
8
Data Integration
You may remember from the previous chapters that we separated data integration from other integration use cases covered under cloud integration. Since data integration differs from the process integration style, the patterns and tools used for these two categories are distinct.
With data integration, we bring together data from different sources so that the combined data has a meaning for a specific purpose. This may be for operational requirements; however, it is mostly for analytics and reporting purposes such as producing business insights or replicating data into a data warehouse. Data integration is also naturally relevant to big data and artificial intelligence (AI)/machine learning (ML) use cases.
As you can remember, we covered master data integration in the previous chapter because its patterns and motivations are more akin to the process integration style.
We will cover the following topics in this chapter:
- Why do we need data integration?
- SAP Data Intelligence
- Other SAP solutions for data integration
Technical requirements
The simplest way to try out the examples in this chapter is to get a trial SAP Business Technology Platform (BTP) account or an account with a free tier, as described in the Technical requirements section of Chapter 3, Establishing a Foundation for SAP Business Technology Platform.
Why do we need data integration?
We have highlighted many times how today’s world necessitates enterprises to be intelligent. This intelligence can only be established on the foundation of quality data that is managed systematically. Hybrid and heterogeneous information technology (IT) landscapes expose the usual challenge here because businesses need to bring together data from disparate sources in order to produce actionable insights.
Distributed data across several systems is one side of the story. With the recent advancements in the IT world, innovative businesses have a great appetite to exploit data that is sophisticated in many dimensions. In data science, these are formulated as the 5 V’s of big data: Volume, Variety, Velocity, Veracity, and Value, as represented in the following diagram:
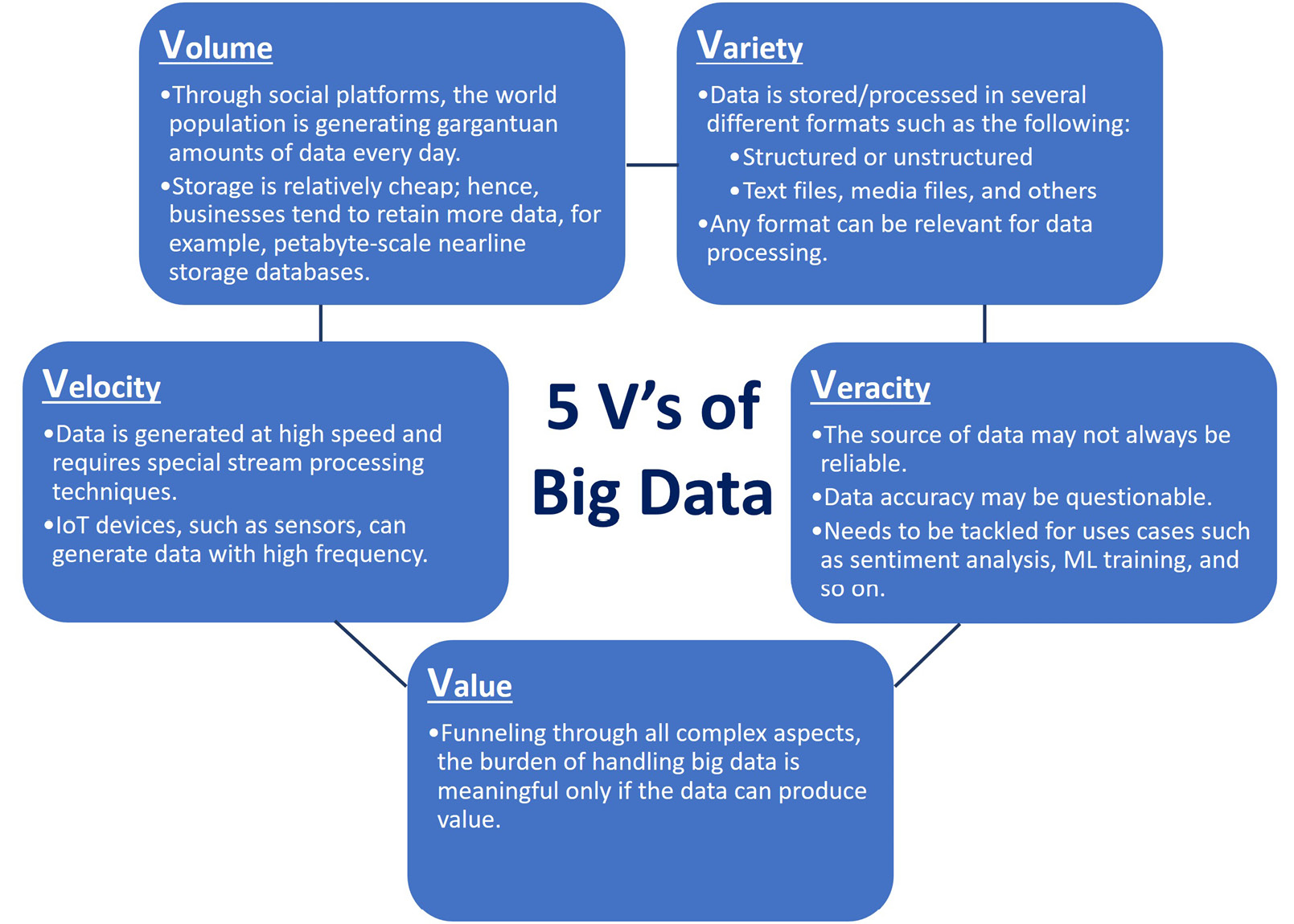
Figure 8.1: The 5 V’s of big data
Figure 8.1 illustrates the 5 V’s of big data and provides brief examples. Although these dimensions define big data, they are still relevant when projected to smaller-scale data management. Leaving the other parts to you as a thought exercise, let’s now focus on the value part and elaborate.
To harvest the fruits of your investment in establishing a data platform, you need to make sure the data can produce value. This is a prerequisite for an efficient digital transformation and an intelligent enterprise. When you remove this aspect from your motivation, you will face the trap of magpie culture, hoarding data for no beneficial purposes.
Let’s understand some examples of how data can produce value, as follows:
- Actionable insights: The world is becoming extremely dynamic, where several intertwined factors influence a consequence. Businesses need to survive in this dynamism and efficiently deal with the chaos it creates. For that, the decision-makers heavily depend on data analytics, which provides them with actionable insights, such as the lights of a glide path for planes or a harbor lighthouse for ships. The decision-makers need access to concise data distilled into insights that help them see trends and set strategies.
- Predictive analytics: Predictive analytics can take insights to the next level, providing predictions. Although a human touch is inevitable for critical decisions, having the support of analytics done with an objective science would help. Predictive algorithms, AI, ML, and automation can unlock the next stage of digital transformation: autonomous enterprises.
- Real-time stream processing: With the internet of things (IoT) and mobile technologies, smart devices and sensors create a world that is more interconnected than ever. The technology can tackle high-velocity data by stream processing techniques to extract insight from streams of events and respond immediately to changing conditions. The streaming data can be fed into real-time monitoring dashboards for critical operations. For example, with predictive maintenance, sensor data can be used together with AI/ML and predictive analytics to predict anomalies in equipment. This is a foundational element of Industry 4.0.
Today, we have the technology to tackle data-related complexities and generate tremendous value. As a result, businesses implement data-to-value scenarios as a differentiator for gaining momentum in their competition.
