
Iteration and recursion are two fundamental concepts without which it would be impossible to do much, if anything, useful in computing. Sorting names, calculating credit-card transaction totals, and printing order line items all require that each record, each data point, be processed to achieve the desired result.
Iteration is simply the repetition of processing steps. How many repetitions are required can be determined by many different factors. For example, to calculate the total of your stock portfolio, you would iterate over your stock holdings, keeping a running total until each holding has been processed. In this case, the number of repetitions is determined by how many holdings you happen to have. Recursion is another technique for solving problems. Recursion can often, though not always, be a more natural way of expressing an algorithm than iteration. If you've done any programming at all, you probably already know what recursion is — you just didn't know you knew.
A recursive algorithm involves a method or function calling itself. It does this by breaking a problem into smaller and smaller parts, each looking very similar to the larger part yet finer grained. This can be a difficult concept to grasp at first.
You will find that algorithms tend to fall naturally into one category or the other; they are most easily expressed either iteratively or recursively. Having said this, it is fair to say that recursive algorithms are fewer and farther between than iterative ones for most practical applications. In this chapter, we assume you are familiar with how to construct loops, make method calls, and so on, and so we instead concentrate on how iteration and recursion are used to solve problems.
This chapter describes the following:
How iteration is used to perform calculations
How iteration is used to process arrays
How to abstract the problem of iteration from simple arrays to more complex data structures
How recursion is another technique for solving similar problems
Iteration can be used to perform calculations. Possibly one of the simplest examples of this is to raise one number (the base) to the power of another (the exponent): baseexp. This involves repeatedly multiplying the base by itself as many times as defined by the exponent. For example: 3^2 = 3 × 3 = 9 and 10^6 = 10 × 10 × 10 × 10 × 10 × 10 = 1,000,000.
In this section, you'll implement a class, PowerCalculator, with a single method, calculate, that takes two parameters — an integer base and an exponent — and returns the value of the base raised to the power of the exponent. Although it's possible to use a negative exponent, for the purposes of this example you can assume that only exponents greater than or equal to zero will be used.
Begin by creating the test class itself, which does little more than extend TestCase:
package com.wrox.algorithms.iteration;
import junit.framework.TestCase;
public class PowerCalculatorTest extends TestCase {
...
}The first rule involves raising the base to the power of zero. In all cases, this should result in the value of 1:
public void testAnythingRaisedToThePowerOfZeroIsOne() {
PowerCalculator calculator = PowerCalculator.INSTANCE;
assertEquals(1, calculator.calculate(0, 0));
assertEquals(1, calculator.calculate(1, 0));
assertEquals(1, calculator.calculate(27, 0));
assertEquals(1, calculator.calculate(143, 0));
}The next rule involves raising the base to the power of one. In this case, the result should always be the base itself:
public void testAnythingRaisedToThePowerOfOneIsItself() {
PowerCalculator calculator = PowerCalculator.INSTANCE;
assertEquals(0, calculator.calculate(0, 1));
assertEquals(1, calculator.calculate(1, 1));
assertEquals(27, calculator.calculate(27, 1));
assertEquals(143, calculator.calculate(143, 1));
}Finally, you arrive at the general case:
public void testAritrary() {
PowerCalculator calculator = PowerCalculator.INSTANCE;
assertEquals(0, calculator.calculate(0, 2));
assertEquals(1, calculator.calculate(1, 2));
assertEquals(4, calculator.calculate(2, 2));
assertEquals(8, calculator.calculate(2, 3));
assertEquals(27, calculator.calculate(3, 3));
}The first rule makes a number of calculations, each with different values, and ensures that the calculation returns 1 in all cases. Notice that even 0 raised to the power of zero is actually 1!
Also in the second rule, you perform a number of calculations with varying base values but this time using an exponent of 1.
This time, the outcome of the calculation is tested using a number of different combinations of base and exponent.
The calculate() method first checks to ensure that the exponent is valid (remember that you don't allow negative values) and initializes the result to 1. Then comes the iteration in the form of a for loop. If the exponent was 0, the loop would terminate without performing any multiplication and the result would still be 1 — anything raised to the power of zero is one. If the exponent was 1, the loop would make a single pass, multiplying the initial result by the base and returning to the caller — a number raised to the power of one is the number itself. For values of the exponent larger than this, the loop will continue, multiplying the result by the base as many times as specified.
A private constructor is used in order to prevent instances of the class from being constructed from outside the class itself. Instead, a single instance can be accessed via the constant
INSTANCE. This is an example of the Singleton design pattern [Gamma, 1995].
