
HTML is probably the first markup language most of us came into contact with. It is a great language, but it’s not without its problems.
For example, HTML mixes content data with the way the information is presented, thereby making it difficult to present the same data in different ways and to standardize presentations across multiple sets of data. Cascading Style Sheets (CSS) significantly reduces this problem but doesn’t completely eliminate it, and it also forces you to learn yet another language.
Another problem, partly due to the way in which HTML is defined, is that the browsers are very forgiving about inconsistently written pages. In many cases, they’re able to render pages with unquoted attribute values and tags that aren’t closed properly. This encourages sloppiness in coding and wastes computer resources.
XML (whose standard is available at www.w3.org/standards/xml/) lets you organize information into a treelike structure in which each item of information represents a leaf. Its power and flexibility lie in the idea of defining its syntax and a mechanism for defining tags. This makes it possible for you to define your own markup language tailored for the type of information you’re dealing with. This also lets you define XHTML, a version of HTML clean of inconsistencies, as a well-formatted XML file.
Also, XML is the perfect vehicle for exchanging structured information. In fact, XML’s purpose is precisely to describe information.
I have introduced XML starting from HTML, because you’re familiar with HTML and they’re both markup languages. However, the usefulness of XML goes well beyond providing a better syntax for HTML. The great advantage of using XML in preference to proprietary formats whenever information needs to be structured is that standardized parsers make the manipulation of XML documents easy. In this chapter, you will also learn how to parse an XML document in JSP with XML custom tags and XPath.
XML represents one of the most used standard methods for the representation of information in many organizations. The other method is JSON (JavaScript Object Notation). JSON is not in the scope of this book, but it is important to introduce it against XML standard. It is a syntax used for storing and exchanging data adopted by organizations for communication instead of XML documents.
Both JSON and XML are used by a lot of programming languages: on one hand XML supports various data types, it offers the capability to display data being a markup language, and it is more secure; on the other, JSON is easy to retrieve (it can be parsed also by JavaScript functions), and it is faster and shorter because it fetches a JSON string. At last, XML presents attributes that let it a better document descriptor and it is more human readable, so it is used for configuration files. So, the choice of technology depends on the scope of your web application.
Cascading Style Sheets
Style sheets are used to separate presentation from content (whose standard is available at www.w3.org/Style/CSS/). The term cascading refers to the fact that you can write a series of style sheets, whereby each one builds upon and refines the styles defined in the more general ones.
You need the following three components to define styles: selector {property: value}
You can place style elements inside the head or body HTML elements of your pages or define styles for individual elements by placing style definitions separated by semicolons in their style attribute.
The XML Document
enterprises.xml
The first line defines the standard and the character set used in the document. The tags are always closed, either with an end tag when they have a body (e.g., <title>...</title>) or with a slash if they’re empty (e.g., <class .../>). There can be repeated tags (e.g., starship), and the attribute names are not unique (e.g., name).
As you can see, the tags reflect the logical structure of the data, although there are certainly many ways of structuring the same information. Each tag identifies an element node labeled with a name (e.g., starfleet, title, and class, also called an element type), often characterized by attributes that consist of a name and a value (e.g., sn="NCC-1701"), and possibly containing child nodes (e.g., captain inside starship), also called sub-elements.
XML documents can also contain processing instructions for the applications that handle them (enclosed between <? and ?>), comments (enclosed between <!-- and -->), and document-type declarations (more about that later). Notice that enterprises.xml doesn’t provide any information concerning how the data it contains might be presented.
Yes, you could. It all depends on what you think you might like to do with the element in the future. With captain defined as an element, you can define attributes for it, such as its birth date. This wouldn’t be possible if you had defined captain as an attribute. And the same applies to the class element. You could also replace the starship attributes name and sn with two children elements, but how much sense would it make?
Defining Your Own XML Documents
The usefulness of being able to use XML tags tailored to your needs is greatly expanded by the possibility of formally specifying them in a separate document. This enables you to verify the validity of the XML documents and also to communicate their structure to others. Without a specification in a standardized format, you would have to describe your document structure in plain language or via examples. It wouldn’t be the most efficient way, and it certainly wouldn’t be good enough for automatic validation. The two most widely used methods to specify document structures are XML DTDs and XML schemas. You will see later on in this chapter that you can select which method your XML document uses for validation by adding an appropriate element to it.
XML DTDs
starfleet.dtd
Line 01 defines the starfleet element as consisting of one title element and an undefined number of starship elements. Replacing the asterisk with a plus sign would require starship to occur at least once, and a question mark would mean zero or one starships. If you replaced starship with (starship|shuttle), it would mean that you could have a mix of starship and shuttle elements following the title (just as an example, because you haven’t defined shuttle).
Line 02 specifies title to be a string of characters (the PC of PCDATA stands for parsed character). Line 07 shows how to specify that an element not be allowed to have a body. To complete the description of how to define elements, I only need to add that if you replaced EMPTY with ANY, it would mean that the element could contain any type of data.
Where attributeType can have a dozen of possible values, including CDATA (to indicate character data), an enumeration of all strings allowed (enclosed in parentheses and with bars as separators, as in (left|right|center)), ID (to indicate a unique identifier), and IDREF (the ID of another element). The defaultValue can be a quoted value (e.g., “0” or “a string”), the keyword #REQUIRED (to indicate that it’s mandatory), the keyword #IMPLIED (to indicate that it can be omitted), or the keyword #FIXED followed by a value (to force the attribute to have that value).
