
Customer relationship management, or CRM for short, is one of the more tangible results of drinking from the firehose of customer data. In return for capturing customer data at the point of sales or service, you can now tell how often people purchase something, whether they buy more frequently on special days, and how often they call for service. It has revolutionized the strategic use of customer data.
After integrating social media into the customer care process (Chapter 4), it seems only a small step to integrate this social media data into a CRM tool and use it to conduct market research and customer analytics. While Chapter 4 was more about operational discussions, we will look now at the data. Besides directly answering a customer question, is there anything else that can be done with this data? The answer is yes. In the future we will be able to combine several data sources from customer service data over product discussion to product usage data. That kind of customer-centric data base has the potential to be leveraged for market research purposes.
One key advantage of this type of integration is that the issue of whether we are “listening to the right people” (see Mind the Trolls) is no longer a factor, since you have all those social media comments enriched with your CRM data of your paying customers.[92] Another advantage is that the data is accessible in one way: this is a kind of master data management (MDM) system, only with one important differentiation. The social CRM system of the future will contain all different types of data: structured, unstructured, transactional, and nontransactional. Using this database, you can easily judge whether a comment is from an important client (someone who buys a lot) or not, and how important the comment is overall. Another advantage is the capability of using social data to cast a wider net versus the “walled garden” of traditional market research activities, such as consumer panels and focus groups.
Finally, this type of integration is part of a larger trend where we are increasingly listening to customers, rather than interrupting them and asking them for data. This chapter explores the difficulties of connecting the dots within the CRM data. The new generation of marketing research and product management is not yet around the corner—not because of technology but mainly because of organizational barriers.
We discussed several times that social media commentary has the disadvantage of being unfocused. Your client might mention a brand without taking a position about it. A tweet like, “My son just spilled Pepsi over my new sofa. Does anyone know a good cleaner?” has no relation to your brand if you are Pepsi. So let’s first look at focused data: customer satisfaction surveys. Many companies use these: they ask their customers many questions, aggregate the answers in metrics, and display them on dashboards. And what happens then? Unfortunately, not a lot. While “customer first” is a slogan used often, it is seldom put into action. Most of the time, one of three issues keeps companies from really acting on customer surveys:
Silos are disconnected.
Time relationship is too short.
Averages disguise the issues.
Peter Crayfourd is the former head of customer lifecycle strategy for a global telecommunications firm with revenues in excess of 45 billion euros per year as of 2010. Peter and his team established a complete overview of all aspects of a customer lifecycle. Their focus is to capture the mood of their customers. “The way of thinking about a customer is what prohibits change,” Peter said. “Often, companies see customer relations in the same way they are structured: in silos.”
No matter which metrics one organization uses, NPS,[93] C-SAT scores,[94] or any other way, “They often do not measure the customer journey in its entity.”
Let’s look at a telecommunications firm. Why are customers unhappy? Maybe they were unhappy with the service quality of the network. They might be by chance then asked about another product of the company’s or how happy they are with the store service. Most likely, their experience with the network will determine their reaction. “Companies tend to measure those interactions separately, but they are linked together,” Peter explained. It is important to connect all parts of the customer experience over time. “What is the likelyhood that a customer will leave us when we dropped their calls several times?”
Telecom companies have the answer to questions like these in the network. They can correlate network service quality with the overall customer journey and the voice of the customer. Mapping different interactions with an overall happiness score will circumnavigate the issues of silos. But the more products there are, and the more possible interactions there are, the more data is needed to create a regression model. Those models are not new for most online retailers. Many of them use the structured data of clicks and products bought to predict the customer lifetime value. The big retailers with many users, and thus with a lot of data, can predict the lifetime value after only the first three clicks on a site with a likelihood of 90% or more.
These types of models are also possible with unstructured data from customer service centers. Jörg Niessing is an associate partner at Prophet, a strategic brand and marketing consultancy. He and his team built a predictive model for a bank in the US. “We could show that the likelihood for a customer to cancel the bank account and to go to a competitor is much higher when someone had to call the customer hotline more then once over the weekend,” he said.
