
Chapter 1. A new design for the Web
This chapter covers
- Asynchronous network interactions and usage patterns
- The key differences between Ajax and classic web applications
- The four fundamental principles of Ajax
- Ajax in the real world
Ideally, a user interface (UI) will be invisible to users, providing them with the options they need when they need them but otherwise staying out of their way, leaving users free to focus on the problem at hand. Unfortunately, this is a very hard thing to get right, and we become accustomed, or resigned, to working with suboptimal UIs on a daily basis—until someone shows us a better way, and we realize how frustrating our current method of doing things can be.
The Internet is currently undergoing such a realization, as the basic web browser technologies used to display document content have been pushed beyond the limits of what they can sanely accomplish.
Ajax (Asynchronous JavaScript + XML) is a relatively recent name, coined by Jesse James Garrett of Adaptive Path. Some parts of Ajax have been previously described as Dynamic HTML and remote scripting. Ajax is a snappier name, evoking images of cleaning powder, Dutch football teams, and Greek heroes suffering the throes of madness.
It’s more than just a name, though. There is plenty of excitement surrounding Ajax, and quite a lot to get excited about, from both a technological and a business perspective. Technologically, Ajax gives expression to a lot of unrealized potential in the web browser technologies. Google and a few other major players are using Ajax to raise the expectations of the general public as to what a web application can do.
The classical “web application” that we have become used to is beginning to creak under the strain that increasingly sophisticated web-based services are placing on it. A variety of technologies are lining up to fill the gap with richer, smarter, or otherwise improved clients. Ajax is able to deliver this better, smarter richness using only technologies that are already installed on the majority of modern computers.
With Ajax, we are taking a bunch of dusty old technologies and stretching them well beyond their original scope. We need to be able to manage the complexity that we have introduced. This book will discuss the how-tos of the individual technologies but will also look at the bigger picture of managing large Ajax projects. We’ll introduce Ajax design patterns throughout the book as well to help us get this job done. Design patterns help us to capture our knowledge and experience with a technology as we acquire it and to communicate it with others. By introducing regularity to a codebase, they can facilitate creating applications that are easy to modify and extend as requirements change. Design patterns are even a joy to work with!
1.1. Why Ajax rich clients?
Building a rich client interface is a bit more complicated than designing a web page. What is the incentive, then, for going this extra mile? What’s the payoff? What is a rich client, anyway?
Two key features characterize a rich client: it’s rich, and it’s a client.
Let me explain a little more. Rich refers here to the interaction model of the client. A rich user interaction model is one that can support a variety of input methods and that responds intuitively and in a timely fashion. We could set a rather unambitious yardstick for this by saying that for user interaction to be rich, it must be as good as the current generation of desktop applications, such as word processors and spreadsheets. Let’s take a look at what that would entail.
1.1.1. Comparing the user experiences
Take a few minutes to play with an application of your choice (other than a web browser), and count the types of user interaction that it offers. Come back here when you’ve finished. I’m going to discuss a spreadsheet as an example shortly, but the points I’ll make are sufficiently generic that anything from a text editor up will do.
Finished? I am. While typing a few simple equations into my spreadsheet, I found that I could interact with it in a number of ways, editing data in situ, navigating the data with keyboard and mouse, and reorganizing data using drag and drop.
As I did these things, the program gave me feedback. The cursor changed shape, buttons lit up as I hovered over them, selected text changed color, highlighted windows and dialogs were represented differently, and so on (figure 1.1). That’s what passes for rich interactivity these days. Arguably there’s still some way to go, but it’s a start.
Figure 1.1. This desktop spreadsheet application illustrates a variety of possibilities for user interaction. The headers for the selected rows and columns are highlighted; buttons offer tooltips on mouseover; toolbars contain a variety of rich widget types; and the cells can be interactively inspected and edited.

So is the spreadsheet application a rich client? I would say that it isn’t.
In a spreadsheet or similar desktop application, the logic and the data model are both executed in a closed environment, in which they can see each other very clearly but shut the rest of the world out (figure 1.2). My definition of a client is a program that communicates to a different, independent process, typically running on a server. Traditionally, the server is bigger, stronger, and better than the client, and it stores monstrously huge amounts of information. The client allows end users to view and modify this information, and if several clients are connected to the same server, it allows them to share that data. Figure 1.3 shows a simple schematic of a client/server architecture.
Figure 1.2. Schematic architectures for a standalone desktop application. The application runs in a process of its own, within which the data model and the program logic can “see” one another. A second running instance of the application on the same computer has no access to the data model of the first, except via the filesystem. Typically, the entire program state is stored in a single file, which is locked while the application is running, preventing any simultaneous exchange of information.
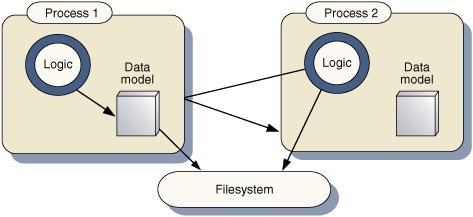
Figure 1.3. Schematic architectures for client/server systems and n-tier architectures. The server offers a shared data model, with which clients can interact. The clients still maintain their own partial data models, for rapid access, but these defer to the server model as the definitive representation of the business domain objects. Several clients can interact with the same server, with locking of resources handled at a fine-grain level of individual objects or database rows. The server may be a single process, as in the traditional client/server model of the early- to mid-1990s, or consist of several middleware tiers, external web services, and so on. In any case, from the client’s perspective, the server has a single entry point and can be considered a black box.

