
Chapter 8. Performance
This chapter covers
- Profiling Ajax applications
- Managing memory footprints
- Using design patterns for consistent performance
- Handling browser-specific performance issues
In the previous three chapters, we have built up our understanding of how Ajax applications can be made robust and reliable—able to withstand real-life usage patterns and changes in requirements. Design patterns help us to keep our code organized, and the principle of separation of concerns keeps the coupling in our code low enough to allow us to respond quickly to changes without breaking things.
Of course, to make our application really useful, it also has to be able to function at a reasonable speed and without bringing the rest of our user’s computer to a grinding halt. So far, we’ve been operating in a high-tech Shangri-la in which our user’s workstations have infinite resources and web browsers know how to make use of them effectively. In this chapter, we’ll descend to the grubby side streets of the real world and look at the issue of performance. We’ll be taking our idealistic refactoring and design patterns with us. Even down here, they can provide a vocabulary—and valuable insights—into performance issues that we might encounter.
8.1. What is performance?
The performance of a computer program hinges on two factors: how fast it can run and how much of the system resources (most crucially, memory and CPU load) it takes up. A program that is too slow is frustrating to work with for most tasks. In a modern multitasking operating system, a program that makes the rest of a user’s activities grind to a halt is doubly frustrating. These are both relative issues. There is no fixed point at which execution speed or CPU usage becomes acceptable, and perception is important here, too. As programmers, we like to focus on the logic of our applications. Performance is a necessary evil that we need to keep an eye on. If we don’t, our users will certainly remind us.
Like chess, computer languages offer self-contained worlds that operate by a well-specified set of rules. Within that set of rules, everything is properly defined and fully explicable. There is a certain allure to this comfortable clockwork world, and as programmers, we can be tempted to believe that the self-contained rules fully describe the system that we’re working on to earn our daily bread. Modern trends in computer languages toward virtual machines reinforce this notion that we can write code to the spec and ignore the underlying metal.
This is completely understandable—and quite wrong. Modern operating systems and software are far too complicated to be understood in this mathematically pure way, and web browsers are no exception. To write code that can actually perform on a real machine, we need to be able to look beyond the shiny veneer of the W3C DOM spec or the ECMA-262 specification for JavaScript and come to grips with the grim realities and compromises built into the browsers that we know and love. If we don’t acknowledge these lower layers of the software stack, things can start to go wrong.
If our application takes several seconds to respond to a button being clicked or several minutes to process a form, then we are in trouble, however elegant the design of the system. Similarly, if our application needs to grab 20MB of system memory every time we ask it what the time is and lets go of only 15MB, then our potential users will quickly discard it.
JavaScript is (rightly) not known for being a fast language, and it won’t perform mathematical calculations with the rapidity of hand-tuned C. JavaScript objects are not light either, and DOM elements in particular take up a lot of memory. Web browser implementations too tend to be a little rough around the edges in many cases and prone to memory leaks of their own.
Performance of JavaScript code is especially important to Ajax developers because we are boldly going where no web programmer has gone before. The amount of JavaScript that a full-blown Ajax application needs is significantly more than a traditional web application would use. Further, our JavaScript objects may be longer lived than is usual in a classic web app, because we don’t refresh the entire page often, if at all.
In the following two sections, we’ll pursue the two pillars of performance, namely, execution speed and memory footprint. Finally, we’ll round out this chapter with a case study that demonstrates the importance of naming and understanding the patterns that a developer uses when working with Ajax and with the DOM.
8.2. JavaScript execution speed
We live in a world that values speed, in which things have to get finished yesterday. (If you don’t live in such a world, drop me a postcard, or better still, an immigration form.) Fast code is at a competitive advantage to slower code, provided that it does the job, of course. As developers of code, we should take an interest in how fast our code runs and how to improve it.
As a general rule, a program will execute at the speed of its slowest subsystem. We can time how fast our entire program runs, but having a number at the end of that won’t tell us very much. It’s much more useful if we can also time individual subsystems. The business of measuring the execution speed of code in detail is generally known as profiling. The process of creating good code, like creating good art, is never finished but just stops in interesting places. (Bad code, on the other hand, often just stops in interesting places.) We can always squeeze a little more speed out of our code by optimizing. The limiting factor is usually our time rather than our skill or ingenuity. With the help of a good profiler to identify the bottlenecks in our code, we can determine where to concentrate our efforts to get the best results. If, on the other hand, we try to optimize our code while writing it, the results can be mixed. Performance bottlenecks are rarely where one would expect them to be.
In this section, we will examine several ways of timing application code, and we’ll build a simple profiling tool in JavaScript, as well as examine a real profiler in action. We’ll then go on to look at a few simple programs and run them through the profiler to see how best to optimize them.
8.2.1. Timing your application the hard way
The simplest tool for measuring time that we have at our disposal is the system clock, which JavaScript exposes to us through the Date object. If we instantiate a Date object with no arguments, then it tells us the current time. If one Date is subtracted from another, it will give us the difference in milliseconds. Listing 8.1 summarizes our use of the Date object to time events.
Listing 8.1. Timing code with the Date object
function myTimeConsumingFunction(){
var beginning=new Date();
...
//do something interesting and time-consuming!
...
var ending=new Date();
var duration=ending-beginning;
alert("this function took "+duration
+"ms to do something interesting!");
}
We define a date at each end of the block of code that we want to measure, in this case our function, and then calculate the duration as the difference between the two. In this example, we used an alert() statement to notify us of the timing, but this will work only in the simplest of cases without interrupting the workflow that we are trying to measure. The usual approach to gathering this sort of data is to write it to a log file, but the JavaScript security model prevents us from accessing the local filesystem. The best approach available to an Ajax application is to store profiling data in memory as a series of objects, which we later render as DOM nodes to create a report.
Note that we want our profiling code to be as fast and simple as possible while the program is running, to avoid interfering with the system that we are trying to measure. Writing a variable to memory is much quicker than creating extra DOM nodes during the middle of the program flow.
Listing 8.2 defines a simple stopwatch library that we can use to profile our code. Profiling data is stored in memory while the test program runs and rendered as a report afterward.
Listing 8.2. stopwatch.js


Our stopwatch system is composed of one or more categories, each of which can time one active event at a time and maintain a list of previous timed events. When client code calls stopwatch.start() with a given ID as argument, the system will create a new StopWatch object for that category or else reuse the existing one. The client code can then start() and stop() the watch several times. On each call to stop(), a TimedEvent object is generated, noting the start time and duration of that timed event. If a stopwatch is started multiple times without being stopped in between, all but the latest call to start() will be discarded.
This results in an object graph of StopWatch categories, each containing a history of timed events, as illustrated in figure 8.1.
Figure 8.1. Object graph of stopwatch library classes. Each category is represented by an object that contains a history of events for that category. All categories are accessible from the stopwatch.watches singleton.

When data has been gathered, the entire object graph can be queried and visualized. The render() function here makes use of the ObjectViewer library that we encountered in chapter 5 to automatically render a report. We leave it as an exercise to the reader to output the data in CSV format for cutting and pasting into a file.
Listing 8.3 shows how to apply the stopwatch code to our example “time consuming” function.
Listing 8.3. Timing code with the stopwatch library
function myTimeConsumingFunction(){
var watch=stopwatch.getWatch("my time consuming function",true);
...
//do something interesting and time-consuming!
...
watch.stop();
}
The stopwatch code can now be added relatively unobtrusively into our code. We can define as few or as many categories as we like, for different purposes. In this case, we named the category after the function name.
Before we move on, let’s apply this to a working example. A suitable candidate is the mousemat example that we used in chapter 4 when discussing the Observer pattern and JavaScript events. The example has two processes watching mouse movements over the main mousemat DOM element. One writes the current coordinates to the browser status bar, and the other plots the mouse cursor position in a small thumbnail element. Both are providing us with useful information, but they involve some processing overhead, too. We might wonder which is taking up the most processor time.
