
In real-world scenarios, Solr runs with other applications on a web server. A typical example is an online store application. The store provides a user interface, a shopping cart, an items catalogue, and a way to make purchases. It needs to store this information some sort of database. Here, Solr makes easy so add the capability of searching data in the online store. To make data searchable, you need to feed it to Solr for indexing. Data can be fed to Solr in various ways and also in various formats, such as .pdf, .doc, .txt, and so on. In the process of feeding data to Solr, you need to define a schema. A schema is a way of telling Solr about data and how you want to make your data indexed. A lot many factors need to be considered while feeding data, which we will discuss in detail in upcoming chapters.
Solr queries are RESTful, which means that a Solr query is just a simple HTTP request and the response is a structured document, mainly in XML, but it could be JSON, CSV, or any other format as well based on your requirement. A typical architecture of Solr in the real world looks something like this:
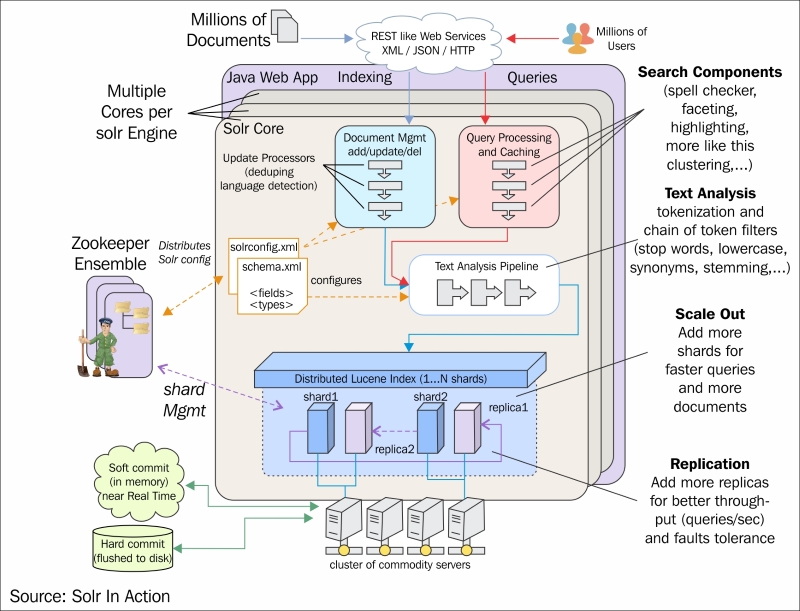
Do not worry if you are not able to understand the preceding diagram right now. We will cover every component related to indexing in detail. The purpose of this diagram is to give you a feel of the current architecture of Solr and its working in the real world. If you see the preceding diagram properly, you will find two .xml files named schema.xml and solrconfig.xml. These are the two most important files in the Solr configuration and are considered the building blocks of Solr.
Here's the directory layout of a typical Solr Home directory:
| + conf | - schema.xml | - solrconfig.xml | - stopwords.txt | - synonyms.txt etc | + data | - index | - spellchecker
Let's get a brief understanding of solrconfig.xml and schema.xml here before we proceed further, as these are the building blocks of Solr (as stated earlier). We will cover them in detail in the next few chapters.
The solrconfig.xml file is the core configuration file of Solr, with most parameters affecting Solr itself directly. This file can be found in the solr/collection1/conf/ directory. When configuring Solr, you'll work with solrconfig.xml often. The file consists of a series of XML statements that set configuration values, and some of the most important configurations are:
- Defining
data dir(the directory where indexed files remain) - Request handlers (handle upcoming HTTP requests)
- Listeners
- Request dispatchers (used to manage HTTP communications)
- Admin web interface settings
- Replication and duplication parameters
These are some of the important configurations defined in solrconfig.xml. This file is well commented; I would advise you to go through it from the start and read all the comments. You will get a very good understanding of the various components involved in the Solr configuration.
The second most important configuration file is called schema.xml. This file can be found in the solr/collection1/conf/ directory. As the name says, this file is used to define the schema of the data (content) that you want to index and make searchable. Data is called document in Solr terminology. The schema.xml file contains all the details about the fields that your documents can contain, and how these fields should be dealt with when adding documents to the index or when querying those fields. This file can be divided broadly into two sections:
- The types section (the definitions of all types)
- The fields section (the definitions of the document structure using types)
The structure of your document should be defined as a field under the fields section. Let's say you have to define a book as a document in Solr with fields as isbn, title, author, and price. The schema will be as follows:
<field name="isbn" type="string" required="true" indexed="true" stored="true"/> <field name="title" type="text_general" indexed="true" stored="true"/> <field name="author" type="text-general" indexed="true" stored="true" multiValued="true"/> <field name="price" type="int" indexed="true" stored="true"/>
In the preceding schema, you see a type attribute, which defines the data type of the field. You can change the behavior of the field by changing the type. The multiValued attribute is used to tell Solr that the field can hold multiple values, while the required attribute makes the field mandatory for creating a document. After the fields section ends, we need to mention which field is going to be unique. In our case, it is going to be isbn:
<uniqueKey>isbn</uniqueKey>
The schema.xml file is also well-commented file. I will again advise you to go through the comments of this file, for starting this will help you understand the various field types and data types in detail.