XML Schemas
starfleet.xsd
Lines 02–07 establish that this schema conforms to the standard XML schema and define the schema’s namespace and how XML files are supposed to refer to elements and attributes. To understand it all, you need to learn quite a bit about namespaces and schemas.
Lines 08–12 are essentially a comment.
Lines 13–20 specify the starfleet element, which is of a complex type, as defined in Line 14. This means that starfleet can have attributes and/or can contain other elements. Line 15 tells you in which way starfleet is complex: it contains a sequence of elements. Elements in xs:sequence must appear in the order in which they are specified (in this case, title followed by starship).
Line 16 specifies that title is of type xs:string, which is a primitive type hard-coded in the standard XML Schema. Line 16 also tells you that there can be maximum one title per starfleet. It is also possible to define minOccurs, and the default for both minOccurs and maxOccurs is 1. This means that by omitting minOccurs, you make title mandatory.
Line 17 declares that the starship element is of type ShipType, which is defined somewhere else in starfleet.xsd. This is an alternative to defining the type of an element inside its body, as we did with the starfleet element. Naming a type lets you use it for several element definitions and as a base for more complex types. However, I have only extracted the type specification from the body of starship to make the code more readable. maxOccurs="unbounded" states that there can be as many starship elements in starfleet as you need.
Lines 21–28 define the type of the starship element. It’s a complex type, but it’s different from that of starfleet. The xs:all group means that there can only be up to one element each of all those listed, in any order. This would normally mean that each starship could be empty or contain a class, a captain, or both as children. However, we want to make ship class and captain mandatory. To achieve this result, we specified the attribute minOccurs="1" for both elements.
Lines 26–27 define the two attributes of starship. The use attribute lets you specify that they are mandatory.
If you now look again at enterprises.xml, you’ll notice that the class element has an attribute (name). Because of this attribute, you must define its type as complex, although class has no body. This is done in lines 29–31. As you can see, you specify an empty body by creating a complex type without sub-elements.
Occurrence Constraints
In starfleet.xsd, we used three attributes to limit the number of occurrences: minOccurs and maxOccurs when declaring elements and use when declaring attributes. While the constraints for elements accept non-negative integers as values (with 1 as the default), use can only have one of the following values: required, optional (the default), and prohibited. You can use two additional attributes when declaring either elements or attributes: default and fixed.
When applied to an attribute, default supplies the value of an optional attribute in case it is omitted when you define its element in the XML document (it is an error to provide a default for attributes that are required). Note that when you define elements in an XML document, they’re always created with all their attributes, whether you explicitly define them in the XML document or not, because their existence is determined by their presence in the schema. When applied to an element, default refers to the element content, but it never results in the creation of elements. It only provides content for empty elements, for example, <xs:attribute name="country" type="xs:string" default="USA"/>.
The fixed constraint forces an attribute value or an element content to have a particular value. You can still define a value in the XML document, but it must match the fixed value assigned in the schema.
Data Types
String Data types are used for values containing character strings.
Date Data types are used for values containing date and time.
Numeric Data types are used for values containing numeric elements.
Miscellaneous Data types are used for other specific values.
XML Primitive Types
Type | Example/Description |
|---|---|
String Data types String | It contains characters, line feeds, and tab character, for example, "This is a string". |
Numeric Data types | |
Decimal | It contains numeric values, for example, 123.456. |
Date Data types | |
Date | Like the date portion of dateTime, but with the addition of the time zone. |
dateTime | For example, 2007-12-05T15:00:00.345-05:00 means 345 milliseconds after 3 PM Eastern Standard Time (EST) of December 5, 2007; fractional seconds can be omitted. |
Duration | For example, PaYbMcDTdHeMfS means a years, b months, c days, d hours, e minutes, and f seconds; a minus at the beginning, when present, indicates “in the past”. |
gDay | For example, 25. |
gMonth | For example, 12. |
gMonthDay | For example, 12–25. |
gYear | For example, 2007. |
gYearMonth | For example, 2007–12; g stands for Gregorian calendar, which is the calendar we use. |
Time | Like the time portion of dateTime. |
Miscellaneous Data types | |
base64Binary | MIME encoding consisting of A–Z, a–z, 0–9, +, and /, with A = 0 and / = 63. |
Boolean | For example, true and false. |
Double | Formatted like float, but uses 64 bits. |
Float | 32-bit floating point, for example, 1.2e–4. |
hexBinary | Hexadecimal encoding, for example, 1F represents the number 31 and corresponds to a byte containing the bit sequence 01111111. |
NOTATION | Externally defined formats. |
QName | Qualified XML name, for example, xs:string. |
anyURI | Either an absolute or a relative URI. |
XML Derived Types
Type | Example/Description |
|---|---|
Data types derive from the String data type | |
language | A natural language code as specified in the ISO 639 standard (e.g., FR for French and EN-US for American English) |
normalizedString | A string that doesn’t contain any carriage return, line feed, or tab characters |
token | A string that doesn’t contain any carriage return, line feed, tab characters, leading or trailing spaces, or sequences of two or more consecutive spaces |
Name | A string that contains a valid XML name |
Data types derive from the Numeric data type | |
Byte | An integer number between –27 (–128) and 27–1 (127) |
Int | An integer number between –231 (–2,147,483,648) and 231–1 (2,147,483,647) |
Integer | An integer number |
Long | An integer number between –263 (–9,223,372,036,854,775,808) and 263–1 (9,223,372,036,854,775,807) |
negativeInteger | An integer number < 0 |
nonNegativeInteger | An integer number >= 0 |
nonPositiveInteger | An integer number <= 0 |
positiveInteger | An integer number > 0 |
short | An integer number between –215 (–32,768) and 215-1 (32,767) |
unsignedByte | An integer number between 0 and 28–1 (255) |
unsignedInt | An integer number between 0 and 232–1 (4,294,967,295) |
unsignedLong | An integer number between 0 and 264–1 (18,446,744,073,709,551,615) |
unsignedShort | An integer number between 0 and 216–1 (65,535) |
Simple Types
Besides maxLength, you can also apply the length and minLength attributes to listlike types. Additionally, you can use the whiteSpace and pattern attributes.
