
12
SAP HANA Cloud
Applications are increasingly becoming data-driven, and data is generated by everything from enterprise applications and social media to smart devices. While companies are excited about the possibilities with all their data, how to manage data and extract value from it is becoming a common and urgent challenge. In the meantime, modern cloud design principles lead to an increasing number of distributed systems such as microservices architecture and cloud-native applications, resulting in increased complexity for integrating data.
In this chapter, we will introduce database and data management capabilities as part of SAP BTP and how they can help to address these challenges, such as accessing data, processing data, and how to get the maximum value from data. We will focus on the following topics:
- Data-driven use cases
- Data architecture concepts and patterns
- SAP HANA Cloud
- SAP HANA Cloud, HANA database
Before that, let’s have a look at typical data-driven use cases, and data architecture concepts and patterns.
Technical requirements
If you have already registered for an SAP BTP trial account, it is good enough to get hands-on experience with the products we are going to cover in this chapter.
Data-driven use cases
Data is the core element for applications serving diverse use cases from traditional analytics and machine learning (ML)/artificial intelligence (AI) to data-intensive applications that combine both analytical and transactional workloads. All these applications generate data, and almost all enterprises today rely on multiple applications to support their business processes and fight with data accumulated in silos from different applications in their information technology (IT) landscapes. Furthermore, modern applications use a much larger number of data stores—such as objects, documents, and graphs—compared to legacy applications mainly leveraging a relational store. A modern data architecture supported by various data integration and processing technologies will need to address these challenges and hide the aforementioned underlying complexity.
Let’s have a look at a concrete example based on an Intelligent Enterprise scenario to see how data and workflow can be integrated across SAP applications—for example, how to get an overview of and the ability to drill down into all workforce costs such as salary, bonus, travel, equipment, and the external workforce, all scattered among different systems such as SAP S/4HANA, SAP SuccessFactors, SAP Concur, and SAP Fieldglass.
S/4HANA is an enterprise resource planning (ERP) system that typically holds transactions such as salary, bonus, and payments; SAP SuccessFactors is a core human resources (HR) system that keeps all employee master data, including compensation details and bonus plans. SAP Ariba and SAP Fieldglass are procurement systems that employees use to order IT equipment and services, and SAP Concur provides information about business travel and expense reimbursement.
To get full visibility of workforce costs, data sitting in all these systems must be brought together in a harmonized way and be aggregated to calculate key performance indicators (KPIs). Besides employee salary, travel plans can be highly sensitive data and thus must be protected. Access control must be consistently enforced across all involved systems. In addition, insights derived from data can be fed back into systems to trigger new processes—for example, to apply a new travel policy based on budget situations and employee job families. The use case can be further extended with event-driven processing of data, to enable active notifications or other real-time interactions.
Derived from the aforementioned use case are typical data-driven scenarios in which data coming from multiple places must be combined, and should include both structured and unstructured data such as images and documents that are stored in various databases or storage systems.
The following list is not a complete list of all scenarios; rather, it provides a glimpse of common use cases that each company may have:
- Data and process integration: To enable business process and workflow integration based on data. In such integration scenarios, data is shared across multiple applications through aligned data models or application programming interfaces (APIs), or an integration middleware such as SAP Integration Suite. Data or events generated in one application can trigger actions in other applications. A loosely coupled event-driven pattern can be used to achieve integrations elegantly.
- Cross-product analytics: As with the workforce cost use case, it is essential to combine data from multiple sources to gain insights and realize the value of data. To be able to join data together, data harmonization is required, such as master data entities—for example, employee or cost center. Data can be connected both through federation that connects data virtually and replication into a central location for advanced processing. Data modeling and metadata management must be included, and analytical contents created must be extensible to meet different business needs—for example, adding a new data source.
- ML/AI applications: Apart from classical analytics applications, ML/AI applications usually need to process all types of data such as images, voices, videos, and sensor data from smart devices. Training of algorithms can be resource-intensive and requires underneath data platforms to support heavy computations. In this case, it would make more sense to extract data from source applications and consolidate this in a centralized data platform.
- Data-intensive applications: Require fast processing of huge amounts of data that often needs a distributed high-performance data platform with parallel execution. Such applications may involve ML/AI but with more focus on processing than training—for example, extracting information from invoices, monitoring sensor data, and performing searches over vast amounts of data. Besides, data pipelines with the necessary data lineage and life-cycle management (LCM) can provide transparency as data is usually processed in multiple steps.
Data architecture concepts and patterns
To support the data-driven use cases, architecture concepts and patterns have evolved over the years to solve specific problems. Let’s review them together, and later, we will discuss SAP data management capabilities in this context.
OLTP, OLAP, HTAP
The terms online transaction processing (OLTP) and online analytical processing (OLAP) look similar but refer to two different kinds of data systems. An OLTP system captures and manages transactions in a database, in the form of insertion, updating, and deletion of data frequently. Tables in an OLTP database are usually normalized, and data integrity must be taken care of in case of any transaction failure. In comparison, OLAP’s main operation is to extract multidimensional data for analytics, which has less frequent transactions but requires a longer time to process data as data needs to be denormalized and joined together by running complex queries to turn data into information.
The different requirements of OLTP and OLAP result in having different data systems optimized for their purposes. Data from one or more OLTP systems is ingested into OLAP systems through the process of extract, transform, load (ETL). An ETL pipeline supported by various tools collects data from several sources, transforms it into the desired format, then loads it into a destination system such as an OLAP data warehouse to support analytics and business intelligence (BI) for insights. Depending on the use case, the ETL process can be very complex and requires extra storage, special care with data security, and privacy alongside data movement.
In some areas, using after-the-fact analysis is not acceptable. Organizations must respond quickly to business opportunities in real time. Hybrid transactional/analytical processing (HTAP) is a term that represents a data architecture that can handle both transactional and analytical workloads in one system, thus eliminating the need for multiple copies of the same data and the ETL process. HTAP has the potential to change existing business processes as well as create new ones by offering real-time decision-making based on live transactional data and the capability to run sophisticated analytics on large amounts of data. Most HTAP systems are enabled by in-memory and scalable transactional processing technologies. SAP HANA and its managed offering of SAP HANA Cloud are examples of such HTAP systems.
NoSQL, big data, and cloud object stores
To extend the data architecture beyond relational database management systems (RDBMS), we cannot avoid talking about NoSQL and big data. NoSQL is not a product; rather, it’s a collection of different data storage and processing systems to meet different kinds of needs.
NoSQL had a good run; it was created by Hadoop MapReduce in 2004 and was accelerated by Dynamo and BigTable in 2007. NoSQL has won in terms of popularity in the past decade by addressing one of the core limitations of traditional RDBMS—scalability, by starting with distributed system design and data management that provide high availability (HA) and scalability. In the Consistency, Availability, and Partition Tolerance (CAP) theorem, most NoSQL databases prioritize A and support eventual consistency for C. While it promises scalability and flexibility, NoSQL has fallen short in many areas, especially in its early days, such as no support for Structured Query Language (SQL), no support for transactions, and no schema management. It has also evolved from simple key-value stores to document stores, column family stores, and SQL on Files processing engines.
During its prime time, Hadoop and NoSQL technologies were often connected with big data, and this represents a whole ecosystem of technologies. In the past few years, we have seen consolidations in this space; however, it is still one of the key challenges many organizations face during data integration and building a future-proof data architecture. Besides, many NoSQL databases have added SQL-like capabilities such as the Cassandra Query Language (CQL) and Spark SQL, thus the term NoSQL itself is becoming obsolete.
