
The sales process has always been driven by knowledge and trust: knowledge from the sales person about what the customer really wants, knowledge from the customer about the existence of the product, and trust from the customer in the salesperson or company. Data analytics and social media play distinct roles in archiving knowledge and trust. However, social media and the data taken out of social media are often confused as one and the same. They are not.
On one hand, we can use social media to create knowledge about a product and trust into this product. On the other hand, data derived from social interactions or the shopping experience as such can be used to create knowledge about the customer and thus serve the customer better. In both cases, the social sales approach as well as the analytics of social data are aiming to support our sales efforts. But the actual work and skill sets are quite different. In this chapter we will look at both areas. In the first part, we will discuss social networks and how they can be used. In the second part of this chapter, we will look at data analytics derived either from social data or from customer purchase behavior.[46]
A social layer within an online sales process adds not only the possibility to create reach, as discussed in Chapter 1, but also knowledge and trust. Consider the following case:
While shopping Walmart online, you find a product you like. You can discuss whether you should buy it, ask friends about its quality, or just comment on how it looks via Facebook, Twitter, or Pinterest directly. By providing the opportunity to discuss this product, Walmart can not only offer a way for its customers to gain trust in the product, but it helps as well to create reach and spread the word.
This is an example of social commerce. The term social commerce was first coined by Yahoo! in 2005. It describes ecommerce transactions that are triggered or guided by social interactions or supported by social network data. Social commerce usually consists of one or more of the following elements:
User-generated recommendations such as ratings and reviews
The ability to spread information about a product to a social network
Recommendations based on consumers’ online behavior
Because the social media world is full of different tools, platforms, and functions, the social commerce world also has many names and faces: “T-commerce” stands for commerce via Twitter and “F-commerce” for sales via Facebook. We are sure there are many more terms to come. Social commerce seems to have become the “next big thing,” and the numbers appear to justify this hype. There are over a billion users on Facebook, and more than 170 million active Twitter accounts. Let’s assume we could sell each of them something for only $2—that would result in a revenue of $2.3 billion.
Social commerce is sometimes presented in terms that practically guarantee raining money, if you only implement “F-”, “T-”, or whatever-commerce. The reality, of course, is often different from this, and many merchants have lost money from “being social.” Should we thus refrain from social commerce?
Let’s be guided by lessons from history. For example, in the mid-1990s, people promoted the practice of having a page on the World Wide Web as a sure-fire way to sell products and services. A few years later, the crash of many dot-com startups taught us that the medium itself wasn’t the ticket to sales success. Today, social commerce has had the same glow of youth and promise for boosting sales, ever since the term was first coined. In all likelihood, history will prove these tools to have a similar trajectory to the growth of the Web.
Of course, websites and ecommerce not only work as selling tools but have also created a billion-dollar industry. They are now ubiquitous for anyone in business today, much like having a telephone. However, their adoption took longer than anticipated, and online capabilities are only an additional tool for the sales process. In much the same way, social commerce will develop. It is here to stay and will become a significant part of the online commerce world, but the adoption will take longer than expected. Social commerce is not the one-and-only savior; it is one additional tool to facilitate the sales process.
Using social commerce, we will also find an answer to the often-discussed question of ROI from social media. Sales are the ultimate link to ROI for efforts in social media. As discussed in Chapter 10, often it is hard to link effects from social media, such as an improved audience reach to an ROI. The “R,” or the financial return, is often too undefined, or a causation is too hard to prove (see Chapter 9). This is different with social commerce. One can create a direct link between the investment into a social sales channel and the return in terms of additional margin dollars earned.[47]
Related to social commerce is the usage of data within the sales approach. But while the data might be taken from social interactions, this data is by no means the only source available to support sales activities. The second part of this chapter will touch on a few standard topics about the way data can be used to improve the sales experience. The underlying aim here is the same. Like with social commerce, we are using data to create one of the two major drivers in a sales process: knowledge and trust. Let’s look at the following cases:
You are about to choose a movie to download on Netflix, and the site recommends one that has already been seen by three of your friends. Netflix uses your social graph to motivate you to see this movie as well. You know your friends and you trust their taste, and this might motivate you to watch the movie.
You search for a book on Amazon. In addition to showing you the book itself, Amazon lists its ratings from other customers, and suggests books other people have purchased. Some of these look interesting, and you add one or two of them to your order. Amazon is using the purchasing behavior of you and others to gain knowledge about you.
Those two cases are using the data available about you. In both cases, an algorithm combines data taken from your user behavior—meaning what you have bought and done before on the site—with information about your friends (in the Netflix example) or with information about what the general public (in the Amazon example) would do. The data is used to create knowledge about you. We commonly refer to this process as recommendation engine. The second part of this chapter will explain what recommendation engines are and the main challenges in setting them up.
