
11
Containers and Kubernetes
Cloud-native patterns and new cloud operating systems based on containers and Kubernetes have been growing rapidly over the past few years. Together with solutions through the viable ecosystem of the Cloud Native Computing Foundation (CNCF - https://www.cncf.io/), they have changed the development, delivery, and life cycle management of modern software.
Containers and Kubernetes have become the important cornerstones of building, running, and managing cloud services and applications. Like virtual machines (VMs), containers enable applications to share the OS kernel. Compared to VMs, a running container is less resource-intensive but retains isolation, thus improving resource utilization.
Containers are decoupled from the underlying infrastructure and portable across cloud and on-premises environments. Containers are created from images to produce identical environments across development, testing, and production deployments. Containers provide a good way to package all the necessary libraries, dependencies, and files for your applications; however, you need to manage the containers effectively and ensure that your applications are auto-scaling, and design for failures and recovery. This is where Kubernetes plays its part.
Kubernetes is a portable and extensible platform for managing containerized workloads and running distributed systems resiliently. It takes care of scaling and failover, facilitates declarative configuration and deployment patterns, and provides a self-healing ability, load balancing, and network traffic management. Kubernetes has evolved into the de facto industry standard for container orchestration.
Cloud-native technologies have enabled a new paradigm of software development and its capabilities. They have enabled agile development, continuous integration and continuous deployment (CI/CD), infrastructure automation, and a new way to structure teams, culture, and technology to manage complexity and unlock velocity.
SAP embraced cloud-native patterns and Kubernetes at an early stage, and has actively contributed to multiple CNCF projects, such as the open-source projects Gardener (https://gardener.cloud/) and Kyma (https://kyma-project.io/). Today, many SAP applications are already running on Kubernetes, while many others are in the process of migrating to Kubernetes. In SAP Business Technology Platform (BTP), Kyma Runtime is the cloud-native extension platform and SAP BTP itself runs on top of Kubernetes, which is enabled by Gardener.
We will discuss Gardener and Kyma in more detail later. First, let’s have a look at what we are going to cover in this chapter:
- What is Kubernetes and how does it enable a new type of architecture?
- Gardener as a managed Kubernetes service that is available in multi-cloud environment
- Kyma as the cloud-native extension platform of SAP BTP
- When should you use Cloud Foundry or Kubernetes?
Understanding Kubernetes architecture
So, what is Kubernetes and how does it make cloud-native development much easier?
Initially developed by Google based on many years of running Linux containers both at a basic level and at scale, Kubernetes is a system for running and managing which containers run where, coordinating large numbers of containers, and facilitating communication between containers across hosts. In addition, Kubernetes provides a common infrastructure layer that abstracts underlying infrastructure environments, such as public, private, and hybrid clouds running in virtual or physical machines.
Kubernetes creates an abstraction layer that allows the developers and operators to work collectively and helps focus on control at the service level instead of the individual container level. If containers have empowered the productivity of individual developers, Kubernetes has allowed teams to compose services out of containers. This improved coordination has enhanced development velocity, service availability, and agility at scale.
To understand how Kubernetes provides the capacity to achieve those objectives, let’s get a sense of how it is designed at a high level, as illustrated in Figure 11.1, and discuss each component in the following subsections.
