
Chapter 1
What Is Agile Data Warehousing?
How are agile approaches different than traditional methods?
What does it take to make agile succeed for data warehousing projects?
Where do we have to be careful with this new approach?
Faster, better, cheaper. That’s the promise that agile methods have been delivering upon during the past decade for general application development. Although they are an increasingly popular style of programming for transaction-processing or data- capture applications, they have not been employed nearly as much for data warehousing/business intelligence (DWBI) applications. It usually takes a combination of project disasters and existential threats to inspire corporate DWBI departments to consider replacing their traditional development methods. Typically, the impetus to change begins after several projects seriously overrun their go-live dates and/or forecasted delivery budgets. Next, the project sponsors in the company’s business departments start to grumble. “Our corporate data warehousing department is way too slow and far too expensive.” Eventually, one end-user department finds a way to build an analytical application using an outside services vendor and reports to the other business leads that this new system required a fraction of corporate DWBI’s typical time and cost brackets. “Should we send all of our business intelligence (BI) work to outside vendors?” the business departments begin asking themselves. It does not matter to them that outside vendors trying to deliver fast frequently neglect to program the many hidden attributes needed to make a system manageable, scalable, and extensible over the long run. All the business sponsors saw was fast delivery of what they asked for. If the business units are frustrated over time and cost, corporate DWBI will survive only if it finds a way to accelerate its deliveries and lower programming expense, restoring its rapport with the customer. This type of predicament is exactly why corporate DWBI should consider agile data warehousing techniques.
On the one hand, it is easy to understand why the popularity of agile for data warehousing lags 10 years behind its usage for general applications. It is hard to envision delivering any DWBI capabilities quickly. For data capture applications, creating a new element requires simply creating a column for it in the database and then dropping an entry field for it on the screen. To deliver a new warehousing attribute, however, a team has to create several distinct programs to extract, scrub, integrate, and dimensionalize the data sets containing the element before it can be placed on the end user’s console. Compared to the single transaction application challenge that agile methods originally focused on, data warehousing projects are trying to deliver a half-dozen new applications at once. They have too many architectural layers to manage for a team to update the data transform logic quickly in order to satisfy a program sponsor’s latest functional whim.
On the other hand, data warehousing professionals need to be discussing agile methods intently, because every year more business intelligence departments large and small are experimenting with rapid delivery techniques for analytic and reporting applications. To succeed, they are adapting the generic agile approaches somewhat, but not beyond recognition. These adaptations make the resulting methods one notch more complex than agile for transaction-capture systems, but they are no less effective. In practice, agile methods applied properly to large data integration and information visualization projects have lowered the development hours needed and driven coding defects to zero. All this is accomplished while placing a steady stream of new features before the development team’s business partner. By saving the customer time and money while steadily delivering increments of business value, agile methods for BI projects go a long way toward solving the challenges many DWBI departments have with pleasing their business customers.
For those readers who are new to agile concepts, this chapter begins with a sketch of the method to be followed throughout most of this book. The next sections provide a high-level contrast between traditional development methods and the agile approach, and a listing of the key innovative techniques that give agile methods much of their delivery speed. After surveying evidence that agile methods accelerate general application development, the presentation introduces a key set of adaptations that will make agile a productive approach for data warehousing. Next, the chapter outlines two fundamental challenges unique to data warehousing that any development method must address in order to succeed. It then closes with a guide to the remainder of the book and a second volume that will follow it.
A quick peek at an agile method
The practice of agile data warehousing is the application of several styles of iterative and incremental development to the specific challenges of integrating and presenting data for analytics and decision support. By adopting techniques such as colocating programmers together in a single workspace and embedding a business representative in the team to guide them, companies can build DWBI applications without a large portion of the time-consuming procedures and artifacts typically required by formal software development methods. Working intently on deliverables without investing time in a full suite of formal specifications necessarily requires that developers focus only on a few deliverables at time. Building only small pieces at a time, in turn, repeats the delivery process many times. These repeated deliveries of small scopes place agile methods in the category of “iterative and incremental development” methods for project management.
When following agile methods, DWBI developers essentially roll up their sleeves and work like they have only a few weeks before the system is due. They concentrate on the most important features first and perform only those activities that directly generate fully shippable code, thus realizing a tremendous boost in delivery speed. Achieving breakthrough programming speeds on a BI project will require developers to work differently than most of them are trained, including the way they define requirements, estimate work, design and code their systems, and communicate results to stakeholders, plus the way they test and document the resulting system modules. To make iterative and incremental delivery work, they will also need to change the physical environment in which they work and the role of the project manager. Most traditional DWBI departments will find these changes disorienting for a while, but their disruption will be more than compensated for by the increased programmer productivity they unleash.
Depending on how one counts, there are at least a dozen agile development styles to choose from (see sidebar). They differ by the level of ongoing ceremonies they follow during development and the amount of project planning they invest in before coding begins. By far the most popular flavor of agile is Scrum, first introduced in 1995 by Dr. Jeff Sutherland and Ken Schwaber. [Schwaber 2004] Scrum involves a small amount of both ceremony and planning, making it fast for teams to learn and easy for them to follow dependably. It has many other advantages, among them being that it
• Adroitly organizes a team of 6 to 10 developers
• Intuitively synchronizes coding efforts with repeated time boxes
• Embeds a business partner in the team to maximize customer engagement
• Appeals to business partners with its lightweight requirements artifacts
• Double estimates the work for accuracy using two units of measure
• Forecasts overall project duration and cost when necessary
• Includes regular self-optimizing efforts in every time box
Agile Development Methods
| Adaptive | [Highsmith 1999] |
| Crystal | [Cockburn 2004] |
| Disciplined Agile Delivery | [Ambler 2012] |
| Dynamic Systems Development Method (DSDM) | [Stapleton 2003] |
| Extreme Programming (XP) | [Beck 2004] |
| Feature Driven Development (FDD) | [Palmer 2002] |
| Lean Development | [Poppendieck 2003] |
| Kanban | [Anderson 2010] |
| Pragmatic | [Hunt 1999] |
| Scrum | [Cohn 2009] |
| Unified Processes (Essential, Open, Rational, etc.) | [Jacobson, Booch, & Rumbaugh 1999] |
Scrum has such mindshare that, unless one clarifies he is speaking of another approach, Scrum is generally assumed to be the base method whenever one says “agile.” Even if that assumption is right, however, the listener still has to interpret the situation with care. Scrum teams are constantly optimizing their practices and borrowing techniques from other sources so that they all quickly arrive at their own particular development method. Over time Scrum teams can vary their practice considerably, to the point of even dropping a key component or two such as the time box. Given this diversity in implementations, this book refers to Scrum when speaking of the precise method as defined by Sutherland and Schwaber. It employs the more general term “agile” when the context involves an ongoing project that may well have started with Scrum but then customized the method to better meet the situation at hand.
Figure 1.1 depicts the simple, five-step structure of an iteration with which Scrum teams build their applications. A team of 6 to 10 individuals—including an embedded partner from the customer organization that will own the applications—repeats this cycle every 2 to 8 weeks. The next chapter presents the iteration cycle in detail. Here, the objective is to provide the reader with enough understanding of an agile approach to contrast it with a traditional method.
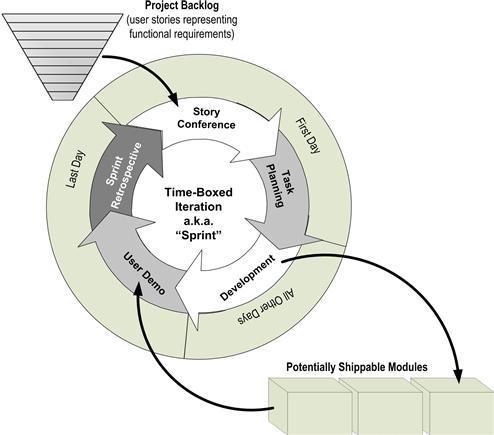
Figure 1.1 Structure of Scrum development iteration and duration of its phases.