In the meantime, cloud object stores such as Amazon Web Services (AWS) Simple Storage Service (S3) are becoming attractive and are the preferred storage solution for many companies. Object storage benefits from the mature infrastructure of cloud providers with low cost and built-in capabilities such as HA, scalability, and global and regional distribution, without worrying about the complexity of setting up and maintaining landscapes.
Data federation and data replication
Given the complexity of the existing and ever-growing ecosystems of data technologies, how we can bring together data? Now, let’s talk about data integration approaches such as data federation and data replication.
Data federation allows multiple databases to function as one. Data federation helps to remove data silos, resulting in more accurate, reliable, and consistent data. Data federation also avoids costs for redundant storage, software licenses, or extra data governance. Because it doesn’t replicate or physically move data, it reduces the risk of data loss and makes it much easier to set up and manage authentication and authorization of data access.
However, data federation runs into limitations when data volumes and complexities are present—for example, HA and scalability, predictable low latency, and high performance. Data federation also falls short when sophisticated data cleaning and transformation are required. In such cases, data replication is the better approach. Creating multiple copies of data through data replication increases overall availability and reduces latency as data can be stored closer to its consumers. It also improves performance and provides more flexibility to run complex queries or advanced analytics with dedicated data stores optimized for workloads, instead of distributed fragile joins involving multiple databases and high network latency through data federation.
As there are advantages and disadvantages to both approaches, a modern data architecture will need to involve both and be able to switch between them seamlessly.
SAP HANA Cloud
SAP HANA Cloud is a managed offering of the in-memory HTAP database SAP HANA. It inherits the capabilities of SAP HANA such as multi-model support (relational, hierarchies, graph, geo-spatial, semi-structured data), advanced analytical processing, and flexible data integration. As a cloud offering, all infrastructure layers such as compute, storage, and networking are automatically provisioned and monitored; backups and upgrades are taken care of automatically, so you can benefit from the reliability, scalability, integrated security, and productivity improvement of unified cloud-based tooling.
HANA Cloud supports a variety of use cases. It can act as a gateway to all enterprise data with virtual connections and data replications, be the backbone of advanced analytics and reporting with SAP Data Warehouse Cloud and SAP Analytics Cloud, and be the runtime database for your enterprise applications such as SAP Intelligent Suite applications.
In a nutshell, HANA Cloud is comprised of the following components to store and process various types of data:
- SAP HANA Cloud, SAP HANA database: This is an in-memory database for multi-model data processing, providing fast access and unmatchable performance.
- SAP HANA Cloud, Data Lake: Leverages inexpensive storage options to lower costs, while providing high performance for querying petabytes (PB) of relational data.
- SAP Adaptive Server Enterprise (SAP ASE): Enables extreme OLTP scenarios for many concurrent users.
- SAP HANA Cloud, SAP ASE Replication: This is a log-based replication system that supports real-time data replication between ASE instances.
While multiple components have been introduced into SAP HANA Cloud to provide the necessary flexibility to scale data from an in-memory disk to an object store (SQL access to relational data in Parquet files), it allows picking the best option based on required qualities concerning performance, cost, or other key performance indicators (KPIs). The following diagram provides high-level guidance on data storage options in SAP HANA Cloud:
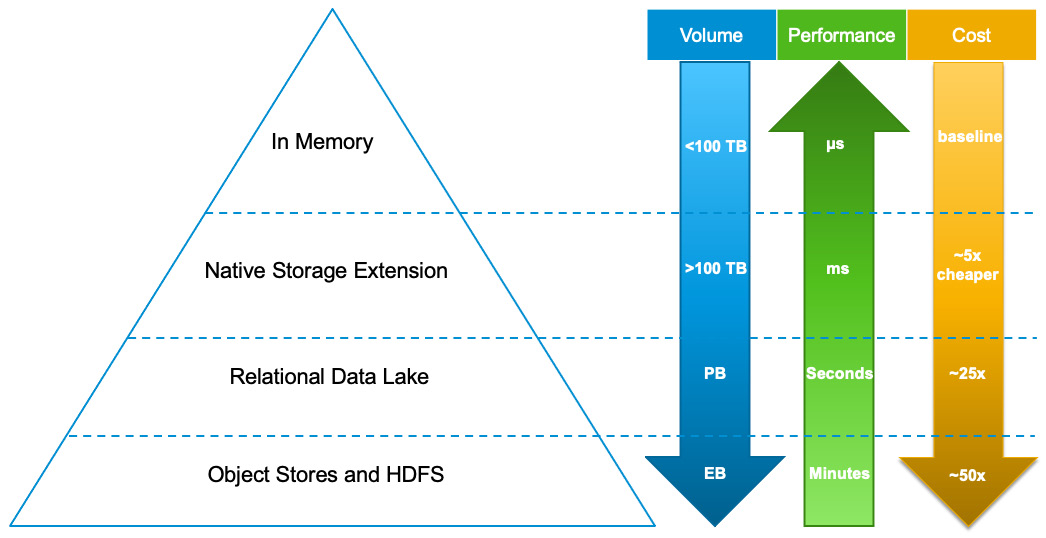
Figure 12.1: Data pyramid of SAP HANA Cloud
Besides this, HANA Cloud optimizes data access and query processing between different storage options—for example, sending child plan fragments to a remote source.
Rather than hold all data in memory, Native Storage Extension (NSE) is a built-in warm store to manage less frequently accessed data. NSE is enabled in SAP HANA Cloud by default. It uses techniques to only load pages related to your query into memory; you can use the ALTER TABLE and CREATE TABLE commands to specify which columns, tables, or table partitions are page-loadable through the <load_unit> PAGE value. NSE is transactionally consistent with in-memory hot data, included in backup and system replication operations, as a substantial increase of data capacity with overall good performance for SAP HANA to handle high-volume data.
SAP HANA Cloud, Data Lake, based on Intelligent Query (IQ) technology, is the relational data lake layer that scales independently and integrates with HANA Database through a highly optimized Smart Data Access (SDA) connection including query delegation. It also provides the capability to access cloud object storage such as AWS S3, and Google Cloud Platform (GCP) Cloud Storage.
SAP HANA Cloud runs on containers and Kubernetes managed through Gardener, mentioned in the previous chapter, to accommodate independent and elastic scaling of storage and computing, and provides HA, scalability, resiliency, and total cost of ownership (TCO) optimization.
Important Note
SAP HANA Cloud is the successor of SAP HANA Service, a managed HANA database offered through Neo and multi-cloud environments. SAP will continue to support the SAP HANA service for customers with existing contracts, but new customers are not eligible to buy the SAP HANA service anymore.
Tools to access SAP HANA Cloud
One of the cloud benefits is to access SAP HANA Cloud through a centralized, unified user experience (UX) with powerful cloud-based tooling, all through web user interfaces (UIs). Depending on the role and task type, you can use one of the tools mentioned next to achieve your goals.
SAP BTP Cockpit
SAP BTP Cockpit is an administration interface for managing almost all components and services in SAP BTP, such as global accounts, subaccounts, entitlements and quotas, subscriptions, and authentication and authorization. It is the starting point for creating and managing SAP HANA Cloud instances. To get an overview of your instances, navigate to the Cloud Foundry (CF) space and then choose SAP HANA Cloud in the navigation area. For each instance, you can check the status, memory, central processing unit (CPU), and storage consumption, or navigate to other cloud tools for more detailed administrative tasks.
SAP HANA Cloud Central
SAP HANA Cloud Central is where you can create, edit, or delete your instances. The provisioning wizard allows users to configure options such as type of instance, availability zones (AZs) and replicas, network connectivity, and other settings.
Replica management is also supported; you can add a new replica to improve availability or initiate a takeover from an asynchronous replica for your HANA instance. In a recovery scenario, there are different options—you can either recover the backup into a new instance by using Recreate Instance or recover to a selected point in time of the same instance using Start Recovery if a backup is available, providing businesses options to meet their business continuity (BC) requirements.
