
Chapter 3. Introducing order to Ajax
This chapter covers
- Developing and maintaining large Ajax client codebases
- Refactoring Ajax JavaScript code
- Exploring common design patterns used in Ajax applications
- Using Model-View-Controller on the server side of an Ajax app
- Overview of third-party Ajax libraries
In chapter 2, we covered all the basic technologies that make up an Ajax application. With what we’ve learned so far, it’s possible to build that super-duper Ajax-powered web application that you’ve always dreamed of. It’s also possible to get into terrible trouble and end up with a tangle of code, HTML markup, and styling that is impossible to maintain and that mysteriously stops working one day. Or worse, you end up with an application that continues to work so long as you don’t breathe near it or make a sudden loud noise. To be in such a situation on a personal project can be disheartening. To be in such a situation with an employer’s or paying customer’s site—someone who wants a few tweaks here and there—can be positively frightening.
Fortunately, this problem has been endemic since the dawn of computing—and probably before that! People have developed ways to manage complexity and to keep increasingly large codebases in working order. In this chapter, we’ll introduce the core tools for keeping on top of your code, allowing you to write and rewrite your Ajax application to your customer’s heart’s content, and still go home from work on time.
Ajax represents a break from the previous use of DHTML technologies not only in the way the technologies are put together but also in the scale at which they are used. We’re dealing with much more JavaScript than a classic web application would, and the code will often be resident in the browser for a much longer time. Consequently, Ajax needs to manage complexity in a way that classic DHTML doesn’t.
In this chapter, we’ll give an overview of the tools and techniques that can help you keep your code clean. These techniques are most useful, in our experience, when developing large, complex Ajax applications. If you want to write only simple Ajax applications, then we suggest you skip ahead to the example-driven chapters, starting with chapter 9. If you already know refactoring and design patterns back to front, then you may wish to skim this chapter and move on to the application of these techniques to Ajax in chapters 4 through 6. Even so, the groundwork that we lay here is important in adapting these approaches to JavaScript, so we expect you’ll return here at some point. We also take the opportunity at the end of this chapter to review the current state of third-party libraries for Ajax, so if you’re shopping for frameworks to streamline your project, you may want to check out section 3.5.
3.1. Order out of chaos
The main tool that we will apply is refactoring, the process of rewriting code to introduce greater clarity rather than to add new functionality. Introducing greater clarity can be a satisfying end in itself, but it also has some compelling advantages that should appeal to the bottom-line, when-the-chips-are-down mentality.
It is typically easier to add new functionality to well-factored code, to modify its existing functionality, and to remove functionality from it. In short, it is understandable. In a poorly factored codebase, it is often the case that everything does what the current requirements specify, but the programming team isn’t fully confident as to why it all works.
Changing requirements, often with short time frames, are a regular part of most professional coding work. Refactoring keeps your code clean and maintainable and allows you to face—and implement—changes in requirements without fear.
We already saw some elementary refactoring at work in our examples in chapter 2, when we moved the JavaScript, HTML, and stylesheets into separate files. However, the JavaScript is starting to get rather long at 120 lines or so and is mixing together low-level functionality (such as making requests to the server) with code that deals specifically with our list object. As we begin to tackle bigger projects, this single JavaScript file (and single stylesheet, for that matter) will suffer. The goal that we’re pursuing—creating small, easily readable, easily changeable chunks of code that address one particular issue—is often called separation of responsibilities.
Refactoring often has a second motive, too, of identifying common solutions and ways of doing things and moving code toward that particular pattern. Again, this can be satisfying in its own right, but it has a very practical effect. Let’s consider this issue next.
3.1.1. Patterns: creating a common vocabulary
Code conforming to any well-established pattern stands a good chance of working satisfactorily, simply because it’s been done before. Many of the issues surrounding it have already been thought about and, we hope, addressed. If we’re lucky, someone’s even written a reusable framework exemplifying a particular way of doing things.
This way of doing things is sometimes known as a design pattern. The concept of patterns was coined in the 1970s to describe solutions to architectural and planning problems, but it has been borrowed by software development for the last ten years or so. Server-side Java has a strong culture of design patterns, and Microsoft has recently been pushing them strongly for the .NET Framework. The term often carries a rather forbidding academic aura and is frequently misused in an effort to sound impressive. At its root, though, a design pattern is simply a description of a repeatable way of solving a particular problem in software design. It’s important to note that design patterns give names to abstract technical solutions, making them easier to talk about and easier to understand.
Design patterns can be important to refactoring because they allow us to succinctly describe our intended goal. To say that we “pull out these bits of code into objects that encapsulate the process of performing a user action, and can then undo everything if we want” is quite a mouthful—and rather a wordy goal to have in mind while rewriting the code. If we can say that we are introducing the Command pattern to our code, we have a goal that is both more precise and easier to talk about.
If you’re a hardened Java server developer, or an architect of any hue, then you’re probably wondering what’s new in what we’ve said. If you’ve come from the trenches of the web design/new media world, you may be thinking that we’re those weird sorts of control freaks who prefer drawing diagrams to writing real code. In either case, you may be wondering what this has to do with Ajax. Our short answer is “quite a lot.” Let’s explore what the working Ajax programmer stands to gain from refactoring.
3.1.2. Refactoring and Ajax
We’ve already noted that Ajax applications are likely to use more JavaScript code and that the code will tend to be longer lived.
In a classic web app, the complex code lives on the server, and design patterns are routinely applied to the PHP, Java, or .NET code that runs there. With Ajax, we can look at using the same techniques with the client code.
There is even an argument for suggesting that JavaScript needs this organization more than its rigidly structured counterparts Java and C#. Despite its C-like syntax, JavaScript is a closer cousin to languages such as Ruby, Python, and even Common Lisp than it is to Java or C#. It offers a tremendous amount of flexibility and scope for developing personal styles and idioms. In the hands of a skilled developer, this can be wonderful, but it also provides much less of a safety net for the average programmer. Enterprise languages such as Java and C# are designed to work well with teams of average programmers and rapid turnover of members. JavaScript is not.
The danger of creating tangled, unfathomable JavaScript code is relatively high, and as we scale up its use from simple web page tricks to Ajax applications, the reality of this can begin to bite. For this reason, I advocate the use of refactoring in Ajax more strongly than I do in Java or C#, the “safe” languages within whose communities design patterns have bloomed.
3.1.3. Keeping a sense of proportion
Before we move on, it’s important to say that refactoring and design patterns are just tools and should be used only where they are actually going to be useful. If overused, they can induce a condition known as paralysis by analysis, in which implementation of an application is forestalled indefinitely by design after redesign, in order to increase the flexibility of the structure or accommodate possible future requirements that may never be realized.
Design patterns expert Erich Gamma summed this up nicely in a recent interview (see Resources at end of chapter) in which he described a call for help from a reader who had managed to implement only 21 of the 23 design patterns described in the seminal Design Patterns book into his application. Just as a developer wouldn’t struggle to make use of integers, strings, and arrays in every piece of code that he writes, a design pattern is useful only in particular situations.
Gamma recommends refactoring as the best way to introduce patterns. Write the code first in the simplest way that works, and then introduce patterns to solve common problems as you encounter them. If you’ve already written a lot of code, or are charged with maintaining someone else’s tangled mess, you may have been experiencing a sinking, left-out-of-the-party feeling until now. Fortunately, it’s possible to apply design patterns retroactively to code of any quality. In the next section, we’ll take some of the rough-and-ready code that we developed in chapter 2 and see what refactoring can do for it.
3.1.4. Refactoring in action
This refactoring thing might sound like a good idea, but the more practical-minded among you will want to see it working before you buy in. Let’s take a few moments now to apply a bit of refactoring to the core Ajax functionality that we developed in the previous chapter, in listing 2.11. To recap the structure of that code, we had defined a sendRequest() function that fired off a request to the server. sendRequest() delegated to an initHttpRequest() function to find the appropriate XMLHttpRequest object and assigned a hard-coded callback function, onReadyState(), to process the response. The XMLHttpRequest object was defined as a global variable, allowing the callback function to pick up a reference to it. The callback handler then interrogated the state of the request object and produced some debug information.
The code in listing 2.11 does what we needed it to but is somewhat difficult to reuse. Typically when we make a request to the server, we want to parse the response and do something quite specific to our application with the results. To plug custom business logic into the current code, we need to modify sections of the onReadyState() function.
The presence of the global variable is also problematic. If we want to make several calls to the server simultaneously, then we must be able to assign different callback handlers to each. If we’re fetching a list of resources to update and another list of resources to discard, it’s important that we know which is which, after all!
In object-oriented (OO) programming, the standard solution to this sort of issue is to encapsulate the required functionality into an object. JavaScript supports OO coding styles well enough for us to do that. We’ll call our object ContentLoader, because it loads content from the server. So what should our object look like? Ideally, we’d be able to create one, passing in a URL to which the request will be sent. We should also be able to pass a reference to a custom callback handler to be executed if the document loads successfully and another to be executed in case of errors. A call to the object might look like this:
var loader=new net.ContentLoader('mydata.xml',parseMyData);
where parseMyData is a callback function to be invoked when the document loads successfully. Listing 3.1 shows the code required to implement the ContentLoader object. There are a few new concepts here, which we’ll discuss next.
Listing 3.1. ContentLoader object


The first thing to notice about the code is that we define a single global variable net ![]() and attach all our other references to that. This minimizes the risk of clashes in variable names and keeps all the code
related to network requests in a single place.
and attach all our other references to that. This minimizes the risk of clashes in variable names and keeps all the code
related to network requests in a single place.