The possible values for whiteSpace are preserve (the default), replace, and collapse. With replace, all carriage return, line feed, and tab characters are replaced with simple spaces. With collapse, leading and trailing spaces are removed, and sequences of multiple spaces are collapsed into single spaces.
A regular expression is a string that matches a set of strings according to certain rules. The basic component of a regular expression is called an atom. It consists of a single character (specified either individually or as a class of characters enclosed between square brackets) indicating that any of the characters in the class are a match. For example, both "a" and "[a]" are regular expressions matching the lowercase character ‘a’, while "[a-zA-Z]" matches all letters of the English alphabet.
Things can get complicated, because you can also subtract a class from a group or create a negative group by sticking a ^ character at the beginning of it. For example, "[(^abc) - [ABC]]" matches any character with the exclusion of the characters ‘a’, ‘b’, and ‘c’ in uppercase or lowercase. This is because the group ^abc matches everything with the exclusion of the three letters in lowercase, and the subtraction of [ABC] removes the same three letters in uppercase. Obviously, you could have obtained the same effect with the regular expression "[^aAbBcC]".
The characters |.-^?*+{}()[] are special and must be escaped with a backslash. You can also use for newlines, for returns, and for tabs.
With atoms, you can build pieces by appending to it a quantifier. Possible quantifiers are ? (the question mark), + (the plus sign), * (the asterisk), and {n,m}, with n <= m indicating non-negative integers. The question mark indicates that the atom can be missing; the plus sign means any concatenation of one or more atoms; the asterisk means any concatenation of atoms (including none at all); and {n,m} means any concatenation of length >= n and <= m (e.g., "[a-z]{2,7}" means all strings containing between two and seven lowercase alphabetic characters). If you omit m but leave the comma in place, you leave the upper limit unbounded. If, on the other hand, you also omit the comma, you define a string of fixed length (e.g., "[0-9]{3}" means a string of exactly three numeric characters). You can concatenate pieces simply by writing them one after the other. For example, to define an identifier consisting of alphanumeric characters and underscores but beginning with a letter, you could write the expression "[a-zA-Z]{1}[a-zA-Z0-9_]*". The general term branch is used to indicate a single piece or a concatenation of pieces when the distinction is not relevant.
To specify partial patterns, you can insert at the beginning and/or at the end of each atom a sequence formed with a period and an asterisk. For example, ".*ABC.*" identifies all strings containing in any position the substring ABC. Without dot-asterisk wildcarding, "ABC" only matches a string of exactly three characters of length.
Several branches can be further composed by means of vertical bars to form a more general regular expression. For example, "[a-zA-Z]* | [0-9]*" matches all strings composed entirely of letters or of digits but not a mix of the two.
Complex Types
whatever
no, whatever
yes1, whatever
yes2, whatever
yes1, yes2, whatever
yes2, yes1, whatever
Complex type definitions provide many additional options, but are not always easy to handle. One might even argue that they’ve been overengineered. Therefore, to describe them in detail would exceed the scope of this manual. Nevertheless, the information I have provided on primitive and simple types, together with the description of the three model groups, is already enough to cover most cases.
Validation
An XML document is said to be valid if it passes the checks done by a validating parser against the document’s DTD or XML schema. For the parser to be able to operate, the XML document must be well formed, which means that all tags are closed, the attributes are quoted, the nesting is done correctly, and so on. A validating parser, besides checking for well formedness, also checks for validity.
You actually have to validate two documents: the XML file and the DTD or XML Schema. In the example, those are enterprises.xml and starfleet.dtd/starfleet.xsd, respectively. The simplest way to do the validation is to use a development environment like Eclipse, which validates the documents as you type. An alternative is to use online services. For example, the tool available at http://xmlvalidation.com can check XML files, DTD files, and XML schemas.
- 1.
Associate the document to the DTD/schema against which it is to be validated.
- 2.
Define an exception handler to specify what happens when a validation error is detected.
- 3.
Parse the document with a validating parser, which validates your XML document against the DTD/schema.
A parser is a piece of software that breaks down a document into tokens, analyzes the syntax of the tokens to form valid expressions, and finally interprets the expressions and performs corresponding actions.
DOM parsers build a tree of nodes after loading the whole document in memory. Therefore, they require quite a bit of memory. SAX, on the other hand, parses the documents from streams and therefore has a smaller memory footprint. The flexibility of the DOM also costs in terms of performance, and DOM implementations tend to be slower than SAX implementations, although they might overall be more efficient with small XML files that don’t stretch memory usage. The two most widely used packages implementing DOM and SAX are Xerces and Java API for XML Processing (JAXP). I have used JAXP in all the examples of this chapter: it is present in the JDK package.