But what to do with this information? Of course this is a predictive model, where you need volumes of data to build it. But does the prediction have value? Only if you can react before something goes bad. That, however, is not always so easy. “If a user can not do some specific task and he is unhappy because of this, we can not change the banking application on the fly,” said Jörg.
However, that information can be used to improve internal processes. At Verizon’s call center, for example, a customer care agent will see a first guess by the computer about why that client is calling in, particularly if there have been network-related issues. This way the agent can already prepare a proper and customer-centric response and this way lower any retention failure.
Peter and his team want to go a step further: “Do not even wait till the customer calls in,” he said. “Interact with him proactively until he is satisfied.” Here is where Peter’s “happiness” score shows its strength. Organizational focus can be achieved more easily if it is not only about retention or customer lifetime value but also about how the customer feels about the company. A telecom company might have difficulties improving the network quality around a single person that very moment. However, it can react proactively and start to talk to the client once a call gets dropped. For example, each company that knows which customers are unhappy might offer a special treat. “Companies should not wait until a customer complains,” Peter said. “We have all the data to react proactively.”
The second issue is that companies often tend to forget the time component. “They treat customers as a financial relationship over time,” he said. “At the end of the contract, we are the customer’s best friend as we want him to renew, but we might have forgotten to keep him happy during the time of his contract.” He is right; ideally we would have a model to measure the overall satisfaction of a client throughout his journey with the company. But if there are too many factors impacting the relationship, it will be hard, if not impossible, to include the time dimension.
The last of the issues that stops companies from using surveys effectively is the matter of averages. Data is often not put into models that try to predict behavior or customer happiness. Instead, it is stored in dashboards showing average metrics for a given timeframe, which disguises correlations. What does an average service quality of 85% mean for you as a person? You might be the one for whom the network just dropped the call a couple of times (see Figure 5-1). Yes, you were unlucky, but you as a client will not care because you are unhappy. “If you manage your business by averages, you run an average business,” explained Peter.
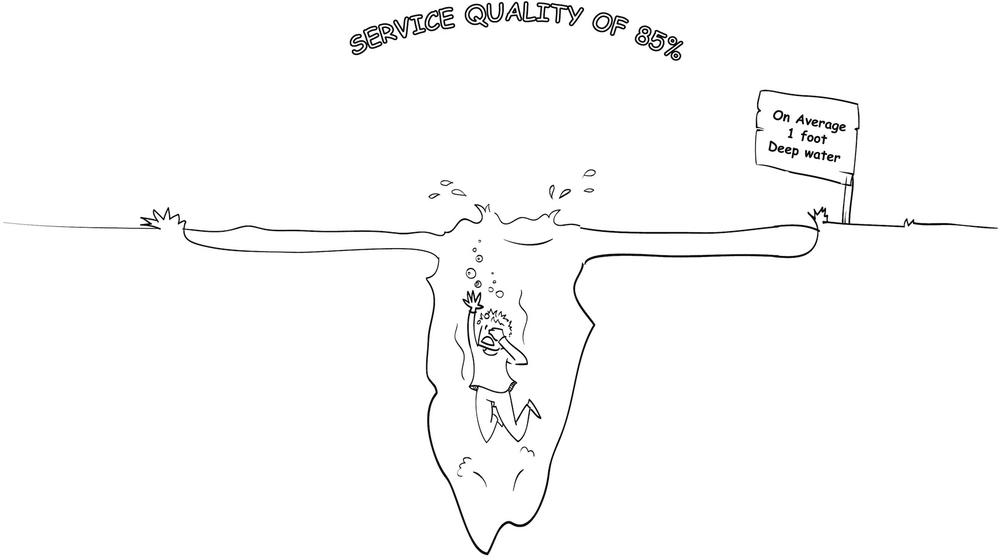
How would you show that bad network quality creates unhappy customers? You would need to break the average down to each customer. Here, averages are not helpful. All in all, you need a predictive model that mixes the perception data of the customer survey (the overall happiness or customer satisfaction) with the hard facts of the network quality for this very customer.
From banking to telecommunications, we see that more and more processes rely on predictive analytics in order to anticipate customer behavior and to react faster, better, or more efficiently. Underlying those models are machine-learning approaches that analyze data to see patterns, as described in Chapter 2. Let’s analyze what this will mean for the area of market research.