We provide a single constructor function for our object ![]() . It has three arguments, but only the first two are mandatory. In the case of the error handler, we test for null values and provide a sensible default if necessary. The ability to pass a varying number of arguments to a function might
look odd to OO programmers, as might the ability to pass functions as first-class references. These are common features of JavaScript.
We discuss these language features in more detail in appendix B.
. It has three arguments, but only the first two are mandatory. In the case of the error handler, we test for null values and provide a sensible default if necessary. The ability to pass a varying number of arguments to a function might
look odd to OO programmers, as might the ability to pass functions as first-class references. These are common features of JavaScript.
We discuss these language features in more detail in appendix B.
We have moved large parts of our initXMLHttpRequest() ![]() and sendRequest() functions
and sendRequest() functions ![]() from listing 2.11 into the object’s internals. We’ve also renamed the function to reflect its slightly greater scope here as well. It is now
known as loadXMLDoc.
from listing 2.11 into the object’s internals. We’ve also renamed the function to reflect its slightly greater scope here as well. It is now
known as loadXMLDoc. ![]() We still use the same techniques to find an XMLHttpRequest object and to initiate a request, but the user of the object doesn’t
need to worry about it. The onReadyState callback function
We still use the same techniques to find an XMLHttpRequest object and to initiate a request, but the user of the object doesn’t
need to worry about it. The onReadyState callback function ![]() should also look largely familiar from listing 2.11. We have replaced the calls to the debug console with calls to the onload and onerror functions. The syntax might look a little odd, so let’s examine it a bit closer. onload and onerror are Function objects, and Function.call() is a method of that object. The first argument to Function.call() becomes the context of the function, that is, it can be referenced within the called function by the keyword this.
should also look largely familiar from listing 2.11. We have replaced the calls to the debug console with calls to the onload and onerror functions. The syntax might look a little odd, so let’s examine it a bit closer. onload and onerror are Function objects, and Function.call() is a method of that object. The first argument to Function.call() becomes the context of the function, that is, it can be referenced within the called function by the keyword this.
Writing a callback handler to pass into our ContentLoader is quite simple, then. If we need to refer to any of the ContentLoader’s properties, such as the XMLHttpRequest or the url, we can simply use this to do so. For example:
function myCallBack(){
alert(
this.url
+" loaded! Here's the content:
"
+this.req.responseText
);
}
Setting up the necessary “plumbing” requires some understanding of JavaScript’s quirks, but once the object is written, the end user doesn’t need to worry about it.
This situation is often a sign of good refactoring. We’ve tucked away the difficult bits of code inside the object while presenting an easy-to-use exterior. The end user is saved from a lot of unnecessary difficulty, and the expert responsible for maintaining the difficult code has isolated it into a single place. Fixes need only be applied once, in order to be rolled out across the codebase.
We’ve covered the basics of refactoring and shown how it can work to our benefit in practice. In the next section, we’ll look at some more common problems in Ajax programming and see how we can use refactoring to address them. Along the way, we will discover some useful tricks that we can reuse in subsequent chapters and that you can apply to your own projects as well.
3.2. Some small refactoring case studies
The following sections address some issues in Ajax development and look at some common solutions to them. In each case, we’ll show you how to refactor to ease the pain associated with that issue, and then we’ll identify the elements of the solution that can be reused elsewhere.
In keeping with an honorable tradition in design patterns literature, we will present each issue in terms of a problem, the technical solution, and then a discussion of the larger issues involved.
3.2.1. Cross-browser inconsistencies: Façade and Adapter patterns
If you ask any web developers—be they coders, designers, graphics artists, or allrounders—for their pet peeves in relation to their work, there’s a good chance that getting their work to display correctly on different browsers will be on their list. The Web is full of standards for technology, and most browser vendors implement most of the standards more or less completely most of the time. Sometimes the standards are vague and open to different interpretations, sometimes the browser vendors extended the standards in useful but inconsistent ways, and sometimes the browsers just have good old-fashioned bugs in them.
JavaScript coders have resorted since the early days to checking in their code which browser they’re using or to testing whether or not an object exists. Let’s take a very simple example.
Working with DOM elements
As we discussed in chapter 2, a web page is exposed to JavaScript through the Document Object Model (DOM), a tree-like structure whose elements correspond to the tags of an HTML document. When manipulating a DOM tree programmatically, it is quite common to want to find out an element’s position on the page. Unfortunately, browser vendors have provided various nonstandard methods for doing so over the years, making it difficult to write fail-safe cross-browser code to accomplish the task. Listing 3.2—a simplified version of a function from Mike Foster’s x library (see section 3.5)—shows a comprehensive way of discovering the pixel position of the left edge of the DOM element e passed in as an argument.
Listing 3.2. getLeft() function
function getLeft(e){
if(!(e=xGetElementById(e))){
return 0;
}
var css=xDef(e.style);
if (css && xStr(e.style.left)) {
iX=parseInt(e.style.left);
if(isNaN(iX)) iX=0;
}else if(css && xDef(e.style.pixelLeft)) {
iX=e.style.pixelLeft;
}
return iX;
}
Different browsers offer many ways of determining the position of the node via the style array that we encountered in chapter 2. The W3C CSS2 standard supports a property called style.left, defined as a string describing value and units, such as 100px. Units other than pixels may be supported. style.pixelLeft, in contrast, is numeric and assumes all values to be measured in pixels. pixelLeft is supported only in Microsoft Internet Explorer. The getLeft() method discussed here first checks that CSS is supported and then tests both values, trying the W3C standard first. If no values are found, then a value of zero is returned by default. Note that we don’t explicitly check for browser names or versions but use the more robust object-detection technique that we discussed in chapter 2.
Writing functions like these to accommodate cross-browser peculiarities is a tedious business, but once it is done, the developer can get on with developing the application without having to worry about these issues. And with well-tested libraries such as x, most of the hard work has already been done for us. Having a reliable adapter function for discovering the on-page position of a DOM element can speed up the development of an Ajax user interface considerably.
Making requests to the server
We’ve already come across another similar cross-browser incompatibility in chapter 2. Browser vendors have provided nonstandard mechanisms for obtaining the XMLHttpRequest object used to make asynchronous requests to the server. When we wanted to load an XML document from the server, we needed to figure out which of the possibilities to use.
Internet Explorer will only deliver the goods if we ask for an ActiveX component, whereas Mozilla and Safari will play nice if we ask for a native built-in object. Only the XML loading code itself knew about those differences. Once the XMLHttpRequest object was returned into the rest of the code, it behaved identically in both cases. Calling code doesn’t need to understand either the ActiveX or the native object subsystem; it only needs to understand the net.ContentLoader() constructor.
The Façade pattern
For both getLeft() and new net.ContentLoader(), the code that does the object detection is ugly and tedious. By defining a function to hide it from the rest of our code, we are making the rest of the code easier to read and isolating the object-detection code in a single place. This is a basic principle in refactoring—don’t repeat yourself, often abbreviated to DRY. If we discover an edge case that our object-detection code doesn’t handle properly, then fixing it once rolls that change out to all calls to discover the left coordinate of a DOM element, create an XML Request object, or whatever else we are trying to do.
In the language of design patterns, we are using a pattern known as Façade. Façade is a pattern used to provide a common access point to different implementations of a service or piece of functionality. The XMLHttpRequest object, for example, offers a useful service, and our application doesn’t really care how it is delivered as long as it works (figure 3.1).
Figure 3.1. Schematic of the Façade pattern, as it relates to the XMLHttpRequest object across browsers. The loadXML() function requires an XMLHttpRequest object, but doesn’t care about its actual implementation. Underlying implementations may offer considerably more complex HTTP Request semantics, but both are simplified here to provide the basic functionality required by the calling function.

In many cases, we also want to simplify access to a subsystem. In the case of getting the left-edge coordinate of a DOM element, for example, the CSS spec provided us with a plethora of choices, allowing the value to be specified in pixels, points, ems, and other units. This freedom of expression may be more than we need. The getLeft() function in listing 3.2 will work as long as we are using pixels as the unit throughout our layout system. Simplifying the subsystem in this way is another feature of the Façade pattern.
The Adapter pattern
A closely related pattern is Adapter. In Adapter, we also work with two subsystems that perform the same function, such as the Microsoft and Mozilla approaches to getting an XMLHttpRequest object. Rather than constructing a new Façade for each to use, as we did earlier, we provide an extra layer over one of the subsystems that presents the same API as the other subsystem. This layer is known as the Adapter. The Sarissa XML library for Ajax, which we will discuss in section 3.5.1, uses the Adapter pattern to make Internet Explorer’s ActiveX control look like the Mozilla built-in XMLHttpRequest. Both approaches are valid and can help to integrate legacy or third-party code (including the browsers themselves) into your Ajax project.
Let’s move on to the next case study, in which we consider issues with JavaScript’s event-handling model.
3.2.2. Managing event handlers: Observer pattern
We can’t write very much Ajax code without coming across event-based programming techniques. JavaScript user interfaces are heavily event-driven, and the introduction of asynchronous requests with Ajax adds a further set of callbacks and events for our application to deal with. In a relatively simple application, an event such as a mouse click or the arrival of data from the server can be handled by a single function. As an application grows in size and complexity, though, we may want to notify several distinct subsystems and even to expose a mechanism whereby interested parties can sign themselves up for such notification. Let’s explore an example to see what the issues are.