SAP HANA Cockpit
SAP HANA Cockpit is available for both HANA on-premises and HANA Cloud, providing a range of tools for database-level administrative and monitoring tasks. It is provisioned in the same CF space when the HANA Cloud instance is created, so you don’t need to install it separately.
SAP HANA Cockpit aims to provide a single pane of glass for HANA database instances. It provides a SAP Fiori-based launchpad with real-time information in the form of tiles arranged in groups. Administrators can use it to manage multiple landscapes and instances with less effort, have more visibility of the overall system status with detailed metrics of each resource, and be alerted when attention is needed to prevent system downtime. SAP HANA Cockpit includes the following features:
- Managing database configurations and update parameters/values for different server types
- Managing database operations such as data volume encryption, automated backups, and data replications
- Monitoring and analyzing workloads, alerting, and diagnostics; monitoring service status, performance, and threads; and understanding resource utilization (CPU, memory, and disk) and SQL statement analysis
- Security administration (for example—manage users and roles, enable audit trails and policies, manage certificates, configure identity providers (IdPs))
SAP HANA Database Explorer
Integrated into SAP HANA Cockpit, SAP HANA Database Explorer is a tool for managing data and database objects of SAP HANA Cloud. You can browse the database catalog and check individual database schemes, tables, views, procedures, remote connections, or other objects. It includes the SQL console where you can execute SQL statements and analyze the query execution, or even debug an SQLScript procedure.
SAP Business Application Studio
SAP Business Application Studio is the next generation of SAP Web IDE, offering a development environment for SAP BTP. You can launch SAP Business Application Studio from SAP BTP Cockpit. At the heart of SAP Business Application Studio are Dev Spaces, which are private environments such as isolated virtual machines (VMs) to develop, build, test, and run your code. Each Dev Space type includes tailored tools and preconfigured runtimes for the target development scenario—for example, SAP Fiori, mobile development, CAP-based (here, CAP refers to SAP Cloud Application Programming Model) applications, and certainly HANA native applications. The following screenshot shows the page to create a Dev Space for HANA development with default and additional predefined extensions:

Figure 12.2: Creating a Dev Space for SAP HANA Native Development
Important Note
If you are using an SAP BTP trial account, SAP Business Application Studio may have already added it to your subaccount. Otherwise, enter the CF environment and find SAP Business Application Studio in the Service Marketplace and create a subscription. After that, it will appear in Instances and Subscriptions in SAP BTP Cockpit.
SAP HANA Cloud, HANA Database
At the core of SAP HANA Cloud is the HANA database itself—the in-memory data platform. In this section, we will discuss topics you as an architect would like to know, from its system architecture, various development scenarios, data integration approaches, HA and BC, data encryption, feature compatibility, migration, and pricing, as well as its release strategy and data center availability. We have quite a lot to cover, so let’s start!
System architecture and server types
The HANA system is comprised of multiple server components running as different operating system (OS) processes and services in a host or a cluster of hosts. In SAP HANA Cloud, here are the core servers:
- Name server: Owns the information of the topology of the overall system. In a distributed system, it knows where the components are running and where data is located.
- Index server: Contains in-memory data stores. It segments all queries and contains several engines and processors for query executions, such as Planning Engine, Calculation Engine, and Store Procedure Processor. It also includes Transaction and Session Management for coordinating all database transactions and managing sessions and connections. An index server is not shared, and each tenant database must have its own index server.
- Compile server: Performs steps for compiling stored procedures written in SQLScript.
- Data provisioning server (dpserver): Offered as part of Smart Data Integration (SDI), which provides data provisioning, data transformation, and data quality functions, adapters for remote sources, and a software development kit (SDK) for creating additional adapters.
- SAP HANA Deployment Infrastructure Server (diserver): Simplifies the deployment of database objects using design-time artifacts.
You may notice that HANA Cloud has fewer servers in comparison to the HANA on-premises system, which has additional servers such as the preprocessor server used by the index server for text analysis and text search, or SAP HANA XS Advanced Services for HANA native application development. These server components are removed from HANA Cloud.
Development with SAP HANA
There are multiple ways of developing applications with SAP HANA Cloud, from using HANA as the database runtime through Java Database Connectivity (JDBC)/Open Database Connectivity (ODBC) or Object Relational Mapping (ORM) frameworks, advanced data modeling, to native development with HANA Deployment Infrastructure (HDI) containers and using the CAP model to create full-stack applications. We will discuss these development scenarios next.
Using SAP HANA Cloud as the database runtime
Just as with any other database, you can use HANA as the database runtime. In this case, you can use standard SQL statements to create, update, or delete database objects such as schemas, tables, and views, as well as run queries, join tables, filter data, and so on.
SAP HANA Client needs to be installed to provide a connection to the HANA Database using JDBC and ODBC, with the following connection strings respectively:
- JDBC: "jdbc:sap://<endpoint>:<port>/?encrypt=true"
- ODBC: "driver=libodbcHDB.so; serverNode=<endpoint>:<port>;encrypt=Yes"
The SAP HANA client also includes a command-line tool for executing database commands (for example, Data Definition Language (DDL); Data Manipulation Language (DML)) in a terminal window—HDBSQL. It can also execute commands from a script file for scheduled execution.
Drivers and libraries are supported for all major programming languages. For Node.js,@sap/hana-client can be used to connect and run SQL queries. It can be simply installed by running npm install @sap/hana-client. Find more details at https://www.npmjs.com/package/@sap/hana-client.
Similarly, Python, Go, Ruby, ADO.NET, and more programming languages and OSs are supported. You can check SAP Note 2648274 for SAP HANA client interfaces at https://launchpad.support.sap.com/#/notes/2648274.
Data modeling with SAP HANA Cloud
The modeling process involves the activities of slicing and dicing data in database tables by creating information views that can be used for reporting and decision-making. SAP HANA supports extended SQL views generated from design-time objects—modeled views. Historically, three types of modeled views were supported, which are attribute views, analytic views, and calculation views.
Calculation View
The Calculation View combines the functionalities of all three types of views, and it is the only one supported in SAP HANA Cloud for modeling and analytical use cases.
Calculation Views allow data modelers to create advanced slices of data for analytics and multidimensional reports, by integrating various combinations of data (for example, entities and their relationships) to model a business use case. Data can be combined and processed with operations such as joins, unions, projections, and aggregations. If CUBE is selected as the data category, Star Join can be enabled to simplify the design process to join fact tables and dimensional tables. Advanced SQL logic can be applied, and in complex data models, multiple layers of Calculation Views can be combined. At the top of a Calculation View is the semantics node, where attributes (descriptive data such as customer identifier (ID) or sales order), measures (quantifiable data such as revenue or sales amount), and aggregation methods such as AVG, SUM, and MAX can be specified, which determines how the data will be exposed and consumed.
It is important to understand that Calculation Views are design-time artifacts and different from the corresponding database objects such as runtime objects. Actual database objects are created when the views are deployed (through HDI, which we will discuss in the SAP HANA Native Development section).
SQLScript
SQLScript is the default programming language for writing database procedures in SAP HANA. SQLScript is a collection of SQL extensions—for example, data type extension with table types. A table type defines the name and attributes of an “internal table” that can be viewed as a temporary table without creating an actual database table. It can then be used to create table variables; the intermediate results of a SQL statement can be stored in the table variables and can be used as the data source for subsequent SQL queries.