Besides performing calculations, iteration is also used to process arrays. Imagine you wanted to apply a discount to a group of orders. The following code snippet iterates over an array of orders, applying a specified discount to each:
Order[] orders = ...;
for (int i = 0; i < orders.length; ++i) {
orders[i].applyDiscount(percentage);
}We first initialize our index variable with the position of the first element (int i = 0) and continue incrementing it (++i) until reaching the last element (i < orders.length – 1), applying the percentage. Notice that each iteration compares the value of the index variable with the length of the array.
Sometimes you may wish to process an array in reverse. For example, you may need to print a list of names in reverse order. The following code snippet iterates backward over an array of customers, printing the name of each:
Customer[] customers = ...;
for (int i = customers.length − 1; i >= 0; −−i) {
System.out.println(customers[i].getName());
}This time, initialize the index variable to the position of the last element (int i = customers.length – 1) and continue decrementing (−−i) until reaching the first (i >= 0), printing the customer's name each time through the loop.
Although array-based iteration is useful when dealing with very simple data structures, it is quite difficult to construct generalized algorithms that do much more than process every element of an array from start to finish. For example, suppose you want to process only every second item; include or exclude specific values based on some selection criteria; or even process the items in reverse order as shown earlier. Being tied to arrays also makes it difficult to write applications that operate on databases or files without first copying the data into an array for processing.
Using simple array-based iteration not only ties algorithms to using arrays, but also requires that the logic for determining which elements stay, which go, and in which order to process them, is known in advance. Even worse, if you need to perform the iteration in more than one place in your code, you will likely end up duplicating the logic. This clearly isn't a very extensible approach. Instead, what's needed is a way to separate the logic for selecting the data from the code that actually processes it.
An iterator (also known as an enumerator) solves these problems by providing a generic interface for looping over a set of data so that the underlying data structure or storage mechanism — such as an array, database, and so on — is hidden. Whereas simple iteration generally requires you to write specific code to handle where the data is sourced from or even what kind of ordering or preprocessing is required, an iterator enables you to write simpler, more generic algorithms.
An iterator provides a number of operations for traversing and accessing data. Looking at the operations listed in Table 2-1, you will notice there are methods for traversing backward as well as forward.
Remember that an iterator is a concept, not an implementation. Java itself already defines an Iterator interface as part of the standard Java Collections Framework. The iterator we define here, however, is noticeably and deliberately different from the standard Java version, and instead conforms more closely to the iterator discussed in Design Patterns [Gamma, 1995].
Table 2.1. Iterator Operations
Operation | Description |
|---|---|
previous | Positions to the previous item. Throws |
isDone | Determines whether the iterator refers to an item. Returns |
current | Obtains the value of the current item. Throws |
Most methods can potentially throw an UnsupportedOperationException. Not all data structures allow traversing the data in both directions, nor does it always make sense. For this reason, it is acceptable for any of the traversal methods — first(), last(), next(), and previous() — to throw an UnsupportedOperationException to indicate this missing or unimplemented behavior.
You should also leave the behavior of calling current() before either first() or last() has been called undefined. Some iterator implementations may well position to the first item, while others may require you to call first() or last(). In any event, relying on this behavior is considered to be programming by coincidence and should be avoided. Instead, when using iterators, be sure to follow one of the idioms described in the "Iterator Idioms" section, later in the chapter.
From the operations just described, you can create the following Java interface:
package com.wrox.algorithms.iteration;
public interface Iterator {
public void first();
public void last();
public boolean isDone();
public void next();
public void previous();
public Object current() throws IteratorOutOfBoundsException;
}As demonstrated, you have quite literally translated the operations into a Java interface, one method per operation.
You also need to define the exception that will be thrown if an attempt is made to access the current item when there are no more items to process:
package com.wrox.algorithms.iteration;
public class IteratorOutOfBoundsException extends RuntimeException {
}Because accessing an iterator out-of-bounds is considered a programming error, it can be coded around. For this reason, it's a good idea to make IteratorOutOfBoundsException extend RuntimeException, making it a so-called unchecked exception. This ensures that client code need not handle the exception. In fact, if you adhere to the idioms discussed soon, you should almost never see an IteratorOutOfBoundsException.
In addition to the Iterator interface, you'll also create another interface that provides a generic way to obtain an iterator from any data structure that supports it:
package com.wrox.algorithms.iteration;
public interface Iterable {
public Iterator iterator();
}The Iterable interface defines a single method — iterator() — that obtains an iterator over the data contained in whatever the underlying data structure contains. Although not used in this chapter, the Iterable interface enables code that only needs to iterate over the contents of a data structure to treat all those that implement it in the same way, irrespective of the underlying implementation.