People like Peter and Jörg are on the leading edge of a new discipline: using CRM data to conduct market research. Or, perhaps more accurately, they are part of a natural evolution in how we leverage our customers as a source of data and strategic insight. Market research expert Robert Moran describes this evolution in terms of three “epochs”:[95]
- Data Collection Epoch (or Asking Epoch)
Marked by interviews and surveys
- Listening Epoch
Defined by observational analytics, ranging from social media data to exotic things such as tracking eye movements
- Simulation Epoch
Shifts the focus to anticipatory research driven by market research game simulations, Delphi panels, and strategic foresight
In Moran’s view, we are now exiting the Data Collection Epoch and moving toward both the Listening Epoch and the Simulation Epoch. Big data is a necessary component of the Listening Epoch and potentially a driver for the Simulation Epoch, as well. Put simply, we are entering an era where customers now leave a substantive footprint of data in the course of their normal activities, and this data is a force to be used and managed.
Similar trends have been validated by the larger market research community. A 2011 UK survey of senior market research professionals showed that more than half are at least experimenting with techniques like market research online communities (MROCs) and web scraping. The former are curated groups, and the latter extracts data from social media sources such as blogs, Facebook, and Twitter. Close to half are also practicing or exploring co-creation (online collaborative concept or design work) and digital ethnography (in-depth qualitative studies of individuals or families using online data).[96]
All of these trends point to the fact that social media and big data are growing as tools for both marketing research and customer connectivity.
Asking customers questions to get insights has always been a time-consuming and expensive approach. It might take a month until a survey is returned—valuable time. Social media has the potential to approximate surveys inexpensively, even with a very simple approach. Welcome to the new fronter of analytical CRM.
Traditional market research would yield common segmentation criteria for consumers. You would use factors such as gender, income, age, or nationality to describe taste and purchase behavior. Then businesses started to realize that more segments seemed to be needed, as the traditional ones did not really help with all the correct classification. So it was no surprise that more and more segments were soon invented: the adventurer, blue collar, emerging adults, health and fitness, Hispanics, women with children, and so on.
But where does all this segmentation lead? Today an individual person is not best classified by personal demographics such as gender, race, income, or skin color. Today we are looking more into people’s actions. After a few decades, the song from Lee Michaels, “You are what you do,” seems to have become something of a reality. Increasingly, we analyze a person based on purchasing, reading, or other activities. In the future, marketing may increasingly revolve around the long tail of specific individuals.
As an example, Annet Aris, a strategy professor at INSEAD, frequently asks her students to identify two candidates: Segmentation Candidate 1 and Candidate 2. Both are male, born in 1948, British, in second marriages, affluent, and from well-known families. In most cases, the first guess is clear: “Prince of Wales Charles of Windsor.” But do you know is the second one? It is the “Prince of Darkness” rock musician Ozzy Osbourne. To put both men into the same segment and assume similar shopping or customer behaviors is clearly not applicable.
Thus, the question might be asked, “Is this the end for traditional CRM?” Many sources, like Johanna Blakley’s talk on TED.com, say it is “the end of gender,” pointing to the fact that each person might develop individual interests that cannot be classified by the the main demographical segments. This does not, however, mean that each of us is now a complete “individual.” Humans tend to organize their behavior, as well their shopping habits, in groups. Some of those groups will be characterized best by demographics. Take women’s underwear as an example. Other products might not have a very clear-cut user group, and the marketing of those products will greatly benefit by changing the way we measure demographics.
The daily routine for many marketeers looks different, however; their industry is slow to change, and gender and age are still big parts of the discussion. As Blakley notes:
Media and advertising companies still use the same old demographics to understand audiences, but they’re becoming increasingly harder to track online, as social media outgrows traditional media, and women users outnumber men.[97]
It will still take a while until we move from the data collection epoch to the simulation epoch. The word “simulation” means that we test out hypotheses using data. For example, we run on subsections of our customers A/B tests. The more tests we run, the more hypotheses we can test. Google has mastered this. It has become known for testing the different colors of blue underlying a link.