For example, with the advanced technology in its foundation, SAP HANA brings online transaction processing (OLTP) and online analytical processing (OLAP) together in one database platform. Besides, with Smart Data Access (SDA), SAP HANA federates data access where a query can access data in a remote database without moving the persistent data. SDA lets you define a data fabric because the data is accessed as if it is all part of the same entity.
However, the aforementioned SAP HANA features have their use in certain circumstances and do not eliminate the need for data warehouses or moving persistent data from one database to another. Therefore, data integration and orchestration solutions are still relevant in modern architecture designs.
Now, let’s return to the integration domain and see how data integration is different from process integration. At the end of the day, in both cases, data travels between systems, right?
How is data integration different from process integration?
The main point separating data integration from other integration patterns is the integration scenario being data oriented. What does this mean?
In a process integration scenario, the amount of data that flows between applications is generally small because it deals with a particular business object. In some instances, such as searching, this may include multiple objects; however, the data volume is still relatively low. Besides, the integration needs to be at the process-aware application level because it runs explicitly for a business process and probably with the involvement of a user who is expecting to see results in a relatively short period of time.
As you can gather from our earlier discussions in this chapter, data integration is more about moving data where process integration techniques would not be efficient due to factors increasing complexity. Here, remember the 5 Vs we discussed earlier in this chapter. That’s why we generally push down the operation to a lower level—that is, to the database level, where we can apply techniques that can deal with large amounts of data, tackle the processing of data generated with high frequency, or replicate data very fast. Alternatively, when the operation is at the application layer, it is specifically calibrated for the data perspective.
Data integration techniques
For data integration, mainly depending on the complexity of the landscape, you can choose different techniques, as outlined here:
- You can consolidate data from several systems into a single platform, such as bringing data into a data warehouse system.
- You can move data between systems as required, such as synchronizing data between different systems—for example, by using change data capture (CDC) at the source.
- You can establish a layer that can retrieve data from different systems, concealing the complexity and presenting this layer as a unified data layer, such as SAP Graph.
- You can federate/virtualize data access, such as using SAP HANA SDA, as discussed earlier.
You can use extract-transform-load (ETL) procedures when you need to move data between systems. Most data integration solutions on the market provide ETL capabilities that include connectivity with different types of databases to retrieve or write data and functions for data transformation. For example, SAP Data Services is an on-premise solution that provides comprehensive data integration capabilities. Another example is SAP Landscape Transformation Replication Server (SLT), which offers powerful replication technology, especially for scenarios where the source is an ABAP-based system-based system.
If the integration target is an SAP HANA database, you can also use SAP HANA Smart Data Integration (SDI). With SDI, you can create flowgraphs that contain ETL procedures for reading data from a supported source database, transforming it, and writing it to the SAP HANA database.
On the other hand, if it is about processing event data that is generated with high frequency, you can leverage complex event processing (CEP) or event stream processing (ESP) technologies. Event brokers such as SAP Event Mesh can handle event processing to a certain degree. For more complex data, you can use technologies such as SAP HANA Streaming Analytics, Apache Kafka, and Apache Flink, which are specialized products for ESP scenarios. For example, these technologies can persist event streams in contrast to an event broker, which deletes an event after it’s consumed. In addition, they can enrich, transform, filter, and combine data through the processing pipeline. Another feature these technologies can provide is event sourcing, where the system stores state change as a sequence of events by the time they happen. With event sourcing, you can reconstruct the state of an object that was valid at an arbitrary point in time.
SAP Data Intelligence is a strategic solution SAP offers; therefore, we will cover it in more detail in the next section. Afterward, we will also cover some of the technologies we mentioned previously.
SAP Data Intelligence
Here, we discuss SAP Data Intelligence under the topic of data integration; however, calling it only a data integration tool would be a significant undervaluation. SAP positions it as an all-encompassing data management platform for governance, integration, orchestration, and processing of data. Besides, SAP Data Intelligence provides features to create, deploy and leverage ML models. For the sake of completeness, we will also briefly cover other SAP Data Intelligence features besides its data integration capabilities.
The following diagram depicts an overview of SAP Data Intelligence features and connection types it supports for implementing data management, integration, and ML use cases:
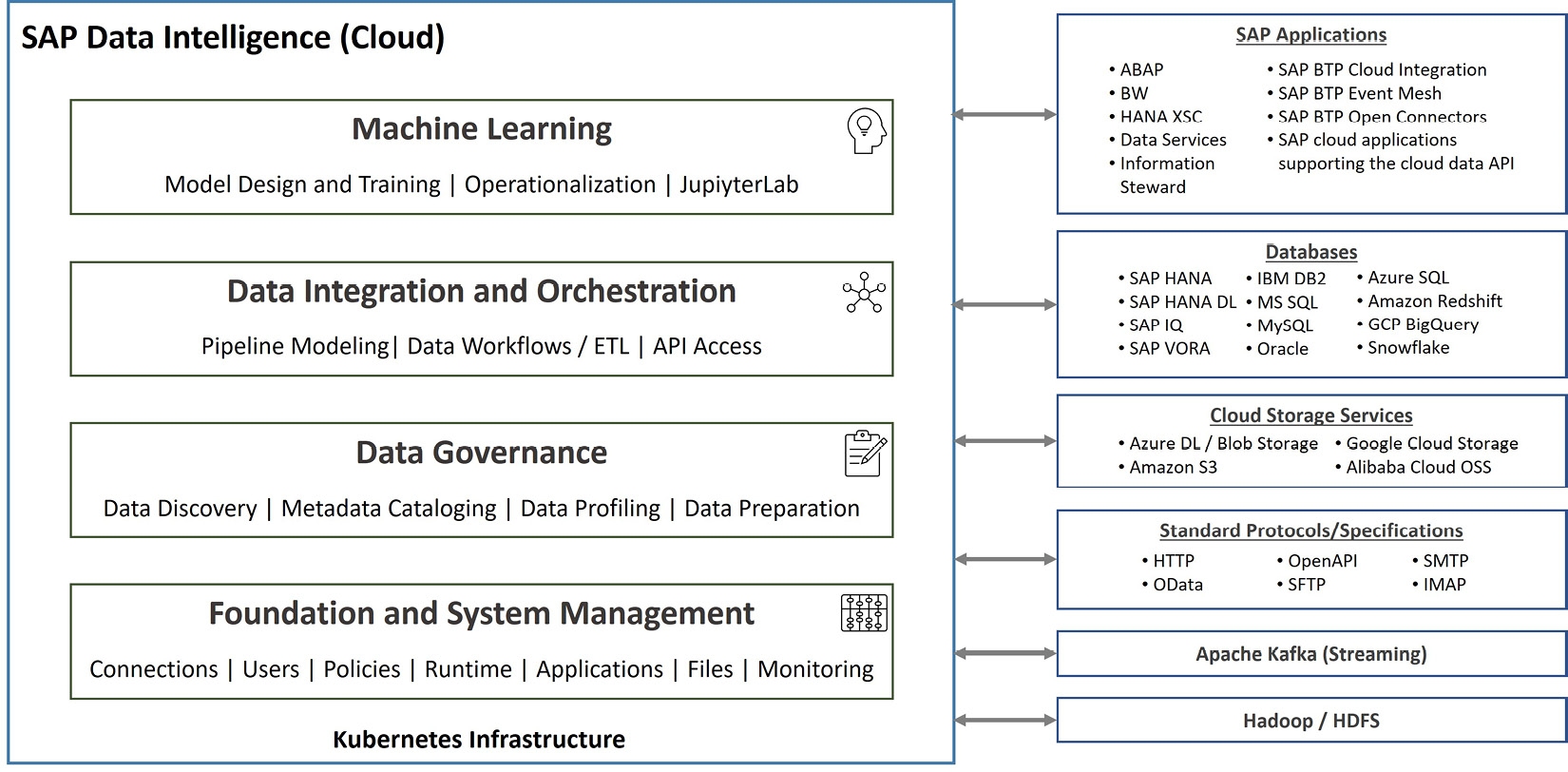
Figure 8.2: SAP Data Intelligence overview
Foundations
Before getting into the capabilities, let’s touch upon the architecture and foundation of SAP Data Intelligence. In fact, SAP Data Intelligence brings together the traditional data services SAP previously offered via SAP Data Hub and the ML features from the SAP Leonardo Machine Learning Foundation (SAP Leonardo MLF). So, in a sense, SAP Data Intelligence is the successor for these two offerings.
