
Text analysis is a topic that covers text-processing steps such as tokenization, case normalization, stemming, query expansion using synonyms, and other miscellaneous text processing. The analysis is applied to a text field at index time and as part of query string processing at search time. It's an important part of search engines since most of the time business-relevant information is in an unstructured form, primarily text. Also, the details have an effect on getting good search results, especially to recall—a dimension of search result quality pertaining to whether all relevant documents are in the search results.
Tip
This chapter is almost completely Lucene-centric and so also applies to any other software built on top of Lucene. For the most part, Solr merely offers XML configuration for the code in Lucene that provides this capability. For information beyond what is covered here, including writing your own analysis components, read Lucene in Action, Second Edition, Manning Publications.
Text analysis converts text for a particular field into a sequence of terms. A term is the fundamental unit that Lucene actually indexes and searches. The analysis is used on the original incoming value at index time; the resulting terms are ultimately recorded onto disk in Lucene's index structure where it can be searched. The analysis is also performed on words and phrases parsed from the query string; the resulting terms are then searched in Lucene's index. An exception to this is the prefix, wildcard and fuzzy queries, all of which skip text analysis. You'll read about them in Chapter 5, Searching.
Tip
In a hurry?
As a starting point, you should use the existing field types in Solr's default schema, which includes a variety of text field types for different situations. They will suffice for now and you can return to this chapter later. There will surely come a time when you are trying to figure out why a simple query isn't matching a document that you think it should, and it will quite often come down to your text analysis configuration.
We try to cover Solr in a comprehensive fashion and this chapter mainly focuses on the text analysis for English language.
Tip
Non-English text analysis
Text analysis for non-English languages is not straightforward as the rules vary by language. You can refer to the wiki page https://cwiki.apache.org/confluence/display/solr/Language+Analysis for more information. There are 34 language factories available at the time of writing. You'll notice that there is some variation in how to configure Solr for each of them, and that some languages have multiple options. Most language-specific elements are the stemmer and the stop word list, and for Eastern languages, the tokenizer too. There is also a set of International Components for Unicode (ICU) related analysis components, some of which you can use for mapping some non-Latin characters to Latin equivalents. We will also discuss the approaches for supporting multilingual search later in this chapter.
Solr has various field types as we've previously explained, and the most important one is TextField. This is the field type that has an analyzer configuration. Let's look at the configuration for the text_en_splitting field type definition that comes with Solr's example schema. It uses a diverse set of analysis components. We added in a character filter, albeit commented, to show what it looks like. As you read about text analysis in this chapter, you may want to flip back to see this configuration.
<fieldType name="text_en_splitting" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="true">
<analyzer type="index">
<!--<charFilter class="solr.MappingCharFilterFactory" mapping="mapping-ISOLatin1Accent.txt"/>-->
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="stopwords_en.txt"
enablePositionIncrements="true"
/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1" catenateNumbers="1"
catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
<analyzer type="query">
<!--<charFilter class="solr.MappingCharFilterFactory" mapping="mapping-ISOLatin1Accent.txt"/>-->
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="stopwords_en.txt"
enablePositionIncrements="true"
/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="0" catenateNumbers="0" catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>The configuration example defines two analyzers, each of which specify an ordered sequence of processing steps that convert text into a sequence of terms. The type attribute, which can hold a value of index or query, differentiates whether the analyzer is applied at index time or query time, respectively. If the same analysis is to be performed at both index and query times, you can specify just one analyzer without a type. When both are specified as in the previous example, they usually only differ a little.
Tip
Analyzers, tokenizers, filters, oh my!
These are the three main classes in the org.apache.lucene.analysis package from which all analysis processes are derived, which are about to be defined. They are all conceptually the same—they take in text and spit out text, sometimes filtering, sometimes adding new terms, and sometimes modifying terms. The difference is in the specific flavor of input and output for them—either character based or token based. Also, term, token, and word are often used interchangeably.
An analyzer can optionally begin with one or more character filters, which operate at a streaming character level to perform manipulations on original input text. These are most commonly used to normalize characters, such as the removal of accents. Following any optional character filters is the tokenizer—the only mandatory piece of the chain. This analyzer takes a stream of characters and tokenizes it into a stream of tokens, perhaps with a simple algorithm, such as splitting on whitespace. The remaining analysis steps, if any, are all token filters (often abbreviated to just filters), which perform a great variety of manipulations on tokens. The final tokens at the end are referred to as terms at this point; they are what Lucene actually indexes and searches. The order of these components is very important and, in most cases, you may want it to be the same at index time and query time. Note that some filters such as WordDelimeterFilterFactory actually perform a tokenization action, but they do it on a token, whereas a bonafide tokenizer works from a character stream.
Tip
All the class names end with Factory. This is a convention followed by all the names of Lucene's Java classes that accept the configuration and instantiate Lucene's analysis components that have the same simple name, minus the Factory suffix. References to these analysis components in this book and elsewhere sometimes include the Factory suffix and sometimes not; no distinction is intended.
