
Chapter 12. Live search using XSLT
This chapter covers
- Dynamic search techniques
- Using XSLT to translate XML to HTML
- Bookmarking dynamic information
- Building a live search component
With Ajax, it’s easy to perform server-side actions while controlling what is happening on the client. If a process takes an extended period of time, we can show animated GIFs that display messages that let the user know what’s happening. The user can perform other actions while the server-side process is taking place and will be less likely to think that the browser has frozen.
In this chapter, we use this Ajax technique to create a live search. It utilizes Extensible Stylesheet Language Transformations (XSLT) to transform an XML document into an HTML layout. The XSLT translation is easier to maintain than the code to manually parse the XML and produce HTML using JavaScript statements. It uses a tree-oriented transformation on a dynamically generated XML document, which replaces the server-side code and the JavaScript on which the previous projects relied. We are eliminating the hassles of manually making sure that all the HTML elements are formed properly.
As with previous examples, we first develop the code in a straightforward way and then refactor it into a reusable component. By the end of this chapter, you should understand the principles of using XSLT with Ajax and have a ready-rolled search component that you can drop into your own projects.
12.1. Understanding the search techniques
When we perform searches, we are accustomed to seeing the page freeze while the search is conducted on the server. (At least, this is the case on websites that do not have 1,200 clustered servers that perform a search over 8 billion pages in less than a second. The budget constraints of your project may vary.) To eliminate the pause, some developers implement pop-up windows and frames. The additional window is used to perform the processing so the user’s experience can be enhanced, but this also creates problems. With Ajax, we can eliminate the common delays of the classic form and frame submissions.
12.1.1. Looking at the classic search
In a classic search process, when we include a search form on our website, one or more form elements are posted back to the server. Google’s main search page is an example. Google’s search page (www.google.com) contains a single textbox and two search buttons. Depending on what search action we select, the form either directs us to a list of records, which we can navigate, or takes us to a single result in that list. This design is well suited for a page that doesn’t have any other functionality, but if it is part of a larger project, the design may cause problems, such as losing the state of the page, clearing form fields, and so on. Figure 12.1 is a diagram of the classic search model, where the entire page is posted back to the server for processing and a complete, new results page is returned.
Figure 12.1. Classic search model showing the processing over a period of time
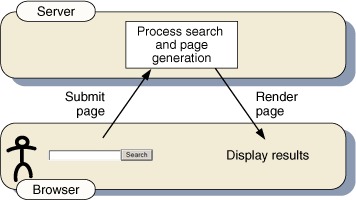
One source of delay is that database queries can take an extended period of time. The browser is not accessible to the user until the results are displayed, causing the page to seem as if it has become frozen or inaccessible. Developers attempt to alleviate this inaccessibility period by adding functionality to the page to notify the user that the process is happening. It’s important to note that this inaccessibility problem is not limited to search operations. It can appear when updating or deleting records in a database, running a complicated server-side transaction, and so on.
One way developers try to cope with this is to display an animated GIF, such as a status bar, while the server is processing the submission. A common question on forums such as JavaRanch (www.JavaRanch.com) is how this can be done. The problem with an animated GIF is that it does not always run. The GIF tends to remain on the first frame with Microsoft Internet Explorer and does not loop through the GIF animation cycle. Developers have reported that some users think that their browser has frozen since they do not see the animation, and they click the refresh button or close their browser.
The classic search form also suffers from the same problems as some of the previous examples in which the page has to be re-rendered. The scroll position of the page may be lost because the new page is loaded at the top of the page instead of where the action took place. The form fields may not stay filled in, which requires the user to enter the data again. Developers attempt to solve these problems by using frames and pop-up windows, but they end up creating more problems. Let’s take a look at the underlying reasons.
12.1.2. The flaws of the frame and pop-up methods
Developers have traditionally used frames, IFrames, and pop-up windows to avoid the problems with pages appearing to be frozen, losing scroll position, and so on. The frames and the pop-up window allow the processing to be continued in another part of the web page, so the user can manipulate the part of the form where the action originated. Not only can the user manipulate the form, but other JavaScript functions can be executed as well.
The frame and pop-up windows have other added benefits. The frame solution allows the returned record set to be scrolled while the search form elements remain in the view of the user. The pop-up window permits the result to be displayed in a separate window, taking the processing away from the main window. With some parent/child window communication, we can pass data from the child window back to the parent window to return results. The pop-up window is great for adding searches in large forms when the user needs specific information that can be hard to memorize. The window can also be set to close after the processing is complete. That is useful when we want to perform updates without returning any data.
Figure 12.2 shows how a search in a frame is implemented. The bottom frame is responsible for submitting the search request to the server, allowing the results to be processed. As a result of having the bottom frame initiate the search, the frame at the top of the window is still accessible to the user, unlike the classic search shown in figure 12.1.
Figure 12.2. Process flow of a search executed in the frame model

Although these solutions solve the problems that we talked about earlier, they also introduce new problems. Frames have been (and still are) one of developers’ worst nightmares. The main problem is navigation, since we do not know how the frame will react with the browser. We wonder how the back button will affect the frame. Will the frame take us to the right page, will it destroy our frameset, or will it just not seem to work? These are the questions that are typically in our minds when testing. And what if the pages are opened in a browser that does not support framesets? To avoid this latter problem, we would have to include frame-detection scripts on the page, adding more weight to our application and introducing more code to manage, and thus increasing the complexity of our codebase.
Pop-up windows, on the other hand, are subject to pop-up blockers as users increasingly turn them on. Pop-up windows should have no problem if they are explicitly initiated by the user’s button click, but pop-up windows can be spawned by the browser automatically, such as an onload or onunload pop-up. These onload pop-up windows are often prevented from opening since they tend to be abused as advertisements. Some users block all pop-up windows—which means users will never get their results since no window will open.
Other problems can occur with pop-up windows, such as when the child window appears underneath its parent; the pop-up window cannot be seen since it is covered by the parent window. This is known as a pop-under. Another problem can happen when an action takes place in the parent window. If the user clicks a link or refreshes the page, the action can sever the child-parent relationship, resulting in loss of communication between the windows. When the page refreshes, the pop-up window object is destroyed; there is no way to carry the object from page to page in a reasonable manner.
As you can see, although the frame and pop-up methods solve the problems inherent in traditional form submission, their solutions may lead to bigger problems. One way to fix these problems is to use Ajax. Ajax handles server communication independently of the browser page, which allows our animations to play and maintains the page state; we do not have to worry about outside factors such as pop-up blockers and users closing the window because they think it is frozen.
12.1.3. Examining a live search with Ajax and XSLT
We can improve the functionality of certain search features on a website by turning the search into a live search, which is how some developers are naming the functionality of Ajax searches. This search is performed without posting the entire page to the server (as in the traditional search), which means that the current state of the page can be maintained. In addition, we can run JavaScript and GIF animations without any major problems, since the results are displayed within the browser with innerHTML or other DOM methods.
Let’s say we have a search that triggers a long database transaction that appears to lock the page. With Ajax, the animation can start when the database transaction starts. When we begin to output the results, we can simply set the CSS display property of the animated image to none, which will make the animation disappear. A variation on this is to place the animation image in the output location where the results are to be displayed. When the transaction is complete, we replace the GIF with the results, so the wait image is removed. Either way, the user can still use the form while the XMLHttpRequest object is processing the data of the server.
Let’s look at a popular example of allowing the user to work with an application while processing is being done on the server: Google Maps. We send out a request to the server for, say, restaurants on Main Street, and we are still able to manipulate the map while the server processes our request. We do not have to wait as we would with a normal form submission. The server-side process then returns the results to the page, where they are displayed to the user. In the same way, our live search allows the user to interact with the page while the server is processing the data. Figure 12.3 shows Ajax’s process flow.