Using our stopwatch library, we can easily add profiling capabilities to the example. Listing 8.4 shows us the modified page, with a new DIV element to hold the profiler report and a few stopwatch JavaScript methods sprinkled across the blocks of code that we are interested in.
Listing 8.4. mousemat.html with profiling
<html>
<head>
<link rel='stylesheet' type='text/css' href='mousemat.css' />
<link rel='stylesheet' type='text/css' href='objviewer.css' />
<script type='text/javascript' src='x/x_core.js'></script>
<script type='text/javascript' src='extras-array.js'></script>
<script type='text/javascript' src='styling.js'></script>
<script type='text/javascript' src='objviewer.js'></script>
<script type='text/javascript' src='stopwatch.js'></script>
<script type='text/javascript' src='eventRouter.js'></script>
<script type='text/javascript'>
var cursor=null;
window.onload=function(){
var watch=stopwatch.getWatch("window onload",true);
var mat=document.getElementById('mousemat'),
cursor=document.getElementById('cursor'),
var mouseRouter=new jsEvent.EventRouter(mat,"onmousemove");
mouseRouter.addListener(writeStatus);
mouseRouter.addListener(drawThumbnail);
watch.stop();
}
function writeStatus(e){
var watch=stopwatch.getWatch("write status",true);
window.status=e.clientX+","+e.clientY;
watch.stop();
}
function drawThumbnail(e){
var watch=stopwatch.getWatch("draw thumbnail",true);
cursor.style.left=((e.clientX/5)-2)+"px";
cursor.style.top=((e.clientY/5)-2)+"px";
watch.stop();
}
</script>
</head>
<body>
<div>
<a href='javascript:stopwatch.report("profiler")'>profile</a>
</div>
<div>
<div class='mousemat' id='mousemat'></div>
<div class='thumbnail' id='thumbnail'>
<div class='cursor' id='cursor'></div>
</div>
<div class='profiler objViewBorder' id='profiler'></div>
</div>
</body>
</html>
We define three stopwatches: for the window.onload event and for each mouse listener process. We assign meaningful names to the stopwatches, as these will be used by the report that we generate. Let’s load the modified application, then, and give it a quick spin.
When we mouse over the mousemat as before, our profiler is busy collecting data, which we can examine at any point by clicking the profile link in the top left. Figure 8.2 shows the application in the browser after a few hundred mouse moves, with the profiler report showing.
Figure 8.2. Mousemat example from chapter 4 with the JavaScript profiler running and generating a report on the active stopwatches. We have chosen to profile the window.onload event, the drawing of the thumbnail cursor in response to mouse movement, and the updating of the status bar with the mouse coordinates. count indicates the number of recordings made of each code block, and total the time spent in that block of code.

On both Firefox and Internet Explorer browsers we can see that in this case, the write status method takes less than one quarter the time of the draw thumbnail method.
Note that the window.onload event appears to have executed in 0 ms, owing to the limited granularity of the JavaScript Date object. With this profiling system, we’re working entirely within the JavaScript interpreter, with all of the limitations that apply there. Mozilla browsers can take advantage of a native profiler built into the browser. Let’s look at that next.
8.2.2. Using the Venkman profiler
The Mozilla family of browsers enjoys a rich set of plug-in extensions. One of the older, more established ones is the Venkman debugger, which can be used to step through JavaScript code line by line. We discuss Venkman’s debugging features in appendix A. For now, though, let’s look at one of its lesser-known capabilities, as a code profiler.
To profile code in Venkman, simply open the page that you’re interested in, and then open the debugger from the browser’s Tools menu. (This assumes that you have the Venkman extension installed. If you don’t yet, see appendix A.) On the toolbar there is a clock button labeled Profile (figure 8.3). Clicking this button adds a green tick to the icon.
Figure 8.3. Venkman debugger for Mozilla with the Profile button checked, indicating that time spent executing all loaded scripts (as shown in the panel on the top left) is being recorded.
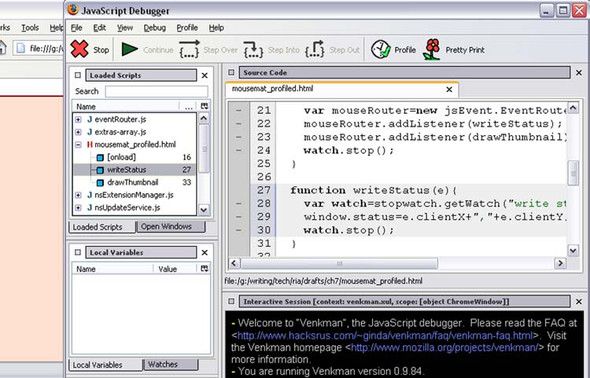
Venkman is now meticulously recording all that goes on in the JavaScript engine of your browser, so drag the mouse around the mousemat area for a few seconds, and then click the Profile button in the debugger again to stop profiling. From the debugger Window menu, select the Profile > Save Profile Data As option. Data can be saved in a number of formats, including CSV (for spreadsheets), an HTML report, or an XML file.
Unfortunately, Venkman tends to generate rather too much data and lists various chrome:// URLs first. These are internal parts of the browser or plug-ins that are implemented in JavaScript, and we can ignore them. In addition to the main methods of the HTML page, all functions in all JavaScript libraries that we are using—including the stopwatch.js profiler that we developed in the previous section—have been recorded. Figure 8.4 shows the relevant section of the HTML report for the main HTML page.
Figure 8.4. Fragment of the HTML profile report generated by Venkman showing the number of calls and total, minimum, maximum, and average time for each method that listens to the mouse movements over the mousemat DOM element in our example page.
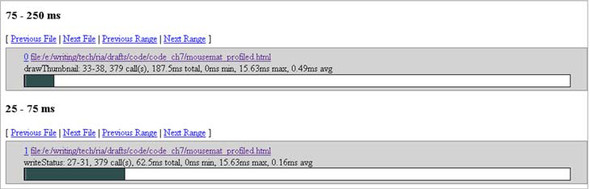
Venkman generates results that broadly agree with the timings of our own stopwatch object—rewriting the status bar takes roughly one third as long as updating the thumbnail element.
Venkman is a useful profiling tool and it can generate a lot of data without us having to modify our code at all. If you need to profile code running across different browsers, then our stopwatch library can help you out. In the following section, we’ll look at a few example pieces of code that demonstrate some refactorings that can be applied to code to help speed it up. We’ll make use of our stopwatch library to measure the benefits.
8.2.3. Optimizing execution speed for Ajax
Optimization of code is a black art. Programming JavaScript for web browsers is often a hit-or-miss affair. It stands to reason, therefore, that optimizing Ajax code is a decidedly murky topic. A substantial body of folklore surrounds this topic, and much of what is said is good. With the profiling library that we developed in section 8.2.1, however, we can put our skeptic’s hat on and put the folklore to the test. In this section, we’ll look at three common strategies for improving execution speed and see how they bear out in practice.
Optimizing a for loop
The first example that we’ll look at is a fairly common programming mistake. It isn’t limited to JavaScript but is certainly easy to make when writing Ajax code. Our example calculation does a long, pointless calculation, simply to take up sufficient time for us to measure a real difference. The calculation that we have chosen here is the Fibonacci sequence, in which each successive number is the sum of the previous two numbers. If we start off the sequence with two 1s, for example, we get
1, 1, 2, 3, 5, 8, ...