As with simple array-based iteration, there are two basic ways, or templates, for using iterators: either a while loop or a for loop. In either case, the procedure is similar: Once an iterator has been obtained — either by explicit construction or as an argument to a method — position to the beginning or end as appropriate. Then, while there are more items remaining, take each one and process it before moving on to the next (or previous).
Using a while loop enables you to perform quite a literal translation from the preceding text into code:
Iterator iterator = ...;
iterator.first();
while (!iterator.isDone()) {
Object object = iterator.current();
...
iterator.next();
}This way is particularly useful when an iterator has been passed as a parameter in a method call. In this case, the method may not need to call first() or last() if the iterator has already been positioned to the appropriate starting point.
The use of a for loop, however, is probably more familiar to you as it closely resembles the way you would normally iterate over an array:
Iterator iterator = ...;
for (iterator.first();!iterator.isDone(); iterator.next()) {
Object object = iterator.current();
...
}Notice how similar this is to array iteration: The initialization becomes a call to first(); the termination condition is a check of isDone(); and the increment is achieved by calling next().
Either idiom is encouraged, and both are used with more or less the same frequency in most real-world code you have seen. Whichever way you choose, or even if you choose to use both, remember to always call first() or last() before you call any other methods. Otherwise, results might be unreliable and depend on the implementation of the iterator.
In addition to the iterators provided by some of the data structures themselves later in this book, or even iterators you might create yourself, several standard implementations provide commonly used functionality. When combined with other iterators, these standard iterators enable you to write quite sophisticated algorithms for data processing.
The most obvious iterator implementation is one that wraps an array. By encapsulating an array within an iterator, you can start writing applications that operate on arrays now and still extend easily to other data structures in the future.
One of the advantages of using iterators is that you don't necessarily have to traverse an array from the start, nor do you need to traverse right to the end. Sometimes you may want to expose only a portion of an array. The first test you will write, therefore, is to ensure that you can construct an array iterator passing in the accessible bounds — in this case, a starting position and an element count. This enables you to create an iterator over all or part of an array using the same constructor:
public void testIterationRespectsBounds() {
Object[] array = new Object[] {"A", "B", "C", "D", "E", "F"};
ArrayIterator iterator = new ArrayIterator(array, 1, 3);
iterator.first();
assertFalse(iterator.isDone());
assertSame(array[1], iterator.current());
iterator.next();
assertFalse(iterator.isDone());
assertSame(array[2], iterator.current());
iterator.next();
assertFalse(iterator.isDone());
assertSame(array[3], iterator.current());
iterator.next();
assertTrue(iterator.isDone());
try {
iterator.current();
fail();
} catch (IteratorOutOfBoundsException e) {
// expected
}
}The next thing you want to test is iterating backward over the array — that is, starting at the last element and working your way toward the first element:
public void testBackwardsIteration() {
Object[] array = new Object[] {"A", "B", "C"};
ArrayIterator iterator = new ArrayIterator(array);
iterator.last();
assertFalse(iterator.isDone());
assertSame(array[2], iterator.current());
iterator.previous();
assertFalse(iterator.isDone());
assertSame(array[1], iterator.current());
iterator.previous();
assertFalse(iterator.isDone());
assertSame(array[0], iterator.current());
iterator.previous();
assertTrue(iterator.isDone());
try {
iterator.current();
fail();
} catch (IteratorOutOfBoundsException e) {
// expected
}
}
}In the first test, you begin by constructing an iterator, passing an array containing six elements. Notice, however, you have also passed a starting position of 1 (the second element) and an element count of 3. Based on this, you expect the iterator to return only the values "B", "C", and "D". To test this, you position the iterator to the first item and ensure that its value is as expected — in this case, "B". You then call next for each of the remaining elements: once for "C" and then again for "D", after which, even though the underlying array has more elements, you expect the iterator to be done. The last part of the test ensures that calling current(), when there are no more items, throws an IteratorOutOfBoundsException.
In the last test, as in the previous test, you construct an iterator, passing in an array. This time, however, you allow the iterator to traverse all the elements of the array, rather than just a portion of them as before. You then position to the last item and work your way backward, calling previous() until you reach the first item. Again, once the iterator signals it is done, you check to ensure that current() throws an exception as expected.
That's it. You could test for a few more scenarios, but for the most part that really is all you need in order to ensure the correct behavior of your array iterator. Now it's time to put the array iterator into practice, which you do in the next Try It Out.
