
Chapter 5. The role of the server
This chapter covers
- Using current web framework types with Ajax
- Exchanging data with the server as content, script, or data
- Communicating updates to the server
- Bundling multiple requests and replies into a single HTTP call
This chapter concludes the work that we started in chapter 4: making our applications robust and scalable. We’ve moved from the proof-of-concept stage to something that you can use in the real world. Chapter 4 examined ways of structuring the client code to achieve our goal; in this chapter, we look at the server and, more specifically, at the communication between the client and the server.
We’ll begin by looking at the big picture and discuss what functions the server performs. We’ll then move on to describe the types of architectures commonly employed in server-side frameworks. Many, many web frameworks are in use today, particularly in the Java world, and we won’t try to cover them all, but rather we’ll identify common approaches and ways of addressing web application development. Most frameworks were designed to generate classic web applications, so we’re particularly interested to see how they adapt to Ajax and where the challenges lie.
Having considered the large-scale patterns, we’ll look at the finer details of communicating between client and server. In chapter 2 we covered the basics of the XMLHttpRequest object and hidden IFrames. We’ll return to these basics here as we examine the various patterns for updating the client from the server and discuss the alternatives to parsing XML documents using DOM methods. In the final section, we’ll present a system for managing client/server traffic over the lifetime of the application, by providing a client-side queue for requests and server-side processes for managing them.
Let’s start off, then, by looking at the role of the server in Ajax.
5.1. Working with the server side
In the lifecycle of an Ajax application, the server has two roles to fulfill, and these are fairly distinct. First, it has to deliver the application to the browser. So far, we’ve assumed that the initial delivery of content is fairly static, that is, we write the application itself as a series of .html, .css, and .js files that even a very basic web server would be able to deliver. Nothing is wrong with this approach—in fact, a lot can be said for it—but it isn’t the only option available to us. We’ll look at the alternatives later, when we discuss server-side frameworks in section 5.3.
The second role of the server is to talk to the client, fielding queries and supplying data on request. Because HTTP is the only transport mechanism available to us, we’re limited to the client starting off any conversation. The server can only respond. In chapter 4, we discussed the need for an Ajax application to maintain a domain model on both the client (for fast responses) and the server (for access to resources such as the database). Keeping the models in sync with one another represents a major challenge, and one that the client can’t solve on its own. We’ll look at ways of writing data to the server in section 5.5 and present a solution to this problem based on one of the patterns that we encountered in chapter 3.
We can deliver the client application—and talk to the client—in several ways, as you will see in this chapter. Is one way better than the others? Do any particular combinations support each other? Can they be mixed and matched? How do the different solutions work with legacy server frameworks and architectures? To answer these questions, a vocabulary for describing our various options will be useful. And that’s exactly what we’re going to develop in this chapter. First, let’s look at the way the server is set up in a web application, and how Ajax affects that.
5.2. Coding the server side
In a conventional web application, the server side tends to be a rather complex place, controlling and monitoring the user’s workflow through the application and maintaining conversational state. The application is designed for a particular language, and set of conventions, that will determine what it can and can’t do. Languages may in themselves be tied to specific architectures, operating systems, or hardware. Picking a programming environment is a big choice to make, so let’s discuss the options available to us.
5.2.1. Popular implementation languages
Server-side programming is dominated by a handful of languages. Over the very brief course of Internet history, fashions in server-side languages have changed remarkably. The current kings of the hill are PHP, Java, and classic ASP, with ASP.NET and Ruby growing in popularity too. These names are undoubtedly familiar to most readers, so I won’t try to explain what they are here. Ajax is primarily a client-side technology and can interoperate with any of these languages. Indeed, some ways of working with Ajax downplay the importance of the server-side language considerably, making it easy to port Ajax applications from one server platform to another.
Web frameworks are in many ways more important to Ajax than the implementation language. Web frameworks carry assumptions with them, about how the application is structured and where key responsibilities lie. Most frameworks have been designed for building classic web applications, and assumptions about the lifecycles of these—which are very different from those of an Ajax app—may be problematic in places. We’ll look at server-side designs and frameworks in the following section, but first, let’s review the basic principles of web-based architectures, in order to lay the groundwork for that discussion.
5.2.2. N-tier architectures
A core concept in distributed applications is that of the tier. A tier often represents a particular set of responsibilities for an application, but it also describes a subsystem that can be physically isolated on a particular machine or process. This distinguishes it from the roles in MVC, for example. Model, View, and Controller aren’t tiers because they typically sit in the same process.
Early distributed systems consisted of a client tier and a server tier. The client tier was a desktop program using a network socket library to communicate to the server. The server tier was typically a database server.
Similarly, early web systems consisted of a browser talking to a web server, a monolithic system on the network sending files from the filesystem.
As web-based applications became more complex and began to require access to databases, the two-tier model of client/server was applied to the web server to create a three-tier model, with the web server mediating between the web browser client and the database. Later refinements on the model saw a further separation of the middle tier into presentation and business roles, either as distinct processes or as a more modular software design within a single process.
Modern web applications typically have two principal tiers. The business tier models the business domain, and talks directly to the database. The presentation tier takes data from the business tier and presents it to the user. The browser acts as a dumb client in this setup.
The introduction of Ajax can be considered to be the development of a further client tier, separating the presentation tier’s traditional responsibilities of workflow and session management between the web server and the client (figure 5.1).
Figure 5.1. An Ajax application moves some of the responsibilities of the presentation tier from the server up to the browser, in a new entity that we call the client tier.
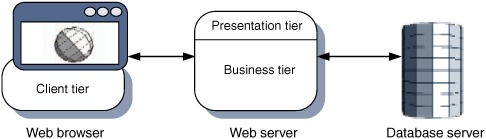
The role of the server-side presentation tier can be much reduced and workflow control partly or completely handed over to the new client tier, written in JavaScript and hosted on the browser.
This new tier in our application brings with it new possibilities, as we’ve already discussed. It also brings the potential for greater complexity and confusion. Clearly, we need a way to manage this.
5.2.3. Maintaining client-side and server-side domain models
In an Ajax application, we still need to model the business domain on the server, close to the database and other vital centralized resources. However, to give the client code sufficient responsiveness and intelligence, we typically will want to maintain at least a partial model in the browser. This presents the interesting problem of keeping the two models in sync with one another.
Adding an extra tier always adds complexity and communications overheads. Fortunately, the problem isn’t entirely new, and similar issues are commonly encountered in J2EE web development, for example, in which there is a strict separation between the business tier and the presentation tier. The domain model sits on the business tier and is queried by the presentation tier, which then generates web content to send to the browser. The problem is solved in J2EE by the use of “transfer objects,” which are simple Java objects designed to pass data between the tiers, presenting limited views of the domain model to the presentation tier.
Ajax provides us with new challenges, though. In J2EE, both tiers are written in a common language with a remote procedure mechanism provided, which is typically not the case with Ajax. We could use JavaScript on the server tier, through Mozilla’s Rhino or Microsoft’s JScript .NET, for example, but it is currently rather unorthodox to do so, and we’d still need to communicate between the two JavaScript engines.
The two basic requirements for communicating between the tiers are reading data from the server and writing data to the server. We’ll look at the details of these in section 5.3 through 5.5. Before we conclude our overview of architectural issues, though, we will look at the main categories of server architecture currently in use. In particular, we’ll be interested to see how they represent the domain model to the presentation tier and what restrictions this might place on an Ajax-based design.
A recent informal survey (see the Resources at the end of this chapter) listed over 60 presentation frameworks for Java alone (to be fair, Java probably suffers from this framework-itis more than any other server language). Most of these differ in the details, fortunately, and we can characterize the presentation tier (in whatever server language) as following one of several architectural patterns. Let’s have a look at these now.
5.3. The big picture: common server-side designs
Server-side frameworks matter to all Ajax applications. If we choose to generate the client code from a sever-side model, it matters a great deal. If we hand-code the client code and serve it as static HTML and JavaScript pages, then the framework isn’t involved in delivering the app, but the data that the application will consume still has to be dynamically generated. Also, as we noted in the previous section, the server-side framework typically contains a domain model of some sort, and the presentation tier framework stands between that model and our Ajax application. We need to be able to work with the framework in order for our application to function smoothly.
Web application servers can be unkindly characterized as developers’ playgrounds. The problem of presenting a coherent workflow to a user through a series of web pages, while interfacing to back-end systems such as database servers, has never been adequately solved. The Web is littered with undernourished, ill-maintained frameworks and utilities, with new projects popping up on a monthly, if not weekly, basis.
Fortunately, we can recognize discrete families within this chaotic mixture. Reducing this framework soup to its essentials, there are possibly four main ways to get the job done. Let’s examine each in turn and see how it can be adapted to the Ajax model.
5.3.1. Naive web server coding without a framework
The simplest kind of framework is no framework at all. Writing a web application without a framework defining the key workflow elements, or mediating access to the back-end systems, doesn’t imply a complete lack of order. Many web sites are still developed this way, with each page generating its own views and performing its own back-end housekeeping, probably with the assistance of some shared library of helper functions or objects. Figure 5.2 illustrates this pattern of programming.
Figure 5.2. Web programming without a framework. Each page, servlet, or CGI script maintains its own logic and presentation details. Helper functions and/or objects may encapsulate common low-level functionality, such as database access.