Our JavaScript calculation of the Fibonacci sequence is as follows:
function fibonacci(count){
var a=1;
var b=1;
for(var i=0;i<count;i++){
var total=a+b;
a=b;
b=total;
}
return b;
}
Our only interest in the sequence is that it takes a little while to compute. Now, let’s suppose that we want to calculate all the Fibonacci sequence values from 1 to n and add them together. Here’s a bit of code to do that:
var total=0;
for (var i=0;i<fibonacci(count);i++){
total+=i;
}
This is a pointless calculation to make, by the way, but in real-world programs you’ll frequently come across a similar situation, in which you need to check a value that is hard to compute within each iteration of a loop. The code above is inefficient, because it computes fibonacci(count) with each iteration, despite the fact that the value will be the same every time. The syntax of the for loop makes it less than obvious, allowing this type of error to slip into code all too easily. We could rewrite the code to calculate fibonacci() only once:
var total=0;
var loopCounter=fibonacci(count);
for (var i=0;i<loopCounter;i++){
total+=i;
}
So, we’ve optimized our code. But by how much? If this is part of a large complex body of code, we need to know whether our efforts have been worthwhile. To find out, we can include both versions of the code in a web page along with our profiling library and attach a stopwatch to each function. Listing 8.5 shows how this is done.
Listing 8.5. Profiling a for loop


The functions slowLoop() and fastLoop() present our two versions of the algorithm and are wrapped by the go() function, which will invoke one or the other with a given counter value. The page provides hyperlinks to execute each version of the loop, passing in a counter value from an adjacent HTML forms textbox. We found a value of 25 to give a reasonable computation time on our testing machine. A third hyperlink will render the profiling report. Table 8.1 shows the results of a simple test.
Table 8.1. Profiling results for loop optimization
|
Algorithm |
Execution Time (ms) |
|---|---|
| Original | 3085 |
| Optimized | 450 |
From this, we can see that taking the lengthy calculation out of the for loop really does have an impact in this case. Of course, in your own code, it might not. If in doubt, profile it!
The next example looks at an Ajax-specific issue: the creation of DOM nodes.
Attaching DOM nodes to a document
To render something in a browser window using Ajax, we generally create DOM nodes and then append them to the document tree, either to document.body or to some other node hanging off it. As soon as it makes contact with the document, a DOM node will render. There is no way of suppressing this feature.
Re-rendering the document in the browser window requires various layout parameters to be recalculated and is potentially expensive. If we are assembling a complex user interface, it therefore makes sense to create all the nodes and add them to each other and then add the assembled structure to the document. This way, the page layout process occurs once. Let’s look at a simple example of creating a container element in which we randomly place lots of little DOM nodes. In our description of this example, we referred to the container node first, so it seems natural to create that first. Here’s a first cut at this code:
var container=document.createElement("div");
container.className='mousemat';
var outermost=document.getElementById('top'),
outermost.appendChild(container);
for(var i=0;i<count;i++){
var node=document.createElement('div'),
node.className='cursor';
node.style.position='absolute';
node.style.left=(4+parseInt(Math.random()*492))+"px";
node.style.top=(4+parseInt(Math.random()*492))+"px";
container.appendChild(node);
}
The element outermost is an existing DOM element, to which we attach our container, and the little nodes inside that. Because we append the container first and then fill it up, we are going to modify the entire document count+1 times! A quick bit of reworking can correct this for us:
var container=document.createElement("div");
container.className='mousemat';
var outermost=document.getElementById('top'),
for(var i=0;i<count;i++){
var node=document.createElement('div'),
node.className='cursor';
node.style.position='absolute';
node.style.left=(4+parseInt(Math.random()*492))+"px";
node.style.top=(4+parseInt(Math.random()*492))+"px";
container.appendChild(node);
}
outermost.appendChild(container);
In fact, we had to move only one line of code to reduce this to a single modification of the existing document. Listing 8.6 shows the full code for a test page that compares these two versions of the function using our stopwatch library.
Listing 8.6. Profiling DOM node creation


Again, we have a hyperlink to invoke both the fast and the slow function, using the value in an HTML form field as the argument. In this case, it specifies how many little DOM nodes to add to the container. We found 640 to be a reasonable value. The results of a simple test are presented in table 8.2.
Table 8.2. Profiling results for DOM node creation
|
Number of Page Layouts |
Execution Time (ms) |
|
|---|---|---|
| Original | 641 | 681 |
| Optimized | 1 | 461 |
Again, the optimization based on received wisdom does make a difference. With our profiler, we can see how much of a difference it is making. In this particular case, we took almost one third off the execution time. In a different layout, with different types of nodes, the numbers may differ. (Note that our example used only absolutely positioned nodes, which require less work by the layout engine.) The profiler is easy to insert into your code, in order to find out.
Our final example looks at a JavaScript language feature and undertakes a comparison between different subsystems to find the bottleneck.
Minimizing dot notation
In JavaScript, as with many languages, we can refer to variables deep in a complex hierarchy of objects by “joining the dots.” For example:
myGrandFather.clock.hands.minute
refers to the minute hand of my grandfather’s clock. Let’s say we want to refer to all three hands on the clock. We could write
var hourHand=myGrandFather.clock.hands.hour; var minuteHand=myGrandFather.clock.hands.minute; var secondHand=myGrandFather.clock.hands.second;
Every time the interpreter encounters a dot character, it will look up the child variable against the parent. In total here, we have made nine such lookups, many of which are repeats. Let’s rewrite the example:
var hands=myGrandFather.clock.hands; var hourHand=hands.hour; var minuteHand=hands.minute; var secondHand=hands.second;
Now we have only five lookups being made, saving the interpreter from a bit of repetitive work. In a compiled language such as Java or C#, the compiler will often optimize these repetitions automatically for us. I don’t know whether JavaScript interpreters can do this (and on which browsers), but I can use the stopwatch library to find out if I ought to be worrying about it.
The example program for this section computes the gravitational attraction between two bodies, called earth and moon. Each body is assigned a number of physical properties such as mass, position, velocity, and acceleration, from which the gravitational forces can be calculated. To give our dot notation a good testing, these properties are stored as a complex object graph, like so:
var earth={
physics:{
mass:10,
pos:{ x:250,y:250 },
vel:{ x:0, y:0 },
acc:{ x:0, y:0 }
}
};
The top-level object, physics, is arguably unnecessary, but it will serve to increase the number of dots to resolve.
The application runs in two stages. First, it computes a simulation for a given number of timesteps, calculating distances, gravitational forces, accelerations, and other such things that we haven’t looked at since high school. It stores the position data at each timestep in an array, along with a running estimate of the minimum and maximum positions of either body.
In the second phase, we use this data to plot the trajectories of the two bodies using DOM nodes, taking the minimum and maximum data to scale the canvas appropriately. In a real application, it would probably be more common to plot the data as the simulation progresses, but I’ve separated the two here to allow the calculation phase and rendering phase to be profiled separately.
Once again, we define two versions of the code, an inefficient one and an optimized one. In the inefficient code, we’ve gone out of our way to use as many dots as possible. Here’s a section (don’t worry too much about what the equations mean!):
var grav=(earth.physics.mass*moon.physics.mass) /(dist*dist*gravF); var xGrav=grav*(distX/dist); var yGrav=grav*(distY/dist); moon.physics.acc.x=-xGrav/(moon.physics.mass); moon.physics.acc.y=-yGrav/(moon.physics.mass); moon.physics.vel.x+=moon.physics.acc.x; moon.physics.vel.y+=moon.physics.acc.y; moon.physics.pos.x+=moon.physics.vel.x; moon.physics.pos.y+=moon.physics.vel.y;
This is something of a caricature—we’ve deliberately used as many deep references down the object graphs as possible, making for verbose and slow code. There is certainly plenty of room for improvement! Here’s the same code from the optimized version:
var mp=moon.physics;
var mpa=mp.acc;
var mpv=mp.vel;
var mpp=mp.pos;
var mpm=mp.mass;
...
var grav=(epm*mpm)/(dist*dist*gravF);
var xGrav=grav*(distX/dist);
var yGrav=grav*(distY/dist);
mpa.x=-xGrav/(mpm);
mpa.y=-yGrav/(mpm);
mpv.x+=mpa.x;
mpv.y+=mpa.y;
mpp.x+=mpv.x;
mpp.y+=mpv.y;
We’ve simply resolved all the necessary references at the start of the calculation as local variables. This makes the code more readable and, more important, reduces the work that the interpreter needs to do. Listing 8.7 shows the code for the complete web page that allows the two algorithms to be profiled side by side.
