
Functions, known internally as
ValueSources, are typically mathematical in nature; they take constants and references to single-valued fields and other functions as input to compute an output number. Functions complement typical queries by enabling you to boost by a function, to sort by a function, to return a value from a function in search results, to filter by a range of values from a function, and they can be used in clever ways wherever Solr accepts a query, such as facet.query. They are very versatile, though they are usually only used for custom relevancy boosting.
There are quite a few ways in which you can incorporate a function into your searches in Solr:
- Dismax query parser using the bf or boost parameters: These two parameters add or multiply the function to the score of the user's query for boosting. They were previously described in the chapter, but you'll see in-depth examples coming up.
- Boost query parser: Like DisMax's
boostparameter, this query parser lets you specify a function that is multiplied to another query. The query string is parsed by the Lucene query parser. Here's an example query:q={!boost b=log(t_trm_lookups)}t_name:Daydreaming - Func query parser: Wherever a query is expected, such as the
qparam, you can put a function query with this query parser. Thefuncquery parser will parse the function and expose it as a query matching all documents and return the function's output as the score. Here is an example URL snippet:q={!func}log(t_trm_lookups)&fl=t_trm_lookups,score - Frange (function range) query parser: This query parser is similar to the
funcquery parser, but it also filters documents based on the resulting score being in a specified range, instead of returning all documents. It takes alparameter for the lower bound, auparameter for the upper bound, andinclandincuBoolean parameters to specify whether the lower or upper bounds are inclusive—which they are by default. The parameters are optional, but you will specify at least one ofuorlfor meaningful effect. Here's an example URL snippet from its documentation:fq={!frange l=0 u=2.2}sum(user_ranking,editor_ranking)Unfortunately, the resulting score from an
frangequery is always1. - Sorting: In addition to sorting on field values, as mentioned in the previous chapter, you can sort on functions too. Here's an example URL snippet sorting by geospatial distance. This
geodistfunction can get its parameters from the URL as other parameters, and we do that here:sort=geodist() asc&pt=…&sfield=…
The preceding list enumerates the places where you can place a function directly. From this list, func and frange are query parsers that wrap the function as a query. Using them, you can in turn use functions wherever Solr accepts a query. There are many such places in Solr, so this opens up more possibilities.
For example, Solr's default query parser can switch to another query parser, even just for a subclause. You can then use func or frange as part of the overall query. Here is an example:
q=t_name:Daydreaming AND {!func v=log(t_trm_lookups)}^0.01The function query portion of it will match all documents, so we combine it with other required clauses to actually limit the results. The score is added to the other parts of the query such as bf. Note that this feature is unique to Solr; Lucene does not natively do this.
Note
Before Solr 4.1, this was possible but required a rather ugly syntax hack in which the function is prefixed, as if you were searching for it in a pseudo-field named _val_, such as _val_:"log(t_trm_lookups)". Similarly, the _query_ pseudo-field was used to enter a different query parser than func. Don't use this old syntax any more.
For fields used in a function query, the constraints are the same as sorting. Essentially, this means the field must be indexed or have DocValues, not multi-valued, and if text fields are used, then they must analyze down to no more than one token. And like sorting, all values get stored in the
field cache (it's internal to Lucene, not found in solrconfig.xml), unless the field has DocValues. We recommend you set
docValues="true"
on these fields.
The field cache will store all the field values in memory upon first use for sorting or functions. You should have a suitable query in newSearcher in solrconfig.xml so that the first search after a commit isn't penalized with the initialization cost. If you want to use fast-changing data, consider managing the data externally and using ExternalFileField, described a little later. Finally, if your field name has problematic characters, such as a space, you can refer to the field as field("my field").
Note
If you have a multivalued field you hoped to use, you'll instead have to put a suitable value into another field during indexing. This might be a simple minimum, maximum, or average calculation. There are UpdateRequestProcessors that can do this; see Chapter 4, Indexing Data.