If you assume that the iterator always operates over the entire length of an array, from start to finish, then the only other information you need to store is the current position. However, you may often wish to only provide access to a portion of the array. For this, the iterator will need to hold the bounds — the upper and lower positions — of the array that are relevant to the client of the iterator:
package com.wrox.algorithms.iteration;
public class ArrayIterator implements Iterator {
private final Object[] _array;
private final int _first;
private final int _last;
private int _current = −1;
public ArrayIterator(Object[] array, int start, int length) {
assert array != null : "array can't be null";
assert start >= 0 : "start can't be < 0";
assert start < array.length : "start can't be > array.length";
assert length >= 0 : "length can't be < 0";
_array = array;
_first = start;
_last = start + length − 1;
assert _last < array.length : "start + length can't be > array.length";
}
...
}Besides iterating over portions of an array, there will of course be times when you want to iterate over the entire array. As a convenience, it's a good idea to also provide a constructor that takes an array as its only argument and calculates the starting and ending positions for you:
public ArrayIterator(Object[] array) {
assert array != null : "array can't be null";
_array = array;
_first = 0;
_last = array.length − 1;
}Now that you have the array and have calculated the upper and lower bounds, implementing first() and last() couldn't be easier:
public void first() {
_current = _first;}
public void last() {
_current = _last;
}Traversing forward and backward is much the same as when directly accessing arrays:
public void next() {
++_current;
}
public void previous() {
−−_current;
}Use the method isDone() to determine whether there are more elements to process. In this case, you can work this out by determining whether the current position falls within the bounds calculated in the constructor:
public boolean isDone() {
return _current < _first || _current > _last;
}If the current position is before the first or after the last, then there are no more elements and the iterator is finished.
Finally, you implement current() to retrieve the value of the current element within the array:
public Object current() throws IteratorOutOfBoundsException {
if (isDone()) {
throw new IteratorOutOfBoundsException();
}
return _array[_current];
}As you can see in the first code block of the preceding example, there is a reference to the underlying array as well as variables to hold the current, first, and last element positions (0, 1, 2, . . .). There is also quite a bit of checking to ensure that the values of the arguments make sense. It would be invalid, for example, for the caller to pass an array of length 10 and a starting position of 20.
Moving on, you already know the position of the first and last elements, so it's simply a matter of setting the current position appropriately. To move forward, you increment the current position; and to move backward, you decrement it.
Notice how you ensure that there is actually a value to return by first calling isDone(). Then, assuming there is a value to return, you use the current position as an index in exactly the same way as when directly accessing the array yourself.
Sometimes you will want to reverse the iteration order without changing the code that processes the values. Imagine an array of names that is sorted in ascending order, A to Z, and displayed to the user somehow. If the user chose to view the names sorted in descending order, Z to A, you might have to re-sort the array or at the very least implement some code that traversed the array backward from the end. With a reverse iterator, however, the same behavior can be achieved without re-sorting and without duplicated code. When the application calls first(), the reverse iterator actually calls last() on the underlying iterator. When the application calls next(), the underlying iterator's previous() method is invoked, and so on. In this way, the behavior of the iterator can be reversed without changing the client code that displays the results, and without re-sorting the array, which could be quite processing intensive, as you will see later in this book when you write some sorting algorithms.
The test class itself defines an array that can be used by each of the test cases. Now, test that the reverse iterator returns the elements of this array in the appropriate order:
public void testForwardsIterationBecomesBackwards() {
ReverseIterator iterator = new ReverseIterator(new ArrayIterator(ARRAY));
iterator.first();
assertFalse(iterator.isDone());
assertSame(ARRAY[2], iterator.current());
iterator.next();
assertFalse(iterator.isDone());
assertSame(ARRAY[1], iterator.current());
iterator.next();
assertFalse(iterator.isDone());
assertSame(ARRAY[0], iterator.current());
iterator.next();
assertTrue(iterator.isDone());try {
iterator.current();
fail();
} catch (IteratorOutOfBoundsException e) {
// expected
}
}Notice that although you are iterating forward through the array from start to finish, the values returned are in reverse order. If it wasn't apparent before, it is hoped that you can now see what a powerful construct this is. Imagine that the array you're iterating over is a list of data in sorted order. You can now reverse the sort order without actually re-sorting(!):
public void testBackwardsIterationBecomesForwards() {
ReverseIterator iterator = new ReverseIterator(new ArrayIterator(ARRAY));
iterator.last();
assertFalse(iterator.isDone());
assertSame(ARRAY[0], iterator.current());
iterator.previous();
assertFalse(iterator.isDone());
assertSame(ARRAY[1], iterator.current());
iterator.previous();
assertFalse(iterator.isDone());
assertSame(ARRAY[2], iterator.current());
iterator.previous();
assertTrue(iterator.isDone());
try {
iterator.current();
fail();
} catch (IteratorOutOfBoundsException e) {
// expected
}
}The first test case ensures that when calling first() and next() on the reverse iterator, you actually get the last and previous elements of the array, respectively.