As shown in Figure 1.1, a list of requirements drives the Scrum process. Typically this list is described as a “backlog of user stories.” User stories are single sentences authored by the business stating one of their functional needs. The embedded business partner owns this list, keeping it sorted by each story’s importance to the business. With this backlog available, Scrum teams repeatedly pull from the top as many stories as they can manage in one time box, turning them into shippable software modules that satisfy the stated needs. In practice, a minority of the stories on a backlog include nonfunctional features, often stipulated for the application by the project architect. These “architectural stories” call for reusable submodules and features supporting quality attributes such as performance and scalability. Scrum does not provide a lot of guidance on where the original backlog of stories comes from. For that reason, project planners need to situate the Scrum development process in a larger project life cycle that will provide important engineering and project management notions such as scope and funding, as well as data and process architecture.
The standard development iteration begins with a story conference where the developers use a top-down estimating technique using what are called “story points” to identify the handful of user stories at the top of the project’s backlog that they can convert into shippable code during the iteration.
Next, the team performs task planning where it decomposes the targeted user stories into development tasks, this time estimating the work bottom-up in terms of labor hours in order to confirm that they have not taken on too much work for one iteration.
After confirming they have targeted just the right amount of work, the teammates now dive into the development phase, where they are asked to self-organize and create over the next couple of weeks the promised enhancement to the application, working in the most productive way they can devise. The primary ceremony that Scrum places upon them during this phase is that they check in with each other in the morning via a short stand-up meeting, that is, it asks them to hold a daily “scrum.”
At the end of the cycle, the team conducts a user demo where the business partner on the team operates the portions of the application that the developers have just completed, often with other business stakeholders looking on. For data integration projects that have not delivered the information yet to a presentation layer, the team will typically provide a simple front end (perhaps a quickly built, provisional BI module) so that the business partner can independently explore the newly loaded data tables. The business partner evaluates the enhanced application by considering each user story targeted during the story conference, deciding whether the team has delivered the functionality requested.
Finally, before beginning the cycle anew, the developers meet for a sprint retrospective, where they discuss the good and bad aspects of the development cycle they just completed and brainstorm new ways to work together during the next cycle in order to smooth out any rough spots they may have encountered.
At this point, the team is ready to start another cycle. These iterations progress as long as there are user stories on the project’s backlog and the sponsors continue funding the project. During an iteration’s development phase, the team’s embedded business partner may well have reshuffled the order of the stories in the backlog, added some new one, and even discarded others. Such “requirements churn” does not bother the developers because they are always working within the near-planning horizon defined by the iteration’s time box. Because Scrum has the developers constantly focused on only the top of the backlog, the business can steer the team in a completely new direction every few weeks, heading to wherever the project needs to go next. Such flexibility often makes business partners very fond of Scrum because it allows the developers from the information technology (IT) department to become very flexible and responsive.
The “disappointment cycle” of many traditional projects
In contrast to Scrum’s iterative approach to delivering systems, traditional software engineering operates on a single-pass model. The most widely cited definition of this approach can be found in the first half of a 1970 white paper entitled “Managing the Development of Large Software Systems” by a TRW researcher named Dr. Winston Royce. [Royce 1970] This paper has been commonly interpreted to suggest that, in order to avoid conceptual errors and extensive reprogramming of an application, all requirements should be gathered before design begins, all design should be completed before programmers begin coding, and the bulk of coding should be completed before serious testing can get underway. In this process, each work phase should “fill up” with specifications before that information spills over into the next phase—a notion that led many to call this approach a cascade or a “waterfall” method.
Many people describe this waterfall process as the “big design up-front” strategy because it requires enormous design specifications to be drafted and approved before programming work can begin. [Ambler 2011] It has also been called a “plan-driven” or “command and control” approach because the big design results in enormous project plans, with possibly thousands of separate tasks, that project managers use to drive the daily activities of the development teams they command. A further name for this style of organizing development is the “big bang” approach because all the value is theoretically dropped upon end users at the conclusion of the project.
Waterfall-style project organization can seem to be a safe approach for large applications, especially those with multiple, intersecting data layers found in data warehouses, because the engineers supposedly think out all aspects of the project thoroughly ahead of time. Scrum, however, simply takes a few requirements off the top of a list and converts them into code before the next set of features is even considered. In contrast to a waterfall method, Scrum can seem very tactical and ad hoc.
For these reasons, when software professionals first learn of agile, they often decide that a waterfall method must be far more robust. Such conclusions are ironic because waterfall methods have had over 40 years to prove themselves, but statistics show that they struggle to deliver applications reliably. The Standish Group’s seminal “Chaos” reports detailed the software industry’s track record in delivering large systems using traditional methods. [Standish Group 1999] After surveying the results of 8380 projects conducted by 365 major America companies, results revealed that even small projects below $750,000 were unable to deliver applications on time, on budget, and with all the promised features more than 55% of the time. As the size of the applications grew, the success rate fell steadily to 25% for efforts over $3M and down to zero for projects over $10M (1999 dollars).
Data warehousing projects fall easily in the middle to upper reaches of the range documented in the Standish study. Not surprisingly, they, too, have demonstrated trouble reliably delivering value under traditional project management methods. A survey performed in 1994—before agile methods were common—by the data management industry’s primary trade magazine revealed that its readers’ data warehouse projects averaged above $12M in cost and failed 65% of the time. [Cited in Ericson 2006] Such statistics do not indicate that every waterfall-based data warehousing project is destined to fail. However, if the approach was as robust as people often assume, plan-driven, big-bang project methods should have achieved a much higher success rate in the 40 years since Royce’s paper first defined the approach.
Unfortunately, there is a good reason to believe that waterfalls will remain a very risky manner in building large systems: the specifications flowing into any one of its phases will always contain flaws. Being only human, the individuals preparing these enormous artifacts will have less than perfect foresight, especially for companies situated in a world market that is constantly changing. Moreover, in this age of increasing global competition, the engineers producing these specifications are also frequently overworked and given too little time to thoroughly research a project’s problem domain. In this reality, developers working from these specifications will steadily encounter the unexpected. Lamentably, waterfall methods contain no back step that allows the developers to substantially revisit requirements if they encounter a major oversight while coding. Testing, compressed to fit into the very last phase of development, cannot call for a major reconsideration of a system’s design. With plan-driven project management, the team is locked into a schedule. They must hurriedly span the gaps between their specifications and the actual situation because, according to plan, work must move steadily downstream so that the project meets its promised delivery date.
Rather than mitigating project risk, the waterfall approach actually inflates it. Aiming for a big design up front, waterfall processes are heavy with documentation and encumbered with numerous reviews in an effort to avoid oversights. However, large specification documents acquire their own inertia by virtue of the long procedures needed to update and reapprove them. With this inertia, errors committed during requirements or design phases get “baked into” the application because it is either too expensive or too late to substantively rework specifications when flaws are discovered in them. The phases cannot validate nor contribute to one another’s success, making each phase a single point of failure. The entire project will either succeed or fail based on the quality of the requirements package taken in isolation, then the quality of the design taken alone, and then finally the quality of the coding as a whole. Because little flaws cannot be simply corrected when they are discovered, their consequences get amplified to where any one of them can threaten the entire undertaking.