Social commerce can be seen as having two distinct levels: creating brand awareness (reach) and stimulating a purchasing intent with subsequent sales. It is important to understand that they are not the same.
Reach describes how many people notice your product offering. Many of the social features of ecommerce sites offer a way to create reach (e.g., one can like a product so your friends see that you liked it). But commerce as such is only then generated if there is a purchase intent. Therefore, social commerce will be successful only if both components (reach and intent) are linked together.
There are many ways to create reach via social media to spread the news about your product and to find customers (buyers) online. For example:
People can create their own “like lists” and offer them publicly. These can also be personalized and sent to specific friends.
People can easily share ideas and fashions with others, both on general social networks like Facebook and specialized sites like Pinterest.
People can be encouraged to share their interests through incentives ranging from attention to overt rewards. For example, eyeglass manufacturer Warby Parker ships prospective customers five pairs of frames and encourages them to post videos on YouTube of themselves modeling the glasses for friends to vote on. Still other companies reward sharing, like address book manager evercontact.com, which gives a free month of service to customers who tweet about the company.
People can have songs they are listening to or news stories they are reading automatically posted to social networks such as Facebook.
All of these could build reach and, potentially, awareness. Also, each of them is easily done. This kind of ease of use is a necessary feature of socially created reach. To support the product and to spread knowledge of it should be as simple for consumers as a click. This is the geniality of the one-click “like” button from Facebook. You can find many similar examples, all of which pretty much make possible the spread of information by piggybacking on the social network connections of the customer.
But as we have noted previously, reach or awareness is not purchasing intent. Creating intention is much harder than creating reach. For example Compass.co,[48] a young startup founded by Bjoern Lasse Herrmann, found out that social media as a primary acquisition channel is two times more effective than traditional methods if the company offers “free” products (monetized indirectly). To get a “free” product onto the market, no high intent is needed. Thus reach or awareness are sufficient and can be created by social media. The picture is different if you look at paid products. Here, Compass.co found out that most companies naturally tend to focus on traditional methods such as direct sales and partnerships, as they are better in creating a purchasing intent in comparison to a pure social media outreach.
And how do you create intent? Any human salesperson will know that trust and knowledge are essential in creating purchase intent. For example, the sales rep at a brick-and-mortar fashion store might offer a customer a jacket based on her age and what she is wearing at that moment. The salesman’s knowledge guides him, as he knows that this specific type of jacket sells best with people like her. He then will build trust through small talk. At the end, he will compliment the customer with, “This jacket looks fantastic on you” to entice her to buy it. Likewise, an insurance salesperson will often create a relationship of trust, which she then will leverage to explore the needs of a client and his family, and then fulfill those needs through her knowledge of insurance.
Trust and knowledge are not only needed in the offline world but also in the virtual world. In the following sections, we will see two ways in which social media can be used to create purchasing intent: via social confirmation and peer pressure. Later, we will see how the knowledge gained from a social group can be used to create recommendations and therefore purchasing intent.
Social confirmation involves people online saying that a given product is good. It creates the trust that was missing so far in online interactions beyond big brand names. Examples of this include two forms of displaying actual purchasing intent.
User reviews can create a significant competitive advantage.[49] These display intent by enabling users or customers to give a numerical or “star” rating, often anonymously. Physician evaluation website HealthGrades.com, for example, enables patients to provide anonymous ratings from zero to five stars, without fear of reprisal from their doctors seeing the ratings. Similarly, RateMyProfessors.com enables students to provide ratings for their teachers on criteria such as easiness, helpfulness, and clarity, as well as a separate binary “hotness” rating if they are physically attractive. In both cases, rating results are displayed publicly.
It is important to note that social confirmation alone is not always a measure of quality. For example, a highly competent but gruff doctor may get poor ratings online, and the same could be true with a brilliant professor who is a tough grader. Ratings that reflect the feelings of someone who posts online are often no substitute for objective data such as medical or academic outcomes. However, trust is important, and personal opinions online often contribute to the process of building this trust.
Just as we normally select only restaurants where there are people happily eating at this very moment, we tend to buy things when there are positive user comments. Many of us will no longer book a hotel room or go to a restaurant without first visiting a site such as TripAdvisor.com, an independent source that enables people to post comments about their traveling experiences. The power of such user comments sites can be gauged by the fact that hotel booking sites like Hotels.com, which has its own rating and commenting systems, now also link to TripAdvisor’s comments.
Please note that social confirmation can be utilized in any tool. It could be Facebook, Twitter, or anywhere else. In order to decide which kind of social media to use, you should ask yourself two questions:
Which tool can create the best reach into my customer base?
Where will I be able to own the user comments so that I can use them for other purposes the way I want to?