Listing 8.7. Profiling variable resolution


The structure should be broadly familiar by now. The functions slowData() ![]() and fastData()
and fastData() ![]() contain the two versions of our calculation phase, which generates the data structures
contain the two versions of our calculation phase, which generates the data structures ![]() . I’ve omitted the full algorithms from the listing here, as they take up a lot of space. The differences in style are described
in the snippets we presented earlier and the full listings are available in the downloadable sample code that accompanies
the book. Each calculation function has a stopWatch object assigned to it, profiling the entire calculation step. These functions
are called by the showOrbit() function, which takes the data and then creates a DOM representation of the calculated trajectories
. I’ve omitted the full algorithms from the listing here, as they take up a lot of space. The differences in style are described
in the snippets we presented earlier and the full listings are available in the downloadable sample code that accompanies
the book. Each calculation function has a stopWatch object assigned to it, profiling the entire calculation step. These functions
are called by the showOrbit() function, which takes the data and then creates a DOM representation of the calculated trajectories ![]() . This has also been profiled by a third stopwatch.
. This has also been profiled by a third stopwatch.
The user interface elements are the same as for the previous two examples, with hyperlinks to run the fast and the slow calculations, passing in the text input box value as a parameter. In this case, it indicates the number of timesteps for which to run the simulation. A third hyperlink displays the profile data. Table 8.3 shows the results from a simple run of the default 640 iterations.
Table 8.3. Profiling results for variable resolution
|
Algorithm |
Execution Time (ms) |
|---|---|
| Original calculation | 94 |
| Optimized calculation | 57 |
| Rendering (average) | 702 |
Once again, we can see that the optimizations yield a significant increase, knocking more than one-third from the execution time. We can conclude that the folk wisdom regarding variable resolution and the use of too many dots is correct. It’s reassuring to have checked it out for ourselves.
However, when we look at the entire pipeline of calculation and rendering, the optimization takes 760 ms, as opposed to the original’s 796 ms—a savings closer to 5 percent than 40 percent. The rendering subsystem, not the calculation subsystem, is the bottleneck in the application, and we can conclude that, in this case, optimizing the calculation code is not going to yield great returns.
This demonstrates the broader value of profiling your code. It is one thing to know that a piece of code can be optimized in a particular way and another to know what the expected returns of such an operation would be. It might be tempting to conclude that DOM operations are roughly eight times more costly than pure JavaScript calculations, but that holds true only for this specific example. You may well find that to be the case in many situations, but a rule of thumb is best supplemented by a few measurements—and preferably on a range of different machines and browsers.
We won’t spend more time now on profiling and execution speed. The examples that we have run through should give you a feel for the benefits that profiling can provide on your Ajax projects. Let’s assume that your code is running at a satisfactory speed thanks to a bit of profiling. To ensure adequate performance, you still need to look at the amount of memory that your application is using. We’ll explore memory footprints in the next section.
8.3. JavaScript memory footprint
The purpose of this section is to introduce the topic of memory management in Ajax programming. Some of the ideas are applicable to any programming language; others are peculiar to Ajax and even to specific web browsers.
A running application is allocated memory by the operating system. Ideally, it will request enough to do its job efficiently, and then hand back what it doesn’t need. A poorly written application may either consume a lot of memory unnecessarily while running, or fail to return memory when it has finished. We refer to the amount of memory that a program is using as its memory footprint.
As we move from coding simple, transient web pages to Ajax rich clients, the quality of our memory management can have a big impact on the responsiveness and stability of our application. Using a patterns-based approach can help by producing regular, maintainable code in which potential memory leaks are easily spotted and avoided.
First, let’s examine the concept of memory management in general.
8.3.1. Avoiding memory leaks
Any program can “leak” memory (that is, claim system memory and then fail to release it when finished), and the allocation and deallocation of memory are a major concern to developers using unmanaged languages such as C. JavaScript is a memory-managed language, in which a garbage-collection process automatically handles the allocation and deallocation of memory for the programmer. This takes care of many of the problems that can plague unmanaged code, but it is a fallacy to assume that memory-managed languages can’t generate memory leaks.
Garbage-collection processes attempt to infer when an unused variable may be safely collected, typically by assessing whether the program is able to reach that variable through the network of references between variables. When a variable is deemed unreachable, it will be marked as ready for collection, and the associated memory will be released in the next sweep of the collector (which may be at any arbitrary point in the future). Creating a memory leak in a managed language is as simple as forgetting to dereference a variable once we have finished with it.
Let’s consider a simple example, in which we define an object model that describes household pets and their owners. First let’s look at the owner, described by the object Person:
function Person(name){
this.name=name;
this.pets=new Array();
}
A person may have one or more pets. When a person acquires a pet, he tells the pet that he now owns it:
Person.prototype.addPet=function(pet){
this.pets[pet.name]=pet;
if (pet.assignOwner){
pet.assignOwner(this);
}
}
Similarly, when a person removes a pet from his list of pets, he tells the pet that he no longer owns it:
this.removePet(petName)=function{
var orphan=this.pets[petName];
this.pets[petName]=null;
if (orphan.unassignOwner){
orphan.unassignOwner(this);
}
}
The person knows at any given time who his pets are and can manage the list of pets using the supplied addPet() and removePet() methods. The owner informs the pet when it becomes owned or disowned, on the assumption that each pet adheres to a contract (in JavaScript, we can leave this contract as implicit and check for adherence to the contract at runtime).
Pets come in several shapes and sizes. Here we define two: a cat and a dog. They differ in the attitude that they take toward being owned, with a cat paying no attention to whom it is owned by, whereas a dog will attach itself to a given owner for life. (I apologize to the animal world for gross generalization at this point!)
So our definition of the pet cat might look like this:
function Cat(name){
this.name=name;
}
Cat.prototype.assignOwner=function(person){
}
Cat.prototype.unassignOwner=function(person){
}
The cat isn’t interested in being owned or disowned, so it provides empty implementations of the contractual methods.
We can define a dog, on the other hand, that slavishly remembers who its owner is, by continuing to hold a reference to its master after it has been disowned (some dogs are like that!):
function Dog(name){
this.name=name;
}
Dog.prototype.assignOwner=function(person){
this.owner=person;
}
Dog.prototype.unassignOwner=function(person){
this.owner=person;
}
Both Cat and Dog objects are badly behaved implementations of Pet. They stick to the letter of the contract of being a pet, but they don’t follow its spirit. In a Java or C# implementation, we would explicitly define a Pet interface, but that wouldn’t stop implementations from breaching the spirit of the contract. In the real world of coding, object modelers spend a lot of time worrying about badly behaved implementations of their interfaces, trying to close off any loopholes that might be exploited.