If there is no value in the field for the document, then the result is zero; otherwise, numeric fields result in the corresponding numeric value. But what about other field types? For TrieDateField, you get the ms() value, which will be explained shortly. Note that 0 ambiguously means the date might be 1970 or blank. For older date fields, you get the ord() value, also explained shortly. For Boolean fields, true is 1 and false is 0. For text fields, you get the ord() value. Some functions can work with the text value—in such cases, you'll need to explicitly use the literal() function.
This section contains a reference of the majority of functions in Solr.
An argument to a function can be a literal constant, such as a number, a field reference, or an embedded function. String constants are quoted. One interesting thing you can do is pull out any argument into a separate named request parameter (in the URL) of your choosing and then refer to it with a leading $:
&defType=func&q=max(t_trm_lookups,$min)&min=50
The parameter might be in the request URL or configured into the request handler configuration. If this parameter dereferencing syntax is familiar to you, then that's because it works the same way in local-params too, as explained in Chapter 5, Searching.
Note
Not all arguments can be of any type. For the function definitions below, any argument named x, y, or z can be any expression: constants, field references, or functions. Other arguments such as a or min require a literal constant, unless otherwise specified. If you attempt to do otherwise, then you will get a parsing error, as it fails to parse the field name as a number.
These functions cover basic math operations and constants:
sum(x,y,z,... ), aliased toaddsums up, that is adds, all of the arguments.sub(x,y)subtractsyfromxas in the expressionx-y.product(x,y,z,...), aliased tomulmultiplies the arguments together.div(x,y) dividesxbyyas in the expressionx/y.log(x)andln(x)refers to the base-10 logarithm and the natural logarithm.- For the
sqrt(x),cbrt(x),ceil(x),floor(x),rint(x),pow(x,y),exp(x),mod(x,y), ande()operations, see thejava.lang.MathAPI at http://docs.oracle.com/javase/7/docs/api/java/lang/Math.html.
The following are Geometric/Trigonometric operations:
rad(x)anddeg(x)converts degrees to radians, and radians to degrees.- For
sin(x),cos(x),tan(x),asin(x),acos(x),atan(x),sinh(x),cosh(x),tanh(x),hypot(x,y),atan2(y,x), andpi(), see thejava.lang.MathAPI. - Geospatial functions will be covered later.
These are useful and straightforward mathematical functions:
map(x,min,max,target,def?): Ifxis found to be betweenminandmaxinclusive, thentargetis returned. Otherwise, ifdef(an optional parameter) is supplied then that is returned. Else,xis returned. This is useful to deal with default values or to limitxto ensure that it isn't above or below some threshold. Themap()function is a little similar toif()anddef().min(x,y,…)andmax(x,y,…): This returns the smallest and greatest parameters, respectively.scale(x,minTarget,maxTarget): This returnsxscaled to be betweenminTargetandmaxTarget. For example, if the value ofxis found to be one-third from the smallest and largest values ofxacross all documents, thenxis returned as one-third of the distance betweenminTargetandmaxTarget.linear(x,m,c): A macro forsum(product(m,x),c), for convenience and speed.recip(x,m,a,c): A macro fordiv(a,linear(x,m,c)), for convenience and speed.
Solr 4.0 includes new Boolean functions. When evaluating an expression as a Boolean, 0 is false and any other value is true. true and false are Boolean literals.
and(x,y,…),or(x,y,…),xor(x,y,…),not(x): These are primitive Boolean functions with names that should be self-explanatory.if(x,y,z): Ifxis true thenyis returned, elsez; a little similar tomap().exists(x): Ifxis a field name, then this returns true if the current document has a value in this field. Ifxis a query, then this returns true if the document matches it. Constants and most other value sources are always true.