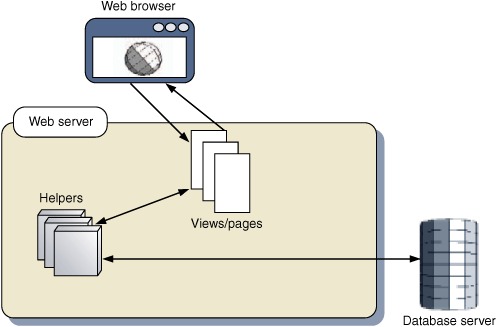
Modifying this approach for Ajax is relatively straightforward, if we assume that the client is hand-coded. Generating client code from the server is a big topic that’s beyond the scope of this book. To deliver the client, we need to define a master page that will include any necessary JavaScript files, stylesheets, and other resources. For supplying data feeds, we simply need to replace the generated HTML pages with XML or the other data stream of our choice (more on this topic later).
The key shortcoming of this approach in a classic web app is that the links between documents are scattered throughout the documents themselves. That is, the Controller role is not clearly defined in one place. If a developer needs to rework the user flow between screens, then hyperlinks must be modified in several places. This could be partly ameliorated by putting link-heavy content such as navigation bars inside include files or generating them programmatically using helper functions, but maintenance costs will still rise steeply as the app becomes more complicated.
In an Ajax application, this may be less of a problem, since hyperlinks and other cross-references will typically not be embedded in data feeds as densely as in a web page, but includes and forwarding instructions between pages will still pose a problem. Includes and forwards won’t be required in a simple XML document, but larger applications may be sending complex structured documents assembled by several subprocesses, as we will see in section 5.5. The early generation of web frameworks used MVC as a cure for these ills, and many of these frameworks are still in use today, so let’s look at them next.
5.3.2. Working with Model2 workflow frameworks
The Model2 design pattern is a variation of MVC, in which the Controller has a single point of entry and a single definition of the users’ possible workflows. Applied to a web application, this means that a single Controller page or servlet is responsible for routing most requests, passing the request through to various back-end services and then out to a particular View. Apache Struts is probably the best-known Model2 framework, although a number of other Java and PHP frameworks follow this pattern. Figure 5.3 illustrates the structure of a Model2 web framework.
Figure 5.3. Model2 web framework. A single controller page or servlet accepts all requests and is configured with a complete graph of user workflows and interactions. The request will be handed to one of a number of ancillary classes or functions for more specialized processing and finally routed out to a View component (for example, a JSP or PHP page) before being sent to the browser.
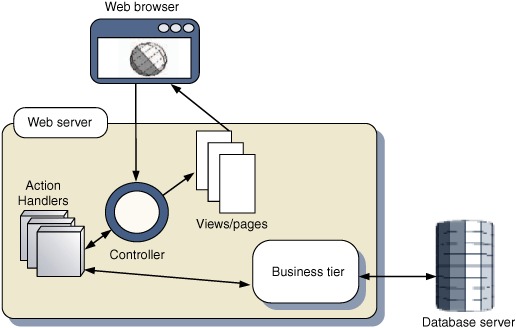
How can we apply this design to a server application talking to an Ajax client, then? Model2 has relatively little to say about the delivery of the client application, which will typically occur at startup as a single payload, identical for all authenticated users. The centralized controller may be involved in the authentication process itself, but there is little merit in expressing the delivery of the application itself through anything other than a single endpoint of the controller.
It provides a workable solution for delivery of data feeds, though. The Views returned by Model2 are essentially independent of the framework, and we may easily swap HTML for XML or other data formats. Part of the Controller responsibility will be passed to the client tier, but some Controller functions may still be usefully expressed through server-side mappings.
Model2 for classic web apps provides a good way of expressing much of the Controller responsibility at a high level of abstraction, but it leaves the implementation of the View as a hand-coding task. Later developments in web frameworks attempted to provide a higher-level abstraction for the View, too. Let’s examine them next.
5.3.3. Working with component-based frameworks
When writing an HTML page for a classic web application, the page author has a very limited set of predefined GUI components at hand, namely the HTML form elements. Their feature set has remained largely unchanged for nearly 10 years, and compared to modern GUI toolkits, they are very basic and uninspiring. If a page author wishes to introduce anything like a tree control or editable grid, a calendar control or an animated hierarchical menu, he needs to resort to low-level programming of basic document elements. Compared with the level of abstraction available to a developer building a desktop GUI using component toolkits such as MFC, GTK+, Cocoa, Swing, or Qt, this seems like a poor option.
Widgets for the web
Component-based frameworks aim to raise the level of abstraction for web UI programming, by providing a toolkit of server-side components whose API resembles that of a desktop GUI widget set. When desktop widgets render themselves, they typically paint onto a graphics context using low-level calls to generate geometric primitives, bitmaps, and the like. When web-based widgets render themselves, they automatically generate a stream of HTML and JavaScript that provides equivalent functionality in the browser, relieving the poor coder from a lot of low-level drudgery. Figure 5.4 illustrates the structure of a component-based web framework.
Figure 5.4. Architecture of a component-based web framework. The application is described as a collection of widgets that render themselves by emitting a stream of HTML and JavaScript into the browser. Each component contains its own small-scale Model, View, and Controller, in addition to the larger Controller that fields browser requests to individual components and the larger domain model.
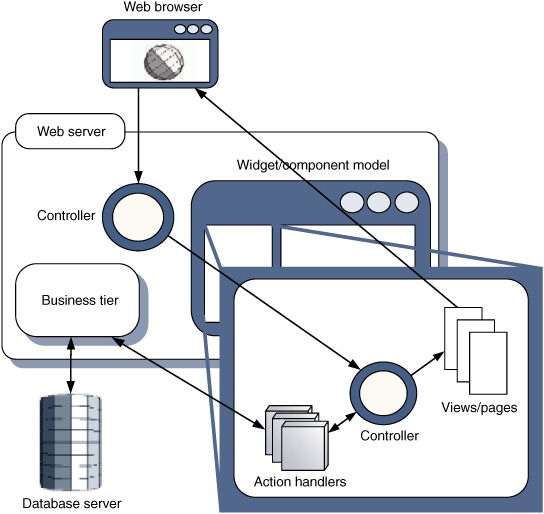
Many component-based frameworks describe user interaction using a desktop-style metaphor. That is, a Button component may have a click event handler, a text field component may have a valueChange handler, and so on. In most frameworks, event processing is largely delegated to the server, with a request being fired for each user interaction. Smarter frameworks manage to do this behind the scenes, but some will refresh the entire page with each user event. This leads to a decidedly clunky user experience, as an application designed as a widget set will typically have lots of fine-grained interactions compared to one designed as a set of pages, using Model2, say.
A significant design goal of these frameworks is to be able to render different types of user interface from a single widget model description. Some frameworks, such as Windows Forms for .NET and JavaServer Faces (JSF), are already able to do this.
Interoperating with Ajax
So how do Component-based frameworks fare with Ajax, then? On the surface, both are moving away from a document-like interface toward a widget-based one, so the overlap ought to be good. This type of framework may have strong possibilities as far as generating the client application goes, if pluggable renderers that understand Ajax can be developed. There is a considerable appeal to doing so, since it avoids the need to retrain developers in the intricacies of JavaScript, and it leaves an easy route for providing an alternative to older browsers through a plain-old HTML rendering system.
Such a solution will work well for applications that require only standard widget types. A certain degree of flexibility, however, will be lacking. Google Maps, for example (see chapter 1), is successful largely because it defines its own set of widgets, from the scrollable map to the zoom slider and the pop-up balloons and map pins. Trying to build this using a standard set of desktop widgets would be difficult and probably less satisfactory in the end.
That said, many applications do fit more easily within the conventional range of widget types and would be better served by these types of framework. This trade-off between flexibility and convenience is common to many code generation–based solutions and is well understood.
To fully serve an Ajax application, the framework must also be able to supply the necessary data feeds. Here, the situation may be somewhat more problematic, as the Controller is heavily tied to the server tiers and is tightly defined through the desktop metaphor. A responsive Ajax application requires more freedom in determining its own event handlers than the server event model seems to allow. Nonetheless, there is considerable momentum behind some of these frameworks, and solutions will undoubtedly emerge as Ajax rises in popularity. The CommandQueue approach that we will introduce in section 5.5.3 may be one way forward for JSF and its cousins, although it wasn’t designed as such. For now, though, these frameworks tie the client a little too closely to their apron strings for my liking.
It will be interesting to see how these frameworks adapt to Ajax in the future. There is already significant interest in providing Ajax-enabled toolkits from within Sun and from several of the JSF vendors, and .NET Forms already support some Ajax-like functionality, with more being promised in the forthcoming Atlas toolkit (see the Resources section at the end of this chapter for URLs to all these).
This raises the question of what a web framework would look like if designed specifically for Ajax. No such beast exists today, but our final step on the tour of web frameworks may one day be recognized as an early ancestor.
5.3.4. Working with service-oriented architectures
The final kind of framework that we’ll look at here is the service-oriented architecture (SOA). A service in an SOA is something that can be called from the network and that will return a structured document as a reply. The emphasis here is on data, not content, which is a good fit with Ajax. Web services are the most common type of service currently, and their use of XML as a lingua franca also works well with Ajax.
Note
The term Web Services, with capital letters, generally refer to systems using SOAP as transport. The broader term web services (in lower case), encompasses any remote data exchange system that runs over HTTP, with no constraints on using SOAP or even XML. XML-RPC, JSON-RPC and any custom system that you develop using the XMLHttpRequest object are web services, but not Web Services. We are talking about the broader category of web services in this section.
