFA MTMM Model 1 (Correlated Traits/Correlated Methods)a
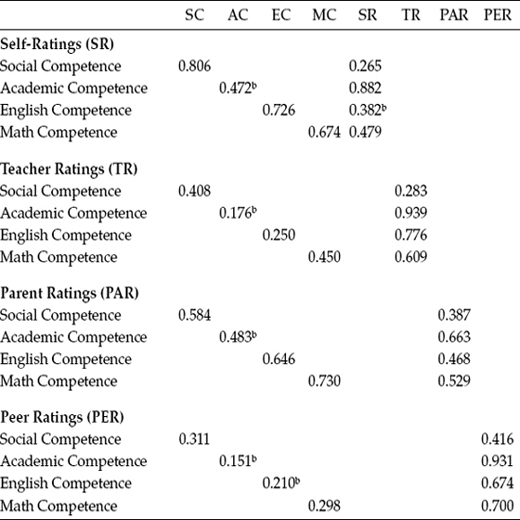
a Standardized estimates.
b Not statistically significant (p < .05).
Determining Evidence of Discriminant Validity
Discriminant validity bearing on particular traits and methods can be evaluated by examining the factor correlation matrices. Although, conceptually, correlations among traits should be negligible in order to satisfy evidence of discriminant validity, such findings are highly unlikely in general, and with respect to psychological data in particular. Although these findings, as reported in Table 10.6, suggest that relations between perceived Academic Competence (AC) and the subject-specific competencies of English (EC) and Math (MC) are most detrimental to the attainment of trait discriminant validity, they are nonetheless consistent with construct validity research in this area as it relates to late preadolescent children (see Byrne & Worth Gavin, 1996).
Table 10.6 Trait and Method Correlations for General CFA MTMM Model 1 (Correlated Traits/Correlated Methods)a
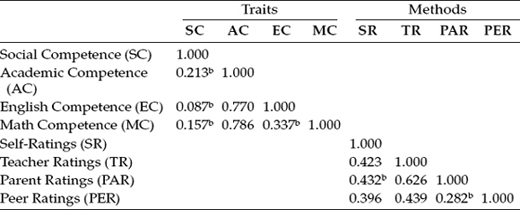
a Standardized estimates.
b Not statistically significant (p < .05).
We turn next to a review of the method factor correlations. Estimated values of these parameters reflect on their discriminability and thus on the extent to which the methods are maximally dissimilar, an important underlying assumption of the MTMM strategy (see Campbell & Fiske, 1959). Given the obvious dissimilarity of self-, teacher, parent, and peer ratings, it is somewhat surprising to find a correlation of .626 between teacher and parent ratings of competence. One possible explanation of this finding is that, except for minor editorial changes necessary in tailoring the instrument to either the teacher or parent as respondents, the substantive content of all comparable items in the teacher and parent rating scales were identically worded, the rationale here being to maximize responses by different raters of the same student.
The Correlated Uniquenesses Approach to MTMM Analyses
As noted earlier, the CU model represents a special case of the general CFA model. Building upon the early work of Kenny (1976, 1979), Marsh (1988, 1989) proposed this alternative MTMM model in answer to the numerous estimation and convergence problems encountered with analyses of general CFA models and, in particular, of the CTCM model (Model 1 in this application). More recently, however, research has shown that the CU model also is not without its own problems, and researchers have proposed a number of specification alternatives to the general CU model (see, e.g., Cole et al., 2007; Conway et al., 2004; Corten, Saris, Coenders, van der Veld, Aalberts, & Kornelis, 2002; Lance et al., 2002). The hypothesized CU model tested here, however, is based on the originally postulated CU model (see, e.g., Kenny, 1976, 1979; Kenny & Kashy, 1992; Marsh, 1989). A schematic representation of this model is shown in Figure 10.10.
In reviewing the model depicted in Figure 10.10, you will note that it embodies just the four correlated trait factors; in this aspect only, it is consistent with the model shown in Figure 10.1. The notably different feature about the CU model, however, is that although no method factors are specified per se, their effects are implied from the specification of correlated residual terms (the uniquenesses)5 associated with each set of observed variables embracing the same method. For example, as indicated in Figure 10.10, all residuals associated with self-rating measures of Social Competence are correlated with one another; likewise, those associated with teacher, parent, and peer ratings are intercorrelated.