A step up from social confirmation involves someone from a customer’s own personal network confirming his purchasing intent for products and services. This is the ultimate social confirmation, because it is not just anyone recommending a product, but a friend whom the customer knows. Many sites facilitate this process by displaying pictures of people from an individual’s network who bought something—or, more recently, as in the case of Facebook’s Open Graph Search functionality, by creating the ability to mine data through one’s social connections (for example, a list of books that are liked by journalists).
This aspect of social media is especially helpful if a service or product depends on network externalities. Take the adoption of a messenger service like Whatsapp or Skype. Both services would benefit highly from a tool that tells the user which of her friends are on it. Another example is the decision to purchase a ticket for a concert. If a person already knows that some of his friends are going, he will make sure that he is there as well, so as not to miss out.
This process leverages the network of an individual, and thus people with a bigger network can be used for more social confirmation than others. Are those people influencers? As we discussed in Chapter 1, the concept of an “influencer” is often overrated. The person with the biggest network might be used the most to create a social confirmation. But the network size does not say anything of its ability to create an intention. Intention might be created at a local level by only a few very specific personal contacts. A well-designed social commerce setup will need to learn this kind of network information that goes way beyond any network size description.
Most of us marketeers wish that social commerce would enable us to click a few buttons and suddenly we’ve created purchasing intent with our potential customers. We get this asked all the time: “What do I need to post so that my products sell more?” or “Which tool should I use so that my sales double?” Reality does not work this way, of course. Whether or not social commerce works depends on the customers and the product. We see, however, that some social commerce tools work better then others in most cases.
It also seems that average shoppers prefer structured data, such as ratings and reviews, as social confirmation. There is a demonstrable impact: one study by eccomplished found that the number of people using online ratings and reviews is about eight times higher than the number of people using only social media recommendations (see Figure 2-1). For us, this shows that the ordered format of an aggregated sum of online reviews is more successful in persuading someone to buy something than the relatively unstructured format of different blogs, tweets, and the like.
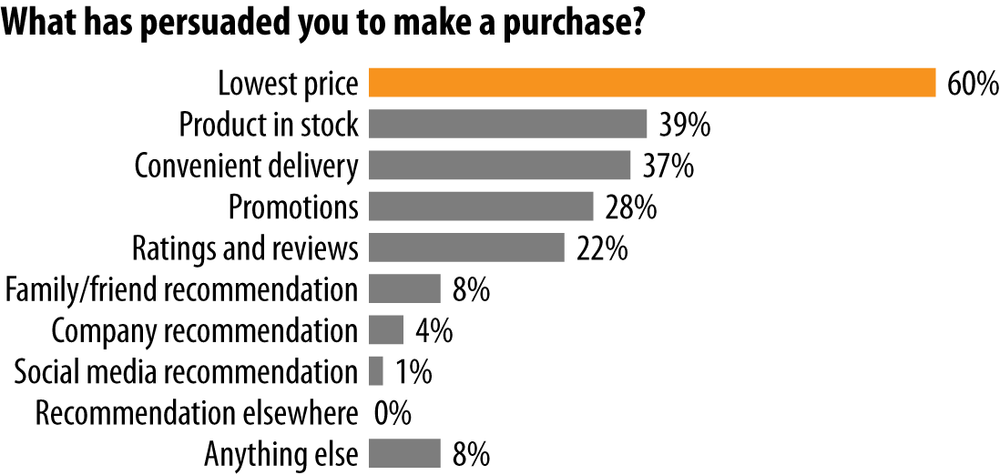
Unfortunately up to 38% of those reviews are actually fake or paid.[50] Those fraudulent reviews are an issue for all social networks. As soon as consumers realize they were tricked, they’ll lose trust and the power of social endorsement and social confirmation will vanish. That is the reason why more companies offer what was specifically recommended by your connections. Those kinds of recommendations are so far not that common since there are often not enough reviews within one person’s network to provide an effective customer experience. This will change as social networks become a bigger part of our daily shopping experience. Friends’ recommendations will become some of the most effective ways to create intention. They can be easily transported into the world of social commerce even without the knowledge of social media tools or social graphs. For example, Leskovec and his colleagues described the success of a sales attempt in which the first person to purchase an item recommended through an emailed referral link got a 10% discount, and the recommender received a 10% credit.[51]
Data such as these indicate that social confirmation and peer pressure do, in fact, influence our purchasing intent. This view is further validated by the large sums of money many large firms spend on mining and delivering such social confirmation. Though we feel that we are independent, and indeed we do not like being told what to do, the opinions of others often influence our own decision-making process.
Reviews and recommendations can influence consumer decisions about what to buy and whether or not to buy something. But how can one manage these in order to have the most positive impact on purchasing intent? For instance:
If there are many reviews, which one should we feature first?
If there are many friends who liked a product, how should we rank them?