When consuming a web service as its data feed, an Ajax client achieves a high degree of independence, similar to that of a desktop email client communicating to a mail server, for example. This is a different kind of reuse from that offered by the component-based toolkits. There, the client is defined once and can be exported to multiple interfaces. Here, the service is defined once and can be used by numerous unrelated clients. Clearly, a combination of SOA and Ajax could be powerful, and we may see separate frameworks evolving to generate, and to serve, Ajax applications.
Exposing server-side objects to Ajax
Many SOA and web service toolkits have appeared that make it possible to expose a plain-old server-side object written in Java, C#, or PHP directly as a web service, with a one-to-one mapping between the object’s methods and the web service interface. Microsoft Visual Studio tools support this, as does Apache Axis for Java. A number of Ajax toolkits, such as DWR (for Java) and SAJAX (for PHP, .NET, Python, and several other languages) enhance these capabilities with JavaScriptspecific client code.
These toolkits can be very useful. They can also be misused if not applied with caution. Let’s look at a simple example using the Java DWR toolkit, in order to work out the right way to use these tools. We will define a server-side object to represent a person.
package com.manning.ajaxinaction;
public class Person{
private String name=null;
public Person(){
}
public String getName(){
return name;
}
public void setName(String name){
this.name=name;
}
}
The object must conform to the basic JavaBeans specification. That is, it must provide a public no-argument constructor, and expose any fields that we want to read or write with getter and setter methods respectively. We then tell DWR to expose this object to the JavaScript tier, by editing the dwr.xml file:
<dwr>
<init>
<convert id="person" converter="bean"
match="com.manning.ajaxinaction.Person"/>
</init>
<allow>
<create creator="new" javascript="person">
<param name="class" value="com.manning.ajaxinaction.Person">
</create>
</allow>
</dwr>
In the <init> section, we define a converter for our class of type bean, and in the <allow> section, we then define a creator that will expose instances of that object to JavaScript as a variable called person. Our Person object only has one public method, getName(), so we will be able to write in our Ajax client code
var name=person.getName();
and retrieve the value asynchronously from the server.
Our Person only has one method, so that’s all we’ve exposed, right? Unfortunately, that’s a false assumption. Our Java Person class is descended from java.lang.Object and inherits a few public methods from there, such as hashCode() and toString(), which we can also invoke from the server. This hidden feature is not peculiar to DWR. The JSONRPCBridge.registerObject() method will do the same, for example. To its credit, DWR does provide a mechanism for restricting access to specific methods within its XML config file. However, the default behavior is to expose everything. This problem is inherent in most reflection-based solutions. We ran across it in chapter 4 in our early versions of the ObjectViewer utility using JavaScript reflection. Let’s see what we can do about it.
Limiting exposure
We’ve accidentally exposed our hashcodes to the Web, but have we really done any damage? In this case, probably not, because the superclass is java.lang.Object, which is unlikely to change. In a more complex domain model, though, we might be exposing implementation details of our own superclasses, which we might want to refactor later. By the time we get around to it, some bright spark is bound to have discovered our unwittingly exposed methods and used them in his client code, so that when we deploy the refactored object model, his client suddenly breaks. In other words, we’ve failed to separate our concerns adequately. If we’re using a toolkit such as DWR or JSON-RPC, then we should take great care to decide which objects we are going to publish as our Ajax interface and preferably create a Façade object of some sort (figure 5.5).
Figure 5.5. Comparison of a system in which all objects are fully exposed as Internet services to an Ajax client and one is using a Façade to expose only a few carefully chosen pieces of functionality. By reducing the number of publicly published methods, we can refactor our domain model without fear of breaking client code over which we have no control.

Using a Façade in this situation offers several advantages. First, as already noted, it allows us to refactor our server-side model without fear. Second, it simplifies the publicly published interface that client code will use. In comparison to code written for internal consumption, interfaces published to other parties are expensive. Either we document them in detail up front or we don’t document them—and become inundated with support calls from people writing to our published interfaces.
Another advantage of Façade is that it allows us to define the level of granularity of our services separately from the design of our domain model. A good domain model may contain lots of small, precise methods, because we require that precision and control within our server-side code. The requirements of a web service interface for an Ajax client are quite different, however, because of network latency. Many small method calls will kill the usability of the client, and, if deployed in sufficient number, may kill the server and even the network.
Think of it as the difference between a face-to-face conversation and a written correspondence (or an IM conversation and an email correspondence, for those too young and hip to remember what pen and paper are). When I talk directly to you, there are many small interchanges, possibly several just to establish that we are both “fine” today. When writing a letter, I may send a single exchange describing the state of my health, a recent vacation, what the family is doing, and a joke that I heard the other day, all in a single document.
By bundling calls across the network into larger documents, service-oriented architectures are making better use of available network resources. Bandwidth is typically less of a problem than latency. They are also causing problems for themselves by standardizing on a bulky XML data format over a verbose transmission protocol (our familiar and well-loved HTTP), but that’s a story for another day. If we look at the options available with Ajax, we can see that we are provided with good native support for HTTP and XML technologies in the browser, and so a document-centric approach to our distributed domain models makes sense.
A conventional document, such as this book, is composed of paragraphs, headings, tables, and figures. Likewise, a document in a call to a service may contain a variety of elements, such as queries, updates, and notifications. The Command pattern, discussed in chapter 3, can provide a good foundation for structuring our documents as a series of undoable actions to be passed between client and server. We’ll look at an implementation of this later in the chapter.
This concludes our discussion of the server-side architectures of the day. None provides a perfect fit for Ajax yet, which is not surprising given that they were designed to serve a considerably different kind of web application. A lot of good work is underway to build Ajax into existing frameworks and the next year or so should prove interesting. Nonetheless, many web developers will be faced with the task of making Ajax work with these legacy systems, and this overview of the strengths and weaknesses for each ought to provide a starting point.
Let’s assume for the moment that we have decided upon one architecture or another and begun the work of developing an Ajax application. We have already discussed the architecture of the client application itself in detail in chapter 4, and we provided examples of retrieving XML data from the server in chapter 2. XML is popular but not the only way of exchanging data between client and server. In the following section, we review the full spectrum of options for communicating between client and server.
5.4. The details: exchanging data
We’ve looked at the big architectural patterns that describe how our web application might behave and shown that there are many options. We’ve stressed the importance of communication between the client and the server’s domain models, and we might naively assume that once we’ve settled on a framework, our design choices are made for us. In this and the following section, we’ll see that this is far from true. If we focus on a single exchange of data, we have many options. We’ll catalog the options here, with the aim of developing a pattern language for Ajax data exchange. With this in hand, we can make more informed decisions about what techniques to use in particular circumstances.
Exchanging pure data has no real analog in the classical web application, and so the pattern language is less well developed in this area. I’ll attempt to fill that void by defining a few phrases of my own. As a first cut, I suggest that we break user interactions into four categories: client-only, content-centric, script-centric, and data-centric. Client-only interactions are simple, so we’ll deal with them quickly in the next section, and then introduce an example that can see us through the other three.
5.4.1. Client-only interactions
A client-only interaction is one in which a user interaction is processed by a script that has already been loaded into the browser. No recourse to the web server (the old presentation tier) is necessary, which is good for responsiveness and for server load. Such an interaction is suitable for relatively trivial calculations, such as adding a sales tax or shipping charge to a customer’s order. In general, for this approach to be effective, the client-side logic that processes the interaction needs to be small and unchanging during the lifetime of the customer interaction. In the case of shipping options, we are on safe ground because the number of options will be of the order of two to five, not several thousands (unlike, say, the full catalog of an online retailer), and the shipping costs are unlikely to change from one minute to the next (unlike, say, a stock ticker or first-come-first-served ticket-reservation system). This type of interaction has already been explored in chapter 4’s discussion of the client-side Controller, so we’ll say no more about it here.
The remaining three categories all involve a trip back to the server and differ primarily in what is fetched. The key differences are summarized in the following sections, along with the pros and cons of each.
5.4.2. Introducing the planet browser example
Before we dive in to the different data exchange mechanisms, let’s introduce a simple example, to serve as a hook on which to hang our arguments. The application will present a range of facts about the planets of our solar system. Our main screen shows an idealized view of the solar system, with an icon for each planet. On the server, we have recorded various facts about these planets, which can be brought up in pop-up windows by clicking on the planet’s icon (figure 5.6). We aren’t using the ObjectViewer from chapter 4 here, but we will get back to it later in this chapter.
Figure 5.6. Screenshot of planetary info application, in which pop-up windows describing each planet can be brought up by clicking on the icons.

The part of the puzzle that interests us now is delivering the data shown in the pop-up from the server to the browser. We’ll look at the format of data that the server sends us in each variation, but we won’t go into the details of generating that data, as we’ve already covered the principles in our discussion of MVC in chapter 3. Listing 5.1 shows the skeleton of our client-side application, around which we can explore the various content-delivery mechanisms.