However, you could also use the Xerces package. Xerces are the developer of SAX, and the version of SAX included in JAXP is not identical to the original one. You can install the Xerces version downloaded from http://xerces.apache.org/. All you need to do is click "Xerces-J-bin.2.12.1.zip" (the binary distribution) under the heading Xerces2 Java (there might be a newer version when you go there), expand Xerces-J-bin.2.12.1.zip, and copy xercesimpl.jar in the project's lib folder of the software package of this chapter. The latest version release of xercesImpl.jar (2.12.1) contains DOM level 3, SAX 2.0.2, and the JAXP 1.4 APIs as well as of the XNI API (the Xerces Native Interface). I have included starfleet_validate_sax_schema_xerces.jsp in the software package (xml-validate) of this chapter as an example.
Using JSP to Validate XML Against a DTD
Notice that the file starfleet.dtd doesn’t need to be in the WEB-INFdtd folder. We had to place the DTDs there because Tomcat expected them there, but if you do the validation yourself, Tomcat is out of the loop. You can therefore place your DTDs wherever you like.
ParsingExceptionHandler.java
As you can see, it’s pretty simple. You define two public attributes: one to save the exception generated by the parser and one to save the error level. You then update the two attributes in each one of the three methods. After each parsing, you can check one of the attributes for null in order to determine whether the parsing succeeded or not.
starfleet_validate_sax.jsp (first cut)
After instantiating the parser factory and setting its validating property to true, you direct the factory to create a SAX parser. Then you instantiate the InputSource class to access the XML document and the exception handler. After that, all you need to do is execute the parser.
This implementation is not very nice, though, because it causes the dumping of a stack trace whenever the validation fails. It is better to wrap the parsing inside a try/catch as shown in Listing 7-6, so that you can display validation errors without stack trace.
Note that before you can execute the improved version of starfleet_validate_sax.jsp, you need to download the StringEscapeUtils from Apache Commons. Their purpose is to convert special characters to their corresponding HTML entities, so that they display correctly in your web page. Go to http://commons.apache.org/proper/commons-text/download_text.cgi and click the link commons-text-1.8-bin.zip.
starfleet_validate_sax.jsp
Now, if you type http://localhost:8080/xml-validate/with-dtd/starfleet_validate_sax.jsp in a browser, you should get a one-liner confirming that enterprises.xml is correct.
starfleet_validate_dom.jsp
Using JSP to Validate XML Against a Schema
The procedure used to validate an XML file against a schema is almost identical to the procedure explained in the previous section for validating against a DTD.
To avoid confusion, I made copies of enterprises.xml and starfleet_validate_sax.jsp and renamed them, respectively, enterprises_schema.xml and starfleet_validate_sax_schema.jsp.
starfleet_validate_sax_schema.jsp
As you can see, apart from updating the page title and the name of the XML file, you only need to switch on two features of the parser that tell it to use a schema instead of a DTD.
What I said about changing SAX to DOM in starfleet_validate_sax.jsp also applies to starfleet_validate_sax_schema.jsp. You will find starfleet_validate_dom_schema.jsp in the software package for this chapter.
JSTL-XML and XSL
The XML actions specified in JSTL are meant to address the basic XML needs that a JSP programmer is likely to encounter.
To make XML file contents easier to access, the W3C specified the XML Path Language (XPath). The name XPath was chosen to indicate that it identifies paths within XML documents (see www.w3.org/TR/xpath). The JSTL-XML actions rely on that language to identify XML components.
To avoid confusion between EL expressions and XPath expressions, the actions that require an XPath expression always use the select attribute. In this way, you can be sure that all expressions outside select are EL expressions. Several XML actions are the XPath counterparts of equivalent core actions, with the attribute select replacing the attribute value (when present). They are x:choose, x:forEach, x:if, x:out, x:otherwise, x:set, and x:when.
The remaining three actions are x:parse and the pair x:transform and x:param. But before you can learn about them, we have to talk about the Extensible Stylesheet Language (XSL).
XSL is a language for expressing style sheets that describe how to display and transform XML documents. The specification documents are available from www.w3.org/Style/XSL/.
While CSS only needs to define how to represent the predefined HTML tags, XSL has to cope with the fact that there are no predefined tags in XML! How do you know whether a <table> element in an XML file represents a table of data as you know it from HTML or an object around which you can sit for dinner? That’s why XSL is more than a style-sheet language. It actually uses XPath (the language to navigate in XML documents), XQuery (the language for querying XML documents), and XSLT (a language to transform XML documents that can completely change their structure).
XPath
XPath expressions identify a set of XML nodes through patterns. Extensible Stylesheet Language Transformations (XSLT) templates (see later in this chapter for XSLT examples) then use those patterns when they apply transformations. Possible XPath nodes can be any of these: document/root, comment, element, attribute, text, processing instruction, and namespace.
The document (or root) node is <whatever>, <!-- bla bla --> is a comment node, <subitem>...</subitem> is an element node, name="anything" is an attribute node, the string The quick brown fox is a text node, <?myAppl "xyz"?> is a processing-instruction node, and xmlns:zzz="http://myWeb.com/whatever" is a namespace node.
As with URLs, XPath uses a slash as a separator. Absolute paths start with a slash, while all other paths are relative. Similar to file directories, a period indicates the current node, while a double period indicates the parent node.
The pattern /a/b selects the four <b> elements, which contain whatever, never, nice, and ok. The <b> element with verywell isn’t selected, because it’s inside <c> instead of <a>. The pattern /a[1]/b[0] selects the <b> element with nice. Attribute names are prefixed by an @. For example, /a[1]/b[1]/@attr refers to the attribute that has the value xxx in the example.
