
The foundation of Solr is based on Lucene's index—the subject of this chapter. In this chapter, you will learn about:
- Schema design decisions in which you map your source data to Lucene's limited structure. In this book, we'll consider the data from www.MusicBrainz.org.
- The structure of the
schema.xmlfile, where the schema definition is defined. This file contains both the definition of field types and the fields of those types that store your data.
The following diagram shows the big picture of how various aspects of working with Solr are related. In this chapter, we will focus on the foundational layer—the index:
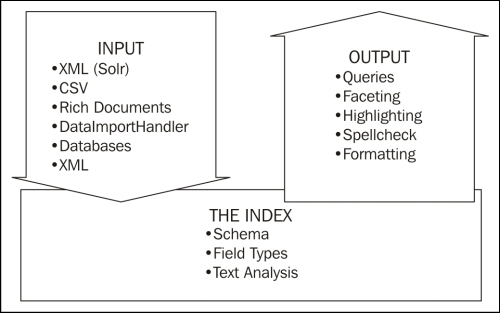
Solr supports a rich schema specification that allows for a wide range of flexibility in dealing with different document fields and has a "free" schema, in that, you don't have to define all of your fields ahead of time using dynamic fields. There are discussions in the search and NoSQL communities questioning the value in a schema. Having the ability to configure the fields in a configuration file, outside the actual code, gives more flexibility and makes us think about the data and business needs, which are key for any successful search engine.
Grant Ingersoll, Lucene and Solr committer, cofounder of the Apache Mahout machine learning project, and a long standing member of the Apache Software Foundation, has the following insightful commentary on the subject:
As for the notion of "schemaless", it's a bit of a marketing term, no? ("Less" schema is probably better, but it doesn't roll off the tongue now does it?) What is really meant by it, as far as I can tell, is that the system uses convention over configuration and that it is easy to change it to adapt to business needs. ElasticSearch has a schema, it's just implied by your JSON and its preset configuration. And if you don't like it you can programmatically go change it, thereby embedding your schema into your code. In Solr, you can also have convention over configuration via dynamic fields and by naming your fields accordingly. There is also work under way to be able to use other conventions programmatically. And I don't know about you, but is opening up a config file and making a few edits really that hard, especially when it makes you think about your data?
You can find the source at http://www.ymc.ch/en/why-we-chose-solr-4-0-instead-of-elasticsearch.