An SQLScript procedure may contain SQL statements or call other procedures. Control flows such as if/else conditions and loops are supported, and a cursor can be opened to iterate through a result set. However, one of the key benefits of SQLScript is to embed data-intensive logic into the database layer to avoid massive data copies to the application layer and allow massive parallelization and execution of complex calculations inside HANA. Even though loops and cursors can process data in each row, it is always recommended to use read-only procedures with declarative table operators to allow mass data processing to achieve the best performance.
SAP HANA Native Development
To understand how HANA Native Development has evolved, let’s go back a little bit to the history of SAP HANA extended application services (XS Classics), XS Advanced, and the introduction of HDI. The following screenshot summarizes the major differences between them:
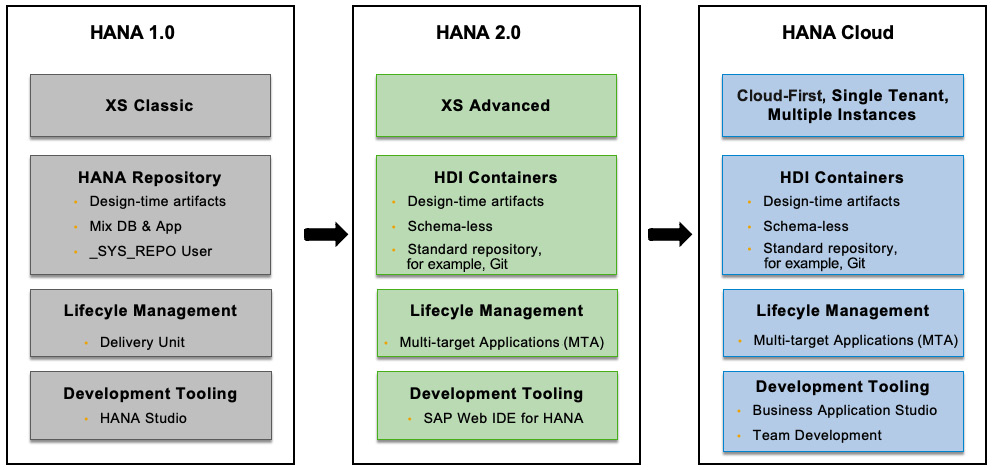
Figure 12.3: HANA Native Development evolution
HANA extended application services (XS Classic) were introduced in HANA 1.0 Support Package Stack (SPS) 05 as an embedded lightweight application server that includes web-based HyperText Transfer Protocol (HTTP) and Open Data Protocol (OData) services. It is tightly coupled with database objects and uses database permissions and database user _SYS_REPO for content management in HANA Repository. All roles are global roles in the database and owned, built, and granted with privileges of _SYS_REPO. Content isolation is only possible using schemas and packages. SAP HANA XS Javascript (XSJS)—server-side JavaScript—and oData are the only programming interfaces supported in XS Classic, using HANA Studio and Web Development Workbench as development environments.
Introduced in HANA 1.0 SPS 11 and widely adopted in HANA 2.0, SAP HANA XS Advanced is an enhanced application server, based on the learning of the limitations of XS Classic such as scalability and the demands of more programming language support such as Java and Node.js. In XS Advanced, contents are deployed into organizations and spaces as with a CF environment; content isolation is achieved by the introduction of HDI containers. Roles are owned by schema-level technical users created by HDI that are separated from application development roles. Instead of using HANA Repository, it uses standard repositories such as Git.
SAP HANA Cloud implements a cloud-first approach for native development. Multi-tenancy is achieved by creating multiple HANA instances, and each instance itself is a single-tenant database. HDI continues to be the core of HANA Native Development in HANA Cloud and has been nicely integrated with development tooling such as Business Application Studio; for example, you can bind your application to an HDI container deployed in a BTP CF environment. Even though HDI was introduced together with XS Advanced, they are not dependent upon each other; XS Advanced is not even included in HANA Cloud.
Understanding HDI
To understand HANA native development, the first thing is to understand what HDI is and the key benefits of using HDI. You may have heard about HDI containers and wondered how they relate to multi-tenant database containers (MDC) or Docker containers. The fact is it has nothing to do with either of them. So, what is HDI?
In a nutshell, HDI is a component and mechanism in SAP HANA to simplify the deployment of database objects using declarative design-time artifacts. It ensures a consistent deployment and implements transactional all-or-nothing deployment by checking dependencies and grants that multiple objects are deployed in the right sequences.
HDI offers a declarative approach to creating database objects; otherwise, these would be created through SQL DDL in imperative statements such as CREATE TABLE. The declarative way allows you to describe the desired target state in a design-time file and let HDI take care of the creation when the design-time file is deployed. This approach offers a higher level of abstraction that is easier to understand and more flexible and powerful to write logic than plain SQL. Design-time files can be versioned in a source code management system such as Git and can be used to ship database contents, just as with other application code. HDI only covers the deployment of database objects such as tables, views, and procedures, not non-database contents such as web and application code.
Isolation is one of the key features of HDI, achieved through HDI containers. In a HANA database, an arbitrary number of HDI containers can be created, and each container is implemented by a set of database schemas technically and isolated from other containers through schema-level access controls. Application developers don’t need to explicitly specify the schema name in SQL statements, and this enables schema-independent code. Instead, the following schemas are created by HDI under the hood:
- Container runtime schema: <schema>, which contains application database objects that are accessible by the application at runtime.
- Container metadata schema: <schema>#DI contains design-time files, dependencies between objects, and additional metadata required for the deployment process.
- Object owner schema: <schema>#OO represents the technical user created as the HDI container’s object owner (also known as #OO user). The object owner is a restricted database user who has a CREATE ANY privilege on the schema but no external privilege by default. The schema itself is empty.
- Design-time user schema: <schema>_<user>_DT represents technical users used for creating database objects from design-time artifacts.
- Runtime application user schema: <schema>_<user>_RT represents technical users to access runtime database objects by the applications.