Market research can use social media for testing. The data provided by social media can help in selecting user groups to be tested. It can help formulate new hypotheses and much more. However, it will take time before this simulation epoch becomes reality. Or as the political and economic consultant Nicolas Checa asked, “It took the research industry almost a decade to come to terms with Web-based surveys, so how difficult will it be with social media?” Therefore, one of the key challenges of social CRM remains not only technology but the inertia of the marketing industry itself.
Analytical CRM is about trying not to think in terms of boxes or classification. Take for example the predictive models formed by Peter and Jörg in the beginning of this chapter—those models do not care about the gender of customers. An algorithm tries to determine the data that has the most impact on predicting the loyalty. Thus, as strange as it sounds, analytical CRM does not start with the customer. It starts with what Peter calls the “touchpoints,” meaning the interactions with the customer. This could be the network quality for a telecom operator, the products sold for an online retailer, or the time someone calls into the service center for a bank. Who the customer is, what he thinks, and what he does is irrelevant at first. The idea of the analytical CRM is to judge customers by what they do and not by their demographic segment.
This can be supported by Netflix, which would not conclude that a 30-year-old male with a high income would probably like the genre of “action movies.” What it cares about is what that user does, and if he is watching kids movies all day long, it might be that this is his taste, or it might be that his kids are watching. Whatever it is, Netflix would use this as the basis to suggest new movies. “He is paying us for this kind of movie, thus he has a definite interest,” said Xavier Amatriain.
Facebook is different from Apple or Google or Amazon or Microsoft, because it doesn’t build products. It seeks to improve the products built by everyone else.
The idea of an analytical CRM is to not only use traditional information on your client, like where he lives or how old he is, but to take all of the possible information you own to create a complete picture of him. What is he doing if he goes online, what does he buy, and when does he buy it?
There is one company that is trying to do exactly the same thing: Facebook. It wants to be a platform and wants to integrate all this data into a massive CRM store. It calls it Open Graph. Open Graph is the further development of social graph. The social graph showed the network of your users, while Open Graph shows much more. It shows not only the network, but all of the other pieces of information belonging to each user.
Facebook’s Open Graph capability links users’ activities to their social network. You see it whenever, for example, digital music service Spotify posts what song you are listening to on the news feed of each of your friends—or when an application asks you to log in via Facebook, and then posts on your behalf. It is powerful, and at times controversial: for example, users do not always want to have their entire network see what movie they are watching through Netflix, or have an application suggest things to their friends on their behalf. However, this capability is a metaphor for how people are becoming increasingly linked through social media—and how the trail of socially-linked data they leave behind can become strategic intelligence.
The trick, however, is that Facebook does not even own all this data. Many companies would most likely not give all of the consumer data to Facebook. This would be neither legal nor strategically beneficial. But Facebook attempts to organize data from others because Mark Zuckerberg has the fundamental belief that “a social version of anything can almost always be more engaging and outperform a non-social version.”
Let’s take the example of a bookseller. If it wants to serve ads to Facebook users, it could simply select a random sample of users and receive a certain response rate. Or it could select Facebook users who have “liked” particular books or publishers, in which case the response rate would likely be greater. The bookseller is leveraging the simplest part of Open Graph, filtering structured data to select a more targeted audience. In an interview with Wired Magazine, Mike Vernal, head of Facebook’s Open Graph development team, explained that the book recommendation site Goodreads.com has seen an 800 percent increase in impressions from Facebook since going live with Open Graph in early 2012.
According to Mike, the social experiences of Facebook revolve around the ability to quickly analyze how people interact with content and its relative importance. In the interview, he noted, “If you prefer music, we show you more music. If you prefer games, we show you more games. Then we merge those two sets of scores together, to influence what Newsfeed shows and what Timeline shows and what some other systems show.”[98]
As always in this book, the question is not about technology or data; the question is how to use this data successfully. The main question Facebook has in mind is how to use its data to effectively place advertisements and enable social commerce, the so called “F-commerce.”
