
A key thing to come to grips with is that the queries you need Solr to support completely drive your Solr schema design. This is very important to understand. Conversely, relational databases typically use standard third normal form decomposition of the data, largely because they have strong SQL relational-join support. Since queries drive the Solr schema design, all the data needed to match a document, that is, the criteria, should be in the document matched, not in a related one. To satisfy that requirement, data that would otherwise exist in one place is copied into related documents that need it to support a search. For example, an artist's name in MusicBrainz will not just exist on an artist document but also in a track document to support searching for tracks by artist. Solr 4's new Join support allows this design principle to be relaxed; however, it's not as capable as a SQL join and is often slow, so only consider this as a last resort.
At this point, we're going to outline a series of steps to follow in order to arrive at one or more Solr schemas to power searches for an application of any sort. For specifics, we will consider the www.MusicBrainz.org website and how it could work, hypothetically. It goes as far as listing the fields but not into text analysis or making changes for particular search features, such as faceting. In truth, schema design is somewhat creative and is always evolutionary—so consider these steps as a guide for your first time at it, though not a foolproof process.
Any text search capability is going to be Solr powered. At the risk of stating the obvious, we're referring strictly to those places where a user types in a bit of text and subsequently gets some search results. On the MusicBrainz website, the main search function is accessed through the form that is always present on the top. There is also a more advanced form that adds a few options but is essentially the same capability present on the search menu page, and we treat it as such from Solr's point of view. We can see the MusicBrainz search form in the following screenshot:
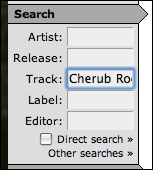
Once we look through the remaining steps, we may find that Solr should additionally power some faceted navigation in areas that are not accompanied by text search (that is, the facets are of the entire dataset, not necessarily limited to the search results of a text query alongside it). An example of this at MusicBrainz is the Top Voters tally, which we'll address soon.
For the MusicBrainz search form, this is easy. The entities are: artists, releases, tracks, labels, and editors. It just so happens that in MusicBrainz, a search will only return one entity type. However, that needn't be the case. Note that internally, each result from a search corresponds to a distinct document in the Solr index and so each entity will have a corresponding document. This entity also probably corresponds to a particular row in a database table, assuming that's where it's coming from.
For each entity type, find all of the data in the schema that will be needed across all searches of it. By "all searches of it", we mean that there might actually be multiple search forms, as identified in Step 1 – determine which searches are going to be powered by Solr. Such data includes any data queried for (that is, criteria to determine whether a document matches or not) and any data that is displayed in the search results. The end result of denormalization is to have each document sufficiently self-contained, even if the data is duplicated across the index(es).
Tip
Solr 4 has a new feature called Joins, which allows a query to match a document based on data in another document related by some field in common. It can be used as an alternative to denormalization when denormalization is impractical due to ballooning index size or for some complex one-to-many query scenarios described soon. A Join query is fairly slow, so always prefer denormalization when you can. See Chapter 5, Searching, for more information on Joins.
Let's see an example. Consider a search for tracks matching Cherub Rock:
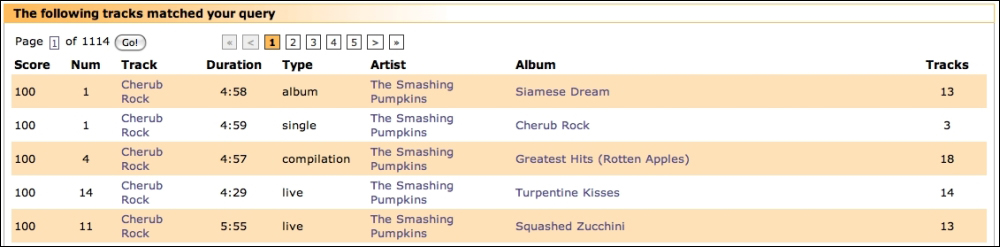
A MusicBrainz track's name and duration are definitely in the track table, but the artist and album names are each in their own tables in the MusicBrainz schema. This is a relatively simple case, because each track has no more than one artist or album. Both the artist name and album name would get their own field in Solr's flat schema for a track. They also happen to be elsewhere in our Solr schema, because artists and albums were identified in Step 2 – determine the entities returned from each search. Since the artist and album names are not unambiguous references, it is useful to also add the IDs for these tables into the track schema to support linking in the user interface, among other things.