Deployment into HDI containers includes two steps: first, upload design-time artifacts into the container metadata schema, then deploy the contents in the metadata schema into the database. The uploaded design-time artifacts are organized in virtual filesystems in HDI. For each HDI container, there are two virtual filesystems. Newly uploaded design-time files are stored in the work filesystem first, and then promoted to the “deployed” file time during the deployment, and corresponding database objects are created or updated in the container schema. The deployment operation, as well as uploading design-time files, is invoked by calling the HDI APIs (based on SQL procedures) generated in the container metadata schema when a container is created. The following screenshot shows an example of generated HDI schemas and the HDI API procedures of a HANA database project created in Business Application Studio named MYHANA:
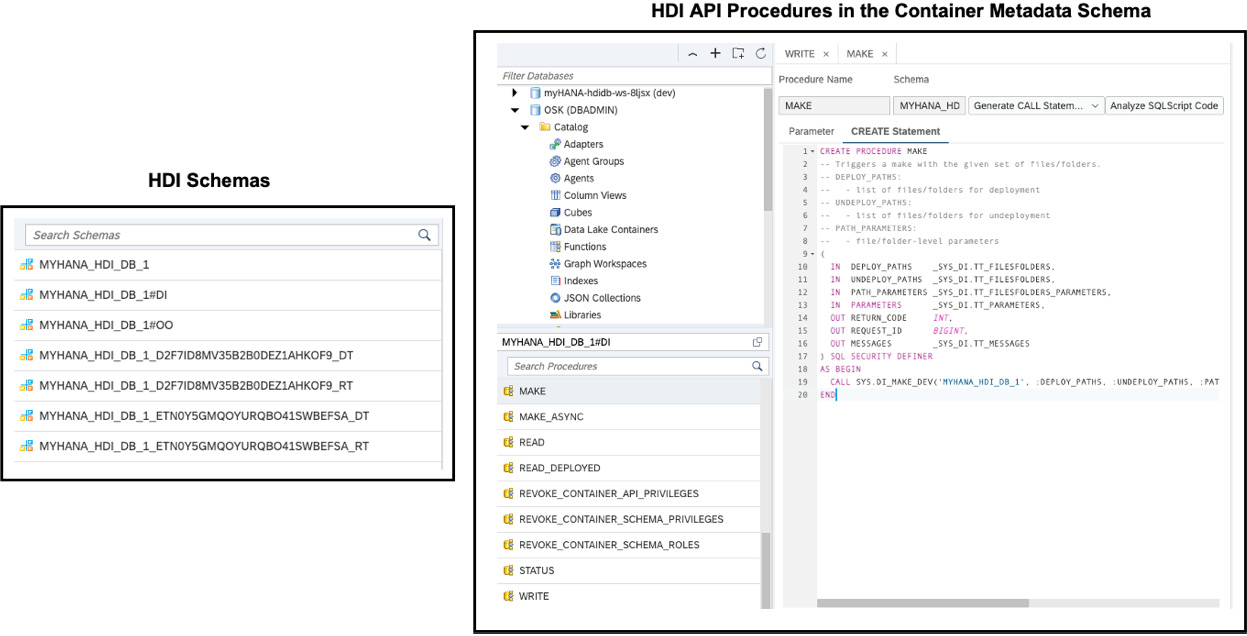
Figure 12.4: HDI schemas and HDI API procedures
HDI uses container-specific technical users; there are different technical users for different tasks—for example, the technical user that is used to create application database objects should have no access to the metadata schema and HDI API procedures and ensure runtime users only have access privileges on the container schema. These technical users are created in the object owner, design-time, and runtime user schemas. Cross-container access is prevented by default but can be enabled by granting necessary privileges explicitly and creating synonym binding configurations in the .hdbsynonym file. To be able to access objects in another container, the container’s object owner user will require corresponding access privileges on objects in the target schema—for example, grant a SELECT privilege of the target schema to the #OO user with the GRANT/ADMIN option. Synonym binding is also applicable when you need access to a non-HDI-managed schema.
The following diagram illustrates how deployment to an HDI container works in steps:
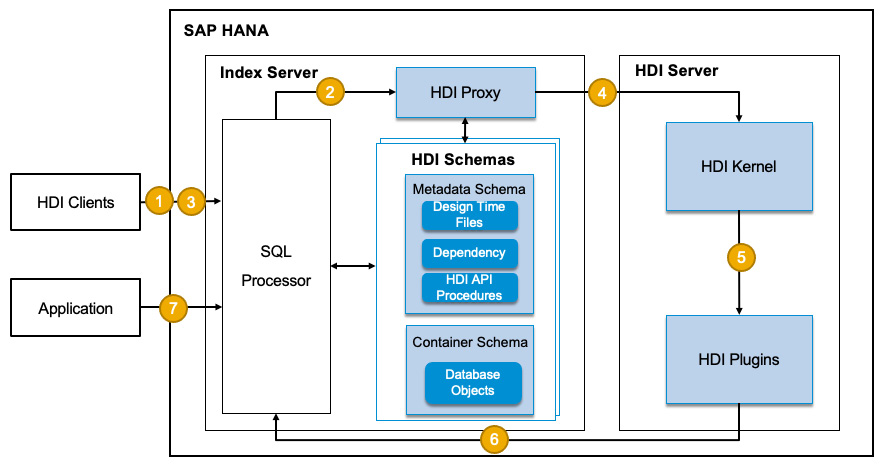
Figure 12.5: HDI deployment steps
The steps go like this:
- HDC clients (for example, through Business Application Studio in the CF environment) upload the design-time files by calling a container-specific WRITE API procedure to SQL Processor.
- SQL Processor delegates to the HDI proxy library to write the files to the “work” virtual filesystem in the container metadata schema.
- Once uploaded, the HDI clients call the MAKE API procedure to trigger the deployment of involved contents in the virtual filesystem, which is dispatched to the HDI proxy again.
- The HDI proxy calls the HDI server. The HDI server reads the files from the container metadata schema.
- The HDI kernel in the HDI server calls the HDI plugins for the different types of design-time files—for example, .hdbtable for table definition, .hdbprocedure for stored procedures definition, as well as Core Data Services (CDS) files. The mapping between plugins and file types can be configured in a configuration file (.hdiconfig, a join file that contains a list of bindings between design-time artifact file types and plugins and their versions). The plugins interpret the files and extract dependencies to determine the deployment order and translate them into SQL statements to be executed.
- The HDI kernel evaluates the extracted dependency information and calls the plugins to execute SQL to apply changes in the container schema, after which transactional deployment is ensured—for example, the entire transaction is rolled back in the event of an error.
- Finally, database objects are created or updated in the container schema and then can be accessed by the applications.
HDI containers can be grouped via container groups for administrative purposes. An HDI container administrator can create container groups, add a container to a container group, and manage container group privileges. A container group role is granted to the container object owners (the #OO user) belonging to a container group.
HDI Administration Cockpit, as part of SAP HANA Cockpit, provides the monitoring and administration of HDI containers and container groups that you can use to investigate resource utilization and manage administrator privileges.
You have now understood what HDI is and how it works; so, how do your applications connect with HDI containers?
Binding an application to a SAP HANA Cloud instance
You can bind an application to a SAP HANA Cloud instance through a schema or an HDI container, through a SAP HANA service broker instance (SAP HANA Schemas & HDI Containers) that provides schema and hdi-shared service plans, as shown in the following screenshot:
Figure 12.6: SAP HANA Schemas & HDI Containers’ service plans
The schema service plan can be used to create a plain schema that you can manage manually. Consider using it if you want to use an ORM framework or use HANA as the database runtime only.
The hdi-shared service plan is used to create a broker instance to bind an application deployed in SAP BTP to an HDI container via the HDI Deployer. The HDI Deployer is essentially a Node.js (@sap/hdi-deploy) based deployment module for HDI-based persistence models. Usually, the HDI Deployer is already packaged into the db module as part of a multi-target application (MTA). The HDI Deployer can also be used without MTAs; to install it manually, simply run the following command:
npm i @sap/hdi-deploy
The following screenshot shows the configuration in an MTA.yaml file and credentials applications received once bound to an HDI container. The binding enables applications to access the HDI container without worrying about database access and connections. You will also see that the technical users mentioned previously (such as <schema>_<user>_DT and <schema>_<user>_RT) are used to access the corresponding design-time and runtime objects:

Figure 12.7: Application binding to an HDI container
CAP, CDS, and HANA Cloud
SAP CAP is a development framework for enterprise applications that provides the necessary libraries and out-of-box capabilities to speed up development. CAP is an opinionated framework based on a core set of open source and SAP technologies.
CDS is the universal modeling language and backbone of CAP that allows you to define domain models, services, queries, and expressions in a declarative way. CDS models are plain JavaScript objects based on Core Schema Notation (CSN), an open specification based on JavaScript Object Notation (JSON) Schema, which is used to generate target models such as OData/Entity Data Model (EDM) or OpenAPI, and database persistence models.
CDS, in combination with HDI previously discussed, is basically how CAP-based applications work with HANA Cloud. An entity created by CDS that serves as a façade of the objects is called a façade entity. The façade entity handles CDS-to-database-type mapping—for example, map an entity name to a database object name; map elements of an entity to database table columns; map the data types. You can create entities, associations, and compositions to capture the relationships between entities. It is possible to create either new database objects or use existing ones in a CDS model. To tell CDS that an object is already in the database, just add the @cds.persistence.exists annotation so that it will not be generated again. To understand more about CAP, please visit https://cap.cloud.sap/docs/.