Finally, we want to point out the autoGeneratePhraseQueries Boolean attribute—an option only applicable to text fields. If search-time query text analysis yields more than one token, such as Wi-Fi tokenizing to Wi and Fi, then by default these tokens are simply different search terms with no relation to their position. If this attribute is enabled, then the tokens become a phrase query, such as WiFi and consequently these tokens must be adjacent in the index. This automatic phrase query generation would always happen prior to Solr 3.1, but it is now configurable and defaults to false.
Tip
We recommend disabling autoGeneratePhraseQueries
There is conflicting opinion among experts on a suitable setting; setting it to false increases recall but decreases precision—two dimensions of search result quality. We favor that choice, since you'll learn in Chapter 6, Search Relevancy, how to do automatic phrase boosting to get the most relevant documents (those that match the phrase Wi Fi) at the top of the results.
Before we dive into the details of particular analysis components, it's important to become comfortable with Solr's analysis page, which is an experimentation and a troubleshooting tool that is indispensable. You'll use this to try out different configurations to verify whether you get the desired effect, and you'll use this when troubleshooting to find out why certain queries aren't matching certain text that you think they should. In Solr's admin interface, you'll see a link named Analysis, which takes you to this screen:
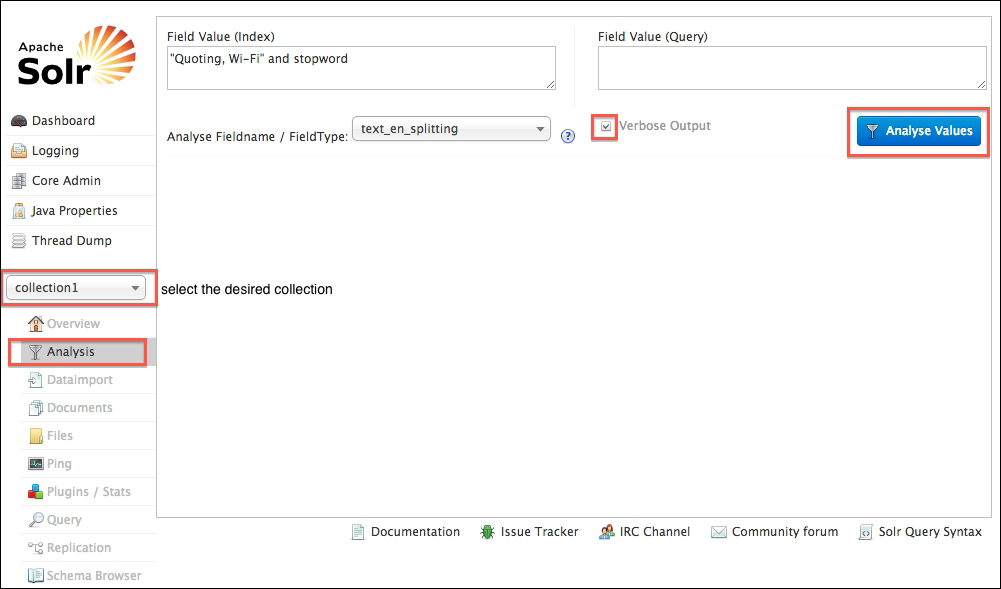
As shown in the preceding screenshot, the option on the form Analyse Fieldname / FieldType is required. You pick whether you want to choose a field type directly by its name, or if you want to indirectly choose one based on the name of a field. In this example, we're choosing the text_en_splitting field type that has some interesting text analysis. This tool is mainly for text-oriented field types, not Boolean, date, and numeric oriented types. You may get strange results if you try those.
At this point, you can analyze index or query text or both at the same time. If you are troubleshooting why a particular query isn't matching a particular document's field value, then you'd put the field value into the Index box and the query text into the Query box. Technically, that might not be the same thing as the original query string, because the query string may use various operators to target specified fields, do fuzzy queries, and so on. You will want to check off Verbose Output to take full advantage of this tool.
The output after clicking on the Analyse Values button is a bit verbose with Verbose Output checked and so we've disabled it for this upcoming screenshot. We encourage you to try it yourself.
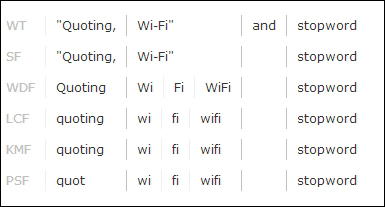
Each row shown here represents one step in the chain of processing as configured in the analyzer, for example, the third analysis component is WordDelimeterFilter and the results of its processing are shown in the third row. The columns separate the tokens, and if more than one token shares the same column, then they share the same term position. The distinction of the term position pertains to how phrase queries work. One interesting thing to notice about the analysis results is that Quoting ultimately became quot after stemming and lowercasing. Also, the word and was omitted by the StopFilter, which is the second row.