In a modern n-tier architecture, of course, the server will communicate to further back-end servers such as databases, giving rise to middleware layers that act as both client and server. Our Ajax applications typically sit at the end of this chain, acting as client only, so we can treat the entire n-tier system as a single black box labeled “server” for the purposes of our current discussion.
My spreadsheet sits on its own little pile of data, stored locally in memory and on the local filesystem. If it is well architected, the coupling between data and presentation may be admirably loose, but I can’t split it across the network or share it as such. And so, for our present purposes, it isn’t a client.
Web browsers are clients, of course, contacting the web servers from which they request pages. The browser has some rich functionality for the purpose of managing the user’s web browsing, such as back buttons, history lists, and tabs for storing several documents. But if we consider the web pages for a particular site as an application, then these generic browser controls are not related to the application any more than the Windows Start menu or window list are related to my spreadsheet.
Let’s have a look at a modern web application. Simply because everyone has heard of it, we’ll pick on Amazon, the bookseller (figure 1.4). I point my browser to the Amazon site, and, because it remembers who I am from my last visit, it shows me a friendly greeting, a list of recommended books, and information about my purchasing history.
Figure 1.4. Amazon.com home page. The system has remembered who I am from a previous visit, and the navigational links are a mixture of generic boilerplate and personal information.

Clicking on a title from the recommendations list leads me to a separate page (that is, the screen flickers and I lose sight of all the lists that I was viewing a few seconds earlier). This, too, is stuffed full of contextual information: reviews, secondhand prices for the book, links to similar authors, and titles of other books that I’ve recently checked out (figure 1.5).
Figure 1.5. Amazon.com book details page. Again, a dense set of hyperlinks combines generic and personal information. Nonetheless, a significant amount of detail is identical to that shown in figure 1.4, which must, owing to the document-based operation of the web browser, be retransmitted with every page.
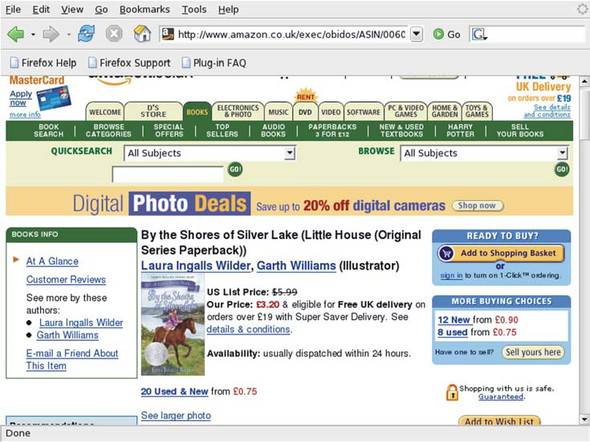
In short, I’m presented with very rich, tightly interwoven information. And yet my only way of interacting with this information is through clicking hyperlinks and filling in text forms. If I fell asleep at the keyboard while browsing the site and awoke the next day, I wouldn’t know that the new Harry Potter book had been released until I refreshed the entire page. I can’t take my lists with me from one page to another, and I can’t resize portions of the document to see several bits of content at once.
This is not to knock Amazon. It’s doing a good job at working within some very tight bounds. But compared to the spreadsheet, the interaction model it relies on is unquestionably limiting.
So why are those limits present in modern web applications? There are sound technical reasons for the current situation, so let’s take a look at them now.
1.1.2. Network latency
The grand vision of the Internet age is that all computers in the world interconnect as one very large computing resource. Remote and local procedure calls become indistinguishable, and issuers are no longer even aware of which physical machine (or machines) they are working on, as they happily compute the folds in their proteins or decode extraterrestrial signals.
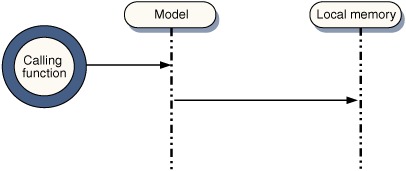
Remote and local procedure calls are not the same thing at all, unfortunately. Communications over a network are expensive (that is, they are slow and unreliable). When a non-networked piece of code is compiled or interpreted, the various methods and functions are coded as instructions stored in the same local memory as the data on which the methods operate (figure 1.6). Thus, passing data to a method and returning a result is pretty straightforward.
Figure 1.6. Sequence diagram of a local procedure call. Very few actors are involved here, as the program logic and the data model are both stored in local memory and can see each other directly.
Under the hood, a lot of computation is going on at both ends of a network connection in order to send and receive data (figure 1.7). It’s this computation that slows things down, more than the physical journey along the wire. The various stages of encoding and decoding cover aspects of the communication ranging from physical signals passing along the wire (or airwaves), translation of these signals as the 1s and 0s of binary data, error checking and re-sending, to the reassembling of the sequence, and ultimately the meaning, of the binary information.
Figure 1.7. Sequence diagram of a remote procedure call. The program logic on one machine attempts to manipulate a data model on another machine.
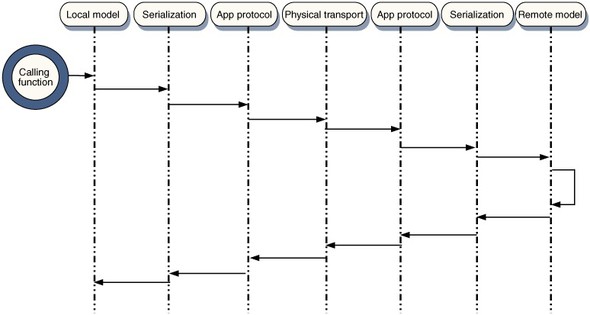
The calling function’s request must be encoded as an object, which is then serialized (that is, converted into a linear set of bytes). The serialized data is then passed to the application protocol (usually HTTP these days) and sent across the physical transport (a copper or fiber-optic cable, or a wireless connection of some sort).