In this light, an iterative approach mitigates risk in an important way. Scrum validates the engineering of each small slice of the project by pushing it through requirements, design, coding, and testing before work on the next set of stories from the backlog begins. Errors detected in any of these engineering steps can provide important guidance on how the team should pursue the remainder of the project. Scrum practitioners note that the method pushes errors to the surface early in the process while there is still time to correct assumptions and the foundations of the project’s coding. (See, for example, [Vingrys 2011].) In contrast to the tendency of a waterfall to allow errors to undermine a whole project, the agile approach works to contain failures to just one project slice at a time.
Being large undertakings by nature, data warehousing initiatives pursued with a single-delivery paradigm demonstrate waterfall’s whole project failure pattern all too often. A quick sampling of horror stories shared with the author by prospective customers seeking a better approach to building business intelligence systems illustrates the point well:
• A major waste management company complained “We hired one of the world’s top systems integrators to build our data warehouse. It cost us $2 million and 3 years of time. All we got was one report. Seems like a very expensive report.”
• A Fortune 500 telecommunications company related with alarm “We purchased a ‘ready-to-use’ enterprise data model from our data warehouse appliance vendor. Once it was in place, their consultants told us they would need 2 years to customize it for our company and 3 years to populate it with data before we could build our first dashboard.
• A Fortune 50 pharmaceuticals company lamented “Our electronic data management project required 150 people for over 3 years and got so expensive it was starting to hurt our share price.”
When large, plan-driven projects begin to fail, the managers start taking extraordinary measures to rebalance budgets, deadlines, and intended features. As depicted in Figure 1.2, such a project starts out with a firm forecast of cost, time, and scope. As it becomes stressed by nasty surprises, time and cost estimates start to climb, forcing sponsors to steadily accept less scope in order to keep the project affordable. After several such crises and delays, the company is eventually grateful to push even a small subset of functions into production and declare some level of victory, although the functionality delivered is far less than promised and the cost often double or more than planned for.
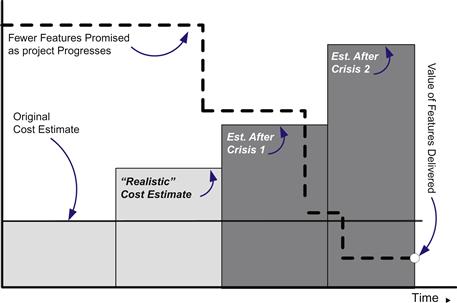
Figure 1.2 All too often, waterfall methods yield to the project “disappointment cycle.”
Data warehousing/business intelligence departments turn this all-too-common pattern of increasing costs and shrinking deliverables into a cycle of disappointment because, still believing that a big design up front is the best strategy, they repeat this basic approach for the next project. They believe the last project failed because they did not manage it carefully enough, and start the next project with even more extensive planning and detailed design.
We can rule out unique occurrences of unusual circumstances as the primary cause for failed projects such as the ones sketched earlier. Unlike Tolstoy’s unhappy families, failed waterfall projects in data warehousing all seem to be miserable for the same basic reasons. On an average engagement, the project manager specifies work packages in excruciating detail with 5000 lines or more in the project plan. He directs and cajoles the developers relentlessly. Everyone works nights and weekends, and still the project runs months behind and millions over budget, delivering only a fraction of what was promised. When the after-project, lessons-learned session is convened, participants will voice the same rueful observations heard on so many previous efforts:
• We should have done better at gathering requirements.
• The business didn’t know what they wanted because they had never seen a warehouse before.
• Design took too long, leaving no time for careful coding.
• Conflicting definitions for data elements made designs worthless.
• Coding went too slow so testing got started far too late to catch some crucial defects.
• Programmers didn’t build what was specified.
• Dirty data created nightmares that undermined our schedule.
• By the time we finally delivered, the business had changed and the customer wanted something else besides what we built.
With each pass through the disappointment cycle, IT and project management typically respond to failure by heaping even more specifications, reviews, and process controls on the development process. The process becomes opaque to the project sponsor and projects take even longer to deliver, leaving the customer increasingly alienated from the software creation process, steadily more frustrated with corporate IT, and wondering ever more intently whether an outside service vendor might have a better way to run a project.
The waterfall method was, in fact, a mistake
If the plan-driven, single-delivery approach to data warehousing provides such problematic results, it is natural to ask how the strategy got started and why many software development organizations continue to advocate it.
Sadly, the waterfall approach became the reigning paradigm only through a series of mistakes originating with the U.S. military. Toward the end of the Viet Nam war, the Department of Defense (DOD) was struggling to establish uniform requirements for software development in order to achieve better results from its systems integration contractors. The DOD issued a series of process specifications, including DOD-STD-2167, issued in 1985, which made the single-pass waterfall method as outlined in Dr. Royce’s white paper the standard approach for procured systems. [DOD 1985]
As the military’s standard for evaluating contractor development processes, DOD-STD-2167 proved to be particularly influential and soon transported the single-pass approach into many further methods descriptions throughout the world. The large-system contractors naturally trained their developers in the approach, and these individuals carried 2167’s plan-driven approach to the successive companies they worked for throughout the remainder of their careers. The resulting waterfall methods proliferated, despite the fact that the military’s experience with the approach was disappointing to say the least. A 1995 report on failure rates in a sample of DOD projects revealed that given the $37 billion spent on these projects, 75% of the projects failed or were never used, and only 2% were utilized without extensive modification. [Jarzombek 99]
Ironically, DOD-STD-2167 can only be viewed as a grievous misreading of Royce’s paper. In its opening pages, Royce identifies the classic waterfall phases, but describes them as only the “essential steps common to all computer program developments, regardless of size or complexity.” In the second half of the document, Royce clearly advocates an iterative path for progressing through these process steps. Pursuing them sequentially from analysis through coding in a single pass “is risky and invites failure,” he warned, suggesting that such a method would work only for “the most uncomplicated projects.”
When interviewed in the mid-1990s, the author of DOD-STD-2167 in fact admitted that he had been unaware of the notion of incremental delivery when he drafted his recommendations, even though there were many such methods available at the time. One can only speculate that, in the rush to fix the military’s software procurement process for development services, he had read no more than the first half of the Royce’s white paper and missed the warning completely. With hindsight, he said, he would have strongly advocated the iterative development method instead. [Larman 2004]
In 1994, DOD replaced STD-2167 with a standard that promoted an incremental and iterative approach. Unfortunately, other governmental departments and several standards bodies had by that time based their methods and operations on 2167 so that the waterfall strategy was the software industry’s de facto standard for systems engineering, still in force today. Knowing its origin, however, offers an opportunity to advocate an alternative. One can argue that to persist with a noniterative, document-driven method is to cling to a fundamental error in software engineering, acknowledged by the author of the very approach most the world is following. In fact, switching to incremental and iterative delivery would be simply returning to the methodological direction that Royce established over 40 years ago.
Although the history just described clarifies how waterfall methods got established, explaining why we stick to it after decades of project failures is a bit harder. If the plan-driven, big design up-front strategy remains common, despite its high documented failure rate, it must have a strong psychological appeal, such as
• It parallels the construction industry where buildings are completely blueprinted and costs are estimated in detail ahead of time.
• Those whole project estimates seem to mitigate risk by “thinking of everything” before project sponsors allow coding to begin.
• Fully detailed plans make progress easy to control because project managers can make statements such as “the design work in now done, and we have spent only 45% of the budget—about what we expected.”
• The detailed work breakdown structure contained in a plan provides the appearance of a highly controlled process, reassuring stakeholders that the calamities of previous projects cannot occur again.
Perhaps it is important to add one final consideration about why IT departments stick with plan-driven approaches: professional risk. Project managers who take on multimillion dollar projects know they cannot guarantee the engagement will succeed, but they can follow the company’s waterfall method in every aspect. If the project later disappoints its stakeholders, the project manager can deflect blame and its consequences by claiming “We followed the method to the letter. If this project failed, then it must be the method’s fault, not ours.”