Listing 5.1. popups.html


We have included a few JavaScript libraries ![]() in our file. net.js handles the low-level HTTP request mechanics for us, using the XMLHttpRequest object that we described
in chapter 2. windows.js defines a draggable window object that we can use as our pop-up window. The details of the implementation of
the window needn’t concern us here, beyond the signature of the constructor:
in our file. net.js handles the low-level HTTP request mechanics for us, using the XMLHttpRequest object that we described
in chapter 2. windows.js defines a draggable window object that we can use as our pop-up window. The details of the implementation of
the window needn’t concern us here, beyond the signature of the constructor:
var MyWindow=new Window(bodyDiv,title,x,y,w,h);
where bodyDiv is a DOM element that will be added into the window body, title is a display string to show in the window titlebar, and x,y,w,h describes the initial window geometry. By specifying a DOM element as the argument, we give ourselves considerable flexibility as to how the content is supplied to the window. The downloadable source code accompanying the book contains the full listing for the Window object.
In the HTML, we simply define a div element for each planet ![]() , to which we assign an onclick handler in the window.onload function
, to which we assign an onclick handler in the window.onload function ![]() , using the standard DOM tree navigation methods. The onclick handler, showInfo(), isn’t defined here, as we’ll provide several implementations in this chapter. Let’s start by looking at the various actions
that we can take when we come to loading the content.
, using the standard DOM tree navigation methods. The onclick handler, showInfo(), isn’t defined here, as we’ll provide several implementations in this chapter. Let’s start by looking at the various actions
that we can take when we come to loading the content.
5.4.3. Thinking like a web page: content-centric interactions
The first steps that we take toward Ajax will resemble the classic web application that we are moving away from, as noted in chapter 1 when discussing horses and bicycles. Content-centric patterns of interaction still follow the classic web paradigm but may have a role to play in an Ajax application.
Overview
In a content-centric pattern of interaction, HTML content is still being generated by the server and sent to an IFrame embedded in the main web page. We discussed IFrames in chapter 2 and showed how to define them in the HTML markup of the page or generate them programmatically. In the latter case, we can still be looking at a fairly radically dynamic style of interface more akin to a window manager than a desktop. Figure 5.7 outlines the content-centric architecture.
Figure 5.7. Content-centric architecture in an Ajax application. The client creates an IFrame and launches a request to the server for content. The content is generated from a Model, View, and Controller on the server presentation tier and returned to the IFrame. There is no requirement for a business domain model on the client tier.

Listing 5.2 shows an implementation of the event handler for our planetary info application, using a content-centric approach.
Listing 5.2. ContentPopup.js
var offset=8;
function showInfo(event){
var planet=this.id;
var infoWin=new ContentPopup(
"info_"+planet+".html",
planet+"Popup",
planet,offset,offset,320,320
);
offset+=32;
}
function ContentPopup(url,winEl,displayStr,x,y,w,h){
var bod=document.createElement("div");
document.body.appendChild(bod);
this.iframe=document.createElement("iframe");
this.iframe.className="winContents";
this.iframe.src=url;
bod.appendChild(this.iframe);
this.win=new windows.Window(bod,displayStr,x,y,w,h);
}
showInfo() is the event-handler function for the DOM element representing the planet. Within the event handler, this refers to the DOM element, and we use that element’s id to determine for which planet we display information.
We define a ContentPopup object that composes one of the generic Window objects, creates an IFrame to use as the main content in the window body, and loads the given URL into it. In this case, we have simply constructed the name of a static HTML file as the URL. In a more sophisticated system with dynamically generated data, we would probably add querystring parameters to the URL instead. The simple file that we load into the IFrame in this example, shown in listing 5.3, is generated by the server.
Listing 5.3. info_earth.html
<html> <head> <link rel=stylesheet type="text/css" href="../style.css"/> </head> <body class="info"> <div class="framedInfo" id="info"> <div class="title" id="infotitle">earth</div> <div class="content" id="infocontent"> A small blue planet near the outer rim of the galaxy, third planet out from a middle-sized sun. </div> </div> </body> </html>
Nothing remarkable there—we can just use plain HTML markup as we would for a classic web application.
In a content-centric pattern, the client-tier code needs only a limited understanding of the business logic of the application, being responsible for placing the IFrame and constructing the URL needed to invoke the content. Coupling between the client and presentation tiers is quite loose, with most responsibility still loaded onto the server. The benefit of this style of interaction is that there is plenty of HTML floating around on the Web, ready to use. Two scenarios in which it could be useful are incorporating content from external sites—possibly business partners or public services—and displaying legacy content from an application. HTML markup can be very effective, and there is little point in converting some types of content into application-style content. Help pages are a prime example. In many cases where a classic web application would use a pop-up window, an Ajax application might prefer a content-centric piece of code, particularly in light of the pop-up blocker features in many recent browsers.
This pattern is useful in a limited set of situations, then. Let’s briefly review its limitations before moving on.
Problems and limitations
Because they resemble conventional web pages so much, content-centric interactions have many of the limitations of the old way of doing things. The content document is isolated within the IFrame from the page in which it is embedded. This partitions the screen real estate to some extent. In terms of layout, the IFrame imposes a single rectangular window for the child document, although it may be assigned a transparent background to help blend it into the parent document.
It may be tempting to use this mechanism to deliver highly dynamic subpages within the highly dynamic application, but the introduction of IFrames in this way can be problematic. Each IFrame maintains its own scripting context, and the amount of “plumbing” code required for scripts in the IFrame and parent to talk to one another can be considerable. For communication with scripts in other frames, the problem worsens. We’ll return to this issue shortly when we look at script-centric patterns.
We also suffer many of the usability problems of traditional web applications. First, if the layout of the IFrame involves nontrivial boilerplate markup, we are still resending static content with each request for content. Second, although the main document won’t suffer from “blinking” when data is refreshed, the IFrame might, if the same frame is reused for multiple fetches of content. This latter issue could be avoided with a bit of extra coding to present a loading message over the top of the frame, for example.
So, “content-centric” is the first new term for our vocabulary of Ajax server request techniques. Content-centric approaches are limited in usefulness, but it’s good to have a name for them. There are many scenarios that can’t be easily addressed by a content-centric approach, such as updating a small part of a widget’s surface, for example, a single icon or a single row in a table. One way to perform such modifications is to send JavaScript code. Let’s look at that option now.
Variations
The content-centric style that we’ve applied so far has used an IFrame to receive the server-generated content. An alternative approach that might be considered content-centric is to generate a fragment of HTML in response to an asynchronous request, and assign the response to the innerHTML of a DOM element in the current document. We use that approach in chapter 12 in our XSLT-driven phonebook, so we won’t reproduce a full example here.
5.4.4. Thinking like a plug-in: script-centric interactions
When we send a JavaScript file from our web server to a browser, and it executes in that browser for us, we are actually doing something quite advanced. If we generate the JavaScript that we are sending from a program, we are setting up an even more complex system. Traditionally, client/server programs communicate data to one another. Communicating executable, mobile code across the network opens up a lot of flexibility. Enterprise-grade network languages such as Java and the .NET stack are only just catching on to the possibilities of mobile code, through technologies such as RMI, Jini, and the .NET Remoting Framework. We lightweight web developers have been doing it for years! As usual, Ajax lets us do a few new interesting things with this capability, so let’s see what they are.
Overview
In a classic web application, a piece of JavaScript and its associated HTML are delivered in a single bundle, and the script is typically authored to work with that particular page. Using Ajax, we can load scripts and pages independently of one another, giving us the possibility of modifying a particular page in a number of different ways, depending on the script that we load. The code that constitutes our client-tier application can effectively be extended at runtime. This introduces both problems and opportunities, as we will see. Figure 5.8 illustrates the basic architecture of a script-centric application.
Figure 5.8. Script-centric architecture in an Ajax application. The client application makes a request to the server for a fragment of JavaScript, which it then interprets. The client app exposes several entry points for generated scripts to hook into, allowing manipulation of the client by the script.
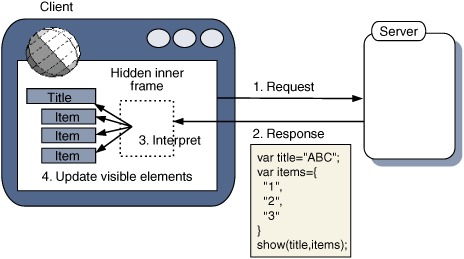
The first advantage of this approach over a content-centric solution is that the network activity is relegated to the background, eliminating visual blinking.
The exact nature of the script that we generate will depend on the hooks that we expose in the client tier itself. As with much code generation, success hinges on keeping the generated portion simple and making use of nongenerated library code where possible, either transmitted alongside the generated code or resident in the client application.
Either way, this pattern results in relatively tight coupling between the tiers. That is, the code generated by the server requires intimate knowledge of API calls on the client. Two problems emerge. First, changes to the server and client code can unintentionally break them. Good modular design principles can offset this to some extent, by providing a well-defined, well-documented API—implementing the Façade pattern. The second issue is that the stream of JavaScript is very specifically designed for this client, and it is unlikely to be as reusable in other contexts in comparison to, say, a stream of XML. Reusability isn’t important in all cases, however.
Let’s have a look at our planetary info example again. Listing 5.4 shows a simple API for displaying our information windows.
Listing 5.4. showPopup() function and supporting code
var offset=8;
function showPopup(name,description){
var win=new ScriptIframePopup
(name,description,offset,offset,320,320);
offset+=32;
}
function ScriptIframePopup(name,description,x,y,w,h){
var bod=document.createElement("div");
document.body.appendChild(bod);
this.contentDiv=document.createElement("div");
this.contentDiv.className="winContents";
this.contentDiv.innerHTML=description;
bod.appendChild(this.contentDiv);
this.win=new windows.Window(bod,name,x,y,w,h);
}
We define a function showPopup that takes a name and description as argument and constructs a window object for us. Listing 5.5 shows an example script that invokes this function.