A clever thing in XPath: you can use conditions as indexes. For example, /a/b[@attr="zz"] selects the same <b> element selected by /a[1]/b[0], while /a[b] selects all <a> elements that have <b> as a child (in the example, both), and /a[b="never"] selects the first <a> element. A final example: /a/b[@attr][0] selects the first <b> element that is contained in an <a> and has the attribute attr (i.e., it selects once again the element /a[1]/b[0]).
XPath defines several operators and functions related to node sets, positions, or namespaces, and it defines string, numeric, boolean, and conversion operations.
A node set is a group of nodes considered collectively. A node set resulting from the execution of an XPath expression doesn’t necessarily contain several nodes. It can consist of a single node or even none. Keep in mind that the nodes belonging to a node set can be organized in a tree, but not necessarily. For example, the expression $myDoc//C identifies all C elements in a document that was parsed into the variable myDoc. It is unlikely that they form a tree.
XPath Mappings of Implicit JSP Objects
JSP | XPath |
|---|---|
pageContext.findAttribute("attrName") | $attrName |
request.getParameter("parName") | $param:paramName |
request.getHeader("headerName") | $header:headerName |
cookie's value for name foo | $cookie:foo |
application.getInitParameter("initParName") | $initParam:initParName |
pageContext.getAttribute("attrName", PageContext.PAGE_SCOPE) | $pageScope:attrName |
pageContext.getAttribute("attrName", PageContext.REQUEST_SCOPE) | $requestScope:attrName |
pageContext.getAttribute("attrName", PageContext.SESSION_SCOPE) | $sessionScope:attrName |
pageContext.getAttribute("attrName", PageContext.APPLICATION_SCOPE) | $applicationScope:attrName |
Before we look at an XPath example, I would like to give you a more rigorous reference of its syntax and explain some terms that you are likely to encounter “out there.”
To identify a node or a set of nodes, you need to navigate through the tree structure of an XML document from your current position within the tree (the context node) to the target. The path description consists of a series of steps separated by slashes, whereby each step includes the navigation direction (the axis specifier), an expression identifying the node[s] (the node test), and a condition to be satisfied (the predicate) enclosed between square brackets.
where child, ::, and position()= are simply omitted and attribute is represented by @.
Axis Specifiers
Specifier | Abbreviated Syntax |
|---|---|
Ancestor | Not available (n/a) |
ancestor-or-self | n/a |
Attribute | @ |
Child | Default; do not specify it |
Descendant | // |
descendant-or-self | n/a |
Following | n/a |
following-sibling | n/a |
Namespace | n/a |
Parent | (i.e., two dots) |
Preceding | n/a |
preceding-sibling | n/a |
Self | (i.e., a single dot) |
As node tests, you can use node names with or without a namespace prefix, or you can use an asterisk to indicate all names. With abbreviated syntax, an asterisk on its own indicates all element nodes, and @* indicates all attributes.
You can also use node() as a node test to indicate all possible nodes of any type. Similarly, comment() indicates all comment nodes, text() indicates all text nodes, and processing-instruction() indicates all processing-instruction nodes.
To form expressions, besides the operators you have already seen (i.e., slash, double slash, and square brackets), you have available all standard arithmetic and comparison operators (i.e., +, -, *, div, mod, =, !=, <, <=, >, and >=). Additionally, you have and and or for boolean operations and the union operator | (i.e., the vertical bar) to merge two node sets.
where I parse an XML document into the variable dom and then use $dom when I refer to it in an XPath expression.
An XPath Example
starfleet.xml

Starfleet information parsing XML file
starfleet.jsp
In line 04, you load the XML file in memory, and in line 05, you parse it into an object of type org.apache.xerces.dom.DeferredDocumentImpl, which implements the standard interface org.w3c.dom.Document of a Document Object Model (DOM). In lines 13–21, you loop through all the starship tags of the DOM, regardless of how “deep” they are in the structure. You can achieve this with the double slash. Inside the x:forEach loop, the variable tag refers in turn to each starship, and you can display the information contained in attributes and sub-elements. Notice that the select paths inside the loop always start with the slash. This is because the root element in each loop iteration is a starship tag, not starfleet, which is the root element of the document.
x:parse
x:parse Attributes
Attribute | Description |
|---|---|
doc | Source XML document to be parsed. |
varDom | Name of the EL variable to store the parsed XML data as an object of type org.w3c.dom.Document. |
scopeDom | Scope for varDom. |
filter | Filter of type org.xml.sax.XMLFilter to be applied to the source XML. |
systemId | System identifier for parsing the XML source. It is a URI that identify the origin of the XML data, potentially useful to some parsers. |
var | Name of the variable to store the parse XML data (of implementation-dependent type). |
scope | Scope for var. |
xml | Text of the document to parse. |
Instead of storing the XML source code in the attribute doc, you can also make x:parse a bodied action and store the source XML in its body.
What About JSON?
Now can we represent Starfleet in another way and convert it in HTML with another technology? The answer is JSON. JSON is a free and independent data format derived from JavaScript. It is regularly used for reading data from a web server, and for displaying them the data in a web page, simply because its format is only text. Now, it is useful to introduce at first JavaScript basics.
JavaScript
JavaScript is the most widely used client-side scripting language on the Web. By adding it to your web pages, you can make your pages do things, such as prevalidate forms or immediately react to a user’s actions. The syntax of JavaScript was modeled on that of Java. Therefore, if you know Java, you should find JavaScript easy to learn.