Important note
At the time of writing this book, SAP announced two new SAP BTP services: SAP AI Core and SAP AI Launchpad. These services offer ML capabilities similar to SAP Data Intelligence; however, they are better suited for performance-intensive AI use cases. We are yet to see how SAP will position these offerings and the criteria to distinguish between use cases that better fit SAP Data Intelligence or SAP AI Core.
SAP Data Intelligence is built on top of a Kubernetes cluster. This makes the installation highly scalable and flexible to adjust under different performance requirements. The pipelines you build are deployed, executed, and managed as containerized applications.
You can install SAP Data Intelligence on-premise on an SAP-certified environment in your data center or an infrastructure-as-a-service (IaaS) provider’s data center. On the other hand, you have the option of using SAP Data Intelligence Cloud, which is offered as a service via SAP BTP. The on-premise and cloud versions are equivalent in terms of features and capabilities, except the cloud version gets the latest features before the on-premise version.
After you have your SAP Data Intelligence environment ready, you can create users and assign policies to them. You can consider policies as roles that enable role-based access control (RBAC).
Next, you need to define connections so that you can access data. As you can see in Figure 8.2, SAP Data Intelligence supports a plethora of connection types. With a connection, you basically define technical connectivity elements and authentication details. For SAP Data Intelligence Cloud, you can connect your tenant (Kubernetes cluster) to your on-premise systems via SAP Cloud Connector. Alternatively, you can connect via a site-to-site virtual private network (VPN) or virtual network (VNet) peering, depending on where your on-premise systems are hosted and the provider (hyperscaler) of the subaccount SAP Data Intelligence is provisioned. After the connectivity requirements are fulfilled, you can start using the capabilities of SAP Data Intelligence.
Here, you can see a screenshot of SAP Data Intelligence Launchpad:
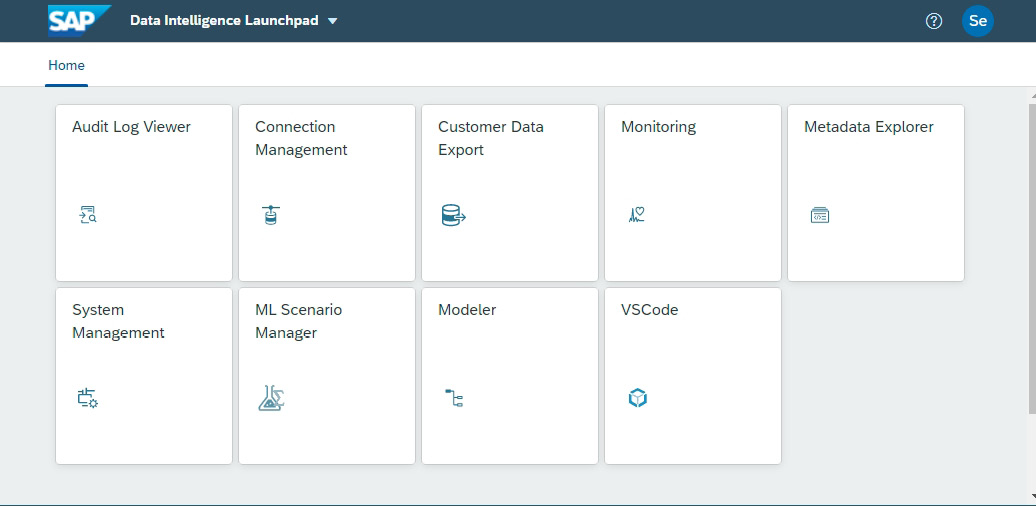
Figure 8.3: SAP Data Intelligence Launchpad
Launchpad is the single point of entry for all SAP Data Intelligence functionalities. Depending on the policies (roles) assigned to a user, the Launchpad can have a different number of tiles. Clicking on tiles navigates to applications, which we will discuss shortly. In addition, SAP Data Intelligence provides the flexibility to add other applications. For example, the VSCode application in Figure 8.3 is a custom addition to the standard set of Launchpad tiles.
Data governance
Let’s make a start by thinking of a data scientist or a data engineer persona. You would be dealing with several data files with different structures, semantics, and formats so that you can produce value from an ocean of data. Before it becomes the task of finding a needle in a haystack, you need to adopt a systematic approach to handling the data. Without such an approach, as it goes with the popular saying among data scientists, your data lake may turn into a data swamp.
You can use SAP Data Intelligence’s data governance capabilities to handle your data methodically. For example, after defining your connections, you can browse and discover data exposed from the corresponding systems. You can then produce metadata information and publish the data in the metadata catalog so that others can view or use the contents of the datasets. Next, you can profile the dataset so that more information about the dataset becomes available. After profiling, you can view the fact sheet for the dataset, which includes information such as column data types, unique keys, distinct values, percentage of null/blank values, and so on.