Figure 12.3. Process flow of the Ajax model. The server-side process generates data, which the client-side code inserts into the page directly. Less bandwidth is used, and the user interface is smoother.
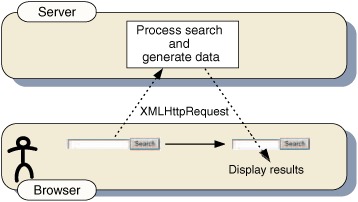
The Ajax approach to handling searches and long transitions allows us to eliminate the problems that we have faced with the other options used in the past. This live search feature is not only useful when used with a search engine like Google or Yahoo, but it can also be helpful for smaller lookups. For instance, we can use a live search to perform a lookup to a database table to retrieve information for some of the form fields, such as an address, based on what the user has entered so far—all while the user is filling in other fields. Any long transaction with the server can be turned into a live process, with the server providing incremental updates to the client, which are displayed in an unobtrusive way (see chapter 6). With Ajax, we can improve data transfer and get the results to the client in a richer environment.
12.1.4. Sending the results back to the client
When the server returns the result of a live search, we can send the information back to the client in one of several ways. We can format the results as XML, plain text, or HTML tags. In previous examples, we created an XML document on the server. The JavaScript code on the client side then called XML DOM methods to build the results table on the client side by looping through the XML nodes. This process used two loops. The first loop was on the server when we built the XML document, and the second was the loop to build the HTML table on the client.
We can avoid the client-side XML DOM loop by building the HTML table on the server before we send it back, rather than building the XML file. With this technique, we concatenate HTML tags into a large string, similar to what we did to create the XML document. However, instead of building it with XML tags, we use table elements. The HTML string is returned to the client, and we can apply it directly to an element’s innerHTML property. In this case, we would use the XMLHttpRequest object’s responseText property since we would have no need to navigate through the nodes.
The problem with these techniques is that—whether it happens on the server or the client—there is a requirement to loop through the data and build the table dynamically. If we need to make changes to the table format in the future, it may be a tedious task, depending on the complexity of the table. Adding or subtracting a column may cause a problem, since we must alter the code inside the loop. We also need to take into account the extra quotes that are contained inside our string; we must make sure that we are escaping the quotes when building the string. Also, if we embed JavaScript into this HTML tag, it adds even more quotes and apostrophes to worry about—we have to verify that all of the tags are closed and that they are properly formatted. The only way we can do that effectively is by examining the text after we build the string.
One option that lets us avoid these problems is to use XSLT. With Ajax, it is possible to combine an XSLT file with an XML document and display the results, thus avoiding DOM methods. If a developer knows XSLT and is not great at coding JavaScript, this may be an excellent solution.
One thing to note about an Ajax search is that it does not require a postback to the server, and consequently the URL of the page does not change to match the search results. Therefore bookmarking the URL will not give us the results we want. In a classic search, such as Google, we can easily copy a URL from a page found by the search and paste it into an e-mail; when the recipient clicks the link, they see the results. However, with an Ajax search, we need to add a little extra code to make this happen. We will look at this solution in section 12.5.4.
12.2. The client-side code
Formatting XML data using XSLT is a popular technique since XML has a structured layout that can be easily manipulated. In previous projects such as the type-ahead suggest in chapter 10, we used JavaScript, XML, and DOM manipulation to create the HTML that we were to display. In this example, we use XSLT to produce the same effect.
XSLT enables us to format our data by building the HTML layout in another file and combining it with the XML document. The XSLT file takes all of the guesswork out of navigating through the XML nodes and building our tables, menus, and HTML layouts. With Ajax, we can retrieve a static or dynamic XML file and a static or dynamic XLST file from the server, and combine them on the client to build our HTML document. XSLT could also be undertaken on the server side, but we’ll look at client-side transformations here.
12.2.1. Setting up the client
For this project, we perform a phonebook search on a user’s name. We use one textbox and one submit button to do this. Our simple search form is shown in listing 12.1.
Listing 12.1. Client-side form
<form name="Form1" ID="Form1" onsubmit="GrabNumber();return false;">Add onsubmit handler Name: <input name="user" type="text"/>
Insert textbox <input type="submit" name="btnSearch" value="Search" />
Add submit button <br/><br/> <div id="results"></div>
Add div for results </form>
To initialize the live search, we need to add an event handler to the form tag. The onsubmit event handler ![]() intercepts clicks on both the Enter key on the textbox and the submit button. This event handler calls the function GrabNumber(), which initiates the XMLHttpRequest without submitting the form back to the page. (In a production environment, we would
check to see whether the user has JavaScript disabled. In that case, the form would have to be submitted back to the server, and we could use a classic search form to
support that user. However, we are not adding that functionality to this project.)
intercepts clicks on both the Enter key on the textbox and the submit button. This event handler calls the function GrabNumber(), which initiates the XMLHttpRequest without submitting the form back to the page. (In a production environment, we would
check to see whether the user has JavaScript disabled. In that case, the form would have to be submitted back to the server, and we could use a classic search form to
support that user. However, we are not adding that functionality to this project.)
The form that we have created is basic, containing only one event handler to initialize the XMLHttpRequest. The textbox ![]() and the submit button
and the submit button ![]() are added to the form to collect the user’s search criteria. If we wanted to get fancy, we could also add an onblur handler to the textbox that calls the function GrabNumber(), and when the user removes focus from the textbox, it would perform the search. In this example, we stick with the onsubmit handler to perform the search.
are added to the form to collect the user’s search criteria. If we wanted to get fancy, we could also add an onblur handler to the textbox that calls the function GrabNumber(), and when the user removes focus from the textbox, it would perform the search. In this example, we stick with the onsubmit handler to perform the search.
We next add our div element ![]() to the document as the output location for the search results. We can position the div wherever we want the results to appear on the page. The ID is added to the div so that we can reference it to add the results and an animated GIF. We are not required to use a div element to output the results. We could easily output the results into a cell in a table or even a span; in fact, we can
use any HTML element whose innerHTML property can be manipulated. We are using a div because it is a block element, which contains a line break before and after the element. The div also takes up 100 percent of the available width of the browser, making it easier for larger results tables to be displayed
to the user.
to the document as the output location for the search results. We can position the div wherever we want the results to appear on the page. The ID is added to the div so that we can reference it to add the results and an animated GIF. We are not required to use a div element to output the results. We could easily output the results into a cell in a table or even a span; in fact, we can
use any HTML element whose innerHTML property can be manipulated. We are using a div because it is a block element, which contains a line break before and after the element. The div also takes up 100 percent of the available width of the browser, making it easier for larger results tables to be displayed
to the user.
It is important to note that the onsubmit handler must return false when the event handler is executing. This informs the browser that the form should not be submitted back to the server, which would trigger a full-page refresh and interrupt our JavaScript programming of the form. We’ll see the return value in listing 12.2 in the next section.
12.2.2. Initiating the process
In this example, we use two files on the server: an XML document and an XSL document. The XML document is created dynamically by PHP when the client requests it. The PHP code takes the user input posted from the page, runs a query against the database, and then formats the results into an XML document. The static XSL document transforms our dynamic XML file into an HTML document. Because it is static, it does not have to be created by the server at the time of the client request, but can be set up ahead of time.
Just as with the other projects in this book, we are using a function to initialize our XMLHttpRequest object. We gather this information and call the function in listing 12.2.