One noteworthy difference from Java is that you can omit variable declarations in the top-level code. Moreover, JavaScript lacks Java’s static typing and strong type checking. This gives you more freedom, but it comes with the risk of messing things up in a big way. JavaScript relies on built-in objects, but it does not support classes or inheritance. It is an interpreted language, and object binding is done at runtime.
JavaScript is also the most popular implementation of ES.ECMAScript (abbreviated to ES) standard upon which it is based. This standard, its implementations and its evolution in time, represents the importance of this technology. Moreover, ESNext is the name that indicates the future version of JavaScript and of its new features than will be added to different engines implemented in projects widely used in web application (e.g., node.js, angular.js, etc.). Similarly JavaScript is also the base of TypeScript, an open source programming language used for developing JavaScript applications.
Parsing JSON
Now, I will introduce a simple example that uses the JSON.parse function of JavaScript for parsing a JSON file in an html script. You can import in Eclipse the project “jsonexample” to analyze it. JSON.parse is a function that converts a string (written in JSON) into a JavaScript object. Its simplicity shows why it is used in many sectors as NoSQL database management or social media websites. It is characterized by a comma-separated list of properties and delimited by braces. It is also can be validated to ensure that required properties are met.
JSON Types
Attribute | Description |
|---|---|
Number | Signed decimal number |
String | Sequence of characters |
Boolean | Values true or false |
Array | Ordered list of zero or more values |
Object | Collection of properties where the keys are strings |
Null | Empty value |
JSON Starfleet Example File
In this example, the starship is a type array within five objects with the following keys: Name, SN, Class, Year, and Captain.
starfleet.js
jsontest.html
JSON.parse used to convert the string into a JavaScript object
insertRow used to dynamically insert a new row in an html table
insertCell used to dynamically insert a new cell in a row
innerHTML property used to insert an element in the HTML content

Starfleet information parsing JSON file
As you can see, it is the same of Figure 7-1. Very simple, isn’t it?
There are a lot of websites and books that analyze JSON in detail: the validation, the standardization, the grammar, the features, the fields of application, and its Java third-party APIs (e.g., mJson.Gson) available for parsing and creating JSON objects. This is only a simple introduction for everyone who is interested to this technology and to a smart comparison with XML.
XSLT: Transformation from One XML Format to Another
At the beginning of this chapter, I showed you the file enterprises.xml (Listing 7-1), and, later on, to explain XPath, I expanded it to starfleet.xml (Listing 7-9).
The presence of a title element
The removal in the class element of the commissioned attribute
The replacement of the class body with an attribute named name
enterprises.xsl
Lines 01 and 02 state that the file is in XML format and specify its namespace. In line 02, you could replace xsl:stylesheet with xsl:transform, because the two keywords are considered synonyms.
Line 03 specifies that the output is also an XML document. XML is the default output format, but by writing it explicitly, you can also request that the output be indented. Otherwise, by default, the generated code would be written on a single very long line. The element also lets you specify an encoding other than ISO-8859-1.
The xsl:template element associates a template to an element, and in line 04, you write match="/" to specify the whole source document. In lines 05–06 and 25, you write the enterprise and title elements to the output.
The loop between lines 07 and 24 is where you scan all the starship elements. Immediately inside the loop, you select the two starships you’re interested in with an xsl:if. In XSL, you could have also used the choose/when/otherwise construct that you encountered in Chapter 6 when I described JSTL-core, but in this case, it would not be appropriate, because you do not need an else.
The actual work is done in lines 09–22. The xsl:element and xsl:attribute elements create a new element and a new attribute, respectively, while xsl:value-of copies data from the source XML file to the output. Notice that the XPath expressions in the select attributes are relative to the current element selected by xsl:for-each. Also, notice that the only difference between the source and the output is handled in lines 17–19, where you assign to the name attribute of the class element what was originally in the element’s body. The class attribute commissioned is simply ignored, so that it doesn’t appear in the output.
The xsl:copy-of element copies the whole element to the output, including attributes and children elements. If you only want to copy the element tag, you can use xsl:copy.
XSL includes more than 30 elements, but the dozen or so that I have just described cover the vast majority of what you are likely to need. You will find the official documentation about XSLT at www.w3.org/TR/xslt.
XSLT: Transformation from XML to HTML
As you have seen, you can use XPath in a JSP page to navigate through an XML document and display it in HTML format. In this section, I’m going to show you how you can use XSLT to transform the same starfleet.xml directly into HTML. The two strategies are subtly different: with JSP, you pick up the nodes one by one and display them in HTML; with XSLT, you specify how the nodes of the XML files are to be mapped into HTML elements.
starfleet.xsl
After the first example (Listing 7-14), it should be clear how this works. There is just one point I would like to clarify: if you wanted to, you could omit the third line because, although the default output format is XML, XSL automatically recognizes that you’re generating HTML if the first tag it encounters is <html>. Nevertheless, I recommend that you define the output format explicitly so that you can set HTML version, encoding, and indentation.
XSL Transformation: Browser Side vs. Server Side
I still haven’t told you how to apply an XSL style sheet to an XML file to perform the transformation. This is because I first have to clarify the distinction between browser-side vs. server-side transformation.