You can see an example of a fact sheet page here:
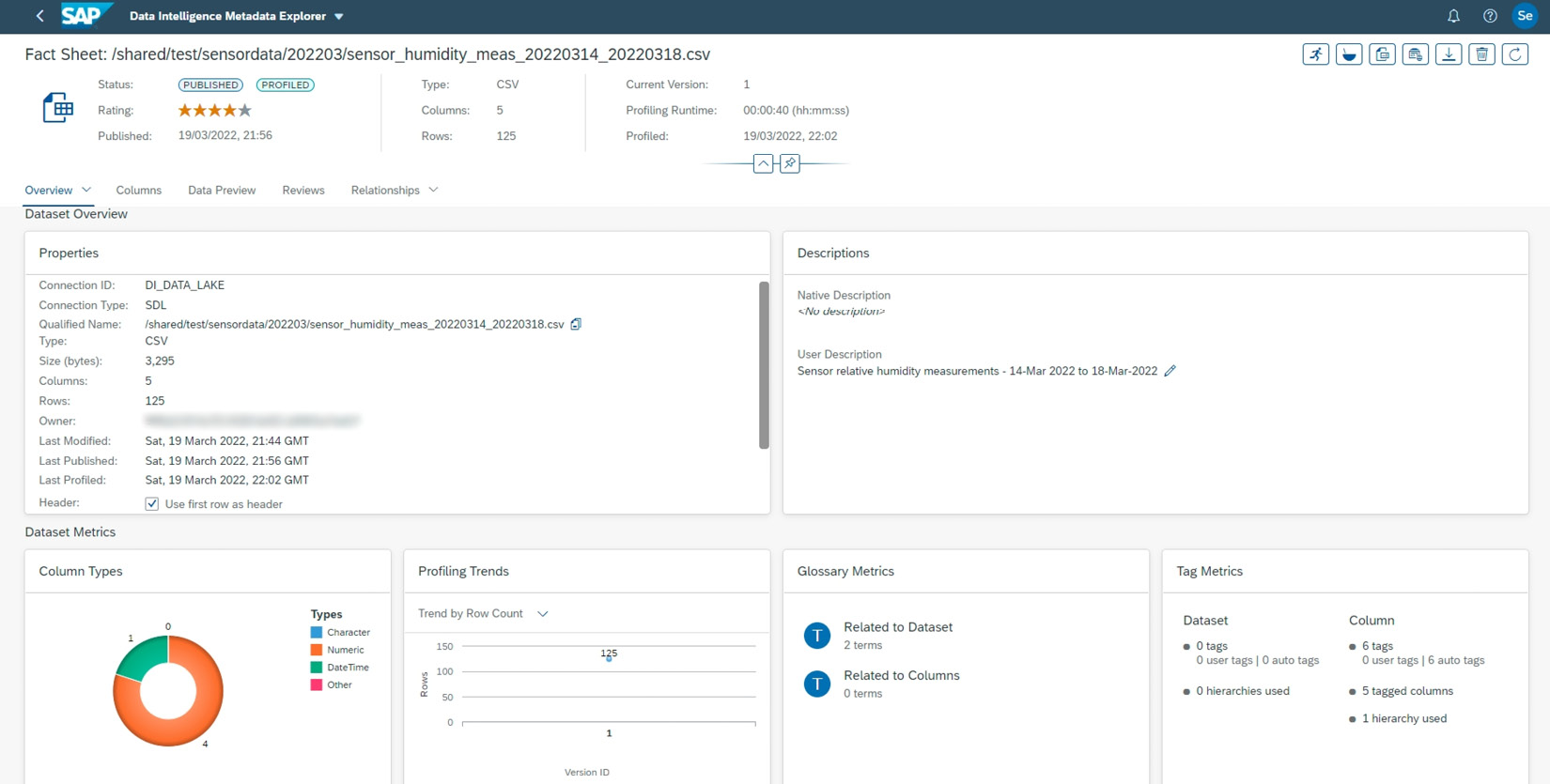
Figure 8.4: A fact sheet page for a dataset
The fact sheet page shown in Figure 8.4 is for a dataset that comes from a comma-separated text file. Here, in addition to the information directly derived from the data, you can view and manage user descriptions, tags, relationships, reviews, and comments.
You can define rules for data validation and organize them under rulebooks. Then, you can run these rules for datasets to identify problems or anomalies. By using rules, you can realize the quality of your data and take necessary actions to improve its quality. If you are already using SAP Information Steward in your estate, SAP Data Intelligence can import rules from it via a connection or exported files. Lastly, you can create rules dashboards with scorecards to track trends in data quality.
You can create glossaries to add terms with their definitions to enrich semantics. You can then establish relationships between a term and another term, a dataset, a column of a dataset, a rulebook, or a rule.
After working on datasets by applying several operations to data from different sources, it may be important to remember the origins of the transformed data. By using lineage analysis, you can see where the data is coming from and the intermediary steps that transformed the data.
Data integration and orchestration
Earlier, in the first section of this chapter, we already discussed the theoretical side of data integration and how it differs from process integration. As you may remember, data integration targets the challenges around cases where complexity increases in dimensions such as volume and frequency.
As a data platform, SAP Data Intelligence includes capabilities for processing data and moving data between several types of systems. You can create flow models for data integration and orchestration using these capabilities. In SAP Data Intelligence, these flow models are called pipelines or graphs. You will see these two terms used interchangeably. For consistency, we will use the term pipeline going forward. You can execute pipelines on an ad hoc basis or schedule them. If needed, you can schedule pipelines to run indefinitely.
Modeler
The SAP Data Intelligence Modeler application is a graphical tool for creating and managing pipelines. As you can see in the following screenshot, it provides a canvas for adding a chain of operators to build pipelines. Behind the graphics, SAP Data Intelligence creates a JavaScript Object Notation (JSON) specification for the flow:
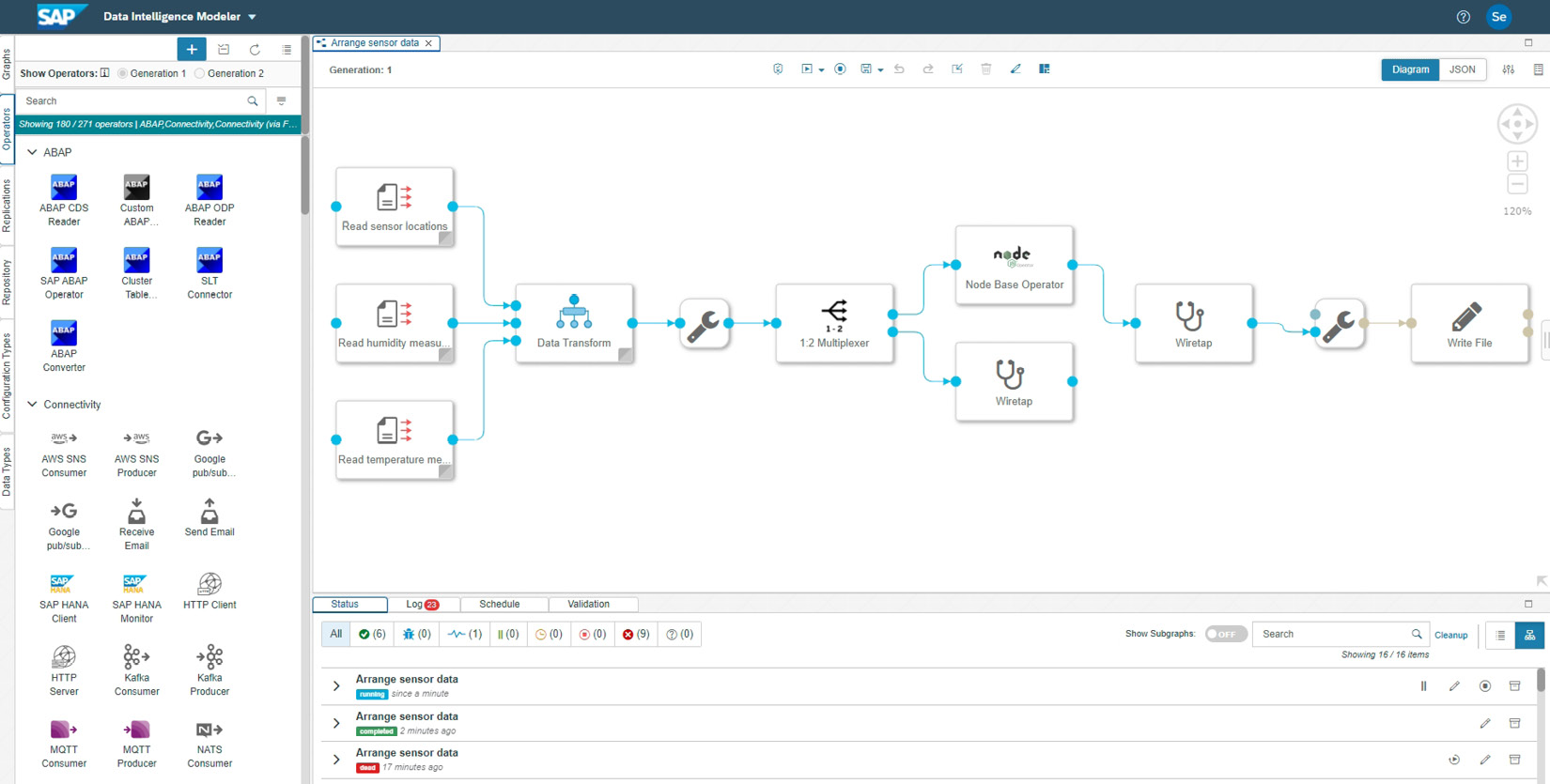
Figure 8.5: SAP Data Intelligence Modeler showing a pipeline
Using the Modeler, you can use one of the predefined graphs as a template for building your own pipeline. These can give you a head start when creating pipelines for typical scenarios. Besides, you can check them out as examples built by SAP.