Although having a document-heavy, plan-driven method to hide behind might provide some job security, it imposes tremendous risk and cost upon the customer and considerable stress upon the developers who work in the micromanaged environment it engenders. Considering all this risk and the misery of failure, both IT and its business partners can reasonably ask: “Isn’t there a better way?” Luckily, with agile methods, the answer is now “yes.”
Agile’s iterative and incremental delivery alternative
During the 1990s, software programmers were wildly excited about the potential for object-oriented languages to speed up application coding. They became frustrated at first, however, because overall delivery times of their projects remained too lengthy. Eventually, many of them realized that the greatest loss of velocity involved the large specifications they were authoring and the time spent managing work plans based on them. They began to experiment and succeed with blending small amounts of requirements, design, coding, and user review on a small piece of the system at a time. Such an approach kept their projects focused on business value and accelerated their overall development by eliminating the time wasted not only on formally prepared documents, but also on the misconceptions that naturally accumulate during single-pass requirements and design efforts.
In 2001, many of these methodological innovators gathered in Park City, Utah to identify the commonalities among their different new project management styles, which had become known as “agile” methods. The result was the Agile Manifesto, which features four philosophical tenets.
We are uncovering better ways of developing software by doing it and helping others do it. Through this work we have come to value:
• Individuals and interactions over processes and tools
• Working software over comprehensive documentation
That is, while there is value in the items on the right, we value the items on the left more. (See www.agilemanifesto.org)
With this manifesto, the agile community verbalized their perception that creating shippable code was the true generator of value for their customers. The time-consuming requirement specifications, detailed design documents, and elaborate project plans were only a means to that end and should be kept as light as possible in order to put the maximum resources into solving business problems with coding. The manifesto’s authors encapsulated this notion by urging software teams to “maximize the work not done.”
The signatories of the Agile Manifesto elaborated on the four tenets by providing 12 principles. These principles are listed in the sidebar. Several of these principles clearly indicate an approach where the development team should iteratively build working software, addressing only a narrow swath of breadth and depth from the application’s full scope each time.
The 12 Principles of the Agile Manifesto
1. Our highest priority is to satisfy the customer through early and continuous delivery of valuable software.
2. Welcome changing requirements, even late in development. Agile processes harness change for the customer’s competitive advantage.
3. Deliver working software frequently, from a couple of weeks to a couple of months, with a preference to the shorter timescale.
4. Business people and developers must work together daily throughout the project.
5. Build projects around motivated individuals. Give them the environment and support they need, and trust them to get the job done.
6. The most efficient and effective method of conveying information to and within a development team is face-to-face conversation.
7. Working software is the primary measure of progress.
8. Agile processes promote sustainable development. The sponsors, developers, and users should be able to maintain a constant pace indefinitely.
9. Continuous attention to technical excellence and good design enhances agility.
10. Simplicity—the art of maximizing the amount of work not done—is essential.
11. The best architectures, requirements, and designs emerge from self-organizing teams.
12. At regular intervals, the team reflects on how to become more effective and then tunes and adjusts its behavior accordingly.
Agile as an answer to waterfall’s problems
With the outlines of both waterfall and iterative approaches now in focus, we can identify the primary areas where Scrum answers the disadvantages of waterfall while lowering risk and accelerating deliveries. Coming chapters will cite this collection as a means of ensuring that the adaptations this book makes to Scrum have left the practitioner with a method that is still “agile.”
Increments of small scope
Scrum’s time box allows only a small amount of scope to be tackled at once. Teams validate results of each iteration and apply lessons learned to the next iteration. Waterfall, however, validates work only as the project nears conclusion, and lessons learned can only be applied to the next project. When a waterfall team fails, it fails on an entire project, not just one small piece of the application.
Business centric
Scrum’s embedded business partner steers the team and provides much of the validation of work. The business partner sees a steady stream of business-intelligible enhancements to the application, thereby believing he is constantly receiving value from the development team. The business is also validating work as it is completed, guiding the team away from mistakes as they occur and keeping risks minimized. Catching errors early and often keeps the team from losing too much time to a misconception, thus accelerating the overall delivery. With waterfall, the team disappears from business view once it gathers requirements, returning only many months later when the application is placed into user acceptance testing. The business feels locked out of the software creation and perceives a high level of risk.
Colocation
Teams gather in a shared workspace to build each iteration. Colocation allows them to share specifications verbally, eye to eye, thus allowing them to dispense with most of the written to-be specifications that plan-driven methods require. In contrast, because a waterfall project separates the development roles by time and often space, specifications have to be prepared carefully ahead of time and reviewed thoroughly, consuming tremendous amounts of time. Colocation can be relaxed to “close collaboration” for projects involving remote teammates, as discussed in a later chapter.
Self-organized teams
The engineers and programmers on a team are free to organize their work as they see fit. Through sprint retrospectives held at the end of each iteration, they refine and formalize among themselves the working patterns that allow the greatest speed and quality. Waterfall relies on a project manager to direct work, locking out process innovations that do not support the manager’s need to control activity. With this constraint, teams do not work as efficiently and delivery speeds suffer.
Just in time
Developers perform detailed requirement clarification, analysis, and design when they start on a module. By locating these predecessors as close as possible to the act of coding, quality and development speed are maximized because the business contexts, constraints, and tradeoffs undergirding each design are still fresh in the developer’s mind. Waterfall, however, builds up large inventories of requirements, analyses, and designs that grow stale, costing teammates time to review the documents and allowing them to commit errors when they do not read the specification perfectly.
80-20 Specifications
Scrum teams do research requirements ahead of time, and they draft the overarching design and data architecture of their applications before coding begins. However, they pursue this work only until the solution is clarified just well enough for coding to begin. They understand that as long as the key integration points of the system are clear, the details bounded within the scope of each module can wait to be addressed until that module is actually developed. Therefore, agile teams develop guidelines such as “just barely good enough” [Ambler 2005] or “just enough architecture” [Fairbanks 2010] to indicate how much effort to invest before coding.
It is convenient to call the results of this satisficing approach to investigation and design as “80-20 specifications.” Using such specifications, programmers begin coding once they are clear on the most important 80% of engineering details of a module, as colocation and small-scope validation will fill in the remaining details as needed. This 80% clarity needs to be documented only enough to retain clarity until the code is built, at which time the developers will draft as-built documentation that meets the standards of their department. Lightly sketching the most important 80% of a module typically requires only 20% of the time that waterfall would invest in building a polished specification, therefore the 80-20 approach accelerates agile teams.
Fail fast and fix quickly
Contrary to waterfall methods’ goal of eliminating project errors through comprehensive requirements and design, agile does not consider failure during software development as bad—as long as such failures are small in scope and occur early enough in the project to be corrected. This attitude has become embodied in a belief among agile practitioners that a strategy of “fail fast and fix quickly” minimizes greatly the risk faced by each project.
Few software professionals have ever witnessed a perfect project. Development teams are frequently surprised by unknown complexities and their own mistakes throughout the entire life cycle of a software application. If developers are going to encounter challenges in every aspect of a project, the agile community argues that teams are better structuring their off work so that these issues appear as early in a project as possible. With each new feature or system aspect they add to an application, agile teams want to detect failure before too much time has passed so that any rework required will not be too much for their streamlined methods to repair quickly.
