
We'll create a new schema that will hold the metadata information for our indexed files. Apache Tika will extract the metadata information from the file that we pass to it. The schema.xml configuration, which we'll use, looks like the following:
<?xml version="1.0" encoding="UTF-8" ?>
<schema name="tika-example" version="1.5">
<field name="title" type="text_general" indexed="true" stored="true" multiValued="true"/>
<field name="author" type="text_general" indexed="true" stored="true"/>
<field name="content" type="text_general" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="attr_*" type="text_general" indexed="true"
stored="false" multiValued="true"/>
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<charFilter class="solr.PatternReplaceCharFilterFactory" pattern="([\n])" replacement=""/>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
</schema>Let's now send a Word document to Solr for indexing. All the relevant code examples and sample files can be found in $SOLR_INDEXING_BOOK/Chapter06/tika-example.
We'll use the post.jar tool to index a Word document (.doc) to the Solr server:
$ java -Durl=http://localhost:8983/solr/tika-example/update/extract?commit=true -Dtype=application/msword -jar post.jar %SOLR_EXAMPLES/Chapter06/test-tika.docx
As we can see from the command, we're specifying the content-type of the file that we're indexing through –Dtype=application/msword. As we're sending a PDF file, we can use application/pdf as the content type.
After running the command, we will see the following output:
SimplePostTool version 1.5 Posting files to base url http://localhost:8983/solr/tika-example/update/extract using content-type application/msword.. POSTing file test-tika.docx 1 files indexed. COMMITting Solr index changes to http://localhost:8983/solr/tika-example/update/ extract.. Time spent: 0:00:01.499
After we've indexed the sample Word document in index, we can use the Solr query browser to see how the document has been indexed in Solr. As we can see from the preceding screenshot, the Solr query returns the following indexed document, and the content inside the Word document is stored in the content field.
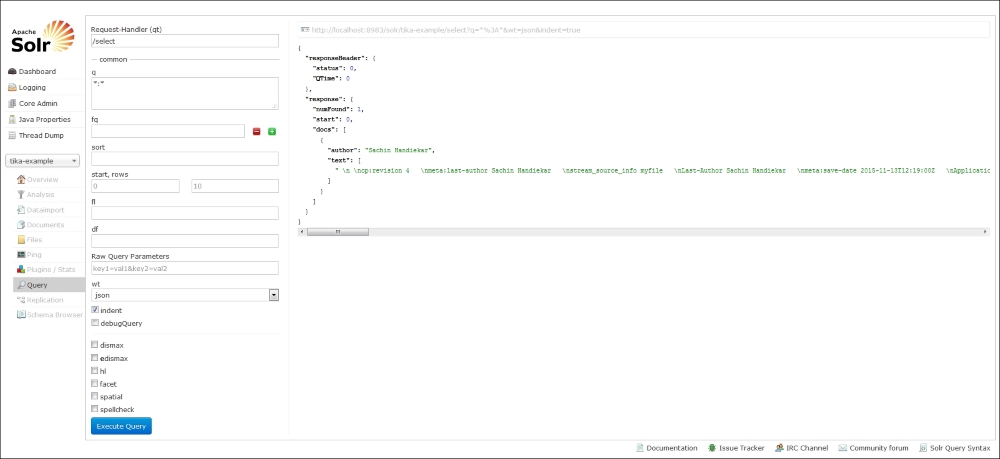
The metadata attributes are currently not stored in Solr while indexing the document. However, we can enable indexing for the metadata attribute by changing the dynamic attribute field in schema.xml to the following:
<dynamicField name="attr_*" type="text_general" indexed="true" stored="true" multiValued="true"/>