Using the relevant section of the left pane, you can also access the repository to manage artifacts that are saved as files under several predefined folders. In addition, you can maintain operators, as well as configuration types and data types that are used in operators.
Finally, you can validate, run, schedule, and debug your pipelines using the Modeler. Relevant sections of the Modeler provide information on the execution of the graph, logs, failure reasons, metrics, and more.
Operators
SAP Data Intelligence provides data functions in the form of operators that execute a single specific function. Operators include input and output (I/O) ports as required through which data flows. You create a pipeline by connecting a number of operators. There are more than 250 prebuilt operators. Let’s briefly see what these operators do. But before we start, let’s remind you that there are more examples than the ones we provide here. Also, it’s always good to check the latest state of these operators as SAP adds new ones, and some may become deprecated.
Important note
At the time of authoring this book, SAP came up with a set of Generation 2 operators, which are practically new versions of operators that are not compatible with older operators and pipelines using older operators. Currently, you can use either Generation 1 or Generation 2 operators in a pipeline.
ABAP operators
It’s not surprising to see specific operators that access data in ABAP-based systems. The ABAP operators you include in a pipeline are actually just shells, and the processes of these operators are implemented in the ABAP system. Here, the ABAP system version and the Data Migration Server (DMIS) component version are important as they define the availability of operators and their versions.
For example, using Core Data Services (CDS) / Operational Data Processing (ODP) Reader operators, you can read data from CDS views and ODP objects. Alternatively, especially for ERP Central Component (ECC) systems and older Suite for HANA (S/4HANA) systems, you can establish a connection between SAP SLT (dedicated or embedded) using the SLT Connector operator and replicate tables from the source ABAP system.
The newer versions of these operators allow you to resume the execution of a pipeline in case it is stopped automatically or manually.
If needed, you can also create custom ABAP operators in your ABAP system by implementing a business add-in (BAdI). By using custom operators, you can trigger the execution of custom logic in ABAP systems.
Connectivity operators
This group of operators is for connecting to different SAP or non-SAP systems to read and write data. This includes generic protocol-level operators such as the following:
- Hypertext Transfer Protocol (HTTP) Client/Server operators
- Message Queueing Telemetry Transport (MQTT) Producer/Consumer operators
- Web Application Messaging Protocol (WAMP) Producer/Consumer operators
- Receive/Send Email operators (using Internet Message Access Protocol (IMAP) and Simple Mail Transfer Protocol (SMTP) protocols, respectively)
- OpenAPI Client operator, which can invoke REpresentational State Transfer (REST) services
- OpenAPI Servlow operator, which can serve application programming interfaces (APIs) by listening to calls made to a specific path
This group also includes product-specific operators, such as the following:
- Amazon Web Services Simple Notification Service (AWS SNS) Producer/Consumer operators
- Google Pub/Sub Producer/Consumer operators
- SAP HANA Client operator, which is a generic operator for executing Structured Query Language (SQL) statements and inserting data into an SAP HANA instance
- SAP HANA Monitor operator, which watches SAP HANA and outputs newly inserted rows
- Kafka Producer/Consumer operators
Finally, we can also consider in this group the operators that use the Flowagent subengine, such as the following:
- Table Replicator operator, which uses CDC technology and supports certain source and target connection types to replicate data between them
- Flowagent SQL Executor operator, which can execute arbitrary SQL statements in supported connection types
Data workflow and external execution operators
Especially for orchestration purposes, you can invoke execution in external systems using data workflow and external execution operators. For example, you can start the execution of the following:
- SAP Business Warehouse (BW) process chains
- SAP HANA flowgraphs
- SAP Data Services jobs
- SAP Integration Suite, Cloud Integration iFlows
- Hadoop and Spark jobs
- Other SAP Data Intelligence pipelines
The data workflow operators return the execution status information, which means you can cascade them in data orchestration workflows with status feedback.
SAP ML operators
We will briefly cover the ML capabilities of SAP Data Intelligence in the next section. To build your complete ML scenarios, you can create pipelines that include core ML operators. You can utilize these operators to train your models, submit model key performance indicators (KPIs)/metrics, deploy models, and send inference requests to your models or ML libraries in SAP HANA.
In addition to the core operators, you can use the functional services for typical ML scenarios such as image classification.
File and structured data operators
It’s typical to use files when dealing with data integration, especially for mass data processing. And as you can expect, SAP Data Intelligence provides operators to list, read, write, and delete files in supported connection types. Besides, you can use the Monitor Files operator, which polls the connected system for monitoring any file changes by comparing the list of files. The operator can highlight whether a file is added, changed, or removed.
If the data has a structure, the structured data operators can be used as they provide extra capabilities for structured data. For example, with the Data Transform operator, you can specify a set of transformation operations such as combining, aggregating, and joining datasets.
Data quality operators
As part of a data integration scenario, you may want to improve the quality of data for which you can use the data quality operators. Here are some examples of operators you can use for different scenarios:
- Anonymization and Data Masking operators for protecting the privacy of individuals and other sensitive information
- Operators accessing SAP Data Quality Management (DQM) microservices for location data for address cleansing, and reverse geo lookups
- Person and Firm Cleanse operator for identifying people and firms data for cleansing purposes
- Validation Rule operator for building basic data validation rules to apply to data for filtering
Custom processing operators
For complex data processing requirements, SAP Data Intelligence allows you to incorporate custom logic into your pipelines. For this, there are different alternatives. The easiest one is to use the processing operators that already exist in the list of prebuilt operators and provide you with a generic container to include your custom script. There are such operators for Python, R, Go, JavaScript and Node.js. You can also build scripts in Continuous Computation Language (CCL) for streaming analytics.