If consumers’ friends or people similar to them bought something, should we or should we not recommend this to them?
Those questions can be answered using recommendation engines or systems, the point where big data analytics and social media intersect. Recommendation systems select the product, review, or even site layout that is best for the consumer’s given aim. Compared with pure review sites such as TripAdvisor.com, which does not rank comments from visitors, a recommendation system openly facilitates a purchasing decision by suggesting things a consumer is most likely, based on data, to want.
Even if, on the surface, there are no social features—and thus no comments, no ratings, and no Facebook friends—recommendation engines use a collaborative approach to recommend products that others “like you” have bought. Thus it is a social group feature, as the engine has put similar consumers into a group and then suggested something for them to buy. The work of those engines often occurs within milliseconds, in a way that is invisible to the normal user.
Recommendation systems are perhaps the most critical link between social data and purchasing intent. The next sections explore the function, technology, and development of these systems.
Go to Amazon and look up one of your favorite books. It will show you information about the book, of course. But one of the most prominent things that will catch your eye on the same page is a section entitled “Customers Who Bought This Item Also Bought” with a list of other books.
Or go to Netflix, which recommends movies based on factors ranging from your social circle to box-office performance. You may not realize it, but these recommendations have as much to do with algorithms such as regression analysis and singular value decomposition as they do with what people rented last week.
These are examples of recommendations systems, and their purpose is to foster incremental purchasing intent. They have become extremely common, and these days, they are ubiquitous among ecommerce systems. They are also big for business. For example, roughly 60% of rentals from Netflix are based on personal recommendations, and their Netflix Prize competition awarded $1 million in 2008 to the first team to develop an algorithm that could improve the accuracy of its predicted movie ratings by 10%. For companies the size of Netflix, which generated a revenue of $3.2 billion in fiscal year 2011, better recommendations can have a tangible financial impact.
While recommendation systems are not always obvious to the end user, they are everywhere, and not only restricted to social commerce. For example, Google ranks search results for you personally, your favorite newspaper selects news articles on its web page to fit your taste, Last.fm suggests music to you based on your previous musical choices, and a social network like LinkedIn suggests people you might know and thus should connect to.
Recommendation systems try to take as much information as they can about consumers and calculate on the fly what to recommend. Recommendation engines are the best example of how to get value—our fourth “V”—from the data. Often to get this value, companies try to gather as much information as possible. For example, Google measures up to 25 signals about each consumer, and based on those signals, it will offer search results. These signals include:
Whether the user is on a mobile device, a PC, or a Mac
Location data, such as whether the user is signed in from the US, Europe, or India
The user’s search patterns, including whether or not the user has signed into Google and opted in to sharing data
Depending on these signals, different search users may see Mac applications versus PC ones, German versus English commentary, or articles about baseball batters versus cricket batters. More importantly, the context of previous unrelated searches may influence the results; one person may get travel articles about a country, while another may get political or economic articles.
Recommendation systems creating knowledge about a user and his purchasing behavior, together with user reviews and ratings creating trust and reach, form the backbone of what we call social commerce. Their underlying strategy is to make the customer feel special. They use a system that adapts the website to each consumer personally and decides what is best suited for the consumer in hopes of increasing his purchasing intent.
All of those systems used to create recommendations based on data. This data could be based either on consumers’ past behavior, or it could be based on the content of the product itself. Thus, recommendation systems can be split into two areas: collaborative systems that leverage one’s social data, or the collaborative wisdom of the crowd and content-based systems that rely exclusively on content.
Most of the examples we discussed in this chapter are based on collaborative recommendation systems. Sometimes we refer to them as crowdsourced systems, as they use patterns from other users or user actions. As a very simple example: if Pete and Tom both purchase items 1 and 11, but Tom also purchases 2 and 4, then 2 and 4 are likely to be recommended (rightly or wrongly) to Pete. Tom is also sometimes called the “identical twin,” as his behavior is similar to Pete’s. In reality, those systems will look not only for Tom to recommend products to Pete but to many others as well.
The most famous example of a collaborative recommendation system is Amazon’s listing of what people who bought the same book also purchased, as described previously. Amazon can take advantage of a database of millions of users to drive these recommendations.
Note that this collaborative approach is different from the content-based approach, which we will discuss next.
Each of us has already touched a content-based recommendation engine. At a shopping site, for example, a system might pull up items that are similar to the ones you recently purchased. For example, if you selected a red shoe for checkout, suddenly there might be a lot of other red shoes on your screen. Those shoes might be placed via advertisements on banners or via your online store, directly in the “recommended” section. The algorithm selected the shoes because it realized that you are about to buy a red shoe. As we saw in Chapter 1’s discussion of behavioral targeting, the chance of creating purchasing intent is greater the closer a consumer is to the point of sale. So if you already voiced the purchasing intent to buy a red shoe, why not have the system try to suggest other red shoes? This approach has nothing to do with the tastes of your friends or similar people. It has only to do with the content of the item selected, hence the name content-based recommendation engine.