Using multiple event handlers
It’s common practice when scripting DOM nodes using JavaScript to define the script in the window.onload function, which is executed after the page (and therefore the DOM tree) is fully loaded. Let’s say that we have a DOM element on our page that will display dynamically generated data fetched from the server at regular intervals once the page is loaded. The JavaScript that coordinates the data fetching and the display needs a reference to the DOM node, so it gets it by defining a window.onload event:
window.onload=function(){
displayDiv=document.getElementById('display'),
}
All well and good. Let’s say that we now want to add a second visual display that provides alerts from a news feed, for example (see chapter 13 if you’re interested in implementing this functionality). The code that controls the news feed display also needs to grab references to some DOM elements on startup. So it defines a window.onload event handler, too:
window.onload=function(){
feedDiv=document.getElementById('feeds'),
}
We test both sets of code on separate pages and find them both to work fine. When we put them together, the second window.onload function overwrites the first, and the data feed fails to display and starts to generate JavaScript errors. The problem lies in the fact that the window object allows only a single onload function to be attached to it.
Limitations of a composite event handler
Our second event handler overrides the first one. We can get around this by writing a single composite function:
window.onload=function(){
displayDiv=document.getElementById('display'),
feedDiv=document.getElementById('feeds'),
}
This works for our current example, but it tangles together code from the data display and the news feed viewer, which are otherwise unrelated to each other. If we were dealing with 10 or 20 systems rather than 2, and each needed to get references to several DOM elements, then a composite event handler like this would become hard to maintain. Swapping individual components in and out would become difficult and error prone, leading to exactly the sort of situation that we described in the introduction, where nobody wants to touch the code in case it should break. Let’s try to refactor a little further, by defining a loader function for each subsystem:
window.onload=function(){
getDisplayElements();
getFeedElements();
}
function getDisplayElements(){
displayDiv=document.getElementById('display'),
}
function getFeedElements(){
feedDiv=document.getElementById('feeds'),
}
This introduces some clarity, reducing our composite window.onload() to a single line for each subsystem, but the composite function is still a weak point in the design and is likely to cause us trouble. In the following section, we’ll examine a slightly more complex but more scalable solution to the problem.
The Observer pattern
It can be helpful sometimes to ask where the responsibility for an action lies. The composite function approach places responsibility for getting the references to DOM elements on the window object, which then has to know which subsystems are present in the current page. Ideally, each subsystem should be responsible for acquiring its own references. That way, if it is present on a page, it will get them, and if it isn’t present, it won’t.
To set the division of responsibility straight, we can allow systems to register for notification of the onload event happening by passing a function to call when the window.onload event is fired. Here’s a simple implementation:
window.onloadListeners=new Array();
window.addOnLoadListener(listener){
window.onloadListeners[window.onloadListeners.length]=listener;
}
When the window is fully loaded, then the window object need only iterate through its array of listeners and call each one in turn:
window.onload=function(){
for(var i=0;i<window.onloadListeners.length;i++){
var func=window.onlloadListeners[i];
func.call();
}
}
Provided that every subsystem uses this approach, we can offer a much cleaner way of setting up all the subsystems without tangling them up in one another. Of course, it takes only one rogue piece of code to directly override window.onload and the system will break. But we have to take charge of our codebase at some point to prevent this from happening.
It’s worth pointing out here that the newer W3C event model also implements a multiple event handler system. We’ve chosen to build our own here on top of the old JavaScript event model because implementations of the W3C model aren’t consistent across browsers. We discuss this in greater detail in chapter 4.
The design pattern into which our code here is refactored is called Observer. Observer defines an Observable object, in our case the built-in window object, and a set of Observers or Listeners that can register themselves with it (figure 3.2).
Figure 3.2. Division of responsibility in the Observer pattern. Objects wishing to be notified of an event, the Observers, can register and unregister themselves with the event source, Observable, which will notify all registered parties when an event occurs.
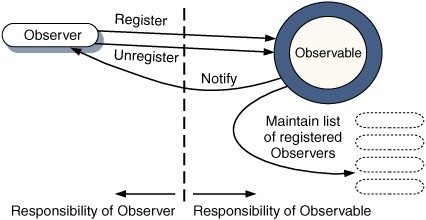
With the Observer pattern, responsibility is apportioned appropriately between the event source and the event handler. Handlers take responsibility for registering and unregistering themselves. The event source takes responsibility for maintaining a list of registered parties and firing notifications when the event occurs. The pattern has a long history of use in event-driven UI programming, and we’ll return to Observer when we discuss JavaScript events in more detail in chapter 4. And, as we’ll see, it can also be used in our own code objects independently of the browser’s mouse and key event processing.
For now, let’s move on to the next recurring issue that we can solve through refactoring.
3.2.3. Reusing user action handlers: Command pattern
It may be obvious to say that in most applications, the user is telling (through mouse clicks and keyboard presses) the app to do something, and the app then does it. In a simple program, we might present the user with only one way to perform an action, but in more complex interfaces, we will often want the user to be able to trigger the same action from several routes.
Implementing a button widget
Let’s say that we have a DOM element styled to look like a button widget that performs a calculation when pressed and updates an HTML table with the result. We could define a mouse-click event-handler function for the button element that looks like this:
function buttonOnclickHandler(event){
var data=new Array();
data[0]=6;
data[1]=data[0]/3;
data[2]=data[0]*data[1]+7;
var newRow=createTableRow(dataTable);
for (var i=0;i<data.length;i++){
createTableCell(newRow,data[i]);
}
}
We’re assuming here that the variable dataTable is a reference to an existing table and that the functions createTableRow() and createTableCell() take care of the details of DOM manipulation for us. The interesting thing here is the calculation phase, which could, in a real-world application, run to hundreds of lines of code. We assign this event handler to the button element like so:
buttonDiv.onclick=buttonOnclickHandler;
Supporting multiple event types
Let’s say that we have now supercharged our application with Ajax. We are polling the server for updates, and we want to perform this calculation if a particular value is updated from the server, too, and update a different table with the data. We don’t need to go into the details of setting up a repeated polling of the server here. Let’s assume that we have a reference to an object called poller. Internally, it is using an XMLHttpRequest object and has set its onreadystatechange handler to call an onload function whenever it has finished loading an update from the server. We could abstract out the calculation and display phases into helper functions, like this:
function buttonOnclickHandler(event){
var data=calculate();
showData(dataTable,data);
}
function ajaxOnloadHandler(){
var data=calculate();
showData(otherDataTable,data);
}
function calculate(){
var data=new Array();
data[0]=6;
data[1]=data[0]/3;
data[2]=data[0]*data[1]+7;
return data;
}
function showData(table,data){
var newRow=createTableRow(table);
for (var i=0;i<data.length;i++){
createTableCell(newRow,data[i]);
}
}
buttonDiv.onclick=buttonOnclickHandler;
poller.onload=ajaxOnloadHandler;
A lot of the common functionality has been abstracted out into the calculate() and showData() functions, and we’re only repeating ourselves a little in the onclick and onload handlers.
We’ve achieved a much better separation between the business logic and the UI updates. Once again, we’ve stumbled upon a useful repeatable solution. This time it is known as the Command pattern. The Command object defines some activity of arbitrary complexity that can be passed around in code easily and swapped between UI elements easily. In the classic Command pattern for object-oriented languages, user interactions are wrapped up as Command objects, which typically derive from a base class or interface. We’ve solved the same problem in a slightly different way here. Because JavaScript functions are first-class objects, we can treat them as Command objects directly and still provide the same level of abstraction.
Wrapping up everything that the user does as a Command might seem a little cumbersome, but it has a hidden payoff. When all our user actions are wrapped up in Command objects, we can easily associate other standard functionality with them. The most commonly discussed extension is to add an undo() method. When this is done, the foundations for a generic undo facility across an application are laid. In a more complex example, Commands could be recorded in a stack as they execute, and the user can use the undo button to work back up the stack, returning the application to previous states (figure 3.3).
Figure 3.3. Using the Command pattern to implement a generic undo stack in a word processing application. All user interactions are represented as commands, which can be undone as well as executed.

Each new command is placed on the top of the stack, which may be undone item by item. The user creates a document by a series of write actions. Then she selects the entire document and accidentally hits the delete button. When she invokes the undo function, the topmost item is popped from the stack, and its undo() method is called, returning the deleted text. A further undo would deselect the text, and so on.
Of course, using Command to create an undo stack means some extra work for the developer, in ensuring that the combination of executing and undoing the command returns the system to its initial state. A working undo feature can be a strong differentiator between products, however, particularly for applications that enjoy heavy or prolonged use. As we discussed in chapter 1, that’s exactly the territory that Ajax is moving into.
Command objects can also be useful when we need to pass information across boundaries between subsystems in an application. The network, of course, is just such a boundary, and we’ll revisit the Command pattern in chapter 5, when we discuss client/server interactions.
3.2.4. Keeping only one reference to a resource: Singleton pattern
In some situations, it is important to ensure that there is only one point of contact with a particular resource. Again, this is best explained by working with a specific example, so let’s look at one now.
A simple trading example
Let’s say that our Ajax application manipulates stock market data, allowing us to trade on the real markets, perform what-if calculations, and run simulation games over a network against other users. We define three modes for our application, named after traffic lights. In real-time mode (green mode), we can buy and sell stocks on live markets, when they are open, and perform what-if calculations against stored datasets. When the markets are closed, we revert to analysis-only mode (red mode) and can still perform the what-if analyses, but we can’t buy or sell. In simulation mode (amber mode), we can perform all the actions available to green mode, but we do so against a dummy dataset rather than interacting with real stock markets.