If you want to reuse the custom logic you build or encapsulate it in an operator structure, you can create custom operators in Modeler, as shown in the following diagram:
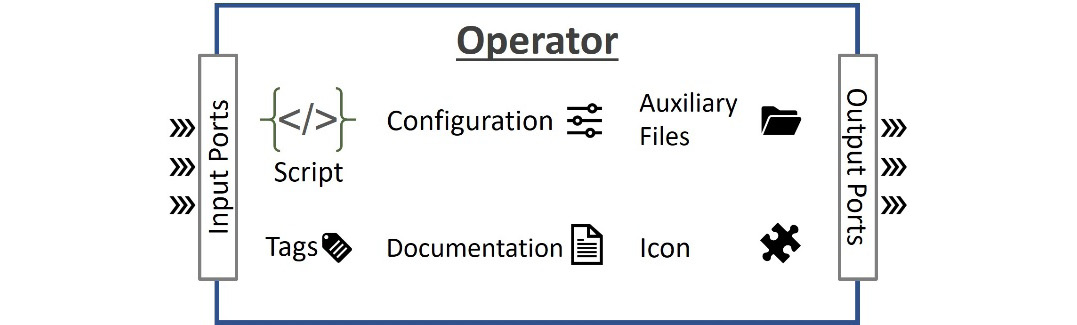
Figure 8.6 – Parts of an operator specification
As depicted in Figure 8.6, in order to create a custom operator, you need to specify the following:
- I/O ports so that the operator can interact with other operators in a pipeline. The input ports are used while listening to events that would trigger the execution of the operator. The output ports can provide input to the next operator in the pipeline. You can assign standard or custom data types to ports so that the pipeline engine can make sure the data flows consistently between operators.
- A script in one of the supported languages so that the operator runs the required logic to process data.
- Configuration parameters that can be used to configure the operator’s function in a pipeline at design time.
- Tags that point to the type of container environment in which the operator will run its processing logic. When creating a custom operator, you select a built-in base operator. This base operator also determines the subengine, the foundational runtime environment that runs the operator and corresponds to a programming language. At the time of authoring this book, SAP Data Intelligence supported ABAP, Node.js, and Python subengines. Upon this foundation, you can also specify a specific container (Docker) environment to include extra elements such as libraries and frameworks for running the operator.
- Documentation that elaborates on the operator’s function and provides specifications for its ports and configuration elements.
- Optional auxiliary files the script uses, such as binary executables.
- An icon that is displayed in the Modeler to represent the operator as a step.
Utility operators
Apart from the operators that are directly used for data processing, there are utility operators that can be used for convenience and design-time efficiency. For example, you can use the Wiretap operator by connecting it to the output of another operator whose output message you would like to inspect. Another example is the Application Logging operator, which you can use to write application messages as logs.
So far, we have covered a subset of operators, hoping they would be enough for you to grasp different types of operators and exemplify what they can do. You can get more information from the help documentation, which is also available within the Modeler. By concluding this section, we also complete the data integration section. Next, we will briefly touch upon the ML capabilities of SAP Data Intelligence.
ML
SAP positions SAP Data Intelligence as a data management platform that allows data scientists to deal with all aspects of data processing using one single platform. This naturally includes ML tasks as well. SAP Data Intelligence is part of SAP’s ML solutions, along with SAP HANA’s ML capabilities and business AI services. As you may remember, this is practically a result of SAP Data Intelligence being the successor of the SAP Leonardo MLF. For example, in your pipelines, you can use the following SAP ML functional services, which can be added as operators in pipelines:
- Image classification
- Image feature extraction
- Optical character recognition (OCR)
- Similarity score
- Text classification
- Topic detection
SAP Data Intelligence provides more ML features than just using readily available services. Looking from a data scientist’s perspective, it all starts with a dataset that is then profiled and prepared for further processing. We briefly covered the journey up to this point earlier in the Data governance section. At this point, the data scientist can begin developing an ML scenario.
You can register datasets to an ML scenario, which makes them consumable by the scenario via a unique technical identifier (ID). Then, you can create Jupyter notebooks to run experiments on the dataset, including creating visualizations. As you can see in the following screenshot, in a Jupyter notebook, you can install Python libraries and run ML algorithms. For example, you can execute SAP HANA’s Predictive Analysis Library (PAL) and Automated Predictive Library (APL) algorithms on data that resides in SAP HANA without moving it. Besides, you can leverage the SAP Python software development kit (SDK) for Data Intelligence, using which you can create and maintain SAP Data Intelligence elements, such as pipelines, configurations, and ML scenarios. Furthermore, you can use SAP Data Intelligence’s scalable Vora database or use data from other connections, such as files from an Amazon Simple Storage Service (S3) bucket or the Semantic Data Lake (SDL):
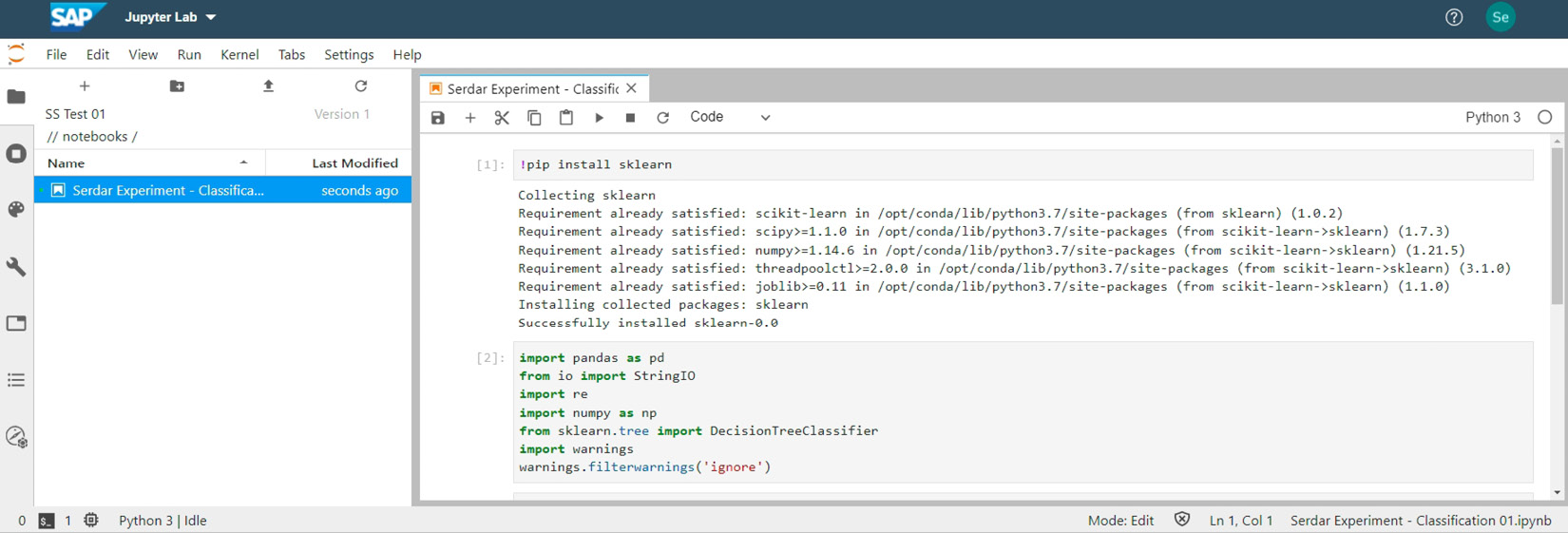
Figure 8.7: An example Jupyter notebook in SAP Data Intelligence
When you are happy with your experiment, you can progress your work to create and execute pipelines to train your system. This way, you operationalize and productize your ML scenario. The metrics, KPIs, and models are saved as part of the ML scenario. Then, you can deploy your model upon which it becomes consumable by business applications via a REST API.