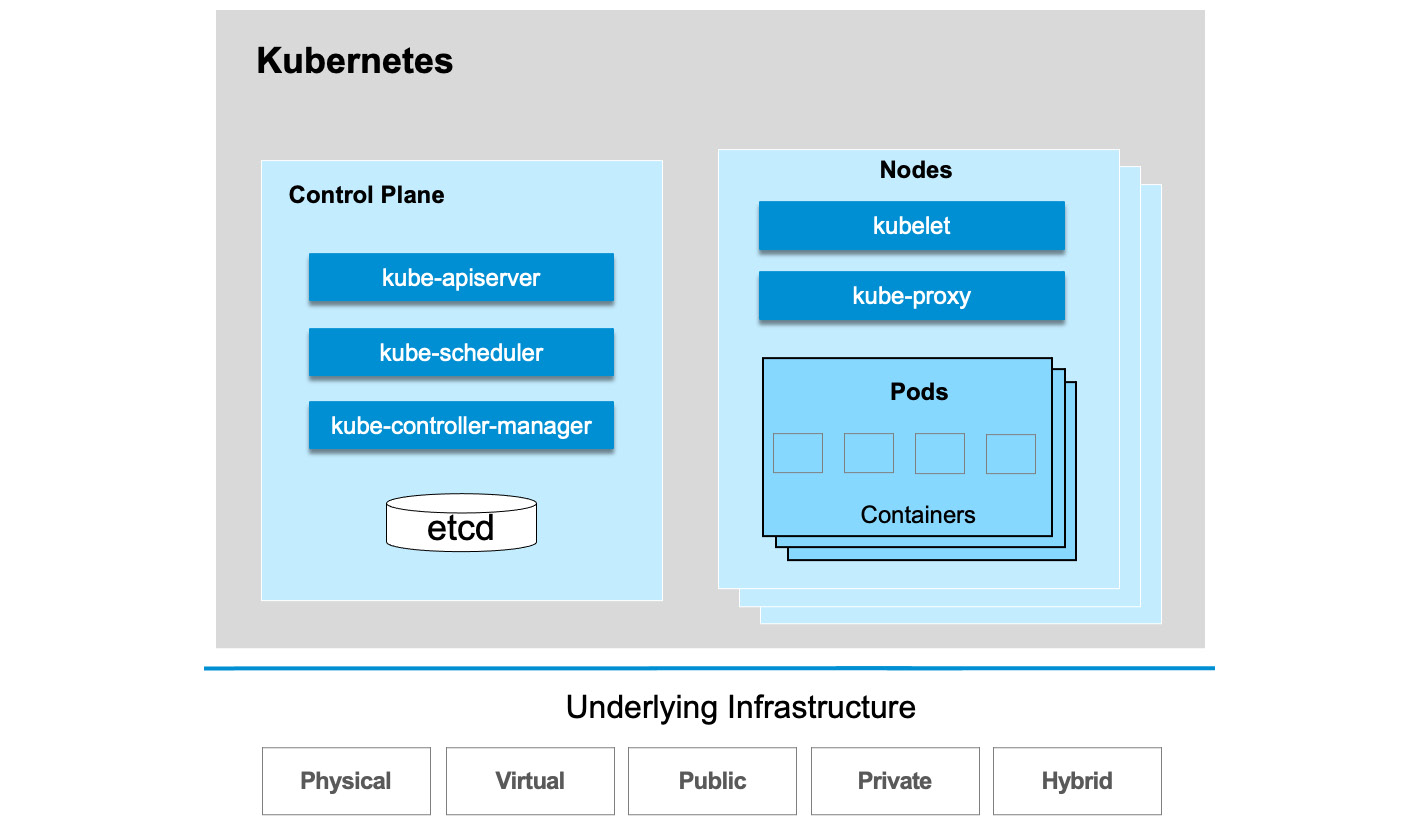
Figure 11.1: The Kubernetes architecture
Now let’s take a look at the core components of Kubernetes.
The control plane
In Kubernetes, users interact with the cluster by communicating with the API server, and the control plane is responsible for determining the best way to schedule the workload containers by examining the requirements and the current state of the system.
As part of the control plane, etcd is a lightweight distributed key-value store that Kubernetes uses to store configuration data, which can be accessed by each node in the clusters. It is used for service discovery and maintains the cluster state.
kube-apiserver is the API server that exposes the APIs and the main management point of the cluster, as it allows users to configure the workloads through REST API calls or the kubectl command-line interface.
kube-scheduler performs the actual task of assigning workloads to specific nodes in the cluster. It tracks the status and available capacity on each host, considers the resource needs of a Pod, and then schedules the Pods to the appropriate node.
kube-controller-manager contains serval controller functions in one and is responsible for implementing the procedures that fulfill the desired state. For example, a replication controller ensures the correct number of replicas is deployed as defined for a Pod. An endpoints controller populates endpoint objects and a node controller notices and responds when nodes go down.
Nodes
The servers that perform the work of running containers are called nodes.
A Pod is the smallest deployment unit in the Kubernetes object model and represents a single instance of an application. Each Pod is made up of one or more tightly coupled containers that should be scheduled on the same node. Each node contains a kubelet, a small service that communicates with the control plane and assumes the responsibility of executing tasks and maintaining the state of work on the node server.
kube-proxy is a network proxy for facilitating network communications inside or outside of the Kubernetes cluster. It forwards requests to the correct containers, maintains network rules, and either replies on the OS’s packet filtering layer or forwards the traffic itself.