Let’s play with the object model a bit. In the script below, we create three objects:
- jim, a Person
- whiskers, a Cat
- fido, a Dog
First, we instantiate a Person (step 1):
var jim=new Person("jim");
Next, we give that person a pet cat (step 2). Whiskers is instantiated inline in the call to addPet(), and so that particular reference to the cat persists only as long as the method call. However, jim also makes a reference to whiskers, who will be reachable for as long as jim is, that is, until we delete him at the end of the script:
jim.addPet(new Cat("whiskers"));
Let’s give jim a pet dog, too (step 3). Fido is given a slight edge over whiskers in being declared as a global variable, too:
var fido=new Dog("fido");
jim.addPet(fido);
One day, Jim gets rid of his cat (step 4):
jim.removePet("whiskers");
Later, he gets rid of his dog, too (step 5). Maybe he’s emigrating?
jim.removePet("fido");
We lose interest in jim and release our reference on him (step 6):
jim=null;
Finally, we release our reference on fido, too (step 7):
fido=null;
Between steps 6 and 7, we may believe that we have gotten rid of jim by declaring him to be null. In fact, he is still referenced by fido and so is still reachable by our code as fido.owner. The garbage collector can’t touch him, leaving him lurking on the JavaScript engine’s heap, taking up precious memory. Only in step 7, when fido is declared null, does Jim become unreachable, and our memory can be released.
In our simple script, this a small and temporary problem, but it serves to illustrate that seemingly arbitrary decisions affect the garbage-collection process. Fido may not be deleted directly after jim and, if he had the ability to remember more than one previous owner, might consign entire legions of Person objects to a shadow life on the heap before being destroyed. If we had chosen to declare fido inline and the cat as a global, we wouldn’t have had any such problem. To assess the seriousness of fido’s behavior, we need to ask ourselves the following questions:
- How much memory might he consume in terms of references to otherwise deleted objects? We know that our simple fido can remember only one Person at a time, but even so, that Person might have a reference to 500 otherwise-unreachable pet cats, so the extra memory consumption might be arbitrarily large.
- How long will the extra memory be held? In our simple script here, the answer is “not very long,” but we might later add extra steps in between deleting jim and deleting fido. Further, JavaScript tends toward event-driven programming, and so, if the deletion of jim and of fido takes place in separate event handlers, we can’t predict a hard answer, not even a probabilistic one without performing some sort of use-case analysis.
Neither question is quite as easy to answer as it might seem. The best that we can do is to keep these sorts of questions in mind as we write and modify our code and to conduct tests to see if we’re right in our assumptions. We need to think about the usage patterns of our application while we code, not solely as an afterthought.
This covers the general principles of memory management. There are specific issues to be aware of in an Ajax application, so let’s address them next.
8.3.2. Special considerations for Ajax
So far, we’ve covered some ground that is common to the memory management of most programming languages. Properly understanding concepts such as footprint and reachability are important when developing Ajax applications, but there are also issues that are specific to Ajax. With Ajax, we are operating in a managed environment, in a container that has exposed some of its native functionality and locked us out of others. This changes the picture somewhat.
In chapter 4, our Ajax application was divided into three notional subsystems: the Model, View, and Controller. The Model is usually composed of pure JavaScript objects that we have defined and instantiated ourselves. The View is composed largely of DOM nodes, which are native objects exposed to the JavaScript environment by the browser. The Controller glues the two together. It is in this layer that we need to pay special attention to memory management.
Breaking cyclic references
In section 4.3.1, we introduced a commonly used pattern for event handling, in which we attach domain model objects (that is, parts of the Model subsystem) to DOM nodes (that is, part of the View). Let’s recap on the example that we presented. Here is a constructor for a domain model object representing a pushbutton:
function Button(value,domEl){
this.domEl=domEl;
this.value=value;
this.domEl.buttonObj=this;
this.domEl.onclick=this.clickHandler;
}
Note that a two-way reference between the DOM element domEl and the domain object itself is created. Below, the event-handler function referenced in the constructor:
Button.prototype.clickHandler=function(event){
var buttonObj=this.buttonObj;
var value=(buttonObj && buttonObj.value) ?
buttonObj.value : "unknown value";
alert(value);
}
Remember that the event-handler function will be called with the DOM node, not the Button object, as its context. We need a reference from the View to the Model in order to interact with the Model tier. In this case, we read its value property. In other cases where we have used this pattern in this book, we have invoked functions on the domain objects.
The domain model object of type Button will be reachable as long as any other reachable object has a reference to it. Similarly, the DOM element will remain reachable as long as any other reachable element refers to it. In the case of DOM elements, an element is always reachable if it is attached to the main document tree, even if no programmatic references are held to it. Thus, unless we explicitly break the link between the DOM element and the Button object, the Button can’t be garbage-collected as long as the DOM element is still part of the document.
When scripted domain model objects interact with the Document Object Model, it is possible to create a local JavaScript object that remains reachable via the DOM rather than through any global variables we have defined. To ensure that objects aren’t kept from garbage collection unnecessarily by we can write simple clean-up functions (a step back toward C++ object destructors in many ways, although we need to invoke them manually). For the Button object, we could write the following:
Button.prototype.cleanUp=function(){
this.domEl.buttonObj=null;
this.domEl=null;
}
The first line removes the reference that the DOM node has on this object. The second line removes this object’s reference to the DOM node. It doesn’t destroy the node but simply resets this local reference to the node to a null value. The DOM node was passed to our object as a constructor argument in this case, so it isn’t our responsibility to dispose of it. In other cases, though, we do have that responsibility, so let’s see how to handle it.
Disposing of DOM elements
When working with Ajax, and with large domain models in particular, it is common practice to construct new DOM nodes and interact with the document tree programmatically, rather than just via HTML declarations when the page first loads. Our ObjectViewer from chapters 4 and 5 and the notifications framework in chapter 6, for example, both contained several domain model objects capable of rendering themselves by creating additional DOM elements and attaching them to a part of the main document. With this great power comes great responsibility, and, for each node created programmatically, good housekeeping rules dictate that we are obliged to see to its disposal programmatically as well.
Neither the W3C DOM nor the popular browser implementations provide a way of destroying a DOM node outright once it has been created. The best we can do in destroying a created DOM node is to detach it from the document tree and hope that the garbage-collection mechanism in the browser will find it.
Let’s look at a straightforward example. The following script demonstrates a simple pop-up message box that uses the DOM to find itself using document.getElementById() when being closed:
function Message(txt, timeout){
var box=document.createElement("div");
box.id="messagebox";
box.classname="messagebox";
var txtNode=document.createTextNode(txt);
box.appendChild(txtNode);
setTimeout("removeBox('messagebox')",timeout);
}
function removeBox(id){
var box=document.getElementById(id);
if (box){
box.style.display='none';
}
}
When we call Message(), a visible message box is created, and a JavaScript timer is set to call another function that removes the message after a given time.
The variables box and txtNode are both created locally and go out of scope as soon as the function Message() has exited, but the document nodes that are created will still be reachable, because they have been attached to the DOM tree.
The removeBox() function handles the job of making the created DOM node go away when we’re done with it. We have several possible options for doing this, from a technical standpoint. In the example above, we removed the box simply by hiding it from view. It will still occupy memory when invisible, but if we are planning on redisplaying it soon, that won’t be a problem.
Alternatively, we could alter our remove() method to dislocate the DOM nodes from the main document and hope that the garbage collector spots them before too long. Again, though, we don’t actually destroy the variable, and the duration of its stay in memory is outside our control.
function removeBox(id){
var box=document.getElementById(id);
if (box && box.parentNode){
box.parentNode.removeChild(box);
}
}
We can discern two patterns for GUI element removal here, which we will refer to as Remove By Hiding and Remove By Detachment. The Message object here has no event handlers—it simply appears and disappears at its own speed. If we link the domain model and DOM nodes in both directions, as we did for our Button object, we would need to explicitly invoke the cleanUp() function if we were using a Remove By Detachment pattern.
Both approaches have their advantages and disadvantages. The main deciding factor for us is to ask whether we are going to reuse the DOM node at a later date. In the case of a general-purpose message box the answer is probably “yes,” and we would opt for removal by hiding. In the case of a more specific use, such as a node in a complex tree widget, it is usually simpler to destroy the node when finished with it than to try to keep lots of references to dormant nodes.