But not all believe that Facebook has been successful in this approach. This is mainly because, as noted in previous chapters, behavioral clues we collect from searches are more powerful then public statements we make by “liking” something. To get back to the book example, I might say I like a book of Nietzsche’s, but in reality read more easy-to-swallow comics on love, crime, and rock’n roll. Facebook has realized this and started to collect, via applications of its partners, useful user data such as whether someone actually reads Nietzsche or whether he spends more time on comics.
Nevertheless, Facebook’s Open Graph approach has the beauty of combining both what people do and what they say to give a much more detailed picture about each personality. Perhaps the social aspect is often not the main enhancement, as unstructured data is still too difficult to read. Facebook thus tries to get developers to put a structure on the content to make it easier and less complex to read.
In 2001, World Wide Web founder Tim Berners-Lee put forth the term “semantic web” to describe where he felt unstructured data was going: semantic information bound together by metadata and relationships and not just structured data. For example, you could search for a picture or video on the Web based on its metadata or find a range of prices corresponding to a class of data. Facebook’s Open Graph approaches this ideal by providing third-party applications with a way to structure their data, which in turn enables Facebook to access and reuse this data. According to Vernal, Facebook bases its capabilities around an “object store” (containing object data and metadata) as well as an “edge store” (containing relationships between objects).
Let’s go back to the approach of linking the voice of the customer with the internal data about the service. Which data should be included in the discussion? Many companies sit on an abundance of data, more then they know. A telecom operator, for example, could save each connection, each bandwidth allocation, and each status of each base station. A retailer would not only know which clients have bought something, but also which ads they saw or which clicks they made before they came into the store. On top of that, we could save all social media communication. Does this make sense? Shall we really save everything? Aside from privacy concerns, the answer is yes. Saving data is meaningless until we have the right question so that we can create value out of the data. Often in the beginning, we do not have the right question in mind. Since storage has become cheap, we still should capture all this information for a later stage once we have the right question formulated.
Often, companies are faced with enough complexity to store and enable their internal, mainly structured data. Social media, however, is unstructured data, and in Chapter 9, we explain why it is more difficult to gain insights from such data. Shall we—on top of all internal data—save unstructured socia media data in order to correlate this with our CRM data? Depending on who you ask, you might get two quite contradictory messages: “too shallow,” will one camp say; “too sensitive,” say the others. Let’s look at both arguments.
Is social media too shallow to use it for customer insights? An online retailer or a telecom company has a massive amount of data about user behavior. This kind of data is mainly structured. We will discuss the difference between structured and unstructured data more in Chapter 9, the summary in short is, that structured data is easier data mined. It is more suited for computer and thus is more likely to yield better insights. The unstructured data such as social media commentary contains a lot of noise not only for us humans but even more so for computer and machine learning algorithm. It is thus much harder to identify any trends or structure in this kind of data.
But this is not the only reason why social media data is ill-suited at first sight. It is culturally biased: it is more likely to be generated by people in the Millennial generation rather than older Baby Boomers. Thus, the results from them might be highly skewed, and statistical relevancy might always be an issue. And indeed one can not find a lot of academic studies that have explored the impact of social media on market research, according to literature survey by marketing professor Anthony Patino.[100]
But there are situations where you want to have social media data. When? The answer is simple: when there is no better data around. Take the recent surge of patient communities like PatienceLikeMe, cofounded by Jamie Heywood; or Ubiqi, founded by Jacqueline Thong. Members of those sites discuss their symptoms, share how a medication has worked, and register when they are “happy” or “in pain.” This is unstructured data at its best. Moreover it is skewed: highly skewed, even, as mainly younger, tech-savvy people will use those methods. But all this data is unique. It offers valuable insights because all of those members discussing their treatment are becoming a part of a virtual study. Using their members’ data, PatienceLikeMe has published more then 35 research studies. The data is not “too noisy” or “too shallow.” Over time, we will see many more examples like this. Social-sourced data is by no means “too shallow.”