On the remote machine, the application protocol is decoded, and the bytes of data deserialized, to create a copy of the request object. This object can then be applied to the data model and a response object generated. To communicate the response to the calling function, the serialization and transport layers must be navigated once more, eventually resulting in a response object being returned to the calling function.
These interactions are complex but amenable to automation. Modern programming environments such as Java and the Microsoft .NET Framework offer this functionality for free. Nonetheless, internally a lot of activity is going on when a remote procedure call (RPC) is made, and if such calls are made too freely, performance will suffer.
So, making a call over a network will never be as efficient as calling a local method in memory. Furthermore, the unreliability of the network (and hence the need to resend lost packets of information) makes this inefficiency variable and hard to predict. The responsiveness of the memory bus on your local machine is not only better but also very well defined in comparison.
But what does that have to do with usability? Quite a lot, as it turns out.
A successful computer UI does need to mimic our expectations of the real world at the very basic level. One of the most basic ground rules for interaction is that when we push, prod, or poke at something, it responds immediately. Slight delays between prodding something and the response can be disorienting and distracting, moving the user’s attention from the task at hand to the UI itself.
Having to do all that extra work to traverse the network is often enough to slow down a system such that the delay becomes noticeable. In a desktop application, we need to make bad usability design decisions to make the application feel buggy or unresponsive, but in a networked application, we can get all that for free!
Because of the unpredictability of network latency, this perceived bugginess will come and go, and testing the responsiveness of the application can be harder, too. Hence, network latency is a common cause of poor interactivity in real-world applications.
1.1.3. Asynchronous interactions
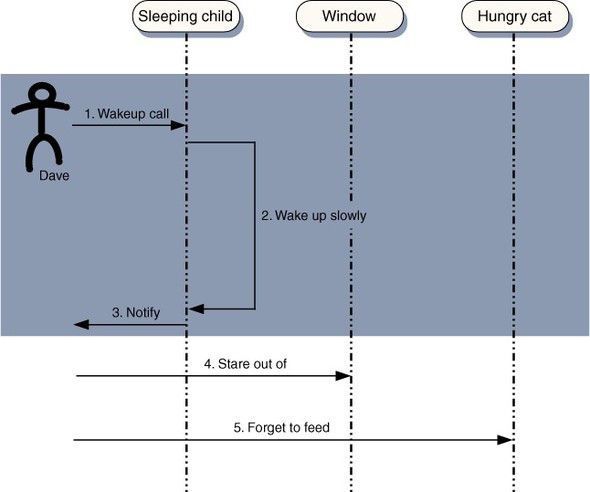
There is only one sane response to the network latency problem available to the UI developer—assume the worst. In practical terms, we must try to make UI responses independent of network activity. Fortunately, a holding response is often sufficient, as long as it is timely. Let’s take a trip to the physical world again. A key part of my morning routine is to wake my children up for school. I could stand over them prodding them until they are out of bed and dressed, but this is a time-consuming approach, leaving a long period of time in which I have very little to do (figure 1.8).
Figure 1.8. Sequence diagram of a synchronous response to user input, during my morning routine. In a sequence diagram, the passage of time is vertical. The height of the shaded area indicates the length of time for which I am blocked from further input.
I need to wake up my children, stare out the window, and ignore the cat. The children will notify me when they are properly awake by asking for breakfast. Like server-side processes, children are slow to wake. If I follow a synchronous interaction model, I will spend a long time waiting. As long as they are able to mutter a basic “Yes, I’m awake,” I can happily move on to something else and check up on them later if need be.
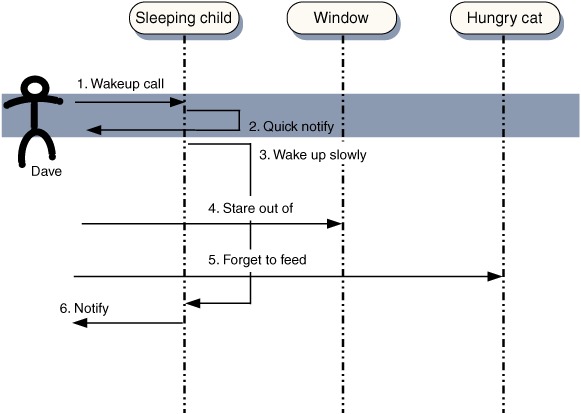
In computer terms, what I’m doing here is spawning an asynchronous process, in a separate thread. Once they’re started, my children will wake up by themselves in their own thread, and I, the parent thread, don’t need to synchronize with them until they notify me (usually with a request to be fed). While they’re waking up, I can’t interact with them as if they were already up and dressed, but I can be confident that it will happen in due course (figure 1.9).
Figure 1.9. Sequence diagram of an asynchronous response to user input. If I follow an asynchronous input model, I can let the children notify me that they are starting to wake up. I can then continue with my other activities while the wakeup happens and remain blocked for a much shorter period of time.
With any UI, it’s a well-established practice to spawn an asynchronous thread to handle any lengthy piece of computation and let it run in the background while the user gets on with other things. The user is necessarily blocked while that thread is launched, but this can be done in an acceptably short span of time. Because of network latency, it is good practice to treat any RPC as potentially lengthy and handle it asynchronously.