Our client code represents these permutations as a JavaScript object, as defined here:
var MODE_RED=1;
var MODE_AMBER=2;
var MODE_GREEN=2;
function TradingMode(){
this.mode=MODE_RED;
}
We can query and set the mode represented in this object and will do so in our code in many places. We could provide getMode() and setMode() functions that would check conditions such as whether or not the real markets were open, but for now let’s keep it simple.
Let’s say that two of the options open to the user are to buy and sell stocks and to calculate potential gains and losses from a transaction before undertaking it. The buy and sell actions will point to different web services depending on the mode of operation—internal ones in amber mode, our broker’s server in green mode—and will be switched off in red mode. Similarly, the analyses will be based on retrieving data feeds on current and recent prices—simulated in amber mode and live market data in green mode. To know which feeds to point to, both will refer to a TradingMode object as defined here (figure 3.4).
Figure 3.4. In our example Ajax trading application, both buy/sell and analysis functions determine whether to use real or simulated data based on a TradingMode object’s status, talking to the simulation server if it is in amber mode and to the live trading server in green mode. If more than one TradingMode object is present in the system, the system can end up in an inconsistent state.
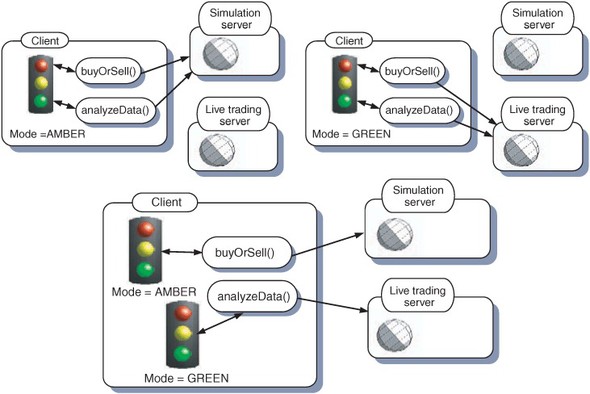
It is imperative that both activities point to the same TradingMode object. If our user is buying and selling in a simulated market but basing her decisions on analysis of live market data, she will probably lose the game. If she’s buying and selling real stocks based on analysis of a simulation, she’s apt to lose her job!
An object of which there is only one instance is sometimes described as a singleton. We’ll look at how singletons are handled in an object-oriented language first and then work out a strategy for using them in JavaScript.
Singletons in Java
Singletons are typically implemented in Java-like languages by hiding the object constructor and providing a getter method, as illustrated in listing 3.3.
Listing 3.3. Singleton TradingMode object in Java
public class TradingMode{
private static TradingMode instance=null;
public int mode;
private TradingMode(){
mode=MODE_RED;
}
public static TradingMode getInstance(){
if (instance==null){
instance=new TradingMode();
}
return instance;
}
public void setMode(int mode){
...
}
}
The Java-based solution makes use of the private and public access modifiers to enforce singleton behavior. The code
new TradingMode().setMode(MODE_AMBER);
won’t compile because the constructor is not publicly accessible, whereas the following will:
TradingMode.getInstance().setMode(MODE_AMBER);
This code ensures that every call is routed to the same TradingMode object. We’ve used several language features here that aren’t available in JavaScript, so let’s see how we can get around this.
Singletons in JavaScript
In JavaScript, we don’t have built-in support for access modifiers, but we can “hide” the constructor by not providing one. JavaScript is prototype-based, with constructors being ordinary Function objects (see appendix B if you don’t understand what this means). We could write a TradingMode object in the ordinary way:
function TradingMode(){
this.mode=MODE_RED;
}
TradingMode.prototype.setMode=function(){
}
and provide a global variable as a pseudo-Singleton:
TradingMode.instance=new TradingMode();
But this wouldn’t prevent rogue code from calling the constructor. On the other hand, we can construct the entire object manually, without a prototype:
var TradingMode=new Object();
TradingMode.mode=MODE_RED;
TradingMode.setMode=function(){
...
}
We can also define it more concisely like this:
var TradingMode={
mode:MODE_RED,
setMode:function(){
...
}
};
Both of these examples will generate an identical object. The first way of writing it is probably more familiar to Java or C# programmers. We’ve shown the latter approach as well, because it is often used in the Prototype library and in frameworks derived from it.
This solution works within the confines of a single scripting context. If the script is loaded into a separate IFrame, it will launch its own copy of the singleton. We can modify this by explicitly specifying that the singleton object be accessed from the topmost document (in JavaScript, top is always a reference to this document), as illustrated in listing 3.4.
Listing 3.4. Singleton TradingMode object in JavaScript
Function getTradingMode(){
if (!top.TradingMode){
top.TradingMode=new Object();
top.TradingMode.mode=MODE_RED;
top.TradingMode.setMode=function(){
...
}
}
return top.TradingMode;
}
This allows the script to be safely included in multiple IFrames, while preserving the uniqueness of the Singleton object. (If you’re planning on supporting a Singleton across multiple top-level windows, you’ll need to investigate top.opener. Due to constraints of space, we leave that as an exercise for the reader.)
You’re not likely to have a strong need for singletons when writing UI code, but they can be extremely useful when modeling business logic in JavaScript. In a traditional web app, business logic is typically modeled only on the server, but doing things the Ajax way changes that, and Singleton can be useful to know about.
This provides a first taste of what refactoring can do for us at a practical level. The cases that we’ve looked at so far have all been fairly simple, but even so, using refactoring to clarify the code has helped to remove several weak points that could otherwise come back to haunt us as the applications grow.
Along the way, we encountered a few design patterns. In the following section, we’ll look at a large-scale server-side pattern and see how we can refactor some initially tangled code toward a cleaner, more flexible state.
3.3. Model-View-Controller
The small patterns that we’ve looked at so far can usefully be applied to specific coding tasks. Patterns have also been developed for the organization of entire applications, sometimes referred to as architectural patterns. In this section, we’re going to look at an architectural pattern that can help us to organize our Ajax projects in several ways, making them easier to code and easier to maintain.
Model-View-Controller (MVC) is a way of describing a good separation between the part of a program that interacts with a user and the part that does the heavy lifting, number crunching, or other “business end” of the application.
MVC is typically applied at a large scale, covering entire layers of an application or even stretching between the layers. In this chapter, we introduce the pattern and show how to apply it to the web server when serving data to an Ajax application. In chapter 4, we’ll look at the rather more involved case of applying it to the JavaScript client application.
The MVC pattern identifies three roles that a component in the system can fulfill. The Model is the representation of the application’s problem domain, the thing that it is there to work with. A word processor would model a document; a mapping application would model points on a grid, contour lines, and so on.
The View is the part of the program that presents things to the user—input forms, pictures, text, or widgets. The View need not be graphical. In a voicedriven program, for example, the spoken prompts are the View.
The golden rule of MVC is that the View and the Model shouldn’t talk to each other. Taken at face value, that might sound like a pretty dysfunctional program, but this is where the Controller comes in. When the user presses a button or fills in a form, the View tells the Controller. The Controller then manipulates the Model and decides whether the changes in the Model require an update of the View. If so, it tells the View how to change itself (see figure 3.5).
Figure 3.5. The main components of the Model-View-Controller pattern. The View and Model do not interact directly but always through the Controller. The Controller can be thought of as a thin boundary layer that allows the Model and View to communicate but enforces clear separation of the codebase, improving flexibility and maintainability of the code over time.
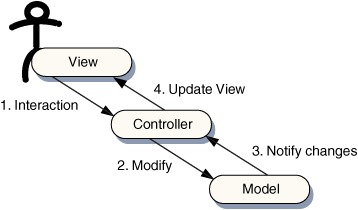
The advantage of this is that the Model and View remain loosely coupled, that is, neither has a deep understanding of the other. Obviously they need to know enough to get the job done, but the View knows about the Model only in very general terms.
Let’s consider a program for managing inventories. The Controller might provide the View with a function that returns a list of all product lines matching a given category ID, but the View knows nothing about how that list was derived. It may be that version 1 of this program stored the data used to generate the list in an array in memory or read it from a flat text file. With the second version of the program, there was a requirement to handle much larger datasets, and a relational database server was added to the architecture. The implications of this change on the Model would be significant, and a lot of code would need to be rewritten. Provided that the Controller could still deliver a list of product lines matching a category, the impact on the View code would be nil.
Similarly, the engineers working on the View should be free to improve the usability of the application without worrying about breaking hidden assumptions in the Model, so long as they stick to a basic agreement on the interfaces with which the Controller provides them. By dividing the system into subsystems, MVC provides an insurance policy against minor changes rippling right across a codebase and allows the team behind each subsystem to respond quickly without treading on one another’s toes.
The MVC pattern is commonly applied to classic web application frameworks in a particular way, in order to serve up the succession of static pages that compose the interface. When an Ajax application is up and running and requesting data from the server, the mechanics of serving up the data are similar to those of a classic web app. Web server–style MVC can also benefit Ajax applications, and because it’s well understood, we’ll start here and move on to other more Ajax-specific ways of working with MVC later.
If you’re new to web frameworks, this section should provide you with the information you need to understand how they can make an Ajax application more scalable and robust. If, on the other hand, you’re familiar with web-tier tools such as template engines and Object-Relational Mapping (ORM) tools or with frameworks such as Struts, Spring, or Tapestry, you’ll probably already know most of what we’re going to say here. In this case, you might like to skim over this section and pick up the MVC trail in chapter 4, where we discuss its use in a very different way.