Blurring the layers of IaaS, PaaS, and SaaS
We often categorize our stacks into three layers – infrastructure as a service (IaaS), platform as a service (PaaS), and software as a service (SaaS). Then, we classify all the components or services within these layers. For example, VMware falls into the IaaS layer, Cloud Foundry is a PaaS layer sitting on top of an IaaS, whereas cloud applications such as SAP’s Intelligent Suite fall into the SaaS layer.
This classification helps with the separation of concerns (SoC) in terms of having the design patterns and tools focused on specific areas that add value. However, it still requires glue to connect the layers, which is typically the role of a cloud platform. So, when we think about this and the architecture of Kubernetes, what it essentially enables is a new style of architecture design that focuses on extensibility. This extensibility works across all layers, including hardware extensions.
By making use of containers and Kubernetes, we can move from machine-centric designs to application-centric and service-centric designs. We call this type of architecture cloud-native architecture, and Kubernetes is the key enabler that provides the flexibility of IaaS, the extensibility of PaaS, and the simplicity of SaaS. Figure 11.2 illustrates how Kubernetes brings together the layers.

Figure 11.2: Kubernetes connects the layers
Now that we understand the Kubernetes architecture and how it enables application-centric and service-centric architecture design, let’s next have a look at how we can interact with Kubernetes through its object model.
Understanding Kubernetes objects
When we work with the Kubernetes API, we are ultimately dealing with Kubernetes objects, which are persistent entities that represent the states of different Kubernetes clusters and how the workloads are organized in Kubernetes. When creating an object in Kubernetes, we are basically telling the Kubernetes system our desired states, such as the following:
- Where an application needs to run
- The resources available to the application
- How the application will behave during restart policies, load balancing, or fault tolerance
More often than not, we create Kubernetes objects by providing information to the kubectl command-line terminal in a .yaml file. kubectl converts it into JSON and calls the Kubernetes API, and the control plane manages the object’s actual state to match the desired state, as specified in the .yaml file. As such, it is important to understand the different types of objects that can be used to define the workloads in Kubernetes.
Here are some of the core objects:
- A Pod is the most basic unit in Kubernetes, which can contain one or multiple tightly coupled containers that should always be scheduled in the same node and share the same life cycle.
- A ReplicaSet defines the number of Pods that should be deployed in the cluster.
- A Deployment uses ReplicaSets as its building blocks and defines the life cycle of replicated Pods. A Deployment is likely to be the object that we will work with most frequently to create and manage workloads. Based on the Deployment, Kubernetes can adjust ReplicaSets, support applications for a rolling upgrade, and maintain event history.
- A StatefulSet is a specialized Pod controller often associated with data-centric applications, such as databases or stateful applications, which have specific requirements on deployment ordering, persistent volumes, and stable networking.
- A DaemonSet is another specialized controller that runs a Pod on each node in a cluster and is often used for fundamental services, such as collecting logs or aggregating metrics.
- A Job is used to perform a one-off or batch processing task and is expected to exit once the task is completed. A CronJob is just like a conventional cron job in Linux and is used to schedule a Job to run on a regular or reoccurring basis.
- A Service is a component that acts as the interface and internal load balancer to Pods. It groups a collection of Pods and provides the abstraction layer to give access to another application or other consumers. A Service’s IP address remains stable regardless of the Pods that it routes to and can be made available outside of a Kubernetes cluster by opening a static port or through a LoadBalancer that integrates with a cloud provider.
- A PersistentVolume is a mechanism to abstract storage and allows administrators to configure storage at the cluster level, is shared by all containers, and remains available even when a Pod is terminated.
Figure 11.3 summarizes the aforementioned core objects in Kubernetes and their relation to one another.

Figure 11.3: Kubernetes core objects
Imperative and declarative
In Kubernetes, there are two ways to deploy objects, imperatively and declaratively.
The imperative approach outlines how a machine will do something and how it aligns with the operational model of a machine, such as kubectl commands, and is good for interactive experimentation.
In comparison, with a declarative approach, you declare the expected outcomes powered by the declarative Kubernetes API and the controllers. You can tell Kubernetes what you want to do, and it will deliver the outcome within some technical boundaries. This can be achieved by writing manifests in YAML/JSON using the kubectl apply command that refers to the manifest file. Here, the distinction is in how versus what. Declarative design is easier to understand and allows you to focus on problematic domains. Therefore, the declarative approach is used in most production deployments.