Solr 4.0 includes new functions that expose statistics useful in relevancy. They are fairly advanced, so don't worry if you are new to Solr and these definitions seem confusing. In the following list of functions, field is a field name reference, and term is an indexed term (a word):
docfreq(field,term),totaltermfreq(field,term)—aliased tottf,sumtotaltermfreq(field)—aliased tosttf,idf(field,term),termfreq(field,term)—aliased totf,norm(field),maxdoc(), andnumdocs(): These functions have names that should be recognizable to anyone who might already want to use them. The earlier part of this chapter defined several of these terms.joindf(idField,linkField): This returns the document frequency of the current document'sidFieldvalue inlinkField. Consider the use case where Solr is storing crawled web pages with the URL inidField(need not be the unique key) andlinkFieldis a multivalued field referencing linked pages. This function would tell you how many other pages reference the current page.
As mentioned earlier, ord(fieldReference) is implied for references to text fields in the function query. The following is a brief description of ord() and rord():
ord(field): Given a hypothetical ascending sorted array of all unique indexed values forfield, this returns the array position; in other words, the ordinal of a document's indexed value. Thefieldparameter is of course a reference to a field. The order of the values is in an ascending order and the first position is1. A non-existent value results in0.rord(field): This refers to the reverse ordinal, as if the term ordering was reversed.
Not every function falls into a neat category; this section covers a few.
The def(x,y,…) function returns the first parameter found that exists; otherwise, the last parameter is returned. def is short for default.
There are multiple ways to use the ms() function to get a date-time value, since its arguments are all optional. Times are in milliseconds, since the commonly used time epoch of 1970-01-01T00:00:00Z, which is zero. Times before then are negative. Note that any field reference to a time will be ambiguous to a blank value, which is zero.
If no arguments are supplied to the ms(date1?,date2?) function, you get the current time. If one argument is supplied, its value is returned; if two are supplied, the second is subtracted from the first. The date reference might be the name of a field or Solr's date math; for example, ms(NOW/DAY,a_end_date/DAY).
Interestingly, there are a couple of function queries that return the score results of another query. It's a fairly esoteric feature but they have their uses, described as follows:
query(q,def?): This returns the document's score, as applied to the query given in the first argument. If it doesn't match, then the optional second parameter is returned if supplied, otherwise0is returned. Due to the awkward location of the query during function query parsing, it sometimes can't be entered plainly. The query can be put in another parameter and referenced asquery($param)¶m=t_trm_attributes:4. Else, it can be specified using local-params with the query inv, asquery({!v="t_trm_attributes:4"}). We've used this function to sort by another query, one that returns the distance as its score.boost(q,boost): This is similar toquery(q), but with the score multiplied by theboostconstant.
Another interesting function query is one that calculates the string distance between two strings based on a specified algorithm. The values are between 0 and 1.
In strdist(x,y,alg), the first two arguments are strings to compute the string distance on. Next is one of jw (Jaro Winkler), edit (Levenshtein), or ngram in quotes. The default ngram size is 2, but you can supply an additional argument for something else. For the field references, remember the restrictions listed earlier. In particular, you probably shouldn't reference a tokenized field.
This concludes the Function references section of the chapter. For a potentially more up-to-date source, check out the wiki at http://wiki.apache.org/solr/FunctionQuery. The source code is always definitive; see ValueSourceParser.java.
As you may recall from Chapter 4, Indexing Data, if you update a document, Solr internally re-indexes the whole thing, not just the new content. If you were to consider doing this just to increase a number every time a user clicked on a document or clicked some "thumbs-up" button, and so on, then there is quite a bit of work Solr is doing just to ultimately increase a number. For this specific use case, Solr has a specialized field type called ExternalFileField, which gets its data from a simple text file containing the field's values. This field type is very limited—the values are limited to floating point numbers and the field can only be referenced within Solr in a function. Changes are only picked up on a commit.
And if you are using Solr 4.1 or later, register ExternalFileFieldReloader in firstSearcher and newSearcher in solrconfig.xml. An application using this feature should generate this file on a periodic basis, possibly aligning it with the commit frequency. For more information on how to use this advanced feature, consult the API docs at http://lucene.apache.org/solr/api/org/apache/solr/schema/ExternalFileField.html and search Solr's mailing list.