3.4. Web server MVC
Web applications are no stranger to MVC, even the classic page-based variety that we spend so much time bashing in this book! The very nature of a web application enforces some degree of separation between the View and the Model, because they are on different machines. Does a web application inherently follow the MVC pattern then? Or, put another way, is it possible to write a web application that tangles the View and the Model together?
Unfortunately, it is. It’s very easy, and most web developers have probably done it at some point, the authors included.
Most proponents of MVC on the Web treat the generated HTML page, and the code that generates it, as the View, rather than what the user actually sees when that page renders. In the case of an Ajax application serving data to a JavaScript client, the View from this perspective is the XML document being returned to the client in the HTTP response. Separating the generated document from the business logic does require a little discipline, then.
3.4.1. The Ajax web server tier without patterns
To illustrate our discussion, let’s develop an example web server tier for an Ajax application. We’ve already seen the fundamentals of the client-side Ajax code in chapter 2 and section 3.1.4, and we’ll return to them in chapter 4. Right now, we’ll concentrate on what goes on in the web server. We’ll begin by coding it in the simplest way possible and gradually refactor toward the MVC pattern to see how it benefits our application in terms of its ability to respond to change. First, let’s introduce the application.
We have a list of clothes in a clothing store, which are stored in a database, and we want to query this database and present the list of items to the user, showing an image, a title, a short description, and a price. Where the item is available in several colors or sizes, we want to provide a picker for that, too. Figure 3.6 shows the main components of this system, namely the database, a data structure representing a single product, and an XML document to be transmitted to our Ajax client, listing all the products that match a query.
Figure 3.6. Main components used to generate an XML feed of product data in our online shop example. In the process of generating the view, we extract a set of results from the database, use it to populate data structures representing individual garments, and then transmit that data to the client as an XML stream.

Let’s say that the user has just entered the store and is offered a choice between Menswear, Womenswear, and Children’s clothing. Each product is assigned to one of these categories by the Category column of the database table named Garments. A simple piece of SQL to retrieve all relevant items for a search under Menswear might be
SELECT * FROM garments WHERE CATEGORY = 'Menswear';
We need to fetch the results of this query and then send them to the Ajax application as XML. Let’s see how we can do that.
Generating XML data for the client
Listing 3.5 shows a quick-and-dirty solution to this particular requirement. This example uses PHP with a MySQL database, but the important thing to note is the general structure. An ASP or JSP page, or a Ruby script, could be constructed similarly.
Listing 3.5. Quick-and-dirty generation of an XML stream from a database query

The PHP page in listing 3.5 will generate an XML page for us, looking something like listing 3.6, in the case where we have two matching products in our database. Indentation has been added for readability. We’ve chosen XML as the communication medium between client and server because it is commonly used for this purpose and because we saw in chapter 2 how to consume an XML document generated by the server using the XMLHttpRequest object. In chapter 5, we’ll explore the various other options in more detail.
Listing 3.6. Sample XML output from listing 3.5
<garments>
<garment id="SCK001" title="Golfers' Socks">
<description>Garish diamond patterned socks. Real wool.
Real itchy.</description>
<price>$5.99</price>
<colors>heather combo,hawaiian medley,wild turkey</colors>
</garment>
<garment id="HAT056" title="Deerstalker Cap">
<description>Complete with big flappy bits.
As worn by the great detective Sherlock Holmes.
Pipe is model's own.</description>
<price>$79.99</price>
<sizes>S, M, L, XL, egghead</sizes>
</garment>
</garments>
So, we have a web server application of sorts, assuming that there’s a nice Ajax front end to consume our XML. Let’s look to the future. Suppose that as our product range expands, we want to add subcategories (Smart, Casual, Outdoor, for example) and also a “search by season” function, maybe keyword searching, and a link to clearance items. All of these features could reasonably be served by a similar XML stream. Let’s look at how we might reuse our current code for these purposes and what the barriers might be.
Problems with reusability
There are several barriers to reusing our script as it stands. First, we have hardwired the SQL query into the page. If we wanted to search again by category or keyword, we would need to modify the SQL generation. We could end up with an ugly set of if statements accumulating over time as we add more search options, and a growing list of optional search parameters.
There is an even worse alternative: simply accepting a free-form WHERE clause in the CGI parameters, that is,
$sql="SELECT id,title,description,price,colors,sizes"
."FROM garments
WHERE ".$sqlWhere;
which we can then call directly from the URL, for example:
garments.php?sqlWhere=CATEGORY="Menswear"
This solution confuses the Model and the View even further, exposing raw SQL in the presentation code. It also opens the door to malicious SQL injection attacks, and, although modern versions of PHP have some built-in defenses against these, it’s foolish to rely on them.
Second, we’ve hardwired the XML data format into the page—it’s been buried in there among the printf and echo statements somewhere. There are several reasons why we might want to change the data format. Maybe we want to show an original price alongside the sale price, to try to persuade some poor sap to buy all those itchy golfing socks that we ordered!
Third, the database result set itself is used to generate the XML. This may look like an efficient way to do things initially, but it has two potential problems. We’re keeping a database connection open all the time that we are generating the XML. In this case, we’re not doing anything very difficult during that while() loop, so the connection won’t be too lengthy, but eventually it may prove to be a bottleneck. Also, it works only if we treat our database as a flat data structure.
3.4.2. Refactoring the domain model
We’re handling our lists of colors and sizes in a fairly inefficient manner at present, by storing comma-separated lists in fields in the Garments table. If we normalize our data in keeping with a good relational model, we ought to have a separate table of all available colors, and a bridging table linking garments to colors (what the database wonks call a many-to-many relationship). Figure 3.7 illustrates the use of a many-to-many relationship of this sort.
Figure 3.7. A many-to-many relationship in a database model. The table Colors lists all available colors for all garments, and the table Garments no longer lists any color information.

To determine the available colors for our deerstalker hat, we look up the Garments_to_Colors table on the foreign key garment_id. Relating the color_id column back to the primary key in the Colors table, we can see that the hat is available in shocking pink and blueberry but not battleship gray. By running the query in reverse, we could also use the Garments_to_Colors table to list all garments that match a given color.
We’re making better use of our database now, but the SQL required to fetch all the information begins to get a little hairy. Rather than having to construct elaborate join queries by hand, it would be nice to be able to treat our garments as objects, containing an array of colors and sizes.
Object-relational Mapping tools
Fortunately, there are tools and libraries that can do that for us, known as Object-Relational Mapping (ORM) tools. An ORM automatically translates between database data and in-memory objects, taking the burden of writing raw SQL off the developer. PHP programmers might like to take a look at PEAR DB_DataObject, Easy PHP Data Objects (EZPDO), or Metastorage. Java developers are relatively spoiled for choice, with Hibernate (also ported to .NET) currently a popular choice. ORM tools are a big topic, one that we’ll have to put aside for now.
Looking at our application in MVC terms, we can see that adopting an ORM has had a happy side effect, in that we have the beginnings of a genuine Model on our hands. We now can write our XML-generator routine to talk to the Garment object and leave the ORM to mess around with the database. We’re no longer bound to a particular database’s API (or its quirks). Listing 3.7 shows the change in our code after switching to an ORM.
In this case, we define the business objects (that is, the Model) for our store example in PHP, using the Pear::DB_DataObject, which requires our classes to extend a base DB_DataObject class. Different ORMs do it differently, but the point is that we’re creating a set of objects that we can talk to like regular code, abstracting away the complexities of SQL statements.
Listing 3.7. Object model for our garment store
require_once "DB/DataObject.php";
class GarmentColor extends DB_DataObject {
var $id;
var $garment_id;
var $color_id;
}
class Color extends DB_DataObject {
var $id;
var $name;
}
class Garment extends DB_DataObject {
var $id;
var $title;
var $description;
var $price;
var $colors;
var $category;
function getColors(){
if (!isset($this->colors)){
$linkObject=new GarmentColor();
$linkObject->garment_id = $this->id;
$linkObject->find();
$colors=array();
while ($linkObject->fetch()){
$colorObject=new Color();
$colorObject->id=$linkObject->color_id;
$colorObject->find();
while ($colorObject->fetch()){
$colors[] = clone($colorObject);
}
}
}
return $colors;
}
}
As well as the central Garment object, we’ve defined a Color object and a method of the Garment for fetching all Colors that it is available in. Sizes could be implemented similarly but are omitted here for brevity. Because this library doesn’t directly support many-to-many relationships, we need to define an object type for the link table and iterate through these in the getColors() method. Nonetheless, it represents a fairly complete and readable object model. Let’s see how to make use of that model in our page.
Using the revised model
We’ve generated a data model from our cleaner database structure. Now we need to use it inside our PHP script. Listing 3.8 revises our main page to use the ORMbased objects.