Extensions and custom resources
Kubernetes is extensible through custom resources, which extend the Kubernetes API with resource types that are unavailable in the default Kubernetes installation. Custom resources are widely used by many projects, such as the Istio service mesh, Kubeless Serverless Framework, TensorFlow machine learning framework, and Kubernetes itself to make it more modular. There are two ways to create custom resources:
- CustomResourceDefinitions (CRDs) provide a simple way to create a custom object without any programming.
- API aggregation provides a programmable approach that allows for more control by writing your API server with custom business logic, validation, storage, and additional operations other than create, read, update, and delete (CRUD).
Now, we have discussed the architecture patterns, core objects, and extension mechanisms of Kubernetes, demonstrating the benefits of enabling cloud-native development with its improved resiliency and velocity. For SAP BTP, Kubernetes is a key building block and the underlying layer for building new services and applications. Next, let’s discuss what Kubernetes offers as a part of SAP BTP – Gardener and Kyma.
Understanding Gardener
In many companies, it is the responsibility of a central infrastructure team to build and manage shared Kubernetes clusters, and teams are assigned namespaces to segregate the workloads. In a microservices architecture and DevOps model, teams are empowered to make decisions related to all aspects of any service, including the underlying infrastructure. A managed offering makes it much easier for teams to launch and operate their own Kubernetes clusters suited to their needs.
Gardener is a managed Kubernetes as a Service (KaaS) offering used as part of SAP BTP that works across on-premises and multiple cloud environments. In early 2017, SAP put together a small team to figure out how Kubernetes could work for SAP’s workloads. Later in the same year, SAP joined the CNCF community as a Platinum member. This effort led to the creation of Gardener, with its first open-source commit on October 1, 2018: https://github.com/gardener/gardener/commit/d9619d01845db8c7105d27596fdb7563158effe1.
Gardener was created to run enterprise workloads in Kubernetes at scale, including day-2 operations. It is not only capable of provisioning thousands of Kubernetes clusters but also able to manage them 24/7 with scaling and observability capabilities. Some examples of these are rolling upgrades, a scaling control pane, and worker nodes. Gardener has a broad infrastructure coverage and runs on all SAP target infrastructures, on IaaS providers such as AWS, Azure, GCP, and Alibaba Cloud, as well as on OpenStack, VMware, and bare metal. Gardener supports multiple Linux OSs and provides the flexibility and portability of a managed and homogenous Kubernetes offering, together with multi-cloud support. Equally, minimizing the total cost of ownership (TCO) is one of the key design targets of Gardener. Figure 11.4 summarizes and highlights the key features of Gardener.

Figure 11.4: Overview of Gardener features
Next, let’s discuss the unique architecture of Gardener, which uses Kubernetes to run Kubernetes itself to both improve resiliency and reduce TCO.
Gardener architecture
So, what is unique about Gardener architecture?
The foundation of Gardener is Kubernetes itself. Gardener implements a special pattern to run Kubernetes inside Kubernetes in order to operate and manage a huge number of clusters with a minimal TCO.
When you explore the Gardener-managed end user clusters, you cannot find the control plane components that we discussed earlier in the Understanding Kubernetes architecture section, such as kube-apiserver, kube-scheduler, and kube-control-manager.
Instead, the control plane is deployed as a native Kubernetes workload and runs in Pods inside another Kubernetes cluster, which is called a seed cluster. In essence, what a seed cluster provides is a control plane as a service for the Kubernetes clusters running the actual workloads – the end user clusters. In Gardener terms, these end user clusters are called shoot clusters. A seed cluster can potentially host and manage thousands of control planes of the many shoot clusters. This is its main difference from many other managed Kubernetes offerings. To provide necessary resiliency and business continuity requirements, it is recommended to have a seed cluster for each cloud provider and region.
So, how is this architecture achieved in reality?
Gardener implements a Kubernetes-Inception concept and is ultimately an aggregated API server that extends Kubernetes resources with custom resources, combined with a set of custom controllers. A shoot resource is the CustomResourceDefinition (CRD) used to declare the target status of an end user cluster. Gardener will pick up the definition and provision the actual shoot cluster. For every shoot, Gardener creates a namespace in the seed cluster with appropriate security policies.