The overall process to function query boosting is as follows:
- Pick a formula that has the desired plotted shape.
- Plug in values specific to your data.
- Decide the relative weighting of the boost relative to the user query (for example, 1/3).
- Choose additive or multiplicative boosting and then apply the relative weighting according to the approach you have chosen (see the Add or multiply boosts section).
The upcoming examples address common scenarios with readymade formulas for you.
Tip
If you want to work on formulas instead of taking one provided here as is, I recommend a tool such as a graphing calculator or other software to plot the functions. If you are using Mac OS X, as I am, then your computer already includes Grapher, which generated the charts in this chapter. I highly recommend it. You might be inclined to use a spreadsheet, such as Microsoft Excel, but that's really not the right tool. With luck, you may find some websites that will suffice, perhaps http://www.wolframapha.com.
If your data changes in ways that cause you to alter the constants in your function queries, then consider implementing a periodic automated test of your Solr data to ensure that the data fits within expected bounds. A Continuous Integration (CI) server might be configured to do this task. An approach is to run a search simply sorting by the data field in question to get the highest or lowest value.
The logarithm is a popular formula for inputs that grow without bounds, but the output is also unbounded. However, the growth of the curve is stunted for larger numbers. This in practice is usually fine, even when you ideally want the output to be capped. An example is boosting by a number of likes or a similar popularity measure.
Here is a graph of our formula, given inputs from a future example:
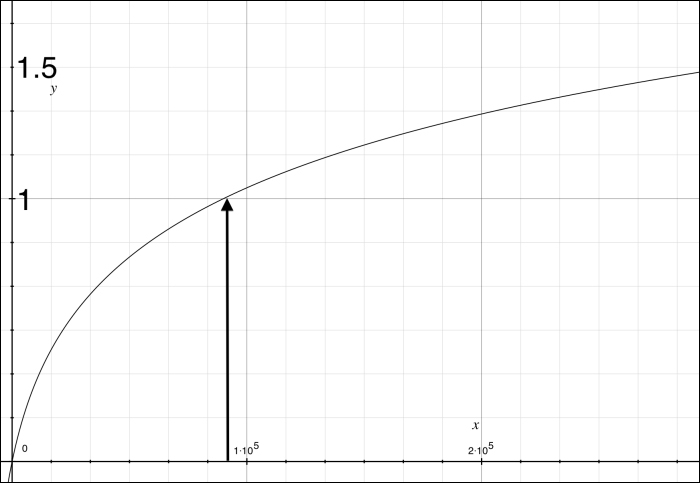
And here is the formula:
In this formula, c is a number greater than 1 and is a value of your choosing that will alter how the curve bends. I recommend 10 as seen in the preceding graph. Smaller values make it too linear and greater values put a knee bend in the curve that seems too early. In this formula, m is the inverse of what I'll call the horizon. At this value, the result is 1. With the logarithm, further values advance the output steadily but at a shallow slope that slowly gets shallower. Here is the Solr function query to use, simplified for when c is 10: log(linear(x,m,1)); where:
xrefers to the input; typically a field reference. It must not be negative.mrefers to 9/horizon where horizon is as described earlier.
Verify your formula by supplying 0, which should result in 0, and then supply horizon, which should result in 1. Now that you have your formula, you are ready to proceed with the other function query boosting steps.
In general, the reciprocal of a linear function is favorable because it gives results that are bounded as the input grows without bounds.
Here is a sample graph to show the curve. The inputs are from a later how-to. The arrow in the following graph shows where the "horizon" (1/m) lies:

Here is the formula:

Here, max is the value that this function approaches, but never quite reaches. It should be greater than 1 and less than 2; 1.5 works well. You can experiment with this to see how it changes the bend in the curve shown next. In the formula, m is the inverse of what I'll call the horizon. At this value, the result is 1, and larger inputs only increase it negligibly.
Here is the Solr function query to use: sum(recip(x,m,a,c),max); where:
xrefers to the input; typically a field reference. It must not be negative.mrefers to 1/horizon, where horizon is as described earlier.arefers to max-max*max.crefers to max – 1.maxis 1.5, or otherwise as defined earlier.