Listing 3.8. Revised page using ORM to talk to the database
<?php
header("Content-type: application/xml");
echo "<?xml version="1.0" encoding="UTF-8" ?>
";
include "garment_business_objects.inc"
$garment=new Garment;
$garment->category = $_GET["cat"];
$number_of_rows = $garment->find();
echo "<garments>
";
while ($garment->fetch()) {
printf("<garment id="%s" title="%s">
"
."<description>%s</description>
<price>%s</price>
",
$garment->id,
$garment->title,
$garment->description,
$garment->price);
$colors=$garment->getColors();
if (count($colors)>0){
echo "<colors>
";
for($i=0;$i<count($colors);$i++){
echo "<color>{$colors[$i]}</color>
";
}
echo "</colors>
";
}
echo "</garment>
";
}
echo "</garments>
";
?>
We include the object model definitions and then talk in terms of the object model. Rather than constructing some ad hoc SQL, we create an empty Garment object and partly populate it with our search criteria. Because the object model is included from a separate file, we can reuse it for other searches, too. The XML View is generated against the object model now as well. Our next refactoring step is to separate the format of the XML from the process of generating it.
3.4.3. Separating content from presentation
Our View code is still rather tangled up with the object, inasmuch as the XML format is tied up in the object-parsing code. If we’re maintaining several pages, then we want to be able to change the XML format in only one place and have that apply everywhere. In the more complex case where we want to maintain more than one format, say one for short and detailed listings for display to customers and another for the stock-taking application, then we want to define each format only once and provide a centralized mapping for them.
Template-based systems
One common approach to this is a template language, that is, a system that accepts a text document containing some special markup notation that acts as a placeholder for real variables during execution. PHP, ASP, and JSP are themselves templating languages of sorts, written as web page content with embedded code, rather than the code with embedded content seen in a Java servlet or traditional CGI script. However, they expose the full power of the scripting language to the page, making it easy to tangle up business logic and presentation.
In contrast, purpose-built template languages, such as PHP Smarty and Apache Velocity (a Java-based system, ported to .NET as NVelocity), offer a more limited ability to code, usually limiting control flow to simple branching (for example, if) and looping (for example, for, while) constructs. Listing 3.9 shows a PHP Smarty template for generating our XML.
Listing 3.9. PHP Smarty template for our XML output
<?xml version="1.0" encoding="UTF-8" ?>
<garments>
{section name=garment loop=$garments}
<garment id="{$garment.id}" title="{$garment.title}">
<description>{$garment.description}</description>
<price>{$garment.price}</price>
{if count($garment.getColors())>0}
<colors>
{section name=color loop=$garment.getColors()}
<color>$color->name</color>
{/section}
</colors>
{/if}
</garment>
{/section}
</garments>
The template expects to see an array variable garments, containing Garment objects, as input. Most of the template is emitted from the engine verbatim, but sections inside the curly braces are interpreted as instructions and are either substituted for variable names or treated as simple branch and loop statements. The structure of the output XML document is more clearly readable in the template than when tangled up with the code, as in the body of listing 3.7. Let’s see how to use the template from our page.
Using the revised view
We’ve moved the definition of our XML format out of our main page into the Smarty template. As a result, now the main page needs only to set up the template engine and pass in the appropriate data. Listing 3.10 shows the changes needed to do this.
Listing 3.10. Using Smarty to generate the XML
<?php
header("Content-type: application/xml");
include "garment_business_objects.inc";
include "smarty.class.php";
$garment=new DataObjects_Garment;
$garment->category = $_GET["cat"];
$number_of_rows = $garment->find();
$smarty=new Smarty;
$smarty->assign('garments',$garments);
$smarty->display('garments_xml.tpl'),
?>
Smarty is very concise to use, following a three-stage process. First, we create a Smarty engine. Then, we populate it with variables. In this case, there is only one, but we can add as many as we like—if the user details were stored in session, we could pass them in, for example, to present a personalized greeting through the template. Finally, we call display(), passing in the name of the template file.
We’ve now achieved the happy state of separating out the View from our search results page. The XML format is defined once and can be invoked in a few lines of code. The search results page is tightly focused, containing only the information that is specific to itself, namely, populating the search parameters and defining an output format. Remember that we dreamed up a requirement earlier to be able to swap in alternative XML formats on the fly? That’s easy with Smarty; we simply define an extra format. It even supports including templates within other templates if we want to be very structured about creating minor variations.
Looking back to the opening discussion about the Model-View-Controller pattern, we can see that we’re now implementing it quite nicely. Figure 3.8 provides a visual summary of where we are.
Figure 3.8. MVC as it is commonly applied in the web application. The web page/servlet acts as the Controller and first queries the Model to get the relevant data. It then passes this data to the template file (the View), which generates the content to be forwarded to the user. Note that this is a read-only situation. If we were modifying the Model, the flow of events would differ slightly, but the roles would remain the same.
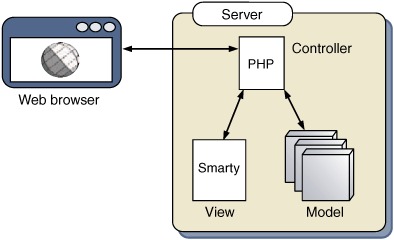
The Model is our collection of domain objects, persisted to the database automatically using our ORM. The View is the template defining the XML format. The Controller is the “search by category” page, and any other pages that we care to define, that glue the Model and the View together.
This is the classic mapping of MVC onto the web application. We’ve worked through it here in the web server tier of an Ajax application that serves XML documents, but it’s easy to see how it could also apply to a classic web application serving HTML pages.
Depending on the technologies you work with, you’ll encounter variations on this pattern, but the principle is the same. J2EE enterprise beans abstract the Model and Controller to the point where they can reside on different servers. .NET “code-behind” classes delegate the Controller role to page-specific objects, whereas frameworks such as Struts define a “front controller” that intercepts and routes all requests to the application. Frameworks such as Apache Struts have worked this down to a fine art, refining the role of the Controller to route the user between pages, as well as applying at the single-page level. (In an Ajax application, we might do this in the JavaScript.) But in all cases, the mapping is basically the same, and this is how MVC is generally understood in the web application world.
Describing our web architecture using MVC is a useful approach, and it will continue to serve us well as we move from classic to Ajax-style applications. But it isn’t the only use to which we can put MVC in Ajax. In chapter 4, we will examine a variation on the pattern that allows us to reap the advantages of structured design throughout our application. Before we do that, though, let’s look at another way of introducing order to our Ajax applications.
As well as refactoring our own code, we can often rationalize a body of code by making use of third-party frameworks and libraries. With the growing interest in Ajax, a number of useful frameworks are emerging, and we conclude this chapter with a brief review of some of the more popular ones.
3.5. Third-party libraries and frameworks
A goal of most refactoring is reducing the amount of repetition in the codebase, by factoring details out to a common function or object. If we take this to its logical conclusion, we can wrap up common functionality into libraries, or frameworks, that can be reused across projects. This reduces the amount of custom coding needed for a project and increases productivity. Further, because the library code has already been tested in previous projects, the quality can be expected to be high.
We’ll develop a few small JavaScript frameworks in this book that you can reuse in your own projects. There’s the ObjectBrowser in chapters 4 and 5, the CommandQueue in chapter 5, the notifications frameworks in chapter 6, the StopWatch profiling tools in chapter 8, and the debugging console in appendix A. We’ll also be refactoring the teaching examples in chapters 9 through 13 at the end of each chapter, to provide reusable components.
Of course, we aren’t the only people playing this game, and plenty of JavaScript and Ajax frameworks are available on the Internet, too. The more established of these have the advantage of some very thorough testing by a large pool of developers.
In this section, we’ll look at some of the third-party libraries and frameworks available to the Ajax community. There’s a lot of activity in the Ajax framework space at the moment, so we can’t cover all the contenders in detail, but we’ll try to provide you with a taste of what sort of frameworks exist and how you can introduce order into your own projects by using them.
3.5.1. Cross-browser libraries
As we noted in section 3.2.1, cross-browser inconsistencies are never far away when writing Ajax applications. A number of libraries fulfill the very useful function of papering over cross-browser inconsistencies by providing a common façade against which the developer can code. Some focus on specific pieces of functionality, and others attempt to provide a more comprehensive programming environment. We list below the libraries of this type that we have found to be helpful when writing Ajax code.
x library
The x library is a mature, general-purpose library for writing DHTML applications. First released in 2001, it superseded the author’s previous CBE (Cross-Browser Extensions) library, using a much simpler programming style. It provides cross-browser functions for manipulating and styling DOM elements, working with the browser event model, and includes out-of-the-box support libraries for animation and drag and drop. It supports Internet Explorer version 4 upward, as well as recent versions of Opera and the Mozilla browsers.
x uses a simple function-based coding style, taking advantage of JavaScript’s variable argument lists and loose typing. For example, it wraps the common document.getElementById() method, which accepts only strings as input, with a function that accepts either strings or DOM elements, resolving the element ID if a string is passed in but returning a DOM element unmodified if that is passed in as argument. Hence, xGetElementById() can be called to ensure that an argument has been resolved from ID to DOM node, without having to test whether it’s already been resolved. Being able to substitute a DOM element for its text ID is particularly useful when creating dynamically generated code, such as when passing a string to the setTimeout() method or to a callback handler.
A similarly concise style is used in the methods for manipulating DOM element styling, with the same function acting as both getter and setter. For example, the statement
xWidth(myElement)
will return the width of the DOM element myElement, where myElement is either a DOM element or the ID of a DOM element. By adding an extra argument, like so
xWidth(myElement,420)
we set the width of the element. Hence, to set the width of one element equal to another, we can write
xWidth(secondElement,xWidth(firstElement))
x does not contain any code for creating network requests, but it is nonetheless a useful library for constructing the user interfaces for Ajax applications, written in a clear, understandable style.