This problem, and the solution, are both well established. Network latency was present in the old client/server model, causing poorly designed clients to freeze up inexplicably as they tried to reach an overloaded server. And now, in the Internet age, network latency causes your browser to “chug” frustratingly while moving between web pages. We can’t get rid of latency, but we know how to deal with it—by processing the remote calls asynchronously, right?
Unfortunately for us web app developers, there’s a catch. HTTP is a request-response protocol. That is, the client issues a request for a document, and the server responds, either by delivering the document, saying that it can’t find it, offering an alternative location, or telling the client to use its cached copy, and so on. A request-response protocol is one-way. The client can make contact with the server, but the server cannot initiate a communication with the client. Indeed, the server doesn’t remember the client from one request to the next.
The majority of web developers using modern languages such as Java, PHP, or .NET will be familiar with the concept of user sessions. These are an afterthought, bolted onto application servers to provide the missing server-side state in the HTTP protocol. HTTP does what it was originally designed for very well, and it has been adapted to reach far beyond that with considerable ingenuity. However, the key feature of our asynchronous callback solution is that the client gets notified twice: once when the thread is spawned and again when the thread is completed. Straightforward HTTP and the classic web application model can’t do this for us.
The classic web app model, as used by Amazon, for example, is still built around the notion of pages. A document is displayed to the user, containing lists of links and/or form elements that allow them to drill down to further documents. Complex datasets can be interacted with in this way on a large scale, and as Amazon and others have demonstrated, the experience of doing so can be compelling enough to build a business on.
This model of interaction has become quite deeply ingrained in our way of thinking over the ten years or so of the commercial, everyday Internet. Friendly WYSIWYG web-authoring tools visualize our site as a collection of pages. Server-side web frameworks model the transition between pages as state transition diagrams. The classic web application is firmly wedded to the unavoidable lack of responsiveness when the page refreshes, without an easy recourse to the asynchronous handler solution.
But Amazon has built a successful business on top of its website. Surely the classic web application can’t be that unusable? To understand why the web page works for Amazon but not for everyone, we ought to consider usage patterns.
1.1.4. Sovereign and transient usage patterns
It’s futile to argue whether a bicycle is better than a sports utility vehicle. Each has its own advantages and disadvantages—comfort, speed, fuel consumption, vague psychological notions about what your mode of transport “says” about you as a person. When we look at particular use patterns, such as getting through the rush hour of a compact city center, taking a large family on vacation, or seeking shelter from the rain, we may arrive at a clear winner. The same is true for computer UIs.
Software usability expert Alan Cooper has written some useful words about usage patterns and defines two key usage modes: transient and sovereign. A transient application might be used every day, but only in short bursts and usually as a secondary activity. A sovereign application, in contrast, must cope with the user’s full attention for several hours at a time.
Many applications are inherently transient or sovereign. A writer’s word processor is a sovereign application, for example, around which a number of transient functions will revolve, such as the file manager (often embedded into the word processor as a file save or open dialog), a dictionary or spellchecker (again, often embedded), and an email or messenger program for communicating with colleagues. To a software developer, the text editor or Integrated Development Environment (IDE) is sovereign, as is the debugger.
Sovereign applications are also often used more intensely. Remember, a wellbehaved UI should be invisible. A good yardstick for the intensity of work is the effect on the user’s workflow of the UI stalling, thus reminding the user that it exists. If I’m simply moving files from one folder to another and hit a two-second delay, I can cope quite happily. If I encounter the same two-second delay while composing a visual masterpiece in a paint program, or in the middle of a heavy debugging session with some tricky code, I might get a bit upset.
Amazon is a transient application. So are eBay and Google—and most of the very large, public web-based applications out there. Since the dawn of the Internet, pundits have been predicting the demise of the traditional desktop office suite under the onslaught of web-based solutions. Ten years later, it hasn’t happened. Web page–based solutions are good enough for transient use but not for sovereign use.
1.1.5. Unlearning the Web
Fortunately, modern web browsers resemble the original ideal of a client for remote document servers about as closely as a Swiss army knife resembles a neolithic flint hunting tool. Interactive gizmos, scripting languages, and plug-ins have been bolted on willy-nilly over the years in a race to create the most compelling browsing experience. (Have a look at www.webhistory.org/www.lists/wwwtalk.1993q1/0182.html to get a perspective on how far we’ve come. In 1993, a pre-Netscape Marc Andreessen tentatively suggested to Tim Berners-Lee and others that HTML might benefit from an image tag.)
A few intrepid souls have been looking at JavaScript as a serious programming language for several years, but on the whole, it is associated with faked-up alert dialogs and “click the monkey to win” banners.
Think of Ajax as a rehabilitation center for this misunderstood, ill-behaved child of the browser wars. By providing some guidance and a framework within which to operate, we can turn JavaScript into a helpful model citizen of the Internet, capable of enhancing the real usability of a web application—and without enraging the user or trashing the browser in the process. Mature, well-understood tools are available to help us do this. Design patterns are one such tool that we make frequent use of in our work and will refer to frequently in this book.
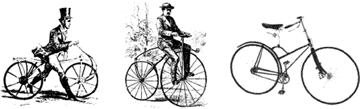
Introducing a new technology is a technical and social process. Once the technology is there, people need to figure out what to do with it, and a first step is often to use it as if it were something older and more familiar. Hence, early bicycles were referred to as “hobbyhorses” or “dandy horses” and were ridden by pushing one’s feet along the ground. As the technology was exposed to a wider audience, a second wave of innovators would discover new ways of using the technology, adding improvements such as pedals, brakes, gears, and pneumatic tires. With each incremental improvement, the bicycle became less horse-like (figure 1.10).