Data for content-based recommendations often takes one of two forms: either data based on consumers’ shopping, purchasing, or search history or a specific user profile that enables the consumer to define her preferences for easier shopping. For example, US shoe retailer Payless allows consumers to enter their gender and shopping preferences, and keeps track of their past ordering history. This data is used to customize in-store recommendations or mail advertising. It is purely based on the content consumers said they like and not based on the patterns of others.
Content-based systems have one disadvantage. To identify similar products, you need a specific description of any product. When looking at a product (clothes, ladies, evening wear), you can easily suggest an evening dress from the same category. However, these categories need to exist in the first place; if you have a product that falls into fewer categories (clothes, ladies), then the system might choose a pair of gym shorts to display next to the evening dress.
When customers do not have the ability to rate items, and companies do not have an infrastructure for evaluating the purchasing history of similar buyers, businesses are often left with content data as the only criteria for making purchasing recommendations. Such data is often less accurate than collaborative data and requires careful planning of data categories to avoid wildly inconsistent recommendations. At the same time, these content-based systems are often much easier to implement, particularly for applications with a smaller audience and/or limited access to social data.
So what goes into a system that predicts whether a potential customer is going to like a specific item? Basically, the computer stores data for each customer. What did he buy? What did he look at? Which country is he in? At what time was he online? What is the weather like? (Yes, even the weather is a factor. If it is sunny, people are less likely to go online and buy things.)
Based on these data points, the recommendation machines are trained by situations in which people actually bought something. At a more abstract level, this is called positive reinforcement, meaning that the desired action was successfully completed. In the future, the algorithm should suggest the same thing in a similar setting in order to create another positive reinforcement. Because there is a true answer, as there is in our previous case to the question of whether the customer did or did not buy, the learning process is called supervised.
Supervised learning is a classical machine-learning problem. It has existed since 1959, when Arthur Samuel wrote a program that played the game of checkers against itself. Here was a possibility for the system to learn, because after each move, the computer would realize whether or not it had lost. In this way, the computer soon learned to play checkers better than Arthur himself. What has changed since 1959 is the amount of available data. Any supervised learning program needs the data in order to “learn.” Thanks to billions of user transactions online, this data is now available.
It is beyond the scope of this book to look into the technology of machine learning, but to give a simple example, let’s discuss regression analysis. Assume you are living just outside a big city and you have to commute each morning to work. Once rush hour kicks in, you know it will take a really long time, so you wonder when would be a good time to leave. You will determine this by using your “intuition”: “If I leave after 8:15, it normally takes me much longer to get into the office.” Machine learning, or regression analysis, in its most basic form, would formalize this process. You do not need to be a statistician to do this. If you plot the duration of your daily commute over the time you leave the house, you will soon have a nice graph that will help you to predict your commuting times. If you get a computer that could draw that curve for you, the program would be considered a machine-learning program (Figure 2-2).
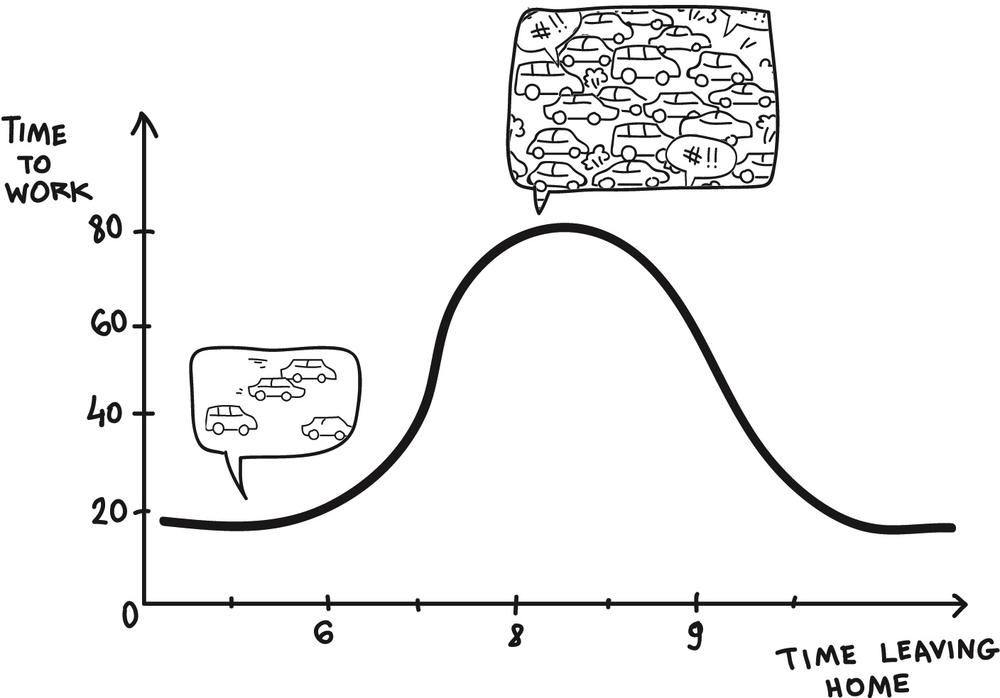
Figure 2-2. Regression algorithm to decide when you should leave home to minimize the commuting time
This is, of course, a simplified example, and in reality you would need to include variables such as weather conditions and school holidays. The more complex the problem becomes, the more difficult it will be to solve it. If you want to know more about support vector machines (SVMs), linear regression, logistic regression, naive Bayes, and other algorithms, there are excellent introductory texts, videos, and online courses. For the beginner, the Stanford class on YouTube by Andrew Ng is a good place to start.