Verify your formula by supplying 0, which should result in 0, to horizon, which should result in 1. Now that you have your formula, you are ready to proceed with the other function query boosting steps.
The reciprocal is an excellent formula to use when you want to maximally boost at input 0 and boost decreasingly less as the input increases. It is often used to boost newly added content by looking at how old a document is.
Here is a sample graph to show the curve. The inputs are from a later how-to. The arrow roughly shows where the horizon input value is.

The formula is simply:
This translates easily to a Solr function query as recip(x,1,c,c); where:
xrefers to the input—a field or another function referencing a field. It should not be negative.cis roughly 1/10th of the horizon input value. As larger values are supplied, the boost effect is negligible.
Verify your formula by supplying 0, which should result in 1, and then horizon (as defined earlier), which should result in a number very close to 0.09. Now that you have your formula, you are ready to proceed with the other function query boosting steps.
If you have a value in your schema (or a computed formula) that you are certain will stay within a fixed range, then the formula to scale and shift this to the 0-1 nominal range is easy. We're also assuming that there is a linear relationship between the desired boost effect and the input.
Simply use the linear(x,m,c) function with appropriate values. Below, a refers to the end of the range that will have the least significant boost. So if your input ranges from 5 to 10 and if 5 is least relevant compared to 10, then a is 5; b takes the other side of the input range:
xrefers to the input, which is typically a fieldmcomputes 1/(b – a) and plug inccomputes a/(a - b) and plug in
Verify your formula by supplying a value from each end of the range and verify the result is 0 or 1 with 1 being the biggest boost. Now that you have your formula, you are ready to proceed with the other function query boosting steps.
In this section, I'm going to describe a few ways to boost a document based on one of its numeric fields. The greater this number is for a document, the greater boost this document should receive. This number might be a count of likes or thumbs-up votes by users, or the number of times a user accessed (for example, clicked) the referenced document, or something else.
In the MusicBrainz database, there are TRM and PUID lookup counts. TRM and PUID are MusicBrainz's audio fingerprint technologies. These identifiers roughly correspond to a song, which, in MusicBrainz, appears as multiple tracks due to various releases that occur as singles, compilations, and so on. By the way, audio fingerprints aren't perfect, and so a very small percentage of TRM IDs and PUIDs refer to songs that are completely different. Since we're only using this to influence scoring, imperfection is acceptable.
MusicBrainz records the number of times one of these IDs are looked up from its servers, which is a good measure of popularity. A track that contains a higher lookup count should score higher than one with a smaller value, with all other factors being equal. This scheme could easily be aggregated to releases and artists, if desired. In the data loading, I've arranged for the sum of TRM and PUID lookup counts to be stored into our track data as t_trm_lookups with the following field specification in the schema:
<field name="t_trm_lookups" type="tint" />
About 25 percent of the tracks have a non-zero value. The maximum value is nearly 300,000 but further inspection shows that only a handful of records exceed a value of 90,000.
The first step is to pick a formula. Since this is a classic case of an increasing number without bound in which the greater the number is, the greater the boost should be, the inverse reciprocal is a very good choice. Next, we plug in our data into the formula specified earlier and we end up with this function query:
sum(recip(t_trm_lookups,0.0000111,-0.75,0.5),1.5)
We verify the formula by plugging in 0 and 90,000, which maps to 0 and 1.
The next step is to choose between additive boosts versus multiplicative boosts. Multiplicative boost with edismax is easier, so we'll choose that. And let's say this function query should weigh one-third of the user query. According to earlier instructions, adding to our function query will reduce its weight counter-intuitively. Adding 2 shifts the 0 to 1 range to 2 to 3 and (3 - 2)/3 results in the one-third boost we're looking for. Since our function query conveniently has sum() as its outer function, we can simply add another argument of 2. Here is a URL snippet that shows the relevant parameters:
q=cherub+rock&defType=edismax&qf=t_name&boost=sum(recip(t_trm_lookups,0.0000111,-0.75,0.5),1.5,2)
This boost absolutely had the desired effect, altering the score order as we wanted. One unintended outcome is that the top document scores used to be ~8.6 and now they are ~21.1, but don't worry about it! The actual scores are irrelevant—a point made in the beginning of the chapter. The goal is to change the relative order of score-sorted documents.