Listing 5.5. script_earth.js
var name='earth'; var description="A small blue planet near the outer rim of the galaxy," +"third planet out from a middle-sized sun."; showPopup (name,description);
We simply define the arguments and make a call against the API. Behind the scenes, though, we need to load this script from the server and persuade the browser to execute it. There are two quite different routes that we can take. Let’s examine each in turn.
Loading scripts into IFrames
If we load a JavaScript using an HTML document <script> tag, the script will automatically be executed by the interpreter when it loads. IFrames are the same as any other document in this respect. We can define a showInfo() method to create an IFrame for us, and load the script into it:
function showInfo(event){
var planet=this.id;
var scriptUrl="script_"+planet+".html";
var dataframe=document.getElementById('dataframe'),
if (!dataframe){
dataframe=document.createElement("iframe");
dataframe.className='dataframe';
dataframe.id='dataframe';
dataframe.src=scriptUrl;
document.body.appendChild(dataframe);
}else{
dataframe.src=scriptUrl;
}
}
The DOM manipulation methods that we’re using should be familiar by now. If we use an invisible IFrame to load our script, we need only concentrate on generating the script itself, since all other interactions are generated for us. So let’s stitch our sample script into an HTML document, as shown in listing 5.6.
Listing 5.6. script_earth.html
<html> <head> <script type='text/javascript' src='script_earth.js'> </script> </head> <body> </body> </html>
When we try to load this code, it doesn’t work, because the IFrame creates its own JavaScript context and can’t directly see the API that we defined in the main document. When our script states
showPopup(name,description);
the browser looks for a function showPopup() defined inside the IFrame’s context. In a simple two-context situation such as this, we can preface API calls with top, that is,
top.showPopup(name,description);
in order to refer to the top-level document. If we were nesting IFrames inside IFrames, or wanted to be able to run our application inside a frameset, things could get much more complicated.
The script that we load uses a functional approach. If we choose to instantiate an object in our IFrame script, we will encounter further complications. Let’s say that we have a file PlanetInfo.js that defines a PlanetInfo type of object that we invoke in our script as
var pinfo=new PlanetInfo(name,description);
To use this type in our script, we could import PlanetInfo.js into the IFrame context, by adding an extra script tag:
<script type='text/javascript' src='PlanetInfo.js'></script> <script type='text/javascript'> var pinfo=new PlanetInfo(name,description); </script>
The PlanetInfo object created within the IFrame would have identical behavior to one created in the top-level frame, but the two wouldn’t have the same prototype. If the IFrame were later destroyed, but the top-level document kept a reference to an object created by that IFrame, subsequent calls to the object’s methods would fail. Further, the instanceof operator would have counterintuitive behavior, as outlined in table 5.1.
Table 5.1. Behavior of instanceof operator across frames
|
instanceof Invoked In |
Obj instanceof Object Evaluates To |
|
|---|---|---|
| Top-level document | Top-level document | true |
| Top-level document | IFrame | false |
| IFrame | Top-level document | false |
| IFrame | IFrame | true |
Importing the same object definition into multiple scripting contexts is not as simple as it first looks. We can avoid it by providing a factory method as part of our top-level document’s API, for example:
function createPlanetInfo(name,description){
return new PlanetInfo(name,description);
}
which our script can then call without needing to refer to its own version of the PlanetInfo type, thus:
<script type='text/javascript'> var pinfo=createPlanetInfo(name,description); </script>
The showPopup() function in listing 5.4 is essentially a factory for the ScriptIframePopup object.
This approach works and does what we want it to. We need to send a small amount of HTML boilerplate with each page, but much less than with the content-centric solution. The biggest drawback of this approach appears to be the creation of a separate JavaScript context. There is a way to avoid that altogether, which we will look at now.
Loading scripts using XMLHttpRequest and eval()
JavaScript, like many scripting languages, has an eval() function, which allows any arbitrary text to be passed directly to the JavaScript interpreter. Using eval() is often discouraged, or noted as being slow, and this is indeed the case when it is called regularly on lots of small scripts. However, it has its uses, and we can exploit it here to evaluate scripts loaded from the server using the XMLHttpRequest object. eval() performs with reasonable efficiency when working on fewer, larger scripts.
Our planetary info example is rewritten to use eval() in the following code:
function showInfo(event){
var planet=this.id;
var scriptUrl="script_"+planet+".js";
new net.ContentLoader(scriptUrl,evalScript);
}
function evalScript(){
var script=this.req.responseText;
eval(script);
}
The showInfo() method now uses the XMLHttpRequest object (wrapped in our ContentLoader class) to fetch the script from the server, without needing to wrap it in an HTML page. The second function, evalScript(), is passed to the ContentLoader as a callback, at which point we can read the responseText property from the XMLHttpRequest object. The entire script is evaluated in the current page context, rather than in a separate context within an IFrame.
We can add the term script-centric to our pattern language now and make a note that there are two implementations of it, using IFrames and eval(). Let’s step back then, and see how script-based approaches compare with the content-based style.
Problems and limitations
When we load a script directly from the server, we are generally transmitting a simpler message, reducing bandwidth to some extent. We also decouple the logic from the presentation to a great degree, with the immediate practical consequence that visual changes aren’t confined to a fixed rectangular portion of the screen as they are with the content-centric approach.
On the downside, however, we introduce a tight coupling between client and server code. The JavaScript emitted by the server is unlikely to be reusable in other contexts and will need to be specifically written for the Ajax client. Further, once published, the API provided by the client will be relatively difficult to change.
It’s a step in the right direction, though. The Ajax application is starting to behave more like an application and less like a document. In the next style of client-server communication that we cover, we can release the tight coupling between client and server that was introduced here.
5.4.5. Thinking like an application: data-centric interactions
With the script-centric approach just described, we have started to behave more like a traditional thick client, with data requests to the server taking place in the background, decoupled from the user interface. The script content remained highly specific to the browser-based client, though.
Overview
In some situations, we may want to share the data feeds to our Ajax client with other front ends, such as Java or .NET smart clients or cell phone/PDA client software. In such cases, we would probably prefer a more neutral data format than a set of JavaScript instructions.
In a data-centric solution, the server serves up streams of pure data, which our own client code, rather than the JavaScript engine, parses. Figure 5.9 illustrates the features of a data-centric solution.
Figure 5.9. In a data-centric system, the server returns streams of raw data (XML in this case), which are parsed on the client tier and used to update the client tier model and/or user interface.

Most of the examples in this book follow a data-centric approach. The most obvious format for data is XML, but other formats are possible, too, as we’ll see next.
Using XML data
XML is a near-ubiquitous data format in modern computing. The web browser environment in which our Ajax application sits, and the XMLHttpRequest object in particular, provides good native support for processing XML. If the XMLHttpRequest receives a response with an XML Content type such as application/xml or text/xml, it can present the response as a Document Object Model, as we have already seen. Listing 5.7 shows how our planetary data application adapts to using XML data feeds.
Listing 5.7. DataXMLPopup.js
var offset=8;
function showPopup(name,description){
var win=new DataPopup(name,description,offset,offset,320,320);
offset+=32;
}
function DataPopup(name,description,x,y,w,h){
var bod=document.createElement("div");
document.body.appendChild(bod);
this.contentDiv=document.createElement("div");
this.contentDiv.className="winContents";
this.contentDiv.innerHTML=description;
bod.appendChild(this.contentDiv);
this.win=new windows.Window(bod,name,x,y,w,h);
}
function showInfo(event){
var planet=this.id;
var scriptUrl=planet+".xml";
new net.ContentLoader(scriptUrl,parseXML);
}
function parseXML(){
var name="";
var descrip="";
var xmlDoc=this.req.responseXML;
var elDocRoot=xmlDoc.getElementsByTagName("planet")[0];
if (elDocRoot){
attrs=elDocRoot.attributes;
name=attrs.getNamedItem("name").value;
var ptype=attrs.getNamedItem("type").value;
if (ptype){
descrip+="<h2>"+ptype+"</h2>";
}
descrip+="<ul>";
for(var i=0;i<elDocRoot.childNodes.length;i++){
elChild=elDocRoot.childNodes[i];
if (elChild.nodeName=="info"){
descrip+="<li>"+elChild.firstChild.data+"</li>
";
}
}
descrip+="</ul>";
}else{
alert("no document");
}
top.showPopup(name,descrip);
}
The showInfo() function simply opens up an XMLHttpRequest object, wrapped up in a ContentLoader object, providing the parseXML() function as a callback. The callback here is slightly more involved than the evalScript() method that we encountered in section 5.6.3, as we have to navigate the response DOM, pull out the data, and then manually invoke the showPopup() method. Listing 5.8 shows an example XML response generated by the server, which our XML data-centric app might consume.
Listing 5.8. earth.xml
<planet name="earth" type="small">
<info id="a" author="dave" date="26/05/04">
Earth is a small planet, third from the sun
</info>
<info id="b" author="dave" date="27/02/05">
Surface coverage of water is roughly two-thirds
</info>
<info id="c" author="dave" date="03/05/05">
Exhibits a remarkable diversity of climates and landscapes
</info>
</planet>
A big advantage of XML is that it lends itself to structuring information. We have taken advantage of this here to provide a number of <info> tags, which we translate into an HTML unordered list in the parseXML() code.