The second test makes sure that iterating backward over an array actually returns the items from the underlying iterator from start to finish.
The last test is structurally very similar to the previous test, but this time you're calling last() and previous() instead of first() and next(), and, of course, checking that the values are returned from start to finish.
Now you're ready to put the reverse iterator into practice, as shown in the next Try It Out.
package com.wrox.algorithms.iteration;
public class ReverseIterator implements Iterator {
private final Iterator _iterator;
public ReverseIterator(Iterator iterator) {
assert iterator != null : "iterator can't be null";
_iterator = iterator;
}
public boolean isDone() {
return _iterator.isDone();
}
public Object current() throws IteratorOutOfBoundsException {
return _iterator.current();
}
public void first() {
_iterator.last();
}
public void last() {
_iterator.first();
}
public void next() {
_iterator.previous();
}
public void previous() {
_iterator.next();
}
}Besides implementing the Iterator interface, the class also holds the iterator to reverse its behavior. As you can see, calls to isDone() and current() are delegated directly. The remaining methods, first(), last(), next(), and previous(), then redirect to their opposite number — last(), first(), next(), and previous(), respectively — thereby reversing the direction of iteration.
One of the more interesting and useful advantages of using iterators is the capability to wrap or decorate (see the Decorator pattern [Gamma, 1995]) another iterator to filter the return values. This could be as simple as only returning every second value, or something more sophisticated such as processing the results of a database query to further remove unwanted values. Imagine a scenario whereby in addition to the database query selection criteria, the client was also able to perform some filtering of its own.
The filter iterator works by wrapping another iterator and only returning values that satisfy some condition, known as a predicate. Each time the underlying iterator is called, the returned value is passed to the predicate to determine whether it should be kept or discarded. It is this continuous evaluation of values with the predicate that enables the data to be filtered.
You begin by creating an interface that represents a predicate:
package com.wrox.algorithms.iteration;
public interface Predicate {
public boolean evaluate(Object object);
}The interface is very simple, containing just one method, evaluate(), that is called for each value, and returning a Boolean to indicate whether the value meets the selection criteria or not. If evaluate() returns true, then the value is to be included and thus returned from the filter iterator. Conversely, if the predicate returns false, then the value will be ignored, and treated as if it never existed.
Although simple, the predicate interface enables you to build very sophisticated filters. You can even implement predicates for AND (&&), OR (||), NOT (!), and so on, enabling the construction of any arbitrarily complex predicate you can think of.
You want to know that the predicate is called once for each item returned from the underlying iterator. For this, you create a predicate specifically for testing purposes:
private static final class DummyPredicate implements Predicate {
private final Iterator _iterator;
private final boolean _result;
public DummyPredicate(boolean result, Iterator iterator) {_iterator = iterator;
_result = result;
_iterator.first();
}
public boolean evaluate(Object object) {
assertSame(_iterator.current(), object);
_iterator.next();
return _result;
}
}
...
}The first test is to ensure that the filter returns values the predicate accepts — evaluate() returns true — while iterating forward:
public void testForwardsIterationIncludesItemsWhenPredicateReturnsTrue() {
Iterator expectedIterator = new ArrayIterator(ARRAY);
Iterator underlyingIterator = new ArrayIterator(ARRAY);
Iterator iterator = new FilterIterator(underlyingIterator,
new DummyPredicate(true, expectedIterator));
iterator.first();
assertFalse(iterator.isDone());
assertSame(ARRAY[0], iterator.current());
iterator.next();
assertFalse(iterator.isDone());
assertSame(ARRAY[1], iterator.current());
iterator.next();
assertFalse(iterator.isDone());
assertSame(ARRAY[2], iterator.current());
iterator.next();
assertTrue(iterator.isDone());
try {
iterator.current();
fail();
} catch (IteratorOutOfBoundsException e) {
// expected
}
assertTrue(expectedIterator.isDone());
assertTrue(underlyingIterator.isDone());
}The next test is much simpler than the first. This time, you want to see what happens when the predicate rejects values — that is, evaluate() returns false:
public void testForwardsIterationExcludesItemsWhenPredicateReturnsFalse() {
Iterator expectedIterator = new ArrayIterator(ARRAY);
Iterator underlyingIterator = new ArrayIterator(ARRAY);
Iterator iterator = new FilterIterator(underlyingIterator,
new DummyPredicate(false, expectedIterator));
iterator.first();
assertTrue(iterator.isDone());
try {
iterator.current();
fail();
} catch (IteratorOutOfBoundsException e) {
// expected
}
assertTrue(expectedIterator.isDone());