Figure 1.10. Development of the modern bicycle
The same processes are at work in web development today. The technologies behind Ajax have the ability to transform web pages into something radically new. Early attempts to use the Ajax technologies resembled the traditional web page document and have that neither-one-thing-nor-the-other flavor of the hobbyhorse. To grasp the potential of Ajax, we must let go of the concept of the web page and, in doing so, unlearn a lot of the assumptions that we have been making for the last few years. In the short few months since Ajax was christened, a lot of unlearning has been taking place.
1.2. The four defining principles of Ajax
The classic page-based application model is hard-wired into many of the frameworks that we use, and also into our ways of thinking. Let’s take a few minutes to discover what these core assumptions are and how we need to rethink them to get the most out of Ajax.
1.2.1. The browser hosts an application, not content
In the classic page-based web application, the browser is effectively a dumb terminal. It doesn’t know anything about where the user is in the greater workflow. All of that information is held on the web server, typically in the user’s session. Server-side user sessions are commonplace these days. If you’re working in Java or .NET, the server-side session is a part of the standard API, along with requests, responses, and Multipurpose Internet Mail Extensions (MIME) types. Figure 1.11 illustrates the typical lifecycle of a classic web application.
Figure 1.11. Lifecycle of a classic web application. All the state of the user’s “conversation” with the application is held on the web server. The user sees a succession of pages, none of which can advance the broader conversation without going back to the server.

When the user logs in or otherwise initializes a session, several server-side objects are created, representing, say, the shopping basket and the customer credentials if this is an e-commerce site. At the same time, the home page is dished up to the browser, in a stream of HTML markup that mixes together standard boilerplate presentation and user-specific data and content such as a list of recently viewed items.
Every time the user interacts with the site, another document is sent to the browser, containing the same mixture of boilerplate and data. The browser dutifully throws the old document away and displays the new one, because it is dumb and doesn’t know what else to do.
When the user hits the logout link or closes the browser, the application exits and the session is destroyed. Any information that the user needs to see the next time she or he logs on will have been handed to the persistence tier by now. An Ajax application moves some of the application logic to the browser, as figure 1.12 illustrates.
Figure 1.12. Lifecycle of an Ajax application. When the user logs in, a client application is delivered to the browser. This application can field many user interactions independently, or else send requests to the server behind the scenes, without interrupting the user’s workflow.

When the user logs in, a more complex document is delivered to the browser, a large proportion of which is JavaScript code. This document will stay with the user throughout the session, although it will probably alter its appearance considerably while the user is interacting with it. It knows how to respond to user input and is able to decide whether to handle the user input itself or to pass a request on to the web server (which has access to the system database and other resources), or to do a combination of both.
Because the document persists over the entire user session, it can store state. A shopping basket’s contents may be stored in the browser, for example, rather than in the server session.
1.2.2. The server delivers data, not content
As we noted, the classic web app serves up the same mixture of boilerplate, content, and data at every step. When our user adds an item to a shopping basket, all that we really need to respond with is the updated price of the basket or whether anything went wrong. As illustrated in figure 1.13, this will be a very small part of the overall document.
Figure 1.13. Breakdown of the content delivered (A) to a classic web application and (B) to an Ajax application. As the application continues to be used, cumulative traffic (C) increases.

An Ajax-based shopping cart could behave somewhat smarter than that, by sending out asynchronous requests to the server. The boilerplate, the navigation lists, and other features of the page layout are all there already, so the server needs to send back only the relevant data.
The Ajax application might do this in a number of ways, such as returning a fragment of JavaScript, a stream of plain text, or a small XML document. We’ll look at the pros and cons of each in detail in chapter 5. Suffice it to say for now that any one of these formats will be much smaller than the mish-mash returned by the classic web application.
In an Ajax application, the traffic is heavily front-loaded, with a large and complex client being delivered in a single burst when the user logs in. Subsequent communications with the server are far more efficient, however. For a transient application, the cumulative traffic may be less for a conventional web page application, but as the average length of interaction time increases, the bandwidth cost of the Ajax application becomes less than that of its classic counterpart.
1.2.3. User interaction with the application can be fluid and continuous
A web browser provides two input mechanisms out of the box: hyperlinks and HTML forms.
Hyperlinks can be constructed on the server and preloaded with Common Gateway Interface (CGI) parameters pointed at dynamic server pages or servlets. They can be dressed up with images and Cascading Style Sheets (CSS) to provide rudimentary feedback when the mouse hovers over them. Given a good web designer, hyperlinks can be made to look like quite fancy UI components.
Form controls offer a basic subset of the standard desktop UI components: input textboxes, checkboxes and radio buttons, and drop-down lists. Several likely candidates are missing, though. There are no out-of-the-box tree controls, editable grids, or combo-boxes provided. Forms, like hyperlinks, point at server-side URLs.
Alternatively, hyperlinks and form controls can be pointed at JavaScript functions. It’s a common technique in web pages to provide rudimentary form validation in JavaScript, checking for empty fields, out-of-range numbers, and so on, before submitting data to the server. These JavaScript functions persist only as long as the page itself and are replaced when the page submits.