Machine learning has reached such a maturity over the last half century that you can create a learning setup quite easily, simply by using a packaged solution of most statistical language programs such as R, SAS, or others. Those software packages already offer a wide selection of different algorithms. They all compete along two dimensions: speed and accuracy.
If you do not want to be too technical, you could even more easily use a prepackaged solution such as the Google Prediction API, which was launched in 2011. This program enables users to build a recommendation engine on the fly. However, be aware that data is the competitive edge for your social commerce and that this power is shared via the API, meaning Google learns from your data as well.
Next, we will look at the typical issues you can face when starting a recommendation engine, beyond pure technical issues such as speed or scalability.
Collaborative recommendation systems are based on “supervised learning.” In order to make recommendations based on what others have done or purchased, the program needs to analyze similar historical data. Therefore, at the beginning of a program, the computer doesn’t know anything, and the likelihood is high that its recommendations will be wrong. Being wrong is a bad thing, because your early customers could lose trust in your ability to make recommendations. This is why sites such as Amazon had to wait until they were running for a while and had more data to work with before they could start making recommendations.
For example, FOUNDD is a young Berlin-based startup that has built a recommendation engine for the movie industry. Despite its brilliant algorithm, the cold-start issue is a serious problem. Without having a long purchase history, such as Netflix would have, the algorithm will not be able to recommend anything useful. Fully aware of it, the founder created a “hot or flop” page in the beginning. Each customer has to rate 10 movies before the system aims to recommend anything. “It has to be fun,” said Lasse Clausen, one of the founders. “Otherwise the user won’t do it, and we will not get up and running.” In order to bypass the cold-start problem, Lasse and his team are are initially using a content-based approach by pre-clustering similar movies according to their genre or popularity.
Only after 5 to 10 movies are rated can the system start recommending. Are 10 movies enough? Most likely not for a superb recommendation, but the more the users rate the movies, the better the system will become at detecting each individual’s preference.
The combination of pre-clustering and initial user input is the best way to avoid the cold-start issue as demonstrated by FOUNDD. Alternatively, if possible, initial “learning” data can be drawn from external sources and then improved upon over time with a company’s own customer data.
A much bigger issue than the cold-start issue has yet to be faced by FOUNDD, the startup we just discussed. They have focused on a set of movies, but when you have thousands of items in your store, it is difficult to figure out which ones are best to recommend.
This issue is often called data sparsity. It is similar to the cold-start issue but broken down in terms of each product. If a retailer has millions of items, it is hard to find good ways to suggest items from the “long tail,” or the millions of items that are not best sellers but still get sold. To recommend products from this long tail, the algorithm needs to include a minimum number of purchases for each of these products.
According to one of the top five online retailers in Germany, the biggest sales come from a changing online assortment, thus the data for their long tail is quite small despite having the potential for many users and many purchases. As a result, the recommendation engine could only suggest its biggest non-changing sales item, which happens to be socks. Of course, recommending socks with each and every purchase did not drive increased incremental sales. The retailer eventually addressed this issue by having a student write manual recommendations for more appropriate goods instead of using a machine-learning approach.
The more complex the system is, and the more items there are to recommend, the more difficult it is to make a good recommendation due to the potential issue of data sparsity. For example, LinkedIn serves employment advertisers by recommending the right people for their posted job ads. For this functionality, LinkedIn needs a tremendous amount of data; such a service was not feasible even with 10 million users. But now that they have more than 100 million users with highly variable data points, it must be addressed as a big data problem. In the extreme, issues such as tastes in human style or matching specific body shapes to clothing choices can also require millions of matching data points in order for a machine to begin to make an accurate recommendation.