assertTrue(underlyingIterator.isDone());
}The remaining two tests are almost identical to the first two except that the order of iteration has been reversed:
public void testBackwardssIterationIncludesItemsWhenPredicateReturnsTrue() {
Iterator expectedIterator = new ReverseIterator(new ArrayIterator(ARRAY));
Iterator underlyingIterator = new ArrayIterator(ARRAY);
Iterator iterator = new FilterIterator(underlyingIterator,
new DummyPredicate(true, expectedIterator));
iterator.last();
assertFalse(iterator.isDone());
assertSame(ARRAY[2], iterator.current());
iterator.previous();
assertFalse(iterator.isDone());
assertSame(ARRAY[1], iterator.current());
iterator.previous();
assertFalse(iterator.isDone());
assertSame(ARRAY[0], iterator.current());
iterator.previous();
assertTrue(iterator.isDone());
try {
iterator.current();
fail();
} catch (IteratorOutOfBoundsException e) {
// expected
}
assertTrue(expectedIterator.isDone());
assertTrue(underlyingIterator.isDone());}
public void testBackwardsIterationExcludesItemsWhenPredicateReturnsFalse() {
Iterator expectedIterator = new ReverseIterator(new ArrayIterator(ARRAY));
Iterator underlyingIterator = new ArrayIterator(ARRAY);
Iterator iterator = new FilterIterator(underlyingIterator,
new DummyPredicate(false, expectedIterator));
iterator.last();
assertTrue(iterator.isDone());
try {
iterator.current();
fail();
} catch (IteratorOutOfBoundsException e) {
// expected
}
assertTrue(expectedIterator.isDone());
assertTrue(underlyingIterator.isDone());
}Besides the test cases themselves, the test class contains little more than some simple test data. However, in order to test the filter iterator adequately, you need to confirm not only the expected iteration results, but also that the predicate is being called correctly.
The DummyPredicate inner class that you created for testing purposes in the second code block holds an iterator that will return the values in the same order as you expect the predicate to be called with. Each time evaluate() is called, you check to make sure that the correct value is being passed. In addition to checking the values, evaluate() also returns a predetermined result — set by the test cases — so that you can check what happens when the predicate accepts values and when it rejects values.
Next, you create the actual tests. You started by creating two iterators: one for the items you expect the predicate to be called with, and the other to provide the items to the filter in the first place. From these, you construct a filter iterator, passing in the underlying iterator and a dummy predicate configured to always accept the values passed to it for evaluation. Then you position the filter iterator to the first item, check that there is in fact an item to obtain, and that the value is as expected. The remainder of the test simply calls next() repeatedly until the iterator is complete, checking the results as it goes. Notice the last two assertions of the first test (in the third code block from the preceding Try it Out) that ensure that both the underlying iterator and the expected iterator have been exhausted.
The next test begins much the same as the previous test except you construct the predicate with a predetermined return value of false. After positioning the filter iterator to the first item, you expect it to be finished straightaway — the predicate is rejecting all values. Once again, however, you still expect both iterators to have been exhausted; and in particular, you expect the underlying iterator to have had all of its values inspected.
In the last test, notice the use of ReverseIterator; the dummy iterator still thinks that it's iterating forward, but in reality it's iterating backward.
In the case of first() and next(), the call is first delegated to the underlying iterator before searching forward from the current position to find a value that satisfies the filter:
public void first() {
_iterator.first();
filterForwards();
}
public void next() {
_iterator.next();
filterForwards();
}
private void filterForwards() {
while (!_iterator.isDone() && !_predicate.evaluate(_iterator.current())) {
_iterator.next();
}
}Finally, you add last() and previous(), which, not surprisingly, look very similar to first() and next():
public void last() {
_iterator.last();filterBackwards();
}
public void previous() {
_iterator.previous();
filterBackwards();
}
private void filterBackwards() {
while (!_iterator.isDone() && !_predicate.evaluate(_iterator.current())) {
_iterator.previous();
}
}The FilterIterator can now be used to traverse any data structure supporting iterators. All you need to do is create an appropriate predicate to do the specific filtering you require.
The filter iterator class implements the Iterator interface, of course, and holds the iterator to be wrapped and the predicate to use for filtering. The constructor first checks to make sure that neither argument is null before assigning them to instance variables for later use. The two methods isDone() and current() need do nothing more than delegate to their respective methods on the underlying iterator. This works because the underlying iterator is always kept in a state such that only an object that is allowed by the predicate is the current object.