The incremental nature of methods such as Scrum allows agile teams to uncover flaws in their process and deliverables early on while placing only a small portion of the application at risk. With the incremental approach, a small piece of the solution leads the team through the entire life cycle from requirements to promotion into production. For DWBI, this small slice of the solution will land in each successive layer of the data architecture from staging to dashboard. Misunderstandings and poor assumptions concerning any stage of engineering or architectural stratum will impede completion of the next incremental release in a painfully clear way. The team may well fail to deliver anything of value to the business for an iteration or two. With such pain revealing the major project risks during early iterations, the team can tune up their process. For the most part, because early failures reveal the biggest misunderstandings and oversights, the benefit of fail fast and fix quickly provides large cost savings over the longest possible time. This long payback of early improvements leads some agile methods, such as Unified Processes, to deliberately steer teams into building out the riskiest portions of a project first. [Kroll & MacIsaac 2006] A project employing Scrum can adapt this strategy as well.
By iterating the construction increments, agile teams can steadily reveal the next most serious set of project unknowns or weaknesses remaining in their development process. As developers repeatedly discover and resolve the layers of challenges in their projects, they steadily reduce the remaining risk faced by the customer. By the time they approach the final deliverable, no impediments large enough to threaten the success of the project should remain. Because the fail fast and fix quickly strategy has led the team to uncover big errors in design or construction in the front of the project, the rework to correct the issues will have been kept as small as possible. The potential impact to the business will have been minimized. All told, the team’s early failures on small increments of features will guarantee the long-term success for the entire project.
Integrated quality assurance
Agile builds quality into the full span of development activities instead of leaving it to a late phase in the project. Within each iteration, coders write the tests that modules must pass before programming starts. Developers also check each other’s work, and the business validates each delivery for fit to purpose. Whereas waterfall identifies defects long after the causal requirements and design efforts have been concluded, agile catches errors early, often while the team still has time to correct both of them. Along with the errors, agile quality practices also provide early identification and resolutions of the erroneous thinking and work patterns that engendered the defects. Each iteration improves the team’s quality efforts and progressively eliminates misconceptions, thus Scrum drives defects toward zero over the length of the project.
Agile methods provide better results
Agile methods allow IT to address the discontent among business partners sketched at the opening of this chapter. Each aspect listed previously saved time and effort for the developers, letting them deliver value to the customer sooner. Saved effort also lowers programming cost. Fast iterations coupled with integrated quality assurance allowed errors to be caught and corrected so that these deliveries gain much in quality. With the combined result, IT is servicing its business partners with a method that is faster, better, and cheaper—the three primary components required for good customer rapport.
Business partners also prefer the overall arch of agile projects compared to waterfall efforts. Whereas traditionally managed projects start off being reported as “green” (on schedule) for the first three-quarters or so of a project, their status reports quickly turn “yellow” (challenged) and then “red” (delayed or over budget) as the deadline looms. Agile projects, in contrast, start off red as the teams dive into the tall stack of unknowns of a project and labor to organize themselves within that problem space. The learning that naturally occurs as the teams cycle through their iterations allows them to quickly surmount the challenges, and the project soon turns yellow, then green, and stays green thereon. Customers can quickly forget the chaos at the beginning of an agile project once new features to their applications begin to appear regularly.
Agile for general application development has demonstrated a good track record. A recent survey of over 600 developers whose teams had recently “gone agile” reported that the new method improved productivity and quality for 82 and 77% of the teams. More importantly, 78% of the respondents answered that agile methods improved customer satisfaction with their services. [Ambler 2008]
Agile for data warehousing
Agile methods may well address the fundamental flaws of the waterfall approach and generate some impressive numbers on adoption surveys, but those facts do not automatically make the incremental and iterative approach right for data warehousing and business intelligence projects. DWBI projects are indeed among the largest, most complex applications that many corporations possess. In practice, agile “straight out of the box” cannot manage their breadth and depth. The challenge of breadth arises from many warehouses’ long data processing chains with components that vary widely in the type of modules being built. The challenge of depth occurs when one or more of these modules become a Pandora’s box of conflicting data definitions, complex business rules, and high data volumes. Teams will need Scrum’s adaptive nature to fashion a method for their project that can surmount these twin challenges.
Data warehousing entails a “breadth of complexity”
The breadth of a warehousing project stretches between the twin poles concerning “dashboarding” and “data integration.” These antipodes are so different in terms of the tools employed and the type of work performed that for larger projects they are treated as separate subapplications and are often pursued by distinct teams with completely different staffing. “Dashboarding” is a shorthand label for the front-end components of a warehouse application that end users employ to review and explore the organization’s data in an unrestricted, self-service manner. The dashboarding tools available today are quite mature and “nimble,” making their application programming typically very straightforward, if not easier than building the transaction-capture systems that agile methods were originally invented for.
Before business intelligence data can be displayed on a dashboard, however, it must be prepared by a data integration system. Data must be extracted from its source, transformed to unlock the secrets it contains, and loaded into a target database that can get increasingly temperamental as the volume of data inserted into it goes up. To date, this extract, transform, and load (ETL) work is still a much larger problem domain than dashboarding. Even with the best of data integration tools, ETL can require far more effort per finished module than dashboarding. For most dashboarding work, programmers can operate within a prepared framework of data structures and semantics and need only build a single application to achieve their desired result. Data integration work, however, requires four or more modules to achieve anything usable. Typically it must traverse several distinct architectural layers, each dedicated to a particular task, including
• extracting necessary data from source systems
• cleansing it of errors and standardizing its formatting
• integrating the cleansed records with data from other source systems
• transforming integrated records into dimensional structures for easy data exploration
Consequently, to place a single new element on an existing dashboard can be as simple as creating a little space for it on a particular window and double clicking from a pick list to drop the desired attribute on the display. In contrast, the data integration work required to make that attribute appear in the pick list can require a team to build, test, and promote four or more separate subapplications.
With such diversity in tools and objects across the breadth of a data warehousing project, dashboarding and data integration naturally require different flavors of agile collaboration. The more straightforward challenge of dashboarding yields nicely to the generic Scrum methods detailed in the next chapter. The more nimble tool set generally allows developers to build dashboards from a loosely defined list of user stories and to place several new enhancements into production every iteration. The embedded business partner can demand wildly different objectives for each iteration, and the team will be able to keep up with him.
The tougher data integration portions of a warehouse project require teams to significantly augment those agile techniques. Even the basics of additional agile techniques data integration teams will require most of this book to present. Not only does data integration require processing modules to move data across the layers of the target database, the data volumes involved may be so large that it takes days to load the warehouse for its next user demo. Because each data element requires considerable time to be presentable to end users, data integration stories do not immediately lend themselves to small, repeated programming efforts and frequent test drives by the customer. To meet the challenges of data integration, Scrum will need the adaptations detailed later in this book, which include
• Creating another layer of functional requests underneath that of user stories
• Adding three additional team roles to facilitate incremental design, including a project architect and a data architect
• Organizing the team into a pipeline of delivery activities
• Conducting two lead-off iterations before development sprints begin
• Splitting user demos into two stages
• Maintaining many small managed test data sets to enable quick data loads before changes arrive at user acceptance testing
Teams will need to incorporate progressively more of these adaptations in their method as the extent of data integration required by their project increases. Projects that are mostly dashboarding will involve only one or two architectural layers and little data reloading. They can employ the generic agile method with few data warehousing adaptations. Projects that must span elaborate data models and complex transformation rules will require most, if not all, of the adaptations listed earlier. Figure 1.3 portrays this relationship between the amount of data integration inherent in a project and the degree to which agile data warehousing techniques must be employed.
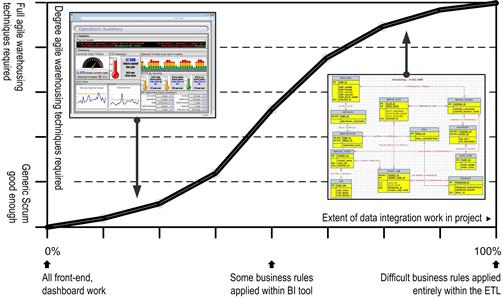
Figure 1.3 Complex data integration requires increasing modifications to generic agile methods.