Listing 12.2. Initiation function
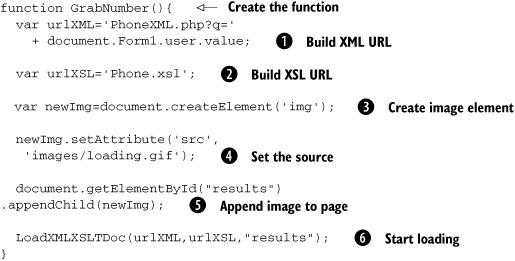
This function assembles the information needed for the call to the server, sets the “in progress” image, and calls the server,
which will dynamically build the response data based on the querystring value we send. The first parameter of the LoadXMLXSLTDoc() function is the URL of the PHP page that generates the XML document, combined with the querystring, which is built by referencing
the value of HTML form field ![]() . The second parameter is the name of the XSLT file
. The second parameter is the name of the XSLT file ![]() that is used in the transformation of the XML data. The third parameter that we need for the function LoadXMLXSLTDoc() is the ID of the div where the search results are to appear. The ID is just the string name of the output element and is not the object’s reference;
in this case, the string is “results”.
that is used in the transformation of the XML data. The third parameter that we need for the function LoadXMLXSLTDoc() is the ID of the div where the search results are to appear. The ID is just the string name of the output element and is not the object’s reference;
in this case, the string is “results”.
The next step is to add the loading image to the web page, using DOM methods. The image element ![]() is created and the source attribute
is created and the source attribute ![]() of the image is set. We append the newly created element
of the image is set. We append the newly created element ![]() to the results div. This places the image file on the page when our function is called from the onsubmit handler of the form. It is important to show the user visual feedback, such as a message or an image, to indicate that the
request processing is happening. This eliminates the chance of the user repeatedly clicking the submit button, thinking that
nothing has happened, since Ajax is a “silent” process.
to the results div. This places the image file on the page when our function is called from the onsubmit handler of the form. It is important to show the user visual feedback, such as a message or an image, to indicate that the
request processing is happening. This eliminates the chance of the user repeatedly clicking the submit button, thinking that
nothing has happened, since Ajax is a “silent” process.
The last step is to call the function LoadXMLXSLTDoc() ![]() , which initiates the process of sending the information to the server. The LoadXMLXSLTDoc() function that we will build in section 12.4 will handle calling our ContentLoader(), which requests the documents from the server. By specifying the output location as a parameter instead of hard-coding the value into our LoadXMLXSLTDoc() function, we can reuse this function multiple times on the same page without having to add multiple functions or if statements to separate the functionality. Therefore, we redirect the output of different searches to different parts of the
page. But before we do this, let’s look at how we build the XML and XSLT documents on the server.
, which initiates the process of sending the information to the server. The LoadXMLXSLTDoc() function that we will build in section 12.4 will handle calling our ContentLoader(), which requests the documents from the server. By specifying the output location as a parameter instead of hard-coding the value into our LoadXMLXSLTDoc() function, we can reuse this function multiple times on the same page without having to add multiple functions or if statements to separate the functionality. Therefore, we redirect the output of different searches to different parts of the
page. But before we do this, let’s look at how we build the XML and XSLT documents on the server.
12.3. The server-side code: PHP
In this section, we create the dynamic XML document for this project using the popular open source scripting language PHP (remember, Ajax is able to work with any server-side language or platform). The XML document is dynamically generated from the result set of a database query at the time of the client’s request. We also show how to create the static XSLT document, which resides on the server and is retrieved each time the dynamic file is requested. Both of these documents are sent back to the client separately when the ContentLoader requests each of them in two separate requests, as shown in listing 12.7. The XSLT transforms our dynamic XML document on the client and creates an HTML table that is displayed to the user.
12.3.1. Building the XML document
Since we are using XSLT, we need a structured XML document that is just a simple listing of information, so the XSLT file can perform a basic transformation. For this project, we develop a dynamic XML file when the PHP file is requested from the client.
Designing the XML structure
Before we can start to build the XML file, we need to create a template for that file. The template should reflect the structure of the data returned by the search. For our address book example, we’ll return the company name, the name of a contact person, the country, and a phone number. Listing 12.3 shows our basic XML template containing the four fields.
Listing 12.3. Basic XML file
<?xml version="1.0" ?>
<phonebook>
<entry>
<company>Company Name</company>
<contact>Contact Name</contact>
<country>Country Name</country>
<phone>Phone Number</phone>
</entry>
</phonebook>
The first element is phonebook. The next one is the entry element, which contains the subelements that hold all the details that relate to each contact found in the query. If we have five results, there will be five entry elements in our XML document. The company name is displayed in the company element. We are also adding the contact name, the country name, and the phone number. We are not limited to just these fields; we can add and subtract fields depending on the information we want to display.
Instead of displaying an alert message to the user if results are not found, we can create an entry displaying that information to the user. This makes it easy for us to return the result to the user without having to add any extra client-side code. The code in listing 12.4 is almost the same as that in listing 12.3, but this time we are inserting text into the XML elements that we want to display to the user to show that no results were returned.
Listing 12.4. XML file with no results
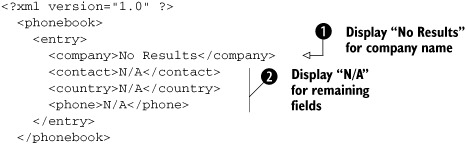
With this code, we display a single row to the user showing that there is no information. In the company tag ![]() , we display a message to the user informing her that there were no results. In the other tags
, we display a message to the user informing her that there were no results. In the other tags ![]() , we are telling the user that there is no information. If we do not want to display “N/A”, we can add a nonbreaking space,
, instead, which allows the table cells to show up. If we were to not add any information, the cells would not appear in the
table.
, we are telling the user that there is no information. If we do not want to display “N/A”, we can add a nonbreaking space,
, instead, which allows the table cells to show up. If we were to not add any information, the cells would not appear in the
table.
As you can see, the XML format has a very simple structure. If this XML file were static, it would be rather easy for any user to add a new customer to the file. Because we are creating it dynamically, we will have to create a loop, which builds our XML document from our result set.
Building the dynamic XML document
As always, we build our XML document on the server. Following our policy of using different server languages for our illustrations, we’ve implemented the server code for this chapter in PHP. Ajax can work with any server-side language, and the fine details of the server code aren’t important to our story here. Listing 12.5 shows the server-side code. The code obtains the querystring parameter and generates a result set of a database query. We then loop through the result set and create an entry in the XML file for each phone entry returned from the query, following our basic template (listing 12.4).
Listing 12.5. phoneXML.php: Server-side XML generation


In order for this dynamic XML document generation to work, we must set the document’s type to text/xml ![]() ; if we skip this step, the XSLT transformation may not take place, especially with Mozilla and Firefox.
; if we skip this step, the XSLT transformation may not take place, especially with Mozilla and Firefox.
The data that we are searching for is stored in a database table. We need to select the relevant entries. In this case, we
are using PHP’s built-in MySQL functions to talk to the database directly, in order to keep things as simple as possible.
We connect to the database ajax running on the local database server as the user ajax with password action ![]() . We then construct our SQL query string using the request parameter passed in from the client code to populate the WHERE clause
. We then construct our SQL query string using the request parameter passed in from the client code to populate the WHERE clause ![]() .
.
For a more robust server-side implementation, we recommend an Object-Relational Mapping system such as Pear DB_DataObject (see chapter 3) rather than talking directly to the database as we have done here. However, the current implementation is simple and can
be easily configured by readers wanting to test the example for themselves. Having returned the result set, we check whether
it is empty ![]() , and then either iterate over it
, and then either iterate over it ![]() to create the phone entries, or print out the “No Results” message
to create the phone entries, or print out the “No Results” message ![]() .
