
If you have text in various languages, the main issues you have to think about are the same issues for working with any one language—how to analyze content, configure fields, define search defaults, and so on. In this section, we present three approaches to integrate linguistic analysis into Solr.
With this approach, you will need to create one field per language for all the searchable text fields. As part of your indexing process, you can identify the language and apply the relevant analyzers, tokenizers, and token filters for each of those fields. The following diagram represents how each of the documents in your index will have language-specific fields:
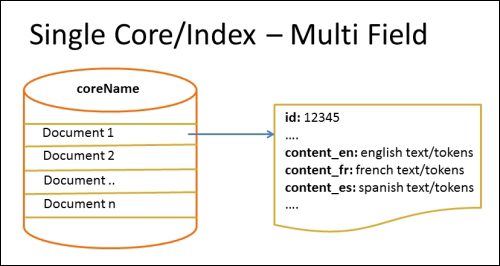
The following are the pros:
- As you have separate fields for each language, searching, filtering, and/or faceting will be easy
- You will have accurate and meaningful relevancy scores (TF/IDF)
The following are the cons:
As represented in the following diagram, the second approach uses one core (or shard) per language. Each core will contain documents of the same language. As part of the indexing process, you will need to identify the language of each document and index into the appropriate core. Language-specific analyzers, tokenizers and token filters will still be required.

The following are the pros:
- The field names are the same in all the cores, which simplifies query-time processing, and it's easy to search, filter, and facet by language.
- As you have separate cores per language, you will have flexibility in adding or removing specific languages without affecting other cores.
The following are the cons:
- There is overhead in maintaining multiple cores.
- If you make copies of the multilingual documents on every core whose language matches one of the languages of the documents, there is a high possibility that a distributed search query will bring back the same original document from multiple cores, which will show as duplicates to the user.
- Term frequency (TF) counts are per core, so if search results are being pulled from multiple queries, you have to decide how to merge the relevancy scores presented by each core. Solr will do a basic merge for you, but it may not be what you expect.
The following diagram represents the third approach, which is to have a single field for all languages that you want to support. The simplest way to implement this as described here is to use ICUTokenizerFactory provided by ICU4J in contrib/analysis-extras. Alternatively, you can write a custom analyzer that analyzes differently depending on the language of the text, but that is very complex and has its own pros/cons.
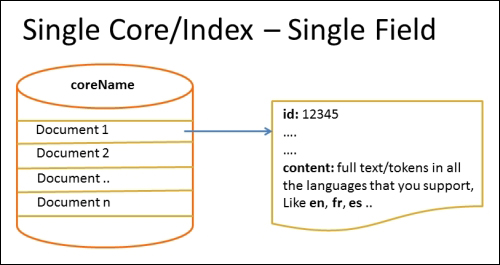
The following are the pros:
The following are the cons:
- You can't use any of the stemmers, as they are language specific. Not stemming hurts recall in search results. You can't remove stop words either, as this is also language specific.
- As all of the languages are in the same field, a document's relevancy (TF/IDF) score (described in Chapter 6, Search Relevancy) may be poor.