Consistent with the CTUM model (Model 4 in this application), the CU model assumes that effects associated with one type of method are uncorrelated with those of the other methods (Marsh & Grayson, 1995). However, one critically important difference between the CU model and both the CTCM (Model 1) and CTUM (Model 4) models involves the assumed unidimensionality of the method factors. Whereas Models 1 and 4 implicitly assume that the method effects associated with a particular method are unidimensional (i.e., they can be explained by a single latent method factor), the CU model makes no such assumption (Marsh & Grayson, 1995). These authors further noted that when an MTMM model includes more than three trait factors, this important distinction can be tested. However, when the number of traits equals three, the CU model is formally equivalent to the other two in the sense that the “number of estimated parameters and model goodness-of-fit are the same, and parameter estimates from one can be transformed into the other” (Marsh & Grayson, 1995, p. 185).
Of course, from a practical perspective, the most important distinction between the CU model and Models 1 and 4 is that it typically results in a proper solution (Kenny & Kashy, 1992; Marsh, 1989; Marsh & Bailey, 1991). The CTCM model (Model 1), on the other hand, is now notorious for its tendency to yield inadmissible solutions, as we observed in the present application. As a case in point, Marsh and Bailey, in their analyses of 435 MTMM matrices based on both real and simulated data, reported that whereas the CTCM model resulted in improper solutions 77% of the time, the CU model yielded proper solutions nearly every time (98%). (For additional examples of the incidence of improper solutions with respect to Model 1, see Kenny & Kashy, 1992.) We turn now to the analyses based on the CU model.
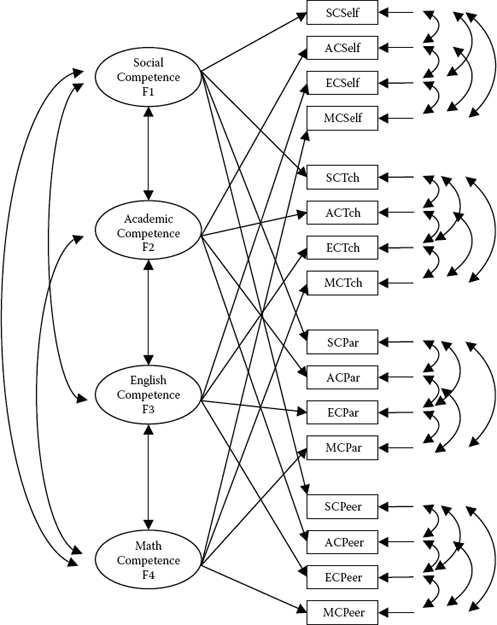
Figure 10.10. Hypothesized correlated uniquenesses (CU) MTMM model.
Input File
Reviewing, once again, the model depicted in Figure 10.10, we see that there are four trait factors and that these factors are hypothesized to correlate among themselves. In lieu of the method factors specified for the general CFA models, however, the correlated residuals for each set of observed variables measuring the same method of measurement are considered to reflect these method effects. The related input file is shown in Figure 10.11. Of particular note here, of course, is the specific correlations among each set of residuals.
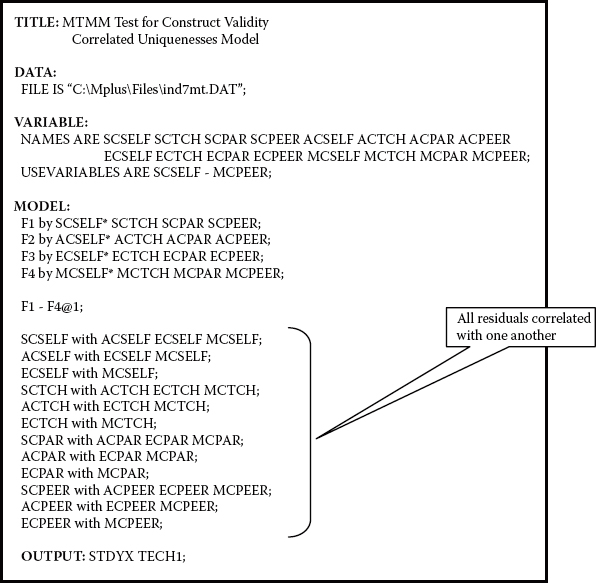
Figure 10.11. Mplus input file for test of correlated uniquenesses (CU) MTMM model.