.
12.3.2. Building the XSLT document
We can use XSLT to transform our XML file into a nice HTML table with only a few lines of code. The XSLT document allows for pattern matching if necessary to display the data in any format we want. The pattern matching uses a template to display the data. We loop through the source tree nodes with the XSLT to display the data. The XSLT takes the structured XML file and converts it into a viewable format that is easy to update and change. Our XSLT document will be defined statically.
Explaining the XSLT structure
An XSLT transformation contains the rules for transforming a source tree into a result tree. The whole XSLT process consists of pattern matching. When a pattern is matched against the source tree elements, the template then creates our result tree.
The result tree structure does not have to be related to the source tree structure. Since they can be different, we can take our XML file and convert it into any format we want. We are not required to stick with a tabular dataset.
This XSLT transformation is called a stylesheet since it styles the result tree. The stylesheet contains template rules, which have two parts. The first part is the pattern, which is matched against the nodes of the source tree. When a match is found, the XSLT processor uses the second part, the template, which contains the tags to build the source tree.
Building the XSLT document
Building the XSLT transformation for this project is rather simple. Since we are developing a table, we won’t need any special pattern matching; instead, we will loop through the source tree element nodes. The template that we’ll develop outputs an HTML table with four columns. Listing 12.6 shows the XSLT file for this project.
Listing 12.6. XSLT file

When we create an XSLT transformation, we need to state the version and encoding ![]() of the XML. The XSLT namespace
of the XML. The XSLT namespace ![]() needs to be specified. The namespace gives the document the rules and specifications that it is expected to follow. The elements in the XML namespace are recognized in the source document and not in the results document. The prefix xsl is used to define all our elements in the XSLT namespace. We can then set the template rule to the match pattern of /
needs to be specified. The namespace gives the document the rules and specifications that it is expected to follow. The elements in the XML namespace are recognized in the source document and not in the results document. The prefix xsl is used to define all our elements in the XSLT namespace. We can then set the template rule to the match pattern of / ![]() , which references the whole document.
, which references the whole document.
We can start building the table template that displays our results. We add the table tag ![]() , giving the table an ID. The table header row
, giving the table an ID. The table header row ![]() is next inserted, which contains the column names to be displayed to the user so she can understand what information is contained
in the table.
is next inserted, which contains the column names to be displayed to the user so she can understand what information is contained
in the table.
By looping through the source node set, we obtain the remaining rows of the table. For this, we use the for-each loop ![]() to iterate over the records to obtain the nodes that are located in phonebook/entry.
to iterate over the records to obtain the nodes that are located in phonebook/entry.
The column values have to be selected as we are looping through the document tree. To select the values from the nodes, we
use value-of ![]() , which extracts the value of an XML element and adds it to the output stream of the transformation. To specify the XML element
whose text we want to retrieve, we use the select attribute with the element’s name. Now that we have built the XSLT file and created the code to dynamically generate the
XML document, we can finish building the JavaScript code to see how the XSLT transformation structures our XML file into a
viewable table when we combine them.
, which extracts the value of an XML element and adds it to the output stream of the transformation. To specify the XML element
whose text we want to retrieve, we use the select attribute with the element’s name. Now that we have built the XSLT file and created the code to dynamically generate the
XML document, we can finish building the JavaScript code to see how the XSLT transformation structures our XML file into a
viewable table when we combine them.
The next step takes us back to the client, which retrieves the files that we just created with the HTTP response.
12.4. Combining the XSLT and XML documents
Back on the client, we need to combine the XSLT and XML documents from the server. When using an XSLT transformation, we’ll find that the browsers differ on how they combine the two documents. Therefore, we first check to see what method the browser supports in order to load and combine our two documents.
Again we’re using the ContentLoader object, introduced in chapter 3. It is contained in the external JavaScript file, net.js. This file does all of the work of determining how to send the information to the server, hiding any browser-specific code behind the easy-to-use wrapper object.
<script type="text/javascript" src="net.js"></script>
Now we can begin the process of obtaining the server-side files and combining them on the client. In listing 12.7, the LoadXMLXSLTDoc() function is being called from the function GrabNumber() in listing 12.2. The function GrabNumber() passes in the values for the URL that generates the XML data, the XSL file, and the output reference ID. With these three values, we are able to load the two documents and combine them when both have been completely loaded. After they have been loaded, we have to do some cross-browser coding in order to combine the XML and XSL files. You can see all of this happening in listing 12.7.
Listing 12.7. LoadXMLXSLTDoc
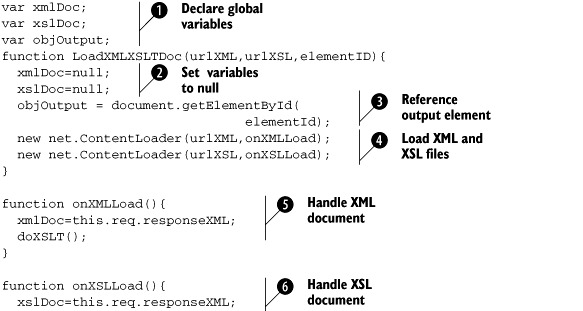
To simplify the client-side script, we need to declare three global variables ![]() to hold three different objects. The first two variables, xmlDoc and xslDoc, are going to hold the XML and XSLT files returned from the server. The third variable, objOutput, holds the object reference to our DOM element where the results are to be inserted. With these variables defined, we can
now build the function LoadXMLXSLTDoc(), which we invoked from the function GrabNumber().
to hold three different objects. The first two variables, xmlDoc and xslDoc, are going to hold the XML and XSLT files returned from the server. The third variable, objOutput, holds the object reference to our DOM element where the results are to be inserted. With these variables defined, we can
now build the function LoadXMLXSLTDoc(), which we invoked from the function GrabNumber().
Since we are loading two documents, we need a way to determine when they are both loaded. We do this by looking to see if
the variables xmlDoc and xslDoc contain their respective documents. Before we start, we must set the variables to null ![]() . This removes any data that may exist in the variables if this function is run more than once on the page. The output location
for the results is set
. This removes any data that may exist in the variables if this function is run more than once on the page. The output location
for the results is set ![]() by using the passed element ID from the function call. Now we call the ContentLoader
by using the passed element ID from the function call. Now we call the ContentLoader ![]() twice, once for the XML document and once for the XSL document. In each call, the ContentLoader will get the URL and then
call another function to load the documents. onXMLLoad()
twice, once for the XML document and once for the XSL document. In each call, the ContentLoader will get the URL and then
call another function to load the documents. onXMLLoad() ![]() loads the returned XML results into our global variable xmlDoc and then calls the function doXSLT() for future processing. onXSLLoad()
loads the returned XML results into our global variable xmlDoc and then calls the function doXSLT() for future processing. onXSLLoad() ![]() loads the XSL document into the global variable xslDoc and also calls the doXSLT() function.
loads the XSL document into the global variable xslDoc and also calls the doXSLT() function.
Processing cannot continue until both documents have been loaded, and there is no way of knowing which will be loaded first,
so the doXSLT() function first checks for that. It is called twice, once after the XML document is loaded and once after the XSL document
is loaded. The first time it is called, one of our global variables is still set to null and we exit the function ![]() . The next time it is called, the function will not exit since neither of the variables will be null. With both documents now loaded, we are able to perform the XSLT transformation
. The next time it is called, the function will not exit since neither of the variables will be null. With both documents now loaded, we are able to perform the XSLT transformation ![]() .
.