While the page is submitting, the user is effectively in limbo. The old page may still be visible for a while, and the browser may even allow the user to click on any visible links, but doing so will produce unpredictable results and may wreak havoc with the server-side session. The user is generally expected to wait until the page is refreshed, often with a set of choices similar to those that were snatched away from them seconds earlier. After all, adding a pair of trousers to the shopping basket is unlikely to modify the top-level categories from “menswear,” “women’s wear,” “children’s,” and “accessories.”
Let’s take the shopping cart example again. Because our Ajax shopping cart sends data asynchronously, users can drop things into it as fast as they can click. If the cart’s client-side code is robust, it will handle this load easily, and the users can get on with what they’re doing.
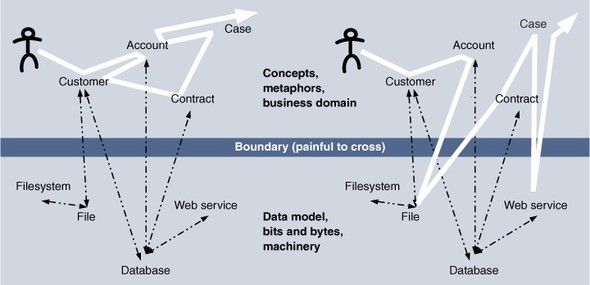
There is no cart to drop things into, of course, just an object in session on the server. Users don’t want to know about session objects while shopping, and the cart metaphor provides a more comfortable real-world description of what’s taking place. Switching contexts between the metaphor and direct access to the computer is distracting to users. Waiting for a page to refresh will jerk them back to the reality of sitting at a computer for a short time (figure 1.14), and our Ajax implementation avoids doing this. Shopping is a transient activity, but if we consider a different business domain, for example, a high-pressure help desk scenario or a complex engineering task, then the cost of disrupting the workflow every few seconds with a page refresh is prohibitive.
Figure 1.14. Interrupting the user’s workflow to process events. The user deals with two types of object: those relating to their business, and those relating to the computer system. Where the user is forced to switch between the two frequently, disorientation and lack of productivity may occur.
The second advantage of Ajax is that we can hook events to a wider range of user actions. More sophisticated UI concepts such as drag-and-drop become feasible, bringing the UI experience fully up to par with the desktop application widget sets. From a usability perspective, this freedom is important not so much because it allows us to exercise our imagination, but because it allows us to blend the user interaction and server-side requests more fully.
To contact the server in a classic web application, we need to click a hyperlink or submit a form, and then wait. This interrupts the user’s workflow. In contrast, contacting the server in response to a mouse movement or drag, or a keystroke, allows the server to work alongside the user. Google Suggest (www.google.com/webhp?complete=1) is a very simple but effective example of this: responding to users keystrokes as they type into the search box and contacting the server to retrieve and display a list of likely completions for the phrases, based on searches made by other users of the search engine worldwide. We provide a simple implementation of a similar service in chapter 8.
1.2.4. This is real coding and requires discipline
Classic web applications have been making use of JavaScript for some time now, to add bells and whistles around the edge of their pages. The page-based model prevents any of these enhancements from staying around for too long, which limits the uses to which they can be put. This catch-22 situation has led, unfairly, to JavaScript getting a reputation as a trivial, hacky sort of language, looked down upon by the serious developers.
Coding an Ajax application is a different matter entirely. The code that you deliver when users launch the application must run until they close it, without breaking, without slowing down, and without generating memory leaks. If we’re aiming at the sovereign application market, then this means several hours of heavy usage. To meet this goal, we must write high-performance, maintainable code, using the same discipline and understanding that is successfully applied to the server tiers.
The codebase will also typically be larger than anything written for a classic web application. Good practices in structuring the codebase become important. The code may become the responsibility of a team rather than an individual, bringing up issues of maintainability, separation of concerns, and common coding styles and patterns.
An Ajax application, then, is a complex functional piece of code that communicates efficiently with the server while the user gets on with work. It is clearly a descendent of the classic page-based application, but the similarity is no stronger than that between the early hobbyhorse and a modern touring bike. Bearing these differences in mind will help you to create truly compelling web applications.
1.3. Ajax rich clients in the real world
So much for the theory. Ajax is already being used to create real applications, and the benefit of the Ajax approach can already be seen. It’s still very much early days—the bicycles of a few far-sighted individuals have pedals and solid rubber tires, and some are starting to build disc brakes and gearboxes, so to speak. The following section surveys the current state of the art and then looks in detail at one of the prominent early adopters to see where the payoff in using Ajax lies.
1.3.1. Surveying the field
Google has done more than any other company to raise the profile of Ajax applications (and it, like the majority of adopters, was doing so before the name Ajax was coined). Its GMail service was launched in beta form in early 2004. Along with the extremely generous mailbox size, the main buzz around GMail was the UI, which allowed users to open several mail messages at once and which updated mailbox lists automatically, even while the user was typing in a message. Compared with the average web mail system offered by most Internet service providers (ISPs) at the time, this was a major step forward. Compared with the corporate mail server web interfaces of the likes of Microsoft Outlook and Lotus Notes, GMail offered most of the functionality without resorting to heavy, troublesome ActiveX controls or Java applets, making it available across most platforms and locations, rather than the corporate user’s carefully preinstalled machine.
Google has followed this up with further interactive features, such as Google Suggest, which searches the server for likely completions for your query as you type, and Google Maps, an interactive zoomable map used to perform location-based searches. At the same time, other companies have begun to experiment with the technology, such as Flickr’s online photo-sharing system, now part of Yahoo!