If we choose to use Remove By Hiding, we can adopt a complementary approach of reusing DOM nodes. Here, we modify the message-creation function to first check for an existing node and create a new one only if necessary. We could rewrite our Message object constructor to accommodate this:
function Message(txt, timeout){
var box=document.geElementById("messagebox");
var txtNode=document.createTextNode(txt);
if (box==null){
box=document.createElement("div");
box.id="messagebox";
box.classname="messagebox";
box.style.display='block';
box.appendChild(txtNode);
}else{
var oldTxtNode=box.firstChild;
box.replaceChild(txtNode,oldTxtNode);
}
setTimeout("removeBox('messagebox')",timeout);
}
We can now contrast two patterns for GUI element creation, which we will refer to as Create Always (our original example) and Create If Not Exists (the modified version above). Because the ID that we check for is hard-coded, only one Message can be shown at a time (and that is probably appropriate here). Where we have attached a domain model object to a reusable DOM node, that domain object can be used to fetch the initial reference to the DOM node, allowing Create If Not Exists to coexist with multiple instances of an object.
Note
When writing an Ajax application, then, it is important to be aware of memory-management issues regarding DOM elements, as well as conventional variables that we create ourselves. We also need to take account of the managed nature of DOM elements and treat their disposal differently. When mixing DOM nodes and ordinary variables, the use of cleanup code is advised, to break cyclic references.
In the following section, we’ll look at further considerations that the Ajax programmer needs to take into account when working with Internet Explorer.
Further special considerations for Internet Explorer
Each web browser implements its own garbage collector, and some work differently than others. The exact mechanisms of the Internet Explorer browser garbage collection are not well understood, but, according to the consensus of the comp.lang.JavaScript newsgroup, it has specific difficulties with releasing variables where a circular reference exists between DOM elements and ordinary JavaScript objects. It has been suggested that manually severing such links would be a good idea.
To describe this by example, the following code defines a circular reference:
function MyObject(id){
this.id=id;
this.front=document.createElement("div");
this.front.backingObj=this;
}
MyObject is a user-defined type. Every instance will refer to a DOM node as this.front, and the DOM node will refer back to the JavaScript object as this.backingObj.
To remove this circular reference while finalizing the object, we might offer a method such as this:
MyObject.prototype.finalize=function(){
this.front.backingObj=null;
this.front=null;
}
By setting both references to null, we break the circular reference.
Alternatively, a DOM tree could be cleaned up in a generic fashion, by walking the DOM tree and eliminating references on the basis of name, type, or whatever. Richard Cornford has suggested such a function, specifically for dealing with event handler functions attached to DOM elements (see the Resources section at the end of this chapter).
My feeling is that generic approaches such as this should be used only as a last resort, as they may scale poorly to the large document trees typified by Ajax rich clients. A structured pattern-based approach to the codebase should enable the programmer to keep track of the specific cases where cleanup is required.
A second point worth noting for IE is that a top-level “undocumented” function called CollectGarbage() is available. Under IE v6, this function exists and can be called but seems to be an empty stub. We have never seen it make a difference to reported memory in the Task Manager.
Now that we understand the issues of memory management, let’s explore the practicalities of measuring it and applying those measurements to a real-life application.
8.4. Designing for performance
We stated at the outset that performance consisted of both good execution speed and a controllable memory footprint. We also said that design patterns could help us to achieve these goals.
In this section, we’ll see how to measure memory footprint in real applications, and we’ll use a simple example to show how the use of design patterns can help us to understand the fluctuations in memory footprint that we may see in working code.
8.4.1. Measuring memory footprint
When we measured execution speed, we could do so either in JavaScript code using the Date object or with an external tool. JavaScript doesn’t provide any built-in capabilities to read system memory usage, so we’re dependent on external tools. Fortunately, we have several to choose from.
There are a variety of ways to see how much memory your browser is consuming during execution of your application. The simplest way to do so is to use a system utility appropriate to your operating system to see the underlying processes. On Windows systems, there is the Task Manager, and UNIX systems have the console-based top command. Let’s look at each of these in turn.
Windows Task Manager
The Windows Task Manager (figure 8.5) is available on many versions of Windows (Windows 95 and 98 users are out of luck here). It provides a view of all processes running in the operating system and their resource use. It can usually be invoked from the menu presented to the user when she presses the Ctrl+Alt+Delete key combination. The Task Manager interface has several tabs. We are interested in the tab labeled Processes.
Figure 8.5. Windows Task Manager showing running processes and their memory usage. Processes are being sorted by memory usage, in descending order.
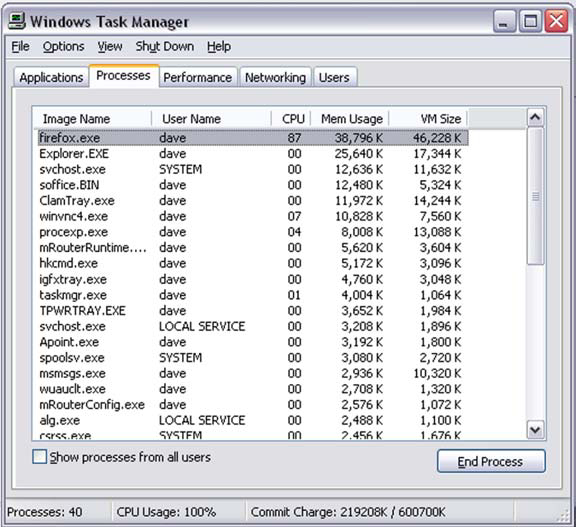
The highlighted row shows that Firefox is currently using around 38MB of memory on our machine. In its default state, the Mem Usage column provides information on active memory usage by the application. On some versions of Windows, the user can add extra columns using the View > Select Columns menu (figure 8.6).
Figure 8.6. Selecting additional columns to view in the Task Manager’s Processes tab. Virtual Memory Size shows the total amount of memory allocated to the process.
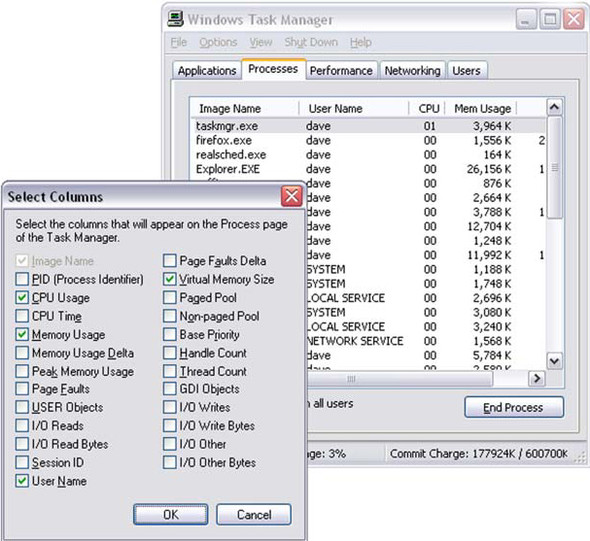
Showing the Virtual Memory Size of a process as well as Memory Usage can be useful. Memory Usage represents active memory assigned to an application, whereas Virtual Memory Size represents inactive memory that has been written to the swap partition or file. When a Windows application is minimized, the Mem Usage will typically drop considerably, but VM Size will stay more or less flat, indicating that the application still has an option to consume real system resources in the future.
UNIX top
A console-based application for UNIX systems (including Mac OS X), top shows a very similar view of processes to the Windows Task Manager (figure 8.7).
Figure 8.7. UNIX top command running inside a console, showing memory and CPU usage by process.

As with Task Manager, each line represents an active process, with columns showing memory and CPU usage and other statistics. The top application is driven by keyboard commands, which are documented in the man or info pages and on the Internet. Space precludes a fuller tutorial on top here, or an exploration of the GUI equivalents such as the GNOME System Manager that may be present on some UNIX/Linux systems.