Adapted scrum handles the breadth of data warehousing well
The adaptations listed earlier allow agile warehousing teams to dynamically adjust their implementation of Scrum as the changing mix of dashboarding and data integration will require. Empirical evidence shows that agile data warehousing works. The author has either worked with or interviewed companies with household names in the software, insurance, retail, transport, health care, and manufacturing industries that have implemented their own versions of Scrum for data management projects with great success. As of the time of this printing, the author is collaborating with The Data Warehousing Institute to conduct a survey of the DWBI profession to document the style and success rates of agile warehousing among the practitioners in the field. Results will be accessible soon via a link within the companion Web site for this book.
The author and his company have also had the rare opportunity to benchmark agile data warehousing side by side with another comparable effort that was pursued using a waterfall method. The projects were sponsored by one of the top U.S. telecommunications firms in 2008. They had approximately the same goal of placing sales and revenue of third-party equipment manufacturers into a data mart. The agile team focused on resold cell phone handsets and services, whereas the waterfall project focused on resold satellite video products and programming. Both teams worked with the same business partner and project architect so both started with identical levels of definition.
The agile project had the larger scope, as can be seen in Table 1.1, which compares labor hours as tracked by the official reporting systems of the company’s project management office. Because the waterfall project had more difficult extracts to contend with, the numbers in Table 1.1 exclude the data staging effort. Also, because the dashboard applications were funded separately, the work compared in Table 1.1 involves only the design, development, and testing of modules to transform data from staging into dimensional targets. Both development teams were staffed with a project architect, data architect, systems analyst, and four developers.
Table 1.1 Relative Performance of Waterfall and Agile Projects When Run Side By Side

Judging from the numbers shown in Table 1.1, the agile’s approach provides a clear advantage to data integration teams. Agile reduced project start-up time by 75%, increased programmer productivity by nearly a factor of three, and drove the project’s defect rate to zero. If one is looking for a faster, cheaper, and better way to build data warehouses, the agile data warehousing techniques employed in this benchmark case clearly delivered.
We must note that the agile project cited earlier was led by a very experienced solutions architect who had years of experience as a DWBI scrum master. The acceleration that a new team with a freshly trained scrum master will achieve cannot be predicted from data given previously. Estimating subjectively, however, the author believes that by following the tenets set forth in this book, a new team should be able achieve a 20 to 40% improvement in development speed within its first year of operation, which is in line with forecasts made by others who write on Scrum for nonwarehousing projects. [Benefield 2008; Maurer & Martel 2002] Several considerations for securing the highest productivity gains for beginner projects can be found in the final chapter of this book where it discusses starting a new team.
Managing data warehousing’s “depth of complexity”
Dashboarding and data integration define only the breadth of difficulties that DWBI projects will encounter. There is another dimension of depth that an agile approach must sufficiently address if it is to conquer anything more involved than a data mart. This dimension appears when warehousing teams discover that some of their integration modules and even a few of their dashboard components contain abysmally deep problems involving vague requirements, inconsistent data definitions (“semantics”), and intricate business rules. If an agile team were to rush into coding these modules with only a casual understanding of their depths, it could easily produce a warehouse with inaccurate information or data that cannot be utilized for any query outside of the narrow purpose it was derived for. Such deficiencies can cause companies to abandon their DWBI applications, either immediately or after a few years, resulting in a significant waste of funds.
The danger posed by a warehousing module containing a thorny problem can harm a team in two ways. They could stumble into it unprepared and become ineffective as they try to code their way out of the morass or they could be blind to it completely and allow it to sneak into their finished product, only to see end users seriously harmed by the oversight later. This twin danger usually underlies traditional warehousing architects’ insistence that warehousing teams should perform a disciplined and thorough analysis of the enterprise before starting design of the warehouse’s target data structures. There are many frameworks that teams can use for such a thorough analysis, such as the Zachman and TOGAF. Zachman employs the “Six W’s” (who, what, when, where, why, and how) to progressively elaborate an organization’s drivers, processes, logical models, physical models, and business rules. TOGAF reveals enterprise-level requirements and concepts by matrixing the business, data, applications, and technology against a company’s products, organization, and processes, plus its informational and locational elements. [Reynolds 2010]
The Data Warehousing Institute provides a similar disciplined approach to data architecture for DWBI in particular that drives development teams to completing a robust data model for their projects. This framework requires developers to stretch separate views for business context, concepts, business systems, and IT applications across an organization’s transactional, decision, and analytical functions. Executed fully, this framework resolves conflicts in business definitions, yields a fact-qualifier matrix documenting the required analytics, and provides dependable logical models for both integration and dimensional data layers. [TDWI 2011]
Such disciplined analysis before programming has both advantages and disadvantages that an agile practitioner has to weigh carefully. These frameworks generate a lot of information and consequently require significant time and documentation to perform correctly. Optimists would cite that if a team is going to avoid absolutely all mistakes regarding requirements and design, such a large collection of details will be a necessary input. Pessimists would wonder whether a team can dependably sift through such a gob of information to find the details it needs when it needs them. Agilists would question whether the time required to assemble these details will undermine the purpose of the very program they were intended to assist.
Figure 1.4 shows how an agile practitioner could weigh the tradeoff between design risk and time consumed. The solid curve depicts the risk of making an error in the warehouse’s requirements or data architecture. With enough effort, a team can drive this risk to zero. The dashed line in Figure 1.4 portrays another, equally important risk—the risk of delivering too late for the company to benefit from the market opportunity that caused the project sponsors to fund the development effort. Whether the application was intended to help capture new revenues, reduce expenses, or assist in regulatory compliance, the opportunity cost of delaying its deployment can be driven progressively higher by taking too long to put its capabilities online. Just like the risk of error, the value of a warehouse solution can be driven to zero with time. This diagram reveals the rational mix of speed and care a warehouse project should seek. Racing solutions into production places a team on the left side of the diagram where errors will far exceed the urgency of the need. However, investing in a complete enterprise architecture specification places the team on the right side where no need for the warehouse remains once it is finally available. The optimum level of precoding analysis and design the project should take can be found were the total of the two risk curves combine into a minimum overall risk, as indicated by the sweet spot highlighted in Figure 1.4.
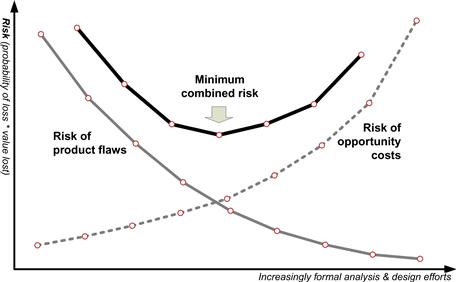
Figure 1.4 An agile perspective on the competing risks for DWBI projects.
Finding the optimum mix between haste and defensive analysis is an art, but there are guidelines for agile practitioners to draw upon. An approach with a good mix for general application development can be found with Scott Ambler’s “agile modeling,” which presents some practices for economically engineering applications with techniques such as “prioritized requirements,” “look-ahead modeling,” test-driven design, “document late,” and “just barely good enough.” Data warehousing teams can derive for themselves a DWBI-specific method for mitigating the risk posed by vague requirements, conflicting definitions, and complex business rules by applying these agile modeling principles and techniques to the TDWI framework discussed earlier for drafting domain and logical models for data warehouses.