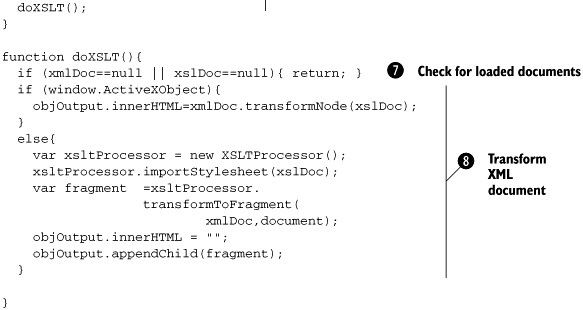
Once the two documents are loaded, we need to transform the XML document with the XSLT. As you can see by looking at the code in the listing, there are two different ways to do this, depending on the browser. Internet Explorer uses transformNode(), whereas Mozilla uses the XSLTProcessor object. Let’s examine these two different implementations of performing the transformation in greater detail.
12.4.1. Working with Microsoft Internet Explorer
Internet Explorer makes it easy to transform the XML document with the XSLT with only a few lines of code. We use the transformNode() method, which takes the XML and XSLT documents and combines them in one step:
if (window.ActiveXObject){
objOutput.innerHTML=xmlDoc.transformNode(xslDoc);
}
We first check to see if the browser supports the transformNode() method. We’ve done this here by testing for ActiveX object support. If it supports it, we call the transformNode() method on the global variable containing our XML data, passing it the global variable containing our XSLT data. The result of this transformation is added to the innerHTML of our result element, which then contains the newly formatted search results.
Now that we are able to format the results for Internet Explorer, let’s get this functioning for Mozilla-compatible browsers.
12.4.2. Working with Mozilla
With Mozilla, we need to use the XSLTProcessor object, which lets us combine the XML and XSLT documents. Note that even though Opera and Safari both support the XMLHttpRequest object, they still do not support the XSLTProcessor object, and they cannot run this project without support from the server (we will address this issue in section 12.5.2). In the listing 12.8, we transform the XML document using the XSLT and display the formatted result set.
Listing 12.8. Invoking XSLT for Mozilla
else{
var xsltProcessor = new XSLTProcessor();
xsltProcessor.importStylesheet(xslDoc);
var fragment=xsltProcessor.transformToFragment(xmlDoc,document);
objOutput.innerHTML = "";
objOutput.appendChild(fragment);
}
The first step is to initialize the XSLTProcessor object, which enables us to join the XML and XSLT files together. The importStylesheet method of the XSLTProcessor object allows us to import the XSLT file so that we can join it to the XML file in the upcoming steps. When the XSLT file is loaded into the processor, we are left with transforming the XML document. The XSLTProcessor is used again with a new method called transformToFragment(). The transformToFragment() method takes the XML file and combines it with the XSLT, and then returns the formatted result tree.
We replace the content that exists in our result element by setting the innerHTML with a blank string. This removes our loading animation from the page. Finally, we take the result we obtained from the transformToFragment() method and append it to the element. The newly formatted search results are now displayed to the user.
This code introduced some new concepts to us, including the XSLTProcessor object, which allows us to combine arbitrary XML and XSLT files. The Mozilla and Firefox browsers require us to use more DOM methods to combine the two documents. Internet Explorer, on the other hand, required only a single line of code to transform the XML document. The overall end result is exactly the same: they both show our results formatted according to the XSLT file.
Now that the client-side code is finished, we can save our documents and run a test of our live search. Enter some text into the textbox, and click the search button. The results should appear in the table format shown in figure 12.4.
Figure 12.4. The search results are displayed from the Ajax live search.

As you can see, we have finished building our XSLT document and were able to run a successful search. The table displayed in figure 12.4 is rather dull since it has no formatting. That means the only thing that we have left to do is style our results table to make it more visually appealing. To do that, we need to use Cascading Style Sheets (CSS).
12.5. Completing the search
Now that we have combined our XML and XSLT documents to get our results, we need to enhance the style of the search results by applying CSS to our elements. Styling the elements will make it easier for the users to read the results. The first step in improving the user experience is to apply our CSS rules to the HTML elements.
12.5.1. Applying a Cascading Style Sheet
We introduced Cascading Style Sheets in chapter 2. A Cascading Style Sheet will make the results look professional with a minimum amount of effort on our part, separating the presentation of the results from the document structure and from the transformation logic. Along the way, if the manager or client hates the colors, we can make the changes quickly and easily. If we’re on a large project with separate design and coding teams, CSS helps to keep them from treading on each other’s toes. We can either include the stylesheet as an external file on our search page or embed the code into the search page. Using an external CSS file is preferable since it is cached by the browser and decreases the page-loading time in the future. The stylesheet rules are shown in listing 12.9.
Listing 12.9. Cascading Style Sheet

The first CSS rule we are applying is to the table tag ![]() . In this case, we want to make the border a solid-black line one pixel wide. We set the table’s border-collapse property to collapse. The collapse CSS model basically allows the properties of the table to be uniform. The borders become even thicknesses,
with adjacent cells sharing borders rather than accumulating to double or triple thicknesses. The final step for the table tag is to set the table width property. In this case, we are setting the width of the table to 50% of the div that it is contained in since we are not returning a large number of columns. Each of our columns will contain only a small
amount of data, so the table does not need wide spacing.
. In this case, we want to make the border a solid-black line one pixel wide. We set the table’s border-collapse property to collapse. The collapse CSS model basically allows the properties of the table to be uniform. The borders become even thicknesses,
with adjacent cells sharing borders rather than accumulating to double or triple thicknesses. The final step for the table tag is to set the table width property. In this case, we are setting the width of the table to 50% of the div that it is contained in since we are not returning a large number of columns. Each of our columns will contain only a small
amount of data, so the table does not need wide spacing.
After styling the table element, our next step is to format the table’s body and header cells ![]() . Just as we did for the table, we are setting the border to be a solid-black one-pixel line. We insert padding into the cells
so that the text is not sitting directly on the cell borders. We also set the width property of the cells to 25% of the width of the table so that all four columns are uniform in size.
. Just as we did for the table, we are setting the border to be a solid-black one-pixel line. We insert padding into the cells
so that the text is not sitting directly on the cell borders. We also set the width property of the cells to 25% of the width of the table so that all four columns are uniform in size.
The final step to apply CSS to our table is to change the properties of the header cell so it stands out from the body cell.
We reference the header cell ![]() and change the background-color of the cell to a shade of gray. We can change other properties here, such as font-weight, color, and so on. After we finish applying the stylesheet properties, we save our document and run the same search again. Our new formatted table is shown in
figure 12.5.
and change the background-color of the cell to a shade of gray. We can change other properties here, such as font-weight, color, and so on. After we finish applying the stylesheet properties, we save our document and run the same search again. Our new formatted table is shown in
figure 12.5.
Figure 12.5. The search results are displayed from the Ajax live search with CSS applied to the elements.

As you can see, the table has a structured format that was easily created by applying CSS properties to our table elements. If we wanted to add more functionality to our stylesheet, we could add class references to the XSLT file to make it even more flexible. CSS lets us customize the table any way we want, but we may want to improve the search in other areas as well.
12.5.2. Improving the search
One of the benefits of Ajax is that it’s easy to pass information back to the server. This project was a simple exercise for creating a search utilizing Ajax and XSLT to display a formatted results table with a minimum amount of effort. We can make the live search as sophisticated as we want. Let’s look at some ways to improve it.
Including new features
The search form we created uses a single textbox and a single submit button to perform the search. We can easily adapt this search to use multiple parameters, such as additional search parameters with the contact name or country. All we have to do is send the additional parameters back to the server and have the server-side code check for them. That means the users can have additional ways to look for information, making the form more useful.