Output File
In reviewing results for the CU model, we turn first to the goodness-of-fit statistics, which are presented in Table 10.7. As shown here, it is easy to see that this model represents an excellent fit to the data. Furthermore, consistent with past reported results (e.g., Kenny & Kashy, 1992; Marsh & Bailey, 1991), this solution resulted in no lack of convergence or problematic parameter estimates.
Assessment of convergent and discriminant validity for the CU model can be accomplished in the same way that it was for the General CFA model when focused at the individual parameter level. As shown in Table 10.8, evidence related to the convergent validity of the traits, not surprisingly, was substantial and somewhat higher than for the CTCM model (Model 1; see Table 10.5). Indeed, there are two notable and interesting differences between these two models. First, whereas the CTCM model resulted in five trait-loading estimates that were not statistically significant, the CU model resulted in all estimates being statistically significant. Second, with the exception of all ratings pertinent to Social Competence, as well as self-ratings of English Competence, all remaining trait loadings for the CU model were higher than those for the CTCM model.
Table 10.7 Mplus Output: Selected Goodness-of-Fit Statistics for the Correlated Uniquenesses Model
| Tests of Model Fit | ||
| Chi-Square Test of Model Fit | ||
| Value | 96.975 | |
| Degrees of freedom | 74 | |
| p–value | 0.0379 | |
| CFI/TLI | ||
| CFI | 0.983 | |
| TLI | 0.973 | |
| Root Mean Square Error of Approximation (RMSEA) | ||
| Estimate | 0.040 | |
| 90 percent confidence interval (CI) | 0.010 | 0.061 |
| Probability RMSEA <= .05 | 0.766 | |
| Standardized Root Mean Square Residual (SRMR) | ||
| Value | 0.067 | |
Let's look now at the factor correlations relevant only to the traits; these estimates are presented in Table 10.9. In reviewing these values, we see that all but one estimated correlation are statistically significant, and virtually all trait estimates higher than they were for the CTCM model. One commonality between the two models, however, was the nonsignificant estimate of the correlation between Social Competence and English Competence.
Method effects in the CU model are determined by the degree to which the residuals terms are correlated with one another (Kenny & Kashy, 1992), and these estimates for the CU model are presented in Table 10.10. It is interesting to note that the strongest method effects are clearly associated with teacher and peer ratings of the two specific academic competencies of English (0.684 and 0.579, respectively) and math (0.511 and 0.652, respectively). Indeed, from a substantive standpoint, these findings certainly seem perfectly reasonable. On the other hand, the strong method effects shown by self- and parent ratings of only the academic area of Math Competence (0.556 and 0.467, respectively) are intriguing. One possible explanation may lie in the fact that perceptions of Academic Competence are unintentionally equated with Math Competence. In other words, self-perceptions as well as parental perceptions of academic competence appear to be defined in terms of one's competence in math.
Table 10.8 Trait-Loading Estimates for Correlated Uniquenesses Modela
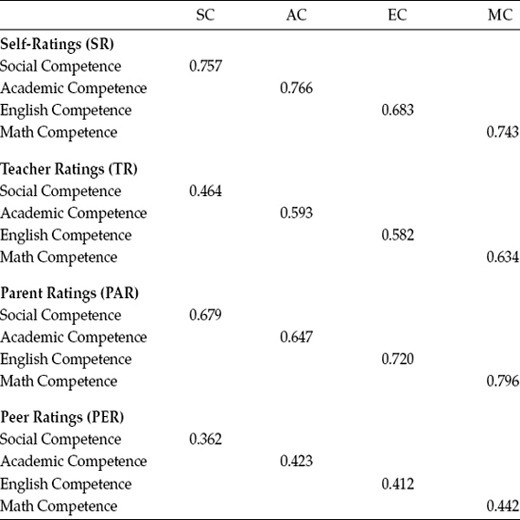
a Standardized estimates.