Many CRM systems already have the ability to attach social media information. But this feature is seldom used in an analytical setup. Even when social media can deliver insights, the transition of market research from “asking” to “listening” will still require time and infrastructure. According to the Confirmit 2011 Annual MR Software Survey discussed previously, a plurality of companies (42%) feel that it is hard to gather insights from unstructured text, and less than a third feel the process is easy. Perceptions such as these remain one of the challenges in effectively transitioning to social CRM from traditionally structured customer data.[101]
The second argument was “social media data is too sensitive.” This is surely a contradiction to the idea that it is “too shallow.” If it were too shallow, how could it be too sensitive? Well, whenever it is actually used to gain insights. Insights from social media data often enter into areas that are personal, like health or financial well-being. Human communication is personal; so are the insights. Take for example the German credit-rating company Schufa. It started a project to analyze whether data from Twitter, Facebook, and Xing (the German LinkedIn) could help to predict credit ratings. Together with the Hasso-Plattner-Institut from the University of Potsdam (HPI), they founded the Schufa-Lab@HPI. The idea behind this project was to scan social networks for information that could possibly lead to conclusions about a person’s financial capacity. Without waiting for the research to be done, we knew that there would be a correlation. Think about the success Garmeen Bank had with microfinancing. Some of its success can be attributed to a good understanding of the real-world social networks of the lender. Schufa planned to bring the same process into financing.
Suddenly what we wrote and said in this semi-private space of social media had the potential to impact our credit score. The reactions to this from the public and politicians were fierce, voicing concerns about privacy. Some government officials even intervened, and the project ultimately was stopped as a result of the intense opposition. Schufa was not the first case of its kind and it will not be the last.
Wary of those issues, some even preemptively ban themselves from entering into any research. We once showed French government officials how to analyze the public discussion. They were excited about the richness of the analytics. We could show them insights about the public opinion they had not seen before. Despite this initial excitement, they decided to not go on with any measurement. “If the general public starts to realize that we ‘spy’ on our citizens, we might have a crisis that we cannot cope with,” said the leading secretary.
Really? Is this spying? Well, it depends on what you do with the data. If you use it for the better of the planet or—less ambitious—for the better of your customers, you are welcomed as “visionary”; if you use it to do evil or with the clear intention to spy, you will meet some resistance.
Since we do not know how companies and governments around the world plan to use our data, we fear the unknown. Thus the best advice would be transparency as we show throughout this book, this fourth “V” as we coined it in the beginning is not easy to be found. Thus often it is not clear what you want to do with the data. However, it is clear that there is value in data itself. But since it is hidden and not yet clear, many of us fear the unknown.
In short, many data sources are very sensitive, including social media data: maybe not every single tweet or Facebook update, but the collection of data BCG’s John Rose pointed out in a conversation with Martin Gilles on data privacy issues. The future focus should not be so much about how we safeguard data but more on transparency in how data is used.[102] But here we are in a catch-22. Neither governments nor companies often know what they want to do with all the data they are collecting. As we’ve pointed out several times throughout this book, the fourth “V” (value) is hard to find. Thus we keep on looking for it and at this very moment, many companies and governments cannot be transparent about the use, because they simply do not yet know. Often, companies start off with a kind of “senseless” data-collection approach. While collecting data, they are doing tests to see how best to use the data. For example, let’s go back to SCHUFA, the German credit ranking company. It didn’t know whether Facebook posts or Facebook friends had a correlation with your credit score, however, before it can find out, it will start to collect data. This worried German citizens immediately.
After a short but very emotional public debate, SCHUFA had to stop; however, like always in research, it is hard to stop an idea. Other smaller companies picked it up. The British short-term loan firm Wonga is one such smaller company. They offer money at very high interest rates for very short periods of time, with instant online approval. As part of their application process, they publicly state on their web page that connecting with them on Facebook will allow them to get to know you better and will improve the chances of being approved for a loan:
Connecting with Facebook helps us to get to know you better. This will improve your chances of being approved for a loan.
Social media information is as sensitive as healthcare information, and therefore many consumers are concerned. Any company using social media information to predict or to model user behavior would be well advised to be as transparent as possible to users.
The aim of market research is to understand why customers behave the way they do. Traditionally, to find this out, you had to get them out of their natural surroundings and into a rather artificial interview situation, where they could be questioned about things they tend to do instinctively.