We could add other Ajax features to this script, such as the double combination script, as we did in chapter 9. This would help reduce the possibilities from which the user can choose. We can implement techniques from chapter 10 with the type-ahead suggest, too.
Supporting Opera and Safari
If you recall, we have a problem with Opera and Safari not supporting either the transformNode() method or the XSLTProcessor object. We have two options for supporting Opera and Safari. The first one is to use Ajax to send the files to a server-side page for processing. The server-side code can combine the XML and XSLT documents. We would then fetch the result of the transformation using a single ContentLoader object, rather than fetching the XML data and the XSLT stylesheet independently. This is not the best solution since we have to use two round-trips to perform the transformation.
Our second option is to submit the entire page back to the server without the use of Ajax. The server in this case would handle the submission and combine the XML and XSLT documents on the server as we would do traditionally. This approach is better because it lets all users use the search. If a person is using an early version of a browser that does not support the XMLHttpRequest object, then that user can use the form. If we used the Ajax-only technique, the people without the ability to use Ajax would not be able to retrieve the two files for processing. Our second approach gives them the ability to use the form since Ajax is not required. In order to add this functionality, we need to make two changes to the LoadXMLXSLTDoc() function, as shown in listing 12.10. We must alter the first if statement to include a check for the XSLT processor. Then we must add an else statement to force the submit back to the server.
Listing 12.10. Altering LoadXMLXSLTDoc to support Opera and Safari
function LoadXMLXSLTDoc(urlXML,urlXSL,elementID){
var reqXML;
var reqXSL;
if (window.XMLHttpRequest && window.XSLTProcessor){
//...do Mozilla client XSLT
}else if (window.ActiveXObject){
//...do Internet Explorer client XSLT
}else{
document.Form1.onsubmit = function(){return true;}
document.Form1.submit();
}
}
In listing 12.10, we remove the onsubmit event handler inside the else branch of the conditional check so that we submit the form to the server. Without removing the onsubmit handler, the form would not submit back to the server.
The server-side page then has to do all of the processing and put the element on the form. In return, we get a fast response for those users who can combine XSLT with JavaScript, and we do not alienate the users who do not support Ajax or the XSLTProcessor. Remember that Ajax is giving us the benefit of not having to re-render the entire page, which can lose the current state of the page. We do not have to worry about the scroll position, form values, and so on. Since we were able to solve this problem with Opera and Safari, that is one less argument we have to face when determining whether it is a wise solution to use an XSLT transformation.
12.5.3. Deciding to use XSLT
One of the discussions that we may have with our development team or boss is why we’re using XSLT in the first place. The argument starts out with “You have to generate the XML file dynamically on the server, so why don’t you just generate the results table instead?”
The major point that our fellow developers are trying to make is that we are using more processing in order to display the results to the user. That is true in the sense that the web page has to perform extra work when the browser renders the results table. Instead of loading one file, the Ajax code has to load two files, which then have to be combined.
We can dynamically build the table on the server with no major problems. The results table is displayed by using the responseText property of the XMLHttpRequest object and applying the returned value to our HTML element. There is nothing wrong with this method since it means one less step to deal with.
The one problem that we face when building the HTML table with the server-side code is the effort required to update the table if changes need to be made. As we discussed earlier in this chapter, we as developers may face many problems when building the table. We have to worry about quotes, tag syntax, attributes, event handlers, and so much more. If the users want us to change the order of the columns of the results table, we have to alter a bunch of code to perform this task.
By using XSLT, we are taking the building of the table away from our server-side code. The server can build a simplified version of the results table in XML format. XML format is very easy to look at and makes it easy to find mistakes. Also, the XSLT looks like an HTML page. We do not have to sit and count quotation marks or search through strings to see if a tag is there. With XSLT we can look directly at it and know that it is correct.
Another feature is that we can easily take a table layout that a web designer has designed and place it into an XSLT file. If we ever need to make a change such as swapping columns, it is as easy as cutting and pasting the data. No more scratching our heads wondering if the tags are still going to be right when we paste them. By using XSLT, we are removing the processing of the HTML from our dynamic code. This allows us to change the results table without any major problems.
And finally, using JavaScript lets us do some things very easily that we couldn’t do if we did the transformation on the server:
- We can retrieve different XSL documents based on a theme, screen dimensions, language, and so on.
- We can retrieve an XML document and an XSL document without help from the server.
- We can examine an XML log file on our local machine without having control over the XML document structure.
When performing your daily tasks, you’ll find that Ajax gives you so many possibilities.
We still have one issue with the live search that we need to address: allowing the user to bookmark the results page.
12.5.4. Overcoming the Ajax bookmark pitfall
There is one downside to using Ajax to perform searches: Bookmarking the page in the traditional manner is not an option. (This same problem occurs with frames and pop-up windows.) Bookmarks allow us to come back to the search results in the future without having to type in the request information, and they can be easily sent to friends and colleagues by email or messaging. Since an Ajax search does not require a postback to the server, we are not changing the URL of the page during the search, and therefore bookmarking the URL will simply mark the starting point for our application, not the results that we want to preserve.
An easy solution for this is to add a behavior that lets us remember the search. We can build a dynamic string that will be used to create a dynamic bookmark. This dynamic string will contain a direct link to the page it’s on and will include a querystring parameter with the search value. Therefore, when we write this string to the page to form the link, the user can either bookmark it (by right-clicking on the link) or copy the link, and her search will be automatically saved. We add this functionality of reading the querystring value when the page is loaded after we build the link.
The link can be built when our GrabNumber() function is executed. We add another span to our document so that we have a location to put this link on the page. In this case, the span has an ID of spanSave, as you can see in listing 12.11 by looking at the statement where getElementById is invoked. We can position the span wherever we want on the page so it is convenient for the user.
Listing 12.11. Altering the GrabNumber function to integrate a bookmarking link
function GrabNumber(){
var strLink = "<a href='" +
location.href.split("?")[0] + "?q=" +
document.Form1.user.value + "'>Save Search</a>";
document.getElementById("spanSave").innerHTML = strLink;
The code in listing 12.11 generates a dynamic link to our current search page and adds the querystring parameter q with the value of the textbox. The querystring parameter is what allows us to remember the search. This new link is then added to the span on the page so the user can select the link and send it to others or bookmark it by clicking on the link and setting it to their favorites for future use. In listing 12.12, we obtain the querystring value from the URL when the page loads and then perform the search automatically so the results are shown.
Listing 12.12. Obtaining the querystring value and performing the search
window.onload = function(){
var strQS = window.location.search;
var intQS = strQS.indexOf("q=");
if(intQS != -1){
document.Form1.user.value = strQS.substring(intQS+2);
GrabNumber();
}
}
We add a handler for the onload event to our window object that will execute a function when the page is loaded. We check to see if our querystring value is in the URL; if it is, we obtain the value. The querystring value is placed inside the textbox, and then the GrabNumber() function is executed automatically to build the results table. Adding this code lets us bookmark the search pages and have the search results appear when we come to the page, instead of having to type in the value each time. This makes our Ajax project even more user-friendly.
12.6. Refactoring
It’s time to take our XSLT live search to the next level by—you know the drill—componentizing! We need to take this nifty script and refactor it until we have an object-oriented reusable component. So let’s start with the client-side XSLT processing. This example is different than all the others in the sense that it handles all the DOM manipulation aspects of response handling with XSLT. So let’s start there. We should be able to refactor our XSLT processing in such a way that we can use it with other components—not just the live search. Once we do that, we’ll focus on refactoring the live search in such a way that it can be quickly added to any page as an easy-to-use pluggable component.