There are controllers responsible for standard operations such as creating a cluster, performing regular health checks, or performing automated upgrades. Gardener implements the Kubernetes operator pattern to extend Kubernetes and follow its design principles. If you look into Gardener architecture, you will see its similarity to Kubernetes architecture. Shoot clusters are like Pods and seed clusters are like worker nodes. Gardener reuses the same concepts but creates another dimension of scalability in terms of distributed computing and resource management. Table 11.1 compares the Gardener concepts with Kubernetes itself:
|
Kubernetes |
Gardener |
|
Kubernetes API server |
Gardener API server |
|
Kubernetes controller manager |
Gardener controller manager |
|
Kubernetes scheduler |
Gardener Scheduler |
|
Kubelet |
Gardenlet |
|
Worker node |
Seed cluster |
|
Pod |
Shoot cluster |
Table 11.1: Kubernetes versus Gardener
In Gardener, the controller manager manages the custom resources, while Gardener Scheduler is responsible for finding the appropriate seed cluster to host the control plane for a shoot cluster. Here is an example of the steps to create a shoot cluster in Gardener:
- Gardener creates a namespace in the seed cluster that will host the control plane of a shoot cluster.
- The control plane of a shoot cluster is deployed into the created namespace in the seed cluster, which contains the Machine Controller Manager (MCM) Pod.
- The MCM creates machine CRDs in the seed cluster that specify the configuration and number of replicas for the shoot cluster.
- Pods, PersistentVolumes, and load balancers are created by Kubernetes via the respective cloud and infrastructure provider, and the shoot cluster API server is up and running.
- kube-system daemons and add-ons are deployed into the shoot cluster and the cluster becomes active.
Figure 11.5 illustrates the Gardener architecture and how the aforementioned steps interact with different components.

Figure 11.5: Overview of Gardener architecture
Important Note
Gardener is the underlying runtime of SAP BTP and many SAP applications. It is not necessarily visible to SAP customers who will build extensions or new applications on top of SAP BTP. However, it is helpful for you as an architect to understand this common infrastructure abstraction layer and its benefits. To learn more details about Gardener or even consider contributing to it, check out the open-source project at https://gardener.cloud.
Understanding Kyma
If you have some applications that you’d like to extend in a cloud-native way, with the flexibility to use different technologies that can be scaled independently, or use event-based architecture and serverless functions, Kyma could be of interest to you.
So, what is Kyma?
Kyma is an open-source project designed natively on Kubernetes for extending applications using serverless computing and microservices architecture. Based on many years of experience in extending and customizing different SAP applications, Kyma was donated by SAP as an open-source project in 2018, with a mission statement to enable a flexible way of extending applications and with all the necessary tools to build cloud-native enterprise applications. Technically, Kyma picked the best projects from the growing CNCF community and glued them together to offer an integrated and simplified experience, equipped with the following out-of-the-box capabilities:
- Connecting any existing applications to a Kubernetes cluster and exposing its APIs and BusinessEvents securely. You can orchestrate heterogeneous landscapes to build common extensions. This is achieved by a component in Kyma called Application Connector.
- Implementing business logic in microservices or serverless functions using any programming language. Through its integration with connected applications, the extension logic can be triggered either by events or through API calls.
- Using built-in cloud services through the Service Catalog, which implements an Open Service Broker to consume business and technical backing services from GCP, Azure, and AWS in Kyma.
- Out-of-the-box observability for the functions and workloads running in Kyma, including logging, monitoring, metrics, and tracing.
- Using Knative features, such as Build, Serving, Eventing, and the Operator.
Figure 11.6 illustrates the capabilities Kyma provides and the technical components it puts together.

Figure 11.6: Overview of Kyma architecture
While most of the components in Kyma are based on CNCF open-source projects, Application Connector was created by the Kyma team at SAP to simplify connectivity and integration with enterprise applications, no matter whether they are within an on-premises or a cloud system. Application Connector helps to establish a secure connection with external applications and register the APIs and event catalogs of connected applications, delivers registered events, and maps an application to a Kyma namespace by using the registered APIs and events.
The registered applications are exposed in the Service Catalog and associated with the functions in Kyma through service binding. In this way, you can keep the extension code clean, and variables can be injected into functions automatically. Connectivity is secured using a client certificate verified by Istio and generated and stored as a Kubernetes Secret.