The real work of the iterator is performed when one of the traversal methods is called. Anytime first(), next(), last(), or previous() is invoked, the predicate must be used to include or exclude values as appropriate while still maintaining the semantics of the iterator:
public void first() {
_iterator.first();
filterForwards();
}
public void next() {
_iterator.next();
filterForwards();
}
private void filterForwards() {
while (!_iterator.isDone() && !_predicate.evaluate(_iterator.current())) {
_iterator.next();
}
}When filterForwards is called, it is assumed that the underlying iterator will already have been positioned to an element from which to start searching. The method then loops, calling next() until either there are no more elements or a matching element is found. Notice that in all cases, you call methods on the underlying iterator directly. This prevents unnecessary looping, most likely resulting in abnormal program termination in extreme cases.
public void last() {
_iterator.last();
filterBackwards();
}
public void previous() {
_iterator.previous();
filterBackwards();
}
private void filterBackwards() {
while (!_iterator.isDone() && !_predicate.evaluate(_iterator.current())) {
_iterator.previous();
}
}As you did for first() and next(), last() and previous() call their respective methods on the wrapped class before invoking filterBackwards to find an element that satisfies the predicate.
"To understand recursion, we first need to understand recursion." — Anonymous
Imagine a file system such as the one on your computer. As you probably know, a file system has a root directory with many subdirectories (and files), which in turn have more subdirectories (and files). This directory structure is often referred to as a directory tree — a tree has a root and branches (directories) and leaves (files). Figure 2-1 shows a file system represented as a tree. Notice how it is like an inverted tree, however, with the root at the top and the leaves at the bottom.
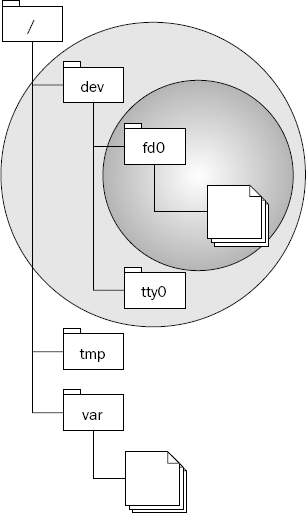
One of the interesting things about "trees" in the computing sense is that each branch looks just like another, smaller tree. Figure 2-2 shows the same tree as before, this time highlighting one of the branches. Notice how the structure is similar to the bigger tree.
This characteristic, whereby some things look the same at different granularities or magnifications, can be applied to solving problems as well. Anytime a problem can be broken down like this into smaller components that look just like the larger one (divide and conquer) is precisely when recursion comes into its own. In a sense, recursion is the ultimate re-use pattern: a method that calls itself.
Let's continue with the file system analogy and write a program to print the contents of an entire directory tree. More often than not, the examples used to demonstrate recursion involve finding prime numbers, fibonacci numbers, and possibly even solving mazes — hardly things you are likely to encounter on a daily basis.
Besides simply printing the names, let's also format the output so that each file and subdirectory is indented under its parent — like a text version of Windows Explorer or Mac OS X Finder. Given what you know about the structure of file systems, you should be able to construct a recursive algorithm to traverse the directory structure by breaking the problem down in such a way that the solution works at one level and then calls itself for each deeper level in the directory tree.
Naturally, you need to start with a class; and as you probably want to run this program from the command line, you will need a main method:
package com.wrox.algorithms.iteration;
import java.io.File;
public final class RecursiveDirectoryTreePrinter {
private static final String SPACES = " ";
public static void main(String[] args) {
assert args != null : "args can't be null";
if (args.length != 1) {
System.err.println("Usage: RecursiveDirectoryTreePrinter <dir>");
System.exit(4);
}
print(new File(args[0]), "");
}
...
}Our program requires the name of a single directory (or file) to be passed on the command line. After performing some rudimentary checking, main() then constructs a java.io.File from the first argument and passes it to a print() method.
Notice that the second argument in the method call is an empty string. This will be used by print() to indent the output, but in this case, because it's the first level of the directory tree you are printing, you don't want any indenting at all, hence the "". The constant SPACES (defined as two spaces) will be used later to increase the indentation.
The print() method accepts a single File and a string that will be used when indenting the output:
public static void print(File file, String indent) {
assert file != null : "file can't be null";
assert indent != null : "indent can't be null";
System.out.print(indent);
System.out.println(file.getName());
if (file.isDirectory()) {
print(file.listFiles(), indent + SPACES);
}
}The code itself is straightforward. First the indentation is printed, followed by the name of the file and a new line. If the file represents a directory (in Java, File objects are used for both individual files and directories), you call a different print() method to process the list of files contained within and the indentation to use them.