12.6.1. An XSLTHelper
We’ve gone through a lot of trouble to learn the ins and outs of XSLT processing on the client side. For example, we’ve noticed that there are completely different APIs for doing XSLT processing on the client based on whether we’re targeting an IE browser or a Mozilla-based browser. And each API has its own set of quirks and peculiarities. So, it would be a shame for us not to encapsulate that hard-earned knowledge so that our colleagues who come behind us don’t have to go through the same pains to do some seemingly simple XSLT transformations. Therefore, let’s do just that by creating an XSLTHelper object to encapsulate all of our XSLT concerns.
All XSLT processing typically requires two sources of information: the XML document to transform and the XSL document to provide the transformation rules. With that in mind, let’s write a constructor for our helper that will give us a way to store that state:
function XSLTHelper( xmlURL, xslURL ) {
this.xmlURL = xmlURL;
this.xslURL = xslURL;
}
The constructor is probably one of the simplest you’ve seen in this book yet. It stores the URLs for the documents we just noted: the XML data document and the XSLT transformation document. But before we get too giddy about the simplicity of it all, we need to think about an API to support graceful degradation. You’ll note that our script conditionally performs only XSLT processing if the browser supports it. So if we’re writing a helper, it would be nice for the helper to provide an API to tell the client whether or not it can perform XSLT operations. However, instantiating some object with XSLT in its name just to find out whether XSLT is supported doesn’t seem right. The solution to this conundrum is an API function that’s not scoped to the prototype object but rather to the constructor function itself. We can think of this function much like a static method in the Java world. The intent is that a client should be able to write code that looks something like this:
XSLTHelper.isXSLTSupported();
rather than having to instantiate an object like this:
var helper = new XSLTHelper( 'phoneBook.xml',
'transformation.xsl' );
var canDoThis = helper.isXSLTSupported();
So let’s accommodate our inquisitive users with a pseudo-static method, which is expressed as follows:
XSLTHelper.isXSLTSupported = function() {
return (window.XMLHttpRequest && window.XSLTProcessor ) ||
XSLTHelper.isIEXmlSupported();
}
XSLTHelper.isIEXmlSupported = function() {
if ( ! window.ActiveXObject )
return false;
try { new ActiveXObject("Microsoft.XMLDOM");
return true; }
catch(err) { return false; }
}
There’s nothing new here. The logic is identical to the logic defined earlier; we’ve just encapsulated that knowledge about how to detect XSLT support. I’m sure someone will thank us for this. So now we can get on to the business of fleshing out the rest of the XSLTHelper API.
Let’s keep things simple. How about saying that we’ll have a single method for clients of our class to call to perform XSLT processing? Our helper will have ancillary methods to separate the responsibilities of all the internal logic, but we’ll provide a single API for our clients to use. The semantics will be as follows:
var helper = new XSLTHelper ( 'phoneBook.xml',
'transformation.xsl' );
helper.loadView( 'someContainerId' );
In this example usage, the phoneBook.xml document should be transformed into HTML by the transformation.xsl document, and the resulting HTML should be placed within the element whose ID is someContainerId. Let’s further specify that the parameter to loadView() can be either a string representing the ID of an element or the element itself. We’ll internally figure out what we’re dealing with and react accordingly. And, by the way, if the client doesn’t care to reuse the helper instance, we can express all this with a single line of code:
new XSLTHelper('phoneBook.xml',
'transformation.xsl').loadView('someContainerId'),
Now that we’ve defined our API and its semantics, let’s implement it as shown in listing 12.13.
Listing 12.13. The loadView method

The first thing the loadView() method does is makes sure it’s operating within a browser runtime that supports XSLT ![]() . The client should have already done this, as in our earlier example, but just in case the user of our code is sloppy, we
take a better-safe-than-sorry approach and check again. Second, the method sets the state variables holding the XML and XSL
documents to null and sets the reference to the container to be updated
. The client should have already done this, as in our earlier example, but just in case the user of our code is sloppy, we
take a better-safe-than-sorry approach and check again. Second, the method sets the state variables holding the XML and XSL
documents to null and sets the reference to the container to be updated ![]() . Lastly, we send the Ajax requests to retrieve the XML and XSL documents
. Lastly, we send the Ajax requests to retrieve the XML and XSL documents ![]() . When the server responds to the request for the XML document, the setXMLDocument() method is called. Likewise, when the server responds to the request for the XSL document, the setXSLDocument() method is called. These functions are shown in listing 12.14.
. When the server responds to the request for the XML document, the setXMLDocument() method is called. Likewise, when the server responds to the request for the XSL document, the setXSLDocument() method is called. These functions are shown in listing 12.14.
Listing 12.14. Setting the XML and XSL documents
setXMLDocument: function(request) {
this.xmlDocument = request.responseXML;
this.updateViewIfDocumentsLoaded();
},
setXSLDocument: function(request) {
this.xslStyleSheet = request.responseXML;
this.updateViewIfDocumentsLoaded();
},
These methods set the state variables of the XSLTHelper corresponding to the XML document and XSL document, respectively. They then call the updateViewIfDocumentsLoaded() method, which checks to see if both documents have been initialized, and if this is the case, updates the view. The updateViewIfDocumentsLoaded() method is implemented as shown here:
updateViewIfDocumentsLoaded: function() {
if ( this.xmlDocument == null || this.xslStyleSheet == null )
return;
this.updateView();
},
Once both responses have come back from the server, we are ready to update the UI. We know that both responses have come back when both the this.xmlDocument and the this.xslStyleSheet state variables are non-null. The updateView() method is shown in listing 12.15.
Listing 12.15. Updating the view
updateView: function () {
if ( ! XSLTHelper.isXSLTSupported() )
return;
if ( window.XMLHttpRequest && window.XSLTProcessor )
this.updateViewMozilla();
else if ( window.ActiveXObject )
this.updateViewIE();
},
As we’ve noted already, we require different implementations for each browser type being supported, so we’ve separated out the details. Let’s look at each implementation, beginning with the Mozilla implementation, shown in listing 12.16.
Listing 12.16. Updating the view in Mozilla

The specific update implementations, whether IE or Mozilla, perform two basic steps: ![]() performing the XSLT transformation, and
performing the XSLT transformation, and ![]() updating the UI with the result. Recall that the result of the Mozilla transformation process is a document fragment that
is added to an element via appendChild(), whereas the IE transformation results in a string that is added via the innerHTML property. So with that in mind, the updateViewIE() implementation is shown here:
updating the UI with the result. Recall that the result of the Mozilla transformation process is a document fragment that
is added to an element via appendChild(), whereas the IE transformation results in a string that is added via the innerHTML property. So with that in mind, the updateViewIE() implementation is shown here:
updateViewIE: function() {
this.container.innerHTML =
this.xmlDocument.transformNode(this.xslStyleSheet);
},
The same two steps are performed in the IE implementation, which is a good deal more compact because the steps of applying the transformation and updating the UI are all done in a single line of code. As to which one is more efficient, we’ll let you decide.
Our XSLTHelper is now complete, and we have a clean, simple, one-method API for performing XSLT transformations. Our helper should prove to be very useful and more than worth the relatively small amount of effort we have put into it. Now let’s refocus our efforts on the live search and contemplate a simple component design.
12.6.2. A live search component
Now that we have some sweet XSLT help in our back pocket, let’s implement our live search script as a component that uses it. The component should satisfy the component requirements that we’ve discussed in detail in our other refactoring examples. These include such things as providing a clean API, being configurable while providing appropriate default values, being unobtrusive to the surrounding HTML, and being able to have multiple instantiations on a page. Let’s develop a clean object-oriented solution with the guiding principle that each responsibility should be encapsulated in a dedicated method. One responsibility, one method. With that in mind, let’s get started in the usual place—considering construction.