To better illustrate the difference, here is the query before boosting and with CSV output (with spaces added for clarity): http://localhost:8983/solr/mbtracks/select?q=cherub+rock&defType=edismax&qf=t_name&fl=id,t_name,t_trm_lookups,score&wt=csv&rows=5:
id,t_name,t_trm_lookups,score Track:2528226, Cherub Rock, 0, 8.615694 Track:2499080, Cherub Rock, 0, 8.615694 Track:2499119, Cherub Rock, 0, 8.615694 Track:2492995, Cherub Rock, 1036, 8.615694 Track:2492999, Cherub Rock, 105, 8.615694
And here is the boosted query and the new results: http://localhost:8983/solr/mbtracks/select?q=cherub+rock&defType=edismax&qf=t_name&boost=sum(recip(t_trm_lookups,0.0000111,-0.75,0.5),1.5,2)&fl=id,t_name,t_trm_lookups,score&wt=csv&rows=5:
id,t_name,t_trm_lookups,score Track:749561, Cherub Rock, 19464, 21.130745 Track:183137, Cherub Rock, 17821, 20.894897 Track:2268634, Cherub Rock, 9468, 19.47599 Track:2203149, Cherub Rock, 9219, 19.426989 Track:7413518, Cherub Rock, 8502, 19.28334
If you're wondering why there are so many tracks with the same name, it's because popular songs like this one are published as singles and as part of other collections.
Using dates in scores presents some different issues. Suppose when we search for releases, we want to include a larger boost for more recent releases. At first glance, this problem may seem just like the previous one, because dates increase as the scores are expected to, but in practice, it is different. Instead of the data ranging from zero to some value that changes occasionally, we now have data ranging from a non-zero value that might change rarely to a value that we always know, but changes continuously—the current date. Instead, approach this from the other side, that is, by considering how much time there is between the current date and the document's date. So at x=0 in the graph (x representing time delta), we want 1 for the greatest boost, and we want it to slope downward towards 0, but not below it.
The first step is to pick a formula. The reciprocal is perfect for this scenario. The function query form as detailed earlier is recip(x,1,c,c).
Based on this scenario, x is the age—a time duration from the present. Our MusicBrainz schema has r_event_date, which is a promising candidate; however, multivalued fields are not supported by function queries. I made a simple addition to the schema and index to record the earliest release event date: r_event_date_earliest. With that done, now we can calculate the age with the two-argument variant of ms(). As a reminder to show how to run these function queries while debugging, here's a URL snippet:
q={!func}ms(NOW,r_event_date_earliest)
&fl=id,r_name,r_event_date_earliest,score&sort=score+ascThe book's dataset hasn't markedly changed since the first edition, but when I first obtained it, I noticed that some of the releases were in the future! What I saw then is reproducible by substituting NOW-6YEARS to get to 2008 as I write this in 2014, instead of just NOW in the function. The first documents (score ascending) have negative values, which means they are from the future. We can't have negative inputs, so instead we'll wrap this function with the absolute value using abs().
The other aspect of the inputs to the reciprocal function is finding out what the horizon is. This should be a duration of time such that any longer durations have a negligible boost impact. Without too much thought, 20 years seems good. Here's a query to have Solr do the math so we can get our millisecond-count: q={!func}ms(NOW,NOW-20YEARS), which is about 6.3E11. In the documentation for the reciprocal formula, we take one-tenth of that for c. Here is our function query:
recip(abs(ms(NOW/DAY,r_event_date_earliest)),1,6.3E10,6.3E10)
At this point, you can follow the final steps in the previous how-to.