Power tools
Beyond these basic tools, various “power tools” are available for tracking memory usage, offering finer-grained views of the operating system’s internal state. We can’t do justice to the full range of these tools, but here are brief pointers to a couple of freeware tools that we have found useful.
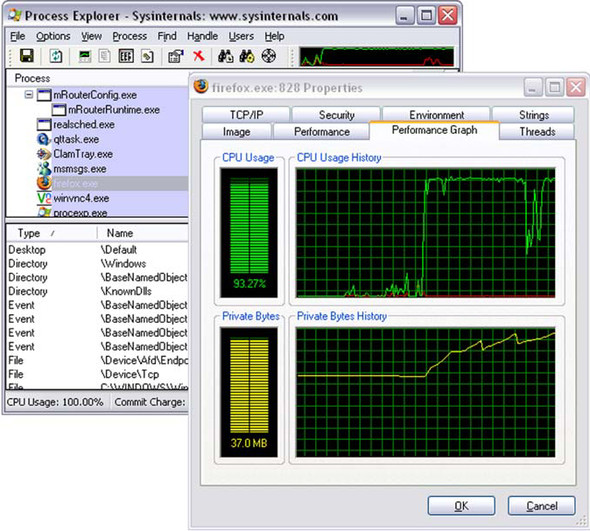
First, Sysinternal.com’s Process Explorer tool (figure 8.8) is perhaps best described as a “task manager on steroids.” It fulfills the same role as Task Manager but allows for detailed drilldown into the memory footprint and processor use of individual processes, allowing us to target Internet Explorer or Firefox specifically.
Figure 8.8. Process Explorer provides detailed reporting on memory and processor usage on a per-process basis, allowing for more accurate tracking of the browser’s footprint on a Windows machine. This window is tracking an instance of Mozilla Firefox running the stress test described in section 8.4.2.
Second, J. G. Webber has developed Drip (see the Resources section), a simple but powerful memory management reporter for Internet Explorer that directly queries an embedded web browser about its known DOM nodes, including those that are no longer attached to the document tree (figure 8.9).
Figure 8.9. The Drip tool allows detailed queries on the internal state of Internet Explorer’s DOM tree.

However, even with the basic tools, we can discover a lot about the state of a running Ajax application.
So far, we’ve looked at individual patterns and idioms for handling performance issues in small sections of code. When we write an Ajax application of even moderate size, the various patterns and idioms in each subsystem can interact with each other in surprising ways. The following section describes a case study that illustrates the importance of understanding how patterns combine with one another.
8.4.2. A simple example
In our discussion thus far, we have covered the theory of memory management and described a few patterns that might help us when programmatically creating interface elements. In a real-world Ajax application, we will employ several patterns, which will interact with one another. Individual patterns have impacts on performance, but so do the interactions between patterns. It is here that having access to a common vocabulary to describe what your code is doing becomes very valuable. The best way to illustrate this principle is by example, so in this section we introduce a simple one and present the performance impact of varying the combination of patterns that it uses.
In the simple test program, we can repeatedly create and destroy small ClickBox widgets, so called because they are little boxes that the user can click on with the mouse. The widgets themselves have a limited behavior, described by the following code:
function ClickBox(container){
this.x=5+Math.floor(Math.random()*370);
this.y=5+Math.floor(Math.random()*370);
this.id="box"+container.boxes.length;
this.state=0;
this.render();
container.add(this);
}
ClickBox.prototype.render=function(){
this.body=null;
if (this.body==null){
this.body=document.createElement("div");
this.body.id=this.id;
}
this.body.className='box1';
this.body.style.left=this.x+"px";
this.body.style.top=this.y+"px";
this.body.onclick=function(){
var clickbox=this.backingObj;
clickbox.incrementState();
}
}
ClickBox.prototype.incrementState=function(){
if (this.state==0){
this.body.className='box2';
}else if (this.state==1){
this.hide();
}
this.state++;
}
ClickBox.prototype.hide=function(){
var bod=this.body;
bod.className='box3';
}
When first rendered, the ClickBoxes are red in appearance. Click on them once, and they turn blue. A second click removes them from view. This behavior is implemented by creating two-way references between the domain model object and the DOM element that represents it on-screen, as discussed earlier.
Programmatically, each ClickBox consists of a unique ID, a position, a record of its internal state (that is, how many clicks it has received), and a body. The body is a DOM node of type DIV. The DOM node retains a reference to the backing object in a variable called backingObj.
A Container class is also defined that houses ClickBox objects and maintains an array of them, as well as a unique ID of its own:
function Container(id){
this.id=id;
this.body=document.getElementById(id);
this.boxes=new Array();
}
Container.prototype.add=function(box){
this.boxes[this.boxes.length]=box;
this.body.appendChild(box.body);
}
Container.prototype.clear=function(){
for(var i=0;i<this.boxes.length;i++){
this.boxes[i].hide();
}
this.boxes=new Array();
report("clear");
newDOMs=0;
reusedDOMs=0;
}
A screenshot of the application is shown in figure 8.10.
Figure 8.10. Our memory management demo application, after creation of the first 100 widgets. The user has just clicked one of the widgets with the mouse.
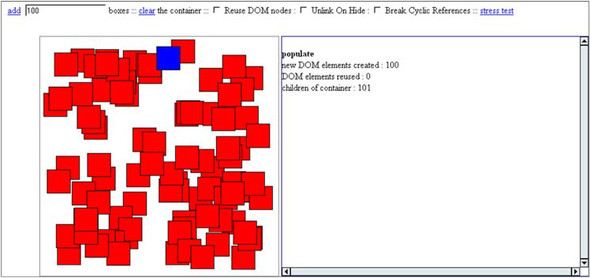
The debug panel on the right reports on the internal state of the system after various user events, such as adding or removing widgets from the container.
The code has been written to allow us to swap in different patterns for creation and destruction of DOM elements and cyclic references while the application is running. The user may choose between these at runtime by checking and unchecking HTML form elements on the page. When the links that add or remove boxes from the container are activated, the combination of patterns that is used to implement the user interface will match the state of the checkboxes. Let’s examine each of these options and the corresponding code.
Reuse DOM Nodes checkbox
Checking this option will determine whether the ClickBox widget will try to find an existing DOM node when creating itself and create a new one only as a last resort. This allows the application to switch between the Create Always and Create If Not Exists patterns that we discussed in section 8.3.2. The modified rendering code follows:
ClickBox.prototype.render=function(){
this.body=null;
if (reuseDOM){
this.body=document.getElementById(this.id);
}
if (this.body==null){
this.body=document.createElement("div");
this.body.id=this.id;
newDOMs++;
}else{
reusedDOMs++;
}
this.body.backingObj=this;
this.body.className='box1';
this.body.style.left=this.x+"px";
this.body.style.top=this.y+"px";
this.body.onclick=function(){
var clickbox=this.backingObj;
clickbox.incrementState();
}
}
Unlink On Hide checkbox
When a ClickBox is removed from the container (either by a second click or by calling Container.clear()), this switch will determine whether it uses the Remove By Hiding or Remove By Detachment pattern (see section 8.3.2):
ClickBox.prototype.hide=function(){
var bod=this.body;
bod.className='box3';
if (unlinkOnHide){
bod.parentNode.removeChild(bod);
}
...
}
Break Cyclic References checkbox
When removing a ClickBox widget, this toggle determines whether the references between the DOM element and the backing object are reset to null or not, using the Break Cyclic References pattern in an attempt to appease the Internet Explorer garbage collector:
ClickBox.prototype.hide=function(){
var bod=this.body;
bod.className='box3';
if (unlinkOnHide){
bod.parentNode.removeChild(bod);
}
if (breakCyclics){
bod.backingObj=null;
this.body=null;
}
}
Form controls allow the user to add ClickBoxes to the container and to clear the container. The application may be driven manually, but for the purposes of gathering results here, we have also written a stress-testing function that simulates several manual actions. This function runs an automatic sequence of actions, in which the following sequence is repeated 240 times:
- Add 100 widgets to the container, using the populate() function.
