
In the previous chapter, we saw how we can use Solr to retrieve documents that are indexed into it in real time. In this chapter, we'll cover some advanced topics that will help us use the full potential of Solr.
Specifically, we'll cover the following topics in this chapter:
- Indexing a document in multiple languages
- Detecting duplicate documents (deduplication)
- Streaming of documents in Solr (content streaming)
- UIMA integration with Solr
Solr provides us with a way to index multilanguage documents in it. In this section, we'll cover how to easily index multilanguage documents in Solr and also how to auto-detect a document language.
Let's create a new core called languages-example. It will contain the following fields in schema.xml, which we're going to use for our example:
<fields> <field name="id" type="string" indexed="true" stored="true" required="true"/> <field name="content" type="text_general" indexed="true" stored="true" /> <field name="text" type="text_general" multiValued="true" indexed="true" stored="false" /> <copyField source="content" dest="text" /> <field name="language" type="string" stored="true" indexed="true" /> <dynamicField name="*_en" type="text_en" stored="true" indexed="true" /> <dynamicField name="*_ru" type="text_ru" stored="true" indexed="true" /> <dynamicField name="*_fr" type="text_fr" stored="true" indexed="true" /> </fields>
After we have added the fields, we'll modify our solrconfig.xml configuration file to add the language detection feature, which is provided by LangDetect (http://code.google.com/p/language-detection/):
<lib dir="${user.dir}/../contrib/analysis-extras/lucene-libs/" />
<lib dir="${user.dir}/../contrib/analysis-extras/lib/" />
<lib dir="${user.dir}/../dist/" regex="solr-langid-.*.jar" />
<lib dir="${user.dir}/../contrib/langid/lib/" />Next, after adding the libraries, we'll add an UpdateRequestProcessorChain element, which will contain the language detection processor:
<updateRequestProcessorChain name="languages">
<processor class="solr.LangDetectLanguageIdentifierUpdateProcessorFactory">
<lst name="invariants">
<str name="langid.fl">content</str>
<str name="langid.whitelist">en,fr,ru</str>
<str name="langid.fallback">en</str>
<str name="langid.langField">language</str>
<bool name="langid.map">true</bool>
<bool name="langid.map.keepOrig">false</bool>
</lst>
</processor>
<processor class="solr.RunUpdateProcessorFactory" />
</updateRequestProcessorChain>We've added the solr.LangDetectLanguageIdentifierUpdateProcessorFactory class in UpdateRequestProcessor, which will automatically detect the language from the document and will store it in the language field.
Alternatively, we can use solr.TikaLanguageIdentifierUpdateProcessorFactory to detect the language of the document.
Note
More information on using the processor factory is available at https://cwiki.apache.org/confluence/display/solr/Detecting+Languages+During+Indexing.
We'll be indexing the following XML file (multilang-doc.xml), which will contain three separate documents in English, Russian, and French:
<add>
<!-- English -->
<doc>
<field name="id">doc1</field>
<field name="content">
<![CDATA[Hello, This is an example for the Solr Indexing book.]]>
</field>
</doc>
<!-- Russian -->
<doc>
<field name="id">doc2</field>
<field name="content">
<![CDATA[Привет , это пример для индексации книги Solr.]]>
</field>
</doc>
<!-- French -->
<doc>
<field name="id">doc3</field>
<field name="content">
<![CDATA[Bonjour, Ceci est un exemple pour le livre d'indexation Solr.]]>
</field>
</doc>
</add>Let's go ahead and index the document in our newly created core. To do this, we'll start up Solr and run the following command:
$ curl 'http://localhost:8983/solr/languages-example/update?commit=true' -H "Content-Type: text/xml" --data-binary @multilang-doc.xml
After we execute the command, we'll see the following output from Solr, which confirms that it has been successful in sending the document to Solr:
<?xml version="1.0" encoding="UTF-8"?> <response> <lst name="responseHeader"><int name="status">0</int><int name="QTime">513</int></lst> </response>
After indexing, let's go ahead and query the indexed data in Solr. So, open up the Solr Query browser or go to http://localhost:8983/solr/languages-example/select?q=*%3A*&wt=json&indent=true.
We can see the following response from the server:
{
responseHeader : {
status : 0,
QTime : 2
},
response : {
numFound : 3,
start : 0,
docs : [{
id : "doc1",
language : "en",
content_en : " Hello, This is an example for the Solr Indexing book. "
}, {
id : "doc2",
language : "ru",
content_ru : " Привет , это пример для индексации книги Solr. "
}, {
id : "doc3",
language : "fr",
content_fr : " Bonjour, Ceci est un exemple pour le livre d'indexation Solr. "
}
]
}
}As we can see from the preceding response—the language field has been auto-populated by solr.LangDetectLanguageIdentifierUpdateProcessorFactory—we can realize how easy it is to index multilanguage documents in Solr.
We can also create separate search handlers based on the language. An example of using various language handlers has been provided in solrconfig.xml, which is available in the code examples.
The following is an example of a sample search handler (/selectRU) that we can use to search for documents whose language is set to Russian (ru):
<requestHandler name="/selectRU" class="solr.SearchHandler" >
<lst name="invariants">
<str name="fq">language:ru</str>
</lst>
</requestHandler>In the Solr Query browser, we can search for all documents whose language is Russian using the /selectRU search handler. Here is a screenshot that shows the use of this handler:
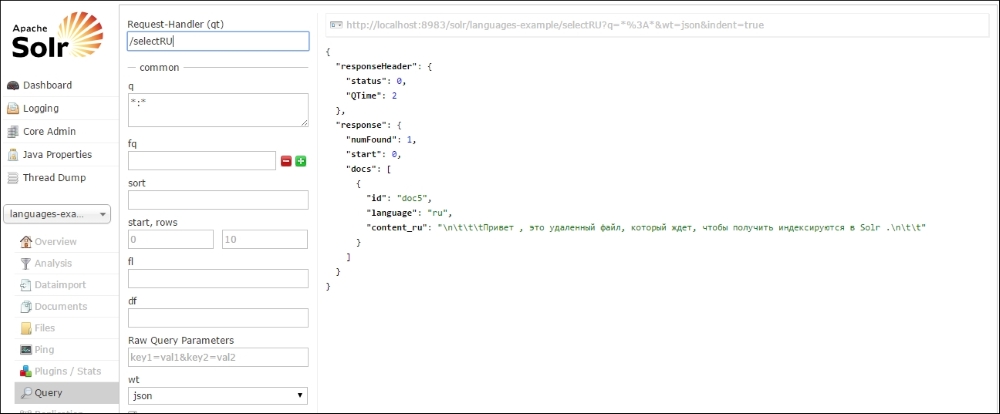
Now let's move on to a different topic, which will help us remove duplicate documents from our index. In the next section, we'll see how we can use SignatureUpdateProcessorFactory to remove/overwrite duplicate elements.