Because you are about to nest another level down in the tree, you want to increase the amount of indentation — that is, print everything shifted a couple of spaces to the right. You can achieve this by taking the current indentation and appending the value of the constant SPACES. At first, the indentation would be an empty string, in which case it will increase to two spaces, then four spaces, then six, and so on, thereby causing the printed output to be shifted right each time.
Now, as indicated, the method listFiles() returns an array; and as you don't have a version of print() that accepts one of those yet, let's create one:
public static void print(File[] files, String indent) {
assert files != null : "files can't be null";
for (int i = 0; i < files.length; ++i) {
print(files[i], indent);
}
}This method iterates over the array, calling the original print() method for each file.
Can you see how this is recursive? Recall that the first print() method — the one that takes a single file — calls the second print() method, the one that takes an array, which in turn calls the first method, and so on. This would go on forever but for the fact that eventually the second print() method runs out of files — that is, it reaches the end of the array — and returns.
The following code shows some sample output from running this program over the directory tree containing the code for this book:
Beginning Algorithms
build
classes
com
wrox
algorithms
iteration
ArrayIterator.class
ArrayIteratorTest.class
Iterator.class
IteratorOutOfBoundsException.class
RecursiveDirectoryTreePrinter.class
ReverseIterator.class
ReverseIteratorTest.class
SingletonIterator.class
SingletonIteratorTest.class
src
build.xml
conf
build.properties
checkstyle-header.txt
checkstyle-main.xml
checkstyle-test.xml
checkstyle.xsl
simian.xsl
libantlr-2.7.2.jar
checkstyle-3.5.jar
checkstyle-optional-3.5.jar
commons-beanutils.jar
commons-collections-3.1.jar
getopt.jar
jakarta-oro.jar
jakarta-regexp.jar
jamaica-tools.jar
junit-3.8.1.jar
simian-2.2.2.jar
main
com
wrox
algorithms
iteration
ArrayIterator.java
Iterator.java
IteratorOutOfBoundsException.java
RecursiveDirectoryTreePrinter.java
ReverseIterator.java
SingletonIterator.javaAs you can see, the output is nicely formatted with appropriate indentation each time the contents of a directory are printed. It is hoped that this has demonstrated, in a practical way, how recursion can be used to solve some kinds of problems.
Any problem that can be solved recursively can also be solved iteratively, although doing so can sometimes be rather difficult and cumbersome, requiring data structures that have not been covered yet, such as stacks (see Chapter 5).
No matter what the problem, a recursive algorithm can usually be broken down into two parts: a base case and a general case. Let's reexamine the previous example and identify these elements.
In the example, when you encounter a single file, you are dealing with the problem at the smallest level of granularity necessary to perform whatever action the algorithm has been designed to do; in this case, print its name. This is known as the base case.
The base case, therefore, is that part of the problem that you can easily solve without requiring any more recursion. It is also the halting case that prevents the recursion from continuing forever.
A
StackOverflowExceptionwhile executing a recursive algorithm is often an indication of a missing or insufficient termination condition, causing your program to make more and more nested calls until eventually it runs out of memory. Of course, it might also indicate that the problem you are trying to solve is too large for the computing resources you have available!
The general case, being what happens most of the time, is where the recursive call is made. In the example, the first recursive call occurs when you encounter a file that represents a directory. Having printed its name, you then wish to process all the files contained within the directory, so you call the second print() method.
The second print() method then calls back on the first print() method for each file found in the directory.
Using two methods that call each other recursively like this is also known as mutual recursion.
Iteration and recursion are fundamental to implementing any algorithm. In fact, the rest of this book relies heavily on these two concepts so it is important that you fully understand them before continuing.
This chapter demonstrated the following:
Iteration lends itself more readily to solving some problems while for others recursion can seem more natural.
Iteration is a very simple, straightforward approach to solving many common problems such as performing calculations and processing arrays.
Simple array-based iteration doesn't scale particularly well in most real-world applications. To overcome this, we introduced the concept of an iterator and discussed several different types of iterators.
Recursion uses a divide-and-conquer approach whereby a method makes repeated, nested calls to itself. It is often a better choice for processing nested data structures.
Many problems can be solved using either iteration or recursion.
You will find sample answers to these exercises (and all of the exercises from other chapters as well) in Appendix D, "Exercise Answers."
Create an iterator that only returns the value of every nth element, where n is any integer greater than zero.
Create a predicate that performs a Boolean
AND(&&) of two other predicates.Re-implement
PowerCalculatorusing recursion instead of iteration.Replace the use of arrays with iterators in the recursive directory tree printer.
Create an iterator that holds only a single value.
Create an empty iterator that is always done.