From the perspective of component state, the live search component has to keep track of more “stuff” than most other components we’ve written. It needs to know about an XML document source, an XSL document source, a field that initiates the search, and the URL of the page that it should use to support bookmarking. So, that means our constructor is going to be a little heavier in this example than in previous ones. However, it should still be quite manageable. Let’s take a stab at a live search constructor now:
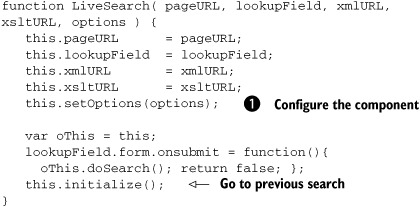
The first four arguments of our constructor are the things we just indicated we’d have to keep up with: the URL of the page,
the search field, and the two document URLs. The last parameter is our familiar options parameter for providing component configurability. The options argument is passed to the setOptions() method, which, as you recall, provides some default values for all configurable data ![]() . Let’s look briefly at the defaults before moving on:
. Let’s look briefly at the defaults before moving on:
setOptions: function(options) {
this.options = options;
if ( !this.options.loadingImage )
this.options.loadingImage = 'images/loading.gif';
if ( !this.options.bookmarkContainerId )
this.options.bookmarkContainerId = 'bookmark';
if ( !this.options.resultsContainerId )
this.options.resultsContainerId = 'results';
if ( !this.options.bookmarkText )
this.options.bookmarkText = 'Bookmark Search';
},
The setOptions() method is not as succinct as its counterpart in the TextSuggest component (see chapter 10), which used the Prototype library’s extend() method to make the expression of this nice and compact. This method performs the same chores, however, and provides default values for the loading image, the ID of the element to contain the bookmark, the ID of the element to contain the result data, and, finally, the text of the generated bookmark. Recapping the mechanism, any values to these properties that live in the options object passed in by the user will override the defaults that are specified here. The resulting options object is a merged set of defaults and their overrides in a single object. These options are then used at the appropriate points throughout the rest of the example to configure the component.
With component configurability and defaults squared away, let’s turn our attention back to the constructor for a moment and recall these two unassuming lines of code:
var oThis = this;
lookupField.form.onsubmit = function(){
oThis.doSearch(); return false; };
You will recall that our script in its original form modified the HTML by putting an onsubmit handler on the search form:
<form name="Form1" onsubmit="GrabNumber();return false;">
Because we are striving to make our components as unobtrusive as possible, at least in terms of the amount of HTML that needs to be modified to use them, the same functionality has been provided by these two aforementioned lines of our constructor. The difference from a naming point of view is that we’ve renamed GrabNumber() to a more generic name, doSearch(), and doSearch() is a method of our component rather than a global function. Speaking of which, let’s now take a look at the doSearch() method implementation:
doSearch: function() {
if ( XSLTHelper.isXSLTSupported() )
this.doAjaxSearch();
else
this.submitTheForm();
},
Our smarty-pants component knows that it should be checking for XSLT support before trying to actually do XSLT processing, so the search method uses the XSLTHelper API we wrote earlier to determine whether to use XSLT processing or to just do a standard form submission. Pretty smart indeed. Our client can just call the doSearch() method and not have to worry about whether it’s doing XSLT. We’ve taken care of all the worrying for it. Let’s take each of the two forms of searching and look at them in detail. Because the form submission is simpler, we’ll look at it first:
submitTheForm: function() {
var searchForm = this.lookupField.form;
searchForm.onsubmit = function() { return true; };
searchForm.submit();
},
This method simply finds the reference to the appropriate form through the lookup field and changes its onsubmit to a function that returns true. This allows the search request to be submitted back to the server in an explicit way. Then the method just calls the submit() method of the native HTML form, which causes a traditional form submission. In this scenario, the component assumes that there is an appropriate action attribute of the form and that the result of the action returns an appropriate page with search results.
Now let’s look at the Ajax implementation of searching:
doAjaxSearch: function() {
this.showLoadingImage(); Show loading image
var searchUrl = this.appendToUrl( this.xmlURL,
'q',
this.lookupField.value); Formulate URL
new XSLTHelper(searchUrl, Perform XSLT processing
this.xsltURL).loadView(
this.options.resultsContainerId);
this.updateBookmark (); Update bookmark
},
The doAjaxSearch() method performs the same steps that the first iteration of our script did, but it puts each step into a method to perform each responsibility. At this point, you might object and say that this method has four responsibilities. Well, actually it just has one: searching. However, the responsibility of searching has four parts, each a responsibility on its own. So let’s look at each in turn:
This method gets the container element and the text for the bookmark from the options object. The URL for the generated bookmark is the value passed into the constructor as the pageURL argument. The q= parameter with the value of the current search are appended to that URL. The innerHTML property of the container is updated with all of these values to produce the appropriate URL.
If a bookmark is stored and used to hit our page, the user is returned to our page with a q=someValue parameter. But what initiates the search to produce the result? Recall that the final line of the constructor called this.initialize();. We’ve not peeked at what that actually does yet, so we should do so now. As you’ve probably guessed, the initialize() method is there to support our bookmarking feature. The implementation is as follows:
initialize: function() {
var currentQuery = document.location.search;
var qIndex = currentQuery.indexOf('q='),
if ( qIndex != -1 ) {
this.lookupField.value =
currentQuery.substring( qIndex + 2 );
this.doSearch();
}
},
The initialize() method takes the current location of the document and looks for a parameter named q in the querystring. If one exists, it parses the value of the parameter and places it into the lookup field. Then, it simply initiates a search via the doSearch() method. Mystery solved.
12.6.3. Refactoring debriefing
Let’s take a moment to consider what we’ve accomplished so far. We’ve written a helper class called XSLTHelper, which encapsulates the hard-earned knowledge of providing XSLT support on the browser client. We’ve taken advantage of that helper in our live search component. We’ve written a simple yet generic configurable live search component that can take just a few pieces of information and transform the user’s web page into a responsive searching animal. We’ve written our component in a clean OO style that exemplifies simple design and separation of responsibilities. Overall, not bad for a day’s work.
12.7. Summary
In this chapter, we took a basic search page and added Ajax functionality to it. The search allows the process to flow so that we can control the window while the server-side process is taking place. This means that we are able to place an animation in the browser. Having control of the browser allows us to perform other operations so we can make sure that the users of the application know that their search is taking place.
We then implemented XSLT processing to transform our XML document into formatted HTML code, which we applied to our div element’s innerHTML property. This let us avoid using JavaScript to dynamically loop through the XML nodes and build a large string to apply to the document. Instead, we could rely on XSLT to produce the document from the XML.
Just because we used the processing animation and the XSLT with the live search does not mean we cannot apply these concepts to other projects. We can easily add this capability to a normal transaction with the server. I always hear people say that they have a process that takes several minutes to complete. Is there a way to show a message? We can easily use the innerHTML property that we used in this project to add an image or message telling the user that the processing of the search is under way. With almost every Ajax application, we should show that an action is taking place so the user does not repeatedly click the submit or the refresh buttons.
We can use XSLT to style RSS feeds or to change any of the other projects that we have done by using XSLT instead of performing the XML DOM looping on the client.
In the four examples that we’ve developed so far, we’ve implemented our own server-side processes specifically to serve our Ajax clients. In the final chapter, we’ll look at an Ajax client that communicates directly to an Internet standard web service: an RSS news syndication feed.