HANA ML libraries
SAP HANA includes Automated Predictive Library (APL) and Predictive Analysis Library (PAL) to support ML and data mining capabilities covering a variety of algorithms and predictive models such as clustering, classification, regression, time-series forecasting, and more. The regression models and classification models implement a “gradient boosting” approach that applies learnings from each iteration step to provide a more accurate modeling result.
Both APL and PAL are installed in SAP HANA Cloud by default. However, they require Script Server to execute functions. Script Server is not enabled by default and can be enabled or disabled in SAP HANA Cloud Central.
Important Note
APL can also be called in Python via the Python ML client for SAP HANA (hana-ml). More details on hana-ml can be found at https://help.sap.com/doc/1d0ebfe5e8dd44d09606814d83308d4b/2.0.05/en-US/html/hana_ml.html.
Data integration through federation and replication
In SAP HANA Cloud, you can create virtual tables through federation to access remote data as it was stored as a local table or use data replication.
A virtual table creates a link to a physical table in another HANA instance or other database, and data is read from the remote table and translated to HANA data types, in batches or in real time. While this gives the advantage that data doesn’t need to be copied (thus reducing time), accessing data remotely might not be the ideal approach if you need to run complex queries by joining multiple tables spanning across different databases or have a specific need for query performance. In that case, data replication is recommended, and you can also set up replications automatically, such as by using remote table replication.
Next, we will have a look at the different technologies available in HANA Cloud to support the different scenarios of federating or replicating data into SAP HANA Cloud from various sources—SDA and SDI. The following screenshot shows different methods for remote access when SAP HANA Cloud is the target system:
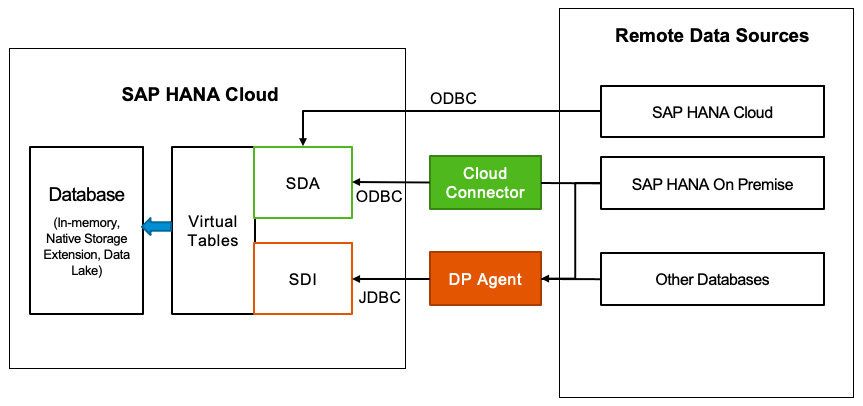
Figure 12.8: SAP HANA Cloud Data integration options
- If the source system is also SAP HANA Cloud, SDA is the simplest way to use the ODBC adapter.
- If the source system is a non-HANA database, SDI with the Data Provisioning Agent (DP Agent) should be used.
- If the source system is a SAP HANA on-premises database, either SDA (ODBC) or SDI with DB Agent (JDBC) can be used. Cloud Connector is needed if the one-premise HANA is protected by a firewall.
Important Note
SDA and SDI support a different set of connections. The list of supported remote sources is also different between SAP HANA Cloud and SAP HANA On-Premise. New sources can be added or removed from a new release; see SAP Note 2600176 – SAP HANA Smart Data Access Supported Remote Sources for the latest information at https://launchpad.support.sap.com/#/notes/2600176 and SDI Product Availability Matrix (PAM) at https://support.sap.com/content/dam/launchpad/en_us/pam/pam-essentials/TIP/PAM_HANA_SDI_2_0.pdf.
Data encryption
Data encryption at rest and in transit has become a mandatory requirement in modern system architecture. Encryption in transit protects data if communications are intercepted during data movement; for instance, Transport Layer Security (TLS) is often used for encrypting information—encrypted before transmission and decrypted on arrival.
Encryption at rest protects data while stored and can be applied at different layers such as database, application, or the underneath storage layer at the disk volume level. However, storing encryption keys on the same server as data no longer meets security standards for many companies. Several standards exist, depending on the industry—for example, Payment Card Industry Data Security Standard (PCI DSS) defines the duration of the period until keys must be rotated. Federal Information Processing Standard Publication 140-2 (FIPS 140-2) defines security levels and where to store encryption keys.
There are two types of encryption keys: symmetric and asymmetric. The symmetric approach uses the same key for encryption and decryption, while the asymmetric approach uses a pair of public and private keys that are mathematically related, to encrypt data with a public key and decrypt data with the corresponding private key. As the asymmetric approach is computationally intensive, it is often used for encrypting keys named key encryption keys (KEKs), while the actual data is encrypted by a data encryption key (DEK) using the symmetric approach. DEKs encrypted with KEKs are typically stored separately outside of a key management system (KMS) or a hardware security module (HSM). KEKs used to encrypt DEKs never leave the KMS or HSM. This hybrid approach is often referred to as envelop encryption, as illustrated in the following diagram:
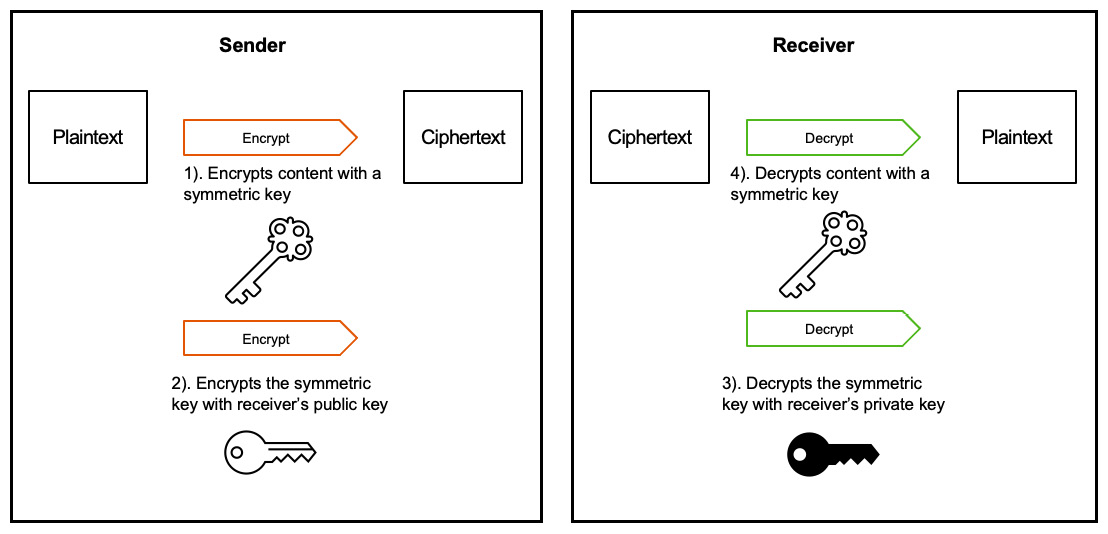
Figure 12.9: Envelop encryption with symmetric and asymmetric keys
In SAP BTP, SAP Data Custodian is the KMS fulfilling the compliance requirement for encryption keys, which provides a consistent way to manage the life cycle, including key rotations, secure storage of encryption keys, and audit logs for transparency. It integrates with the hyperscaler provider’s KMS and HSM services that meet FIPS 140-2 Level 2 and FIPS 140-2 Level 3 compliance respectively. SAP HANA Cloud uses SAP Data Custodian to provide advanced encryption capabilities to enable customers to supply and manage their keys.