Machines only learn based on popular choices. Thus, they are more likely to recommend the obvious popular choices that are safer to recommend.
Let’s say you have just finished the fourth book of the seven books in the Harry Potter series. What will be a likely recommendation from a machine-learning algorithm? The correct answer: books one through three. But that is not useful, since you most likely have already read them. Similarly, recommending book five would not be helpful, as you probably already know that it exists. A good recommendation would be a book in the same genre or style or maybe based on one of the other attributes of the book that you appreciated the most.
A good bookseller will understand your needs quickly. A recommendation engine will, at least so far, only recommend what others have read. This is the reason Amazon cannot replace the recommendation of a human bookseller—at least not yet.
If you were to scratch the surface of the major recommendation engines, you could envision a set of complex analyses guarded by a top-secret formula. At the top of the online retailing spectrum, there is in fact some truth to this stereotype. But a more important point is that, for most people, recommendation systems revolve around making use of clear and observable data.
Let’s look at the leaders in recommending emotional content, such as Amazon and Netflix. Both have great recommendation systems. Their sites suggest things to their users such as movies to watch or books to read, and the recommendations are very important to sales. At Netflix, 75% of all user choices are based on recommendations made for them by their own system. During the Strata 2012 conference, Xavier Amatriain (@xamat) from Netflix explained some of the inputs that are used by their recommendation system:
- User ratings
Plain user feedback on movies watched.
- Context
Uses, for example, the time of the day or week as an indicator.
- Popularity
General metric on what is popular among users overall.
- Interest
What is the user normally interested in, and what kind of interests did she list in her profile?
- Freshness
The aim to offer new and diverse ideas to the user.
- Friends’ recommendations via Facebook
What do the user’s friends like?
Those are many variables, and there are surely more. But more importantly, each of those six areas are influenced by several indicators taken out of millions of data points from 23 million subscribers in 47 countries with over 5 billion recommendations. Mind-blowing? Probably not! If you look further into your own company, you will find similar amounts of data lying around. Most of it is probably not used; or even worse, it might not be easily accessible as it is within Netflix. However, you have a complexity of your own, and the question you must ask yourself is how to use the data.
Let’s have a look at how Netflix has used the data. It did not start out with many different variables; it started out with just a simple method of recommendations. As discussed in Chapter 9, the strategy it used is highly suitable because it is:
- Easy to measure
Netflix asks the users for their preferences directly.
- Low on error
We can assume that people are rating those videos accurately or, at least, honestly.
- High on correlation
The correlation between the users’ tastes in the past and in the future is very clear.
The lesson learned from Netflix is to start simple. Only after the correlations were proven did Netflix start to expand the system step by step. It started by optimizing a few metrics where causation was highly predictable and then built from there. Even today, when according to Netflix, 75% of what people view is recommendation-based, it continues to refine features and algorithms using a simple baseline of viewer opinions. Looking at your own process of using recommendations, you could boil the process down into three key guidelines:[56]
As we discussed earlier, trust is a critical component of any kind of sales transaction. It has become particularly important in light of the issues discussed in the chapter on astroturfing and bots (Chapter 6), such as how people use social data to game the system. Things such as spam, fake followers, and astroturfing increase our suspicions, particularly when someone wants to sell us something. We see that there are two key ways to instill trust when it comes to online interactions:
Trust in a product by the social confirmation of others.
Trust in the algorithms to recommend the “right” item for our taste.
It is this social component of social commerce that instills trust. With trust, there will be a higher likelihood to buy, but please note that this is only one of many factors that could trigger purchasing intent. Moreover, the process of creating trust is, as we all know, not completely deterministic. Thus, while we may understand the overall logic and purpose of social recommendations, it is not 100% predictable how this process will work in any given moment or for any given product. In this way, the fuzzy logic of learning by machines can help. In time, we can create data that guides us in selecting, for example, which of several reviews might create the highest trust and with it the highest likelihood to lead someone to buy.
Next to trust, there are two other factors that are supportive of the sales process: personal relationships and reason.
“Hi Lutz, I am Brad your community manager. I wanted to check in with you to see how you like our product.” Brad’s Facebook picture smiles at the top of his email. It is a family photo of him at the beach. It is difficult to know whether Brad is a real person, a robot, or perhaps a human-guided robot, but this company clearly understands that personal relationships are an important part of the sales process, even if—or maybe especially when—someone shops online.
Netflix, as we mentioned earlier, benefits from the ability to tell customers which of their friends watched a movie and uses it as a trustworthy recommendation. However, not every company has products that are so commonly bought by many friends. If you are a bike retailer, you would need to be lucky to find some friends of your customers who just happened to have bought a similar bike and thus could be used as an endorsement to instill purchasing intent.