Sarissa
Sarissa is a more targeted library than x, and is concerned chiefly with XML manipulation in JavaScript. It supports Internet Explorer’s MSXML ActiveX components (version 3 and up), Mozilla, Opera, Konqueror, and Safari for basic functionality, although some of the more advanced features such as XPath and XSLT are supported by a smaller range of browsers.
The most important piece of functionality for Ajax developers is cross-browser support for the XMLHttpRequest object. Rather than creating a Façade object of its own, Sarissa uses the Adapter pattern to create a JavaScript-based XMLHttpRequest object on browsers that don’t offer a native object by that name (chiefly Internet Explorer). Internally, this object will make use of the ActiveX objects that we described in chapter 2, but as far as the developer is concerned, the following code will work on any browser once Sarissa has been imported:
var xhr = new XMLHttpRequest();
xhr.open("GET", "myData.xml");
xhr.onreadystatechange = function(){
if(xhr.readyState == 4){
alert(xhr.responseXML);
}
}
xhr.send(null);
Compare this code with listing 2.11 and note that the API calls are identical to those of the native XMLHttpRequest object provided by Mozilla and Safari browsers.
As noted already, Sarissa also provides a number of generic support mechanisms for working with XML documents, such as the ability to serialize arbitrary JavaScript objects to XML. These mechanisms can be useful in processing the XML documents returned from an Ajax request to the server, if your project uses XML as the markup for response data. (We discuss this issue, and the alternatives, in chapter 5.)
Prototype
Prototype is a general-purpose helper library for JavaScript programming, with an emphasis on extending the JavaScript language itself to support a more object-oriented programming style. Prototype has a distinctive style of JavaScript coding, based on these added language features. Although the Prototype code itself can be difficult to read, being far removed from the Java/C# style, using Prototype, and libraries built on top of it, is straightforward. Prototype can be thought of a library for library developers. Ajax application writers are more likely to use libraries built on top of Prototype than to use Prototype itself. We’ll look at some of these libraries in the following sections. In the meantime, a brief discussion of Prototype’s core features will help introduce its style of coding and will be useful when we discuss Scriptaculous, Rico, and Ruby on Rails.
Prototype allows one object to “extend” another by copying all of the parent object’s properties and methods to the child. This feature is best illustrated by an example. Let’s say that we define a parent class Vehicle
function Vehicle(numWheels,maxSpeed){
this.numWheels=numWheels;
this.maxSpeed=maxSpeed;
}
for which we want to define a specific instance that represents a passenger train. In our child class we also want to represent the number of carriages and provide a mechanism for adding and removing them. In ordinary JavaScript, we could write
var passTrain=new Vehicle(24,100);
passTrain.carriageCount=12;
passTrain.addCarriage=function(){
this.carriageCount++;
}
passTrain.removeCarriage=function(){
this.carriageCount--;
}
This provides the required functionality for our passTrain object. Looking at the code from a design perspective, though, it does little to wrap up the extended functionality into a coherent unit. Prototype can help us here, by allowing us to define the extended behavior as an object and then extend the base object with it. First, we define the extended functionality as an object:
function CarriagePuller(carriageCount){
this.carriageCount=carriageCount;
this.addCarriage=function(){
this.carriageCount++;
}
this.removeCarriage=function(){
this.carriageCount--;
}
}
Then we merge the two to provide a single object containing all of the required behavior:
var parent=new Vehicle(24,100); var extension=new CarriagePuller(12); var passTrain=Object.extend(parent,extension);
Note that we define the parent and extension objects separately at first and then mix them together. The parent-child relationship exists between these instances, not between the Vehicle and CarriagePuller classes. While it isn’t exactly classic object orientation, it allows us to keep all the code related to a specific function, in this case pulling carriages, in one place, from which it can easily be reused. While doing so in a small example like this may seem unnecessary, in larger projects, encapsulating functionality in such a way is extremely helpful.
Prototype also provides Ajax support in the form of an Ajax object that can resolve a cross-browser XMLHttpRequest object. Ajax is extended by the Ajax.Request type, which can make requests to the server using XMLHttpRequest, like so:
var req=new Ajax.Request('myData.xml'),
The constructor uses a style that we’ll also see in many of the Prototype-based libraries. It takes an associative array as an optional argument, allowing a wide range of options to be configured as needed. Sensible default values are provided for each option, so we need only pass in those objects that we want to override. In the case of the Ajax.Request constructor, the options array allows post data, request parameters, HTTP methods, and callback handlers to be defined. A more customized invocation of Ajax.Request might look like this:
var req=new Ajax.Request(
'myData.xml',
{
method: 'get',
parameters: { name:'dave',likes:'chocolate,rhubarb' },
onLoaded: function(){ alert('loaded!'), },
onComplete: function(){
alert('done!
'+req.transport.responseText);
}
}
);
The options array here has passed in four parameters. The HTTP method is set to get, because Prototype will default to the HTTP post method. The parameters array will be passed down on the querystring, because we are using HTTP get. If we used POST, it would be passed in the request body. onLoaded and onComplete are callback event handlers that will be fired when the readyState of the underlying XMLHttpRequest object changes. The variable req.transport in the onComplete function is a reference to the underlying XMLHttpRequest object.
On top of Ajax.Request, Prototype further defines an Ajax.Updater type of object that fetches script fragments generated on the server and evaluates them. This follows what we describe as a “script-centric” pattern in chapter 5 and is beyond the scope of our discussion here.
This concludes our brief review of cross-browser libraries. Our choice of libraries has been somewhat arbitrary and incomplete. As we have noted, there is a lot of activity in this space at the moment, and we’ve had to limit ourselves to some of the more popular or well-established offerings. In the next section, we’ll look at some of the widget frameworks built on top of these and other libraries.
3.5.2. Widgets and widget suites
The libraries that we’ve discussed so far have provided cross-browser support for some fairly low-level functionality, such as manipulating DOM elements and fetching resources from the server. With these tools at our disposal, constructing functional UIs and application logic is certainly simplified, but we still need to do a lot more work than our counterparts working with Swing, MFC, or Qt, for example.
Prebuilt widgets, and even complete widget sets for Ajax developers, are starting to emerge. In this section, we’ll look at a few of these—again, more to give a flavor of what’s out there than to provide a comprehensive overview.
Scriptaculous
The Scriptaculous libraries are UI components built on top of Prototype (see the previous section). In its current form, Scriptaculous provides two major pieces of functionality, although it is being actively developed, with several other features planned.
The Effects library defines a range of animated visual effects that can be applied to DOM elements, to make them change size, position, and transparency. Effects can be easily combined, and a number of predefined secondary effects are provided, such as Puff(), which makes an element grow larger and more transparent until it fades away completely. Another useful core effect, called Parallel(), is provided to enable simultaneous execution of multiple effects. Effects can be a useful way of quickly adding visual feedback to an Ajax user interface, as we’ll see in chapter 6.
Invoking a predetermined effect is as simple as calling its constructor, passing in the target DOM element or its ID as an argument, for example:
new Effect.SlideDown(myDOMElement);
Underlying the effects is the concept of a transition object, which can be parameterized in terms of duration and event handlers to be invoked when the transition ends. Several base transition types, such as linear, sinusoidal, wobble, and pulse, are provided. Creating a custom effect is simply a matter of combining core effects and passing in suitable parameters. A detailed discussion of building custom effects is beyond the scope of this brief overview. We’ll see Scriptaculous effects in use again in chapter 6, when we develop a notifications system.
The second feature that Scriptaculous provides is a drag-and-drop library, through the Sortable class. This class takes a parent DOM element as an argument and enables drag-and-drop functionality for all its children. Options passed in to the constructor can specify callback handlers for when the item is dragged and dropped, types of child elements to be made draggable, and a list of valid drop targets (that is, elements that will accept the dragged item if the user lets go of it while mousing over them). Effect objects may also be passed in as options, to be executed when the item is first dragged, while it is in transit, and when it is dropped.
Rico
Rico, like Scriptaculous, is based on the Prototype library, and it also provides some highly customizable effects and drag-and-drop functionality. In addition, it provides a concept of a Behavior object, a piece of code that can be applied to part of a DOM tree to add interactive functionality to it. A few example Behaviors are provided, such as an Accordion widget, which nests a set of DOM elements within a given space, expanding one at a time. (This style of widget is often referred to as outlook bar, having been popularized by its use in Microsoft Outlook.)
Let’s build a simple Rico Accordion widget. Initially, we require a parent DOM element; each child of the parent will become a pane in the accordion. We define a DIV element for each panel, with two further DIVs inside that, representing the header and the body of each panel:
<div id='myAccordion'>
<div>
<div>Dictionary Definition</div>
<div>
<ul>
<li><b>n.</b>A portable wind instrument with a small
keyboard and free metal reeds that sound when air is
forced past them by pleated bellows operated by the
player.</li>
<li><b>adj.</b>Having folds or bends like the bellows
of an accordion: accordion pleats; accordion blinds.</li>
</ul>
</div>
</div>
<div>
<div>A picture</div>
<div>
<img src='monkey-accordion.jpg'></img>
</div>
</div>
</div>
The first panel provides a dictionary definition for the word accordion and the second panel a picture of a monkey playing an accordion (see figure 3.9). Rendered as it is, this will simply display these two elements one above the other. However, we have assigned an ID attribute to the top-level DIV element, allowing us to pass a reference to it to the Accordion object, which we construct like this:
var outer=$('myAccordion'),
outer.style.width='320px';
new Rico.Accordion(
outer,
{ panelHeight:400,
expandedBg:'#909090',
collapsedBg:'#404040',
}
);
Figure 3.9. The Rico framework Behaviors allow plain DOM nodes to be styled as interactive widgets, simply by passing a reference to the top-level node to the Behavior object’s constructor. In this case, the Accordion object has been applied to a set of DIV elements (left) to create an interactive menu widget (right), in which mouse clicks open and close the individual panels.