Browser-Side XSL Transformation
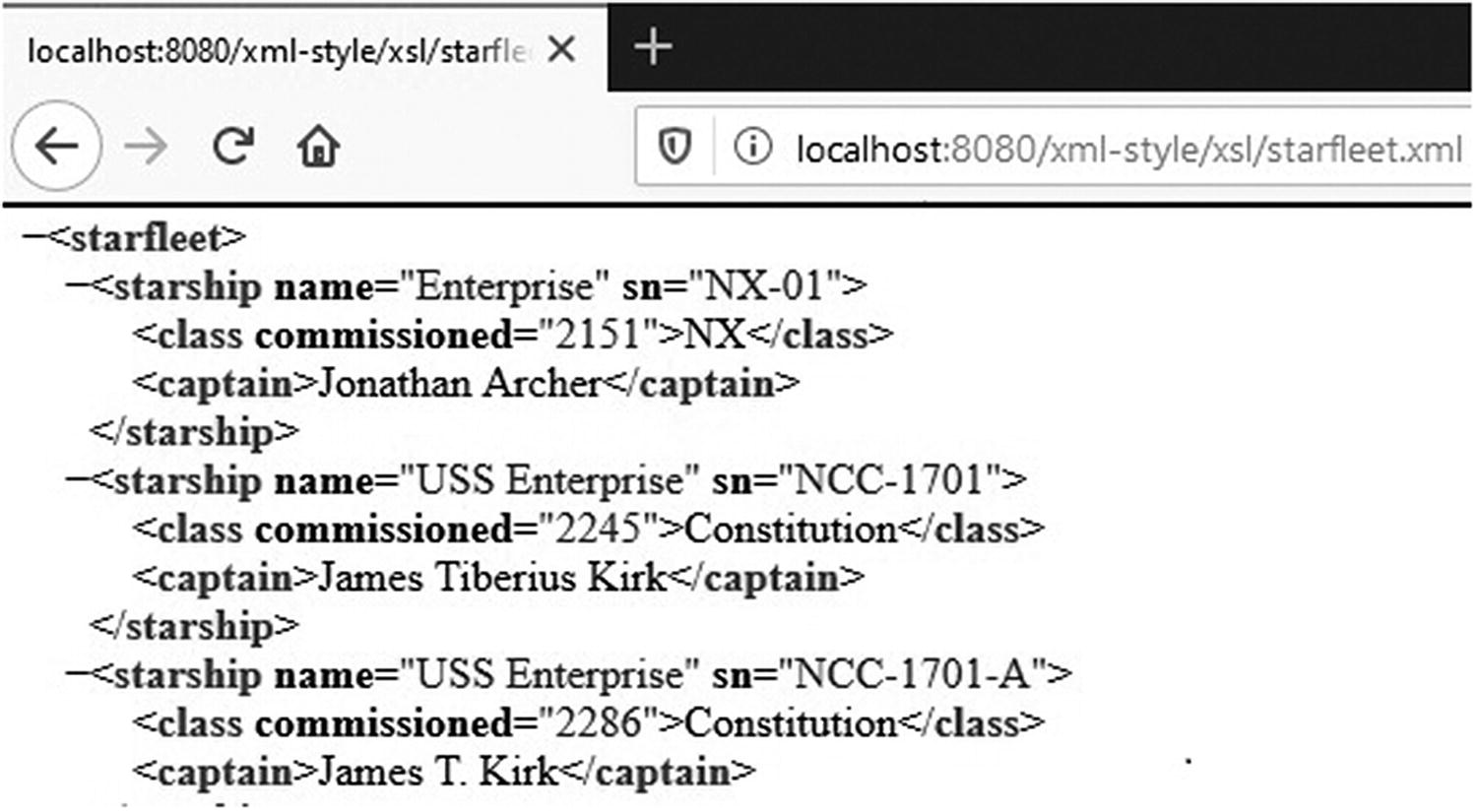
Browsing an XML file without XSL
The browsers can provide this feature because they “know” how to display XML. You probably will see a message at the top of the page indicates that the browser displays the file as a node tree in a generic way because the file doesn’t refer to any XSL style sheet. But all browsers color-code the different components.

Browsing an XML file with XSL
With any browser, if you view the page source, you’ll see the XML file, because it is the browser that does the transformation from XML to HTML. Therefore, the source file is in fact the XML document.
One thing to keep in mind is that the user can also easily obtain your XSL file, because its URL is shown in the XML source. You can display its source and discover the relative URL of the style sheet. Then, you only need to type http://localhost:8080/xml-style/xsl/starfleet.xsl to see the XSL file.
Server-Side XSL Transformation
enterprises_transform.jsp
It looks more complicated than it actually is. Moreover, I have hard-coded the file names for simplicity, but you can add to the JSP page a simple input form to set inFile and xslFile, and you’ll have a small utility you can use to transform all XML files. Following the MVC architecture, you should place the application logic in a servlet (i.e., the Controller), not in a JSP page. But I just wanted to show you in the simplest possible way how this is done in JSP/Java.
- 1.
It instantiates a generic TransformerFactory and uses it to create a Transformer that implements the XSL (lines 19 and 20).
- 2.
In line 21, it registers with the transformer the exception handler that was instantiated in line 17. This is similar to what you did to handle validation exceptions.
- 3.
It opens an input stream to read the XML file and an output stream to write the document that will result from the transformation (lines 22 and 23).
- 4.
It finally does the transformation (line 24).
TransformerExceptionHandler.java
The JSP page enterprises_transform.jsp applies the style sheet enterprises.xsl to starfleet.xml to produce enterprises_out.xml. If you change the file names in lines 15–16 to starfleet.xsl and starfleet_out.html, the same page will generate a file that, when viewed in a browser, will appear identical to what you see in Figure 7-4.