Therefore, in the future, we will see more and more attempts to create personal online connections between salespeople and customers in order to facilitate sales. The need for personal connection is not only needed for the sales process, but also for retention purposes. We will see in Chapter 4 how customer-care efforts in social media help to create a more personal face for a company and thus satisfy this human need for connection.
Research shows that users are highly sensitive to the reasons something is recommended to them. Providing an explanation seems to trigger an automated response pattern similar to the one observed by Robert Cialdini (see Give Me a Reason). The best recommendations are, of course, often those that can be linked to personal data, but this is not necessarily a requirement. Take Amazon, which analyzes our purchasing habits without knowing that our friends are, say, mountain bikers. Amazon’s explanation of why these book recommendations are being made—because others liked them as well—is still much more powerful than just displaying the recommendations alone.
A sales process relies on knowledge and trust. As noted in many other chapters, social media can be used in two distinct and very different ways. On one hand, social media supports sales operations: the tweets, the blogs, the reviews, and all the interactions with customers can create knowledge and trust in the products and hopefully increase sales. On the other hand, social media data by itself can create insights that lead to knowledge about a potential consumer. Those methods of usage are very different and require very different skill sets. Do not ask the marketing agency for deep analytical insights. They will most likely fail in the same way the data scientist will fail to write a catchy marketing message for your Twitter account.
In the first part of this chapter, we discussed how to use social media during the sales process. Essentially the ideas are similar to the ones in Chapter 1. However, in comparison to the discussion there, we can link our action closer to sales success. Thus, we do not need so many descriptive variables. Revenue or closed sales are sufficient metrics. Social media, like no other area, has a feasible and impactful ROI metric.
In the second part of this chapter, we discussed the social media data. This data contains clues about our consumer. What do they think? What do they need? Those clues can help predict what the customer might want to do next. Unlike other areas in a company, predictive modeling comes into play. The binary form of sales process is helpful. Did he buy or not? Using machine learning we can build recommendation systems. We went over the different types and challenges of recommendation engines.
Ultimately, using social data to increase sales leverages human nature and human psychology. We want to trust what we buy, and in the process, we want to feel connected to others. Therefore, if we use smart algorithms to predict behavior, we need to be very careful how we communicate this knowledge.
There is still no magic bullet that will make people buy something, and there likely never will be; however, as the volume of data continues to grow, as well as the connections that can be made as a result, we have more potential than ever to understand and manage purchasing intent.
How can you use social media processes or social media data to support your sales processes? To get you thinking, look at the following workbook questions:
What kind of knowledge is important for your customers? What do your customers normally know before they purchase your products?
How important is trust in the sales process? Is this different in each stage of the sales funnel?
Write down a typical sales flow, starting at the acquisition stage and continuing until the stage where the deal is closed.
What social media tools could you use at each stage of this funnel to foster trust and knowledge?
Recommendation engines are an effective way of getting to the fourth “V,” the value. Setting them up is not always easy, but it coud be the small steps that make the difference between success and failure:
Look through the sales flow you described earlier: where within the flow could one use a recommendation system?
What kind (collaborative versus content) would you use?
How will your customer react to those insights? How could you best explain them without losing trust?
Have you found a new way of engaging within your sales channel? Engage with us via @askmeasurelearn or write on our LinkedIn or Facebook page.
[46] It will come as no surprise that purchase behavior is structured and, consequently, for most applications, the better data set to work with.
[47] Please note that other channels might be cannibalized, prohibiting a 100% direct relationship between investment and return.
[48] Lutz Finger is an advisor to Compass.co.
[49] Tim O’Reilly, “What is Web 2.0: Design Patterns and Business Models for the Next Generation of Software,” Communications & Strategies, 2007, http://ssrn.com/abstract=1008839.
[50] Arjun Mukherjee et al. “Spotting Fake Reviewer Groups in Consumer Reviews,” International World Wide Web Conference (WWW-2012), April 2012, http://bit.ly/1jSvvWH.
[51] Jure Leskovec et al., “The Dynamics of Viral Marketing,” ACM Transactions on Web, 2007, http://bit.ly/1bymUAt.
[52] Carol Roth, “ Big Data: Google Thinks That I’m a Dude and Target Thinks That I’m Pregnant,” blog, May 2012, http://bit.ly/1bZ6Bmy.
[54] Jaron Lanier, “One Half A Manifesto,” Edge, Mai 2005, http://bit.ly/1j08hQr.
[55] Eli Pariser, “Beware online ‘filter bubbles’,” TED Talks, March 2011, http://bit.ly/IRt6N3.
[56] Xavier Amatriain, “Netflix Recommendations: Beyond the 5 stars,” Netflix Tech Blog, April 6, 2012, http://nflx.it/1bHzkKZ.
[57] Robert Cialdini, Influence: The Psychology of Persuasion, December 2006, http://amzn.to/JiD9vO.