HA and BC
HA and BC are important, especially for mission-critical systems. SAP HANA Cloud provides multiple available options based on different business needs, leveraging the multiple AZs provided by the underneath cloud infrastructures.
When creating a new instance through SAP HANA Cloud Central, you can define an AZ of interest to place the instance, which allows placing the database instance as close as possible to the applications to ensure low latency between the systems. For instances running on top of Microsoft Azure, it is possible to derive the AZs based on your Azure subscription ID automatically.
If you have your HANA Cloud instance running and want to extend it with a HA setup— with redundant instances called replicas—you can enable synchronous replication between multiple instances within the same AZ; redo log shipping and replay are enabled continuously. Consistency between the instances is the top priority here, and the replication mechanism guarantees that a transaction is committed only when applied in both instances. SAP HANA comes with built-in failure detection with autonomous takeover if one instance is unavailable.
For disaster recovery (DR) purposes, multiple zone replication allows replicating all persistent data across zones via an asynchronous replication mechanism. In this case, it guarantees eventual consistency; the database doesn’t wait for replication to be completed, so you may lose data in the event of a disruption. Failover doesn’t happen automatically; you will need to trigger failover manually following your DR procedures and after accepting the risk of data loss. Once failover is triggered, the DR failover is fully automated.
The HA and DR setup can be combined if your applications demand the highest level of BC. Besides, a near-zero downtime upgrade can be achieved. The following diagram summarizes the various options to consider:
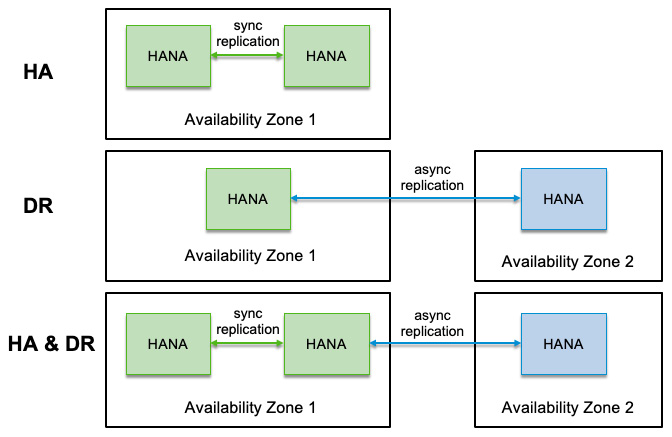
Figure 12.10: SAP HANA Cloud HA/DR options
No surprise that additional replicas incur additional costs. The cost of each replica is the same as the cost of the primary instance. So, it is your business decision to strike a balance between availability and cost, and it is recommended by SAP to plan BC for mission-critical systems.
Finally, there is an option to recreate an existing database instance in another AZ. Recreation will take longer than replication and should only be considered if no other alternative options are available. It is recommended to only take this option once you have filed a support ticket with SAP and have been advised to proceed with the recreation option.
Compatibility and migration
In early 2019, SAP made a decision to split code and prioritize a cloud-first approach and move HANA architecture towards cloud-native qualities such as elasticity and scalability. All the new features and most of the development will be available for cloud-first. To protect the existing investment of customers and safeguard the transition, SAP also keeps the on-premises code line without radical changes but still delivers improvements. Selective features developed for the cloud can potentially be introduced back to an on-premise edition as well. As a result of the code split and the decision to innovate in cloud-first, there are some features originally developed for on-premises that are not supported in HANA Cloud. The following table lists features not available in HANA Cloud. It is not an exhaustive list but provides an initial checklist if you are considering migrating to SAP HANA Cloud and want to compare it with your existing HANA systems:
|
Areas |
Features |
|
System management and operation |
Direct access to OS level SAP HANA MDC SAP host agent Various system privileges (USER ADMIN, DATA ADMIN, EXTENDED STORAGE ADMIN, and more) Various built-in procedures and functions—graph nodes; anonymization nodes; history table option; column store cache option; import/export options Ability to disable logging, LCM, Delta log Volume input/output (I/O) statistics; result caching Scale-out and SQL plan stability (planned but not available initially) |
|
Data definition |
Data-type creation Full-text indexing, geocode indexes, non-unique inverted hash indexes Time-series tables, flexible tables, history tables, temporary row tables BusinessObjects Explorer (BO Explorer) including SQL extensions |
|
Data processing |
Text analysis and text mining SAP HANA dynamic tiering (DT) SAP HANA External Machine Learning (EML) library; TensorFlow integration) SAP HANA Smart Data Quality (SDQ) Hive integration; R integration Capture and replay Live cache |
|
Application development |
SAP HANA XS Advanced (XCA) and SAP HANA XS Classic; includes native OData services and a built-in job scheduler SAP HANA Repository SAP HANA CDS Multidimensional Expressions (MDX) Attribute and analytic views |
|
Tooling |
SAP HANA Studio Enterprise Architect Designer (EAD) |
|
Security |
Client-side encryption SYSTEM user access (replaced by DBADMIN) |
Table 12.1: Feature compatibility of HANA Cloud with HANA On-Premise
Important Note
For the latest information on feature compatibility, please check the help document at https://help.sap.com/viewer/3c53bc7b58934a9795b6dd8c7e28cf05/hanacloud/en-US/11cc86c44d0b4dd3bf70e16870d9d4df.html.
SAP HANA Cloud offers many advantages in comparison with previous versions, such as HA, a built-in data lake, and more. After thorough assessments and if you are planning to migrate to HANA Cloud, here are typical steps to check:
- During the pre-migration assessment and planning phase, it is important to get familiar with the feature capabilities and the differences in SAP HANA Cloud, review your requirements and understand the incompatibilities, and decide how you want to address them. You should also review the data center regions you plan to use and make sure SAP BTP and SAP HANA Cloud are offered in the target regions. Most importantly, have a clear objective for the migration and plan the necessary resources for the migration project.
- During the preparation phase, necessary proofs-of-concept (PoCs) should be performed for validating architecture assumptions, changes, and alternatives. Development and testing environments should be provisioned, and all tools and support services should be prepared. Besides this, the target production environment should be provisioned and configured.
- During the development and validation phases, incompatible database objects and contents should be either removed or converted (for example, legacy database artifacts such as attribute views and flowgraphs should be converted to HDI contents), and dependencies identified and resolved. Multiple testing and validation efforts need to be executed, such as functional testing, load and performance testing, full regression testing, data integrity testing, and migration testing itself.
- Finally, there is the deployment or migration phase, to deploy the actual application and database content and migrate production data from the source system(s). Security, observability, and operational monitoring should be enabled at the target, migrated data, and application functionality is validated and ready for use. The migration is usually done during a maintenance window.
- If you are migrating from the SAP HANA service to SAP HANA Cloud, there is a Self-Service Migration tool provided to check compatibility and identify and migrate database objects, schemas, and data.
Please keep in mind that each database migration is unique and needs to be very well planned to minimize downtime and avoid disruptions. Depending on the complexity of your HANA landscape and your use case, the self-service tool might not be sufficient, or your migration process could be very different from what was described previously, so please consult your SAP support before planning the migration.
Pricing
SAP HANA Cloud instances are sized based on the memory size, in 16 gigabytes (GB) blocks with a minimum of two blocks (32 GB). Compute and storage are allocated automatically—one virtual CPU (vCPU) per block of memory and 120 GB for the first 32 GB of memory, plus 40 GB for each additional 16 GB of memory. Backup storage is added separately, and all provisioned storage is a fixed cost per month, while compute is not charged when an instance is not running. Network data transfer is charged for all data leaving the database, such as reading data from the database to the applications.