- Add another 100 widgets.
- Clear the container.
The code for the stressTest function is provided here:
function stressTest(){
for (var i=0;i<240;i++){
populate (100);
populate(100);
container.clear();
}
alert("done");
}
Note that the functionality being tested here relates to the addition and removal of nodes from the container element, not to the behavior of individual ClickBoxes when clicked.
This test is deliberately simple. We encourage you to develop similar stress tests for your own applications, if only to allow you to see whether memory usage goes up or down when changes are made. Designing the test script will be an art in itself, requiring an understanding of typical usage patterns and possibly of more than one type of usage pattern.
Running the stress test takes over a minute, during which time the browser doesn’t respond to user input. If the number of iterations is increased, the browser may crash. If too few iterations are employed, the change in memory footprint may not be noticeable. We found 240 iterations to be a suitable value for the machine on which we were testing; your mileage may vary considerably.
Recording the change in memory footprint was a relatively primitive business. We ran the tests on the Windows operating system, keeping the Task Manager open. We noted the memory consumption of iexplore.exe directly after loading the test page and then again after the alert box appeared, indicating that the test had completed. top or a similar tool could be used for testing on UNIX (see section 8.4.1). We closed down the browser completely after each run, to kill off any leaked memory, ensuring that each run started from the same baseline.
That’s the methodology, then. In the following section, we’ll see the results of performing these tests.
8.4.3. Results: how to reduce memory footprint 150-fold
Running the stress test we just described under various combinations of patterns yielded radically different values of memory consumption, as reported by the Windows Task Manager. These are summarized in table 8.4.
Table 8.4. Benchmark results for ClickBox example code
|
ID |
Reuse DOM Nodes |
Unlink On Hide |
Break Cyclic Refs |
Final Memory Use (IE) |
|---|---|---|---|---|
| A | N | N | N | 166MB |
| B | N | N | Y | 84.5MB |
| C | N | Y | N | 428MB |
| D | Y | N | N | 14.9MB |
| E | Y | N | Y | 14.6MB |
| F | Y | Y | N | 574MB |
| G | Y | Y | Y | 14.2MB |
The results in table 8.4 were recorded for the stress test on a fairly unremarkable workstation (2.8GHz processor, 1GB of RAM) for Internet Explorer v6 on Windows 2000 Workstation under various permutations of patterns. Initial memory use was approximately 11.5MB in all cases. All memory uses reported are the Mem Usage column of the Processes tab of the Task Manager application (see section 8.4.1).
Since we’re confronting real numbers for the first time, the first thing to note is that the application consumes quite a bit of memory. Ajax is often described as a thin client solution, but an Ajax app is capable of hogging a lot of memory if we make the right combination of coding mistakes!
The second important point about the results is that the choice of design patterns has a drastic effect on memory. Let’s look at the results in detail. Three of our combinations consume less than 15MB of RAM after rendering and unrendering all the ClickBox widgets. The remaining combinations climb upward through 80MB, 160MB, to a staggering 430MB and 580MB at the top end. Given that the browser was consuming 11.5MB of memory, the size of additional memory consumed has varied from 3.5MB to 570MB—that’s a difference of over 150 times, simply by modifying the combination of design patterns that we used. It’s remarkable that the browser continued to function at all with this amount of memory leaking from it.
No particular pattern can be identified as the culprit. The interaction between design patterns is quite complex. Comparing runs A, D, and F, for example, switching on the Reuse DOM pattern resulted in a huge decrease in memory usage (over 90 percent), but switching on Unlink On Hide at the same time generated a threefold increase! In this particular case, the reason is understandable—because the DOM nodes have been unlinked, they can’t be found by a call to document.getElementById() in order to be reused. Similarly, switching on Unlink On Hide by itself increased memory usage against the base case (comparing runs C to A). Before we discount Unlink On Hide as a memory hog, look at runs E and G—in the right context, it does make a small positive difference.
Interestingly, there is no single clear winner, with three quite different combinations all resulting in only a small increase in memory. All three of these reuse DOM nodes, but so does the combination that results in the highest memory increase. We can’t draw a simple conclusion from this exercise, but we can identify sets of patterns that work well together and other sets that don’t. If we understand these patterns and have names for them, then it is much easier to apply them consistently throughout an application and achieve reliable performance. If we weren’t using a fixed set of patterns but coding each subsystem’s DOM lifecycle in an ad hoc fashion, each new piece of code would be a gamble that might introduce a large memory leak or might not.
This benchmarking exercise has provided an overview of the issues involved in developing a DHTML rich client that plays well with your web browser for extended periods of time, and it identified places where errors may occur, both in general and in some of the patterns discussed elsewhere in this book.
To really stay on top of memory issues, you must give them a place in your development methodology. Always ask yourself what the effect on memory usage will be as you introduce changes to your code, and always test for memory usage during implementation of the change.
Adopting a pattern-based approach to your codebase will help here, as similar memory issues will crop up repeatedly with the same patterns. We know, for example, that backing objects create cyclic references between DOM and non-DOM nodes, and that Remove By Detachment patterns interfere with Create If Not Exists patterns. If we use patterns consciously in our designs, we are less likely to run into these sorts of problems.
It can help to write and maintain automated test scripts and benchmark your changes against them. Writing the test scripts is probably the hardest part of this, as it involves knowledge of how users use your application. It may be that your app will have several types of user, in which case you would do well to develop several test scripts rather than a single average that fails to represent anyone. As with any kind of tests, they shouldn’t be seen as set in stone once written but should be actively maintained as your project evolves.
8.5. Summary
Performance of any computer program is a combination of execution speed and resource footprint. With Ajax applications, we’re working within a highly managed environment, far removed from the operating system and the hardware, but we still have the opportunity to affect performance greatly, based on the way we code.
We introduced the practice of profiling, both by using JavaScript libraries and using a native profiler tool such as the Venkman debugger. Profiling helps us to understand where the bottlenecks in our system are, and it also can be used to provide a baseline against which we can measure change. By comparing profiler results before and after a code change, we can assess its impact on the overall execution speed of our application.
We also looked at the issue of memory management and showed how to avoid introducing memory leaks into our code, either through generic bad practices or by running afoul of specific issues with the DOM or Internet Explorer. We saw how to measure memory consumption using the tools available to Windows and UNIX operating systems.
Finally, our benchmark example showed the real impact that attention to these details can have on our code. The role of design patterns was crucial in identifying where the great divergence in memory footprint lay and how to manage it.
Performance is an elusive goal—there is always room for a little more optimization—and we have to adopt a pragmatic approach to getting “good enough” performance from our Ajax apps. This chapter should have provided you with the tools needed to do just that.
8.6. Resources
We looked at a few useful development tools in this chapter.
- Drip, the Internet Explorer leak detector was created by Joel Webber. His blog, http://jgwebber.blogspot.com/2005/05/drip-ie-leak-detector.html, is no longer available, but Drip can currently be found at www.outofhanwell.com/ieleak/.
- Venkman Profiler: www.svendtofte.com/code/learning_venkman/advanced.php#profiling
- Process Explorer: www.sysinternals.com
The official line on Internet Explorer leakiness, and some workarounds, is presented here: http://msdn.microsoft.com/library/default.asp?url=/library/en-us/IETechCol/dnwebgen/ie_leak_patterns.asp. Richard Cornford’s suggested solution can be found on Google Groups by searching for “cornford javascript fixCircleRefs()”—the full URL is too long to print out here.