The applications we have discussed so far are testing the water. They are still transient applications, designed for occasional use. There are signs of an emerging market for sovereign Ajax applications, most notably the proliferation of frameworks in recent months. We look at a few of these in detail in chapter 3, and attempt to summarize the current state of the field in appendix C.
There are, then, sufficient signals to suggest that Ajax is taking hold of the market in a significant way. We developers will play with any new technology for its own sake, but businesses like Google and Yahoo! will join in only if there are compelling business reasons. We’ve already outlined many of the theoretical advantages of Ajax. In the following section, we’ll take apart Google Maps, in order to see how the theory stacks up.
1.3.2. Google Maps
Google Maps is a cross between a map viewer and a search engine. Initially, the map shows the entire United States (figure 1.15). The map can be queried using free text, allowing drill-down to specific street addresses or types of amenity such as hotels and restaurants (figure 1.16).
Figure 1.15. The Google Maps home page offers a scrolling window on a zoomable map of the United States, alongside the familiar Google search bar. Note that the zoom control is positioned on top of the map rather than next to it, allowing the user to zoom without taking his eyes off the map.
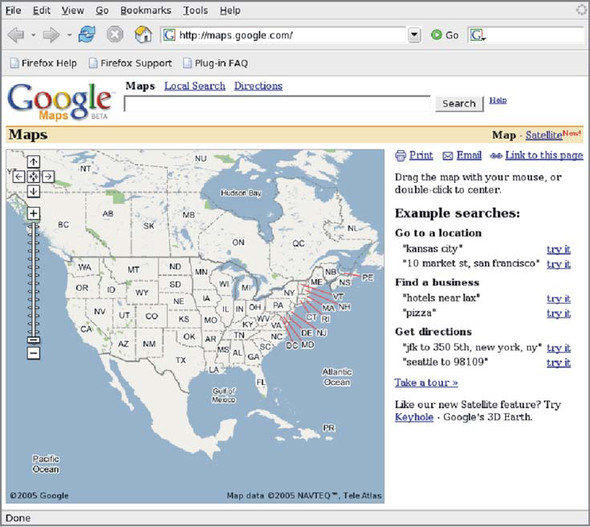
The search feature functions as a classic web app, refreshing the entire page, but the map itself is powered by Ajax. Clicking on individual links from a hotel search will cause additional pop-ups to be displayed on the fly, possibly even scrolling the map slightly to accommodate them. The scrolling of the map itself is the most interesting feature of Google Maps. The user can drag the entire map by using the mouse. The map itself is composed of small tiled images, and if the user scrolls the map far enough to expose a new tile, it will be asynchronously downloaded. There is a noticeable lag at times, with a blank white area showing initially, which is filled in once the map tile is loaded; however, the user can continue to scroll, triggering fresh tile requests, while the download takes place. The map tiles are cached by the browser for the extent of a user’s session, making it much quicker to return to a part of the map already visited.
Figure 1.16. Google Maps hotel search. Note the traditional use of the DHTML technologies to create shadows and rich tooltip balloons. Adding Ajax requests makes these far more dynamic and useful.
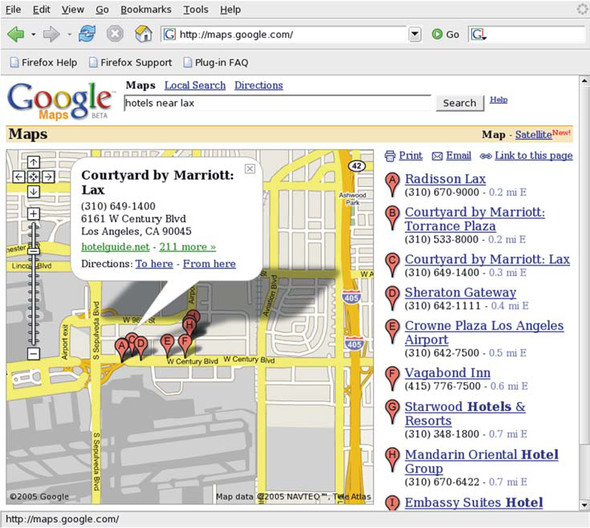
Looking back to our discussions of usability, two important things are apparent. First, the action that triggers the download of new map data is not a specific click on a link saying “fetch more maps” but something that the user is doing anyway, namely, moving the map around. The user workflow is uninterrupted by the need to communicate with the server. Second, the requests themselves are asynchronous, meaning that the contextual links, zoom control, and other page features remain accessible while the map is gathering new data.
Internet-based mapping services are nothing new. If we looked at a typical pre-Ajax Internet mapping site, we would see a different set of interaction patterns. The map would typically be divided into tiles. A zoom control, and perhaps sideways navigation links at the map’s edges, might be provided. Clicking on any of these would invoke a full-screen refresh, resulting in a similar page hosting different map tiles. The user workflow would be interrupted more, and after looking at Google Maps, the user would find the site slow and frustrating.
Turning to the server-side, both services are undoubtedly backed by some powerful mapping solutions. Both serve up map tiles as images. The conventional web server of the pre-Ajax site is continually refreshing boilerplate code when the user scrolls, whereas Google Maps, once up and running, serves only the required data, in this case image tiles that aren’t already cached. (Yes, the browser will cache the images anyway, providing the URL is the same, but browser caching still results in server traffic when checking for up-to-date data and provides a less-reliable approach than programmatic caching in memory.) For a site with the prominent exposure of Google, the bandwidth savings must be considerable.