The pricing of SAP HANA Cloud is based on the concept of capacity units, which are calculated based on compute, storage, and network needed. Each component within SAP HANA Cloud has a different unit of measure and capacity-unit value.
To calculate the number of capacity units, you can use the SAP HANA Cloud Capacity Unit Estimator at https://hcsizingestimator.cfapps.eu10.hana.ondemand.com/.
Release strategy and data center availability
Unlike other services in SAP BTP, SAP HANA Cloud has a release strategy that includes service level and component level. The service level includes administration tools such as SAP HANA Cloud Central and SAP HANA Cockpit, which are updated frequently, all managed by SAP, and you are always working with the latest version. The component levels, such as SAP HANA Cloud, SAP HANA Database, and SAP HANA Cloud, and Data Lake, have different release strategies. As you are planning the upgrade or adopting a new feature, it is important to understand the differences, as outlined here:
- SAP HANA Cloud, SAP HANA Database follows a quarterly release cycle (QRC); for example, QRC 1/2022 means a release in the first quarter of the year 2022. A release can be used for up to 7 months and will be upgraded to the next release automatically in a maintenance window. Customers will be notified before the upgrade. You can also perform a manual upgrade if necessary.
- SAP HANA Cloud, Data Lake also follows a QRC. The latest version is immediately available for new instances; however, existing instances will not be upgraded automatically until 40 days after the release date. Otherwise, you can request a manual upgrade before that.
- SAP HANA Cloud, SAP Adaptive Server Enterprise, and SAP HANA Cloud, SAP Adaptive Server Enterprise Replication don’t have a release every quarter and don’t perform automatic upgrades at the time of writing this book.
SAP HANA Cloud is offered as part of the SAP BTP CF environment and is available in multiple regions. SAP will continue to expand the services to new regions; check https://discovery-center.cloud.sap/serviceCatalog/sap-hana-cloud for the latest information.
SAP HANA Cloud, Data Lake
SAP HANA Cloud is built as a central point to access data from multiple sources and multiple formats (for example, comma-separated values (CSV); Parquet) while providing options to keep performance and cost balanced via flexible data storage options through data virtualization.
SAP HANA Cloud, Data Lake is an optional extension to SAP HANA Cloud, HANA Database, based on SAP IQ, an efficient disk-based relational store. It is optimized for OLAP workloads and large volumes of data, supporting storage capacity from hundreds of terabytes (TB) to multiple petabytes, with the full support of SQL. The data lake storage is much cheaper and stores all data on disk. To use the data lake, tables and schemas are created in the data lake and linked to the HANA database through virtual tables through an optimized high-speed SDA capability to match data types and query data.
SAP HANA Cloud, Data Lake further allows a native integration and high-speed data ingest from cloud object stores such as AWS S3. It provides an SQL on Files capability to efficiently process data files stored in the data lake through SQL queries, without loading data into the database.
From an operational perspective, it is a natively integrated part of HANA Cloud and shares a common security mechanism, tenancy model, and tooling with HANA Cloud. However, it scales independently to accommodate data volume and workload complexity increases and separate provisioning of computing and storage. You can also create a standalone data lake in SAP BTP Cockpit directly or integrate a data lake as part of the SAP HANA Cloud data pyramid.
Technically, the Data Lake is comprised of two components: the Data Lake IQ and Data Lake Files. Data Lake IQ is managed by the HANA database and provides SQL analysis for large volumes of structured data. Data Lake Files uses data lake file containers to store unstructured, semi-structured, and structured data. A Data Lake Files container is a managed object store that integrates with cloud object stores. Here is a high-level architecture diagram that shows how Data Lake works with HANA Database:
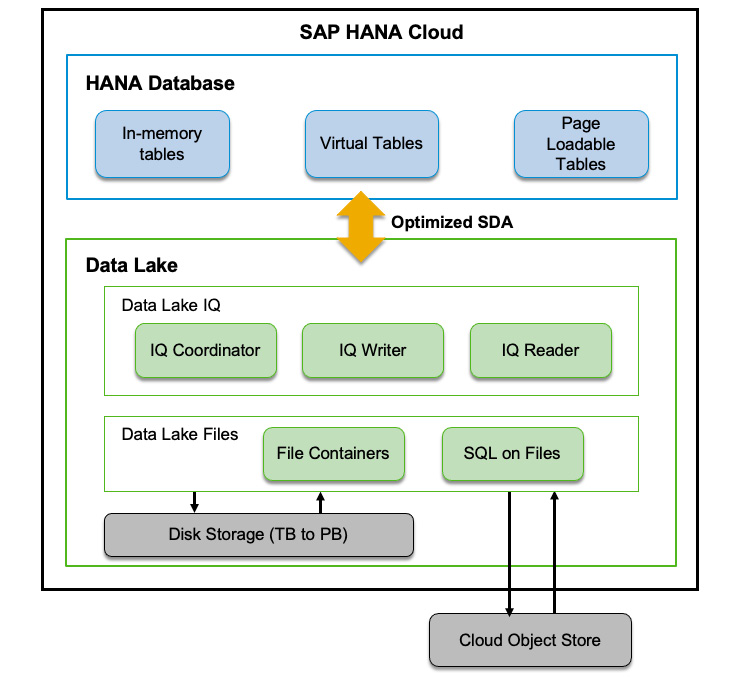
Figure 12.11: HANA Database and HANA Data Lake
SQL execution and SQL reference for Data Lake
When Data Lake is configured with maximum HANA database compatibility, all SQL statements, procedures, and views are embedded in the REMOTE_EXECUTE procedure. Here is an example of creating a Data Lake IQ view:
CALL SYSHDL_CONTAINER1.REMOTE_EXECUTE('
CREATE VIEW VIEW_T AS SELECT * FROM T
');HANA Database connects with the Data Lake IQ via container groups that isolate data and access control to each relationship container. Each relational container has a dedicated connection with HANA database. A single query can include both HANA in-memory tables and virtual tables pointing to Data Lake IQ tables in relational containers. Joins are possible between tables in relational containers or between relational containers’ tables and HANA database tables. The following diagram illustrates the execution of SQL statements involving the HANA database and Data Lake IQ tables:

Figure 12.12: SQL execution from HANA Database to Data Lake
As Data Lake IQ also provides a standalone setup with a full feature set, two SQL references are available for the different setups. The standalone setup uses SQL syntax derived from on-premises IQ; however, the HANA-managed Data Lake IQ uses HANA syntax customized for data lake IQ users. The SQL reference for HANA managed Data Lake IQ can be found at https://help.sap.com/viewer/a898e08b84f21015969fa437e89860c8/QRC_3_2021/en-US/74814c5dca454066804e5670fa2fe4f5.html.
SQL on Files is included in Data Lake IQ and enabled automatically, allowing you to query data directly without loading data into Data Lake IQ. SQL on Files is useful in a scenario where you need to access a large volume of structured data stored as files in The Data Lake. It supports running SQL analysis on top of three file types: CSV, Parquet, and Apache Optimized Row Columnar (ORC).
Summary
Well, we covered quite a lot in this chapter. As this is the first chapter of “data to value,” we started this chapter by discussing typical data-driven use cases and data architecture patterns to support various use cases.
The key element of this chapter was SAP HANA Cloud. We first introduced the different components of SAP HANA Cloud, its server types, and tools to access and work with HANA Cloud. Then, we focused on different development scenarios, from using HANA Cloud as the database runtime, modeling with Calculation Views, and—more importantly—native development, especially with the HDI. We briefly discussed SAP HANA Cloud Data Lake as a built-in extension of HANA database for large- volume data processing.
In the next chapter, we will look at other products as part of the data-to-value offerings, especially SAP Data Warehouse Cloud and SAP Analytics Cloud.