Combining agile modeling techniques with a DWBI-specific architectural framework provides a means of deriving a single, static target model for a team to build out, but there will be some projects requiring a more dynamic approach. Two factors in particular will push a team into work with a progressive set of models, loading and reloading the data schemas that result. The most obvious is that because the business is changing rapidly, no single design will be appropriate for more than a few months. The second is urgency where a business opportunity or threat must be addressed by the warehouse immediately, making the cost of design errors and eventual rework acceptable to the business sponsors. Updating the structure of an existing warehouse table can be painful, however, for a team working with conventional tools. Data already loaded in each table must be converted to match its new purpose. Conversion programs are labor-intensive because they must be analyzed, designed, coded, tested, and promoted like any other ETL module. Unlike ETL modules, however, they are employed only once and thus represent an expensive, nonreusable object for the company. An agile data warehousing program will not be able to maintain its high speed to market if conversion programming is its only strategy for keeping up with quickly changing requirements.
A truly agile method for data warehousing must, then, add a few new facets to its collection of techniques in order to avoid relying on conversion programming.
Agile DWBI practitioners will, then, acquire a set of techniques to add to Scrum that allows them to avoid relying on conversion programming for every transform module that contains a frighteningly deep challenge. The agile team either needs to be able to ferret out those nasty surprises and build them into the 80-20 specification before coding begins or needs the capability to quickly evolve a target data schema and its attendant ETL modules to meet the new requirement that just emerged from the shadows. Answering this call requires both techniques and tools, among them the following:
• a top-down approach that can divide up a project concept into independent data submodels, allowing the team to know that any intertable dependencies they discover later will be tightly localized
• tools that accelerate the collaboration needed to achieve an organizational consensus on the enterprise requirements, definitions, and rules the warehouse will instantiate
• advanced “hypernormalized” data modeling techniques that allow data schemas to be updated as requirements, definitions, and rules change without incurring massive rework and reloading of existing tables
• model-driven warehouse code generators that automate the predictable steps involved with updating, reloading, and reprojecting these hypernormalized data models across a warehouse’s integration, presentation, and semantic layers
• data virtualization products that allow DWBI departments to quickly publish new combinations of data assets that meet pressing or transitory business intelligence requirements without having to code, test, and promote data transformation objects
Combined together, these elements will free an enterprise data warehousing program from having to concentrate on programming. The project developers will be able to focus instead on the shape and quality of the information delivered to end users. Such capability is already taking shape within the DWBI profession, and its practitioners and tool makers describe their organizing principle as “iterate upon the data rather than upon the code.”
The overall strategy for resolving the challenge of unpredictably deep complexity within a DWBI project turns out to be a spectrum of choices for teams within an agile data warehousing program. As suggested by Table 1.2, agile DWBI teams do not need to commit to a one-size-fits-all approach, but instead should select the option from this spectrum that best meets their current needs.
Table 1.2 Spectrum of Strategies for Managing Complex Data Architectures
| Project Context | Management Practice | Book and Treatment |
| Data marts or single-purpose subject areas: Little integration of data assets outside the application being built | Data modeler starts with key data integration points modeled, provides schema details in increments, as needed by the team | Book 1: Data architecture envisioned as another development task for delivering DWBI modules. |
| Multipurpose subject area or master data elements: Complex requirements, data definitions, or business rules, integration with components owned by other DWBI projects | Data modeler becomes team’s interface with enterprise data architecture (EDA), provides team with schemas supporting EDA’s data asset road map; applies agile modeling techniques to domain, logical, and physical data model to create target schema increments for team | Book 1: Complexity still managed within the role of the project’s data architect who may have to arrange for additional resources or extra lead time to stay one iteration ahead of the programmers. Agile modeling for data warehouses addressed in Book 2 |
| Dynamic industry or compressed delivery time frames: Requirements, definitions, and rules unstable, target data structures must evolve | Embedded data architect pursues data governance and data modeling before providing target schemas to development team(s). Model-driven DWBI application generators make evolutionary target schemas manageable. Teams iterate upon data delivered rather than the ETL code they must build. | Book 2: Fundamentals provided by enterprise data architectural frameworks. Accelerating this process so that it is agile requires hypernormalized modeling paradigms and/or auxiliary tools typically affordable only as part of an enterprise warehousing program |
Guide to this book and other materials
The strategies and techniques outlined earlier create a long list of topics, so long in fact that it will require two books to fully present all the necessary concepts. This book is the first of two. It focuses on getting agile methods tuned for data warehousing within the scope of the project room. It focuses on answering the challenge of breadth cited earlier, that is, the fact that DWBI projects can vary from complete dashboarding to solely data integration work. The second book concentrates on scaling the method derived in Book 1 up to the level of enterprise data warehousing programs. It explores solutions to the challenges of depth, that is, warehouse components that entail profound problems involving requirements, definitions, and business rules.
Figure 1.5 provides a view to how the material will be split between these two books and the order topics will be presented in. This book is organized into three parts. Part 1 presents a generic Scrum method, one that a DWBI team could employ immediately for a project consisting of primarily front-end, dashboarding work. Part 2 focuses on solving the challenges that new agile warehousing teams all seem to struggle with, namely decomposing projects into user stories ready for development and then packaging them into an acceptable series of incremental releases for end users. Part 3 describes several adaptations to the agile collaboration process that teams working on a DWBI project with extensive data integration projects will find indispensable.
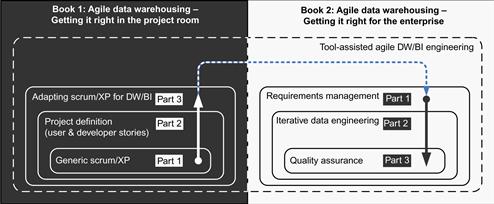
Figure 1.5 High-level structure of this book and its companion volume.
Book 2 begins by discussing frameworks for managing requirements, offering techniques appropriate for a full range of program levels from enterprise data warehousing down to simple data mart projects. It will build upon those requirements management techniques with practices for iterative data engineering, tackling many of the issues introduced in the previous section. It wraps up by describing the components of a robust and agile quality assurance plan for projects both large and small. Throughout all three of these topics, Book 2 discusses the nature of the tools available to streamline and accelerate the work in each discipline.
The astute reader may be wondering why Book 1 starts at the bottom—the recommended process needed within a project team—whereas Book 2 proceeds top-down from requirements, to data design, to testing. A completely top-down approach starting with Book 2 enterprise disciplines would be perhaps more logical, but there are two reasons to focus first upon the reshaping the collaboration within the project room: natural sequencing and progressive perspectives.
First, that sequencing matches the order in which most warehousing teams tend to try agile techniques. It also provides the agile perspective needed to appreciate the remainder of the material. Few companies get started with agile methods by implementing one at the department or program level. The new practices are too unfamiliar for most DWBI departments and the risk of chaos seems too great. Instead a department will start with a pilot project, such as building a single data mart in an agile fashion. They may even start with just the front-end dashboard components and then ease themselves into progressively larger and harder initiatives from the realm of data integration. Only after they feel that they have mastered modestly scoped data integration projects will these companies consider scaling up the agile initiative for the entire department and enterprise warehousing initiatives. Accordingly, this book is structured to start with generic Scrum because those are the practices that DWBI departments will need for their lead-off, single data mart, pilot programs. It then layers on techniques that will equip these departments to tackle the more difficult challenges of data integration efforts. Finally, Book 2 provides techniques for meeting the integrate analytics needed by multiple, loosely related business units requiring enterprise reusable components.
Second, these books start with generic Scrum for dashboarding because it provides the necessary perspective on the fundamentals of agile. The many adaptations suggested after that will draw upon and steadily extend that perspective, downplaying or even discarding many practices cherished by traditional methods and frameworks. These philosophies are easiest to understand when applied to the smallest scope, the work room of a single project. Once the acceleration that these attitudes and behaviors provide for the single project, it becomes much easier to see their advantage at the program and department levels. By the time the DWBI department considers adopting agile as its main method, the cost savings and improved quality of agile projects will have been well demonstrated. With those notable advantages apparent, much of the discussion of the remaining implementation steps usually inverts. Instead of focusing on how to adapt agile development methods to fit into its existing EDW practices, the planners discuss how to adapt those EDW practices to protect and amplify the agile development process that is succeeding every day within the department’s project rooms.