Important Note
Knative is an open-source project for building, deploying, and managing serverless and cloud-native applications in Kubernetes. It is an opinionated approach focusing on three areas: building containers and functions, serving and scaling workloads, and eventing. Kyma works and integrates well with Knative.
SAP BTP, Kyma Runtime
SAP BTP, Kyma Runtime is the managed Kubernetes runtime based on the open-source project Kyma. Kyma Runtime can be enabled via Cloud Platform Enterprise Agreement (CPEA) credits, or through a pay-as-you-go (PAYG) model with zero upfront commitment. The monthly consumption of CPEA credits can be calculated with the estimator tool: https://estimator-don4txf2p3.dispatcher.ap1.hana.ondemand.com/index.html.
With SAP BTP, Kyma Runtime, you will get all the functionalities that the open-source project Kyma provides without worrying about cloud operations. In addition, it is embedded into the SAP BTP account model and so is easier to integrate with the rest of the SAP portfolio that uses SAP BTP as the underlying platform. Every Kyma Runtime environment includes the following:
- A Kubernetes cluster provisioned and managed through Gardener on a specified infrastructure provider and in a specified region. Currently, Kyma Runtime is available in AWS and Azure.
- The open-source project Kyma, including all its components based on the latest stable version.
A Kyma environment can be enabled for a given SAP BTP subaccount through the SAP BTP cockpit and runs in its dedicated Kubernetes cluster. Namespaces can be used to organize resources in a cluster.
In addition, to connect and extend SAP solutions based on an event-driven architecture, you can also use SAP BTP, Kyma Runtime to run microservices or full stack applications.
When should you use Cloud Foundry or Kubernetes?
SAP BTP offers the Cloud Foundry application runtime, which is optimized for enterprise application developers to build stateless apps (that follows the 12-factor apps methodology) without worrying about the heavy lifting of deployment and scaling. Alongside Cloud Foundry, SAP BTP offers Kubernetes for both non-opinionated and opinionated workloads, supporting a broader range of technical capabilities and use cases. However, these additional capabilities come at the price of additional learning curves and effort in the day-to-day jobs of a developer. SAP’s strategy is to make use of the benefits of to suit the different needs of its customers.
Equally, making the decision about which runtime to use requires sufficient information about the technology roadmap and means committing to a specific set of tools, technologies, support, and processes, as migrating from one to another can be very challenging. So, between Cloud Foundry’s higher-level abstraction and higher development efficiency and Kubernetes’ more flexible but lower level of technical capabilities, which do you choose for your use case? The short answer is “it depends.” Table 11.2 provides high-level guidelines on the decision criteria:
|
Decision Criteria |
Cloud Foundry |
Kubernetes |
|
Team skillset |
Citizen developers and application developers need higher-level abstraction. |
Cloud-native developers prefer to have low-level access and are comfortable with the level of complexity in exchange for the necessary flexibility. |
|
Use case types |
Stateless applications that follow the 12-factor apps methodology |
Highly scalable microservices, stateful applications. |
|
Infrastructure and regional coverage |
Runs in hyper-scale public clouds only |
Needs to support hybrid and private cloud environments as well |
|
New technologies and services |
Cloud Foundry-based business services and backing services |
Wants to benefit from cloud-native capabilities, such as service mesh, the operator approach, the need for application-specific backing services (through Open Service Broker), or compatibility with special machine types (for example, for AI workloads). |
Table 11.2: Decision criteria between Cloud Foundry and Kubernetes
Please be aware that there is no one-size-fits-all and you will need to assess what will be more suitable for you.
Summary
To recap, we have learned how containers and Kubernetes have helped to modernize software development and service delivery. We have also learned about the core components of Kubernetes, the object model on how we can interact with Kubernetes, and the support of custom resources and extension mechanisms.
Based on this, we have introduced how SAP embraces the cloud-native technology trend and contributes through its two major open-source projects: Gardener, focusing on multi-cloud Kubernetes provisioning and management, and Kyma, focusing on cloud-native application extension and development. Lastly, we have discussed the decision criteria for selecting the environment of choice for your use cases and how you can use this information to plan your projects to extend and build with SAP BTP.
Starting from the next chapter, we will focus on a new section of chapters on data to value. We will cover databases and data management capabilities, such as SAP HANA Cloud and SAP Data Warehouse Cloud, analytics, and intelligent technologies such as machine learning and artificial intelligence. Data is an exciting topic, and we have a lot to cover, so fasten your seatbelt; it will be a fun ride!