We will cover more about intelligent technologies in Chapter 14, SAP Intelligent Technologies. As we have stepped out of the main focus of this chapter, we needed to be very brief on this topic. Hoping that it provides essential information, let’s get back to the topic of data integration by discussing other relevant SAP solutions.
Other SAP solutions for data integration
SAP Data Intelligence is the future for data management; however, this doesn’t mean it’s the only tool you can use for data integration. As a strategic product, its focus is primarily on innovative use cases, and the support for older version software may have limitations. Nevertheless, you have other options, especially if you want to leverage your existing investment on on-premise tools or are just not ready to transition to a new tool. Let’s briefly check out these other tools.
SAP Data Services
SAP Data Services, previously known as BusinessObjects Data Services (BODS), is a full-fledged on-premise data ETL tool. It supports powerful data transformation and quality features to move data between SAP and non-SAP systems.
If you have been an SAP customer for a while, you probably have SAP Data Services in your on-premise estate to handle data integration workloads as well as data migration requirements. Using jobs, you can build data flows that include transformation steps and move data in batch mode. In addition, SAP Data Services supports changed data capture for delta loads; however, its real-time replication capability is limited to responding to messages it receives—for example, from web applications.
As SAP Data Services has been the flagship data integration tool for on-premise, you may want to protect your investment in it. SAP acknowledges that the cloud transition is a long journey and there are valid reasons for on-premise usage. Therefore, SAP keeps supporting SAP Data Services. This includes the capability of SAP Data Intelligence to run SAP Data Services jobs in a remote system for data orchestration.
Let’s think of an example. Levi is a solution architect and is working on designing a scenario that requires data from an SAP ECC system. The design includes SAP Data Intelligence to run pipelines for data processing. While designing, he realizes there is already an SAP Data Services job that reads the necessary data from the SAP ECC system. It looks as though the same data can be reused for the scenario he is working on, so he decides to leverage this existing investment to save time and cost. The flow in his design happens as depicted in the following diagram:
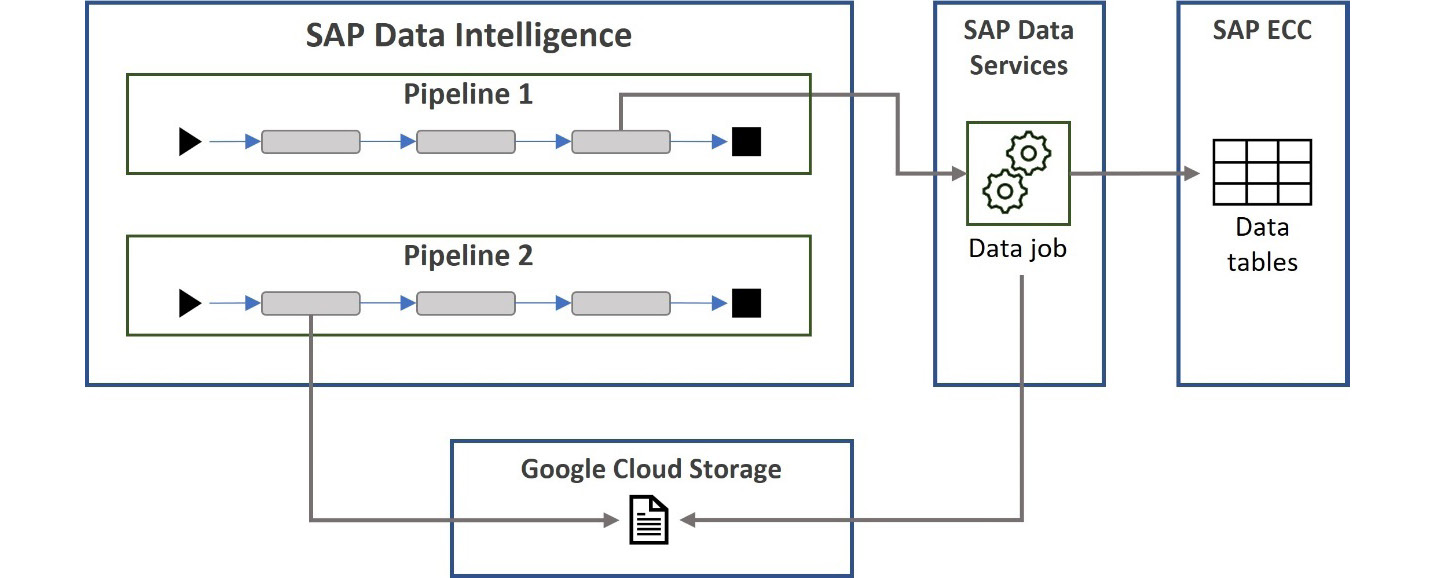
Figure 8.8: Data orchestration using SAP Data Services data jobs
Here’s what happens:
- The first SAP Data Intelligence pipeline triggers the execution of the SAP Data Services job in one of its steps.
- Next, this job reads data from the SAP ECC system, applies transformation, and writes the transformed data to a file in Google Cloud Storage.
- Finally, another SAP Data Intelligence pipeline reads this file from Google Cloud Storage and uses it, for example, to enrich the data it’s processing.
SLT
One of the crucial elements of SAP’s data management tools portfolio for on-premise is SLT. Before getting into what SLT is, we need to clarify a potential confusion point. There is another tool that is called SAP Landscape Transformation, and it is used for on-premise platform operations. What we are talking about here is the SAP Landscape Transformation Replication Server. It’s a different product, and the widely used acronym for it is SLT. It’s confusing because this acronym doesn’t refer to the Replication Server part of the product’s name.
The main use case where SLT shines is data replication from NetWeaver ABAP-based systems. SLT supports trigger-based real-time data replication, which is its most powerful feature, and can handle huge data volumes. You may remember how our example design for the digital integration hub pattern used SLT from the previous chapter.
As source systems, SLT supports all databases NetWeaver supports; hence, it supports non-SAP solutions based on these databases, too. In the source systems, changes are tracked by database triggers and are recorded in logging tables. SLT then reads the data from the application tables. Similarly, several SAP and non-SAP systems are supported as data replication targets. SLT writes changes to these systems using ABAP write modules, APIs, or database connections. Here, you have the flexibility to incorporate custom logic in read and write modules besides standard SLT capabilities such as filtering. After configuring SLT between source and target systems, you can initiate the initial load and then let SLT handle continuous delta replication.
SLT can be installed as a separate standalone system or used within the source or target systems (embedded or via the DMIS add-on) if they are ABAP-based systems. As the available features differ between S/4HANA and other systems and also between versions, you should check what is available for your system versions.
Although SAP Data Intelligence can access data in NetWeaver ABAP-based systems, its main focus is reading the data using CDS views, which is applicable for newer ABAP versions. For older systems, it can use SLT for table-based replication as well as the ODP interfaces.