Table 10.9 Trait Correlation Estimates for Correlated Uniquenesses Modela
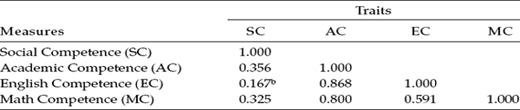
a Standardized estimates.
b Not statistically significant (p < .05).
Table 10.10 Residual Correlation Estimates for Correlated Uniquenesses Modela
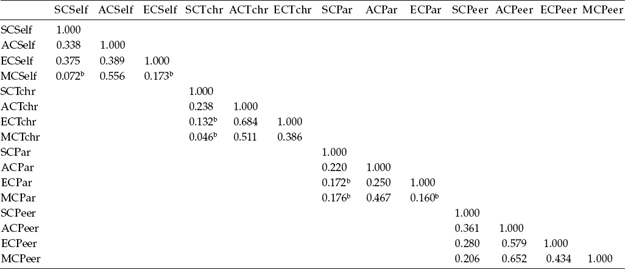
a Standardized estimates.
b Not statistically significant (p < .05).
In contrast to the CTCM model, the CU model makes no assumption that each method factor remains the same for all measures embracing the same method. Rather, as Kenny and Kashy (1992) explained, “In the Correlated Uniqueness model, each measure is assumed to have its own method effect, and the covariances between measures using the same method assess the extent to which there is a common method factor” (p. 169). In other words, as Kenny and Kashy further noted, whereas the General CFA MTMM model assumes that method effects are invariant across traits, the CU model allows for the multidimensionality of method effects. (For critiques of these effects, see Conway et al., 2004; Lance et al., 2002. For an attempt to understand the substance of these correlated residual terms, see Saris & Aalberts, 2003.)
In closing out this chapter, it is worthwhile to underscore Marsh and Grayson's (1995) recommendation regarding the analysis of MTMM data. As they emphasized, “MTMM data have an inherently complicated structure that will not be fully described in all cases by any of the models or approaches typically considered. There is, apparently, no ‘right’ way to analyze MTMM data that works in all situations” (Marsh & Grayson, 1995, p. 198). Consequently, Marsh and Grayson (1995), supported by Cudeck (1989), strongly advised that in the study of MTMM data, researchers should always consider alternative modeling strategies (see, e.g., Cole et al., 2007; Eid et al., 2008; Pohl & Steyer, 2010). In particular, Marsh and Grayson (1995) suggested an initial examination of data within the framework of the original Campbell-Fiske guidelines. This analysis should then be followed by the testing of a subset of at least four CFA models (including the CU model); for example, the five models considered in the present application would constitute an appropriate subset. Finally, given that the composite direct product model6 is designed to test for the presence of multiplicative rather than additive effects, it should also be included in the MTMM analysis alternative approach strategy. (But, for a critique of this approach, readers are referred to Corten et al., 2002.). In evaluating results from each of the covariance structure models noted here, Marsh and Grayson (1995) cautioned that, in addition to technical considerations such as convergence to proper solutions and goodness-of-fit, researchers should place a heavy emphasis on substantive interpretations and theoretical framework.
Notes
| 1. | The term general is used to distinguish the generic CFA model from other special cases, such as the CU model (see Marsh, 1989). |
| 2. | As a consequence of problems related to both the identification and estimation of CFA models, trait-method correlations cannot be freely estimated (see Schmitt & Stults, 1986; Widaman, 1985). |
| 3. | Given that the data were normally distributed, analyses were based on maximum likelihood (ML) estimation. Thus, the chi-square difference value required no scaling correction. |
| 4. | Trait and method variance, within the context of the general CFA MTMM model, equals the factor loading squared. |
| 5. | As noted in Chapter 3, the term uniqueness is used in the factor analytic sense to mean a composite of random measurement error and specific measurement error associated with a particular measuring instrument. |
| 6. | Whereas CFA models assume that test scores represent the sum of trait and method components (i.e., additive effects), the composite direct product model assumes that they derive from the product of the trait and method components (i.e., multiplicative effects). |