Data mining and technology have turned this approach around. First, we can often automatically capture data about customer behavior. Second, we can ask consumers in any given situation how they feel about our product. By doing so, we might give up representative user groups but gain real-life usage moments. In this chapter, we showed how telephone companies and banks are already trying to gather this 360-degree view on the customer.
Those models are about to turn the process of market research around. For one thing, there is a clear turn away from a top-down approach by marketeers. No longer is it a small group of marketers thinking about the relevant features of the market (“young, white fathers with an income over…”). The market itself designs the set of behavioral criteria that describes the subgroup best. Thus whether you are the right fit for action movies, tropical vacations, or any other product or service will in the future be defined by your behavior more than by some arbitrary identifiable personal characteristics. For another thing, companies are turning away from collecting only internal data about customers. Instead, consumers are supplying more data themselves. This might be social media data such as Facebook’s Open Graph, but it might also be self-registered data or other monitored user behavior.
Our aim is to create self-learning models that automatically adapt our offerings toward what makes our customers happiest. For example, we want to know which combination of marketing mail, price points, and service quality will generate the best cost-benefit for an online retailer. In a way, the analytical CRM is closing the loop between product marketing (Chapter 1) and sales (Chapter 3).
However, in order to derive such a “happiness” score, we should not only mine data and technology. To be successful, we need to understand what makes any given person happy. That’s a personal insight, for sure. So we are faced with more and more concerns about privacy. A key success factor in this kind of data mining is not only asking the right question and using the right data or metric, but also how we deal with our customers’ concerns about privacy.
Analytical CRM is the future and will try to encompass all areas of the customer’s lifecycle. Such an analytical approach will then need excellent technology. It will demand an organization that analyzes the customer journey as a whole, and it will raise questions about customer privacy. Please discuss the following questions with your peers:
How are we measuring the voice of the customer? Is the complete customer lifecycle analyzed? Which parts are missing?
Do we know which variables will have the highest impact on an NPS score? In the example Crayfourd gave, it was mobile phone coverage and network service quaity. What is it for your company?
How do you work with customer data? Who owns the data, you or your customer? Who knows what happens with the data?
The last point in particular will become more and more important in the future. Companies will need to find a way to create trust and to get the permission to use the data without a predefined goal or action. Only this way can the full benefit of data be available. What are the best ways to create this trust? Transparency at the time one finds out how to use the data? Open data initiatives? Public data exchange controlled by the users? While many companies collect data about its clients, only a few are transparent about what they do with the data. Privacy and open data will become more important over time, and will be the key to gaining trust from your customers. Please share your views either on Twitter, @askmeasurelearn, or on our LinkedIn or Facebook pages.
[92] Assuming that your clients have told you the social media accounts they use.
[93] NPS: Net Promoter Score. First developed by Bain & Company to explain how likely a customer is to “recommend” the brand further.
[94] C-SAT score stands for “customer satisfaction score.”
[95] Robert Moran, “Measuring the Future of Market Research,” Future of Insights, June 2010, http://bit.ly/1hRfNvm.
[96] Tim Macer, et al., “The Confirmit Annual Market Research Software Survey 2011,” meaning ltd., 2012, http://bit.ly/ITVRJ4.
[97] Johanna Blakley, “ Social media and the end of gender,” TEDWomen, December 2010, http://bit.ly/1kGnjq4.
[98] Cade Metz, “How Facebook Knows What You Really Like,” Wired Magazine, May 2012, http://wrd.cm/1h6X7Fe.
[99] Hank Nothhaft, “Let’s Get Personalized: Moving Beyond Recommendations,” Techcrunch, Jan., 2012. http://tcrn.ch/1hRkfdH.
[100] Anthony Patino et al., “Social media’s emerging importance in market research,” Journal of Consumer Marketing, Vol. 29, Issue 3, pp.233−237, 2012.
[101] Tim Macer, et al., “The Confirmit Annual Market Research Software Survey 2011,” meaning ltd., 2012, http://bit.ly/ITVRJ4.
[102] John Rose and Martin Gilles at the Economist’s Information Forum, in San Francisco, discussing the tension between the benefits of data analytics and the need for privacy.