We’ve achieved better separation of the server and client tiers by using XML. Provided that both sides understand the document format, client and server code can be changed independently of one another. However, getting the JavaScript interpreter to do all the work for us in the script-centric solutions of the previous section was nice. The following example, using JSON, gives us something of the best of both worlds. Let’s look at it now.
Using JSON data
The XMLHttpRequest object is arguably misnamed, as it can receive any text-based information. A useful format for transmitting data to the Ajax client is the JavaScript Object Notation (JSON), a compact way of representing generic JavaScript object graphs. Listing 5.9 shows how we adapt our planetary info example to use JSON.
Listing 5.9. DataJSONPopup.js
function showInfo(event){
var planet=this.id;
var scriptUrl=planet+".json";
new net.ContentLoader(scriptUrl,parseJSON);
}
function parseJSON(){
var name="";
var descrip="";
var jsonTxt=net.req.responseText;
var jsonObj=eval("("+jsonTxt+")");
name=jsonObj.planet.name
var ptype=jsonObj.planet.type;
if (ptype){
descrip+="<h2>"+ptype+"</h2>";
}
var infos=jsonObj.planet.info;
descrip+="<ul>";
for(var i in infos){
descrip+="<li>"+infos[i]+"</li>
";
}
descrip+="</ul>";
top.showPopup(name,descrip);
}
Once again, we fetch the data using a ContentLoader and assign a callback function, here parseJSON(). The entire response text is a valid JavaScript statement, so we can create an object graph in one line by simply calling eval():
var jsonObj=eval("("+jsonTxt+")");
Note that we need to wrap the entire expression in parentheses before we evaluate it. We can then query the object properties directly by name, leading to somewhat more terse and readable code than the DOM manipulation methods that we used for the XML. The showPopup() method is omitted, as it is identical to that in listing 5.7.
So what does JSON actually look like? Listing 5.10 shows our data for planet Earth as a JSON string.
Listing 5.10. earth.json
{"planet": {
"name": "earth",
"type": "small",
"info": [
"Earth is a small planet, third from the sun",
"Surface coverage of water is roughly two-thirds",
"Exhibits a remarkable diversity of climates and landscapes"
]
}}
Curly braces denote associative arrays, and square braces numerical arrays. Either kind of brace can nest the other. Here, we define an object called planet that contains three properties. The name and type properties are simple strings, and the info property is an array.
JSON is less common than XML, although it can be consumed by any JavaScript engine, including the Java-based Mozilla Rhino and Microsoft’s JScript .NET. The JSON-RPC libraries contain JSON parsers for a number of programming languages (see the Resources section at the end of this chapter), as well as a JavaScript “Stringifier” for converting JavaScript objects to JSON strings, for two-way communications using JSON as the medium. If a JavaScript interpreter is available at both the server and client end, JSON is definitely a viable option. The JSON-RPC project has also been developing libraries for parsing and generating JSON for a number of common server-side languages.
We can add data-centric to our vocabulary now and note the potential for a wide range of text-based data formats other than the ever-popular XML.
Using XSLT
Another alternative to manually manipulating the DOM tree to create HTML, as we have done in section 5.7.3, is to use XSLT transformations to automatically convert the XML into XHTML. This is a hybrid between the data-centric and content-centric approaches. From the server’s perspective, it is data-centric, whereas from the client’s, it looks more content-centric. This is quicker and easier but suffers the same limits as a content-centric approach, namely, the response is interpreted purely as visual markup typically affecting a single rectangular region of the visible UI. XSLT is discussed in more detail in chapter 11.
Problems and limitations
The main limitation of a data-centric approach is that it places the burden of parsing the data squarely on the client. Hence the client-tier code will tend to be more complicated, but, where this approach is adopted wholesale in a larger application, the costs can be offset by reusing parser code or abstracting some of the functionality into a library.
The three approaches that we have presented here arguably form a spectrum between the traditional web-app model and the desktop-style thick client. Fortunately, the three patterns are not mutually exclusive and may all be used in the same application.
Client/server communications run both ways, of course. We’ll wrap up this chapter with a look at how the client can send data to the server.
5.5. Writing to the server
So far, we’ve concentrated on one side of the conversation, namely, the server telling the client what is going on. In most applications, the user will want to manipulate the domain model as well as look at it. In a multiuser environment, we also want to receive updates on changes that other users have made.
Let’s consider the case of updating changes that we have made first. Technically, there are two main mechanisms for submitting data: HTML forms and the XMLHttpRequest object. Let’s run through each briefly in turn.
5.5.1. Using HTML forms
In a classic web application, HTML form elements are the standard mechanism for user input of data. Form elements can be declared in the HTML markup for a page:
<form method="POST" action="myFormHandlerURL.php"> <input type="text" name="username"/> <input type="password" name="password"/> <input type="submit" value="login"/> </form>
This will render itself as a couple of blank text boxes. If I enter values of dave and letmein on the form, then an HTTP POST request is sent to myFormHandlerURL.php, with body text of username=dave&password=letmein. In most modern web programming systems, we don’t directly see this encoded form data but have the name-value pairs decoded for us as an associative array or “magic” variables.
It’s fairly common practice these days to add a little JavaScript to validate the form contents locally before submitting. We can modify our simple form to do this:
<form id="myForm" method="POST" action=""
onsubmit="validateForm(); return false;">
<input type="text" name="username"/>
<input type="password" name="password"/>
<input type="submit" value="login"/>
</form>
And we can define a validation routine in the JavaScript for the page:
function validateForm(){
var form=document.getElementById('myForm'),
var user=form.elements[0].value;
var pwd=form.elements[1].value;
if (user && user.length>0 && pwd && pwd.length>0){
form.action='myFormHandlerURL.php';
form.submit();
}else{
alert("please fill in your credentials before logging in");
}
}
The form is initially defined with no action attribute. The real URL is substituted only when the values in the form have been validated correctly. JavaScript can also be used to enhance forms by disabling the Submit button to prevent multiple submissions, encrypting passwords before sending them over the network, and so on. These techniques are well documented elsewhere, and we won’t go into them in depth here. Chapters 9 and 10 contain more detailed working examples of Ajax-enhanced HTML forms.
We can also construct a form element programmatically and submit it behind the scenes. If we style it to not be displayed, we can do so without it ever being seen by the user, as illustrated in listing 5.11.
Listing 5.11. submitData() function
function addParam(form,key,value){
var input=document.createElement("input");
input.name=key;
input.value=value;
form.appendChild(input);
}
function submitData(url,data){
var form=document.createElement("form");
form.action=url;
form.method="POST";
for (var i in data){
addParam(form,i,data[i]);
}
form.style.display="none";
document.body.appendChild(form);
form.submit();
}
submitData() creates the form element and iterates over the data, adding to the form using the addParam() function. We can invoke it like this:
submitData(
"myFormHandlerURL.php",
{username:"dave",password:"letmein"}
);
This technique is concise but has a significant drawback in that there is no easy way of capturing a server response. We could point the form at an invisible IFrame and then parse the result, but this is rather cumbersome at best. Fortunately, we can achieve the same effect by using the XMLHttpRequest object.
5.5.2. Using the XMLHttpRequest object
We’ve already seen the XMLHttpRequest object in action in chapter 2 and earlier in this chapter. The differences between reading and updating are minor from the client code’s point of view. We simply need to specify the POST method and pass in our form parameters.
Listing 5.12 shows the main code for our ContentLoader object developed in section 3.1. We have refactored it to allow parameters to be passed to the request, and any HTTP method to be specified.
Listing 5.12. ContentLoader object


We pass in several new arguments to the constructor ![]() . Only the URL (corresponding to the form action) and the onload handler are required, but the HTTP method, request parameters, and content type may be specified, too. Note that if we’re
submitting key-value pairs of data by POST, then the content type must be set to application/x-www-form-urlencoded. We handle this automatically if no content type is specified. The HTTP method is specified in the open() method of XMLHttpRequest, and the params in the send() method. Thus, a call like this
. Only the URL (corresponding to the form action) and the onload handler are required, but the HTTP method, request parameters, and content type may be specified, too. Note that if we’re
submitting key-value pairs of data by POST, then the content type must be set to application/x-www-form-urlencoded. We handle this automatically if no content type is specified. The HTTP method is specified in the open() method of XMLHttpRequest, and the params in the send() method. Thus, a call like this
var loader=net.ContentLoader( 'myFormHandlerURL.php', showResponse, null, 'POST', 'username=dave&password=letmein' );
will perform the same request as the forms-based submitData() method in listing 5.11. Note that the parameters are passed as a string object using the form-encoded style seen in URL querystrings, for example:
name=dave&job=book&work=Ajax_In+Action
This covers the basic mechanics of submitting data to the server, whether based on textual input from a form or other activity such as drag and drop or mouse movements. In the following section, we’ll pick up our ObjectViewer example from chapter 4 and learn how to manage updates to the domain model in an orderly fashion.
5.5.3. Managing user updates effectively
In chapter 4, we introduced the ObjectViewer, a generic piece of code for browsing complex domain models, and provided a simple example for viewing planetary data. The objects representing the planets in the solar system each contained several parameters, and we marked a couple of simple textual properties—the diameter and distance from the sun—as editable. Changes made to any properties in the system were captured by a central event listener function, which we used to write some debug information to the browser status bar. (The ability to write to the status bar is being restricted in recent builds of Mozilla Firefox. In appendix A, we present a pure JavaScript logging console that could be used to provide status messages to the user in the absence of a native status bar.) This event listener mechanism also provides an ideal way of capturing updates in order to send them to the server.