To online services such as Google, ease of use is a key feature in getting users to visit their service and to come back again. And the number of page impressions is a crucial part of the bottom line for the business. By introducing a better UI with the flexibility that Ajax offers, Google has clearly given traditional mapping services something to worry about. Certainly other factors, such as the quality of the back-end service, come into play, but other things being equal, Ajax can offer a strong business advantage.
We can expect the trend for this to rise as public exposure to richer interfaces becomes more prevalent. As a marketable technology, Ajax looks to have a bright future for the next few years. However, other rich client technologies are looking to move into this space, too. Although they are largely outside the scope of this book, it’s important that we take a look at them before concluding our overview.
1.4. Alternatives to Ajax
Ajax meets a need in the marketplace for richer, more responsive web-based clients that don’t need any local installation. It isn’t the only player in that space, though, and in some cases, it isn’t even the most appropriate choice. In the following section, we’ll briefly describe the main alternatives.
1.4.1. Macromedia Flash-based solutions
Macromedia’s Flash is a system for playing interactive movies using a compressed vector graphics format. Flash movies can be streamed, that is, played as they are downloaded, allowing users to see the first bits of the movie before the last bits have arrived. Flash movies are interactive and are programmed with ActionScript, a close cousin of JavaScript. Some support for input form widgets is also provided, and Flash can be used for anything from interactive games to complex business UIs. Flash has very good vector graphics support, something entirely absent from the basic Ajax technology stack.
Flash has been around for ages and is accessed by a plug-in. As a general rule, relying on a web browser plug-in is a bad idea, but Flash is the web browser plug-in, with the majority of browsers bundling it as a part of the installation. It is available across Windows, Mac OS X, and Linux, although the installation base on Linux is probably smaller than for the other two platforms.
For the purposes of creating rich clients with Flash, two very interesting technologies are Macromedia’s Flex and the open source Laszlo suite, both of which provide simplified server-side frameworks for generating Flash-based business UIs. Both frameworks use Java/Java 2 Enterprise Edition (J2EE) on the server side. For lower-level control over creating Flash movies dynamically, several toolkits, such as PHP’s libswf module, provide core functionality.
1.4.2. Java Web Start and related technologies
Java Web Start is a specification for bundling Java-based web applications on a web server in such a way that a desktop process can find, download, and run them. These applications can be added as hyperlinks, allowing seamless access from a Web Start–savvy web browser. Web Start is bundled with the more recent Java runtimes, and the installation process will automatically enable Web Start on Internet Explorer and Mozilla-based browsers.
Once downloaded, Web Start applications are stored in a managed “sandbox” in the filesystem and automatically updated if a new version is made available. This allows them to be run while disconnected from the network and reduces network traffic on reload, making the deployment of heavy applications weighing several megabytes a possibility. Applications are digitally signed, and the user may choose to grant them full access to the filesystem, network ports, and other resources.
Traditionally, Web Start UIs are written in the Java Swing widget toolkit, about which strong opinions are held on both sides. The Standard Widget Toolkit (SWT) widgets used to power IBM’s Eclipse platform can also be deployed via Web Start, although this requires a bit more work.
Microsoft’s .NET platform offers a similar feature called No Touch Deployment, promising a similar mix of easy deployment, rich UIs, and security.
The main downside to both technologies is the need to have a runtime preinstalled. Of course, any rich client needs a runtime, but Flash and Ajax (which uses the web browser itself as a runtime) use runtimes that are commonly deployed. Java and .NET runtimes are both very limited in their distribution at present and can’t be relied on for a public web service.
1.5. Summary
We’ve discussed the differences between transient and sovereign applications and the requirements of each. Transient applications need to deliver the goods, but, when users are using them, they have already stepped out of their regular flow of work, and so a certain amount of clunkiness is acceptable. Sovereign applications, in contrast, are designed for long-term intensive use, and a good interface for a sovereign application must support the users invisibly, without breaking their concentration on the task at hand.
The client/server and related n-tier architectures are essential for collaborative or centrally coordinated applications, but they raise the specter of network latency, with its ability to break the spell of user productivity. Although a general-purpose solution to the conflict between the two exists in asynchronous remote event handling, the traditional request-response model of the classic web application is ill suited to benefit from it.
We’ve set a goal for ourselves, and for Ajax, in this chapter of delivering usable sovereign applications through a web browser, thereby satisfying the goals of user productivity, networking, and effortless, centralized maintenance of an application all at once. In order for this mission to succeed, we need to start thinking about our web pages and applications in a fundamentally different way. We’ve identified the key ideas that we need to learn and those that we need to unlearn:
- The browser hosts an application, not content.
- The server delivers data, not content.
- The user interacts continuously with the application, and most requests to the server are implicit rather than explicit.
- Our codebase is large, complex, and well structured. It is a first-class citizen in our architecture, and we must take good care of it.
The next chapter will unpack the key Ajax technologies and get our hands dirty with some code. The rest of the book will look at important design principles that can help us to realize these goals.
1.6. Resources
To check out some of our references in greater depth, here are URLs to several of the articles that we’ve referred to in this chapter:
- Jesse James Garrett christened Ajax on February 18, 2005, in this article: www.adaptivepath.com/publications/essays/archives/000385.php
- Alan Cooper’s explanation of sovereign and transient applications can be found here: www.cooper.com/articles/art_your_programs_posture.htm
- Google Maps can be found here if you live in the United States: http://maps.google.com and here if you live in the United Kingdom: http://maps.google.co.uk and here if you live on the moon: http://moon.google.com
The images of the bicycle were taken from the Pedaling History website: www.pedalinghistory.com