One-to-many associations can be easy to handle in the simple case of a field requiring multiple values. Unfortunately, databases usually make this harder than it should be if it's just a simple list. However, Solr's fields directly support the notion of multiple values. Remember that in the MusicBrainz schema, an artist of type group can have some number of other artists as members. Although MusicBrainz's current search capability doesn't leverage this, we'll capture it anyway because it is useful for more interesting searches. The Solr schema to store this would simply have a member name field that is multivalued. The member_id field alone would be insufficient, because denormalization requires that the member's name be copied into the artist. This example is a good segue to how things can get a little more complicated.
If we only record the member name, it is problematic to do things such as have links in the UI from a band member to that member's detail page. This is because we don't have that member's artist ID, but only their name. So we'll add a multivalued field for the member's ID. Multivalued fields maintain ordering so that the two fields would have corresponding values at a given index. If one of the values is optional, remember to supply an empty string placeholder to keep the field values aligned. The client code would have to know about this placeholder.
The following diagram represents an example of one-to-many associations:

Tip
What you should not do is try to shove different types of data into the same field by putting both the artist IDs and names into one field. It could introduce text analysis problems, as the field would have to satisfy both types, and it would require the client to parse out the pieces. The exception to this is when you are merely storing it for display, not searching for it. Then, you can store whatever you want in a field.
A problem with denormalizing one-to-many data comes into play when multiple fields from the other entity are brought in, and you need to search on more than one of those fields at once. For a hypothetical example, imagine a search for releases that contain a track with a particular word in the name and with a particular minimum duration. Both the track name and duration fields on a release would be multivalued, and a search would have criteria for both. Unfortunately, Solr would erroneously return releases in which one track name satisfies the criteria and a separate track duration satisfies the criteria but not necessarily for the same track. One workaround is to search for the track index instead of the release one, and to use Solr's new feature, result grouping, also known as field collapsing, to group by release. This solution, of course, depends on an additional index holding entity relationships going the other way. If you are faced with this challenge but can't create this additional index because the index would be prohibitively large for your data, then you will have to use Solr 4's Join feature. See Chapter 5, Searching, for more information on Joins.
It's not likely that you will actually do this, but it's important to understand the concept. If there is any data shown on the search results that is not queryable, not sorted upon, not faceted on, nor are you using the highlighter feature for, and for that matter you are not using any Solr feature that uses the field except to simply return it in search results, then it is not necessary to include it in the schema for this entity. Let's say, for the sake of argument, that when doing a query for tracks, the only information queryable, sortable, and so on is a track's name. You can opt not to inline the artist name, for example, into the track entity. When your application queries Solr for tracks and needs to render search results with the artist's name, the onus would be on your application to get this data from somewhere—it won't be in the search results from Solr. The application might look these up in a database, in some caching middleware, or perhaps even query our Solr artist index.
This clearly makes generating a search results screen more difficult, because you now have to get the data from more than one place. Moreover, to do it efficiently, you would need to take care to query the needed data in bulk, instead of each row individually. Additionally, it would be wise to consider a caching strategy to reduce the queries to the other data source. It will, in all likelihood, slow down the total render time too. However, the benefit is that you needn't get the data and store it into the index at indexing time. It might be a lot of data, which would grow your index, or it might be data that changes often, necessitating frequent index updates.
If you are using distributed search, as discussed in Chapter 9, Integrating Solr, there is some performance gain in not sending too much data around in the requests. Let's say that you have song lyrics for each track, it is distributed on 20 machines, and you get 100 results. This could result in 2,000 records being sent around the network. Just sending the IDs around would be much more network-efficient; however, this leaves you with the job of collecting the data elsewhere before display. The only way to know if this works for you is to test both scenarios. In general, if the data in question is not large, then keep it in Solr.
At the other end of the extreme is storing all data in Solr. Why not? At least in the case of MusicBrainz, it wouldn't be appropriate. Take the Top Voters tally, for example. The account names listed are actually editors in MusicBrainz terminology. This piece of the screen tallies an edit, grouped by the editor who performed the edit. It's the edit that is the entity in this case. The following screenshot shows the Top Voters (also known as editors), which are tallied by the number of edits:
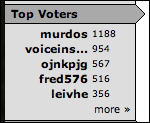
This data simply doesn't belong in an index, because there's no use case for searching edits, only lookup when we want to see the edits on some other entity like an artist. If you insisted on having the voter's tally (as previously seen) powered by Solr, then you'd have to put all this data (of which there is a lot!) into an index, just because you wanted a simple statistical list of top voters. It's just not worth it!
One objective guide to help you decide on whether to put an entity in Solr or not is to ask yourself whether users will ever be doing a text search on that entity—a feature where index technology stands out from databases. If not, then you probably don't want the entity in your Solr index.