Let’s suppose that we have a script updateDomainModel.jsp running on our server that captures the following information:
- The unique ID of the planet being updated
- The name of the property being updated
- The value being assigned to the property
We can write an event handler to fire all changes to the server like so:
function updateServer(propviewer){
var planetObj=propviewer.viewer.object;
var planetId=planetObj.id;
var propName=propviewer.name;
var val=propviewer.value;
net.ContentLoader(
'updateDomainModel.jsp',
someResponseHandler,
null,
'POST',
'planetId='+encodeURI(planetId)
+'&propertyName='+encodeURI(propName)
+'&value='+encodeURI(val)
);
}
And we can attach it to our ObjectViewer:
myObjectViewer.addChangeListener(updateServer);
This is easy to code but can result in a lot of very small bits of traffic to the server, which is inefficient and potentially confusing. If we want to control our traffic, we can capture these updates and queue them locally and then send them to the server in batches at our leisure. A simple update queue implemented in JavaScript is shown in listing 5.13.
Listing 5.13. CommandQueue object
net.CommandQueue=function(id,url,freq){  Create a queue object
this.id=id;
net.cmdQueues[id]=this;
this.url=url;
this.queued=new Array();
this.sent=new Array();
if (freq){
this.repeat(freq);
}
}
net.CommandQueue.prototype.addCommand=function(command){
if (this.isCommand(command)){
this.queue.append(command,true);
}
}
net.CommandQueue.prototype.fireRequest=function(){
Create a queue object
this.id=id;
net.cmdQueues[id]=this;
this.url=url;
this.queued=new Array();
this.sent=new Array();
if (freq){
this.repeat(freq);
}
}
net.CommandQueue.prototype.addCommand=function(command){
if (this.isCommand(command)){
this.queue.append(command,true);
}
}
net.CommandQueue.prototype.fireRequest=function(){  Send request to server
if (this.queued.length==0){
return;
}
var data="data=";
for(var i=0;i<this.queued.length;i++){
var cmd=this.queued[i];
if (this.isCommand(cmd)){
data+=cmd.toRequestString();
this.sent[cmd.id]=cmd;
}
}
this.queued=new Array();
this.loader=new net.ContentLoader(
this.url,
net.CommandQueue.onload,net.CommandQueue.onerror,
"POST",data
);
}
net.CommandQueue.prototype.isCommand=function(obj){
Send request to server
if (this.queued.length==0){
return;
}
var data="data=";
for(var i=0;i<this.queued.length;i++){
var cmd=this.queued[i];
if (this.isCommand(cmd)){
data+=cmd.toRequestString();
this.sent[cmd.id]=cmd;
}
}
this.queued=new Array();
this.loader=new net.ContentLoader(
this.url,
net.CommandQueue.onload,net.CommandQueue.onerror,
"POST",data
);
}
net.CommandQueue.prototype.isCommand=function(obj){  Test object type
return (
obj.implementsProp("id")
&& obj.implementsFunc("toRequestString")
&& obj.implementsFunc("parseResponse")
);
}
net.CommandQueue.onload=function(loader){
Test object type
return (
obj.implementsProp("id")
&& obj.implementsFunc("toRequestString")
&& obj.implementsFunc("parseResponse")
);
}
net.CommandQueue.onload=function(loader){  Parse server response
var xmlDoc=net.req.responseXML;
var elDocRoot=xmlDoc.getElementsByTagName("commands")[0];
if (elDocRoot){
for(i=0;i<elDocRoot.childNodes.length;i++){
elChild=elDocRoot.childNodes[i];
if (elChild.nodeName=="command"){
var attrs=elChild.attributes;
var id=attrs.getNamedItem("id").value;
var command=net.commandQueue.sent[id];
if (command){
command.parseResponse(elChild);
}
}
}
}
}
net.CommandQueue.onerror=function(loader){
alert("problem sending the data to the server");
}
net.CommandQueue.prototype.repeat=function(freq){
Parse server response
var xmlDoc=net.req.responseXML;
var elDocRoot=xmlDoc.getElementsByTagName("commands")[0];
if (elDocRoot){
for(i=0;i<elDocRoot.childNodes.length;i++){
elChild=elDocRoot.childNodes[i];
if (elChild.nodeName=="command"){
var attrs=elChild.attributes;
var id=attrs.getNamedItem("id").value;
var command=net.commandQueue.sent[id];
if (command){
command.parseResponse(elChild);
}
}
}
}
}
net.CommandQueue.onerror=function(loader){
alert("problem sending the data to the server");
}
net.CommandQueue.prototype.repeat=function(freq){  Poll the server
this.unrepeat();
if (freq>0){
this.freq=freq;
var cmd="net.cmdQueues["+this.id+"].fireRequest()";
this.repeater=setInterval(cmd,freq*1000);
}
}
net.CommandQueue.prototype.unrepeat=function(){
Poll the server
this.unrepeat();
if (freq>0){
this.freq=freq;
var cmd="net.cmdQueues["+this.id+"].fireRequest()";
this.repeater=setInterval(cmd,freq*1000);
}
}
net.CommandQueue.prototype.unrepeat=function(){  Switch polling off
if (this.repeater){
clearInterval(this.repeater);
}
this.repeater=null;
}
Switch polling off
if (this.repeater){
clearInterval(this.repeater);
}
this.repeater=null;
}
The CommandQueue object (so called because it queues Command objects—we’ll get to that in a minute) is initialized ![]() with a unique ID, the URL of a server-side script, and, optionally, a flag indicating whether to poll repeatedly. If it doesn’t, then we’ll need to fire it manually every so often. Both modes of operation may be useful, so both are included here.
When the queue fires a request to the server, it converts all commands in the queue to strings and sends them with the request
with a unique ID, the URL of a server-side script, and, optionally, a flag indicating whether to poll repeatedly. If it doesn’t, then we’ll need to fire it manually every so often. Both modes of operation may be useful, so both are included here.
When the queue fires a request to the server, it converts all commands in the queue to strings and sends them with the request
![]() .
.
The queue maintains two arrays. queued is a numerically indexed array, to which new updates are appended. sent is an associative array, containing those updates that have been sent to the server but that are awaiting a reply. The objects
in both queues are Command objects, obeying an interface enforced by the isCommand() function ![]() . That is:
. That is:
- It can provide a unique ID for itself.
- It can serialize itself for inclusion in the POST data sent to the server (see ).
- It can parse a response from the server (see ) in order to determine whether it was successful or not, and what further action, if any, it should take.
We use a function implementsFunc() to check that this contract is being obeyed. Being a method on the base class Object, you might think it is standard JavaScript, but we actually defined it ourselves in a helper library like this:
Object.prototype.implementsFunc=function(funcName){
return this[funcName] && this[funcName] instanceof Function;
}
Appendix B explains the JavaScript prototype in greater detail. Now let’s get back to our queue object. The onload method of the queue ![]() expects the server to return with an XML document consisting of <command> tags inside a central <commands> tag.
expects the server to return with an XML document consisting of <command> tags inside a central <commands> tag.
Finally, the repeat() ![]() and unrepeat()
and unrepeat() ![]() methods are used to manage the repeating timer object that will poll the server periodically with updates.
methods are used to manage the repeating timer object that will poll the server periodically with updates.
The Command object for updating the planet properties is presented in listing 5.14.
Listing 5.14. UpdatePropertyCommand object
planets.commands.UpdatePropertyCommand=function(owner,field,value){
this.id=this.owner.id+"_"+field;
this.obj=owner;
this.field=field;
this.value=value;
}
planets.commands.UpdatePropertyCommand.toRequestString=function(){
return {
type:"updateProperty",
id:this.id,
planetId:this.owner.id,
field:this.field,
value:this.value
}.simpleXmlify("command");
}
planets.commands.UpdatePropertyCommand.parseResponse=function(docEl){
var attrs=docEl.attributes;
var status=attrs.getNamedItem("status").value;
if (status!="ok"){
var reason=attrs.getNamedItem("message").value;
alert("failed to update "
+this.field+" to "+this.value
+"
"+reason);
}
}
The command simply provides a unique ID for the command and encapsulates the parameters needed on the server. The toRequestString() function writes itself as a piece of XML, using a custom function that we have attached to the Object prototype:
Object.prototype.simpleXmlify=function(tagname){
var xml="<"+tagname;
for (i in this){
if (!this[i] instanceof Function){
xml+=" "+i+"=""+this[i]+""";
}
}
xml+="/>";
return xml;
}
This will create a simple XML tag like this (formatted by hand for clarity):
<command type='updateProperty' id='001_diameter' planetId='mercury' field='diameter' value='3'/>
Note that the unique ID consists only of the planet ID and the property name. We can’t send multiple edits of the same value to the server. If we do edit a property several times before the queue fires, each later value will overwrite earlier ones.
The POST data sent to the server will contain one or more of these tags, depending on the polling frequency and how busy the user is. The server process needs to process each command and store the results in a similar response. Our CommandQueue’s onload will match each tag in the response to the Command object in the sent queue and then invoke that Command’s parseResponse method. In this case, we are simply looking for a status attribute, so the response might look like this:
<commands> <command id='001_diameter' status='ok'/> <command id='003_albedo' status='failed' message='value out of range'/> <command id='004_hairColor' status='failed' message='invalid property name'/> </commands>
Mercury’s diameter has been updated, but two other updates have failed, and a reason has been given in each case. Our user has been informed of the problems (in a rather basic fashion using the alert() function) and can take remedial action.