Let’s conclude our discussion on SLT with a basic example. Isidora is a solution architect tasked with producing a design for moving large volumes of data from three systems to a centralized data platform solution. These include an SAP S/4HANA version 2021 system, an SAP ECC 6.0 system, and an SAP BW on HANA system.
Her company uses SLT for replicating data from SAP systems to SAP HANA Cloud. Isidora finds out SAP Data Intelligence can access data in the SAP S/4HANA system using CDS views; however, she needs to include an SLT system in the design for the SAP ECC system.
The following diagram depicts the components included in Isidora’s design:
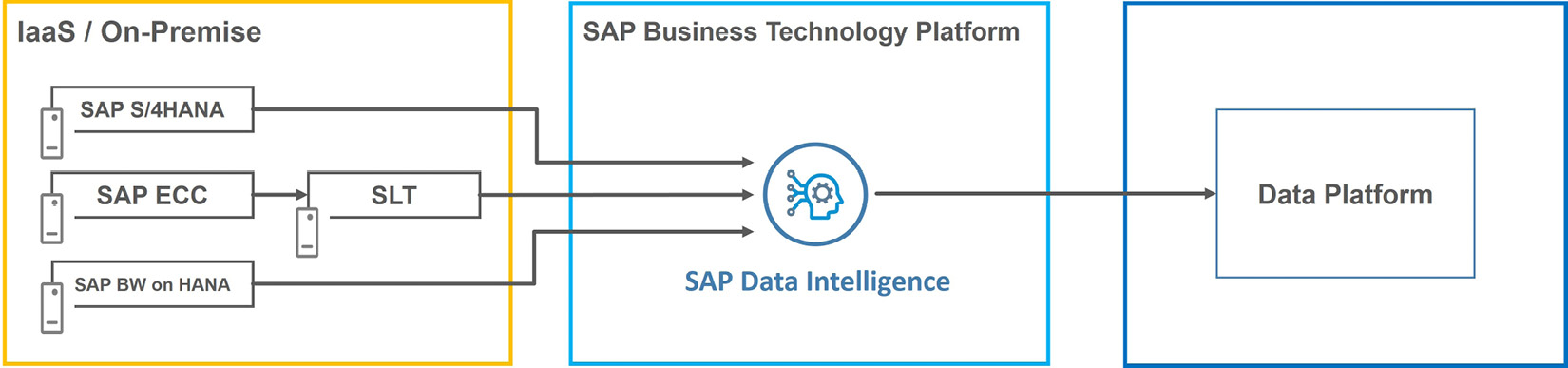
Figure 8.9: Using SAP Data Intelligence to read data from ABAP-based systems
As you can see in Figure 8.9, she positions SLT in between the SAP ECC system and SAP Data Intelligence. In this case, it’s a standalone SLT system, as there is already one being used for other replication work, and provides flexibility for workload management.
SDI
Smart Data Integration (SDI) is part of SAP HANA and provides ETL capabilities to load data into SAP HANA in batch and real time. It’s coupled with SAP HANA Smart Data Quality (SDQ) for data-quality relevant features.
You may have already realized that SDI is built to load data only into SAP HANA as the target system. This can be an on-premise SAP HANA system or an SAP HANA Cloud instance. In order for SDI to work, you need to install the Data Provisioning Agent in the source system, which communicates with the Data Provisioning Server in SAP HANA for replicating data from the source system. For implementing the replication process, which can also include transformation steps, you need to develop flowgraphs or replication tasks, ideally using SAP Business Application Studio (BAS). SDI also provides REST APIs that you can use to execute and monitor flowgraphs. For example, SAP Data Intelligence uses these APIs to trigger flowgraphs. Using SDI, you can replicate data and data structures with an optional initial load. In addition, SDI provides partitioning if the data volume is very large.
The Data Provisioning Agent contains prebuilt adapters to communicate with the Data Provisioning Server from several types of source systems. Besides, you can create your own custom adapters if needed.
SDI is generally confused with SAP HANA SDA, another SAP HANA feature that allows the accessing of data in remote systems as if it is local to SAP HANA. Here, the idea is to access remote data via virtual objects without moving it, also referred to as data virtualization. SDI, on the other hand, is meant for moving data. We will also talk about SDI and SDA in the last part of this book.
For real-time data replication use cases where the target system is SAP HANA and the source system is—for example—an ABAP-based system, it seems we have two powerful options: SLT and SDI. Both have their advantages over the other. For example, you may already have SLT in your estate as it has been around for a while, which means you may want to protect your investment. SLT has better control and flexibility for ABAP-based source systems and supports several target systems. In addition, SLT is proven to handle huge volumes of data. On the other hand, SDI is native to SAP HANA, which means it runs within SAP HANA. The SDI development lifecycle can be aligned better with other SAP HANA artifacts, and if your team has SAP HANA skills, it may be easier to implement SDI, especially for leaner use cases. If SAP HANA Cloud is the target system, using SDI may mean that you do not need significant extra infrastructure resources. However, using SDI will put the load on SAP HANA, which may or may not be preferred.
As you can see, there is no clear-cut winner; hence, SAP keeps supporting both options. SDI may be a better choice if the main complexity of your use case is on the SAP HANA side or if you do not want to deal with an additional on-premise component. On the other hand, SLT may be the better alternative if you already use it, if the main complexity is at the source side (especially if it is an ABAP-based system), or if the data volume is really large. As usual, you need to assess these options, considering the specific requirements of your use case for a final decision.
Other data integration solutions
So far, we have covered the flagship products from SAP’s data integration solutions portfolio. However, some other offerings can be viable options in limited use cases.
SAP Replication Server (SRS) is another data replication tool SAP supports mainly to protect its customers’ investments in solutions that got into the SAP products catalog with the Sybase acquisition. Although it can replicate data between different types of databases, it’s mainly geared toward scenarios having SAP Adaptive Server Enterprise (ASE) or other Sybase products at the center.
SAP Cloud Integration for Data Services (CI-DS) is also a data integration tool with a specific scope. CI-DS is mainly used for bidirectional data transfer between SAP Integrated Business Planning (IBP) and on-premise SAP systems, such as SAP ECC, SAP S/4HANA, and SAP Advanced Planner and Optimizer (APO). It provides out-of-the-box content for such integration scenarios and relies on an on-premise agent for connectivity.
Summary
This chapter focused on data integration, and we devoted most of it to SAP Data Intelligence since it is one of SAP’s strategic tools for data management.
To set the stage, we discussed what data integration is and how it differs from process integration. While covering SAP Data Intelligence, we have been a bit cheeky and also briefly touched upon its capabilities not directly related to data integration. We believe this makes sense to provide a complete picture of SAP Data Intelligence capabilities.
Although it’s strategic, SAP Data Intelligence may still need other components that complement its function, especially in hybrid landscapes and for protecting existing investments. Being one of the fastest-evolving SAP solutions, it may eventually become a one-stop shop for many data management requirements, from data governance to ML scenarios. However, there are other alternative solutions for data integration for now, and we concluded this chapter by briefly discussing them.
This chapter concludes the integration part, and with the next chapter, we will start discussing the extensibility capabilities of SAP BTP. First in line is the chapter for application development, where we will cover building applications using SAP BTP and the peripheral services that help application development.