My apologies if you find all these variations of XML files somewhat confusing. My purpose is to show you most of the possibilities you have for validating and converting XML files. In real life, you will pick the solution that suits your needs best and stick to it. In any case, I’m not done yet, because there is still one way of implementing server-side transformations that I want to show you.
x:transform and x:param
x:transform Attributes
Attribute | Description |
|---|---|
Doc | The well-formed source XML document to be transformed. It can be an object of type java.lang.String, java.io.Reader, javax.xml.transform.Source, org.w3c.dom.Document, or an object resulting from x:parse or x:set. |
Xslt | The transformation style sheet of type java.lang.String, java.io.Reader, or javax.xml.transform.Source. |
var | Name of the EL variable to store the transformed XML document as an object of type org.w3c.dom.Document. |
scope | Scope for var. |
docSystemId | System identifier for parsing the XML source. It is a URI that identifies the origin of the XML data, potentially useful to some parsers. |
xsltSystemId | Like docSystemId but for the XSL style sheet. |
result | Result object to accept the transformation's result. |
starfleet_tag_transform.jsp
At this point, you might ask: why on earth did we go through the complex implementation of enterprise_transform.jsp and TransformerExceptionHandler.java (Listings 5-13 and 5-14) when we can achieve an equivalent result with six lines of code?
There are two reasons: the first one is that you might in the future encounter a situation in which you need to do it the “hard way”; the second reason is that I like to “peek under the hood” every now and then, and I thought you might like to do the same.
JSP in XML Syntax
JSP pages with scripting elements aren’t XML files. This implies that you cannot use XML tools when developing JSP pages. However, it is possible to write JSP in a way to make it correct XML. The trick is to use standard JSP actions, JSTL with EL, and possibly non-JSTL custom actions. Actually, there are some “special standard” JSP actions defined to support the XML syntax (jsp:root, jsp:output, and jsp:directive). In any case, such XML modules are called JSP documents , as opposed to the JSP pages written in the traditional non-XML-compliant way.
Partial hello.jspx
Line 01 states that the file is XML-compliant. The root element in lines 02–07 has several purposes. For example, it lets you use the jsp extension instead of the recommended jspx. It’s also a convenient place where you can group namespace declarations (xmlns). The namespace declaration for the JSTL core tag library is the XML equivalent of the taglib directive in JSP pages. You don’t need to specify the JSP namespace in JSP pages, but you cannot omit it in a JSP document; otherwise, the jsp: tags won’t be recognized.
Lines 08–11 are the XML equivalent of the page directive of JSP pages. Also the include directive has its XML equivalent with the element <jsp:directive.include file="relativeURL"/>.
Notice that the string “Hello World!” in line 15 is enclosed within the jsp:text element. This is necessary, because in XML you cannot have “untagged” text.
Yes, it’s quite a bit of work just to write “Hello World!”, but this overhead is going to stay the same for JSP documents of any size. The first line causes the <?xml ... ?> elements to be written at the beginning of the generated HTML page, while the second element generates the DOCTYPE.
hello.jspx
starfleet.jspx
The first 17 lines are identical to the corresponding lines of hello.jspx, while the rest of the document is identical to the corresponding lines of starfleet.jsp, with the only addition of the closing tag for jsp:root. This is because starfleet.jsp didn’t include any scripting element or untagged text.
What About Eshop and the XML Syntax?
You have just learned about writing JSP documents instead of JPS pages. What impact does that have on what I just said in Chapter 5 about database access? None! This is a consequence of the MVC model: JSP is the view, while only the model has to do with databases.
OrderConfirmation.jsp
OrderConfirmation.jspx
Let’s concentrate on the highlighted code, where the actual work is done. The saving of the order information in the database, which you do in the JSP page (Listing 7-21) by executing a data manager’s method (lines 19–22), you do in the JSP document (Listing 7-22) by executing a custom action (line 31). The same custom action also invalidates the session (which was done in line 24 of the JSP page).
The if/else Java construct in lines 23, 31–32, and 34 of the JSP page becomes in the JSP document the JSTL core construct choose/when/otherwise in lines 32–33, 38–39, and 41–42.
Informing the user of the order acceptance is in HTML and remains basically the same (JSP lines 26–29 become JSPX in lines 34–37). In fact, you could have replaced the scripting expression of the JSP page with the EL expression of the JSP document, making the code identical.
The introduction of the custom action insertOrder is necessary because scriptlets, being Java code, can make assignments and execute methods, while EL expressions cannot. Therefore, when you remove scriptlets because they’re not valid XML code, you have to move the computation to Java beans or custom actions.
InsertOrderTag Definition in eshop.tld
InsertOrderTag.java
Notice how you obtain the servlet context (corresponding to the JSP implicit object application) from pageContext, and from it the data manager, so that you can then execute the same insertOrder method you invoked directly from within the JSP page.
Summary
In this chapter, you learned about the structure and the syntax of XML documents, DTDs, and XML schemas.
You then saw several ways of how to validate XML documents against DTDs and schemas. Next, I introduced you to XSL and explained examples of XPath use and of transformation from XML to XML and from XML to HTML. For the last case, I also introduced a comparison with JSON.
Moreover, I showed how you can convert JSP pages with directives and scripting elements into JSP documents that are fully XML-compliant. To conclude, I showed you an implementation of E-shop application with the XML syntax.
Brace yourself, because in the next chapter I will finally talk about JSF!