The server-side component that handles these requests needs to be able to break the request data into commands and assign each command to an appropriate handler object for processing. As each command is processed, the result will be written back to the HTTP response. A simple implementation of a Java servlet for handling this task is given in listing 5.15.
Listing 5.15. CommandServlet.java
public class CommandServlet extends HttpServlet {
private Map commandTypes=null;
public void init() throws ServletException {
ServletConfig config=getServletConfig();
commandTypes=new HashMap(); Configure handlers on startup
boolean more=true;
for(int counter=1;more;counter++){
String typeName=config.getInitParameter("type"+counter);
String typeImpl=config.getInitParameter("impl"+counter);
if (typeName==null || typeImpl==null){
more=false;
}else{
try{
Class cls=Class.forName(typeImpl);
commandTypes.put(typeName,cls);
}catch (ClassNotFoundException clanfex){
this.log(
"couldn't resolve handler class name "
+typeImpl);
}
}
}
}
protected void doPost(
HttpServletRequest req,
HttpServletResponse resp
) throws IOException{
resp.setContentType("text/xml"); Process a request
Reader reader=req.getReader();
Writer writer=resp.getWriter();
try{
SAXBuilder builder=new SAXBuilder(false);
Document doc=builder.build(reader); Process XML data
Element root=doc.getRootElement();
if ("commands".equals(root.getName())){
for(Iterator iter=root.getChildren("command").iterator();
iter.hasNext();){
Element el=(Element)(iter.next());
String type=el.getAttributeValue("type");
XMLCommandProcessor command=getCommand(type,writer);
if (command!=null){
Element result=command.processXML(el); Delegate to handler
writer.write(result.toString());
}
}
}else{
sendError(writer,
"incorrect document format - "
+"expected top-level command tag");
}
}catch (JDOMException jdomex){
sendError(writer,"unable to parse request document");
}
}
private XMLCommandProcessor getCommand
(String type,Writer writer)
throws IOException{ Match handler to command
XMLCommandProcessor cmd=null;
Class cls=(Class)(commandTypes.get(type));
if (cls!=null){
try{
cmd=(XMLCommandProcessor)(cls.newInstance());
}catch (ClassCastException castex){
sendError(writer,
"class "+cls.getName()
+" is not a command");
} catch (InstantiationException instex) {
sendError(writer,
"not able to create class "+cls.getName());
} catch (IllegalAccessException illex) {
sendError(writer,
"not allowed to create class "+cls.getName());
}
}else{
sendError(writer,"no command type registered for "+type);
}
return cmd;
}`
private void sendError
(Writer writer,String message) throws IOException{
writer.write("<error msg='"+message+"'/>");
writer.flush();
}
}
The servlet maintains a map of XMLCommandProcessor objects that are configured here through the ServletConfig interface ![]() . A more mature framework might provide its own XML config file. When processing an incoming POST request
. A more mature framework might provide its own XML config file. When processing an incoming POST request ![]() , we use JDOM to parse the XML data
, we use JDOM to parse the XML data ![]() and then iterate through the <command> tags matching type attributes to XMLCommandProcessors
and then iterate through the <command> tags matching type attributes to XMLCommandProcessors ![]() . The map holds class definitions, from which we create live instances using reflection in the getCommand() method
. The map holds class definitions, from which we create live instances using reflection in the getCommand() method ![]() .
.
The XMLCommandProcessor interface consists of a single method:
public interface XMLCommandProcessor {
Element processXML(Element el);
}
The interface depends upon the JDOM libraries for a convenient object-based representation of XML, using Element objects as both argument and return type. A simple implementation of this interface for updating planetary data is given in listing 5.16.
Listing 5.16. PlanetUpdateCommandProcessor.java
public class PlanetUpdateCommandProcessor
implements XMLCommandProcessor {
public Element processXML(Element el) {
Element result=new Element("command"); Create XML result node
String id=el.getAttributeValue("id");
result.setAttribute("id",id);
String status=null;
String reason=null;
String planetId=el.getAttributeValue("planetId");
String field=el.getAttributeValue("field");
String value=el.getAttributeValue("value");
Planet planet=findPlanet(planetId); Access domain model
if (planet==null){
status="failed";
reason="no planet found for id "+planetId;
}else{
Double numValue=new Double(value);
Object[] args=new Object[]{ numValue };
String method = "set"+field.substring(0,1).toUpperCase()
+field.substring(1);
Statement statement=new Statement(planet,method,args);
try {
statement.execute(); Update domain model
status="ok";
} catch (Exception e) {
status="failed";
reason="unable to set value "+value+" for field "+field;
}
}
result.setAttribute("status",status);
if (reason!=null){
result.setAttribute("reason",reason);
}
return result;
}
private Planet findPlanet(String planetId) {
// TODO use hibernate Use ORM for domain model
return null;
}
}
As well as using JDOM to parse the incoming XML, we use it here to generate XML, building up a root node ![]() and its children programmatically in the processXML() method. We access the server-side domain model using the findPlanet() method
and its children programmatically in the processXML() method. We access the server-side domain model using the findPlanet() method ![]() , once we have a unique ID to work with. findPlanet() isn’t implemented here, for the sake of brevity—typically an ORM such as Hibernate would be used to talk to the database
behind the scenes
, once we have a unique ID to work with. findPlanet() isn’t implemented here, for the sake of brevity—typically an ORM such as Hibernate would be used to talk to the database
behind the scenes ![]() . We use reflection to update the domain model
. We use reflection to update the domain model ![]() and then return the JDOM object that we have constructed, where it will be serialized by the servlet.
and then return the JDOM object that we have constructed, where it will be serialized by the servlet.
This provides a sketch of the complete lifecycle of our queue-based architecture for combining many small domain model updates into a single HTTP transaction. It combines the ability to execute fine-grained synchronization between the client and server domain models with the need to manage server traffic effectively. As we noted in section 5.3, it may provide a solution for JSF and similar frameworks, in which the structure of the user interface and interaction model is held tightly by the server. In our case, though, it simply provides an efficient way of updating the domain models across the tiers.
This concludes our tour of client/server communication techniques for this chapter and our overview of key design issues for Ajax applications. Along the way, we’ve developed the start of a pattern language for Ajax server requests and a better understanding of the technical options available to us for implementing these.
5.6. Summary
We began this chapter by looking at the key roles of the application server in Ajax, of delivering the client code to the browser, and supplying the client with data once it is running. We looked at the common implementation languages on the server side and took a tour of the common types of server-side frameworks of the day. These are largely designed to serve classic web applications, and we considered how they can adapt to Ajax. The server-side framework space is crowded and fast moving, and rather than looking at particular products, we categorized in terms of generic architectures. This reduced the field to three main approaches: the Model2 frameworks, component-based frameworks, and service-oriented architectures. SOA seems to provide the most natural fit for Ajax, although the others can be adapted with varying degrees of success. We looked at how to enforce good separation of concerns in an SOA by introducing Façades.
Moving down to the fine-grained details, we contrasted three approaches to fetching data from the server, which we labeled as content-centric, script-centric, and data-centric. These form a continuum, with classic web applications tending heavily toward the content-centric style and Ajax toward a data-centric style. In discussing data-centric approaches, we discovered that there is life beyond XML, and we took a look at JSON as a means of transmitting data to the client.
Finally, we described ways of sending updates to the server, using HTML forms and the XMLHttpRequest object. We also considered bandwidth management using a client-side queue of Command objects. This sort of technique can give a significant performance boost by reducing both server load and network traffic, and it is in keeping with what we have observed about best practice in SOA, moving from an RPC-style approach toward a document-based communication strategy.
This chapter concludes our coverage of the core techniques of Ajax. We’ve now covered all the basics and touched on quite a few advanced topics along the way. In the following three chapters we return to the theme of usability and add some polish to the technical wizardry that we’ve accomplished here, in order to highlight key issues that can differentiate a clever hack from something that the lay user will actually want to use.
5.7. Resources
Several web frameworks were discussed in this chapter. Here are the URLs:
- Struts (http://struts.apache.org)
- Tapestry (http://jakarta.apache.org/tapestry/)
- JSF (http://java.sun.com/j2ee/javaserverfaces/faq.html)
- PHP-MVC (www.phpmvc.net)
There are over 60 web frameworks for Java alone listed by the Wicket developers: (http://wicket.sourceforge.net/Introduction.html).
JSF is a broad category covering many individual frameworks and products. Kito Mann, author of JavaServer Faces in Action (Manning, 2004), maintains the definitive portal site for all things JSF at www.jsfcentral.com/. Greg Murray and colleagues of Sun’s Blueprints catalog discuss Ajax and JSF at https://bpcatalog.dev.java.net/nonav/ajax/jsf-ajax/frames.html. AjaxFaces is a commercial Ajax-enabled JSF implementation (www.ajaxfaces.com), and Apache’s Open Source MyFaces is looking at Ajax, too (http://myfaces.apache.org/sandbox/inputSuggestAjax.html).
Microsoft’s Atlas is still under development at the time of writing, but early releases are expected later this year (2005). Scott Guthrie is Project Manager of Atlas. His blog can be found at http://weblogs.asp.net/scottgu/archive/2005/06/28/416185.aspx.
You can find JSON-RPC libraries for a range of programming languages at www.json-rpc.org/impl.xhtml.