Simplified treatment of data architecture for book 1
Given the breadth and depth complexities identified previously, the two books of this set keep their presentations clear by discussing only one of those complexities at a time. Book 1 concentrates on how Scrum must be adapted as a team moves from relatively straightforward dashboarding applications into the challenges of data integration. Although deep questions may arise on those projects regarding cross-project requirements and data architectures, this book glosses over those considerations in deference to Book 2, for which they will be a primary focus. Readers coming from a data architectural background will notice that Book 1, in order to maintain this simplification for clarity, assumes certain solutions at work in the role of the data architect assigned to an agile warehousing project. The solutions packaged into the data architect’s station for each level of architectural challenge were included in Table 1.2.
For data marts or single-purpose subject areas, Book 1 assumes that the data architect will start the project with only the most important aspects of the target data model designed—such as the key data integration paths between major topics. He will then progressively spell out the details of the target schema in increments as needed by his team. Later chapters in the book describe how the method creates the time the data architect will need to stay ahead of his team’s coders.
For projects that advance to data integration objectives involving shared warehouse subject areas or master data elements, Book 1 envisions the data architect parleying with an enterprise data architecture group as needed. He will then transport into the project room the list of shared components the architecture group plans for the enterprise warehousing program and the roadmap scheduling their deployment. The data architect will then provide his teammates with increments of the target schema as their development iterations progress, and these increments will be compatible with the larger data architectural vision of the DWBI department.
Finally, teams developing enterprise warehousing components in a dynamic industry or under a compressed delivery time frame will have to incrementally design and build out enterprise-compatible warehouse data assets for themselves. There will be no other data modeling process for these projects to rely on. Book 1 defers all discussion of data architectural solutions for this scenario to Book 2, where the solution will involve embedding a data architect on the agile warehouse project and asking him to attend to data governance and disciplined data engineering. Book 2 discusses the advance modeling techniques and tools available that will allow the data architect to incrementally draft the necessary domain and logical models needed to keep his team’s deliverables from becoming stove-piped assets that cannot be integrated with or extended to other warehouses in the enterprise.
Companion web site
The topic of agile data warehousing is truly larger than can be presented in even two volumes. Given that these books are published in the age of the Internet, however, the author can maintain a companion site for them at www.agiledatawarehousingbooks.com. This site will contain supplemental assets for the reader, such as
• a continuing discussion of the concepts presented here, often in greater depth and with comments by practitioners who can provide the benefits of their experience
• further best practices, such as ways to combine generic agile practices with data warehousing frameworks and how to address the challenges of formal compliance programs
• links to other books and tools for reengineering data warehouses that will provide essential techniques to the agile teams in the field
• links to agile DWBI professionals, such as solutions architects, data architects, analysts, and testers, who can support the pilot projects of a new agile warehousing program
• surveys on agile warehousing project experiences, their success rates, and the tools and techniques employed throughout our industry
• corrections and elaborations on the contents of this and the author’s other agile data warehousing books
These materials should smooth out the inevitable bumps in the road to a stellar agile warehousing implementation and will provide an important touchstone for those hoping to evolve the practice with standards to make iterative DWBI more portable and easier to deploy.
Where to be cautious with agile data warehousing
Although agile warehousing has proven itself very effective and adaptable, it must be introduced into an organization with some care. Keeping in mind a few guidelines will help.
First, everyone needs to be prepared for some chaos during the early days of a project. In many ways, waterfall methods with their long lists of detailed tasks are far easier for teams to follow—until a project begins to implode from unresolved issues a month or two before the go-live date. Agile, in contrast, is simple, but that does not make it easy to execute. The fact that it regularly drives small slices of functionality all the way from requirements to acceptance testing means fatal misconceptions lying hidden within the project concept will bubble to the surface continually where they will stall progress until addressed effectively.
Those planners leading the newly agile program need to warn stakeholders that this steady stream of issues starts with day 1 and that they are not only part of the agile approach, but one of its best aspects. By forcing teams to address crucial issues early and often, agile ensures that project risks are being truly discovered and resolved, not pushed off until acceptance testing when too little time and resources will be available to resolve them.
Second, each agile team will require some preparatory time before they start coding. Everyone may benefit from the defects and misconceptions revealed with every sprint, but coding errors can overwhelm a team if they become too numerous. As explained earlier, Scrum is a collaboration model for fast application programming. It presupposes that someone provides the application’s fundamental vision and architecture before programming begins. One of the most common mistakes managers make with agile warehousing is to believe they can simply throw coders at business problems. The agile collaboration model does not suddenly provide magic insight for the developers or the team’s business partner regarding requirements and design. Even agile programmers need a moderate amount of guidance on an application’s intent and desired component design. A discovery process, which is introduced as “Iteration −1 and 0” later in this book, is still needed.
Finally, agile warehousing teams need the right leadership. Scrum calls for a process facilitator called a “scrum master.” Managers new to agile warehousing sometime think that scrum master and DWBI are unrelated and that any good scrum master can lead a team. Unfortunately, scrum masters who have never seen a data warehousing project before can drastically underestimate the complexity inherent in building applications with multilayered architectures and large data volumes. These individuals can make some very basic mistakes when leading a warehousing team, including
• organizing the project around user stories that are far too large in scope
• starting development sprints before enough discovery work has been done
• insisting the developers move data from source to final target in a single iteration
• believing developers can demonstrate each iteration’s results using full-volume data loads
• overlooking that the roles a warehouse team can have overlap very little, to the point where many problems can be “swarmed” only by one or two individuals at a time
To prevent this type of faux pas, a company needs to engage scrum masters for DWBI projects who have built warehouses before and understand why the choices can have disappointing results. Better yet, a company should keep the scrum master as a facilitator and provide team leadership from one of the key technical roles, such as the project architect or data architect. Caution needs to be exercised in the opposite direction as well regarding these technical leaders. Modelers and architects that have not worked in an agile environment will be missing many of the practices documented in this book. Without them, these leads will be unable to avoid interdependencies between modules and rework that will slow their teams down. If the first project for an organization is large or highly visible, it may be worth engaging a warehousing architect and data architect who have worked in an agile environment before to join the team. Agile warehousing requires knowing where a team can go fast and where it must go slow. The facilitator and technical leads will only find consensus on which project area falls in each of these categories if they have one foot in both agile and data warehousing worlds.
Summary
For those DWBI professionals who have always felt there must be a better way to pursue application development as a team, agile methods offer an alternative that has proven faster, better, and cheaper for the organizations that have been bold enough to try them. The majority of agile implementations are based on Scrum, which is iterative and embeds the customer within each development cycle so that the business stays fully engaged in the requirements, design, and validation work. This collaborative development process avoids many of the antipatterns noted with the traditional, plan-driven, or “waterfall” approach. Rather than struggling to comprehend and construct a large project in a single pass, agile guides teams toward delivering in small, steadily validated modules. Iterative delivery drives issues of poor development techniques and miscommunications to the surface early so that the software engineers can fix their development processes and customers do not risk waiting too long, spending too much, and receiving too little.
To succeed with incremental delivery, warehousing projects must overcome two primary challenges: the breadth of technical work separating dashboarding from data integration and the depth of thorny requirements, semantics uncertainty, and business rules that can lie hidden in any data transform included in the project. Agile warehousing addresses the challenge of breadth by adapting the Scrum method with several techniques that are covered in this, the first volume of a two-book set. The challenge of depth is discussed in detail in the second volume.