The first line looks rather curious. $ is actually a valid JavaScript variable name and simply refers to a function in the core Prototype library. $() resolves DOM nodes in a way similar to the x library’s xGetElementById() function that we discussed in the previous section. We pass a reference to the resolved DOM element to the Accordion object constructor, along with an array of options, in the standard idiom for Prototype-derived libraries. In this case, the options simply provide some styling of the Accordion widget’s visual elements, although callback handler functions to be triggered when panels are opened or closed can also be passed in here. Figure 3.9 shows the effect of styling the DOM elements using the Accordion object. Rico’s Behaviors provide a simple way of creating reusable widgets from common markup and also separate the content from the interactivity. We’ll explore the topic of applying good design principles to the JavaScript UI in chapter 4.
The final feature of the Rico framework to mention is that it provides very good support for Ajax-style requests to the server, through a global Rico AjaxEngine object. The AjaxEngine provides more than just a cross-browser wrapper around the XMLHttpRequest object. It defines an XML response format that consists of a number of <response> elements. The engine will automatically decode these, and it has built-in support for two types of response: those that directly update DOM elements and those that update JavaScript objects. We’ll look at a similar mechanism in greater detail in section 5.5.3, when we discuss client/server interactions in depth. For now, let’s move on to the next type of framework: one that spans both client and server.
3.5.3. Application frameworks
The frameworks that we have looked at so far are executed exclusively in the browser and can be served up as static JavaScript files from any web server. The final category of frameworks that we will review here are those that reside on the server and generate at least some of the JavaScript code or HTML markup dynamically.
These are the most complex of the frameworks that we are discussing here, and we won’t be able to discuss them in great detail but will give a brief overview of their features. We will return to the topic of server-side frameworks in chapter 5.
DWR, JSON-RPC, and SAJAX
We’ll begin by looking at three small server-side frameworks together, because they share a common approach, although they are written for different server-side languages. SAJAX works with a variety of server-side languages, including PHP, Python, Perl, and Ruby. DWR (which stands for Direct Web Remoting) is a Java-based framework with a similar approach, exposing methods of objects rather than standalone functions. JSON-RPC (JavaScript Object Notation-based Remote Procedure Calls) is also similar in design. It offers support for server-side JavaScript, Python, Ruby, Perl, and Java.
All three allow objects defined on the server to expose their methods directly as Ajax requests. We will frequently have a server-side function that returns a useful result that has to be calculated on the server, say, because it looks up a value from a database. These frameworks provide a convenient way to access those functions or methods from the web browser and can be a good way of exposing the server-side domain model to the web browser code.
Let’s look at an example using SAJAX, exposing functions defined on the server in PHP. We’ll use a straightforward example function that simply returns a string of text, as follows:
<?php
function sayHello(name){
return("Hello! {$name} Ajax in Action!!!!");
?>
To export this function to the JavaScript tier, we simply import the SAJAX engine into our PHP and call the sajax_export function:
<?php
require('Sajax.php'),
sajax_init();
sajax_export("sayHello");
?>
When we write our dynamic web page, then, we use SAJAX to generate some JavaScript wrappers for the exported functions. The generated code creates a local JavaScript function with identical signatures to the server-side function:
<script type='text/javascript'>
<?
sajax_show_javascript();
?>
...
alert(sayHello("Dave"));
...
</script>
When we call sayHello("Dave") in the browser, the generated JavaScript code will make an Ajax request to the server, execute the server-side function, and return the result in the HTTP response. The response will be parsed and the return value extracted to the JavaScript. The developer need not touch any of the Ajax technologies; everything is handled behind the scenes by the SAJAX libraries.
These three frameworks offer a fairly low-level mapping of server-side functions and objects to client-side Ajax calls. They automate what could otherwise be a tedious task, but they do present a danger of exposing too much server-side logic to the Internet. We discuss these issues in greater detail in chapter 5.
The remaining frameworks that we’ll look at in this section take a more sophisticated approach, generating entire UI layers from models declared on the server. Although they use standard Ajax technologies internally, these frameworks essentially provide their own programming model. As a result, working with these frameworks is quite different from writing generic Ajax, and we will be able to provide only a broad overview here.
Backbase
The Backbase Presentation Server provides a rich widget set that binds at runtime to XML tags embedded in the HTML documents generated by the server. The principle here is similar to the Rico behavior components, except that Backbase uses a custom set of XHTML tags to mark up the UI components, rather than standard HTML tags.
Backbase provides server-side implementations for both Java and .NET. It is a commercial product but offers a free community edition.
Echo2
NextApp’s Echo2 framework is a Java-based server engine that generates rich UI components from a model of the user interface that is declared on the server. Once launched in the browser, the widgets are fairly autonomous and will handle user interactions locally using JavaScript or otherwise send requests back to the server in batches using a request queue similar to the one employed by Rico.
Echo2 promotes itself as an Ajax-based solution that requires no knowledge of HTML, JavaScript, or CSS, unless you want to extend the set of components that are available. In most cases, the development of the client application is done using only Java. Echo2 is open source, licensed under a Mozilla-style license, allowing its use in commercial applications.
Ruby on Rails
Ruby on Rails is a web development framework written in the Ruby programming language. It bundles together solutions for mapping server-side objects to a database and presenting content using templates, very much in the style of the server-side MVC that we discussed in section 3.4. Ruby on Rails claims very fast development of simple to medium websites, since it uses code-generation techniques to generate a lot of common code. It also seeks to minimize the amount of configuration required to get a live application running.
In recent versions, Rails has provided strong Ajax support through the Prototype library. Prototype and Rails are a natural fit, since the JavaScript code for Prototype is generated from a Ruby program, and the programming styles are similar. As with Echo2, using Ajax with Rails does not require a strong knowledge of Ajax technologies such as JavaScript, but a developer who does understand JavaScript can extend the Ajax support in new ways.
This concludes our overview of third-party frameworks for Ajax. As we’ve already noted, this is currently a fast-moving area, and most of the frameworks that we have discussed are under active development.
Many of the libraries and frameworks have their own coding idioms and styles, too. In writing the code examples for this book, we have sought to provide a feel for the breadth of Ajax technologies and techniques and have avoided leaning too heavily on any particular framework. Nonetheless, you will encounter some of the products that we have discussed here, sprinkled lightly throughout the rest of the book.
3.6. Summary
In this chapter, we’ve introduced the concept of refactoring as a way of improving code quality and flexibility. Our first taste of refactoring was to roll up the XMLHttpRequest object—the very core of the Ajax stack—into a simple, reusable object.
We’ve looked at a number of design patterns that we can apply to solve commonly encountered problems when working with Ajax. Design patterns provide a semiformal way of capturing the knowledge of the programmers who have gone before us and can help us to refactor toward a concrete goal.
Façade and Adapter provide useful ways of smoothing over the differences between varying implementations. In Ajax, these patterns are especially useful in providing an insulating layer from cross-browser incompatibilities, a major and longstanding source of worry for JavaScript developers.
Observer is a flexible pattern for dealing with event-driven systems. We’ll return to it in chapter 4 when looking at the UI layers of our application. Used together with Command, which offers a good way of encapsulating user interactions, it is possible to develop a robust framework for handling user input and providing an undo facility. Command also has its uses in organizing client/server interactions, as we will see in chapter 5.
Singleton offers a straightforward way of controlling access to specific resources. In Ajax, we may usefully use Singleton to control access to the network, as we will see in chapter 5.
Finally, we introduced the Model-View-Controller pattern, an architectural pattern that has a long history (in Internet time, at least!) of use in web applications. We discussed how the use of MVC can improve the flexibility of a server-side application through use of an abstracted data layer and a template system.
Our garment store example also demonstrated the way in which design patterns and refactoring go hand in hand. Creating a perfectly designed piece of code the first time round is difficult, but refactoring an ugly-but-functional bit of code such as listing 3.4 to gradually bring in the benefits of design patterns is possible, and the end results are every bit as good.
Finally, we looked at third-party libraries and frameworks as another way of introducing order to an Ajax project. A number of libraries and frameworks are springing up at present, from simple cross-browser wrappers to complete widget sets to end-to-end solutions encompassing both client and server. We reviewed several of the more popular frameworks briefly, and we will return to some of them in later chapters.
In the following two chapters, we’ll apply our understanding of refactoring and design patterns to the Ajax client and then to the client/server communication system. This will help us to develop a vocabulary and a set of practices that will make it easier to develop robust and multifeatured web applications.
3.7. Resources
Martin Fowler (with coauthors Kent Beck, John Brant, William Opdyke, and Don Roberts) wrote the seminal guide to refactoring: Refactoring: Improving the Design of Existing Code (Addison-Wesley Professional, 1999).
Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides (also known as “The Gang of Four”) wrote the influential Design Patterns (Addison-Wesley Professional, 1995).
Gamma later went on to become architect for the Eclipse IDE/platform (see appendix A), and discusses both Eclipse and design patterns in this recent interview: www.artima.com/lejava/articles/gammadp.html.
Michael Mahemoff has recently set up a website devoted to cataloging Ajax design patterns: www.ajaxpatterns.org.